1. Basic status of flick
Flink has two basic states: operator state and keyed state. Their main difference is that the scope of action is different. The scope of action of operator state is limited to operator tasks (that is, when the current partition is executed, all data can access the state). In the keying state, not all data in the current partition can access all States. Instead, it is divided according to the key after keyby. The current key can only access its own state.
1.1 Operator State
As the name suggests, the state is bound to the operator, and the state of an operator cannot be accessed by other operators. State all data processed by the same parallel task can access the same state, and the state is shared for the same parallel task. Operator state cannot be accessed by another task with the same or different operators.
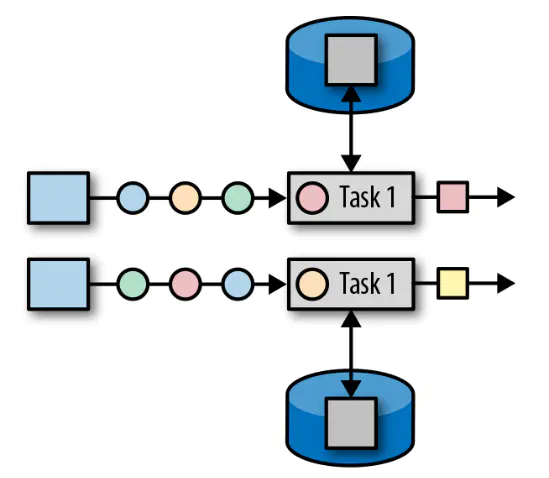
Kafka Connector is a good example of the use of operator state.
Each parallel instance of Kafka consumer maintains a mapping of topic partition and offset as its operator state.
When changing parallelism, the operator state interface supports reallocation of states in parallel instances. There are several options for performing this reassignment.
1.1.1 types of operator States
There are three basic data structures for operator states:
BroadcastState is the operator state used for broadcasting.
BroadcastState is a special type of Operator State. It is introduced to support the use cases that need to broadcast the records of a flow to all downstream tasks. These records are used to maintain the same state among all subtasks.
ListState represents a state as a list of a set of data.
UnionListState stores the state of list type. The difference from ListState is that if the parallelism changes, ListState will summarize all concurrent state instances of the operator and then distribute them to new tasks; The UnionListState only summarizes all concurrent state instances, and the specific division behavior is defined by the user.
1.2 type of keying state
Flink's Keyed State supports the following data types:
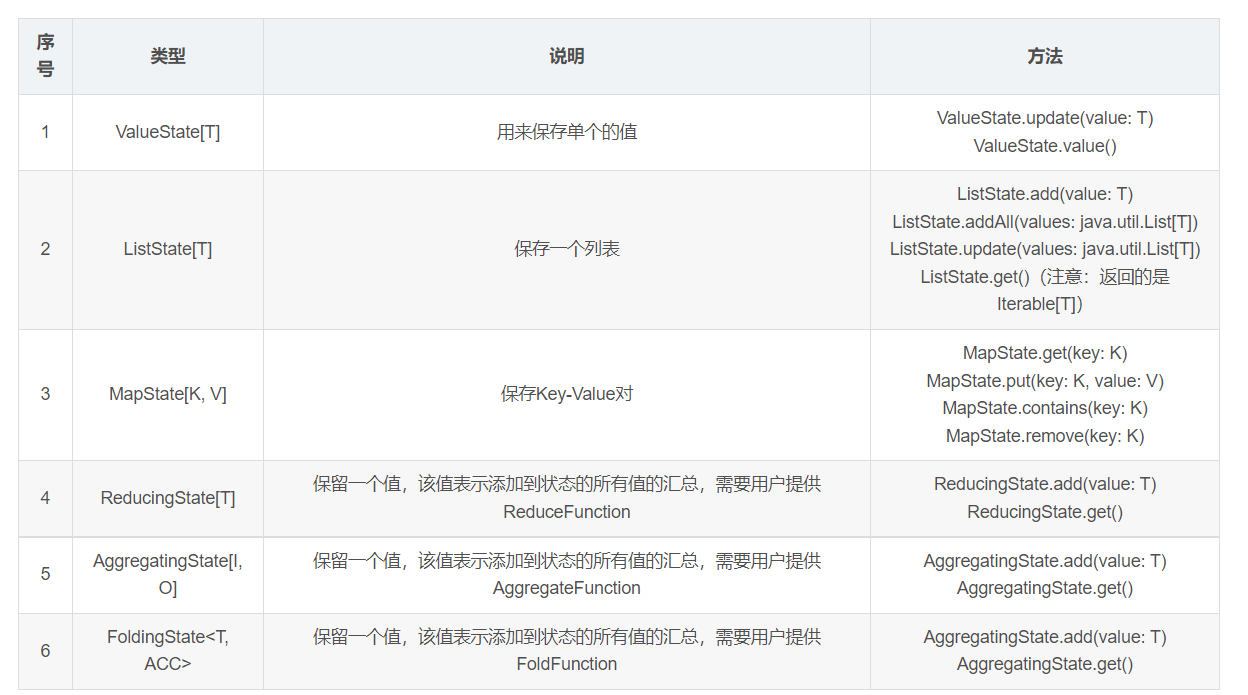
Features and notes:
1. Each state has clear()This is an empty operation. 2.When using keyed state, the flow must be controlled group by Field for. 3. Set the monitoring status, which needs to be passed during status programming RuntimeContext register StateDescriptor. StateDescriptor In state state The name and stored data type are parameters. 4.ttl Policies are set according to your business needs. 5. The status storage should be cleared regularly or according to certain rules. If there is a large amount of data, it will lead to oom.
2. Use the ListState of flynk
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
import java.math.BigDecimal;
import java.util.Collections;
import java.util.List;
@Slf4j
public class SnapshotProcessFunction extends RichFlatMapFunction<Snapshot, Snapshot> {
//Previous operation records
private transient ListState<Snapshot> listState;
/***Status initialization*/
@Override
public void open(Configuration parameters) {
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(1))
// Update only when creating and writing
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ListStateDescriptor descriptor = new ListStateDescriptor<Snapshot>("listDescriptor", Snapshot.class);
descriptor.enableTimeToLive(ttlConfig);
listState = getRuntimeContext().getListState(descriptor);
}
@Override
public void flatMap(Snapshot snapshot, Collector<Snapshot> out) throws Exception {
//Take state
Iterable<Snapshot> snapshots = listState.get();
//If empty, initialize
if (snapshots == null) {
listState.addAll(Collections.emptyList());
} else {
//Not null, add
listState.add(snapshot);
}
List<Snapshot> allEles = Lists.newArrayList(listState.get());
Snapshot prevSnapshot = null;
if (allEles.size() >= 2) {
prevSnapshot = allEles.get(allEles.size() - 2);
}
if (prevSnapshot != null) {
snapshot.setLowPx(prevSnapshot.getLowPx());
snapshot.setHighPx(prevSnapshot.getHighPx());
snapshot.setIncrementVolume(snapshot.getVolume() - prevSnapshot.getVolume());
snapshot.setIncrementAmount(snapshot.getAmount().subtract(prevSnapshot.getAmount()));
// Yesterday's closing price is the closing price of the previous cycle
snapshot.setPreClosepx(prevSnapshot.getLastPx());
} else {
snapshot.setIncrementVolume(snapshot.getVolume());
snapshot.setIncrementAmount(snapshot.getAmount());
}
out.collect(snapshot);
// This is also a clear processing logic, which can be processed according to business needs.
// Clear all first
listState.clear();
// Inserting objects from the previous cycle into the collection
listState.add(allEles.get(allEles.size() - 1));
}
}
reference resources:
https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/datastream/fault-tolerance/state/