1, Introduction to load balancing
1.1. Challenges faced by large websites
Large websites have to face the challenges of huge number of users, high concurrency, massive data and so on. In order to improve the overall performance of the system, vertical expansion and horizontal expansion can be adopted.
Vertical expansion: in the early stage of website development, the server processing capacity can be improved from the perspective of single machine by increasing hardware processing capacity, such as CPU processing capacity, memory capacity, disk, etc. However, a single machine has a performance bottleneck. Once the bottleneck is touched, if you want to improve it, the cost and price will be very high. This obviously can not meet all the challenges of large-scale distributed systems (websites), such as large traffic, high concurrency, massive data and so on.
Horizontal expansion: share the traffic of large websites through clusters. The application servers (nodes) in the cluster are usually designed to be stateless. Users can request any node, and these nodes share the access pressure together. Horizontal expansion has two main points:
-
Application Cluster: deploy the same application to multiple machines to form a processing cluster, receive requests distributed by load balancing devices, process them, and return corresponding data.
-
Load balancing: distribute user access requests to nodes in the cluster through some algorithm.
1.2. What is load balancing
Load Balance (LB) is an essential component of high concurrency and high availability system. The goal is to try our best to distribute the network traffic evenly to multiple servers, so as to improve the overall response speed and availability of the system.
The main functions of load balancing are as follows:
High concurrency: load balancing adjusts the load through the algorithm and tries to evenly distribute the workload of each node in the application cluster, so as to improve the concurrent processing capacity (throughput) of the application cluster.
Scalability: add or reduce the number of servers, and then the distribution is controlled by load balancing. This makes the application cluster scalable.
High availability: the load balancer can monitor candidate servers. When the server is unavailable, it will automatically skip and distribute the request to the available servers. This makes the application cluster highly available.
Security protection: some load balancing software or hardware provide security functions, such as black-and-white list processing, firewall, anti DDos attack, etc.
2, Classification of load balancing
There are many technologies supporting load balancing, which can be classified through different dimensions.
2.1 carrier dimension classification
From the perspective of carriers supporting load balancing, load balancing can be divided into two categories: Hardware load balancing and software load balancing
2.1.1 hardware load balancing
Hardware load balancing is generally an independent load balancing server running on a custom processor, which is expensive and exclusive to local tyrants. The mainstream products of hardware load balancing are F5 and A10.
Advantages of hardware load balancing:
-
Powerful: support global load balancing and provide more comprehensive and complex load balancing algorithms.
-
Strong performance: Hardware load balancing runs on a special processor, so it has a large throughput and can support more than one million concurrency of a single machine.
-
High security: it often has security functions such as firewall and anti DDos attack.
Disadvantages of hardware load balancing:
-
Expensive: the cost of purchasing and maintaining hardware load balancing is high.
-
Poor scalability: when the number of visits increases sharply, it cannot be dynamically expanded beyond the limit.
2.1.2 software load balancing
Software load balancing is widely used in both large and small companies.
Software load balancing realizes load balancing from the software level and can generally run on any standard physical device.
The mainstream products of software load balancing are: Nginx, HAProxy and LVS.
-
LVS can be used as a four layer load balancer. Its load balancing performance is better than Nginx.
-
HAProxy can be used as HTTP and TCP load balancer.
-
Nginx and HAProxy can be used as four or seven layer load balancers.
Advantages of software load balancing:
-
Good scalability: adapt to dynamic changes. You can dynamically expand beyond the initial capacity by adding software load balancing instances.
-
Low cost: software load balancing can run on any standard physical device, reducing the cost of purchase and operation and maintenance.
Disadvantages of software load balancing:
- Slightly poor performance: compared with hardware load balancing, the performance of software load balancing is slightly lower.
2.2 classification of network communication
From the perspective of communication, software load balancing can be divided into four layers and seven layers.
- Seven layer load balancing: the request can be forwarded to a specific host according to the HTTP request header and URL information of the visiting user.
-
DNS redirection
-
HTTP redirection
-
Reverse proxy
- Four layer load balancing: forwarding requests based on IP address and port.
-
Modify IP address
-
Modify MAC address
2.2.1 DNS load balancing
DNS load balancing is generally used in Internet companies, and complex business systems are not suitable for use. Large websites generally use DNS load balancing as the first level load balancing means, and then use other methods internally to do the second level load balancing. DNS LOAD BALANCING belongs to seven layer load balancing.
DNS, the domain name resolution service, is the OSI layer 7 network protocol. DNS is designed as a distributed application with tree structure. From top to bottom, it is: root domain name server, primary domain name server, secondary domain name server,..., local domain name server. Obviously, if all data is stored in the root domain name server, the load and overhead of DNS query will be very huge.
Therefore, compared with the DNS hierarchy, DNS query is a reverse recursive process. The DNS client requests the local DNS server, the upper DNS server, the upper DNS server,..., and the root DNS server (also known as the authoritative DNS server) in turn. Once hit, it returns immediately. In order to reduce the number of queries, each level of DNS server will set DNS query cache.
The working principle of DNS load balancing is to return the IP addresses of different servers according to the load based on DNS query cache.
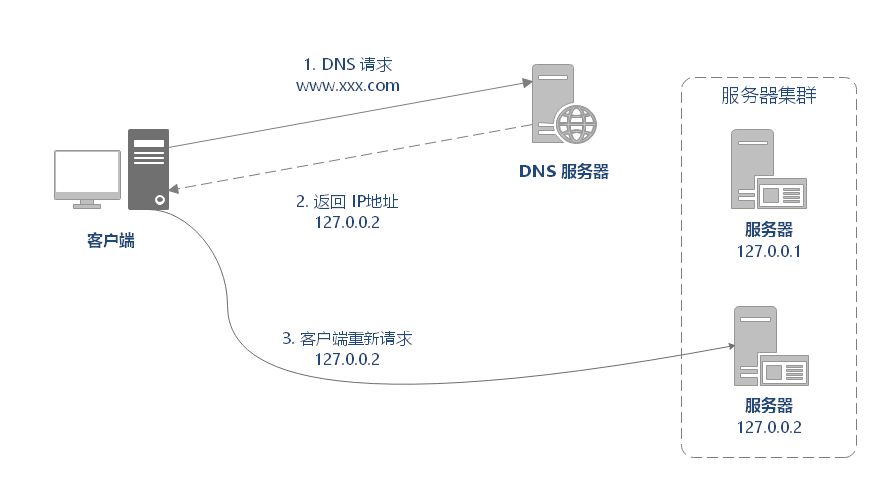
Advantages of DNS redirection:
Simple to use: the load balancing work is handed over to the DNS server, which saves the trouble of maintaining the load balancing server
Improve performance: it can support address based domain name resolution and resolve it to the server address closest to the user (similar to the principle of CDN), which can speed up access speed and improve performance;
Disadvantages of DNS redirection:
Poor availability: DNS resolution is a multi-level resolution. After adding / modifying DNS, the resolution time is long; In the process of parsing, users will fail to visit the website;
Low scalability: the control of DNS load balancing is in the domain name provider, so it is impossible to improve and expand it;
Poor maintainability: it cannot reflect the current running state of the server; Few supported algorithms; The difference between servers cannot be distinguished (the load cannot be judged according to the state of the system and service).
2.2.2 HTTP load balancing
HTTP load balancing is based on HTTP redirection. HTTP load balancing belongs to seven layer load balancing.
The principle of HTTP redirection is: calculate a real server address according to the user's HTTP request, write the server address into the HTTP redirection response, return it to the browser, and the browser can access it again.
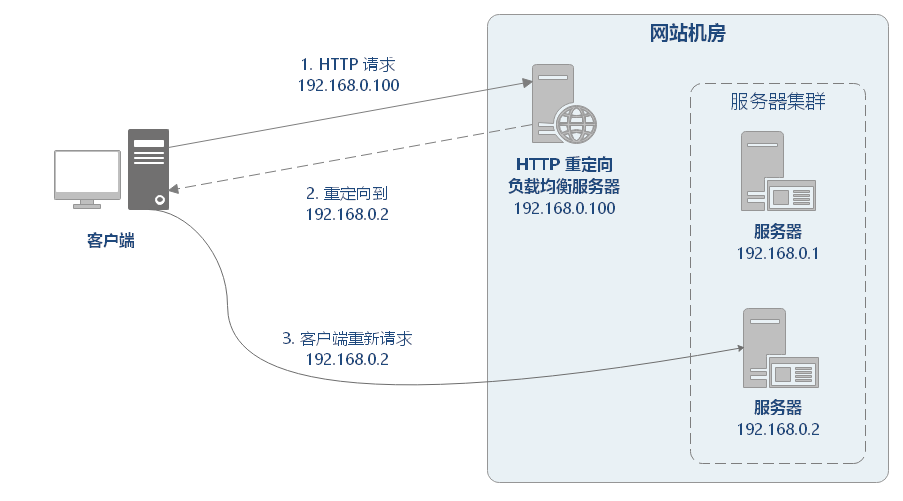
Advantages of HTTP redirection: simple scheme.
Disadvantages of HTTP redirection:
Poor performance: each access requires two requests from the server, which increases the access delay.
Reduce search ranking: using reset backward, search engines will be regarded as SEO cheating.
If the load balancer goes down, the site cannot be accessed.
Because of its obvious shortcomings, this load balancing strategy is less applied in practice.
2.2.3 reverse proxy load balancing
Reverse Proxy means that the proxy server accepts the network request, then forwards the request to the server in the intranet, and returns the result obtained from the server in the intranet to the client of the network request. Reverse Proxy load balancing belongs to seven layer load balancing.
Mainstream products of reverse proxy service: Nginx and Apache.
What is the difference between forward proxy and reverse proxy?
Forward proxy: it occurs on the client and is initiated by the user. Wall climbing software is a typical forward proxy. The client actively accesses the proxy server to enable the proxy server to obtain the required external network data, and then forward it back to the client.
Reverse proxy: it occurs on the server side, and the user does not know the existence of the proxy.
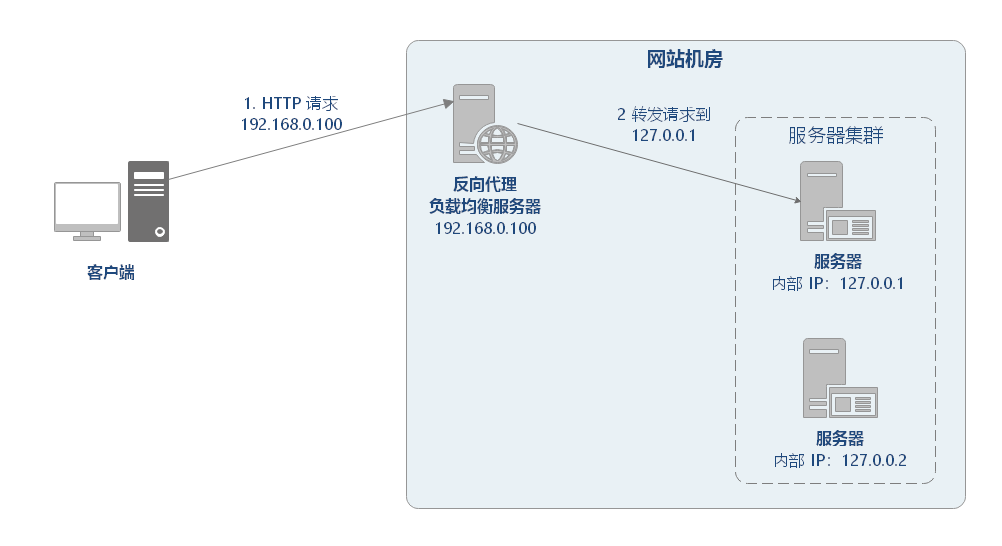
How does reverse proxy achieve load balancing? Take Nginx as an example, as follows:
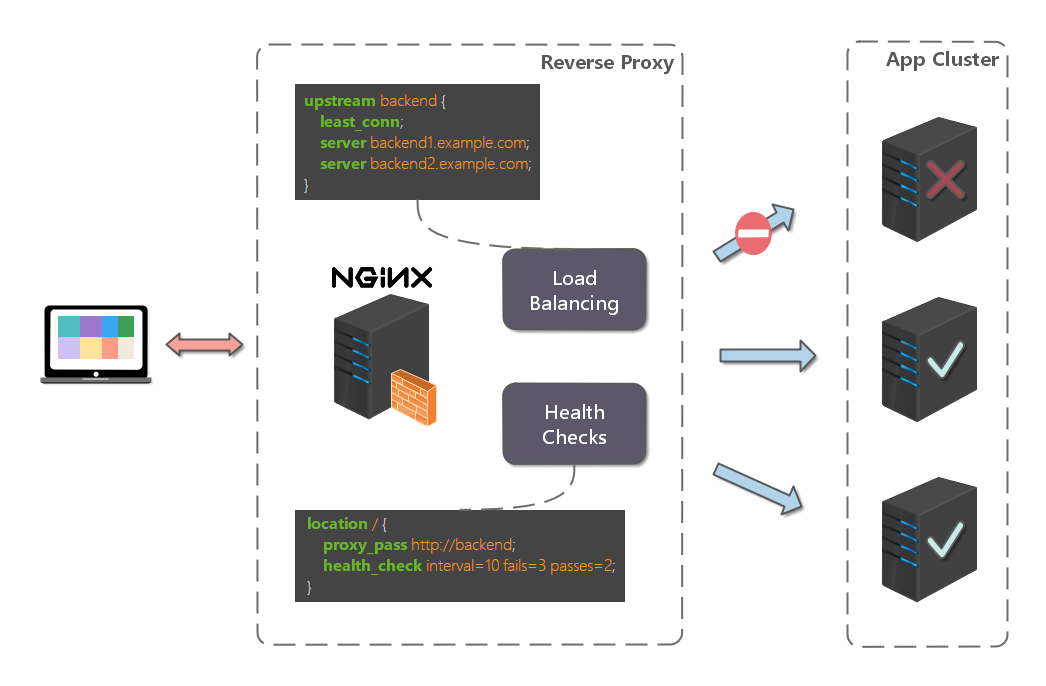
First, set the load balancing rules on the proxy server. Then, when receiving the client request, the reverse proxy server intercepts the specified domain name or IP request and distributes the request to the candidate server according to the load balancing algorithm. Secondly, if a candidate server goes down, the reverse proxy server will have fault-tolerant processing. For example, if the distribution request fails more than 3 times, it will distribute the request to other candidate servers.
Advantages of reverse proxy:
-
Multiple load balancing algorithms: support multiple load balancing algorithms to meet the needs of different scenarios.
-
Can monitor the server: Based on HTTP protocol, you can monitor the status of the forwarding server, such as system load, response time, availability, number of connections, traffic, etc., so as to adjust the load balancing strategy according to these data.
Disadvantages of reverse proxy:
- Additional forwarding overhead: the forwarding operation of the reverse proxy itself has performance overhead, which may include creating a connection, waiting for the connection response, analyzing the response results and so on.
- Increase system complexity: reverse agent is often used for horizontal expansion of distributed applications, but the reverse agent service has the following problems. In order to solve the following problems, it will add additional complexity and operation and maintenance cost to the whole system:
-
If the reverse proxy service goes down, it cannot access the site, so it needs to have a high availability scheme. The common schemes are: active and standby mode (one active and one standby), dual active mode (mutual active and standby).
-
The reverse proxy service itself also has a performance bottleneck. With the increasing number of requests to be forwarded, a scalable scheme is needed.
2.2.4 IP load balancing
IP load balancing is to perform load balancing by modifying the request destination address at the network layer.
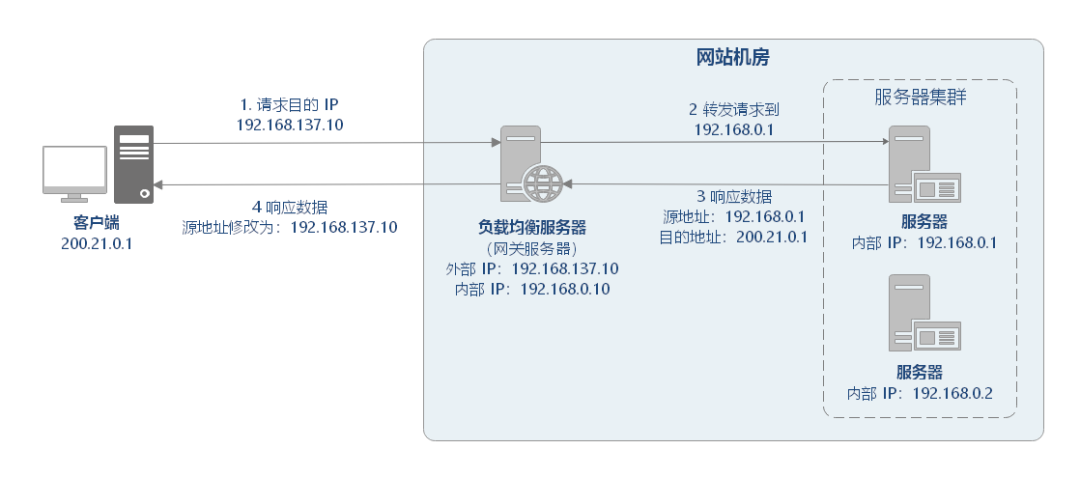
As shown in the figure above, the IP equalization process is roughly as follows:
The client requests 192.168.137.10, and the load balancing server receives the message.
The load balancing server selects a service node 192.168.0.1 according to the algorithm, and then changes the message request address to the IP of the node.
The real service node receives the request message and returns the response data to the load balancing server after processing.
The load balancing server changes the source address of the response data to the address of the load balancing server and returns it to the client.
IP load balancing completes data distribution in the kernel process, which has better slave processing performance than reverse proxy load balancing. However, since all requests and responses must pass through the load balancing server, the throughput of the cluster is limited by the bandwidth of the load balancing server.
2.2.5 data link layer load balancing
Data link layer load balancing refers to modifying mac address in data link layer of communication protocol for load balancing.
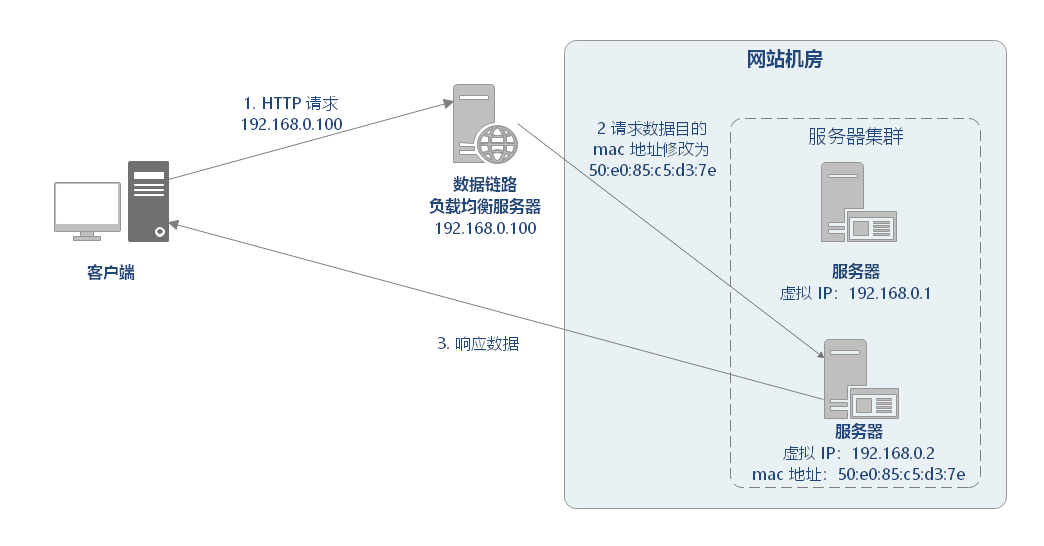
The best link layer load balancing open source product on Linux platform is LVS (Linux Virtual Server). LVS is a load balancing system based on netfilter framework in Linux kernel. netfilter is a kernel Linux firewall mechanism, which can set several checkpoints (hook functions) according to rules to perform relevant operations during the flow of data packets.
The working process of LVS is roughly as follows:
When users access www.sina.com.cn When, the user data passes through the layer by layer network, and finally enters the LVS server network card through the switch, and enters the kernel network layer.
After entering preouting, through route search, it is determined that the destination VIP is the local IP address, so the data packet enters the INPUT chain
IPVS works on the INPUT chain. It will judge whether the request is an IPVS service according to the accessed vip+port. If so, call the registered IPVS HOOK function to carry out IPVS related main processes, forcibly modify the relevant data of the data packet, and send the data packet to the POSTROUTING chain.
After receiving the data packet on POSTROUTING, the data packet is finally sent to the back-end server through routing according to the target IP address (back-end server).
There are three working modes in the open source LVS version, and the working principles of each mode are quite different. It is said that each mode has its own advantages and disadvantages and is suitable for different application scenarios. However, the ultimate essential function is to achieve balanced traffic scheduling and good scalability. It mainly includes three modes: DR mode, NAT mode and Tunnel mode.
3, Load balancing algorithm
The implementation of load balancer can be divided into two parts:
Select a server from the list of candidate servers according to the load balancing algorithm;
Send the request data to the server.
Load balancing algorithm is the core of load balancing service. There are many kinds of load balancing products, but the principles of various load balancing algorithms are common. There are many kinds of load balancing algorithms, which are applicable to different application scenarios. This paper only introduces the characteristics and principles of the most common load balancing algorithms: polling, random, minimum active number, source address hash and consistency hash.
Note: the implementation of load balancing algorithm is recommended Dubbo official load balancing algorithm description , the explanation of the source code is very detailed, which is very worthy of reference.
3.1 random
3.1.1 random algorithm
The Random algorithm randomly distributes requests to candidate servers.
The random algorithm is suitable for scenarios with the same server hardware. Those who have studied probability theory know that when the number of calls is small, the load may be uneven. The larger the number of calls, the more balanced the load is.
[example] implementation example of random algorithm
Load balancing interface
public interface LoadBalance<N extends Node> {
N select(List<N> nodes, String ip);
}
Load balancing abstract class
public abstract class BaseLoadBalance<N extends Node> implements LoadBalance<N> {
@Override
public N select(List<N> nodes, String ip) {
if (CollectionUtil.isEmpty(nodes)) {
return null;
}
// If there is only one node in the nodes list, you can return directly without load balancing
if (nodes.size() == 1) {
return nodes.get(0);
}
return doSelect(nodes, ip);
}
protected abstract N doSelect(List<N> nodes, String ip);
}
Server node class
public class Node implements Comparable<Node> {
protected String url;
protected Integer weight;
protected Integer active;
// ...
}
Random algorithm implementation
public class RandomLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = new Random();
@Override
protected N doSelect(List<N> nodes, String ip) {
// Select a node randomly in the list
int index = random.nextInt(nodes.size());
return nodes.get(index);
}
}
3.1.2 weighted random algorithm
The Weighted Random algorithm adjusts the weight according to the probability on the basis of the random algorithm to distribute the load.
[example] implementation example of weighted random algorithm
public class WeightRandomLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = ThreadLocalRandom.current();
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
AtomicInteger totalWeight = new AtomicInteger(0);
for (N node : nodes) {
Integer weight = node.getWeight();
totalWeight.getAndAdd(weight);
}
if (totalWeight.get() > 0) {
int offset = random.nextInt(totalWeight.get());
for (N node : nodes) {
// Let the random value offset subtract the weight value
offset -= node.getWeight();
if (offset < 0) {
// Return the corresponding Node
return node;
}
}
}
// Directly return one at random
return nodes.get(random.nextInt(length));
}
}
3.2 polling
3.2.1 polling algorithm
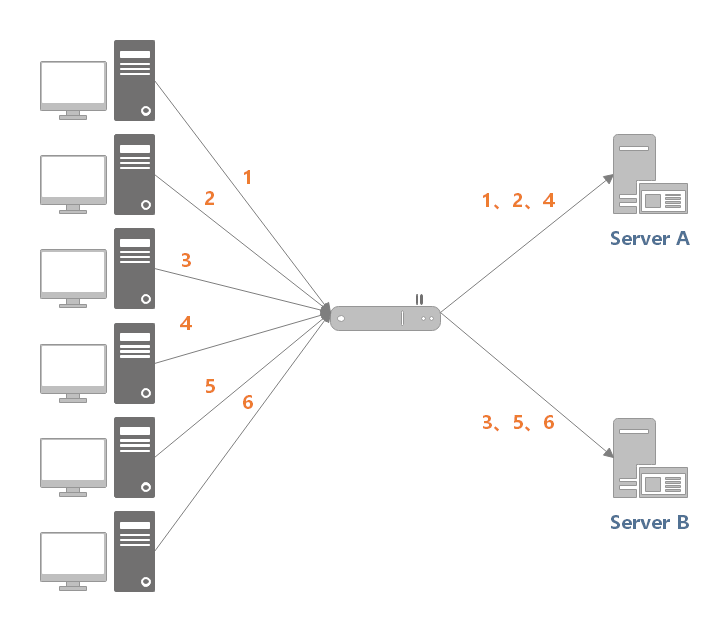
The strategy of Round Robin algorithm is to distribute requests to candidate servers in turn.
As shown in the figure below, the load balancer receives six requests from the client, and the requests of (1, 3, 5) will be sent to server 1, and the requests of (2, 4, 6) will be sent to server 2.
The algorithm is suitable for scenarios: the processing capacity of each server is similar, and the workload of each transaction is not different. If there is a big difference, the slow processing server may backlog requests and eventually cannot bear the excessive load.
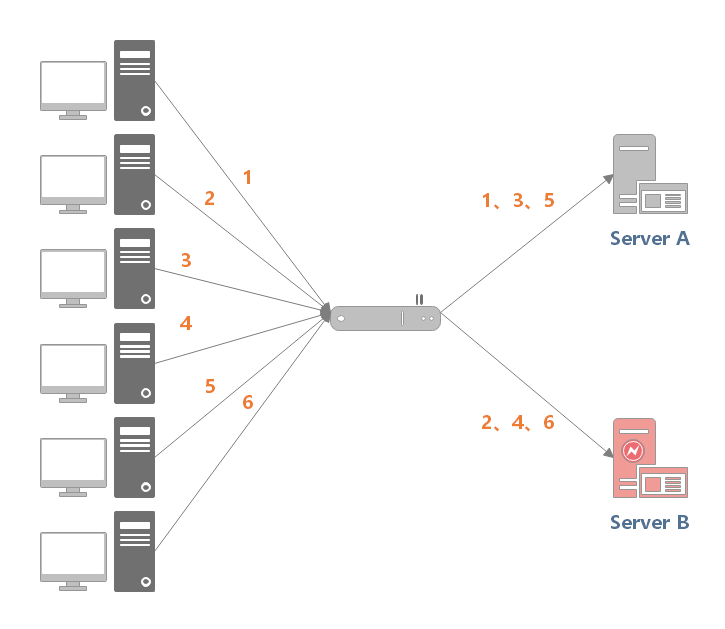
[example] example of polling algorithm
Implementation of polling load balancing algorithm
public class RoundRobinLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final AtomicInteger position = new AtomicInteger(0);
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
// If the position value is already equal to the number of nodes, reset to 0
position.compareAndSet(length, 0);
N node = nodes.get(position.get());
position.getAndIncrement();
return node;
}
}
3.2.2 weighted polling algorithm
The weighted round robin algorithm adds the weight attribute to adjust the number of requests from the forwarding server on the basis of the polling algorithm. Nodes with high performance and fast processing speed should set higher weights to give priority to distributing requests to nodes with higher weights when scoring.
As shown in the figure below, server A sets the weight to 5 and server B sets the weight to 1. When the load balancer receives 6 requests from the client, then (1, 2, 3, 4, 5) requests will be sent to server A and (6) requests will be sent to server B.
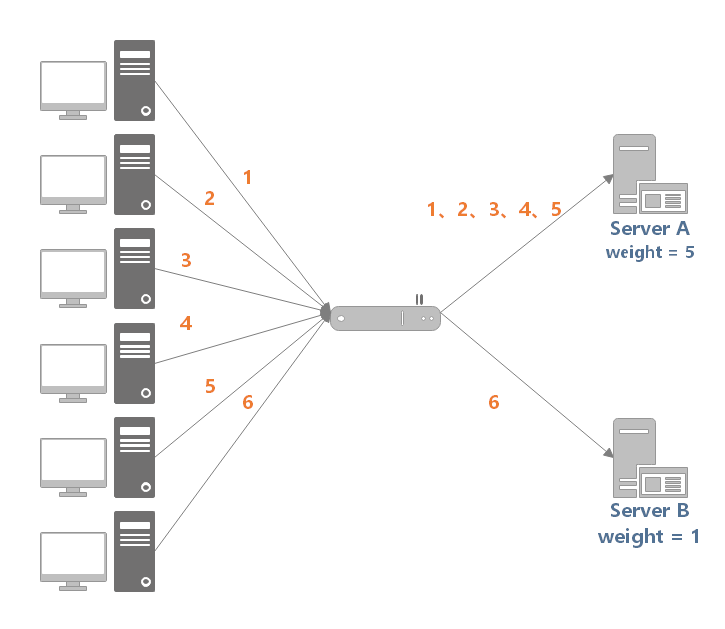
[example] implementation example of weighted polling algorithm
The following implementation is simplified based on Dubbo weighted polling algorithm.
public class WeightRoundRobinLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
/**
* 60 second
*/
private static final int RECYCLE_PERIOD = 60000;
/**
* Node hashcode Mapping to WeightedRoundRobin
*/
private ConcurrentMap<Integer, WeightedRoundRobin> weightMap = new ConcurrentHashMap<>();
/**
* Atomic update lock
*/
private AtomicBoolean updateLock = new AtomicBoolean();
@Override
protected N doSelect(List<N> nodes, String ip) {
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
// Get current time
long now = System.currentTimeMillis();
N selectedNode = null;
WeightedRoundRobin selectedWRR = null;
// The following cycle mainly does the following things:
// 1. Traverse the Node list to check whether the current Node has a corresponding WeightedRoundRobin. If not, create it
// 2. Check whether the Node weight has changed. If so, update the weight field of WeightedRoundRobin
// 3. Add its own weight to the current field, which is equivalent to current += weight
// 4. Set the lastUpdate field, that is, lastUpdate = now
// 5. Find the Node with the largest current and the WeightedRoundRobin corresponding to the Node,
// Temporarily stored for later use
// 6. Calculate the weight sum
for (N node : nodes) {
int hashCode = node.hashCode();
WeightedRoundRobin weightedRoundRobin = weightMap.get(hashCode);
int weight = node.getWeight();
if (weight < 0) {
weight = 0;
}
// Check whether the current Node has a corresponding WeightedRoundRobin. If not, create it
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
// Set Node weight
weightedRoundRobin.setWeight(weight);
// Store the mapping relationship between url unique identifier identifyString and weightedRoundRobin
weightMap.putIfAbsent(hashCode, weightedRoundRobin);
weightedRoundRobin = weightMap.get(hashCode);
}
// The Node weight is not equal to the weight saved in WeightedRoundRobin, indicating that the weight has changed. Update it at this time
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// Let current add its own weight, which is equivalent to current += weight
long current = weightedRoundRobin.increaseCurrent();
// Set lastUpdate to indicate that it has been updated recently
weightedRoundRobin.setLastUpdate(now);
// Find the largest current
if (current > maxCurrent) {
maxCurrent = current;
// Assign the Node with the maximum current weight to selectedNode
selectedNode = node;
// Assign the weightedRoundRobin corresponding to Node to selectedWRR for later use
selectedWRR = weightedRoundRobin;
}
// Calculate weight sum
totalWeight += weight;
}
// Check the weightMap and filter out the nodes that have not been updated for a long time.
// The node may hang up, and the node is not included in nodes, so the lastUpdate of the node cannot be updated for a long time.
// If the duration of non update exceeds the threshold, it will be removed, and the default threshold is 60 seconds.
if (!updateLock.get() && nodes.size() != weightMap.size()) {
if (updateLock.compareAndSet(false, true)) {
try {
// Traverse modification, that is, remove expired records
weightMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD);
} finally {
updateLock.set(false);
}
}
}
if (selectedNode != null) {
// Let current subtract the sum of weights, which is equivalent to current -= totalWeight
selectedWRR.decreaseCurrent(totalWeight);
// Returns the Node with the largest current
return selectedNode;
}
// should not happen here
return nodes.get(0);
}
protected static class WeightedRoundRobin {
// Service provider weight
private int weight;
// Current weight
private AtomicLong current = new AtomicLong(0);
// Last update time
private long lastUpdate;
public long increaseCurrent() {
// current = current + weight;
return current.addAndGet(weight);
}
public long decreaseCurrent(int total) {
// current = current - total;
return current.addAndGet(-1 * total);
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
// Initially, current = 0
current.set(0);
}
public AtomicLong getCurrent() {
return current;
}
public void setCurrent(AtomicLong current) {
this.current = current;
}
public long getLastUpdate() {
return lastUpdate;
}
public void setLastUpdate(long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
}
3.3 minimum active number
The Least Active algorithm distributes the request to the candidate server with the least number of connections / requests (the server that currently processes the least requests).
-
Features: dynamically allocate according to the current number of requested connections of the candidate server.
-
Scenario: applicable to scenarios that are sensitive to system load or have a large difference in the duration of requesting connection.
Because the connection duration of each request is different, if a simple round robin or random algorithm is adopted, the current connection number of some servers may be too large, while the connection of other servers may be too small, resulting in the load is not really balanced. Although both polling and algorithms can adjust the load by weighting the attributes, the weighting method is difficult to deal with dynamic changes.
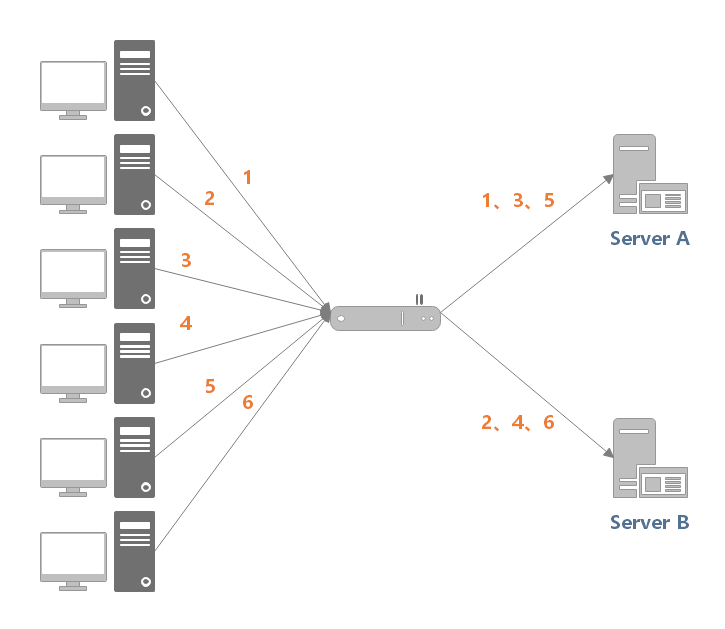
For example, in the following figure, (1, 3, 5) requests will be sent to server 1, but (1, 3) will be disconnected soon. At this time, only (5) requests to connect to server 1; (2, 4, 6) the request is sent to server 2, and only (2) is disconnected. When the system continues to run, server 2 will bear excessive load.
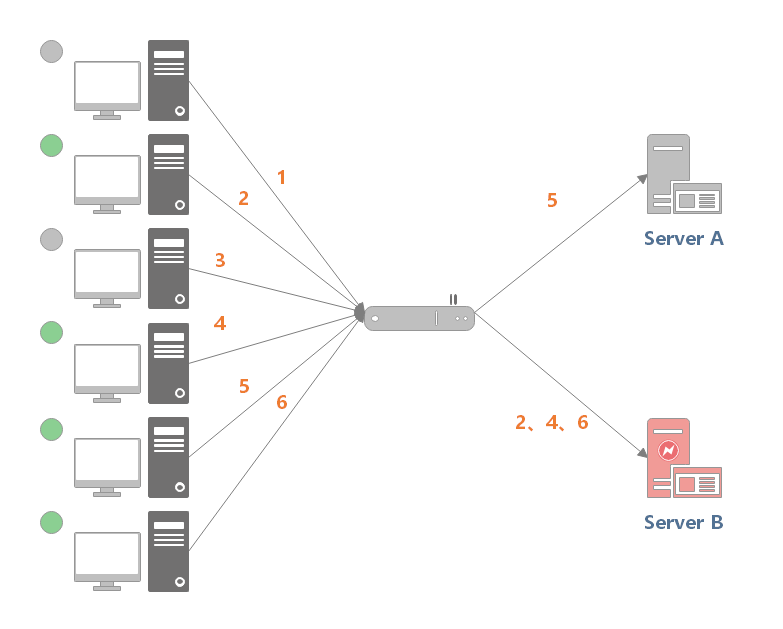
The minimum active number algorithm will record the number of connections being processed by each candidate node at the current time, and then select the node with the minimum number of connections. This strategy can dynamically and real-time reflect the current situation of the server, reasonably distribute the responsibility evenly, and is suitable for scenarios that are sensitive to the current system load.
For example, in the following figure, if the current number of connections of server 1 is the smallest, the new request 6 will be sent to server 1.
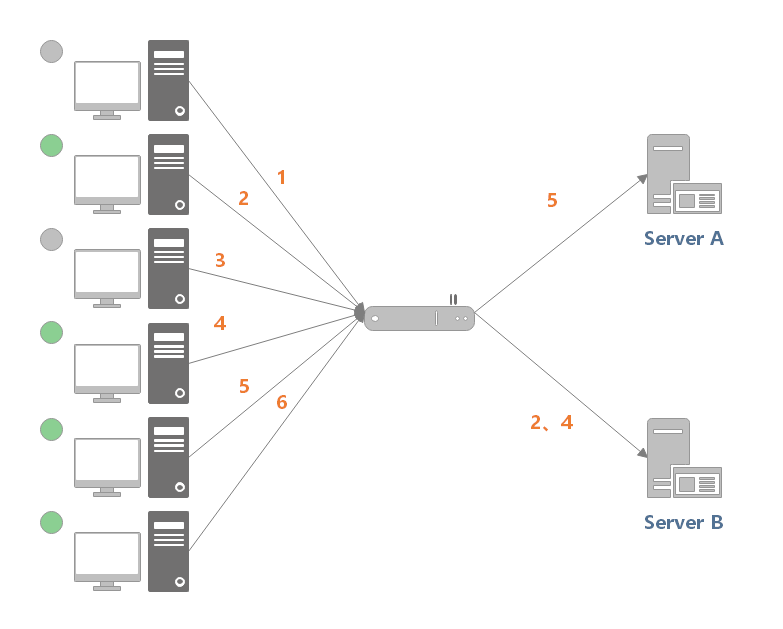
Weighted Least Connection assigns a weight to each server according to the performance of the server on the basis of the minimum active number, and then calculates the number of connections that each server can handle according to the weight.
Implementation points of minimum active number algorithm: the smaller the number of active calls, the higher the processing capacity of the service node, and more requests can be processed per unit time. Requests should be distributed to the service first. In the specific implementation, each service node corresponds to an active number active. Initially, the active number of all service providers is 0. Each time a request is received, the active number is increased by 1, and after the request is completed, the active number is reduced by 1. After the service runs for a period of time, the service provider with good performance processes the request faster, so the active number decreases faster. At this time, such service provider can give priority to obtaining new service requests. This is the basic idea of the minimum active number load balancing algorithm.
[example] implementation of minimum active number algorithm
The following implementation is based on the Dubbo minimum active number load balancing algorithm with some changes.
public class LeastActiveLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = new Random();
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
// Minimum active number
int leastActive = -1;
// The number of service providers (hereinafter referred to as Node) with the same "minimum number of activities"
int leastCount = 0;
// leastIndexs is used to record the subscript information of nodes with the same "minimum active number" in the nodes list
int[] leastIndexs = new int[length];
int totalWeight = 0;
// The Node weight value of the first minimum active number is used to compare with the weight of other nodes with the same minimum active number,
// To check whether the weights of all nodes with the same minimum number of active nodes are equal
int firstWeight = 0;
boolean sameWeight = true;
// Traverse the nodes list
for (int i = 0; i < length; i++) {
N node = nodes.get(i);
// Find a smaller active number and start over
if (leastActive == -1 || node.getActive() < leastActive) {
// Update the minimum active number leastActive with the current active number
leastActive = node.getActive();
// Update leastCount to 1
leastCount = 1;
// Record the current subscript value into leastIndexs
leastIndexs[0] = i;
totalWeight = node.getWeight();
firstWeight = node.getWeight();
sameWeight = true;
// The number of active nodes in the current Node Getactive() is the same as the minimum active number leastActive
} else if (node.getActive() == leastActive) {
// Record the subscript of the current Node in the nodes collection in leastindex
leastIndexs[leastCount++] = i;
// Cumulative weight
totalWeight += node.getWeight();
// Check whether the weight of the current Node is equal to the firstWeight,
// If not, set sameWeight to false
if (sameWeight && i > 0
&& node.getWeight() != firstWeight) {
sameWeight = false;
}
}
}
// When only one Node is active, it can directly return the minimum number of nodes
if (leastCount == 1) {
return nodes.get(leastIndexs[0]);
}
// Multiple nodes have the same minimum active number, but their weights are different
if (!sameWeight && totalWeight > 0) {
// Randomly generate a number between [0, totalweight]
int offsetWeight = random.nextInt(totalWeight);
// Loop the random number minus the weight value of the Node with the minimum active number,
// When offset is less than or equal to 0, the corresponding Node is returned
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexs[i];
// Get the weight value and let the random number subtract the weight value
offsetWeight -= nodes.get(leastIndex).getWeight();
if (offsetWeight <= 0) {
return nodes.get(leastIndex);
}
}
}
// If the weight is the same or the weight is 0, a Node is returned randomly
return nodes.get(leastIndexs[random.nextInt(leastCount)]);
}
}
3.4 source address hash
The source address hash (IP Hash) algorithm obtains a value through hash calculation according to the source IP of the request. The value is used for modular operation in the list of candidate servers, and the result is the selected server.
It can ensure that the requests of clients with the same IP will be forwarded to the same server to realize session Sticky Session.
Features: ensure that specific users always request to the same server. If the server goes down, the session will be lost.
[example] implementation example of source address hash algorithm
public class IpHashLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
@Override
protected N doSelect(List<N> nodes, String ip) {
if (StrUtil.isBlank(ip)) {
ip = "127.0.0.1";
}
int length = nodes.size();
int index = hash(ip) % length;
return nodes.get(index);
}
public int hash(String text) {
return HashUtil.fnvHash(text);
}
}
3.5 consistency hash
The goal of Consistent Hash algorithm is that the same request falls on the same server as much as possible.
Consistent hashing can solve the problem of stability. All storage nodes can be arranged on the Hash ring connected from head to tail. Each key will find the adjacent storage node clockwise after calculating the Hash. When a node joins or exits, it only affects the subsequent nodes clockwise adjacent to the node on the Hash ring.
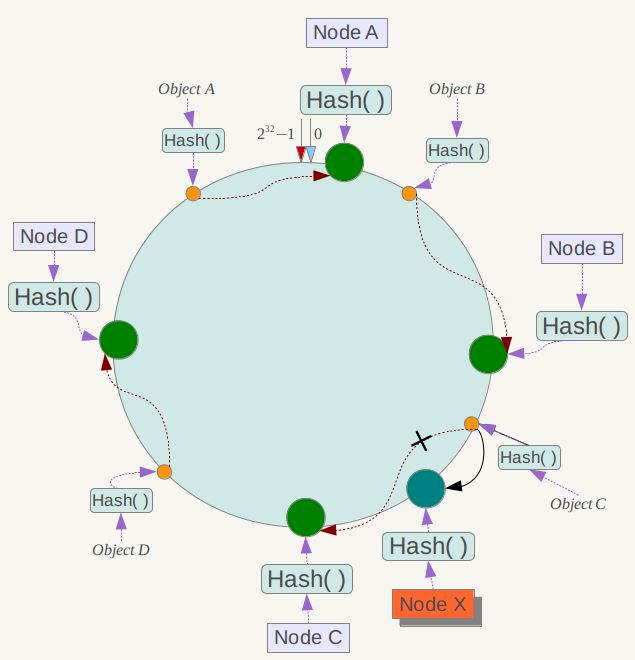
1) The same request refers to: generally, when using consistent hash, you need to specify a key for hash calculation, which may be:
User ID
Requestor IP
Request service name, string composed of parameter list
2) As far as possible, it means that the server may go online and offline, and the changes of a few servers should not affect most requests.
When a candidate server goes down, the requests originally sent to the server will be shared among other candidate servers based on the virtual node without causing drastic changes.
Advantages: adding and deleting nodes only affect the clockwise adjacent nodes in the hash ring, and have no impact on other nodes.
Disadvantages: adding or subtracting nodes will cause some data in the hash ring to fail to hit. When a small number of nodes are used, the changes of nodes will affect the data mapping in the hash ring in a wide range, which is not suitable for the distributed scheme of a small number of data nodes. Common consistent hash partitions need to double or subtract half of the nodes when increasing or decreasing nodes to ensure the balance of data and load.
Note: because of these shortcomings of consistent hash partition, some distributed systems use virtual slots to improve consistent hash, such as Dynamo system.
[example] example of consistent hash algorithm
public class ConsistentHashLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<>();
@SuppressWarnings("unchecked")
@Override
protected N doSelect(List<N> nodes, String ip) {
// The number of slices is set as 4 times of the number of nodes
Integer replicaNum = nodes.size() * 4;
// Get the original hashcode of nodes
int identityHashCode = System.identityHashCode(nodes);
// If nodes is a new List object, it means that the number of nodes has changed
// The selector identityHashCode != Identityhashcode condition holds
ConsistentHashSelector<N> selector = (ConsistentHashSelector<N>) selectors.get(ip);
if (selector == null || selector.identityHashCode != identityHashCode) {
// Create a new ConsistentHashSelector
selectors.put(ip, new ConsistentHashSelector<>(nodes, identityHashCode, replicaNum));
selector = (ConsistentHashSelector<N>) selectors.get(ip);
}
// Call the select method of ConsistentHashSelector to select the Node
return selector.select(ip);
}
/**
* Consistent hash selector
*/
private static final class ConsistentHashSelector<N extends Node> {
/**
* Storage virtual node
*/
private final TreeMap<Long, N> virtualNodes;
private final int identityHashCode;
/**
* constructor
*
* @param nodes Node list
* @param identityHashCode hashcode
* @param replicaNum Number of slices
*/
ConsistentHashSelector(List<N> nodes, int identityHashCode, Integer replicaNum) {
this.virtualNodes = new TreeMap<>();
this.identityHashCode = identityHashCode;
// Get the number of virtual nodes. The default is 100
if (replicaNum == null) {
replicaNum = 100;
}
for (N node : nodes) {
for (int i = 0; i < replicaNum / 4; i++) {
// Perform md5 operation on the url to obtain a 16 byte array
byte[] digest = md5(node.getUrl());
// Four hash operations are performed on some bytes of digest to obtain four different long positive integers
for (int j = 0; j < 4; j++) {
// When h = 0, take 4 bytes with subscript 0 ~ 3 in digest for bit operation
// When h = 1, take 4 bytes with subscripts 4 ~ 7 in digest for bit operation
// The process is the same as above when h = 2 and H = 3
long m = hash(digest, j);
// Store the mapping relationship from hash to node in virtualNodes,
// virtualNodes needs to provide efficient query operations, so TreeMap is selected as the storage structure
virtualNodes.put(m, node);
}
}
}
}
public N select(String key) {
// md5 operation on parameter key
byte[] digest = md5(key);
// Take the first four bytes of the digest array for hash operation, and then pass the hash value to the selectForKey method,
// Find the right Node
return selectForKey(hash(digest, 0));
}
private N selectForKey(long hash) {
// Find the first node greater than or equal to the current hash
Map.Entry<Long, N> entry = virtualNodes.ceilingEntry(hash);
// If the hash is greater than the maximum position of the Node on the hash ring, then entry = null,
// The header node of TreeMap needs to be assigned to entry
if (entry == null) {
entry = virtualNodes.firstEntry();
}
// Return to Node
return entry.getValue();
}
}
/**
* Calculate hash value
*/
public static long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
/**
* Calculate MD5 value
*/
public static byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes = value.getBytes(StandardCharsets.UTF_8);
md5.update(bytes);
return md5.digest();
}
}
The above example makes some simplification based on Dubbo's consistent hash load balancing algorithm.
4, References
2. Technical architecture of large websites: core principles and case analysis
Author: vivo Internet team - Zhang Peng