phenomenon
There are two clusters A and B on the line, which are configured with two-way synchronization and single activity, i.e. only one cluster will be visited at a certain time by the business layer.
A lot of exceptions have been reported in the regionserver log of Cluster A recently, but the monitoring page is working and functionality is not affected.
HBase version 2.0.0;
2019-09-04 02:44:58,115 WARN org.apache.zookeeper.ClientCnxn: Session 0x36abf38cec5531d for server host-15/ip-15:2181, unexpected error, closing socket connection and attempting reconnect java.io.IOException: Broken pipe at sun.nio.ch.FileDispatcherImpl.write0(Native Method) at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47) at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93) at sun.nio.ch.IOUtil.write(IOUtil.java:65) at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471) at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:117) at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:355) at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1073)
Location
1. Looking at the log before and after, you can see that the exception is related to replication
2019-09-04 02:44:56,960 INFO org.apache.hadoop.hbase.replication.ReplicationQueuesZKImpl: Atomically moving host-17,16020,1561539485645/1's WALs to my queue 2019-09-04 02:44:58,115 WARN org.apache.zookeeper.ClientCnxn: Session 0x36abf38cec5531d for server host-15/ip-15:2181, unexpected error, closing socket connection and attempting reconnect java.io.IOException: Broken pipe at sun.nio.ch.FileDispatcherImpl.write0(Native Method) at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47) at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93) at sun.nio.ch.IOUtil.write(IOUtil.java:65) at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471) at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:117) at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:355) at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1073) ... //Exception log for intermediate multiple Broken pipe s ... 2019-09-04 02:45:45,544 ERROR org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper: ZooKeeper multi failed after 4 attempts 2019-09-04 02:45:45,544 WARN org.apache.hadoop.hbase.replication.ReplicationQueuesZKImpl: Got exception in copyQueuesFromRSUsingMulti: org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss at org.apache.zookeeper.KeeperException.create(KeeperException.java:102) at org.apache.zookeeper.ZooKeeper.multiInternal(ZooKeeper.java:944) at org.apache.zookeeper.ZooKeeper.multi(ZooKeeper.java:924) at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.multi(RecoverableZooKeeper.java:663) at org.apache.hadoop.hbase.zookeeper.ZKUtil.multiOrSequential(ZKUtil.java:1670) at org.apache.hadoop.hbase.replication.ReplicationQueuesZKImpl.moveQueueUsingMulti(ReplicationQueuesZKImpl.java:318) at org.apache.hadoop.hbase.replication.ReplicationQueuesZKImpl.claimQueue(ReplicationQueuesZKImpl.java:210) at org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceManager$NodeFailoverWorker.run(ReplicationSourceManager.java:686) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
2. Why did this happen?
The replication processing mechanism of HBase is that each regionServer is responsible for the wal file generated by itself. If an RS exits, other RS will claim the wal file synchronization task that has not been completed by the rs. The above log is the log generated by the claim action.
3. Why did rs exit?
Viewing the command run log in cdh, the most recent restart was August 16, when the cluster parameters were modified.
The earliest time to see an exception in the log was August 16.
4. Why claim failed
View the zk log with a large number of warnings
2019-09-04 02:45:44,270 WARN org.apache.zookeeper.server.NIOServerCnxn: Exception causing close of session 0x36abf38cec5531a due to java.io.IOException: Len error 4448969
This error is a bug in zk that triggers when a single request involves too much data. Fixed versions are 3.4.7, 3.5.2, 3.6.0, our online version is 3.4.5, related issue s:
https://issues.apache.org/jira/browse/ZOOKEEPER-706
However, this is only a direct cause, even if the bug is fixed, it will only temporarily cover up the problem, the root cause still needs to be further analyzed.
5. Why claim involves a lot of data
When rs claims the task, an OP object is generated for each wal file, encapsulated in a List, and finally called multi execute
private Pair<String, SortedSet<String>> moveQueueUsingMulti(String znode, String peerId) { try { // hbase/replication/rs/deadrs String deadRSZnodePath = ZNodePaths.joinZNode(this.queuesZNode, znode); List<ZKUtilOp> listOfOps = new ArrayList<>(); ReplicationQueueInfo replicationQueueInfo = new ReplicationQueueInfo(peerId); String newPeerId = peerId + "-" + znode; String newPeerZnode = ZNodePaths.joinZNode(this.myQueuesZnode, newPeerId); // check the logs queue for the old peer cluster String oldClusterZnode = ZNodePaths.joinZNode(deadRSZnodePath, peerId); List<String> wals = ZKUtil.listChildrenNoWatch(this.zookeeper, oldClusterZnode); if (!peerExists(replicationQueueInfo.getPeerId())) { LOG.warn("Peer " + replicationQueueInfo.getPeerId() + " didn't exist, will move its queue to avoid the failure of multi op"); for (String wal : wals) { String oldWalZnode = ZNodePaths.joinZNode(oldClusterZnode, wal); listOfOps.add(ZKUtilOp.deleteNodeFailSilent(oldWalZnode)); } listOfOps.add(ZKUtilOp.deleteNodeFailSilent(oldClusterZnode)); ZKUtil.multiOrSequential(this.zookeeper, listOfOps, false); return null; } SortedSet<String> logQueue = new TreeSet<>(); if (wals == null || wals.isEmpty()) { listOfOps.add(ZKUtilOp.deleteNodeFailSilent(oldClusterZnode)); } else { // create the new cluster znode ZKUtilOp op = ZKUtilOp.createAndFailSilent(newPeerZnode, HConstants.EMPTY_BYTE_ARRAY); listOfOps.add(op); // get the offset of the logs and set it to new znodes for (String wal : wals) { String oldWalZnode = ZNodePaths.joinZNode(oldClusterZnode, wal); byte[] logOffset = ZKUtil.getData(this.zookeeper, oldWalZnode); LOG.debug("Creating " + wal + " with data " + Bytes.toString(logOffset)); String newLogZnode = ZNodePaths.joinZNode(newPeerZnode, wal); listOfOps.add(ZKUtilOp.createAndFailSilent(newLogZnode, logOffset)); listOfOps.add(ZKUtilOp.deleteNodeFailSilent(oldWalZnode)); logQueue.add(wal); } // add delete op for peer listOfOps.add(ZKUtilOp.deleteNodeFailSilent(oldClusterZnode)); if (LOG.isTraceEnabled()) LOG.trace(" The multi list size is: " + listOfOps.size()); } ZKUtil.multiOrSequential(this.zookeeper, listOfOps, false); LOG.info("Atomically moved " + znode + "/" + peerId + "'s WALs to my queue"); return new Pair<>(newPeerId, logQueue); } catch (KeeperException e) { // Multi call failed; it looks like some other regionserver took away the logs. LOG.warn("Got exception in copyQueuesFromRSUsingMulti: ", e); } catch (InterruptedException e) { LOG.warn("Got exception in copyQueuesFromRSUsingMulti: ", e); Thread.currentThread().interrupt(); } return null; }
This means that exiting RS leaves behind a large number of wal synchronization tasks, and viewing the list of tasks for the RS on zk is/hbase/replication/rs/#rs instance name#/#peerId#;
The result prints out a large number of sub-nodes, and does not end in 10 seconds.
The specific number is not good statistics, but you can see from the cdh that the zk of the cluster has more than 300,000 znodes. For reference, the zk of the Majuqiao cluster only has 12,000 znodes.
6. Why are there so many znode s
Look at the source code of the replication module and comb the core processes as follows: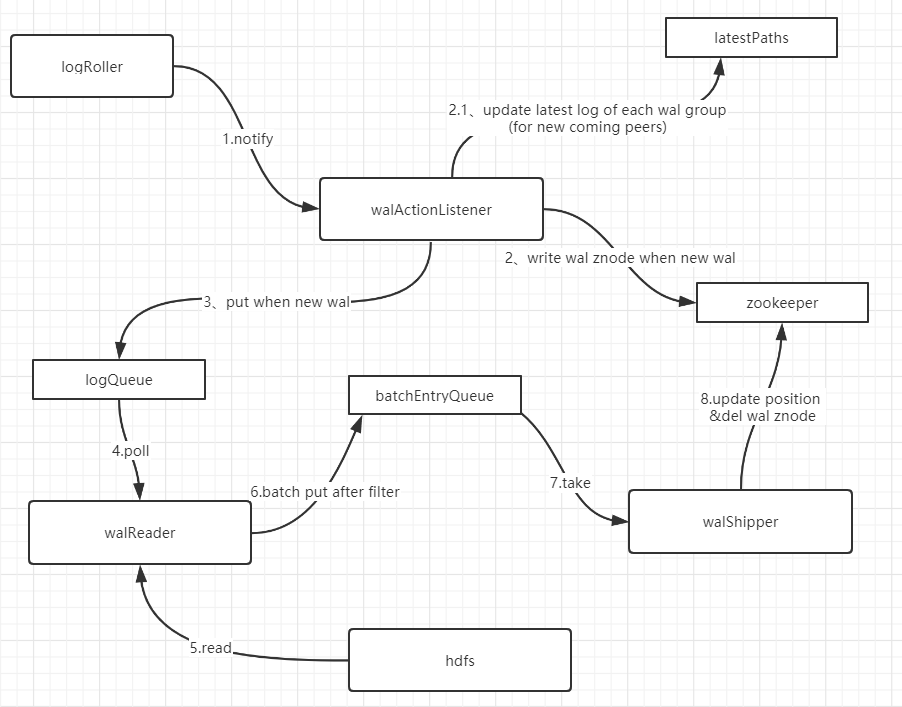
The implementation classes of walReader and walShipper are ReplicationSourceWALReader and ReplicationSourceShipper, respectively, with one thread each starting to communicate through a queue as a producer and consumer.
Deleting wal znodes is the responsibility of shipper. The actual logic is in the shipEdits method, which executes after the data is sent to ensure that the data is not lost. When deleting wal znodes that are older than the wal, they are deleted together.
Since there is a large backlog of znode s, guess that the shipEdits method should not be called for a long time to view stack information for these two threads:
"main-EventThread.replicationSource,2.replicationSource.host-17%2C16020%2C1567586932902.host-17%2C16020%2C1567586932902.regiongroup-0,2.replicationSource.wal-reader.host-17%2C16020%2C1567586932902.host-17%2C16020%2C1567586932902.regiongroup-0,2" #157238 daemon prio=5 os_prio=0 tid=0x00007f7634be8800 nid=0x377ef waiting on condition [0x00007f6114c0e000]"main-EventThread.replicationSource,2.replicationSource.host-17%2C16020%2C1567586932902.host-17%2C16020%2C1567586932902.regiongroup-0,2.replicationSource.wal-reader.host-17%2C16020%2C1567586932902.host-17%2C16020%2C1567586932902.regiongroup-0,2" #157238 daemon prio=5 os_prio=0 tid=0x00007f7634be8800 nid=0x377ef waiting on condition [0x00007f6114c0e000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader.handleEmptyWALEntryBatch(ReplicationSourceWALReader.java:192) at org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader.run(ReplicationSourceWALReader.java:142)
"main-EventThread.replicationSource,2.replicationSource.host-17%2C16020%2C1567586932902.host-17%2C16020%2C1567586932902.regiongroup-0,2" #157237 daemon prio=5 os_prio=0 tid=0x00007f76350b0000 nid=0x377ee waiting on condition [0x00007f6108173000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00007f6f99bb6718> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442) at org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader.take(ReplicationSourceWALReader.java:248) at org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceShipper.run(ReplicationSourceShipper.java:108)
From the stack information, you can see that shipper is indeed blocked;
Look at the walReader code and write the following parts of the queue:
WALEntryBatch batch = readWALEntries(entryStream); if (batch != null && batch.getNbEntries() > 0) { if (LOG.isTraceEnabled()) { LOG.trace(String.format("Read %s WAL entries eligible for replication", batch.getNbEntries())); } entryBatchQueue.put(batch); sleepMultiplier = 1; } else { // got no entries and didn't advance position in WAL handleEmptyWALEntryBatch(batch, entryStream.getCurrentPath()); }
The guess is that it has been going into the else logic, and the handleEmptyWALEntryBatch method code is as follows:
protected void handleEmptyWALEntryBatch(WALEntryBatch batch, Path currentPath) throws InterruptedException { LOG.trace("Didn't read any new entries from WAL"); Thread.sleep(sleepForRetries); }
Open the trace level log for this class and you can see that the following logs are being printed continuously:
2019-09-10 17:09:34,093 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL 2019-09-10 17:09:35,096 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL 2019-09-10 17:09:36,099 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL 2019-09-10 17:09:37,102 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL 2019-09-10 17:09:38,105 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL 2019-09-10 17:09:39,108 TRACE org.apache.hadoop.hbase.replication.regionserver.ReplicationSourceWALReader: Didn't read any new entries from WAL
At the same time, there is no log like "WAL entries eligible for replication";
At this point, you can confirm that it is the result of the empty batch object being returned by walReader while reading;
The wal contains data but returns empty because it has been filtered out and the code for the readWALEntries method is as follows:
private WALEntryBatch readWALEntries(WALEntryStream entryStream) throws IOException { WALEntryBatch batch = null; while (entryStream.hasNext()) { if (batch == null) { batch = new WALEntryBatch(replicationBatchCountCapacity, entryStream.getCurrentPath()); } Entry entry = entryStream.next(); entry = filterEntry(entry); if (entry != null) { WALEdit edit = entry.getEdit(); if (edit != null && !edit.isEmpty()) { long entrySize = getEntrySize(entry); batch.addEntry(entry); updateBatchStats(batch, entry, entryStream.getPosition(), entrySize); boolean totalBufferTooLarge = acquireBufferQuota(entrySize); // Stop if too many entries or too big if (totalBufferTooLarge || batch.getHeapSize() >= replicationBatchSizeCapacity || batch.getNbEntries() >= replicationBatchCountCapacity) { break; } } } } return batch; }
What works here is ClusterMarkingEntryFilter, HBase writes the cluster Id of the source cluster in the synchronized walEntry to avoid the replication loop in master-master mode. If the cluster Id in the currently processed entry is the same as that of the target cluster, it is synchronized from the target cluster and does not need to be synchronized back again, as shown below.
public Entry filter(Entry entry) { // don't replicate if the log entries have already been consumed by the cluster if (replicationEndpoint.canReplicateToSameCluster() || !entry.getKey().getClusterIds().contains(peerClusterId)) { WALEdit edit = entry.getEdit(); WALKeyImpl logKey = (WALKeyImpl)entry.getKey(); if (edit != null && !edit.isEmpty()) { // Mark that the current cluster has the change logKey.addClusterId(clusterId); // We need to set the CC to null else it will be compressed when sent to the sink entry.setCompressionContext(null); return entry; } } return null; }
At this point, the reason is basically clear. The two HBase clusters on the line are configured for two-way synchronization in master-master mode, but only one cluster as active writes data, whereas the cluster as backup accepts synchronized data, wal occurs, but the deletion of shipper cannot be triggered without a write operation.
Solve
Update its lastWalPosition when the batch read is empty and write to the queue with it to trigger shipper's cleanup action;
This bug exists in the 2.0 branch, which has been modified since 2.1 to implement serial replication and no longer exists.
For branch 2.0, an issue has been raised ( https://issues.apache.org/jira/browse/HBASE-23008) To the community, but the branch was not merged because it stopped maintenance when pr was submitted;