This article follows Log Addition Process for Source Analysis RocketMQ DLedger Continue Leader's process of handling client append requests, one of the most critical aspects: log replication.
DLedger multi-copy log forwarding is implemented by DLedger Entry Pusher, which will be described in detail next.
Warm Tip: Due to the length of this article, in order to better understand its realization, you can read through this article with the following questions:
1. raft protocol has a very important concept: log serial number has been submitted, how to implement it.
2. The client sends a log to the DLedger cluster, which must be approved by most nodes in the cluster to be considered successful.
3. How to implement the two actions of adding and submitting in raft protocol.
Log replication (log forwarding) is implemented by DLedgerEntry Pusher. The specific class diagram is as follows: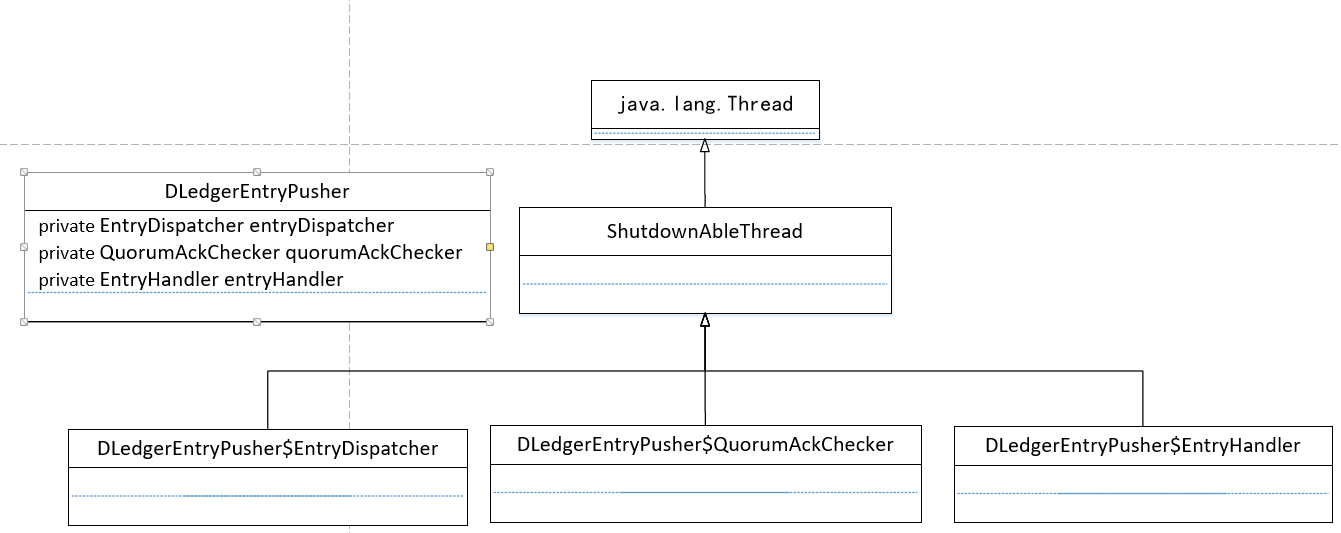
It mainly consists of the following four categories:
- DLedgerEntryPusher
DLedger log forwarding and processing core class, which will start the following three objects, which correspond to a thread. - EntryHandler
The log receives processing threads that are activated when the node is a slave node. - QuorumAckChecker
The log appends the ACK voting processing thread, which is activated when the current node is the primary node. - EntryDispatcher
The log forwarding thread is appended when the current node is the primary node.
Next, we will introduce the above four classes in detail, so as to reveal the core implementation principle of log replication.
1,DLedgerEntryPusher
1.1 Core Class Diagram

The core implementation class of DLedger multi-copy log push will create three core threads: Entry Dispatcher, Quorum Ack Checker and Entry Handler. Its core attributes are as follows:
- DLedgerConfig dLedgerConfig
Multi-copy related configuration. - DLedgerStore dLedgerStore
Store implementation classes. - MemberState memberState
Node state machine. - DLedgerRpcService dLedgerRpcService
RPC service implementation class is used to communicate with other nodes in the cluster. - Map> peerWaterMarksByTerm
Each node is marked by the current water level based on the voting rounds. The key value is the voting rounds, the Concurrent Map node ID /, and the log number /> corresponding to the Long / node. - Map>> pendingAppendResponsesByTerm
Used to store the response results of additional requests (Future mode). - EntryHandler entryHandler
A thread opened on a slave node to receive push requests (append, commit, append) from the primary node. - QuorumAckChecker quorumAckChecker
Additional request voter on primary node. - Map dispatcherMap
Master node log request forwarder, replicate message to slave node, etc.
Next, we introduce the implementation of its core method.
1.2 Construction Method
public DLedgerEntryPusher(DLedgerConfig dLedgerConfig, MemberState memberState, DLedgerStore dLedgerStore, DLedgerRpcService dLedgerRpcService) { this.dLedgerConfig = dLedgerConfig; this.memberState = memberState; this.dLedgerStore = dLedgerStore; this.dLedgerRpcService = dLedgerRpcService; for (String peer : memberState.getPeerMap().keySet()) { if (!peer.equals(memberState.getSelfId())) { dispatcherMap.put(peer, new EntryDispatcher(peer, logger)); } } }
The emphasis of the construction method is to build the corresponding Entry Dispatcher objects according to the nodes in the cluster.
1.3 startup
DLedgerEntryPusher#startup
public void startup() { entryHandler.start(); quorumAckChecker.start(); for (EntryDispatcher dispatcher : dispatcherMap.values()) { dispatcher.start(); } }
Start the Entry Handler, Quorum Ack Checker, and Entry Dispatcher threads in turn.
Note: Other core methods of DLedger Entry Pusher will be introduced in detail in the process of analyzing the principle of log replication.
Next, the implementation principle of RocketMQ DLedger (multi-copy) will be explained from Entry Dispatcher, Quorum Ack Checker and Entry Handler.
2. Entry Dispatcher
2.1 Core Class Diagram
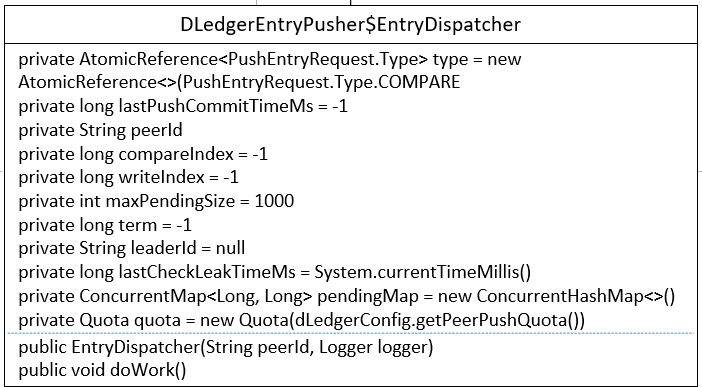
Its core attributes are as follows.
- AtomicReference type = new AtomicReference<>(PushEntryRequest.Type.COMPARE)
Optional values for sending commands to slave nodes: PushEntryRequest.Type.COMPARE, TRUNCATE, APPEND, COMMIT, as detailed below. - long lastPushCommitTimeMs = -1
The last time a submission type timestamp was sent. - String peerId
Target node ID. - long compareIndex = -1
The log serial number of the completed comparison. - long writeIndex = -1
The log serial number that has been written. - int maxPendingSize = 1000
Maximum number of pending logs allowed. -
long term = -1
The current polling rounds of the Leader node.
- String leaderId = null
Leader node ID. - long lastCheckLeakTimeMs = System.currentTimeMillis()
The last time the leak was detected, the so-called leak, is to see if the number of pending log requests checked maxPending Size. - ConcurrentMap pendingMap = new ConcurrentHashMap<>()
Record the hang time of the log, key: entry index of the log, value: hang timestamp. - Quota quota = new Quota(dLedgerConfig.getPeerPushQuota())
Quotas.
2.2 Push request type
DLedger master node replicates log to slave node, which defines four types of requests. The enumeration type is PushEntryRequest.Type, whose values are COMPARE, TRUNCATE, APPEND and COMMIT, respectively.
- COMPARE
If the Leader changes, the new Leader needs to compare with the log entries of his slave node in order to truncate the redundant data of the slave node. - TRUNCATE
If the Leader completes the log comparison by indexing, the Leader will send TRUNCATE to its slave node. - APPEND
Append log entries to slave nodes. - COMMIT
Usually, leader attaches the submitted index to the append request, but if the append request is small and scattered, leader sends a separate request to notify the index submitted from the node.
After we have a preliminary understanding of the request types of master and slave nodes, we will start with the doWork method of Entry Dispatcher's business processing entry.
2.3 doWork method in detail
public void doWork() { try { if (!checkAndFreshState()) { // @1 waitForRunning(1); return; } if (type.get() == PushEntryRequest.Type.APPEND) { // @2 doAppend(); } else { doCompare(); // @3 } waitForRunning(1); } catch (Throwable t) { DLedgerEntryPusher.logger.error("[Push-{}]Error in {} writeIndex={} compareIndex={}", peerId, getName(), writeIndex, compareIndex, t); DLedgerUtils.sleep(500); } }
Code @1: Check status and continue sending append or compare.
Code @2: If the push type is APPEND, the master node propagates the message request to the slave node.
Code @3: The master node sends a contrast data difference request to the slave node (which is often the first step when a new node is elected as the master node).
2.3.1 checkAndFreshState details
EntryDispatcher#checkAndFreshState
private boolean checkAndFreshState() { if (!memberState.isLeader()) { // @1 return false; } if (term != memberState.currTerm() || leaderId == null || !leaderId.equals(memberState.getLeaderId())) { // @2 synchronized (memberState) { if (!memberState.isLeader()) { return false; } PreConditions.check(memberState.getSelfId().equals(memberState.getLeaderId()), DLedgerResponseCode.UNKNOWN); term = memberState.currTerm(); leaderId = memberState.getSelfId(); changeState(-1, PushEntryRequest.Type.COMPARE); } } return true; }
Code @1: If the state of the node is not the primary node, it returns false directly. End this doWork method. Because only the primary node needs to forward the log to the slave node.
Code @2: If the current node state is the primary node, but the current polling rounds are not set with the state machine rounds or leaderId, or the leaderId is not equal to the leaderId of the state machine, this situation usually triggers a re-election in the cluster, sets its term, leaderId and the state machine synchronization, and is about to send COMPARE requests.
Next, take a look at changeState.
private synchronized void changeState(long index, PushEntryRequest.Type target) { logger.info("[Push-{}]Change state from {} to {} at {}", peerId, type.get(), target, index); switch (target) { case APPEND: // @1 compareIndex = -1; updatePeerWaterMark(term, peerId, index); quorumAckChecker.wakeup(); writeIndex = index + 1; break; case COMPARE: // @2 if (this.type.compareAndSet(PushEntryRequest.Type.APPEND, PushEntryRequest.Type.COMPARE)) { compareIndex = -1; pendingMap.clear(); } break; case TRUNCATE: // @3 compareIndex = -1; break; default: break; } type.set(target); }
Code @1: If the target type is set to append, reset compareIndex and set writeIndex to the current index plus 1.
Code @2: If the target type is set to COMPARE, reset compareIndex to negative one, and then send COMPARE requests similar to each slave node and clear pending requests.
Code @3: If the target type is set to TRUNCATE, reset compareIndex to negative one.
Next, let's look specifically at requests such as APPEND, COMPARE, TRUNCATE, and so on.
2.3.2 Appnd Request Details
EntryDispatcher#doAppend
private void doAppend() throws Exception { while (true) { if (!checkAndFreshState()) { // @1 break; } if (type.get() != PushEntryRequest.Type.APPEND) { // @2 break; } if (writeIndex > dLedgerStore.getLedgerEndIndex()) { // @3 doCommit(); doCheckAppendResponse(); break; } if (pendingMap.size() >= maxPendingSize || (DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000)) { // @4 long peerWaterMark = getPeerWaterMark(term, peerId); for (Long index : pendingMap.keySet()) { if (index < peerWaterMark) { pendingMap.remove(index); } } lastCheckLeakTimeMs = System.currentTimeMillis(); } if (pendingMap.size() >= maxPendingSize) { // @5 doCheckAppendResponse(); break; } doAppendInner(writeIndex); // @6 writeIndex++; } }
Code @1: Check status, as detailed above.
Code @2: If the request type is not APPEND, exit and end this round of doWork method execution.
Code @3: writeIndex indicates the ordinal number currently appended to the slave node. Normally, when the master node sends an append request to the slave node, it will be accompanied by the submitted pointer of the master node. However, if the append request is not sent so frequently, the writeIndex is larger than the leaderEndIndex (because the pending request exceeds its pending request). When the queue length (default is 1w), it will prevent the data from appending. At this time, it may occur that the writeIndex is larger than the leaderEndIndex. At this time, COMMIT requests are sent separately.
Code @4: Check whether pending Map (the number of pending requests) sends a leak, that is, whether the capacity in the pending queue exceeds the maximum allowable pending threshold. Gets the current water level of the current node about the current round (log number of the successful append request) and discards it if it finds that the log number of the pending request is less than the water level.
Code @5: If the pending request (waiting for the slave node to append the result) is larger than maxPendingSize, check and append the request.
Code @6: Specific additional requests.
2.3.2.1 doCommit sends submission requests
EntryDispatcher#doCommit
private void doCommit() throws Exception { if (DLedgerUtils.elapsed(lastPushCommitTimeMs) > 1000) { // @1 PushEntryRequest request = buildPushRequest(null, PushEntryRequest.Type.COMMIT); // @2 //Ignore the results dLedgerRpcService.push(request); // @3 lastPushCommitTimeMs = System.currentTimeMillis(); } }
Code @1: If the last time a single commit request was sent was less than 1 s apart from the current time, the submission request would be abandoned.
Code @2: Build the submission request.
Code @3: Send commit requests to slave nodes over the network.
Next, let's look at how to build a commit request package.
EntryDispatcher#buildPushRequest
private PushEntryRequest buildPushRequest(DLedgerEntry entry, PushEntryRequest.Type target) { PushEntryRequest request = new PushEntryRequest(); request.setGroup(memberState.getGroup()); request.setRemoteId(peerId); request.setLeaderId(leaderId); request.setTerm(term); request.setEntry(entry); request.setType(target); request.setCommitIndex(dLedgerStore.getCommittedIndex()); return request; }
The submission package request field mainly contains the following fields: DLedger node belongs to group, slave node id, master node id, current polling rounds, log content, request type and committedIndex (master node has submitted log serial number).
2.3.2.2 doCheckAppendResponse check and append request
EntryDispatcher#doCheckAppendResponse
private void doCheckAppendResponse() throws Exception { long peerWaterMark = getPeerWaterMark(term, peerId); // @1 Long sendTimeMs = pendingMap.get(peerWaterMark + 1); if (sendTimeMs != null && System.currentTimeMillis() - sendTimeMs > dLedgerConfig.getMaxPushTimeOutMs()) { // @2 logger.warn("[Push-{}]Retry to push entry at {}", peerId, peerWaterMark + 1); doAppendInner(peerWaterMark + 1); } }
The function of this method is to check whether the append request has timed out. The key implementation of this method is as follows:
- Gets the serial number of the successful append.
- Get the next delivery time from the pending request queue. If it is not empty and exceeds the append timeout time, then send the append request again. The maximum timeout is default 1 s. The default value can be changed by maxPushTime OutMs.
2.3.2.3 doAppendInner additional request
Send an append request to the slave node.
EntryDispatcher#doAppendInner
private void doAppendInner(long index) throws Exception { DLedgerEntry entry = dLedgerStore.get(index); // @1 PreConditions.check(entry != null, DLedgerResponseCode.UNKNOWN, "writeIndex=%d", index); checkQuotaAndWait(entry); // @2 PushEntryRequest request = buildPushRequest(entry, PushEntryRequest.Type.APPEND); // @3 CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(request); // @4 pendingMap.put(index, System.currentTimeMillis()); // @5 responseFuture.whenComplete((x, ex) -> { try { PreConditions.check(ex == null, DLedgerResponseCode.UNKNOWN); DLedgerResponseCode responseCode = DLedgerResponseCode.valueOf(x.getCode()); switch (responseCode) { case SUCCESS: // @6 pendingMap.remove(x.getIndex()); updatePeerWaterMark(x.getTerm(), peerId, x.getIndex()); quorumAckChecker.wakeup(); break; case INCONSISTENT_STATE: // @7 logger.info("[Push-{}]Get INCONSISTENT_STATE when push index={} term={}", peerId, x.getIndex(), x.getTerm()); changeState(-1, PushEntryRequest.Type.COMPARE); break; default: logger.warn("[Push-{}]Get error response code {} {}", peerId, responseCode, x.baseInfo()); break; } } catch (Throwable t) { logger.error("", t); } }); lastPushCommitTimeMs = System.currentTimeMillis(); }
Code @1: First query the log according to the serial number.
Code @2: Detection quota, if exceeded, will carry out a certain current limit, its key implementation points:
- First trigger condition: the number of append pending requests has exceeded the maximum allowable number of pending requests; based on file storage and master-slave difference over 300 m, it can be configured through peerPushThrottlePoint.
- If the additional log is more than 20m per second (configurable by peerPushQuota), it will be added after sleep 1s.
Code @3: Build the PUSH request log.
Code @4: Send network requests through Netty to slave nodes, and receive requests from nodes will be processed (this article will not discuss network-related implementation details).
Code @5: Use pending Map to record the sending time of the log to be added, which can be used as a basis for sender to determine whether or not the timeout is exceeded.
Code @6: Processing logic for successful requests, the key implementation points are as follows:
- Remove the send timeout for this log from pending Map.
- Update the successfully appended log serial number (organized by polling rounds, and one key-value pair per slave server).
- Wake up the quorum Ack Checker thread (mainly for arbitrating append results), which will be described in detail later.
Code @7: Push requests have inconsistent status, and COMPARE requests will be sent to compare the data consistency of master and slave nodes.
The type of append additional request for log forwarding is described here. Next, let's move on to another request type, compare.
2.3.3 comparison request for details
The request of COMPARE type is sent by the doCompare method. First, the method runs in while (true), so when you look up the following code, you should pay attention to the condition that it exits the loop.
EntryDispatcher#doCompare
if (!checkAndFreshState()) { break; } if (type.get() != PushEntryRequest.Type.COMPARE && type.get() != PushEntryRequest.Type.TRUNCATE) { break; } if (compareIndex == -1 && dLedgerStore.getLedgerEndIndex() == -1) { break; }
Step1: There are several key points to verify whether or not it is executed as follows:
- Judge whether it is the primary node, if it is not the primary node, then jump out directly.
- If the request type is not a COMPARE or TRUNCATE request, jump out directly.
- If the compared index and ledger EndIndex are - 1, representing a new DLedger cluster, then jump out directly.
EntryDispatcher#doCompare
if (compareIndex == -1) { compareIndex = dLedgerStore.getLedgerEndIndex(); logger.info("[Push-{}][DoCompare] compareIndex=-1 means start to compare", peerId); } else if (compareIndex > dLedgerStore.getLedgerEndIndex() || compareIndex < dLedgerStore.getLedgerBeginIndex()) { logger.info("[Push-{}][DoCompare] compareIndex={} out of range {}-{}", peerId, compareIndex, dLedgerStore.getLedgerBeginIndex(), dLedgerStore.getLedgerEndIndex()); compareIndex = dLedgerStore.getLedgerEndIndex(); }
Step2: If compareIndex is - 1 or compareIndex is not valid, reset the sequence number to be compared to the largest log number currently stored: ledgerEndIndex.
DLedgerEntry entry = dLedgerStore.get(compareIndex); PreConditions.check(entry != null, DLedgerResponseCode.INTERNAL_ERROR, "compareIndex=%d", compareIndex); PushEntryRequest request = buildPushRequest(entry, PushEntryRequest.Type.COMPARE); CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(request); PushEntryResponse response = responseFuture.get(3, TimeUnit.SECONDS);
Step3: Query to the log according to the serial number and issue a COMPARE request to the slave node with a timeout of 3 seconds.
EntryDispatcher#doCompare
long truncateIndex = -1; if (response.getCode() == DLedgerResponseCode.SUCCESS.getCode()) { // @1 if (compareIndex == response.getEndIndex()) { changeState(compareIndex, PushEntryRequest.Type.APPEND); break; } else { truncateIndex = compareIndex; } } else if (response.getEndIndex() < dLedgerStore.getLedgerBeginIndex() || response.getBeginIndex() > dLedgerStore.getLedgerEndIndex()) { // @2 truncateIndex = dLedgerStore.getLedgerBeginIndex(); } else if (compareIndex < response.getBeginIndex()) { // @3 truncateIndex = dLedgerStore.getLedgerBeginIndex(); } else if (compareIndex > response.getEndIndex()) { // @4 compareIndex = response.getEndIndex(); } else { // @5 compareIndex--; } if (compareIndex < dLedgerStore.getLedgerBeginIndex()) { // @6 truncateIndex = dLedgerStore.getLedgerBeginIndex(); }
Step4: Calculate the log sequence number that needs to be truncated according to the response results. The key points of its implementation are as follows:
- Code @1: If the log numbers of the two are the same, then no truncation is needed. Next time, the append request will be sent directly from the node; otherwise, the truncateIndex will be set as the endIndex in the response result.
- Code @2: If the maximum log sequence number stored by the slave node is less than the minimum sequence number of the master node, or the minimum log sequence number of the slave node is larger than the maximum log sequence number of the master node, the two do not intersect, which usually occurs when the slave node crashes for a long time and the master node deletes the expired entries. truncateIndex is set to the ledger BeginIndex of the primary node, which is the minimum offset of the primary node at present.
- Code @3: If the compared log sequence number is less than the start log sequence number of the slave node, it is likely that the transmission loss is from the node disk and the synchronization starts from the smallest log sequence number of the master node.
- Code @4: If the compared log sequence number is larger than the maximum log sequence number of the slave node, the comparison index is set to the maximum log sequence number of the slave node, triggering the continued synchronization of data.
- Code @5: If the compared log sequence number is greater than the start log sequence number of the slave node, but less than the maximum log sequence number of the slave node, the comparison index is subtracted by one.
- Code @6: If the log sequence number compared is less than the minimum log requirement of the primary node, the minimum sequence number of the primary node is set.
if (truncateIndex != -1) { changeState(truncateIndex, PushEntryRequest.Type.TRUNCATE); doTruncate(truncateIndex); break; }
Step5: If the compared log number is not equal to - 1, a TRUNCATE request is sent to the slave node.
2.3.3.1 do Truncate
private void doTruncate(long truncateIndex) throws Exception { PreConditions.check(type.get() == PushEntryRequest.Type.TRUNCATE, DLedgerResponseCode.UNKNOWN); DLedgerEntry truncateEntry = dLedgerStore.get(truncateIndex); PreConditions.check(truncateEntry != null, DLedgerResponseCode.UNKNOWN); logger.info("[Push-{}]Will push data to truncate truncateIndex={} pos={}", peerId, truncateIndex, truncateEntry.getPos()); PushEntryRequest truncateRequest = buildPushRequest(truncateEntry, PushEntryRequest.Type.TRUNCATE); PushEntryResponse truncateResponse = dLedgerRpcService.push(truncateRequest).get(3, TimeUnit.SECONDS); PreConditions.check(truncateResponse != null, DLedgerResponseCode.UNKNOWN, "truncateIndex=%d", truncateIndex); PreConditions.check(truncateResponse.getCode() == DLedgerResponseCode.SUCCESS.getCode(), DLedgerResponseCode.valueOf(truncateResponse.getCode()), "truncateIndex=%d", truncateIndex); lastPushCommitTimeMs = System.currentTimeMillis(); changeState(truncateIndex, PushEntryRequest.Type.APPEND); }
This method mainly constructs truncate request to slave node.
Here is the message replication and forwarding of the server. The master node is responsible for requests to the slave server PUSH. The slave node naturally processes these requests. Next, we will analyze how the slave node responds according to the requests sent by the master node.
3. Entry Handler Explanation
EntryHandler is also a thread that is activated when the node state is slave.
3.1 Core Class Diagram

Its core attributes are as follows:
- long lastCheckFastForwardTimeMs
The last time I checked whether the primary server had a push message timestamp. - ConcurrentMap>> writeRequestMap
- Request processing queue.
- BlockingQueue>> compareOrTruncateRequests
COMMIT, COMPARE, TRUNCATE related requests
3.2 handlePush
From the above, the master node will actively propagate logs to the slave node, and the slave node will receive the request data through the network for processing. The call chain is as shown in the figure:
Eventually, the handlePush method of EntryHandler is invoked.
EntryHandler#handlePush
public CompletableFuture<PushEntryResponse> handlePush(PushEntryRequest request) throws Exception { //The timeout should smaller than the remoting layer's request timeout CompletableFuture<PushEntryResponse> future = new TimeoutFuture<>(1000); // @1 switch (request.getType()) { case APPEND: // @2 PreConditions.check(request.getEntry() != null, DLedgerResponseCode.UNEXPECTED_ARGUMENT); long index = request.getEntry().getIndex(); Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> old = writeRequestMap.putIfAbsent(index, new Pair<>(request, future)); if (old != null) { logger.warn("[MONITOR]The index {} has already existed with {} and curr is {}", index, old.getKey().baseInfo(), request.baseInfo()); future.complete(buildResponse(request, DLedgerResponseCode.REPEATED_PUSH.getCode())); } break; case COMMIT: // @3 compareOrTruncateRequests.put(new Pair<>(request, future)); break; case COMPARE: case TRUNCATE: // @4 PreConditions.check(request.getEntry() != null, DLedgerResponseCode.UNEXPECTED_ARGUMENT); writeRequestMap.clear(); compareOrTruncateRequests.put(new Pair<>(request, future)); break; default: logger.error("[BUG]Unknown type {} from {}", request.getType(), request.baseInfo()); future.complete(buildResponse(request, DLedgerResponseCode.UNEXPECTED_ARGUMENT.getCode())); break; } return future; }
From several points to process the push request of the primary node, the key points of its implementation are as follows.
Code @1: First, build a response result Future with a default timeout of 1 s.
Code @2: If it is an APPEND request, put it into the writeRequestMap collection. If the data structure already exists, it indicates that the primary node duplicates the push and builds the return result, and its status code is REPEATED_PUSH. Put it into the writeRequestMap, and the doWork method processes the requests to be written regularly.
Code @3: If a request is submitted, the request is stored in compareOrTruncateRequests request processing, which is handled asynchronously by the doWork method.
Code @4: If it is a COMPARE or TRUNCATE request, empty the write RequestMap to be written to the queue and place the request in the compareOrTruncateRequests request queue, which is handled asynchronously by the doWork method.
Next, we focus on the implementation of the doWork method.
3.3 doWork Method
EntryHandler#doWork
public void doWork() { try { if (!memberState.isFollower()) { // @1 waitForRunning(1); return; } if (compareOrTruncateRequests.peek() != null) { // @2 Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = compareOrTruncateRequests.poll(); PreConditions.check(pair != null, DLedgerResponseCode.UNKNOWN); switch (pair.getKey().getType()) { case TRUNCATE: handleDoTruncate(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue()); break; case COMPARE: handleDoCompare(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue()); break; case COMMIT: handleDoCommit(pair.getKey().getCommitIndex(), pair.getKey(), pair.getValue()); break; default: break; } } else { // @3 long nextIndex = dLedgerStore.getLedgerEndIndex() + 1; Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.remove(nextIndex); if (pair == null) { checkAbnormalFuture(dLedgerStore.getLedgerEndIndex()); waitForRunning(1); return; } PushEntryRequest request = pair.getKey(); handleDoAppend(nextIndex, request, pair.getValue()); } } catch (Throwable t) { DLedgerEntryPusher.logger.error("Error in {}", getName(), t); DLedgerUtils.sleep(100); } }
Code @1: If the status of the current node is not from the node, then jump out.
Code @2: If the compareOrTruncateRequests queue is not empty, it indicates that there are COMMIT, COMPARE, TRUNCATE and other requests, which are processed first. It is worth noting that peek, poll and other non-blocking methods are used here, and then the corresponding method is invoked according to the type of request. More on that later.
Code @3: If there are only append class requests, try to get the next message replication request (ledgerEndIndex + 1) as key from the writeRequestMap container based on the largest message sequence number of the current node. If it is not empty, the doAppend request is executed, and if it is empty, checkAbnormalFuture is called to handle the exception.
Next, we will focus on the details of each processing.
3.3.1 handleDoCommit
Processing the submission request is relatively simple, that is, calling the updateCommittedIndex of DLedgerStore to update its submitted offset, so let's take a look at the updateCommittedIndex method of DLedgerStore.
DLedgerMmapFileStore#updateCommittedIndex
public void updateCommittedIndex(long term, long newCommittedIndex) { // @1 if (newCommittedIndex == -1 || ledgerEndIndex == -1 || term < memberState.currTerm() || newCommittedIndex == this.committedIndex) { // @2 return; } if (newCommittedIndex < this.committedIndex || newCommittedIndex < this.ledgerBeginIndex) { // @3 logger.warn("[MONITOR]Skip update committed index for new={} < old={} or new={} < beginIndex={}", newCommittedIndex, this.committedIndex, newCommittedIndex, this.ledgerBeginIndex); return; } long endIndex = ledgerEndIndex; if (newCommittedIndex > endIndex) { // @4 //If the node fall behind too much, the committedIndex will be larger than enIndex. newCommittedIndex = endIndex; } DLedgerEntry dLedgerEntry = get(newCommittedIndex); // @5 PreConditions.check(dLedgerEntry != null, DLedgerResponseCode.DISK_ERROR); this.committedIndex = newCommittedIndex; this.committedPos = dLedgerEntry.getPos() + dLedgerEntry.getSize(); // @6 }
Code @1: First, we introduce the parameters of the method:
- long term
The current polling rounds of the primary node. - long newCommittedIndex:
The submitted log serial number when the primary node sends a log replication request.
Code @2: If the number of submission to be updated is - 1 or the number of polling rounds is less than that of the slave node or the number of polling rounds of the master node is equal to that of the slave node, the submission action will be ignored directly.
Code @3: If the submitted log number of the primary node is less than the submitted log number of the slave node or the pending submitted log number is less than the minimum valid log number of the current node, the warning log [MONITOR] is output and the submission action is ignored.
Code @4: If the slave node lags too much behind the master node, the submission index is reset to the current maximum valid log serial number of the slave node.
Code @5: Attempts to find data from slave nodes based on the sequence number to be submitted, and throws a DISK_ERROR error if the data does not exist.
Code @6: Update the commitedIndex and committedPos t pointers, DledgerStore will periodically brush the submitted pointer into the checkpoint file to achieve the purpose of persistent commitedIndex pointer.
3.3.2 handleDoCompare
Processing the COMPARE request sent by the main node is also relatively simple, and finally calling the buildResponse method to construct the response result.
EntryHandler#buildResponse
private PushEntryResponse buildResponse(PushEntryRequest request, int code) { PushEntryResponse response = new PushEntryResponse(); response.setGroup(request.getGroup()); response.setCode(code); response.setTerm(request.getTerm()); if (request.getType() != PushEntryRequest.Type.COMMIT) { response.setIndex(request.getEntry().getIndex()); } response.setBeginIndex(dLedgerStore.getLedgerBeginIndex()); response.setEndIndex(dLedgerStore.getLedgerEndIndex()); return response; }
It also returns the current ledger BeginIndex, ledger EndIndex and voting rounds from several points for the main node to judge and compare.
3.3.3 handleDoTruncate
The handleDoTruncate method is relatively simple to implement. It deletes all logs after truncateIndex log serial number from the node and calls dLedgerStore's truncate method. Because its storage design is basically similar to that of RocketMQ, this paper will not introduce in detail the main points of its implementation: according to the log serial number, To locate the log file, if hit a specific file, then modify the corresponding read-write pointer, brush pointer, and delete all the files after the physical file. If you are interested, you can refer to the author's "RocketMQ Technology Insider" Chapter 4: RocketMQ storage related content.
3.3.4 handleDoAppend
private void handleDoAppend(long writeIndex, PushEntryRequest request, CompletableFuture<PushEntryResponse> future) { try { PreConditions.check(writeIndex == request.getEntry().getIndex(), DLedgerResponseCode.INCONSISTENT_STATE); DLedgerEntry entry = dLedgerStore.appendAsFollower(request.getEntry(), request.getTerm(), request.getLeaderId()); PreConditions.check(entry.getIndex() == writeIndex, DLedgerResponseCode.INCONSISTENT_STATE); future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode())); dLedgerStore.updateCommittedIndex(request.getTerm(), request.getCommitIndex()); } catch (Throwable t) { logger.error("[HandleDoWrite] writeIndex={}", writeIndex, t); future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode())); } }
The implementation is also relatively simple. AppndAsFollower method of DLedgerStore is called to append the log, which is the same as AppndAsLeader in the log storage section, except that no further log forwarding is needed from the node.
3.3.5 checkAbnormalFuture
This method is the focus of this section. doWork's maximum effective log number (ledgerEndIndex) +1 sequence number stored from the slave server tries to call when the corresponding request cannot be obtained from the pending request. This is also common, such as the master node does not give the latest data PUSH to the slave node. Next, let's look at the implementation details of this method in detail.
EntryHandler#checkAbnormalFuture
if (DLedgerUtils.elapsed(lastCheckFastForwardTimeMs) < 1000) { return; } lastCheckFastForwardTimeMs = System.currentTimeMillis(); if (writeRequestMap.isEmpty()) { return; }
Step1: If the last check is less than 1 s from now, it jumps out; if there is no backlog of append requests, it jumps out, because it can be equally clear that the primary node has not yet pushed the log.
EntryHandler#checkAbnormalFuture
for (Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair : writeRequestMap.values()) { long index = pair.getKey().getEntry().getIndex(); // @1 //Fall behind if (index <= endIndex) { // @2 try { DLedgerEntry local = dLedgerStore.get(index); PreConditions.check(pair.getKey().getEntry().equals(local), DLedgerResponseCode.INCONSISTENT_STATE); pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.SUCCESS.getCode())); logger.warn("[PushFallBehind]The leader pushed an entry index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", index, endIndex); } catch (Throwable t) { logger.error("[PushFallBehind]The leader pushed an entry index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", index, endIndex, t); pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode())); } writeRequestMap.remove(index); continue; } //Just OK if (index == endIndex + 1) { // @3 //The next entry is coming, just return return; } //Fast forward TimeoutFuture<PushEntryResponse> future = (TimeoutFuture<PushEntryResponse>) pair.getValue(); // @4 if (!future.isTimeOut()) { continue; } if (index < minFastForwardIndex) { // @5 minFastForwardIndex = index; } }
Step 2: traverse the current log append request (the log copy request pushed by the main server) to find the index that needs fast forward. Its key implementation points are as follows:
- Code @1: First get the serial number to be written to the log.
- Code @2: If the serial number of the log to be written is less than the log appended from the slave node (endIndex), and the log is indeed stored in the slave node, it returns success, and outputs the warning log (PushFallBehind) to continue monitoring the next log to be written.
- Code @3: If the index to be written equals endIndex + 1, the loop ends because the next log message is already in the queue to be written and is about to be written.
- Code @4: If the index to be written is greater than endIndex + 1 and does not time out, check the next log to be written directly.
- Code @5: If the index to be written is greater than endIndex + 1 and has timed out, the index is recorded and stored using minFastForward Index.
EntryHandler#checkAbnormalFuture
if (minFastForwardIndex == Long.MAX_VALUE) { return; } Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.get(minFastForwardIndex); if (pair == null) { return; }
Step3: If the log number requiring a quick failure is not found or the request is not found in the writeRequestMap, the detection is terminated directly.
EntryHandler#checkAbnormalFuture
logger.warn("[PushFastForward] ledgerEndIndex={} entryIndex={}", endIndex, minFastForwardIndex); pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
Step4: Reporting to the master that the slave node has inconsistent data with the master node, the slave node does not write a log with the serial number minFastForwardIndex. If the primary node receives such a response, it will stop the log forwarding and send COMPARE requests to each slave node to make the data recovery consistent.
So far, we have described in detail that the primary server sends requests to the slave server and responds from the service. Next, let's look at the processing after the server receives the response results. We need to know that the primary node will propagate logs to all its slave nodes. The primary node needs to receive more than half of the cluster within a specified time. Node validation is the only way to think that log writing is successful, so let's take a look at its implementation.
4,QuorumAckChecker
Log replication voter. A log write request will only be submitted if it receives the response of most nodes in the cluster.
4.1 classes of Graphs

Its core attributes are as follows:
- long lastPrintWatermarkTimeMs
The last time the water level was printed, in milliseconds. - long lastCheckLeakTimeMs
The last time stamp for leak detection was in milliseconds. - long lastQuorumIndex
The log number of the voted arbitration.
4.2 details of dowork
QuorumAckChecker#doWork
if (DLedgerUtils.elapsed(lastPrintWatermarkTimeMs) > 3000) { logger.info("[{}][{}] term={} ledgerBegin={} ledgerEnd={} committed={} watermarks={}", memberState.getSelfId(), memberState.getRole(), memberState.currTerm(), dLedgerStore.getLedgerBeginIndex(), dLedgerStore.getLedgerEndIndex(), dLedgerStore.getCommittedIndex(), JSON.toJSONString(peerWaterMarksByTerm)); lastPrintWatermarkTimeMs = System.currentTimeMillis(); }
Step1: If it takes more than 3 seconds to print the watermap last time, print the current term, ledger Begin, ledger End, committed, peerWaterMarks ByTerm data logs.
QuorumAckChecker#doWork
if (!memberState.isLeader()) { // @2 waitForRunning(1); return; }
Step2: If the current node is not the primary node, return directly and do nothing.
QuorumAckChecker#doWork
if (pendingAppendResponsesByTerm.size() > 1) { // @1 for (Long term : pendingAppendResponsesByTerm.keySet()) { if (term == currTerm) { continue; } for (Map.Entry<Long, TimeoutFuture<AppendEntryResponse>> futureEntry : pendingAppendResponsesByTerm.get(term).entrySet()) { AppendEntryResponse response = new AppendEntryResponse(); response.setGroup(memberState.getGroup()); response.setIndex(futureEntry.getKey()); response.setCode(DLedgerResponseCode.TERM_CHANGED.getCode()); response.setLeaderId(memberState.getLeaderId()); logger.info("[TermChange] Will clear the pending response index={} for term changed from {} to {}", futureEntry.getKey(), term, currTerm); futureEntry.getValue().complete(response); } pendingAppendResponsesByTerm.remove(term); } } if (peerWaterMarksByTerm.size() > 1) { for (Long term : peerWaterMarksByTerm.keySet()) { if (term == currTerm) { continue; } logger.info("[TermChange] Will clear the watermarks for term changed from {} to {}", term, currTerm); peerWaterMarksByTerm.remove(term); } }
Step3: Clean up the data of this polling round in pending AppendResponses ByTerm and peerWaterMarks ByTerm to avoid unnecessary memory usage.
Map<String, Long> peerWaterMarks = peerWaterMarksByTerm.get(currTerm); long quorumIndex = -1; for (Long index : peerWaterMarks.values()) { // @1 int num = 0; for (Long another : peerWaterMarks.values()) { // @2 if (another >= index) { num++; } } if (memberState.isQuorum(num) && index > quorumIndex) { // @3 quorumIndex = index; } } dLedgerStore.updateCommittedIndex(currTerm, quorumIndex); // @4
Step4: Arbitration is conducted to determine the submitted serial number according to the progress of feedback from each slave node. To deepen our understanding of this code, let's go into the role of peerWaterMarks, which stores the log serial numbers that have been successfully appended to each slave node. For example, in a three-node DLedger cluster, peerWaterMarks data storage is roughly as follows:
{ "dledger_group_01_0" : 100, "dledger_group_01_1" : 101, }
Where dledger_group_01_0 is the ID of slave node 1, the current replicated serial number is 100, while dledger_group_01_1 is the ID of node 2, and the current replicated serial number is 101. Plus the primary node, how to determine the committable serial number?
- Code @1: First traverse the value set of peerWaterMarks, which is {100,101} in the example above, and use the temporary variable index to represent the log serial number to be voted. If more than half of the nodes in the cluster need the replicated serial number to exceed that value, the log can be confirmed for submission.
- Code @2: Traverse through all submitted serial numbers in peerWaterMarks and compare them with the current value. If the submitted serial number of a node is greater than or equal to the log index to be voted on, num plus one indicates that it votes in favour.
- Code @3: Arbitrate index and update the value of quorum index to index if it exceeds half and index is larger than quorum index. After traversing the quorum index, we get the largest submissible log serial number at present.
- Code @4: Update the committedIndex index to facilitate DLedgerStore to periodically write committedIndex to checkpoint.
ConcurrentMap<Long, TimeoutFuture<AppendEntryResponse>> responses = pendingAppendResponsesByTerm.get(currTerm); boolean needCheck = false; int ackNum = 0; if (quorumIndex >= 0) { for (Long i = quorumIndex; i >= 0; i--) { // @1 try { CompletableFuture<AppendEntryResponse> future = responses.remove(i); // @2 if (future == null) { // @3 needCheck = lastQuorumIndex != -1 && lastQuorumIndex != quorumIndex && i != lastQuorumIndex; break; } else if (!future.isDone()) { // @4 AppendEntryResponse response = new AppendEntryResponse(); response.setGroup(memberState.getGroup()); response.setTerm(currTerm); response.setIndex(i); response.setLeaderId(memberState.getSelfId()); response.setPos(((AppendFuture) future).getPos()); future.complete(response); } ackNum++; // @5 } catch (Throwable t) { logger.error("Error in ack to index={} term={}", i, currTerm, t); } } }
Step5: Processing pending requests before quorum Index requires sending a response to the client. The implementation steps are as follows:
- Code @1: Processing starts with quorum index, but not one. The serial number is subtracted by one until it is greater than 0 or exits voluntarily. See the exit logic below.
- The pending request to remove the log entry in code @2: responses.
-
Code @3: If no pending request is found, it means that all pending requests have been processed, ready to quit, and set the value of needCheck before quitting, based on the following (three conditions must be met at the same time):
- The log number of the last arbitration is not equal to -1
- And the last time is not equal to the log number of the new arbitration.
- The log number of the last arbitration is not equal to the log of the last arbitration. Normally, condition 1 and condition 2 are usually true, but this probability returns false.
- Code @4: Returns the result to the client.
- Code @5: ackNum, indicating the number of confirmations.
if (ackNum == 0) { for (long i = quorumIndex + 1; i < Integer.MAX_VALUE; i++) { TimeoutFuture<AppendEntryResponse> future = responses.get(i); if (future == null) { break; } else if (future.isTimeOut()) { AppendEntryResponse response = new AppendEntryResponse(); response.setGroup(memberState.getGroup()); response.setCode(DLedgerResponseCode.WAIT_QUORUM_ACK_TIMEOUT.getCode()); response.setTerm(currTerm); response.setIndex(i); response.setLeaderId(memberState.getSelfId()); future.complete(response); } else { break; } } waitForRunning(1); }
Step6: If the number of confirmations is 0, try to determine whether the request exceeding the arbitration number has timed out, and if it has timed out, return the timed response result.
if (DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000 || needCheck) { updatePeerWaterMark(currTerm, memberState.getSelfId(), dLedgerStore.getLedgerEndIndex()); for (Map.Entry<Long, TimeoutFuture<AppendEntryResponse>> futureEntry : responses.entrySet()) { if (futureEntry.getKey() < quorumIndex) { AppendEntryResponse response = new AppendEntryResponse(); response.setGroup(memberState.getGroup()); response.setTerm(currTerm); response.setIndex(futureEntry.getKey()); response.setLeaderId(memberState.getSelfId()); response.setPos(((AppendFuture) futureEntry.getValue()).getPos()); futureEntry.getValue().complete(response); responses.remove(futureEntry.getKey()); } } lastCheckLeakTimeMs = System.currentTimeMillis(); }
Step7: Check whether to send leaks. Its judgment of leakage is based on the removal of pending requests if their log number is less than the submitted one.
Step8: A log arbitration is over and lastQuorumIndex is updated as the new submission value for this arbitration.
That's all for the log replication section of DLedger. This article is a long one. Thank you, dear readers and friends, for your compliments.
Recommended Reading: Source Code Analysis RocketMQ DLedger Multi-copy Series Column
1,RocketMQ Multi-copy Preface: A Preliminary Study of raft Protocol
2,Leader Selector for Multiple Copies of RocketMQ DLedger for Source Code Analysis
3,Implementation of RocketMQ DLedger Multi-copy Storage for Source Code Analysis
4,Log Addition Process for Source Analysis RocketMQ DLedger
The original release date is: 2019-09-23
Author: Ding Wei, author of RocketMQ Technology Insider.
This article comes from Interest Circle of Middleware To learn about relevant information, you can pay attention to it. Interest Circle of Middleware.