Logging Operator is an open source log collection scheme under Banzai cloud under the cloud native scenario. Previously, Xiaobai reprinted an article introduced by boss Cui. However, he had always thought that the architecture of managing Fluent bit and fluent D services simultaneously under a single k8s cluster was bloated, leaving a preliminary impression that it was not applicable. Later, when Xiaobai made a plan for log management of k8s cluster in a multi tenant scenario, he found that the traditional way of unified log configuration management is very flexible. Usually, the operator will take an overall perspective and try to make the log configuration into a template to adapt to the business. Over time, the template will become very large and bloated, which brings great challenges to subsequent maintenance and successors.
After studying the Logging Operator during this period of time, I found that it was very comfortable to use Kubernetes to manage logs. Before opening, let's take a look at its architecture.
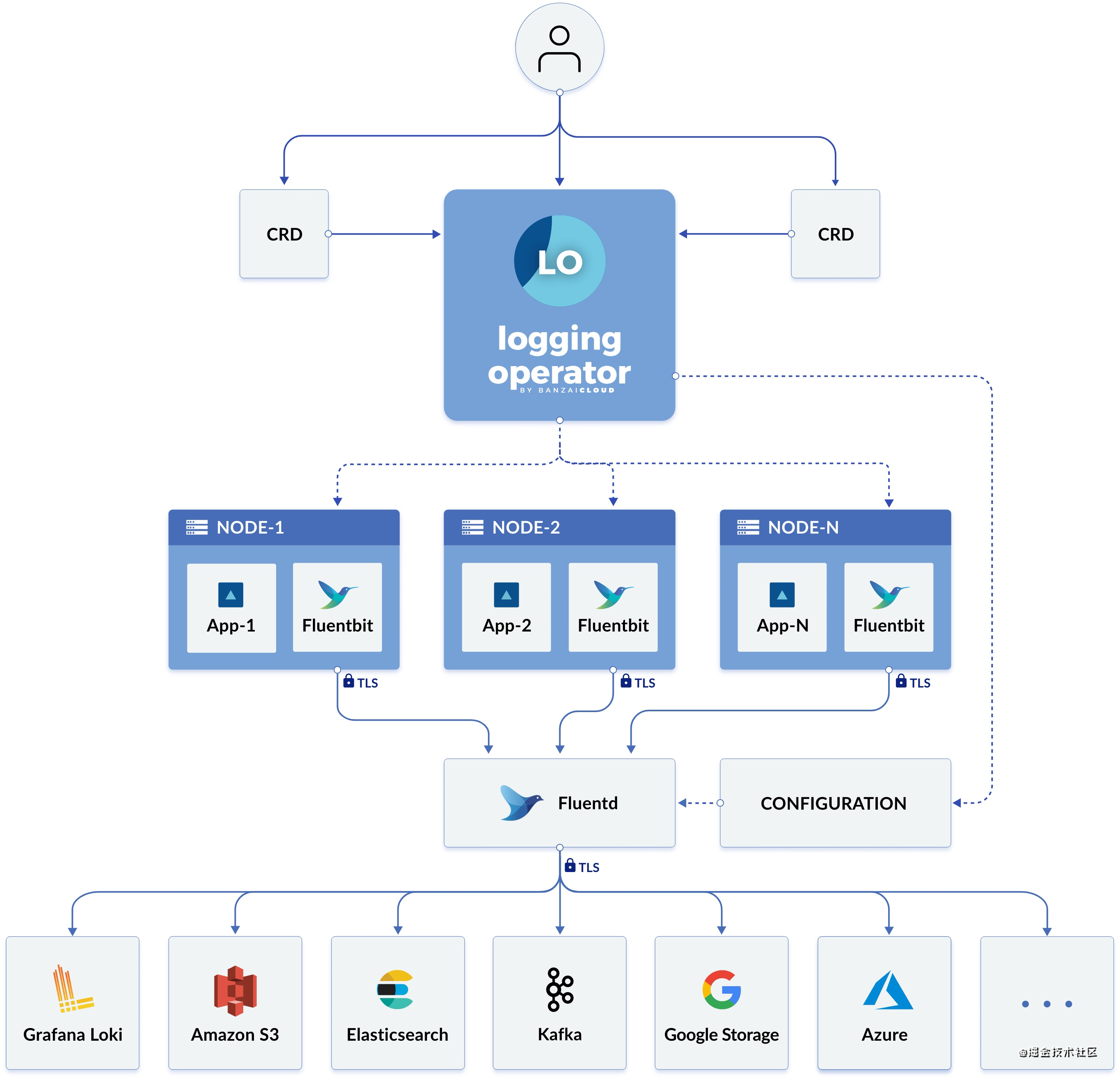
It can be seen that the Logging Operator uses CRD to intervene in the configuration of logs in the three stages of collection, routing and output. In essence, it deploys fluent bit and fluent D in the cluster by using DaemonSet and StatefulSet. Fluent bit collects and preliminarily processes the container log and forwards it to fluent D for further analysis and routing. Finally, fluent D forwards the log results to different services.
Therefore, after the service is containerized, we can discuss whether the log output standard should be printed to standard output or to file.
In addition to managing the log workflow, the Logging Operator can also enable the manager to enable TLS to encrypt the network transmission of logs within the cluster, and ServiceMonitor is integrated by default to expose the status of the log collection end. Of course, the most important thing is that due to the configuration of CRD, our log strategy can finally realize multi tenant management in the cluster.
1.Logging Operator CRD
There are only five core CRD s in the whole Logging Operator. They are
- logging: used to define the basic configuration of a log collection end (FleuntBit) and transmission end (Fleuntd) service;
- flow: used to define a namespace level log filtering, parsing, routing and other rules.
- clusterflow: used to define a cluster level log filtering, parsing, routing and other rules.
- Output: used to define the output and parameters of the namespace level log;
- clusteroutput: used to define the log output and parameters at the cluster level. It can associate flow s in other namespaces;
Through these five CRD s, we can customize the flow direction of container logs in each namespace in the Kubernetes cluster
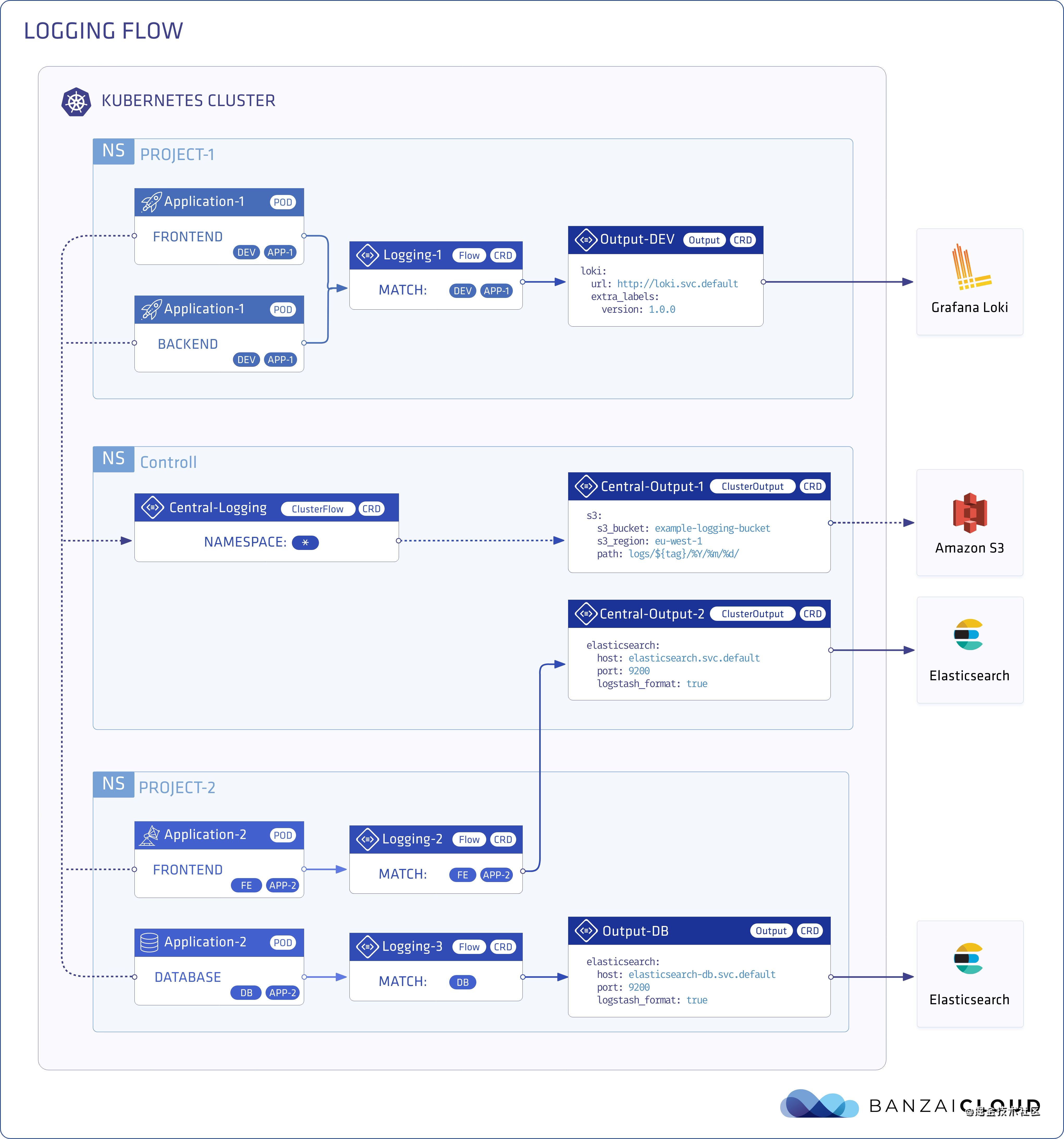
2. Installation of logging operator
Logging Operator relies on kuberentes1 Versions after 14 can be installed in helm and mainfest respectively.
- Helm(v3.21.0 +) installation
$ helm repo add banzaicloud-stable https://kubernetes-charts.banzaicloud.com $ helm repo update $ helm upgrade --install --wait --create-namespace --namespace logging logging-operator banzaicloud-stable/logging-operator \ --set createCustomResource=false"
- Mainfest installation
$ kubectl create ns logging # RBAC $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator-docs/master/docs/install/manifests/rbac.yaml # CRD $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator/master/config/crd/bases/logging.banzaicloud.io_clusterflows.yaml $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator/master/config/crd/bases/logging.banzaicloud.io_clusteroutputs.yaml $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator/master/config/crd/bases/logging.banzaicloud.io_flows.yaml $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator/master/config/crd/bases/logging.banzaicloud.io_loggings.yaml $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator/master/config/crd/bases/logging.banzaicloud.io_outputs.yaml # Operator $ kubectl -n logging create -f https://raw.githubusercontent.com/banzaicloud/logging-operator-docs/master/docs/install/manifests/deployment.yaml
After the installation, we need to verify the status of the service
# Operator status $ kubectl -n logging get pods NAME READY STATUS RESTARTS AGE logging-logging-operator-599c9cf846-5nw2n 1/1 Running 0 52s # CRD status $ kubectl get crd |grep banzaicloud.io NAME CREATED AT clusterflows.logging.banzaicloud.io 2021-03-25T08:49:30Z clusteroutputs.logging.banzaicloud.io 2021-03-25T08:49:30Z flows.logging.banzaicloud.io 2021-03-25T08:49:30Z loggings.logging.banzaicloud.io 2021-03-25T08:49:30Z outputs.logging.banzaicloud.io 2021-03-25T08:49:30Z
Configuring operator.logging
3.1 logging
LoggingSpec
LoggingSpec defines the logging infrastructure service for collecting and transmitting log messages, including the configuration of fluent D and fluent bit. They are deployed in the namespace specified by controlNamespace. A simple example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
namespace: logging
spec:
fluentd: {}
fluentbit: {}
controlNamespace: logging
This example tells the Operator to create a default configured logging service in the logging namespace, including fluent bit and fluent D services
Of course, in fact, we will not only use the default configuration when deploying fluent bit and fluent D in the production environment. Usually, we need to consider many aspects, such as:
- Custom image
- Data persistence of log collection site file
- Buffer data persistence
- CPU / memory resource limit
- Condition monitoring
- Number of fluent replicas and load balancing
- Network parameter optimization
- Container operation safety
Fortunately, the above support is relatively comprehensive in Loggingspec. We can refer to the documentation to customize our own services
Xiaobai selects several important fields to explain the following purposes:
- watchNamespaces
Formulate the namespace for the Operator to listen to Flow and OutPut resources. If you are a multi tenant scenario and each tenant defines the log schema with logging, you can use watchNamespaces to associate the tenant's namespace to narrow the scope of resource filtering
- allowClusterResourcesFromAllNamespaces
Global resources such as ClusterOutput and ClusterFlow only take effect in the namespace associated with controlNamespace by default. If they are defined in other namespaces, they will be ignored unless allowClusterResourcesFromAllNamespaces is set to true
LoggingSpec description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/logging_types/
FluentbitSpec
- filterKubernetes
The plug-in used to obtain the Kubernetes metadata of the log is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd: {}
fluentbit:
filterKubernetes:
Kube_URL: "https://kubernetes.default.svc:443"
Match: "kube.*"
controlNamespace: logging
You can also disable this function with disableKubernetesFilter. The example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd: {}
fluentbit:
disableKubernetesFilter: true
controlNamespace: logging
filterKubernetes description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/fluentbit_types/#filterkubernetes
- inputTail
Define the log tail collection configuration of fluent bit, which is controlled by many detailed parameters. Xiaobai directly pastes the configuration example currently in use:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
inputTail:
Skip_Long_Lines: "true"
#Parser: docker
Parser: cri
Refresh_Interval: "60"
Rotate_Wait: "5"
Mem_Buf_Limit: "128M"
#Docker_Mode: "true"
Docker_Mode: "false
If the container of Kubernetes cluster is container or other CRI at runtime, you need to change the Parser to CRI and disable Docker_Mode
inputTail description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/fluentbit_types/#inputtail
- buffers
It defines the buffer setting of fluent bit, which is more important. Since fluent bit is deployed in Kubernetes cluster in the form of daemon set, we can directly use the volume mount method of hostPath to provide it with data persistence configuration. The example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
bufferStorage:
storage.backlog.mem_limit: 10M
storage.path: /var/log/log-buffer
bufferStorageVolume:
hostPath:
path: "/var/log/log-buffer"
bufferStorage description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/fluentbit_types/#bufferstorage
- positiondb
Defines the file location information of the FluentBit collection log. Similarly, we can support it in the way of hostPath. The example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
positiondb:
hostPath:
path: "/var/log/positiondb"
- image
Provide customized image information of fluent bit. Here I strongly recommend using the image after fluent bit-1.7.3, which fixes the problem of many network connection timeout at the acquisition end. Its example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
image:
repository: fluent/fluent-bit
tag: 1.7.3
pullPolicy: IfNotPresent
- metrics
The monitoring exposure port of fluent bit and the integrated ServiceMonitor collection definition are defined. Its examples are as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
metrics:
interval: 60s
path: /api/v1/metrics/prometheus
port: 2020
serviceMonitor: true
- resources
Defines the resource allocation and restriction information of fluent bit. The example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
resources:
limits:
cpu: "1"
memory: 512Mi
requests:
cpu: 200m
memory: 128Mi
- security
Defines the security settings during the operation of fluent bit, including PSP, RBAC, securityContext and podSecurityContext. Together, they control the permissions in the fluent bit container. Their examples are as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
security:
podSecurityPolicyCreate: true
roleBasedAccessControlCreate: true
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
podSecurityContext:
fsGroup: 101
- performance parameter
This defines some parameters in terms of running performance of fluent bit, including:
1. Turn on forward to forward the upstream response
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
forwardOptions:
Require_ack_response: true
2.TCP connection parameters
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
network:
connectTimeout: 30
keepaliveIdleTimeout: 60
3. Turn on load balancing mode
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
enableUpstream: true
4. Scheduling stain tolerance
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentbit:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
FluentdSpec
- buffers
Here we mainly define the buffer data persistence configuration of fluent D. since fluent D is deployed in StatefulSet mode, it is not appropriate for us to use hostPath. Here we should create a special buffer data volume for each instance of fluent D in the way of PersistentVolumeCliamTemplate. The example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd:
bufferStorageVolume:
pvc:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
storageClassName: csi-rbd
volumeMode: Filesystem
If storageClassName is not specified here, the Operator will create pvc through the storage plug-in whose StorageClass is default
- FluentOutLogrotate
It defines that the standard output of FLUENT is redirected to the file configuration. This is mainly to avoid the chain reaction of fluent when an error occurs, and the error message is returned to the system as a log message to generate another error. An example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd:
fluentOutLogrotate:
enabled: true
path: /fluentd/log/out
age: 10
size: 10485760
The meaning expressed here is to redirect the fluentd log to the / fluentd/log/out directory, keep it for 10 days, and the maximum file size shall not exceed 10M
Fluent outlogrotate description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/fluentd_types/#fluentoutlogrotate
- Scaling
Here we mainly define the number of copies of fluent D. if fluent bit enables upstream support, adjusting the number of copies of fluent D will lead to the rolling update of fluent bit. Its example is as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd:
scaling:
replicas: 4
scaling description document: https://banzaicloud.com/docs/one-eye/logging-operator/configuration/crds/v1beta1/fluentd_types/#fluentdscaling
- Worker
The number of concurrent processes defined by fluent can be significantly increased due to the number of concurrent processes defined by fluent as follows:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd:
workers: 2
When the number of workers is greater than 1, the version before Operator-3.9.2 is not friendly to the buffer data persistent storage of fluent D, which may cause the fluent D container to Crash
- image
The image information of Fluentd is defined. Here, the image customized by Logging Operator must be used. The image version can be customized, and the structure is similar to that of FluetnBit.
- security
Defines the security settings during the operation of fluent, including PSP, RBAC, securityContext and podSecurityContext. The structure is similar to that of fluent bit.
- metrics
The monitoring exposure port of fluent and the integrated ServiceMonitor collection definition are defined. The structure is similar to that of fluent bit.
- resources
It defines the resource allocation and restriction information of fluent, and its structure is similar to that of fluent bit.
Phased summary
This paper introduces the architecture, deployment and CRD of Logging Operator, and describes the definition and important parameters of logging in detail. When we want to use the Operator to collect logs in the production environment, they will become very important. Please refer to the documents before using them.
Since there are many contents of logging operator, I will update the use of Flow, ClusterFlow, Output, ClusterOutput and various Plugins in later issues. Please pay continuous attention
WeChat is concerned about the official account of Yun Yuan Sheng Xiao Bai, and enters Loki learning group.
