Learning objectives
-
Understand the characteristics of numerical data and category data
-
MinMaxScaler is used to normalize the feature data
-
Standardization of feature data using StandardScaler
1. What is feature preprocessing
Feature preprocessing: the process of converting feature data into feature data more suitable for the algorithm model through some conversion functions
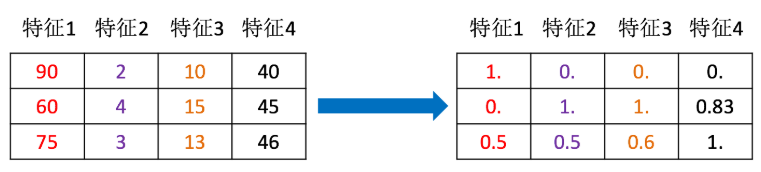
It can be understood from the picture above
1.1 contents
Dimensionless of numerical data:
-
normalization
-
Standardization
1.2 feature preprocessing API
sklearn.preprocessing
Why should we normalize / standardize?
The units or sizes of features differ greatly, or the variance of a feature is several orders of magnitude larger than other features, which is easy to affect (dominate) the target results, so that some algorithms can not learn other features
Date data

We need to use some methods for dimensionless, so that different specifications of data can be converted to the same specification
2 normalization
2.1 definitions
By transforming the original data, the data is mapped to (default is [0,1])
2.2 formula
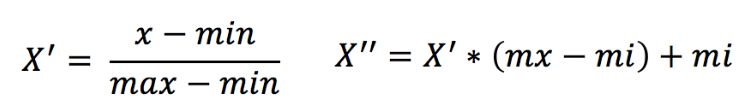
Acting on each column, max is the maximum value of a column and min is the minimum value of a column, then X '' is the final result, mx and mi are the specified interval values respectively, and mx is 1 and mi is 0 by default
So how to understand this process? We pass an example


2.3 API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)... )
- MinMaxScalar.fit_transform(X)
- 10: Data in numpy array format [n_samples,n_features]
- Return value: array with the same shape after conversion
- MinMaxScalar.fit_transform(X)
2.4 data calculation
We calculate the following data in dating Txt. What is saved is the previous date data
milage,Liters,Consumtime,target 40920,8.326976,0.953952,3 14488,7.153469,1.673904,2 26052,1.441871,0.805124,1 75136,13.147394,0.428964,1 38344,1.669788,0.134296,1
analysis
-
Instantiate MinMaxScalar
-
Through fit_transform transform
def minmax_demo():
"""
normalization
:return:
"""
# 1. Get data
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
# 2. Instantiate a converter class
transform = MinMaxScaler()
# transform = MinMaxScaler(feature_range=[2, 3])
# 3. Call fit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None

Question: if there are many outliers in the data, what will be the impact?

2.5 normalization summary
Note that the maximum and minimum values vary. In addition, the maximum and minimum values are very vulnerable to outliers, so this method has poor robustness and is only suitable for traditional accurate small data scenarios.
3 standardization
3.1 definitions
Through the transformation of the original data, the data is transformed into the range of mean value 0 and standard deviation 1
3.2 formula
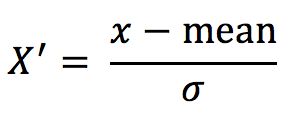
Acting on each column, mean is the average, σ Is the standard deviation
So back to the outliers just now, let's look at standardization

-
For normalization: if there are outliers that affect the maximum and minimum values, the results will obviously change
-
For Standardization: if there are outliers, there are a small number of outliers due to a certain amount of data
-
The effect on the mean value is not large, so the variance change is small.
3.3 API
- sklearn.preprocessing.StandardScaler( )
- After processing, for each column, all data are clustered around the mean value 0, and the standard deviation is 1
- StandardScaler.fit_transform(X)
- 10: Data in numpy array format [n_samples,n_features]
- Return value: array with the same shape after conversion
3.4 data calculation
The above data is also processed
[[90,2,10,40], [60,4,15,45], [75,3,13,46]]
analysis
-
Instantiate StandardScaler
-
Through fit_transform transform
def stand_demo():
"""
Standardization
When there are enough samples, it is suitable for the noisy big data scene
:return:
"""
# 1. Get data
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
# 2. Instantiate a converter class
transform = StandardScaler()
# 3. Call fit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None

3.5 standardization summary
It is stable when there are enough samples, and is suitable for modern noisy big data scenarios.