2.1 overview of k-nearest neighbor algorithm
In short, k-nearest neighbor algorithm uses the method of measuring the distance between different eigenvalues for classification
- Advantages: high precision, insensitive to outliers and no data input assumption
- Disadvantages: high computational complexity and space complexity
- Applicable data range: numerical type and nominal type
- Numerical type: numerical type target variables can be taken from infinite numerical sets, such as 0.100, 42.001, etc. (numerical type target variables are mainly used for regression analysis)
- Nominal type: the results of nominal type target variables only take values in limited target sets, such as true and false (nominal type target variables are mainly used for classification)
K-nearest neighbor (k-NN) is a basic classification and regression method proposed by Cover T and Hart P in 1967. Its working principle is: there is a sample data set, also known as the training sample set, and each data in the sample set has a label, that is, we know the corresponding relationship between each data in the sample set and its classification. After entering the new data without labels, each feature of the new data is compared with the corresponding feature of the data in the sample set, and then the algorithm extracts the classification label of the most similar data (nearest neighbor) of the sample. Generally speaking, we only select the first k most similar data in the sample data set, which is the source of K in the k-nearest neighbor algorithm. Generally, K is an integer not greater than 20. Finally, the most frequent classification among the k most similar data is selected as the classification of new data.
Example: using k-nearest neighbor algorithm to classify love movies and action movies
Figure 2-1 shows the number of fighting and kissing scenes in five action films. If there is a film that has not been seen, KNN can be used to determine whether it is a love film or an action film.

In the picture? It is a graphical display of the number of shots in the unknown film. See table 2-1 for specific figures

By calculating the distance between the unknown movie and other movies in the sample set, its type can be judged.
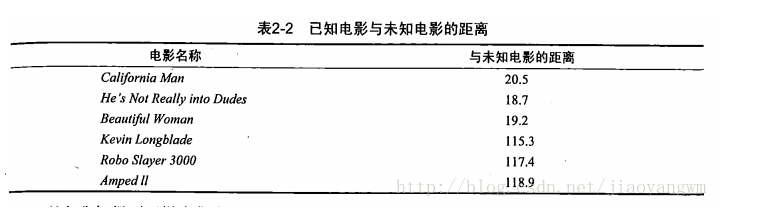
According to the order of increasing distance, you can find k nearest movies. Assuming k=3, all the nearest movies are love movies, which can be judged as love movies.
General process of k-nearest neighbor algorithm:
- 1. Calculate the distance between the point in the known category data set and the current point;
- 2. Sort according to the order of increasing distance;
- 3. Select the k points with the smallest distance from the current point;
- 4. Determine the occurrence frequency of the category where the first k points are located;
- 5. Return the category with the highest frequency of the first k points as the prediction classification of the current point

Distance measurement:


2.1.1 preparation: import data using python
from numpy import *
import operator # Import operator module
# Functions that create datasets and labels
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
if __name__ == '__main__':
group, labels = createDataSet()
print(group)
print(labels)
result:
[[ 1. 1.1] [ 1. 1. ] [ 0. 0. ] [ 0. 0.1]] ['A', 'A', 'B', 'B']
2.1.2 parsing data from text files
The k-nearest neighbor algorithm is used to divide each group of data into a class, and its pseudo code is as follows:
Perform the following operations for each point in the dataset of unknown category attributes in turn:
Calculates the distance between a point in a known category dataset and the current point
Sort by increasing distance
Select the k points with the smallest distance from the current point
Determine the frequency of occurrence of the category where the first k points are located
Return the category with the highest frequency of the first k points as the prediction classification of the current point
import numpy as np
import operator
"""
Function Description: KNN Algorithm, text classification
Parameters:
inX: Data for classification (test set)
dataSet: Data for training (training set)
labels: Classification label
k: kNN Algorithm parameters, select the algorithm with the smallest distance k Point
returns:
Classification results
modify:
2018-03-08
"""
def classify0(inX,dataSet,labels,k):
#numpy function shape[0] returns the number of rows of dataSet
dataSetSize=dataSet.shape[0]
#Repeat inX once (horizontally) in the direction of column vector and inX times (vertically) in the direction of row vector
#numpy.tile([0,0],(1,1))#Repeat [0,0] once in the column direction and once in the row > > > array ([[0,0]])
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#Square of two-dimensional feature subtraction
sqDiffMat=diffMat**2
#sum() adds all elements, sum(0) columns and sum(1) rows
sqDistances=sqDiffMat.sum(axis=1)
#Square off and calculate the distance
distances=sqDistances**0.5
#Returns the index value of the elements in distances sorted from small to large
sortedDistIndices=distances.argsort()
#Define a dictionary that records the number of times of a category
classCount={}
for i in range(k):
#Take out the category of the first k elements
voteIlabel=labels[sortedDistIndices[i]]
#Calculate the number of categories
# dict.get(key,default=None), the get() method of the dictionary, returns the value of the specified key. If the value is not in the dictionary, it returns the default value.
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
#key=operator.items(1) sort by dictionary value
#key=operator.items(0) is sorted according to the key value of the dictionary
#reverse descending sort dictionary
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#The category that returns the most times, that is, the category to be classified
return sortedClassCount[0][0]
Among them, the number of elements of the label vector is the same as the number of rows of the matrix dataSet. In the above program, the Euclidean distance formula is used to calculate the distance between two vector points.
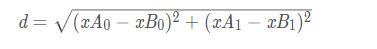
Example of overall program:
result:
```python
import numpy as np
import operator
"""
Function Description: KNN Algorithm, text classification
Parameters:
inX: Data for classification (test set)
dataSet: Data for training (training set)
labels: Classification label
k: kNN Algorithm parameters, select the algorithm with the smallest distance k Point
returns:
Classification results
modify:
2018-03-08
"""
def createDataSet():
group = np.array([[1, 101], [5, 89], [108, 0], [108, 5]])
labels = ['affectional film','affectional film', 'action movie', 'action movie']
return group, labels
def classify0(inX,dataSet,labels,k):
#numpy function shape[0] returns the number of rows of dataSet
dataSetSize=dataSet.shape[0]
#Repeat inX once (horizontally) in the direction of column vector and inX times (vertically) in the direction of row vector
#numpy.tile([0,0],(1,1))#Repeat [0,0] once in the column direction and once in the row > > > array ([[0,0]])
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#Square of two-dimensional feature subtraction
sqDiffMat=diffMat**2
#sum() adds all elements, sum(0) columns and sum(1) rows
sqDistances=sqDiffMat.sum(axis=1)
#Square off and calculate the distance
distances=sqDistances**0.5
#Returns the index value of the elements in distances sorted from small to large
sortedDistIndices=distances.argsort()
#Define a dictionary that records the number of times of a category
classCount={}
for i in range(k):
#Take out the category of the first k elements
voteIlabel=labels[sortedDistIndices[i]]
#Calculate the number of categories
# dict.get(key,default=None), the get() method of the dictionary, returns the value of the specified key. If the value is not in the dictionary, it returns the default value.
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
#key=operator.items(1) sort by dictionary value
#key=operator.items(0) is sorted according to the key value of the dictionary
#reverse descending sort dictionary
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#The category that returns the most times, that is, the category to be classified
return sortedClassCount[0][0]
if __name__ == '__main__':
#Create dataset
group, labels = createDataSet()
#Test set
test = [101,20]
#kNN classification
test_class = classify0(test, group, labels, 3)
#Print classification results
print(test_class)
Output:
action movie
Seeing this, someone may ask, "under what circumstances can the classifier make mistakes?" Or "is the answer always right?" The answer is No
The classifier will not get 100% correct results. We can use a variety of methods to detect the accuracy of the classifier. In addition, the performance of classifier will also be affected by many factors, such as classifier setting and data set. The performance of different algorithms on different data sets may be completely different.
In order to test the effect of the classifier, we can use the data with known answers. Of course, the answers cannot be told to the classifier to test whether the results given by the classifier meet the expected results. Through a large number of test data, we can get the error rate of the classifier - the number of times the classifier gives wrong results divided by the total number of test executions.
Error rate is a common evaluation method, which is mainly used to evaluate the execution effect of classifier on a data set. The error rate of the perfect classifier is 0, and the error rate of the worst classifier is 1.0. At the same time, it is not difficult for us to find that the k-nearest neighbor algorithm does not train the data, and directly uses the unknown data to compare with the known data to get the results. Therefore, it can be said that the K-neighbor algorithm does not have an explicit learning process.