Requirement: count the total number of occurrences of each word in a given stack of text files
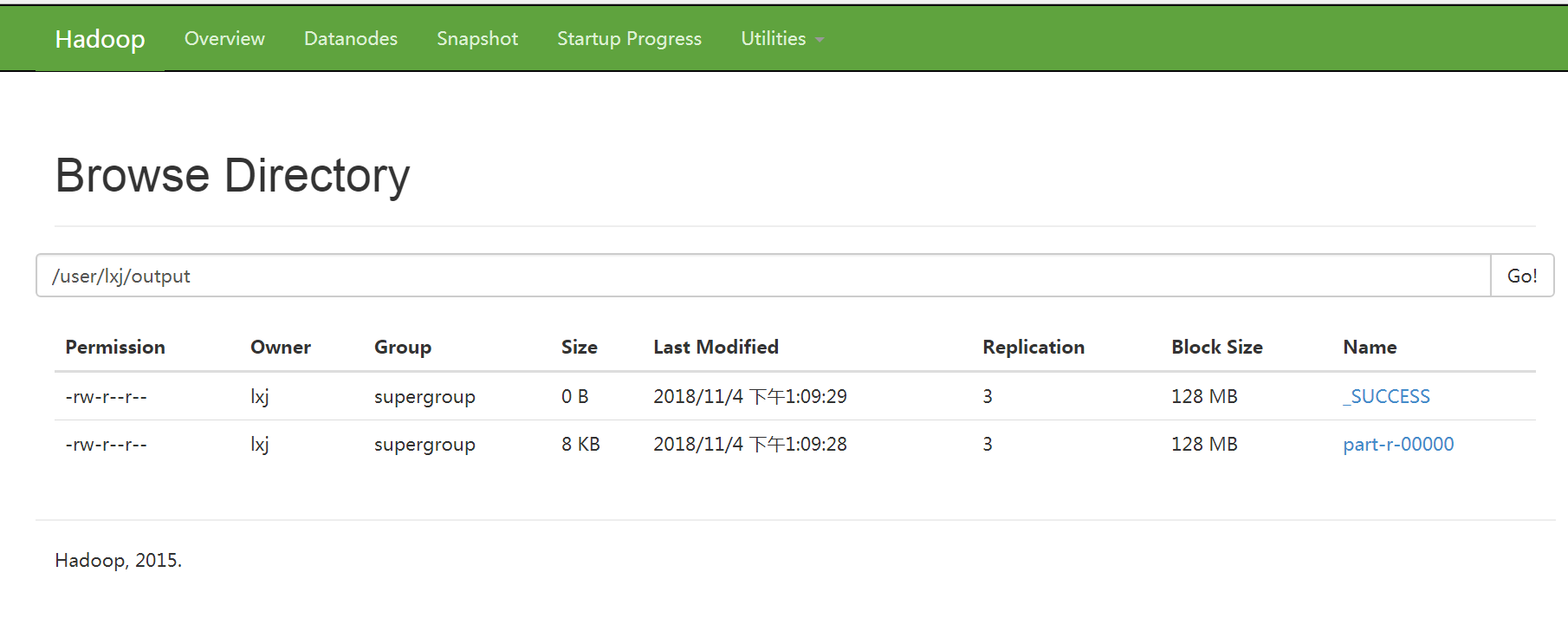
As shown in the figure below is the analysis chart of MapReduce statistical WordCount:
The map stage reads the data from the file, the line number is the key, and the read value of each line is the value. Each key/value pair is output to the reduce stage. In the reduce stage, all the results of the map stage are reduced, and each same key executes the reduce method once.
The code is as follows:
WordCountMapper.java
package com.lxj.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//Map stage: input the line number as the key, and read the value of each line as the value
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text k = new Text();
private IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context) throws java.io.IOException, java.lang.InterruptedException {
// 1 split the lines read in each time
String line = value.toString();
// Convert 2 to String type for segmentation
String[] words = line.split(" ");
// 3 write out each key value pair
for (String word : words) {
String trim = word.trim();
if(!" ".equals(trim)){
k.set(trim);
// The 4 map phase splits the words, not merges them, so the fixed value is 1
context.write(k, v);
}
}
}
}
WordCountReducer.java
package com.lxj.wc;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//In the Reduce phase, the output of the Map phase is taken as the input data of the Reduce phase
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//The same key has and only executes the reduce method once
@Override
protected void reduce(Text text, Iterable<IntWritable> iterable, Context context) throws java.io.IOException, java.lang.InterruptedException {
// 1. Sum the value s of the same key in the map phase
int sum = 0;
Iterator<IntWritable> iterator = iterable.iterator();
while(iterator.hasNext()){
sum += iterator.next().get();
}
if(!text.toString().trim().equals("")){
//Output results
context.write(text, new IntWritable(sum));
}
}
}
WordCountDriver.java
package com.lxj.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//Driver class, associating map with reduce
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. Get configuration information
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2. Set the location path to load the jar, and pass it directly to the current Class object
job.setJarByClass(WordCountDriver.class);
// 3. Set map and reduce classes
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4. Set the output type of map
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5. Set the final output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6. Set input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7. submission
boolean result = job.waitForCompletion(true);
System.exit( result ? 0 : 1);
}
}
Prepare the following documents:
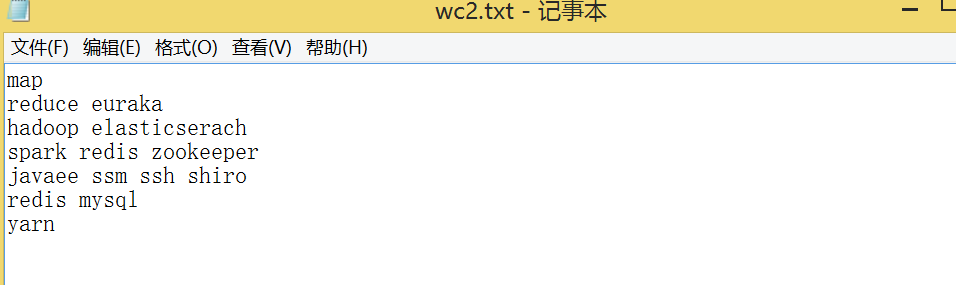

The test results of a local method are as follows:
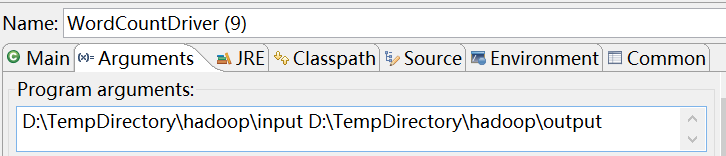
Astonished 1 At 1 But 1 Fate 1 He 2 Immediately 1 Many 1 O 1 Phoenix 1 a 1 admired, 1 again 1 ages 1 al 1 amongst 1 an 1 and 5 animals, 1 appeared 1 around 1 at 1 away 1 beasts, 1 beauty, 1 been 2 began 1 being 1 birds 1 both 1 broke 1 compassion, 1 different 1 elasticserach 1 euraka 1 eye 1 flocked 1 friend 1 great 1 had 2 hadoop 1 hard 1 has 2 he 1 him 3 his 1 in 2 into 1 javaee 1 kinds 1 know 1 last 1 look 1 loved 1 loving 1 map 1 mate 1 most 1 mysql 1 neither 1 never 1 nor 1 now 1 of 4 or 1 out 1 passed 1 phoenix 1 pleasure 1 praise. 1 prudent 1 redis 2 reduce 1 seen 1 shiro 1 short 1 sighed 1 since 1 spark 1 ssh 1 ssm 1 stared 1 the 5 them 1 they 2 time, 1 to 2 unhappy 1 upon 1 will 1 wisest 1 with 1 world. 1 yarn 1 zookeeper 1
2. The Hadoop cluster runs as follows:
First, make the project into a jar package, then upload it to HDFS for analysis, and execute the following command:

View results after successful execution:

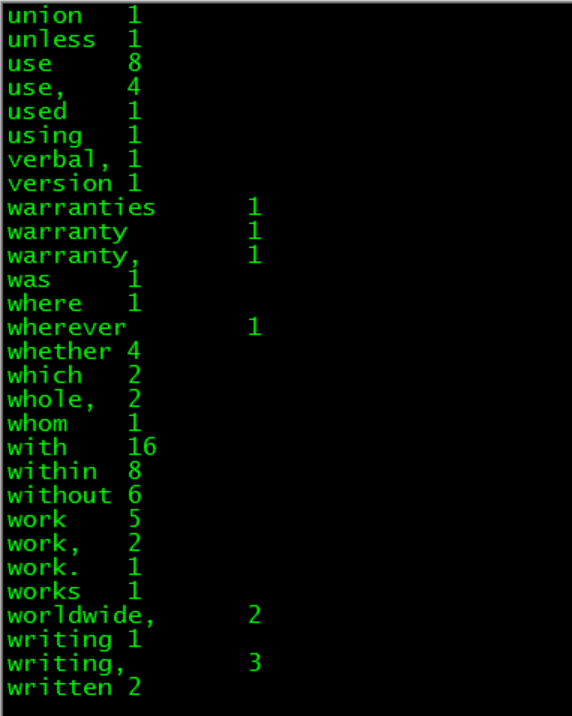
Of course, you can download and view it directly on the web: