Yesterday, I saw an open source project on GitHub, which uses deep learning to detect whether people wear masks. I felt it was quite fun, so I downloaded the trained model and planned to run with the dnn module of OpenCV. However, after forward propagation, the reasoning matrix prob obtained is a 1x5972x2 Mat matrix, which is different from the reasoning results encountered before. After the attempt of various decoding methods, it still failed to decode the reasoning result correctly. And no relevant content can be found in the online search. Almost no netizens use OpenCV to run this model. They basically use the framework of deep learning. This is very helpless. Now we can only put this model aside temporarily and study how to decode its reasoning results at other times.
However, I still want to try to test whether I wear a mask or not, because I was aroused by curiosity, and then because the decoding of the pre training model of the open source project failed, in a rage, I don't want to try one myself. Because I don't have a deep understanding of deep learning, my idea is to use the dnn module of OpenCV for face detection and location, and then use the ml module of OpenCV to identify whether to wear a mask.
The first step is to train the classifier we need. I choose the SVM classifier of ml module in OpenCV to train the mask recognition classifier. The code of the training part is as follows:
string positive_path = "D:\\opencv_c++\\opencv_tutorial\\data\\test\\positive\\";
string negative_path = "D:\\opencv_c++\\opencv_tutorial\\data\\test\\negative\\";
vector<string> positive_images_str, negative_images_str;
glob(positive_path, positive_images_str);
glob(negative_path, negative_images_str);
vector<Mat>positive_images, negative_images;
for (int i = 0; i < positive_images_str.size(); i++)
{
Mat positive_image = imread(positive_images_str[i]);
positive_images.push_back(positive_image);
}
for (int j = 0; j < negative_images_str.size(); j++)
{
Mat negative_image = imread(negative_images_str[j]);
negative_images.push_back(negative_image);
}
string savePath = "face_mask_detection.xml";
trainSVM(positive_images, negative_images, savePath);First, read all training images, including positive sample (with mask) image and negative sample (without mask) image, then package the positive and negative sample sets into vector < mat > type respectively, and pass them into the training function trainSVM(), which is defined in the header file "face_mask.h".
In the training process, we do not fully expand the image for training, but get the HOG feature of each sample image through feature extraction, then calculate the feature descriptor of each HOG feature, and train the SVM classifier through the feature descriptor.
It should be noted that we do not extract and describe the HOG feature of the complete sample image, but extract the face region of the sample image first, and then extract and describe the HOG feature of the extracted face region image and train it.
At the same time, it is also necessary to label the positive and negative sample sets. Positive samples are marked as 1 and negative samples are marked as - 1.
The code is as follows:
for (int i = 0; i < positive_num; i++)
{
Mat positive_face;
Rect positive_faceBox;
if (faceDetected(positive_images[i], positive_face, positive_faceBox))
{
resize(positive_face, positive_face, Size(64, 128));
Mat gray;
cvtColor(positive_face, gray, COLOR_BGR2GRAY);
vector<float> descriptor;
hog_train->compute(gray, descriptor);
train_descriptors.push_back(descriptor);
labels.push_back(1);
}
}
for (int j = 0; j < negative_num; j++)
{
Mat negative_face;
Rect negative_faceBox;
if (faceDetected(negative_images[j], negative_face, negative_faceBox))
{
resize(negative_face, negative_face, Size(64, 128));
Mat gray;
cvtColor(negative_face, gray, COLOR_BGR2GRAY);
vector<float> descriptor;
hog_train->compute(gray, descriptor);
train_descriptors.push_back(descriptor);
labels.push_back(-1);
}
}
int width = train_descriptors[0].size();
int height = train_descriptors.size();
Mat train_data = Mat::zeros(Size(width, height), CV_32F);
for (int r = 0; r < height; r++)
{
for (int c = 0; c < width; c++)
{
train_data.at<float>(r, c) = train_descriptors[r][c];
}
}
auto train_svm = ml::SVM::create();
train_svm->trainAuto(train_data, ml::ROW_SAMPLE, labels);
train_svm->save(path);
hog_train->~HOGDescriptor();
train_svm->clear();The function faceDetected() for face extraction is defined in the header file "face.h". Here we use opencv_face_detector_uint8.pb face detection model.
At this step, the training of SVM classifier for detecting whether to wear mask is realized. The model files obtained from the training are as follows:

Next, we will load the xml file and detect the input image. The function used for detection is FaceMaskDetect(), which is defined in the "face_mask.h" header file.
auto detecModel = ml::SVM::load("face_mask_detection.xml");
Mat test_image = imread("D:/BaiduNetdiskDownload/Face mask detection data set/val/test_00004577.jpg");
FaceMaskDetect(test_image, detecModel);
imshow("test_image", test_image);Here, we have realized the process from training to operation detection. Let's see the effect of operation:
First look at the image without mask. If it is detected that the mask is not worn, the face will be framed in red and marked with red words "Not Face Mask"





If you are wearing a mask, frame your face with a green frame and mark "Face Mask":

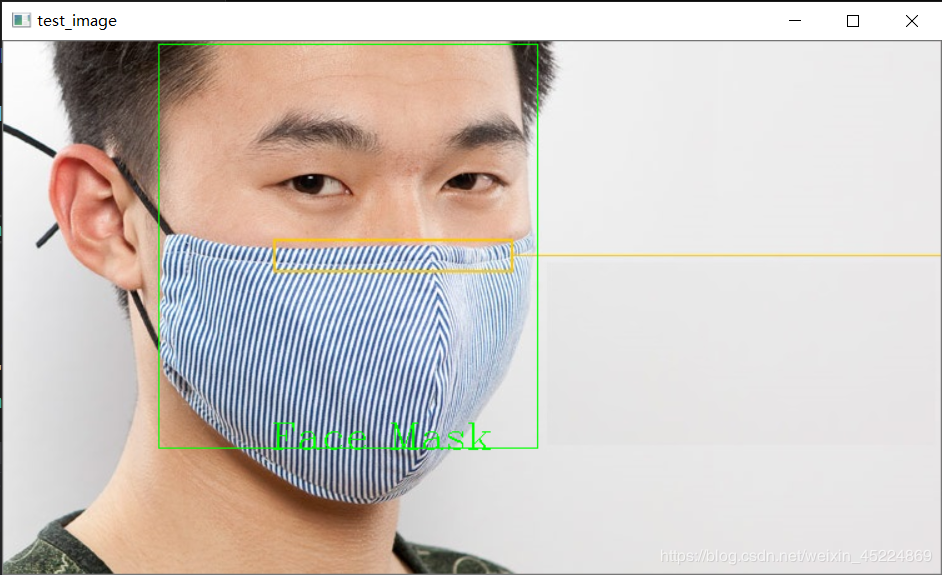

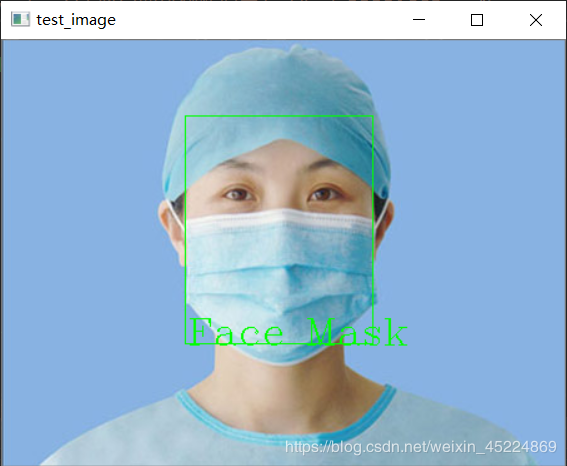
In terms of effect, the test images used are not in the training set, and the success rate of photo recognition of a single face is still OK, but it is certainly not as high as the recognition accuracy of neural network model in open source project. Moreover, when I train here, the ratio of positive and negative samples is about 1:2, and the total sample set is more than 400 training images, which is not worth mentioning compared with the training set of more than 8000 images in the open source project.
However, in the part of face detection, the situation of multiple faces in the same image is not processed, so that when multiple faces appear in one image, only the person with the highest face confidence will be detected wearing a mask, so this part needs to be further optimized.
Of course, it's not interesting to detect only one image. We can also combine cameras to realize real-time detection. The demonstration code is as follows:
VideoCapture capture;
capture.open(0);
if (!capture.isOpened())
{
cout << "can't open camera" << endl;
exit(-1);
}
Mat frame;
while (capture.read(frame))
{
FaceMaskDetect(frame, detecModel);
imshow("test_image", frame);
char ch = waitKey(1);
if (ch == 27)
{
break;
}
}So that's the end of this note. Thank you for reading~
PS: my comments are quite miscellaneous. I have my own experience and knowledge content extracted from online data access, so if there are any similarities, it is purely my tribute to my predecessors. If any predecessors feel that my notes infringe your intellectual property rights, please contact me and I will delete the blog content involved. Thank you!