Author: Lenny MegEngine intern
Brush the shopping App frequently by "planting grass", fingerprint identification is faster and faster than once, and the beauty camera get s your favorite one click P-map
On smart phones, personalized recommendation using AI algorithm can greatly improve the user experience. However, in order for AI to understand you better, many applications need to model train user data. Behind restaurant recommendation is the recommendation system, fingerprint identification uses past data to automatically optimize the model, and behind smart beauty camera is the analysis of user behavior.
In this case, how can AI algorithm understand user preferences more accurately and ensure user data security? An intuitive idea is to train the model directly on the mobile phone, which can not only avoid the risk of leakage caused by data transmission, but also continuously improve the performance of the model. MegEngine It can be trained on both GPU and mobile devices. Can the two be combined to train on mobile devices? The answer is yes.
Next, let's take a look at how to conduct end-to-end training in MegEngine~
It is still the old rule. Take Mnist data set for test, and LeNet is selected as the model. In our internal testing, the code on the call end training interface can be directly run on the mobile phone, and the effect is completely aligned with the general Python training interface.
Reviewing what we did when establishing the training process in the framework of pytoch and Tensorflow, we can find that it mainly includes:
- Build model;
- Add Loss and Optimizer;
- Import dataset;
- Set learning rate, number of training rounds and other super parameters and train.
Build model
In fact, the construction of the model is a process of constructing the forward calculation graph. The output corresponding to the input is obtained by calling the operator.
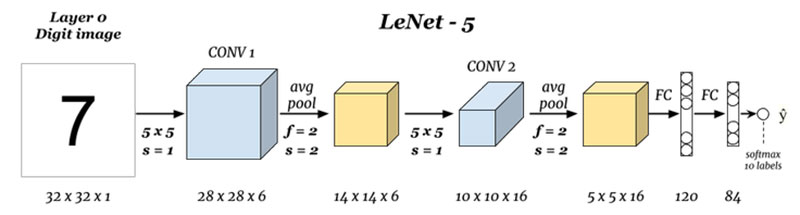
It is easy to know from the model structure of LeNet that we need to call quadratic convolution operator, quadratic pooling operator, quadratic Flatten operator, quadratic matrix multiplication operator and several operators of four operations.
In MegEngine, the operator is only a "black box" responsible for performing operations. We need to set the parameters in advance, and then "feed" the parameters and data to the operator. As shown in the figure below, the data is always transferred layer by layer, and its Layout will be calculated automatically, and the parameters need to be set manually.

For the feedforward neural network of LeNet, we only need to link the output of the previous operator and the next set of parameters to the next operator to connect the calculation process.
Because the code here is lengthy, a simplified code example is given here. It can be seen that the writing method is not different from calling the general Python interface, or even one-to-one correspondence. For example, OPR:: Revolution corresponds to NN Conv2d, opr::MatrixMul corresponds to NN Linear, but because C + + language features are different from python, there will be some differences in writing.
SymbolVar symbol_input =
opr::Host2DeviceCopy::make(*graph, m_input); // Initialize input data
SymbolVar symbol_conv =
opr::Convolution::make(symbol_input, symbol_conv_weight, conv_param); // symbol_ Weights [0] is the convolution filter weight set in advance
symbol_conv = opr::relu(symbol_conv + symbol_conv_bias); //Activated after biasing
SymbolVar symbol_maxpool =
opr::Pooling::make(symbol_conv, pooling_param)
.reshape({batchsize, fc_shape[0]}); //Flatten after pooling
SymbolVar symbol_fc =
opr::MatrixMul::make(symbol_maxpool, symbol_fc_weight) +
symbol_fc_bias;
symbol_fc1= opr::relu(symbol_fc); //The full connection layer is constructed by matrix multiplication
In this way, we can combine operators, data and parameters to construct the forward calculation graph we need.
Call Loss and Optimizer
Now, Loss and Optimizer have been encapsulated in MegEngine at the C + + level. Let's take the cross entropy Loss in Mnist dataset training and SGD Optimizer as examples.
In MegEngine, all reasoning and training are actually carried out on a calculation diagram, while Loss and Optimizer essentially encapsulate part of the tasks of constructing the calculation diagram for users to call directly without repeating "building wheels". For example, in the most familiar mean square error, we actually call the subtraction operator once and then the power operator again.
After understanding this, we just need to continue to the previous step, call the Loss API and splice it after our model output. The code is very simple and very similar to the training in pytoch.
CrossEntopyLoss loss_func; // Firstly, an example of loss function is defined, and the cross entropy loss is selected here SymbolVar symbol_loss = loss_func(symbol_fc, symbol_label); // Take the model output and label as inputs and call the loss function
At this time, we get the symbol_loss is the loss during our training.
Similar to calling the Loss API, we can easily call the optimizer to insert into the existing calculation graph.
SGD optimizer = SGD(0.01f, 5e-4f, .9f); //Instantiate the SGD optimizer and set parameters
SymbolVarArray symbol_updates =
optimizer.make_multiple(symbol_weights, symbol_grads, graph); // Insert Optimizer into the calculation diagram
In this way, after back propagation, the gradient is processed by Optimizer and the model parameters are updated.
Import dataset
Since the model parameters are manually defined, we will certainly notice a problem: how can our data set be transformed into the data involved in the calculation of the calculation diagram?
Of course, MegEngine has prepared methods, which can inherit an interface and implement get_item and size methods, and input the instance of this class into the DataLoader, then you can complete the conversion of the dataset~
The interface we want to inherit is defined as follows. Eh, the little friends who usually use pytoch here must have smelled the familiar smell.
class IDataView {
public:
virtual DataPair get_item(int idx) = 0;
virtual size_t size() = 0;
virtual ~IDataView() = default;
};
Let's go to the previous example. Here we only show how to inherit the interface and get the DataLoader. If you are interested in seeing the specific implementation, you can pay attention to MegEngine~
class MnistDataset : public IDataView {
public:
MnistDataset(std::string dir_name); // Initialize the dataset and specify the storage path of the dataset
void load_data(Mode mode, std::string dir_name); //Read the Mnist dataset and save it in the dataset list.
DataPair get_item(int idx); // Implementation interface
size_t size(); //Implementation interface
protected:
std::vector<DataPair> dataset;
};
// Instantiate the dataset class defined above
auto train_dataset = std::make_shared<MnistDataset>(dataset_dir);
// Use this instance to get the corresponding DataLoader
auto train_dataloader =
DataLoader(train_dataset, batchsize);
train
Now that all steps have been completed, the next thing is to make the training run ~ here is also a simple pseudo code example. Uh... Here, using Pytorch's little buddy, I will feel very familiar with it, that is to recycle every epoch, and each epoch will circulate data and labels in different groups. The difference is that we do not need to call Loss and Optimizer in the loop, because the completed calculation chart has been constructed before. We only need to execute the compiled calculation diagram.
func = graph->compile(); // Compile calculation diagram
for (int epoch = 0; epoch < epochs; epoch++) {
for (size_t i = 0; i < train_dataloader.size(); i++) {
data = train_dataloader.next(); // Get data from DataLoader
func->execute(); // Execution calculation diagram
}
}
Through my example (x), I found that training on the end can achieve the same accuracy as training with Python training interface of Pytorch and MegEngine ~ here, our verification is successful!
After seeing this, I believe you have learned how to conduct end-to-end training in MegEngine. What kind of interfaces are Loss and Optimizer?
Encapsulation of Loss and Optimizer
Sometimes, we need to encapsulate the Loss and Optimizer we need. At this time, it is more important to understand the API of Loss and Optimizer.
The interface of Loss is very simple, which can be summarized as follows:
class ILoss {
public:
virtual mgb::SymbolVar operator()(mgb::SymbolVar symbol_pred,
mgb::SymbolVar symol_label) = 0;
virtual ~ILoss() = default;
};
As long as you can input two calculation nodes: the predicted value and the tag value, you can output one calculation node correspondingly. Careful partners here may have noticed that SymbolVar is the class used when building the forward calculation graph. This is why the essence of Loss is to help you insert a calculation process into the calculation graph.
The Optimizer interface is also very concise, which can be summarized as the following code:
class IOptimizer {
public:
virtual mgb::SymbolVarArray make_multiple(
mgb::SymbolVarArray symbol_weights,
mgb::SymbolVarArray symbol_grads,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual mgb::SymbolVar make(
mgb::SymbolVar symbol_weight, mgb::SymbolVar symbol_grad,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual ~IOptimizer() = default;
};
class Optimizer : public IOptimizer {
public:
mgb::SymbolVarArray make_multiple(
mgb::SymbolVarArray symbol_weights,
mgb::SymbolVarArray symbol_grads,
std::shared_ptr<mgb::cg::ComputingGraph> graph); // Note that this is not a pure virtual function
virtual mgb::SymbolVar make(
mgb::SymbolVar symbol_weight, mgb::SymbolVar symbol_grad,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual ~Optimizer() = default;
};
Similar to Loss, here we also input a calculation node, and then output a calculation node accordingly. It is worth noting that Optimizer is divided into two parts, one is pure interface IOptimizer, and the other is an abstract class Optimizer that inherits this interface. In fact, in many cases, we are used to using an array or list to store our parameters and obtained gradients. At this time, due to the limitation of static language, this situation cannot be directly merged into the case of single input, but in fact, as long as we implement the Make interface, the case that the input is an array will be solved naturally. However, considering the idea that interfaces and classes should be separated, they are separated here and become an interface and an abstract class, and the abstract class contains the default implementation of array input (make_multiple interface).
If you need to add a custom Loss or Optimizer, you only need to inherit the corresponding interface or abstract class and implement it.
For example, the implementation of mean square error MSE:
mgb::SymbolVar MSELoss::operator()(
mgb::SymbolVar symbol_pred, mgb::SymbolVar symol_label) {
return opr::pow(symbol_pred - symol_label, symbol_pred.make_scalar(2));
}
Summary and Prospect
See here, maybe you will be full of curiosity, maybe you will despise
As a direction still under exploration, end-to-end training can not be compared with the existing training and reasoning framework, but the function of end-to-end training provided by MegEngine will provide you with a choice when you need it. In such an era when mobile phones are increasingly occupying people's lives and people's demand for service quality is constantly improving, it must be useful for end-to-end training.
The main problems of current MegEngine end training and possible improvements in the next step are:
- At present, the construction process of the model is relatively primitive, which can further encapsulate similar NN Module.
- Sometimes you already have a weight file with calculation chart information in your hand. Instead of building a calculation chart again, you can directly read the existing calculation chart and insert it into the training process, which can provide a similar API
- Reading data on the C + + side will be troublesome
You are welcome to try to use MegEngine to build an end-to-end training application. You are also welcome to point out the shortcomings of the current end-to-end training in MegEngine so that we can improve it. You can also raise PR to solve the problem together~
MegEngine cpp Training Example
GitHub: Kuangshi Tianyuan MegEngine
Welcome to megaengine technical exchange QQ group: 1029741705