Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
1 Overview
1.1 basic concepts
1.1.1 Topic
By classifying messages through Topic mechanism, we can think that each Topic is a queue.
1.1.2 Partition
Each Topic can have multiple partitions, which are mainly designed to improve concurrency. Under the same Topic, different partitions can receive messages concurrently and allow consumers to pull messages concurrently. As many partitions as there are, there is as much concurrency.
On the Kafka server, partitions exist in the form of file directories. In each partition directory, Kafka will split the partition into multiple logsegments according to the configured size and configuration cycle. Each segment is composed of three parts:
- Log file:*.log - Displacement index file:*.index - Time index file:*.timeindex
Where * log is used to store the data content of the message itself, * index stores the location of the message in the file (including the logical offset and physical storage offset of the message), * timeindex stores the mapping relationship between the message creation time and the corresponding logical address.
The partition is split into multiple segments to control the size of the storage file. It can be easily mapped to memory through the operating system mmap mechanism to improve the efficiency of writing and reading. Another advantage is that when the system wants to clear the expired data, it can directly delete the expired segment files.
If the location information of each message should be saved in the index, the size of the index file itself can easily become very large. Therefore, Kafka designs the index as a sparse index to reduce the size of the index file.
1.1.3 Broker agent
Messages saved in a cluster are called Kafka. Each server in the cluster is a Broker.
1.1.4 Replication replicas
Number of redundant messages. The number of brokers in the cluster cannot be exceeded.
1.2 basic operation
1.2.1 Topic related
# Create Topic # --Topic topic name avoid using [] And [.] number # --Number of replication factor replicas (cannot exceed the number of broker nodes) # --Partitions number of partitions (concurrent) ./bin/kafka-topics.sh --create \ --topic UserDataQueue \ --replication-factor 3 \ --partitions 5 \ --bootstrap-server localhost:9092,localhost:9093,localhost:9094 # View Topic ./bin/kafka-topics.sh --list \ --bootstrap-server localhost:9092,localhost:9093,localhost:9094 # Modify Topic # Delete Topic
1.2.2 Message related
# send message # --Topic specifies the target topic ./bin/kafka-console-producer.sh \ --topic UserDataQueue \ --bootstrap-server localhost:9092,localhost:9093,localhost:9094 # Pull message # --From beginning (get the full amount of existing data) ./bin/kafka-console-consumer.sh \ --topic UserDataQueue \ --bootstrap-server localhost:9092,localhost:9093,localhost:9094 \ --from-beginning
2. Cluster configuration
Kafka cluster depends on Zookeeper.
2.1 Zookeeper configuration and startup
# Parameters to be modified # the directory where the snapshot is stored. dataDir=/kafka/zkdata # the port at which the clients will connect clientPort=2182
# start-up ./bin/zookeeper-server-start.sh -daemon /kafka/zookeeper.properties
2.2 Kafka configuration and startup
# Parameters to be modified # The id of the broker. This must be set to a unique integer for each broker. broker.id=1 # ID must be unique in the same cluster # The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://localhost:9092 # the port number of the same host cannot be the same # A comma separated list of directories under which to store log files log.dirs=/kafka/data01 # The log storage directory needs to be isolated # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2182 # For Zookeeper connection address, see 2.1 zk configuration
# Kafka start # broker-1 ./bin/kafka-server-start.sh -daemon /kafka/server01.properties # broker-2 ./bin/kafka-server-start.sh -daemon /kafka/server02.properties # broker-3 ./bin/kafka-server-start.sh -daemon /kafka/server03.properties
2.3 Zookeeper visualization
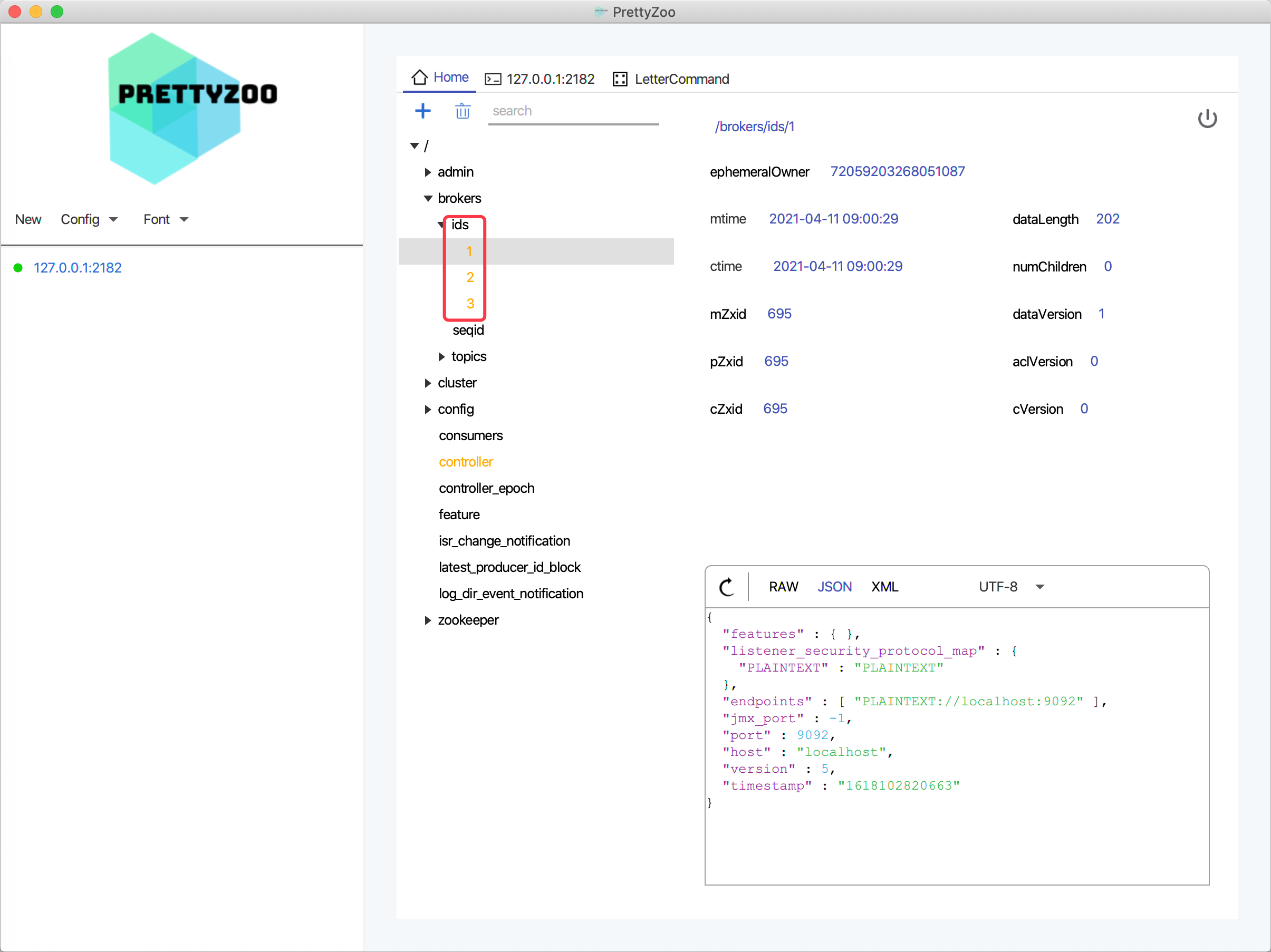
PrettyZoo It is a Zookeeper graphical management client based on Apache cursor and JavaFX.
As can be seen from the figure below, the three brokers in the cluster are started normally.
2.4 Kafka visualization and monitoring
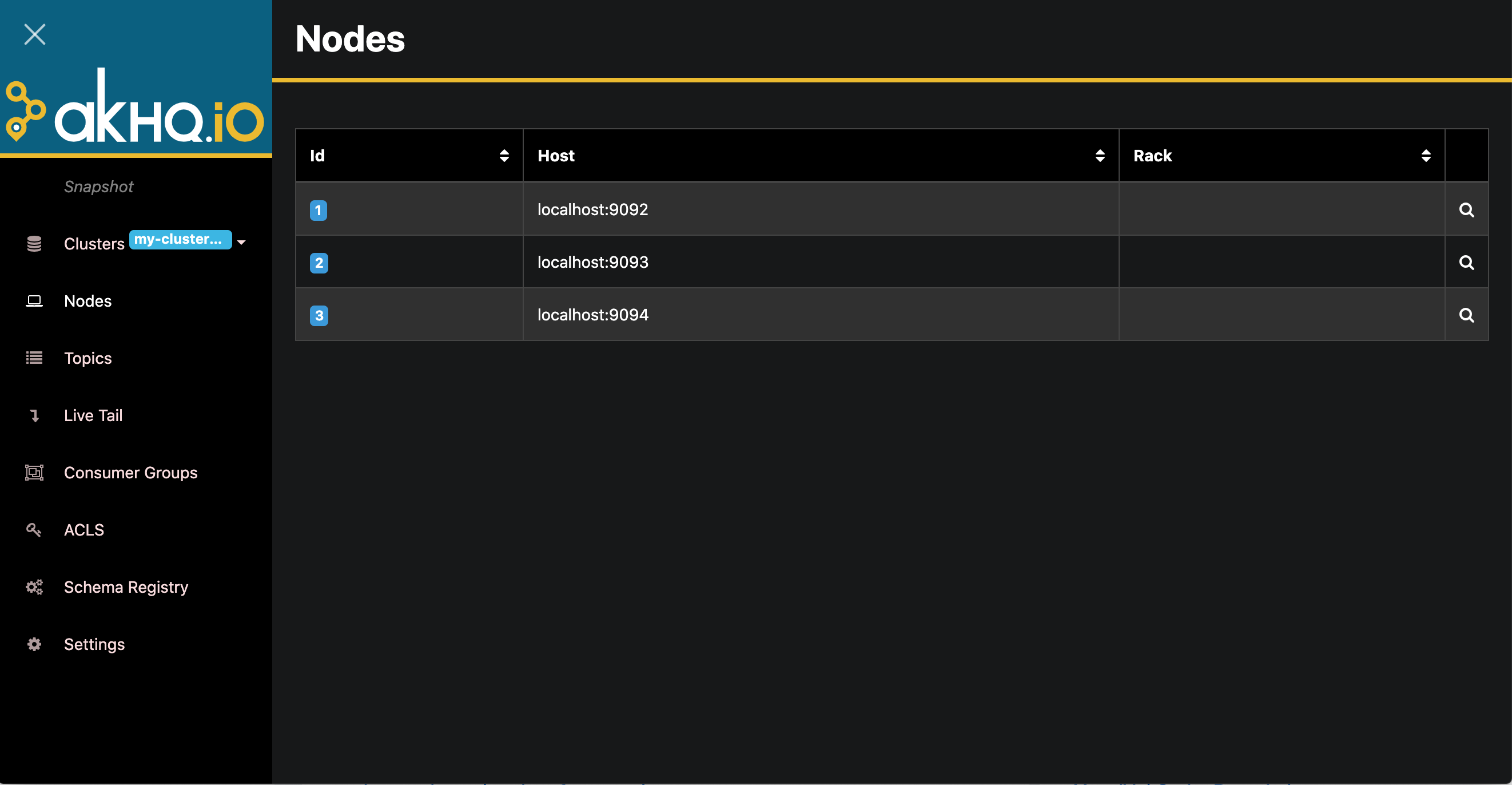
2.4.1 AKHQ
Kafka visualization system for managing Topic, Topic message, consumer group, etc., relevant documents: https://akhq.io/
2.4.2 Kafka Eagle
A simple and efficient monitoring system. Related documents: http://www.kafka-eagle.org/index.html
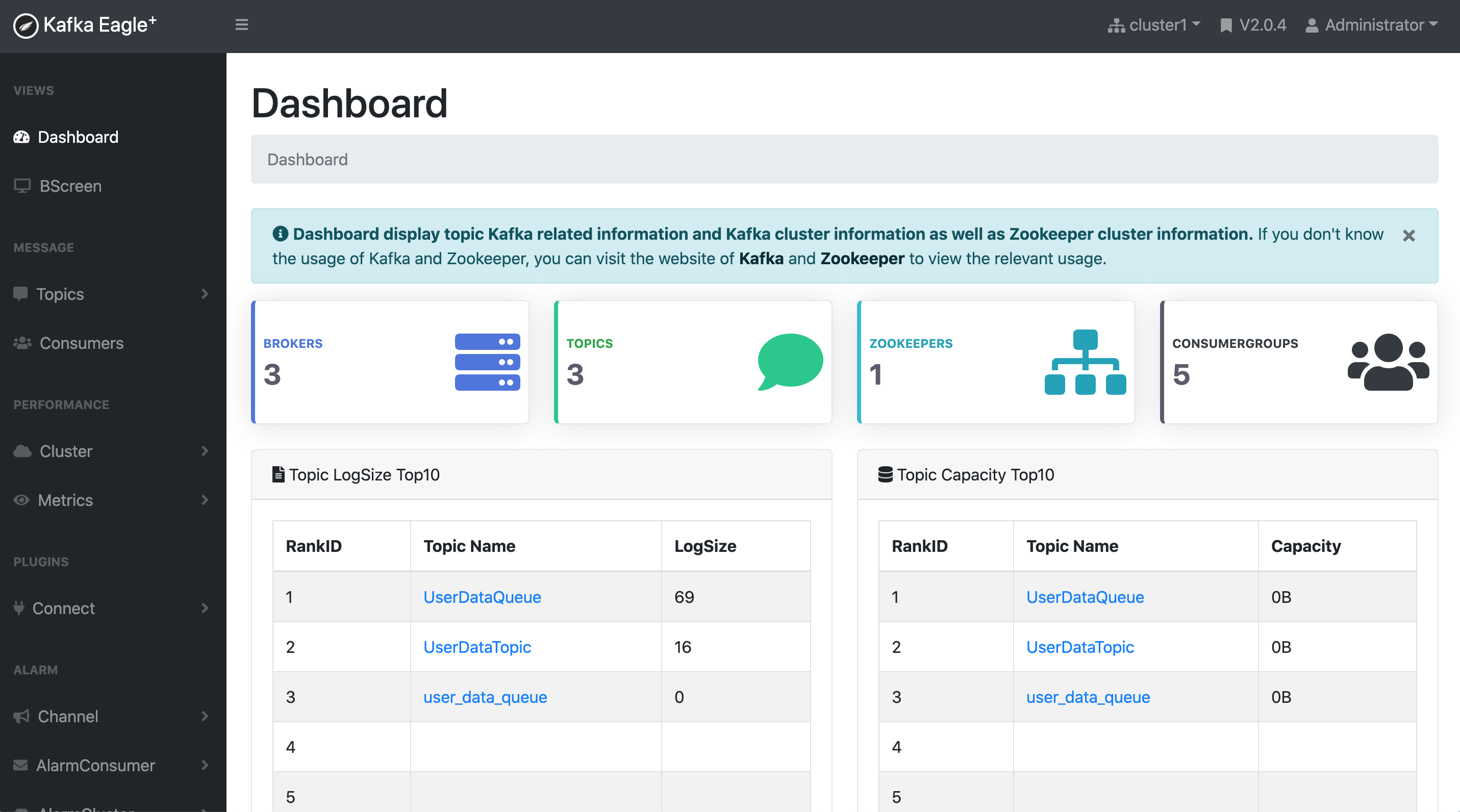
Kafka Eagle has its own monitoring screen.
3 integration with Spring Boot
Spring Boot version: 2.4.4.
3.1 Spring Boot
3.1.1 add dependency
implementation 'org.springframework.kafka:spring-kafka'
3.1.2 configuration file
spring:
kafka:
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094
producer:
client-id: kfk-demo
retries: 3
3.1.3 message sending
@RestController
public class IndexController {
@Autowired
KafkaTemplate<Object, Object> kafkaTemplate;
@GetMapping
public String index() {
int rdm = new Random().nextInt(1000);
kafkaTemplate.send("UserDataQueue", new UserData("", rdm));
return "hello world";
}
@GetMapping("index2")
public String index2() {
// Send string mode
kafkaTemplate.send("UserDataTopic", new Gson().toJson(new UserData("apple", 23)));
return "ok";
}
}
3.1.4 message reception
@Component
@KafkaListener(
id = "kfk-demo-userdata",
topics = {"UserDataQueue"},
groupId = "kfk-demo-group",
clientIdPrefix = "kfk-demo-client")
public class KfkListener {
@KafkaHandler
public void process(@Payload UserData ud,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(String.format("topic: %s, partition: %d, userData: %s", topic, partition, ud));
}
@KafkaHandler(isDefault = true)
public void process(Object obj) {
System.out.println(obj);
}
}
// Receive string mode
@Slf4j
@Component
@KafkaListener(id = "kfk-demo2", topics = {"UserDataTopic"})
public class KfkUserDataTopicListener {
@KafkaHandler
public void process(String userDataStr) {
UserData userData = new Gson().fromJson(userDataStr, UserData.class);
log.info("username: {}, age: {}", userData.getUsername(), userData.getAge());
}
}
3.1.5 automatic creation of topic
@Configuration
public class KafkaConfig {
@Bean
public NewTopic userDataTopic() {
return new NewTopic("UserDataTopic", 3, (short) 1);
}
}