Task: extract medical records. Some medical records exist in pdf books, but these PDFs are in picture format. These contents need to be converted into text content.
Idea: convert the pdf file into a single picture set, and then ocr recognize the single picture, and splice the recognized text.
Use pypdf2 module to read pdf and binary content, and use wand module to convert a page into a picture and save it.
1 read pdf and convert it to picture
Install pypdf2 package.
pip install pypdf2
Install python package: wand
pip install wand
wand's documents: https://docs.wand-py.org/
Upper Code:
import io
from wand.image import Image
from wand.color import Color
from PyPDF2 import PdfFileReader, PdfFileWriter
import json
memo = {}
# Read pdf file with PdfFileReader of PyPDF2
def getPdfReader(filename):
reader = memo.get(filename, None)
if reader is None:
reader = PdfFileReader(filename, strict=False)
memo[filename] = reader
return reader
# Convert pdf pages with page numbers into picture format
def _run_convert(filename, page, res=120):
idx = page + 1
pdfile = getPdfReader(filename)
pageObj = pdfile.getPage(page) # page starts with 0
dst_pdf = PdfFileWriter()
dst_pdf.addPage(pageObj)
pdf_bytes = io.BytesIO()
dst_pdf.write(pdf_bytes)
pdf_bytes.seek(0)
img = Image(file=pdf_bytes, resolution=res)
img.format = 'png'
img.compression_quality = 100
img.background_color = Color("white")
img_path = '{}{}.png'.format(filename[:filename.rindex('.')], idx)
img.save(filename=img_path)
img.destroy()An error will be reported after execution, and ImageMagick is missing.
Installing ImageMagick
ImageMagick is a free and open source image editing software. It can be used from the command line or programmed through C/C + +, Perl, Java, PHP, Python or Ruby call library. ImageMagic's main focus is on performance, reducing bug s and providing stable API and ABI.
Download address: https://imagemagick.org/scrip...
For the use method, refer to: https://www.cnblogs.com/Renyi...
After that, continue to report errors and lack another software Ghostscript.
wand.exceptions.DelegateError: FailedToExecuteCommand `"gswin64c.exe" -q -dQUIET -dSAFER -dBATCH -dNOPAUSE -dNOPROMPT -dMaxBitmap=500000000 -dAlignToPixels=0 -dGridFitTT=2 "-sDEVICE=pngalpha" -dTextAlphaBits=4 -dGraphicsAlphaBits=4 "-r120x120" -dPrinted=false "-sOutputFile=C:/Users/ADMINI~1/AppData/Local/Temp/magick-ZsQSfEM-CFt6Gr4NZ7mUFFR2UbaYvaQr%d" "-fC:/Users/ADMINI~1/AppData/Local/Temp/magick-eT1ogBLBCjx3Tm4r2jidCDxbn3jmkZw6" "-fC:/Users/ADMINI~1/AppData/Local/Temp/magick-UaYBnaqm--_f0Gm6CSzMe8LnumhQQ16A"' (ϵͳ�Ҳ���ָ�����ļ��� ) @ error/delegate.c/ExternalDelegateCommand/516
It indicates that there is no ghostscript software in the system, so ghostscript needs to be installed. Ghostscript is a set of free software compiled based on Adobe, PostScript and page description language of portable document format (PDF). Ghostscript is a basic part of ImageMagick.
Download address: https://ghostscript.com/relea...
You can download Ghostscript 9.55.0 for Windows (64 bit).
At this point, the picture can be generated.
2 call Baidu intelligent cloud recognition text
First of all, you need to have a baidu account to register. After you have an account, you also need to create an "application".
open https://cloud.baidu.com/produ... , select "general scene character recognition" under "product" - "artificial intelligence" - "OCR character recognition".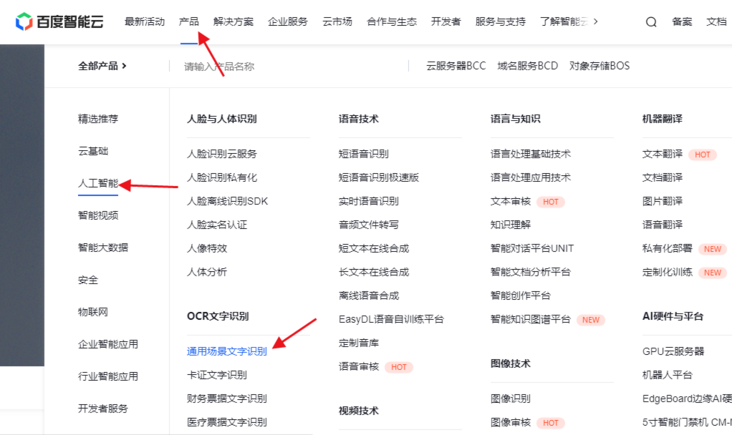
Then, click "use now" in the figure below.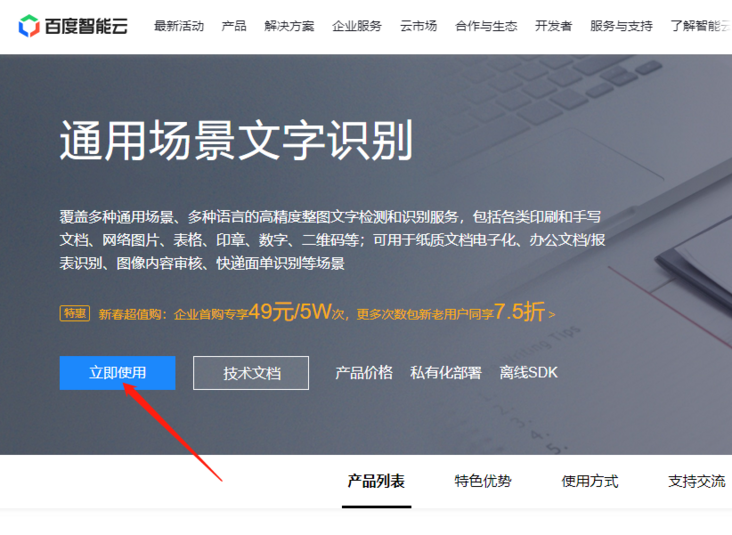
Then click "create application" in the figure below.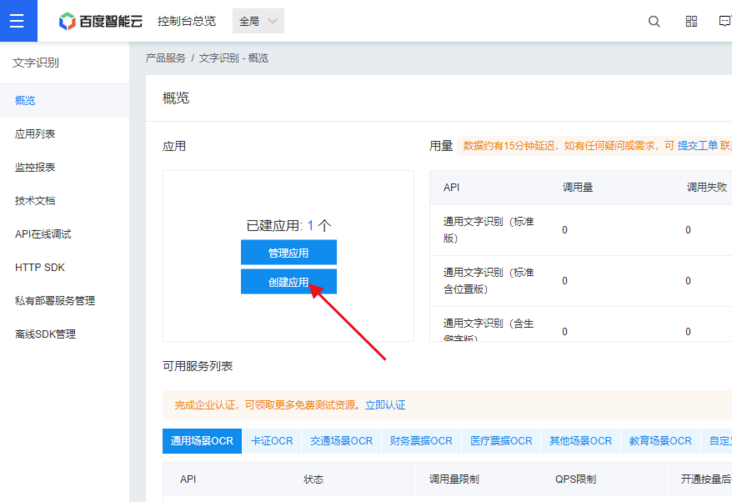
After filling in the information, an application will be created. What I create is "medical record recognition".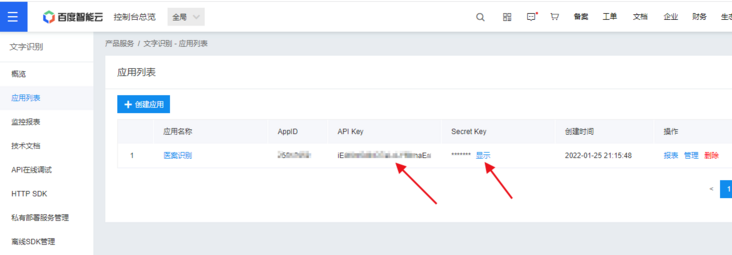
In the figure above, APIKey and Secret Key are what we need to use next.
Upper Code:
def ocr_baidu(filename, access_token):
# encoding:utf-8
'''
Universal character recognition
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# Open picture file in binary mode
f = open(filename, 'rb')
img = base64.b64encode(f.read())
params = {"image": img}
# access_token = '[token obtained by calling authentication interface]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
# print(response.json())
for words in response.json().get("words_result"):
# # print(words.get("words"))
print(words)
return response.json().get("words_result")
else:
return NoneThe final result is a list, which contains a dictionary with words as key, as shown in the following figure:
3 merge text
For example, the "writing instructions" should be the title, and the second to third value values should be combined into one paragraph. The best method should be to use nlp technology for semantic recognition. Here, we just do the character discrimination, which is not very accurate.
Upper Code:
def is_ChineseMarks(char):
if char == ". " or char == "?" or char == "!" or char == """ or char == ": ":
return True
else:
return False
def merge2txt(words_list, line_max_num=26, title_max_num=10):
'''
{'words': 'Preparation instructions'}
{'words': '<Treatise on febrile diseases is a part of treatise on Febrile and miscellaneous diseases written by Zhang Zhongjing, a medical scientist in Han Dynasty.'}
{'words': 'Its principles and methods were followed by doctors of all dynasties,Its prescription is commonly used in ancient and modern clinical practice,Respected as "Fang"'}
{'words': '"The ancestor of books",It is an important volume of Chinese medical classics.'}
1.Title: if words The length of the corresponding string is less than title_max_num,And No. If the number ends, it indicates that it is currently a title.
2.Paragraph: if the last character is. Period, and the length is less than line_max_num,Indicates that the current is a paragraph.
:param words_list:
:param line_max_num:
:param title_max_num:
:return: Merged text content
'''
txt = ""
for i in words_list:
words = str(i.get("words"))
if (not is_ChineseMarks(words[-1])) and len(words) <= title_max_num:
txt += " " # 8 spaces
txt += words
txt += "\n"
elif is_ChineseMarks(words[-1]) and len(words) <= line_max_num:
txt += words
txt += "\n"
# txt += " " # 4 spaces, indicating the beginning of the paragraph
else:
if txt.endswith("\n"):
txt += " "# 4 spaces, indicating the beginning of the paragraph
txt += words
return txtAccess is also required to call Baidu's ocr service_ Token, this access_ The token is generated by the API Key and Secret key used to create the application. You can refer to Baidu's documents: https://ai.baidu.com/ai-doc/R...
get_token() code:
def get_token():
# client_id is the AK and client obtained on the official website_ Secret is the SK obtained on the official website
client_id = "Use yours API Key"
client_secret = "Use yours Secret key"
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret
response = requests.get(host)
# print(host)
# print(response.content)
if response:
access_token = response.json().get("access_token")
return access_tokenUpper main function:
if __name__ == "__main__":
filename = "G:\\data\\attend class;class begins\\Network programming\\2018\\network\\Medical records pdf Transfer text\\Selection and compilation of medical cases of treatise on Febrile Diseases\\Selection and compilation of medical cases of treatise on Febrile Diseases.pdf"
# _run_convert(filename, 3)
access_token = get_token()
filename = "G:\\data\\attend class;class begins\\Network programming\\2018\\network\\Medical records pdf Transfer text\\Selection and compilation of medical cases of treatise on Febrile Diseases\\Selected medical cases of treatise on Febrile Diseases 4.png"
words_list = ocr_baidu(filename, access_token)
txt = merge2txt(words_list,26,10)
print(txt)The results obtained after the merger are as follows:
The original picture is as follows:
It can be seen that there are still some problems in the recognition rate. There is no doubt about Baidu's ocr recognition rate. It should be the best in China. The key problem may be that the pixels may not be enough when pdf generates pictures, resulting in unclear pictures. The solution to this problem will be written in the next article.