Original link: https://www.cnblogs.com/blog5277/p/9334560.html
Original author: blog Garden -- Qugao end and widowhood
See the original link above****************
When you use crawlers at work, you will encounter the following problems:
1. Anti crawler mechanism of the website (verification code, IP sealing, poisoning, js dynamic rendering page)
2. Efficiency and weight removal of distributed crawler
But basically, as long as the data can be opened on the web browser, you can climb it, because we just need to simulate the operation of real people as much as possible. Anti crawler means only increase the cost of crawlers, and it is impossible to eliminate crawlers, because it will hurt many real users by mistake
I won't go into more details. It's a bit off the topic. I still have a lot of ways to go on reptiles (or data mining?). Please refer to the ideas of other great gods
Go further, return to the theme and introduce jsup
Jsup is a Java HTML parser, which is mainly used to parse HTML. Official website Chinese documents
When crawling, when we use a framework such as HttpClient to obtain the web source code, we need to take out the content we want from the web source code,
You can use HTML parsers such as jsoup. It can be implemented very easily.
1. Introduce dependency, maven (Baidu Google "jsoup maven", I recommend the latest one to keep up with the pace of development)
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency>
2. Send get request

3. Send post request

Yes, it's that simple. You don't have to worry about coding or GZIP anymore. If you dare to send it, jsoup can parse it and return it to you
4. Send post with parameters
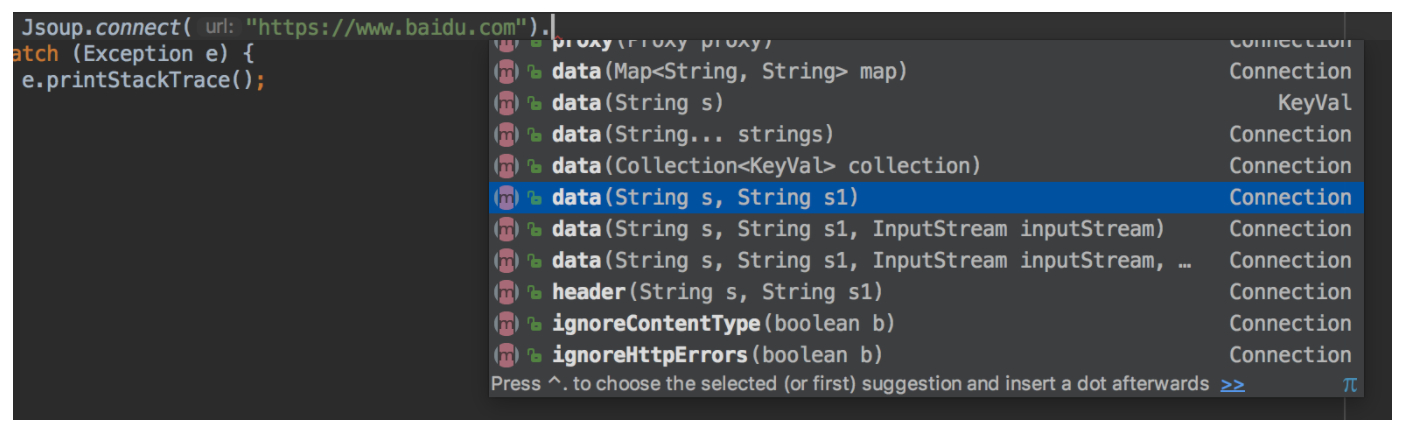
Either more data or a map, and finally. post();
5. Send post with requestbody

6. Set timeout (required for personal suggestion)

7. Set the dynamic proxy IP and write a proxy IP pool to prevent anti crawlers from blocking your IP
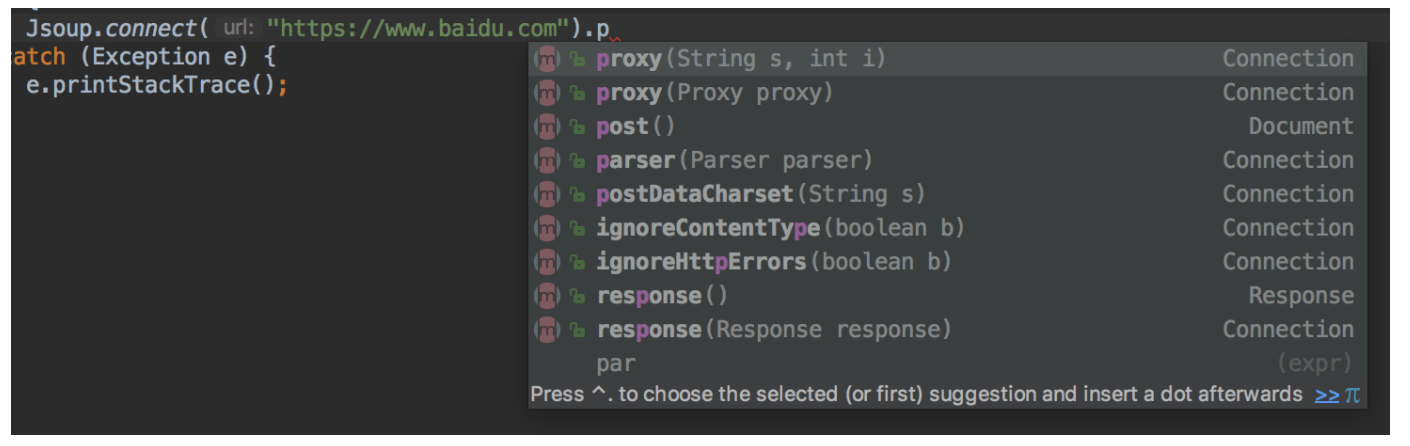
8. Set cookie s

9. Set browser
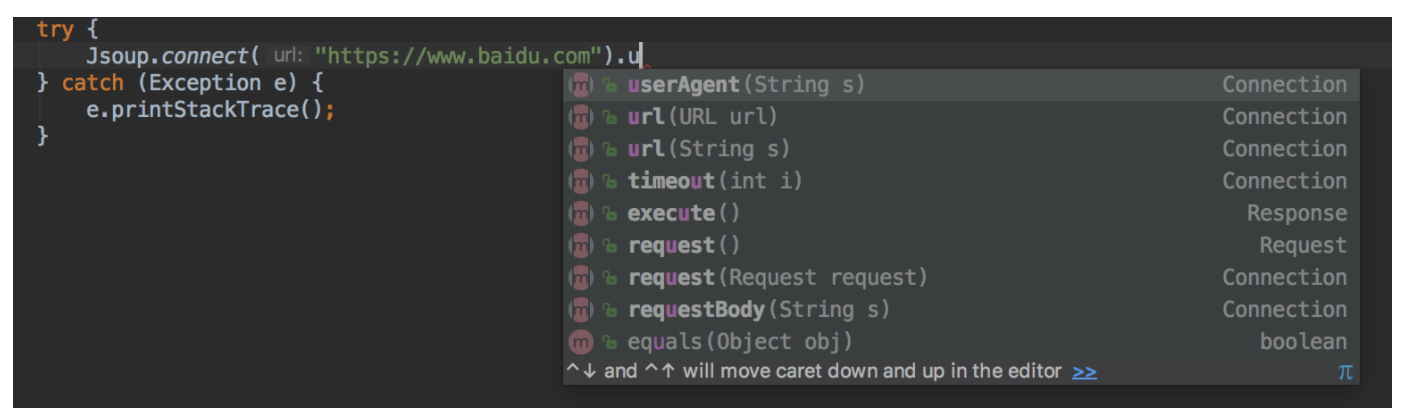
10. Set various header s

Well, don't talk about it. It's very easy for you to take a look at it. In addition, I personally suggest
.ignoreContentType(true) //Ignore content type when parsing document .ignoreHttpErrors(true) // Ignore when an error is reported in the connection HTTP request
These two must be opened
Careful friends must have found it. The return value is Document
So how to return the html source code of String type? Just follow get() or post()

If it is a calling interface and the return value is json, or you only need to return the body without html tag, then this is OK
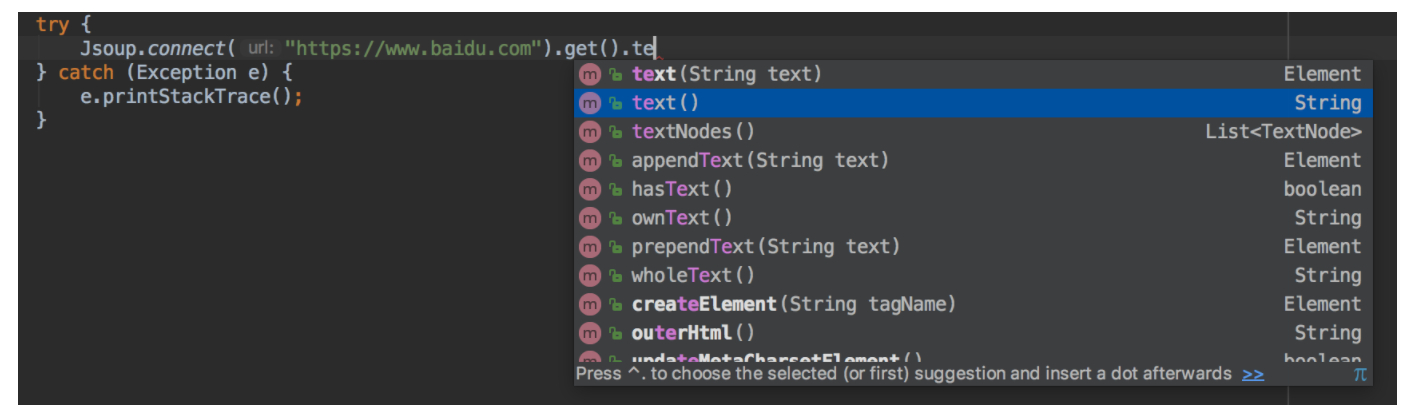
Remember the good habit of trim at any time
Here are two common methods I use to get and post
public static Document getJsoupDocGet(String url) {
//Three trial and error
final int MAX = 10;
int time = 0;
Document doc = null;
while (time < MAX) {
try {
doc = Jsoup
.connect(url)
.ignoreContentType(true)
.ignoreHttpErrors(true)
.timeout(1000 * 30)
.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8")
.header("accept-encoding","gzip, deflate, br")
.header("accept-language","zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7")
.get();
return doc;
} catch (Exception e) {
e.printStackTrace();
} finally {
time++;
}
}
return doc;
}
public static Document getJsoupDocPost(String url, Map<String,String> paramMap) {
//Three trial and error
final int MAX = 10;
int time = 0;
Document doc = null;
while (time < MAX) {
try {
doc = Jsoup
.connect(url)
.ignoreContentType(true)
.ignoreHttpErrors(true)
.timeout(1000 * 30)
.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8")
.header("accept-encoding","gzip, deflate, br")
.header("accept-language","zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7")
.data(paramMap)
.post();
return doc;
} catch (Exception e) {
e.printStackTrace();
} finally {
time++;
}
}
return doc;
}In fact, the return value Document has a more powerful function. It is a DOM parser. I use it to write crawlers. How to implement it, please go by yourself
https://www.jsoup.org/
Study and then go
https://try.jsoup.org/
Experiment, (it is recommended to copy the source code directly instead of using the built-in fetch)
I won't talk about it here. It's really easy to use
Original link: https://www.cnblogs.com/blog5277/p/9334560.html
Original author: blog Garden -- Qugao end and widowhood