
Microservice architecture learning SpringBoot integration Druid
Introduction to Druid
-
A large part of Java programs need to operate the database. In order to improve the performance, they have to use the database connection pool when operating the database.
-
Druid is a database connection pool implementation on Alibaba's open source platform. It combines the advantages of C3P0, DBCP and other DB pools, and adds log monitoring.
-
Druid can well monitor the connection of DB pool and the execution of SQL. It is naturally a DB connection pool for monitoring.
-
Druid has deployed more than 600 applications in Alibaba, which has been severely tested by large-scale deployment in the production environment for more than a year.
-
Hikari data source is used by default above Spring Boot 2.0. It can be said that Hikari and Driud are the best data sources on the current Java Web. Let's focus on how Spring Boot integrates Druid data source and how to realize database monitoring.
-
Github address: github.com/alibaba/dru...
com. alibaba. druid. pool. The basic configuration parameters of druiddatasource are as follows:
| to configure | Default value | explain |
|---|---|---|
| name | The significance of configuring this attribute is that if there are multiple data sources, they can be distinguished by name during monitoring. If there is no configuration, a name will be generated in the format of "DataSource -" + system identityHashCode(this) | |
| jdbcUrl | The url to connect to the database is different from database to database. For example: MySQL: JDBC: mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | User name to connect to the database | |
| password | Password to connect to the database. If you don't want the password written directly in the configuration file, you can use ConfigFilter. See here for details: github.com/alibaba/dru... | |
| driverClassName | Automatic identification according to url | This item can be configured or not. If druid is not configured, it will automatically identify the dbType according to the url, and then select the corresponding driverclassname (under recommended configuration) |
| initialSize | 0 | The number of physical connections established during initialization. Initialization occurs when the display calls the init method or the first getConnection |
| maxActive | 8 | Maximum number of connection pools |
| maxIdle | 8 | It is no longer used, and the configuration has no effect |
| minIdle | Minimum number of connection pools | |
| maxWait | The maximum waiting time to get a connection, in milliseconds. After maxWait is configured, the fair lock is enabled by default, and the concurrency efficiency will be reduced. If necessary, you can use the unfair lock by configuring the useUnfairLock attribute to true. | |
| poolPreparedStatements | false | Whether to cache preparedStatement, that is, PSCache. PSCache greatly improves the performance of databases that support cursors, such as oracle. It is recommended to close under mysql. |
| maxOpenPreparedStatements | -1 | To enable PSCache, it must be configured to be greater than 0. When greater than 0, poolPreparedStatements will be automatically triggered and modified to true. In Druid, there will be no problem that PSCache in Oracle occupies too much memory. You can configure this value to be larger, such as 100 |
| validationQuery | The sql used to check whether the connection is valid requires a query statement. If validationQuery is null, testonmirror, testOnReturn and testwhiteidle will not work. | |
| validationQueryTimeout | Unit: second, the timeout to detect whether the connection is valid. Underlying call jdbc void setQueryTimeout(int seconds) method of Statement object | |
| testOnBorrow | true | When applying for a connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testOnReturn | false | When returning the connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testWhileIdle | false | It is recommended that the configuration is true, and the security is not guaranteed. Check when applying for connection. If the idle time is greater than timebetween evictionrunsmillis, run validationQuery to check whether the connection is valid |
| timeBetweenEvictionRunsMillis | 1 minute ( 1.0.14 ) | It has two meanings: 1) the destroy thread will detect the connection interval; 2) the judgment basis of testwhiteidle. See the description of testwhiteidle attribute for details |
| numTestsPerEvictionRun | No longer used, a DruidDataSource only supports one EvictionRun | |
| minEvictableIdleTimeMillis | 30 Minutes ( 1.0.14 ) | The maximum time a connection remains idle without being evicted |
| connectionInitSqls | sql executed during physical connection initialization | |
| exceptionSorter | Automatic identification according to dbType | When the database throws some unrecoverable exceptions, the connection is discarded |
| filters | The attribute type is string. The extension plug-ins are configured by alias. The commonly used plug-ins are: filter for monitoring statistics: stat, filter for log: log4j, filter for defending sql injection: wall | |
| proxyFilters | The type is list < com alibaba. druid. filter. Filter >, if both filters and proxyFilters are configured, it is a combination relationship, not a replacement relationship |
Configure data source
-
Add Druid data source dependency, which can be accessed from Maven warehouse official website Maven Respository Get in
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.23</version> </dependency> Copy code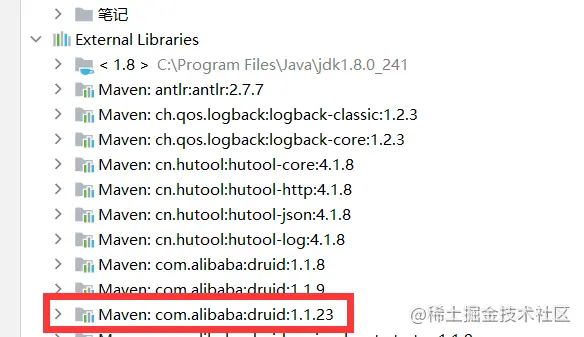
-
Switching data sources; It has been said before that Spring Boot 2.0 or above uses {com by default zaxxer. hikari. Hikaridatasource is a data source, but it can be accessed through spring datasource. Type specifies the data source.
spring: datasource: username: root password: 123456 #Time zone error adding time zone configuration url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=utf8 driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource Copy code -
After data source switching, inject DataSource into the test class, then obtain it, and output to see whether the switching is successful;

-
Switching succeeded! Now that the switch is successful, you can set the initialization size, maximum number of connections, waiting time, minimum number of connections and other settings of the data source connection; You can view the source code
spring: datasource: username: root password: 123456 #Time zone error adding time zone configuration url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=utf8 driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource #Spring Boot does not inject these attribute values by default and needs to bind by itself #druid data source proprietary configuration initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true #Configure filters for monitoring statistics interception, stat: monitoring statistics, log4j: logging, wall: defensive sql injection #If allowed, an error will be reported in Java lang.ClassNotFoundException: org. apache. log4j. Priority #Then import log4j dependency. Maven address: https://mvnrepository.com/artifact/log4j/log4j filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 Copy code -
Dependency of import Log4j
<!-- log4j--> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> Copy code -
Now programmers need to bind the parameters in the global configuration file for DruidDataSource and add them to the container instead of using the automatic generation of Spring Boot; We need to add the DruidDataSource component to the container and bind the attribute;
package com.sxau.config; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; import java.util.Arrays; import java.util.HashMap; import java.util.Map; @Configuration public class DruidConfig { /* Add the customized Druid data source to the container and no longer let Spring Boot create it automatically Bind the Druid data source attribute in the global configuration file to com alibaba. druid. pool. Druiddatasource to make them effective @ConfigurationProperties(prefix = "spring.datasource"): The function is to add the global configuration file The prefix is spring Inject the attribute value of datasource into com alibaba. druid. pool. Druiddatasource is in a parameter with the same name */ @ConfigurationProperties(prefix = "spring.datasource") @Bean public DataSource druidDataSource() { return new DruidDataSource(); } //Configure the Servlet of Druid monitoring and management background; //There is no web when the Servlet container is built in XML file, so the Servlet registration method of Spring Boot is used @Bean public ServletRegistrationBean statViewServlet() { ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*"); // These parameters can be found on COM alibaba. druid. support. http. StatViewServlet // Parent class of com alibaba. druid. support. http. Found in resourceservlet Map<String, String> initParams = new HashMap<>(); initParams.put("loginUsername", "admin"); //Login account of background management interface initParams.put("loginPassword", "123456"); //Login password of background management interface //Who is allowed to access in the background //initParams.put("allow", "localhost"): indicates that only the local machine can access it //initParams.put("allow", ""): when it is empty or null, it means that all access is allowed initParams.put("allow", ""); //deny: Druid, who is denied access in the background //initParams.put("kuangshen", "192.168.1.20"); Indicates that this ip access is prohibited //Set initialization parameters bean.setInitParameters(initParams); return bean; } //Configure the filter for web monitoring of Druid monitoring //WebStatFilter: used to configure management association monitoring statistics between Web and Druid data sources @Bean public FilterRegistrationBean webStatFilter() { FilterRegistrationBean bean = new FilterRegistrationBean(); bean.setFilter(new WebStatFilter()); //exclusions: sets which requests are filtered and excluded so that statistics are not performed Map<String, String> initParams = new HashMap<>(); initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*"); bean.setInitParameters(initParams); //"/ *" means to filter all requests bean.setUrlPatterns(Arrays.asList("/*")); return bean; } } Copy code -
Test in the test class; See if it succeeds!
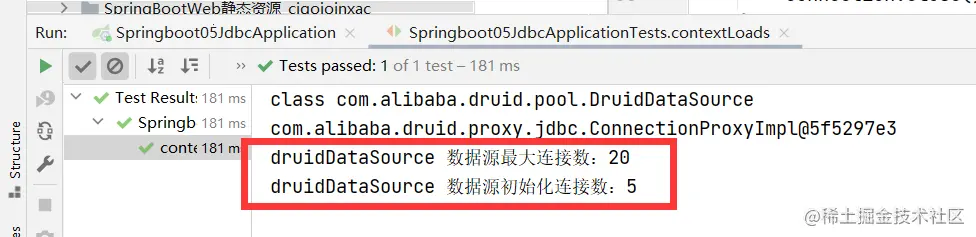
package com.sxau; import com.alibaba.druid.pool.DruidDataSource; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import javax.sql.DataSource; import java.sql.Connection; import java.sql.SQLException; @SpringBootTest class Springboot05JdbcApplicationTests { //DI data injection source @Autowired DataSource dataSource; @Test void contextLoads() throws SQLException { //Check out the default data source: class com zaxxer. hikari. HikariDataSource System.out.println(dataSource.getClass()); //Get database connection Connection connection = dataSource.getConnection(); System.out.println(connection); DruidDataSource druidDataSource = (DruidDataSource) dataSource; System.out.println("druidDataSource Maximum connections to data source:" + druidDataSource.getMaxActive()); System.out.println("druidDataSource Number of data source initialization connections:" + druidDataSource.getInitialSize()); //Close connection connection.close(); } } Copy code -
Output result: it can be seen that the configuration parameters have taken effect!
Configure Druid data source monitoring
Druid data source has the function of monitoring and provides a web interface for users to view. Similarly, when installing a router, people also provide a default web page.
Therefore, the first step is to set Druid's background management page, such as login account, password, etc; Configure background management;
package com.sxau.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
/*
Add the customized Druid data source to the container and no longer let Spring Boot create it automatically
Bind the Druid data source attribute in the global configuration file to com alibaba. druid. pool. Druiddatasource to make them effective
@ConfigurationProperties(prefix = "spring.datasource"): The function is to add the global configuration file
The prefix is spring Inject the attribute value of datasource into com alibaba. druid. pool. Druiddatasource is in a parameter with the same name
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource() {
return new DruidDataSource();
}
//Configure the Servlet of Druid monitoring and management background;
//There is no web when the Servlet container is built in XML file, so the Servlet registration method of Spring Boot is used
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// These parameters can be found on COM alibaba. druid. support. http. StatViewServlet
// Parent class of com alibaba. druid. support. http. Found in resourceservlet
Map<String, String> initParams = new HashMap<>();
initParams.put("loginUsername", "admin"); //Login account of background management interface
initParams.put("loginPassword", "123456"); //Login password of background management interface
//Who is allowed to access in the background
//initParams.put("allow", "localhost"): indicates that only the local machine can access it
//initParams.put("allow", ""): when it is empty or null, it means that all access is allowed
initParams.put("allow", "");
//deny: Druid, who is denied access in the background
//initParams.put("kuangshen", "192.168.1.20"); Indicates that this ip access is prohibited
//Set initialization parameters
bean.setInitParameters(initParams);
return bean;
}
}
Copy codeAfter configuration, we can choose to access: http://localhost:8080/druid/login.html
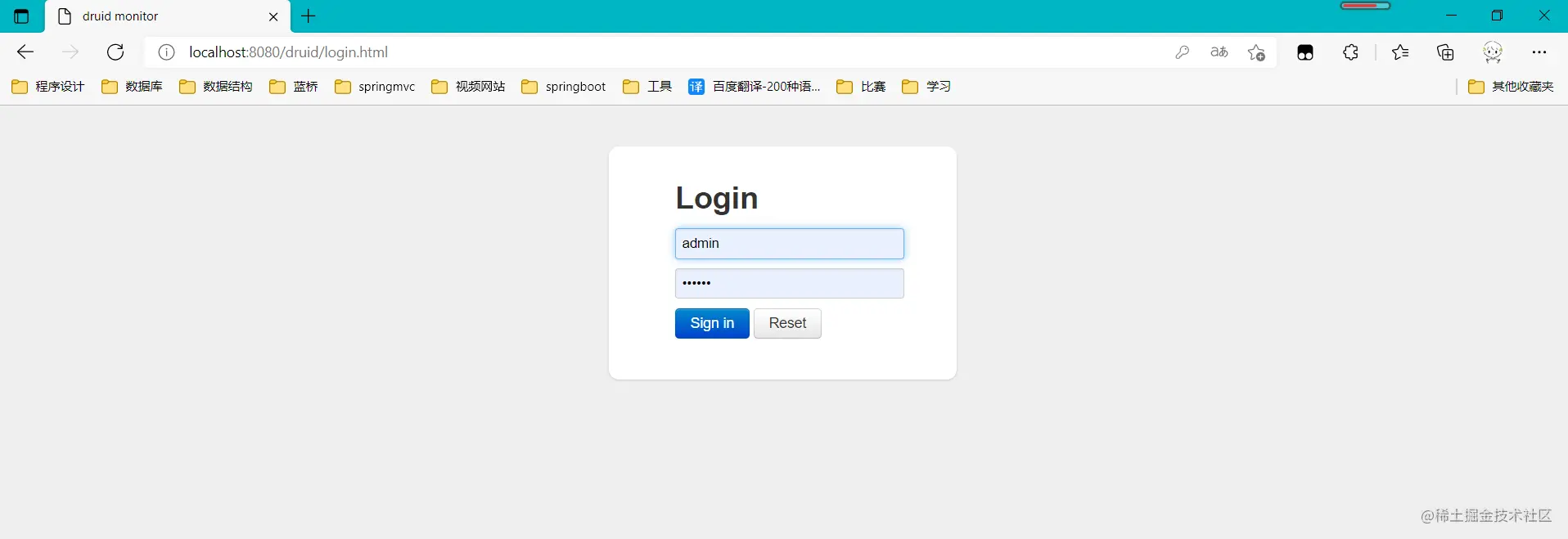
After entering
Configure Druid web monitoring filter
//Configure the filter for web monitoring of Druid monitoring
//WebStatFilter: used to configure management association monitoring statistics between Web and Druid data sources
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions: sets which requests are filtered and excluded so that statistics are not performed
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/ *" means to filter all requests
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}