Preface
The previous article shared some of the ways to handle numeric values, and this one is about string manipulation.
Title is also super simple, record how strings are handled
Misplaced keyboard 🍓 (that is, a misplaced string, using the misplaced character to match the original character)
Length of words 🥝 (String splitting)
Alphabetical rearrangement 🤑 (Substring matches main string, which feels like a good match)
Tex bracket problem (super simple, see below)
Let's get to the point and start what we're doing today 😮 Information about 💨

1. Misplaced keyboard 🚩
🪐 Problem Description
When we are typing, we often type A into S by mistake and S into D.
Now a programmer has mistyped a line of strings by hand. Restore it with your clever brain
(Character order on keyboard:'`1234567890-=QWERTYUIOP[]ASDFGHJKL;'ZXCVBNM,. /')
Sample input: O S, GOMR YPFSU/
Sample output: I AM FINE TODAY
🪐 problem analysis
These kinds of problems come to mind afterwards as character substitution, but it takes a lot of time and effort to replace characters one by one on a keyboard, so we can arrange an array of subscripts to record the position of the characters in the string. For unnecessary conversion, we may want to open the subscript array to 255 so that the ASCII value of each character can be directly indexed to the original string as the subscript of the subscript array.
Then you can know from the input that there are spaces in the input and there are no spaces in the given keyboard, so word breaking is required. Words in Python are handled in a very simple way. A character pointer array can be created in C to store each word in the same way as the average length of the word. You can look down first. You can overlap the character pointer array after word division. Then output in sequence. When output, first index the original string with the character as subscript, then take index-1 to remove the character from the original string. Note the format of the output.
🪐 code implementation
Old Rules First Run Result:

The code is as follows:
import sys
s=sys.stdin.readline().strip().split()
indexarr=[0]*255
# Store all data in an array and index two adjacent letters on the keyboard
mystr="`1234567890-=QWERTYUIOP[]\\ASDFGHJKL;'ZXCVBNM,./"
# Store an index of each letter. Used by data entered for later traversal
for i in range(len(mystr)):
indexarr[ord(mystr[i])]=i
flag=True
#Traverse the input n-segment string
for line in s:
if flag:
flag=False
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")
else:
print(" ",end="")
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")
2. Average Length of Words 🚩
Use of this topic Python Make Super Easy Use c Spaces are counted first if the language does so, and words are added by 1 if no spaces follow. If the space is still followed by the space traversed down, add 1 to the number of letters if a position is not a space Ultimately add 1 to the amount of the word,Because only one word is counted in the first and last word cycle.
🪐 Problem Description
Enter several words that contain only letters, each consisting of one or more spaces
Average Length of Output Words
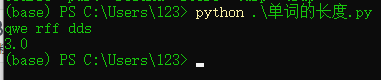
Sample input: qwe qwe qwe
Sample output: 3.0
🪐 problem analysis
Separate the strings, find the length of each string, and divide the length by the number of words
🪐 code implementation
Old Rules First Run Result:
The code is as follows:
import sys
num=0
n=0
# strip() is used here to remove end line breaks from input
# String fragmentation using split() results in a list
mystr=sys.stdin.readline().strip().split()
for i in mystr:
num+=len(i)
n+=1
print(num/n)
3. Alphabetical Rearrangement 🚩
🪐 Problem Description
Enter a dictionary (***** at the end) and then enter several words. For each word w you enter, you need
Find all the words in the dictionary that can be rearranged with the letter w and place them in the order of the dictionary from smallest to largest
Output in line (if none exists, output: 0. Input words are separated by spaces or blank lines, and all input words are separated by
No more than 6 lower case letters. Note that words in a dictionary are not necessarily in dictionary order.
Sample input:
First line tarp given score refund only trap work earn course pepper part
Second line resco nfudre aptr sett oresuc
Sample output:
course part refund score tarp trap
🪐 problem analysis
Gives a dictionary, so when we look up a dictionary, we can first process it and then look up the words according to the dictionary's criteria
Here we can sort the dictionary first to get an alphabetical dictionary, then sort each element in the dictionary.
Sort the substrings you want to query, then iterate through the ordered dictionary to find the direct output (that is, press the standard dictionary by
Processing in a certain way and then comparing the words to be searched with a dictionary after the same conversion)
_Code implementation
Old Rules First Run Result:

The code is as follows:
import sys
# Metadictionary Ordered String
mydic=list(sys.stdin.readline().strip().split())
mydic=sorted(mydic)
words=sys.stdin.readline().strip().split()
# Sorted string
newdic=[]
newwords=[]
for i in mydic:
# Strings cannot be sorted directly. They are first converted into a dictionary and then sorted
newdic.append("".join(sorted(i)))
for i in words:
newwords.append("".join(sorted(i)))
flag=False
i=0
while i<len(newdic):
if newdic[i] in newwords:
if not flag:
print(mydic[i],end="")
flag=True
else:
print(" ",mydic[i],end="")
i+=1
if not flag:
print(0)
4. Tex brackets 🚩
_Problem Description
There is an article that was not formatted as specified at the time of writing and now needs to convert punctuation symbols containing''to
Article "" with Chinese double quotation marks only
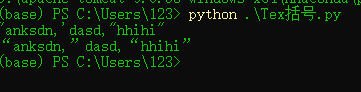
Sample input:'anksdn,'dasd,'hhihi'
Sample output:'anksdn','dasd','hhihi'
_Problem Analysis
It's very similar to the light simulation mentioned above, just need to tidy up the memory marker bits.
You can design a flag tag, and when flag is True, you meet the output of "Make left quotation marks" and then
Change the flag to the opposite value immediately When flag is false, encounter "Output in right quotes immediately."
Then mark flag as True
_Code implementation
Old Rules First Run Result:
The code is as follows:
import sys
s=sys.stdin.readline().strip()
flag=True
for i in s:
if i=="'" or i=="\"":
if flag:
print(""",end="")
else:
print(""",end="")
flag=not flag
continue
print(i,end="")