introduce
Write in front
This experiment is a file system. The content is to expand the file system size of xv6 and realize soft links. The experimental address is here . I feel that this is another view of the operating system. It is different from the previous virtual memory and processes. In comparison, the knowledge of the operating system is simpler. Therefore, I went to supplement the relevant knowledge and felt that this course was good again,. The ability is too poor. It takes a long time to write the code. The code is placed in the github Come on.
file system
The implementation of xv6 file system is roughly the same as that of many other systems, but it is simplified in many places. Files are stored in the form of blocks. Physical disks are read and written in sectors. Generally speaking, each sector is 512 bytes. However, when the operating system reads the disk, because the seek time is very long, the time to read and write data is not so long. Therefore, the operating system will generally read and write multiple consecutive sectors for almost the same time. The operating system takes multiple sectors as a disk block, and xv6 is two sectors, that is, a block is 1024 bytes.
The disk only stores data in the form of sectors, but if there is no reading standard, the disk is a raw disk. The disk needs to store data according to the reading and writing standards of the operating system. The format is as follows:

It can be seen that the data blocks in different regions of the disk have different functions. The 0-th data block is the startup area, from which the computer starts; The first data block is a super block, which stores the information of the whole disk; Then the log area is used for fault recovery; bit map is used to mark whether the disk block is used; Then there are the inode area and the data area.
Inode and data are the main blocks for storing files on disk. In the operating system, the file information is stored in inodes. Each file corresponds to an inode. The inode contains the index information of the disk blocks where the file contents are stored. Users can use this information to find out which blocks of the disk the file is stored in. Inodes blocks store inodes of many files.
Experimental content
Task 1 (Large files)
The inode in xv6 has 12 direct indexes (directly corresponding to the disk blocks in the data area) and one primary index (storing another index pointing to the data area). Therefore, it supports 12 + 256 = 268 data blocks at most, as shown in the following figure:
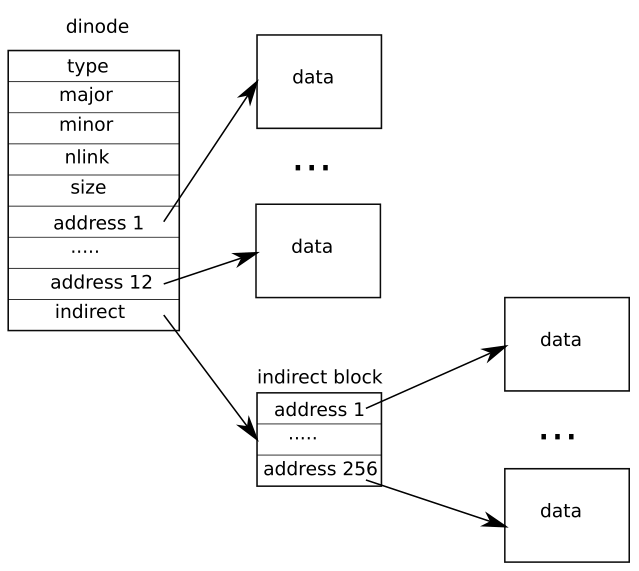
Because of this design, the size of files stored in xv6 is limited. Therefore, the first task of this experiment is to expand the supported file size by implementing secondary index.
The first step is to modify the inode data structure
kernel/fs.h reduce the value of NDIRECT in the file and leave a position for the secondary index:
#define NDIRECT 11
#define NINDIRECT (BSIZE / sizeof(uint))
#define NDINDIRECT NINDIRECT * NINDIRECT
#define MAXFILE (NDIRECT + NINDIRECT + NDINDIRECT)
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses
};
The above is the inode structure in the disk, which also needs to be in the kernel / file H to change the inode structure in memory:
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};
The second step is to implement bmap mapping
Follow the primary index and write the secondary index in kernel / Fs Add code to C:
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
// Secondary index
bn -= NINDIRECT;
if(bn < NDINDIRECT) {
if((addr = ip->addrs[NDIRECT+1]) == 0)
ip->addrs[NDIRECT+1] = addr = balloc(ip->dev);
// Find the next level index through the first level index
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn/NINDIRECT]) == 0) {
a[bn/NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
// Repeat the above code to realize the secondary index
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if ((addr = a[bn%NINDIRECT]) == 0) {
a[bn%NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
The third step is itrunc cleanup
In kernel / Fs C, add the release operation of the second level index:
void
itrunc(struct inode *ip)
{
...
if(ip->addrs[NDIRECT+1]) {
bp = bread(ip->dev, ip->addrs[NDIRECT+1]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++) {
if(a[j]) {
bp2 = bread(ip->dev, a[j]);
a2 = (uint*)bp2->data;
for(i = 0; i < NINDIRECT; i++) {
if(a2[i]) bfree(ip->dev, a2[i]);
}
brelse(bp2);
bfree(ip->dev, a[j]);
a[j] = 0;
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT+1]);
ip->addrs[NDIRECT] = 0;
}
ip->size = 0;
iupdate(ip);
}
Task 2 (Symbolic links)
Hard links refer to multiple file names pointing to the same inode number. It has the following characteristics:
- The same content can be accessed with different file names;
- Modifying the file content will affect all file names;
- Deleting a file name does not affect access to another file name.
The soft link is also a file, but the file content points to the inode of another file. When you open this file, it will automatically open the file it points to, which is similar to the shortcut of windows system.
There is no symbolic link (soft link) in xv6. This task requires us to implement a symbolic link.
The first step is to add symlink system call
- user/usys.pl
entry("symlink");
- user/user.h
int symlink(const char*, const char*);
- kernel/syscall.h
#define SYS_symlink 22
- kernel/syscall.c
extern uint64 sys_symlink(void); [SYS_symlink] sys_symlink,
- knerl/sysfile.c
The last is to implement the system call function, first read the parameters from the register, and then start the transaction to avoid submission errors; Create a new inode for the symbolic link; Write the linked file in the symbolic linked data; Finally, commit the transaction:
uint64
sys_symlink(void)
{
char path[MAXPATH], target[MAXPATH];
struct inode *ip;
// Read parameters
if(argstr(0, target, MAXPATH) < 0)
return -1;
if(argstr(1, path, MAXPATH) < 0)
return -1;
// Open transaction
begin_op();
// Create a new inode for this symbolic link
if((ip = create(path, T_SYMLINK, 0, 0)) == 0) {
end_op();
return -1;
}
// Write the linked file in the symbolic linked data
if(writei(ip, 0, (uint64)target, 0, MAXPATH) < MAXPATH) {
iunlockput(ip);
end_op();
return -1;
}
// Commit transaction
iunlockput(ip);
end_op();
return 0;
}
Step 2: add the flag bit
Add the flag bit according to the experiment manual:
- Add t in kernel/stat.h_ SIMLINK
- kernel/fcntl. Add o to h_ NOFOLLOW
Step 3: modify sys_open function
When opening a file, if you encounter a symbolic link, open the corresponding file directly. Here, in order to prevent symbolic links from being linked to each other, leading to an endless loop, an access depth is set (I set it to 20). If the number of accesses reaches, it indicates that opening the file fails. Each time, first read the corresponding inode, find the corresponding inode according to the file name, and then continue to judge whether the inode is a symbolic link:
int depth = 0;
...
// Constantly determine whether the inode is a symbolic link
while(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)) {
// If the access depth is too large, exit
if (depth++ >= 20) {
iunlockput(ip);
end_op();
return -1;
}
// Read the corresponding inode
if(readi(ip, 0, (uint64)path, 0, MAXPATH) < MAXPATH) {
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
// Find the corresponding inode according to the file name
if((ip = namei(path)) == 0) {
end_op();
return -1;
}
ilock(ip);
}
...
summary
The difficulty of completing the experiment is OK, which is a little more difficult than the previous ones. The main reason is that the knowledge reserve of the file system is not enough. The course corresponding to this experiment doesn't talk much about the experiment content. It's mainly to see how other file system functions are implemented (sys_open function is very helpful, as well as namei, readi, writei and other inode related functions).
Article synchronization in Know.