1. Module class
pytorch can define the instantiation of the model by inheriting the module class, instantiate the internally defined module, and then adjust the servant sub module through forward calculation, so as to complete the construction of the deep learning model.
import torch.nn as nn
class Model(nn.Module):
def __init__(self, ...): # Module initialization Input parameters for the user
super(Model, self).__init__() # Methods that inherit the parent class
... # Define the submodule based on the passed in parameters
def forward(self, ...):
# Define the input parameters of forward calculation, generally tensors or other parameters
ret = ... # Calculate the return tensor according to the incoming tensor and sub module
return ret
Pass__ init__ Method initializes the whole model, and then uses the forward method to carry out forward calculation on the module. In use__ init__ At the time of the method, you can initialize the submodules in the class, then call these initialized sub modules in the forward method, and finally output the tensors.
2. Simple linear regression class based on module class
2.1 example of pytorch linear regression model
import torch
import torch.nn as nn
class LinearModel(nn.Module):
def __init__(self, ndim):
super(LinearModel, self).__init__()
self.ndim = ndim
self.weight = nn.Parameter(torch.randn(ndim, 1)) # Define weights
self.bias = nn.Parameter(torch.randn(1)) # Define offset
def forward(self, x):
# y = Wx + b
return x.mm(self.weight) + self.bias
In order to construct a linear transformation, we need to know the size of the input feature dimension, the weight (self.weight) and bias (self.bias) of the linear regression. Enter an eigenvector in the forward method x x X (the size is the size of the mini batch x the size of the characteristic dimension), perform linear transformation (perform matrix multiplication linear transformation using the mm method), add the offset value, and finally enter a predicted value. nn.Parameter wraps the parameter to make it a sub module (only the sub module with parameter structure) to facilitate subsequent parameter optimization.
2.2 example of calling method of pytorch linear regression model
lm = LinearModel(5) # The model is instantiated, and the number of features is 5 x = torch.randn(4, 5) # Random input, mini batch 4 lm(x) # Output per Mini batch

3. Instantiation and method call of linear regression class
3.1 using named_ The parameters method and the parameters method obtain the parameters of the model.
Both methods return the generator, named_parameters gets the names and corresponding tensor values of all parameters of the model, and the parameters method returns the tensor values corresponding to all parameters of the model.
3.2 use train and eval methods to carry out model training and test state transformation
In model training, some sub modules have two states, training state and prediction state. Pytorch's model often needs to switch between the two states. Calling the train method will convert the module (all sub modules) to the training state, and calling the eval method will convert the module (all sub modules) to the prediction state. The prediction accuracy of pytorch model in different states will be different. It needs to be converted to training state when training the model and to prediction state when predicting, otherwise the final prediction accuracy may be reduced.
3.3 using named_buffers method and buffers method get the cache of tensor
In addition to the parameters for gradient training obtained through back propagation, some parameters do not participate in gradient propagation, but will be updated during training. This parameter is called Buffer. Specific examples include the Mean and Variance of batch normalization layer. Call register_ in module The Buffer method can add this type of tensor to the module and use named_buffers can obtain the generator composed of the name of the cache and the value of the cache tensor. buffers can obtain the generator composed of the value of the cache tensor.
3.4 using named_children method and children method obtain sub modules of the model
Sometimes you need to iterate over the sub modules of a module, so you need to use named_ The children method and the children method to obtain the name of the sub module, the generator of the sub module, and the generator with only the sub module. If you want to get the information of all modules in the module, you can use named_modules and modules to (recursively) get relevant information.
3.5 use the apply method to recursively apply functions to sub modules
If you need the first mock exam to apply all functions to pytorch, you can use apply method to apply these functions recursively by passing in a function or anonymous function. The module of the incoming function is modified as a parameter.
3.6 change the module parameter data type and storage location
In deep learning, you can change the device (CPU or GPU) where the parameters of the module are located. To change the data type of a parameter, you can add the target data type to be changed through the to method. The float method will convert all parameters to single precision floating-point numbers, and the half method will convert all parameters
4. pytorch module method call instance
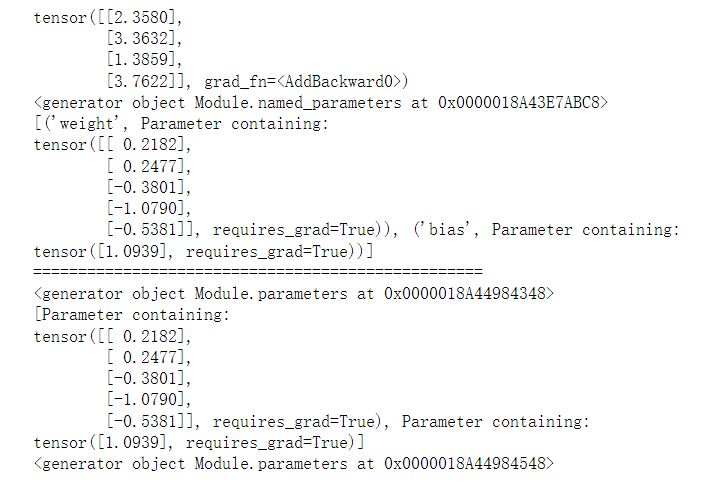
lm = LinearModel(5)
x = torch.randn(4, 5) # Model input
print(lm(x)) # Get the corresponding output of the model
print(lm.named_parameters()) # Generator to get model parameters (with names)
print(list(lm.named_parameters())) # Convert generator to list
print('=' * 50)
print(lm.parameters()) # Grower that gets model parameters (without name)
print(list(lm.parameters())) # Convert generator to list
lm.half() # Convert model parameters to semi precision floating point numbers
print(lm.parameters()) # Display the model parameters, and you can see that they have been converted to semi precision floating-point numbers