
MOJITO
I haven't written anything recently. I can't catch up with a hot spot. I despise myself.
Zhou Dong's new song "MOJITO" (zero on June 12) has been on sale for about a week now. When I look at the MV of station B, I can see that the broadcast volume is over ten million, and the barrage is over one hundred thousand. This popularity is really a bar.
To be honest, the name "MOJITO" is a little out of line for me. I didn't know what it meant when I saw it for the first time.
But the problem is not big. There is nothing Baidu can't solve. If there is, add another Zhihu.
MOJITO's Chinese name is MOJITO, which is introduced in Baidu Encyclopedia:
Mojito is one of the most famous rum wines. It originated in Cuba. Traditionally, mogito is a cocktail of five ingredients: light rum, sugar (traditionally cane juice), lime (lime) juice, soda water and mint. The original Cuban formula used spearmint or lemon mint, which is common on the island of Cuba. The refreshing flavors of lime and mint complement the strength of rum, and make this transparent and colorless concoction one of the hot drinks in summer. This concoction has a relatively low alcohol content (about 10%).
If the alcohol level is about 10%, it can be regarded as a kind of beverage.
Of course, if you want to drive, you can't use MOJITO as a drink. No matter how low the alcohol content is, it's also alcohol.

I've seen the whole MV over and over for several times, and "MOJITO" has not appeared once in the MV except in the lyrics and names. It has no sense of existence.

Climb the bullet curtain of station B
The crawling of the bullet curtain data is relatively simple. I will demonstrate the step-by-step grabbing request to you. Note that the following requests are connected:
Barrage request address:
https://api.bilibili.com/x/v1/dm/list.so?oid=XXX https://comment.bilibili.com/XXX.xml
The first address has been changed due to the web page of site B. now it can't be found in the network of Chrome tool, but it can still be used. This is what I found before.
The second address comes from Baidu. I don't know where all the gods find this address for reference.
In fact, both of the above bullet screen addresses need something called oid, which can be obtained as follows:
First, you can find a directory page interface:
https://api.bilibili.com/x/player/pagelist?bvid=XXX&jsonp=jsonp
This interface also comes from the network of Chrome. The parameter bvid comes from the video address. For example, Zhou Dong's "MOJITO" MV, the address is https://www.bilibili.com/video/BV1PK4y1b7dt The value of bvid is the last part of bv1pk4y1b7dt.

Next in https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp In this interface, we can see the returned json parameters as follows:
{ "code":0, "message":"0", "ttl":1, "data":[ { "cid":201056987, "page":1, "from":"vupload", "part":"JAY-MOJITO_complete MV(Updated version)", "duration":189, "vid":"", "weblink":"", "dimension":{ "width":1920, "height":1080, "rotate":0 } } ] }
Note: since there is only one complete video in this MV, there is only one cid here. If a video is published in different sections, there will be multiple CIDS here. Different CIDS represent different videos.
Of course, the cid here is the oid we were looking for. If we put the cid on the link, we can get https://api.bilibili.com/x/v1/dm/list.so?oid=201056987 Such an address, and then enter it into the browser, you can see the return data of the barrage, which is a text in xml format.
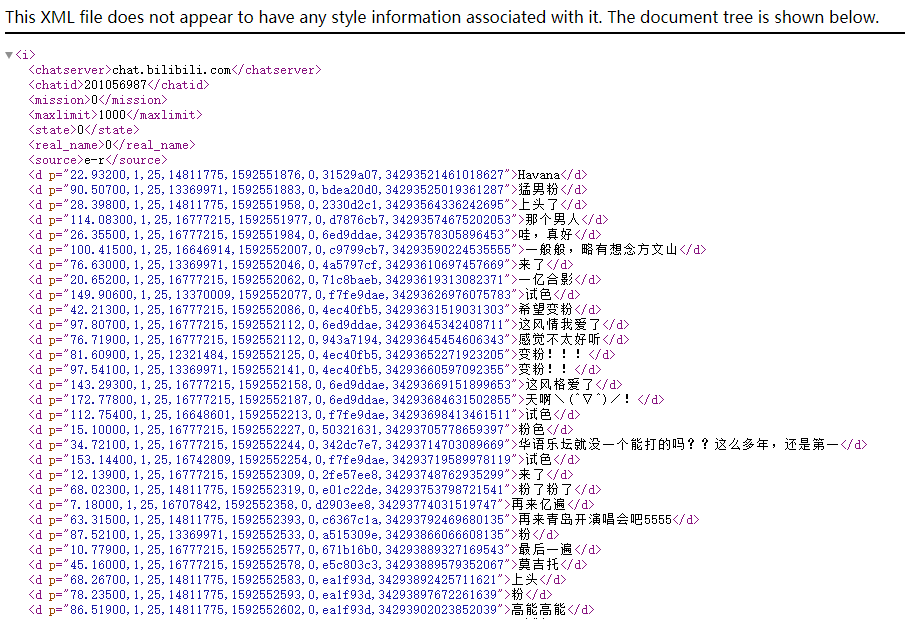
The source code is as follows:
import requests import re # Get cid res = requests.get("https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp") cid = res.json()['data'][0]['cid'] # Extract the barrage xml through regular, and generate list danmu_url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}" result = requests.get(danmu_url).content.decode('utf-8') pattern = re.compile('<d.*?>(.*?)</d>') danmu_list = pattern.findall(result) # Save the bullet list to a txt file with open("dan_mu.txt", mode="w", encoding="utf-8") as f: for item in danmu_list: f.write(item) f.write("\n")
Here I saved the acquired barrage in dan_mu.txt File for subsequent analysis.
Draw word cloud
The first step is to save it in dan_mu.txt The bullet curtain in the file is read out and put into a list:
# Read the bullet screen txt file with open("dan_mu.txt", encoding="utf-8") as f: txt = f.read() danmu_list = txt.split("\n")
Then use the word segmentation tool to segment the bullet screen. The word segmentation tool I use here is the best Python Chinese word segmentation component, jieba. Students who have not installed jieba can use the following command to install it:
pip install jieba
Use jieba to segment the barrage list just obtained:
# jieba participle danmu_cut = [jieba.lcut(item) for item in danmu_list]
In this way, we get the Danmu after the participle_ Cut, this is also a list.
And then we're going to talk about Danmu after the participle_ Cut performs the next operation to remove the stop words:
# Get stop words with open("baidu_stopwords.txt",encoding="utf-8") as f: stop = f.read() stop_words = stop.split() # Remove the final word after the stop word s_data_cut = pd.Series(danmu_cut) all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
Here I introduce a baidu_stopwords.txt File, this file is Baidu's inactive thesaurus. Here I find several common Chinese inactive thesaurus, source: https://github.com/goto456/stopwords .
| Thesaurus file | Glossary name |
|---|---|
| baidu_stopwords.txt | Baidu stop vocabulary |
| hit_stopwords.txt | Stoppage vocabulary of Harbin Institute of Technology |
| scu_stopwords.txt | Machine Intelligence Laboratory of Sichuan University |
| cn_stopwords.txt | Chinese stoppage list |
Here I use Baidu stoppage thesaurus. You can use it according to your own needs, or you can integrate these stoppage thesaurus first and then use it. The main purpose is to remove some words that don't need attention. I will submit the above stoppage thesaurus to the code warehouse for self access if necessary.
Then we count the word frequency after removing the stop words:
# word frequency count all_words = [] for i in all_words_after: all_words.extend(i) word_count = pd.Series(all_words).value_counts()
The final step is to generate our final result, cloud map of words:
wordcloud.WordCloud( font_path='msyh.ttc', background_color="#fff", max_words=1000, max_font_size=200, random_state=42, width=900, height=1600 ).fit_words(word_count).to_file("wordcloud.png")
The final result is as follows:

It can be seen from the cloud chart of the above word that fans are really in love with the song "MOJITO". The most frequent ones are ah, love and pink.
Of course, this pink may also mean the coquettish pink old car in the MV.
There is also a relatively high frequency of Ye Qinghui. I think this means that ye's youth has come back. Indeed, Dong Zhou has been with people of my age all the way. As a 79 year old, he is now 41 years old. Looking back, it's very sad.
In those days, a "nunchaku" was all over the land of China, and the audio and video stores on the street were circulating these songs all day. My generation, who was in school, basically everyone could hum two sentences, "use the nunchaku quickly, hum and ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha ha.
Analysis of Intelligent Emotion tendency
We can also conduct an emotional tendency analysis on the bullet screen. Here I use the emotional tendency analysis interface of "Baidu AI open platform".
Baidu AI open platform document address: https://ai.baidu.com/ai-doc/NLP/zk6z52hds
First, access "Baidu AI open platform" according to the document_ Token, the code is as follows:
# Get Baidu API access_token access_token_url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type={grant_type}&client_id={client_id}&client_secret={client_secret}&' res = requests.post(access_token_url) access_token = res.json()['access_token'] # Universal emotional interface # sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={access_token}' # Customized emotional interface sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify_custom?charset=UTF-8&access_token={access_token}'
Baidu AI open platform has two emotion analysis interfaces, one is universal, and the other is customized. I use the customized interface after training here. If there is no customized interface, there is no problem in using the universal interface.
Grant used above_ type , client_id , client_ The parameters of secret can be obtained after you register. These interfaces on the "Baidu AI open platform" are limited by the number of calls, but we can use them ourselves.
Then read the bullet screen text we just saved:
with open("dan_mu.txt", encoding="utf-8") as f: txt = f.read() danmu_cat = txt.split("\n")
Before invoking the interface to get emotional inclination, we need to do one more thing to deal with the bullet screen, because there will be some emoji expressions in the bullet screen, and emoji directly requests Baidu's interface to return an error, here I use another toolkit to deal with emoji expressions.
First install the toolkit emoji:
pip install emoji
It's very simple to use. We use emoji to process the barrage data once:
import emoji with open("dan_mu.txt", encoding="utf-8") as f: txt = f.read() danmu_list = txt.split("\n") for item in danmu_list: print(emoji.demojize(item))
We have emoji expressions in our data:
❤❤❤❤❤❤❤ # After treatment: :red_heart::red_heart::red_heart::red_heart::red_heart::red_heart::red_heart:
Then, we can call Baidu's sentiment analysis interface to analyze our barrage data:
# Emotion counter optimistic = 0 neutral = 0 pessimistic = 0 for danmu in danmu_list: # Due to the limitation of calling QPS, the interval of each call is 0.5s time.sleep(0.5) req_data = { 'text': emoji.demojize(danmu) } # Call sentiment analysis interface if len(danmu) > 0: r = requests.post(sentiment_url, json = req_data) print(r.json()) for item in r.json()['items']: if item['sentiment'] == 2: # Positive emotion optimistic += 1 if item['sentiment'] == 1: # Neutral emotion neutral += 1 if item['sentiment'] == 0: # Negative emotion pessimistic += 1 print('Positive emotion:', optimistic) print('Neutral emotion:', neutral) print('Negative emotion:', pessimistic) attr = ['Positive emotion','Neutral emotion','Negative emotion'] value = [optimistic, neutral, pessimistic] c = ( Pie() .add("", [list(attr) for attr in zip(attr, value)]) .set_global_opts(title_opts=opts.TitleOpts(title="「MOJITO」Emotional analysis of bullet curtain")) .render("pie_base.html") )
The final result is as follows:
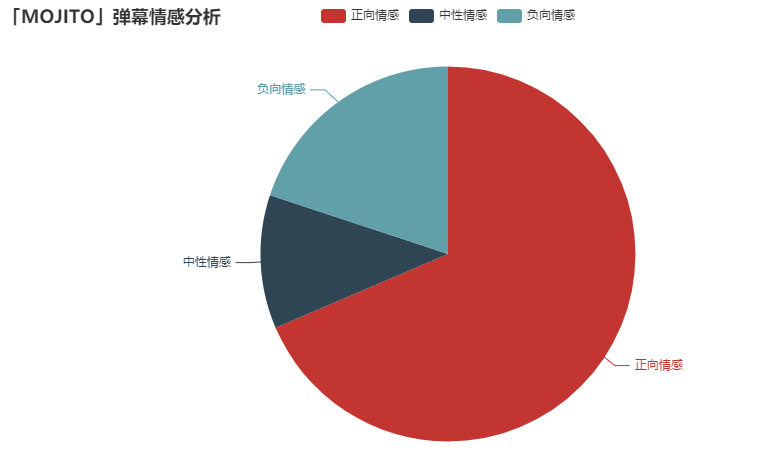
From the final result, the positive emotion accounts for about 2 / 3, while the negative emotion is less than 1 / 4. It seems that most people are still full of excitement when they see Zhou Dong's new song.
However, this data is not necessarily accurate. It can be used as a reference at most.
source code
Students who need source code can reply to "MOJITO" in the background of official account.