1, MPEG format
MPEG standards mainly include the following five, MPEG-1, MPEG-2, MPEG-4, MPEG-7 and MPEG-21.
MPEG-1 standard was officially published in 1992. The standard number is ISO/IEC11172, and its title is "the code rate is about 1.5Mb/s, which is used to encode the moving image and its accompanying sound of digital storage media". MPEG-1 mainly solves the problem of multimedia storage. Its successful formulation has rapidly popularized MPEG-1 products represented by VCD and MP3 all over the world.
MPEG-2 is one of the video and audio lossy compression standards formulated by MPEG (Moving Picture Experts Group). Its official name is "compression standard of moving image and voice based on digital storage media". Compared with MPEG-1 standard, MPEG-2 standard is an image compression standard with higher image quality, more image formats and transmission bit rate. MPEG-2 standard is not a simple upgrade of MPEG-1, but has made more detailed provisions and further improvement in transmission and system. It is a compression scheme for standard digital TV and high-definition TV in various applications. The transmission rate is between 3 Mbit / s and 10 Mbit / s.
2, Experimental principle
- Psychoacoustic model
There is an auditory threshold level in the auditory system, and the sound signal below this level can not be heard. The auditory threshold changes with the change of sound frequency. Whether a person hears a sound depends on the frequency of the sound and whether the amplitude of the sound is higher than the auditory threshold at this frequency. Auditory masking characteristics: that is, the auditory threshold level is adaptive and will change with the sounds of different frequencies. The sound compression algorithm can establish a model of this characteristic to eliminate more redundant data. - Auditory characteristics of human ear
The human auditory system is roughly equivalent to a filter bank composed of 25 overlapping band-pass filters in the frequency range of 0Hz to 20KHz.
The human ear cannot distinguish different sounds occurring simultaneously in the same frequency band;
The human ear frequency band is called critical band;
Critical frequency band is the basic unit of psychoacoustic model analysis.
The masking effect does not change with the increase of bandwidth in a certain frequency range until it exceeds a certain frequency value.
3, Design idea

4, Implementation code
#ifdef NEWENCODE
// Calculate scale factor
scalefactor_calc_new(*sb_sample, scalar, nch, frame.sblimit);
find_sf_max (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR_new (*sb_sample, *j_sample, frame.sblimit);
scalefactor_calc_new (j_sample, &j_scale, 1, frame.sblimit);
}
#else
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);
pick_scale (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);
}
#endif
/* add to */
FILE *output = fopen("output.txt", "wb");
if (frameNum == 20)
{
fprintf(output,"The sampling rate of output audio is:%.1fkhz \r\n", s_freq[header.version][header.sampling_frequency]);
fprintf(output, "The target bit rate is:%dMbps \r\n", bitrate[header.version][header.bitrate_index]);
fprintf(output, "The selected data frame is:%d \r\n", frameNum);
fprintf(output, "The number of bits allocated to this frame is:%dbits\r\n", adb);
for (int k = 0; k < nch; k++)//nch is num channels: 1 for mono, 2 for stereo
{
fprintf(output, "Vocal tract[%d] \r\n", k + 1);
for (int j = 0; j < frame.sblimit; j++)//Total number of subbands
{
fprintf(output, "Subband[%d]: ", j + 1);
for (int m = 0; m < 3; m++)//Each child has 3 scale factors
{
fprintf(output, "%d\t", scalar[k][m][j]);
}
fprintf(output, "\r\n");
}
}
}
#ifdef NEWENCODE
sf_transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation_new (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
write_header (&frame, &bs);
//encode_info (&frame, &bs);
if (error_protection)
putbits (&bs, crc, 16);
write_bit_alloc (bit_alloc, &frame, &bs);
//encode_bit_alloc (bit_alloc, &frame, &bs);
write_scalefactors(bit_alloc, scfsi, scalar, &frame, &bs);
//encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization_new (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
//subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
// *subband, &frame);
write_samples_new(*subband, bit_alloc, &frame, &bs);
//sample_encoding (*subband, bit_alloc, &frame, &bs);
#else
transmission_pattern (scalar, scfsi, &frame);
//Perform iterative bit allocation for subbands according to the masking value to minimize the mask to noise ratio, and then output the bit allocation information of each subband
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
/* add to */
if (frameNum == 20)
{
fprintf(output, "\n Bit allocation:\n");
for (int k = 0; k < nch; k++)
{
fprintf(output, "channel[%d] \r\n", k + 1);
for (int j = 0; j < frame.sblimit; j++)
{
fprintf(output, "subband[%d]:%d\r\n", j, bit_alloc[k][j]);
}
}
}
5, Experimental results
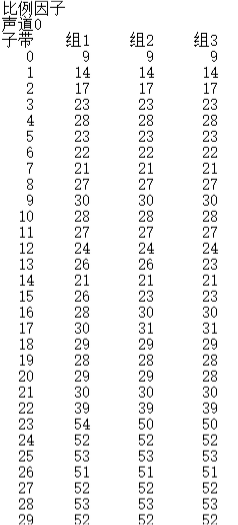

6, Result analysis
The experimental results show that the difference of the three scale factors in the same subband is small, so the file can be compressed by the method of scale factor selection.
In terms of frame bit allocation, the number of allocated bits in high-frequency subband is less, and the number of batch bits in low-frequency subband is more.