preface
Through the previous article Multi view 3D model texture mapping 01 , I basically have a simple understanding of the OpenMVS framework and usage methods. Here I continue to explore based on the previous article and explain the problems left in the previous article.
Known:
1. There are point cloud data taken from 8 angles on hand, and the point cloud has been registered, fused and meshed to form Mesh;
2. External parameters of 8 point clouds (confirmed to be correct);
3. Pictures from 8 angles;
The original point cloud is like this:

After point cloud registration, the above article Global registration optimization of G2O and multi view point cloud As shown in the picture.
realization
Based on OpenMVS, the main implementation code fragments are as follows:
void texture() {
int number_of_thread = 1;
Scene scene(number_of_thread);
Eigen::Matrix4d temp;
std::string t_inPath = "./test/scene/1_in.txt";
loadMat4(t_inPath, temp);
Eigen::Matrix3d _k = temp.block<3, 3>(0, 0); //Camera internal reference
//normalization
_k(0, 0) = _k(0, 0) / 1600;
_k(1, 1) = _k(1, 1) / 1600;
_k(0, 2) = _k(0, 2) / 1600;
_k(1, 2) = _k(1, 2) / 1600;
{ //Fill platform
Platform &plat = scene.platforms.AddEmpty();
//1,name
plat.name = "platform";
CameraIntern &cam = plat.cameras.AddEmpty();
cam.R = RMatrix::IDENTITY;
cam.C = Point3(0, 0, 0);
cam.K = _k;
//Eight camera poses are known
std::string matrix_path = "./test/scene/";
for (int i = 1; i <= vieNum; ++i)
{
std::string _path = matrix_path + std::to_string(i) + "_ex.txt";
Eigen::Matrix4d temp;
loadMat4(_path, temp);
Platform::Pose &pose = plat.poses.AddEmpty();
pose.C = temp.block<3, 1>(0, 3);
pose.R = temp.block<3, 3>(0, 0);
}
}
{//Fill images
std::string imag_path = "test/image/";
std::string matrix_path = "test/scene/";
//ImageArr imgarr = scene.images;
for (int i = 1; i <= vieNum; ++i) {
std::string t_img = imag_path + std::to_string(i) + ".jpg";
String _imgP(t_img);
Image &_img = scene.images.AddEmpty();
_img.ID = i-1;
_img.platformID = 0;
_img.cameraID = 0;
_img.poseID = i-1;
_img.LoadImage(_imgP);
scene.images.push_back(_img);
}
}
scene.mesh.Load("test/sm_mesh.ply");
unsigned nResolutionLevel = 0;
unsigned nMinResolution = 1280;
float fOutlierThreshold = 0.f;
float fRatioDataSmoothness = 0.0f;
bool bGlobalSeamLeveling = true;
bool bLocalSeamLeveling = true;
unsigned nTextureSizeMultiple = 0;
unsigned nRectPackingHeuristic = 0;
bool res = scene.TextureMesh(nResolutionLevel, nMinResolution, fOutlierThreshold,
fRatioDataSmoothness, bGlobalSeamLeveling, bLocalSeamLeveling,
nTextureSizeMultiple, nRectPackingHeuristic);
std::cout << "texture res:" << res << std::endl;
//scene.Save("./test/res_tex.mvs",ARCHIVE_TEXT);
scene.mesh.Save("test/res_tex.ply");
}According to the previous article Multi view 3D model texture mapping 01 As described in, you need to fill in the relevant data members in the Scene. Here I add a Platform and a camera, and then add a Pose of 8 cameras, which is in line with my actual use. I have a camera that takes images from 8 angles of the target, so I have only one Platform and one camera, but I restore the Pose of 8 cameras.
Then, eight images are filled, and the poseID of each Image needs to be strictly corresponding to the Pose in the Platform.
Finally, the Mesh is filled, and the Load() function is used directly.
Dispel doubts
For the two questions in the previous article and why I filled the Platform here in the above way, the main reasons are as follows:
Enter scene The implementation part of texturemesh () code is shown in its view selection module
imageData.UpdateCamera(scene.platforms);
A piece of code. Obviously, this is to update the camera parameters. More specifically, this is to update the member camera in the Image class; Further enter the code:
// compute the camera extrinsics from the platform pose and the relative camera pose to the platform
//Calculating camera external parameters from platform
Camera Image::GetCamera(const PlatformArr& platforms, const Image8U::Size& resolution) const
{
ASSERT(platformID != NO_ID);
ASSERT(cameraID != NO_ID);
ASSERT(poseID != NO_ID);
// compute the normalized absolute camera pose
//Extract the platform information corresponding to the image according to the platform ID
const Platform& platform = platforms[platformID];
Camera camera(platform.GetCamera(cameraID, poseID));
// compute the unnormalized camera
//Calculate the original camera internal parameters (before normalization, real camera internal parameters)
camera.K = camera.GetK<REAL>(resolution.width, resolution.height);
//Integrate the inside and outside of the camera into a 3 * 4 affine matrix (P=KR[I|-C])
camera.ComposeP();
return camera;
} // GetCamera
void Image::UpdateCamera(const PlatformArr& platforms)
{
camera = GetCamera(platforms, Image8U::Size(width, height));
} // UpdateCameraIt can be seen from the above code block that the member camera in the Image class is extracted and calculated from the Platform according to the corresponding ID, that is, Image::camera depends on the Platform! Finally, enter Platform Getcamera (cameraid, poseid) code implementation part:
// return the normalized absolute camera pose
Platform::Camera Platform::GetCamera(uint32_t cameraID, uint32_t poseID) const
{
const Camera& camera = cameras[cameraID];
const Pose& pose = poses[poseID];
// add the relative camera pose to the platform
Camera cam;
cam.K = camera.K;
cam.R = camera.R*pose.R;
cam.C = pose.R.t()*camera.C+pose.C;
return cam;
} // GetCameraIt can be seen from the above code that the camera in the Image is really involved in texture mapping, and the external parameters of the camera are jointly determined by the camera of the Platform and the corresponding pose.
So far, the above code has been explained:
- Part I [question 1]: the camera pose corresponding to each texture image is actually determined by the camera in the Platform and the pose in the Platform
- Part I [question 2]: it is not necessary to fill the camera in the implementation Image in the "external" code. No matter how to fill the data, it will be overwritten by the attributes in the Platform. Of course, if you have filled in palm form correctly
- The above source code also explains why in my own code, I just created a Camera of the Platform, and the created Camera rotation matrix is the unit matrix and the translation matrix is 0 - the Camera and pose of the Platform will participate in the calculation of the Camera in the Image at the same time. At this time, the pose of the Platform I filled in is the correct and real pose matrix corresponding to the Image, Therefore, it is unnecessary and impossible to fill Platfrom's Camera.
experiment
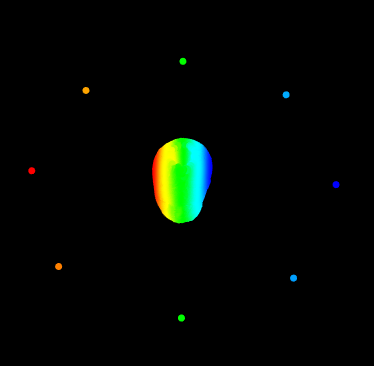
The relationship between the recovered camera pose and the global registration point cloud is as follows:
The Mesh results are shown in the figure below:
The composite texture corresponding to Mesh is as follows:

Reflection and summary
The above understanding of OpenMVS is not completely correct, and needs to be further improved. However, it has temporarily achieved its preliminary expected results.
Let's talk about foreign parameters. The external parameters of the point cloud represent the motion of the point cloud. In contrast, the inverse of the external parameters of the point cloud represents the motion of the corresponding camera. After all the point clouds are globally registered and unified into the world coordinate system, the inverse of each external parameter of the point cloud represents the pose matrix of the corresponding camera in the world coordinate system.
In addition, the camera I use is RGB-D camera, that is, the infrared camera is responsible for generating the point cloud, and the RGB camera is responsible for providing the texture map for the point cloud, that is, the coordinate system of the initial point cloud is under the infrared camera, and the texture map belongs to the RGB camera, so there is also the calibration between the infrared camera and the RGB color camera between the RGB-D camera modules. The calibration matrix here, The essence is the external parameter of the point cloud - the point cloud can only be mapped by transforming it to an RGB camera! It is precisely because the RGB-D camera is used that the matrix required by OpenMVS needs to be filled manually (personal understanding: OpenMVS restores the 3D model directly from the RGB image and then maps it. There is no external parameter from additional point cloud to RGB).
A little further, TexRecon It is also specially used to solve mesh texture mapping. Its input is also mesh +camera + texture map. Unlike in OpenMVS, camera in TexRecon is actually filled with external parameters of point cloud!! However, TexRecon will delete the original mesh during texture mapping, which may lead to additional holes in the original smooth mesh. In addition, TexRecon relies more on third parties (MVE, etc.), which is also the reason why it has not discussed the source code more deeply.
(the effect of TexRecon is not very good, no mapping is needed, or it is not completely correct to use it by yourself)
<Let There Be Color! Large-Scale Texturing of 3D Reconstructions>
Reserved pit:
If you have time and energy in the follow-up, you can further record your previous calibration and implementation process of the turntable, which is also the prequel of these articles.