Thread pool
What is a thread pool
Thread pool in Java is the most used concurrent framework, and almost all programs that need to execute tasks asynchronously or concurrently
Can use thread pools. In the development process, rational use of thread pool can bring three benefits.
First: reduce resource consumption. Reduce the consumption caused by thread creation and destruction by reusing the created threads.
Second: improve the response speed. When the task arrives, the task can be executed immediately without waiting for the thread to be created.
Third: improve the manageability of threads. Threads are scarce resources. If they are created without restrictions, they will not only consume system resources,
It will also reduce the stability of the system. The thread pool can be used for unified allocation, tuning and monitoring. However, we should make rational use of it
Thread pool, you must know its implementation principle like the back of your hand.
Thread pool role
Thread pool is designed for a large number of sudden burst threads. It serves a large number of operations through a limited number of fixed threads, reducing the time required to create and destroy threads, so as to improve efficiency.
If a thread takes a very long time, there is no need to use the thread pool (it is not impossible to operate for a long time, but not suitable). Moreover, we can't control the start, suspend, and abort of threads in the thread pool.
Classification of thread pools
ThreadPoolExecutor
Java is a language that naturally supports concurrency. Supporting concurrency means multithreading. The frequent creation of threads consumes resources in high concurrency and large amount of data, because Java provides thread pool. Before JDK1.5, the use of thread pool was very simple, but it has been greatly improved after JDK1.5. After JDK1.5, java.util.concurrent package is added. The addition of java.util.concurrent package is of great help to developers in developing concurrent programs and solving concurrency problems. This article mainly introduces and contracts the Executor interface. Although the Executor interface is a very old interface (JDK1.5 released in 2004), many programmers are still unfamiliar with some of its principles. Therefore, this article is written to introduce the Executor interface and consolidate their knowledge. If there are errors in the article, you are welcome to point out.
The topmost implementation of the Executor framework is the ThreadPoolExecutor class. The newScheduledThreadPool, newFixedThreadPool and newCachedThreadPool methods provided in the Executors factory class are just different from the constructor parameters of ThreadPoolExecutor. By passing in different parameters, you can construct a thread pool suitable for different application scenarios. How is its underlying principle implemented? This article introduces the running process of ThreadPoolExecutor thread pool.
corePoolSize: the size of the core pool. When a task comes, a thread will be created to execute the task. When the number of threads in the thread pool reaches the corePoolSize, the arriving task will be placed in the cache queue
maximumPoolSize: the maximum number of threads in the thread pool, which indicates the maximum number of threads that can be created in the thread pool;
keepAliveTime: indicates how long the thread will terminate if it has no task to execute.
Unit: the time unit of the parameter keepAliveTime. There are seven values. In the TimeUnit class, there are seven static attributes:
There are four ways to create thread pools
Java provides four kinds of thread pools through Executors (jdk1.5 parallel contracting), which are:
newCachedThreadPool creates a cacheable thread pool. If the length of the thread pool exceeds the processing needs, idle threads can be recycled flexibly. If there is no recyclable thread, a new thread will be created.
Case presentation:
newFixedThreadPool creates a fixed length thread pool, which can control the maximum concurrent number of threads. The exceeded threads will wait in the queue.
newScheduledThreadPool creates a fixed length thread pool to support scheduled and periodic task execution.
Newsinglethreadexecution creates a singleton thread pool. It only uses a unique worker thread to execute tasks, ensuring that all tasks are executed in the specified order (FIFO, LIFO, priority).
newCachedThreadPool
Create a cacheable thread pool. If the length of the thread pool exceeds the processing needs, you can flexibly recycle idle threads. If there is no recyclable thread, you can create a new thread. The example code is as follows:
// Unlimited thread pool jvm auto recycle
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int temp = i;
newCachedThreadPool.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(100);
} catch (Exception e) {
// TODO: handle exception
}
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
Summary: the thread pool is infinite. When the second task is executed, the first task has been completed. The thread executing the first task will be reused instead of creating a new thread each time.
newFixedThreadPool
Create a fixed length thread pool to control the maximum concurrent number of threads. The exceeded threads will wait in the queue. The example code is as follows:
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
final int temp = i;
newFixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId() + ",i:" + temp);
}
});
}
Summary: because the thread pool size is 3 and sleep is 2 seconds after each task outputs index, three numbers are printed every two seconds.
The size of the fixed length route pool is best set according to the system resources. Such as Runtime.getRuntime().availableProcessors()
newScheduledThreadPool
Create a fixed length routing pool to support regular and periodic task execution. The example code of delayed execution is as follows:
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 10; i++) {
final int temp = i;
newScheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println("i:" + temp);
}
}, 3, TimeUnit.SECONDS);
}
Indicates a delay of 3 seconds.
newSingleThreadExecutor
Create a singleton thread pool. It will only use a unique worker thread to execute tasks to ensure that all tasks are executed in the specified order (FIFO, LIFO, priority). The example code is as follows:
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
newSingleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println("index:" + index);
try {
Thread.sleep(200);
} catch (Exception e) {
// TODO: handle exception
}
}
});
}
Note: the results are output in sequence, which is equivalent to executing each task in sequence.
Principle analysis of thread pool
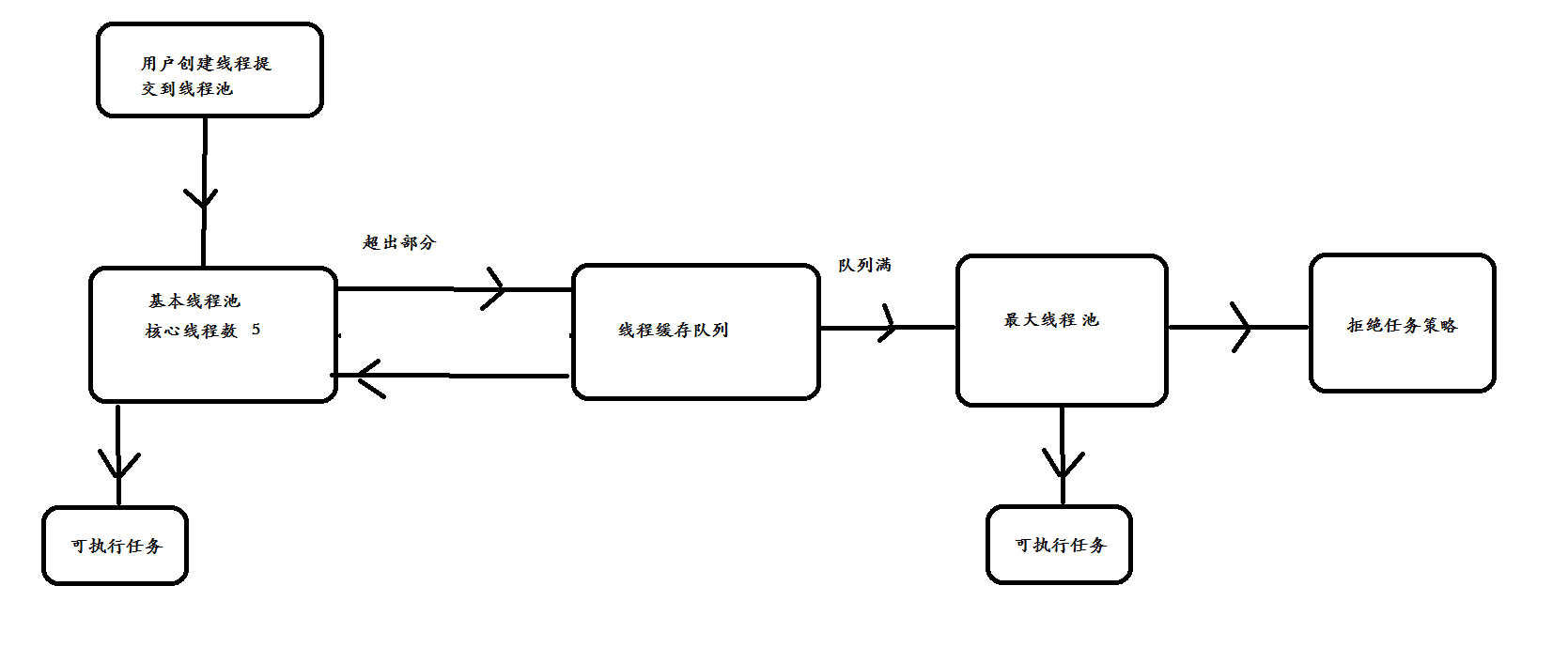
Submit a task to the thread pool. The processing flow of the thread pool is as follows:
1. Judge whether the core threads in the thread pool are executing tasks. If not (the core thread is idle or there are core threads not created), create a new worker thread to execute tasks. If the core threads are executing tasks, the next process is entered.
2. The thread pool determines whether the work queue is full. If the work queue is not full, the newly submitted task is stored in the work queue. If the work queue is full, proceed to the next process.
3. Judge whether all threads in the thread pool are working. If not, create a new working thread to execute the task. If it is full, it is left to the saturation strategy to handle the task.
Reasonably configure thread pool
To reasonably configure the thread pool, you must first analyze the task characteristics from the following perspectives:
Nature of tasks: CPU intensive tasks, IO intensive tasks and hybrid tasks.
Task priority: high, medium and low.
Task execution time: long, medium and short.
Task dependency: whether it depends on other system resources, such as database connection.
Tasks with different task properties can be processed separately with thread pools of different sizes. For CPU intensive tasks, configure as few threads as possible, for example, configure the thread pool of Ncpu+1 thread. For IO intensive tasks, because they need to wait for IO operations and threads are not always executing tasks, configure as many threads as possible, such as 2*Ncpu. If a hybrid task can be split, it can be split into a CPU intensive task and an IO intensive task. As long as the execution time difference between the two tasks is not too large, the throughput of the decomposed task is higher than that of the serial task. If the execution time difference between the two tasks is too large, it is not necessary to decompose. We can obtain the number of CPUs of the current device through the Runtime.getRuntime().availableProcessors() method.
Tasks with different priorities can be processed using the priority BlockingQueue. It allows high priority tasks to be executed first. It should be noted that if high priority tasks are always submitted to the queue, low priority tasks may never be executed.
Tasks with different execution times can be handled by thread pools of different sizes, or priority queues can be used to let tasks with short execution time execute first.
Tasks that depend on the database connection pool, because threads need to wait for the database to return results after submitting SQL. If the waiting time is longer, the CPU idle time is longer, then the number of threads should be set to be larger, so as to make better use of the CPU.
General summary Oh, there are other better ways. I hope you can leave a message. Thank you.
When the task is CPU intensive, the number of threads can be less configured, which is about the same as the number of CPU cores of the machine, so that each thread can execute the task
In IO intensive mode, most threads are blocked, so the number of threads and 2*cpu cores need to be configured
Name and explanation of operating system:
Some processes spend most of their time on computing, while others spend most of their time waiting for I/O,
The former is called computing intensive (CPU intensive) computer bound, and the latter is called I/O-Intensive, I/O-bound.
Depth of Java lock
Pessimistic lock, optimistic lock, exclusive lock
scene
When multiple requests operate the database at the same time, first change the order status to paid, add 200 to the amount, and duplicate notifications will be caused under the query conditions of concurrent scenarios at the same time.
SQL:
Update
Pessimistic lock and optimistic lock
Pessimistic lock: pessimistic lock believes that each operation will cause the loss of updates, and an exclusive lock is added each time.
Every time I go to get the data, I think others will modify it, so I lock it every time I get the data, so that others will block the data until it gets the lock. Many such locking mechanisms are used in traditional relational databases, such as row lock, table lock, read lock and write lock, which are locked before operation.
Select * from xxx for update;
Optimistic lock: optimistic lock is optimistic that each query will not cause update loss, and it is controlled by version field
Reentry lock
As a tool for concurrent sharing of data and ensuring consistency, locks are implemented in a variety of JAVA platforms (such as synchronized and ReentrantLock, etc.). These locks that have been written provide convenience for our development.
Reentry lock, also known as recursive lock, means that after the outer function of the same thread obtains the lock, the inner recursive function still has the code to obtain the lock, but it is not affected.
In JAVA environment, ReentrantLock and synchronized are reentrant locks
public class Test implements Runnable {
public synchronized void get() {
System.out.println("name:" + Thread.currentThread().getName() + " get();");
set();
}
public synchronized void set() {
System.out.println("name:" + Thread.currentThread().getName() + " set();");
}
@Override
public void run() {
get();
}
public static void main(String[] args) {
Test ss = new Test();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
}
}
public class Test02 extends Thread {
ReentrantLock lock = new ReentrantLock();
public void get() {
lock.lock();
System.out.println(Thread.currentThread().getId());
set();
lock.unlock();
}
public void set() {
lock.lock();
System.out.println(Thread.currentThread().getId());
lock.unlock();
}
@Override
public void run() {
get();
}
public static void main(String[] args) {
Test ss = new Test();
new Thread(ss).start();
new Thread(ss).start();
new Thread(ss).start();
}
}
Read write lock
comparison Locks in Java In the Lock implementation, the read-write Lock is more complex. Suppose your program involves read and write operations on some shared resources, and the write operations are not as frequent as the read operations. When there is no write operation, there is no problem for two threads to read a resource at the same time, so multiple threads should be allowed to read shared resources at the same time. However, if a thread wants to write these shared resources, no other thread should read or write to the resource. This requires a read / write Lock to solve this problem. Java 5 already contains read-write locks in the java.util.concurrent package. Nevertheless, we should understand the principle behind its implementation.
public class Cache {
static Map<String, Object> map = new HashMap<String, Object>();
static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
static Lock r = rwl.readLock();
static Lock w = rwl.writeLock();
// Get the value corresponding to a key
public static final Object get(String key) {
r.lock();
try {
System.out.println("Reading operation in progress,key:" + key + " start");
Thread.sleep(100);
Object object = map.get(key);
System.out.println("Reading operation in progress,key:" + key + " end");
System.out.println();
return object;
} catch (InterruptedException e) {
} finally {
r.unlock();
}
return key;
}
// Set the value corresponding to the key and return the old value
public static final Object put(String key, Object value) {
w.lock();
try {
System.out.println("Writing operation in progress,key:" + key + ",value:" + value + "start.");
Thread.sleep(100);
Object object = map.put(key, value);
System.out.println("Writing operation in progress,key:" + key + ",value:" + value + "end.");
System.out.println();
return object;
} catch (InterruptedException e) {
} finally {
w.unlock();
}
return value;
}
// Empty all contents
public static final void clear() {
w.lock();
try {
map.clear();
} finally {
w.unlock();
}
}
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
Cache.put(i + "", i + "");
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
Cache.get(i + "");
}
}
}).start();
}
}
CAS NO lock mechanism
(1) Compared with locks, the use of comparison exchange (hereinafter referred to as CAS) will make the program look more complex. However, due to its non blocking nature, it is inherently immune to deadlock problems, and the interaction between threads is much smaller than that based on locks. More importantly, the lock free method has no system overhead caused by lock competition and frequent scheduling between threads. Therefore, it has better performance than the lock based method.
(2) Lock free benefits:
First, in the case of high concurrency, it has better performance than locked programs;
Second, it is inherently deadlock immune.
With these two advantages, it is worth taking the risk of using lockless concurrency.
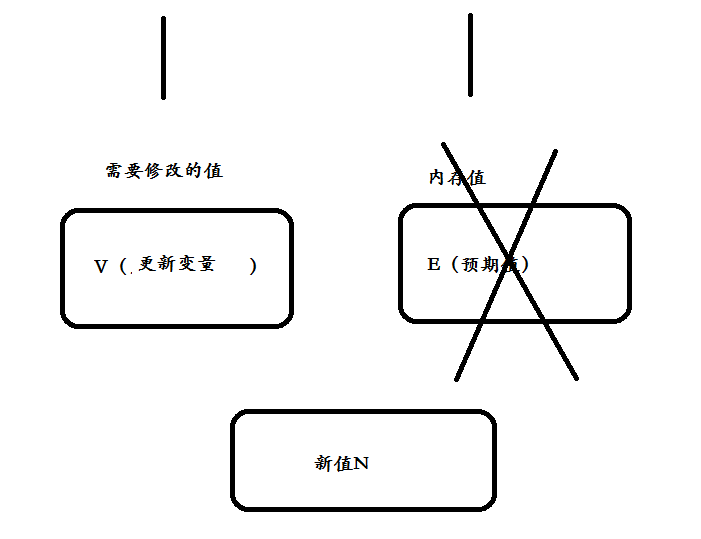
(3) The process of CAS algorithm is as follows: it contains three parameters CAS(V,E,N): V represents the variable to be updated, e represents the expected value, and N represents the new value. The value of V is set to n only when the value of V is equal to the value of E. if the value of V is different from the value of E, it indicates that other threads have updated, and the current thread does nothing. Finally, CAS returns the true value of the current v.
(4) CAS operation is carried out with an optimistic attitude. It always thinks that it can successfully complete the operation. When multiple threads use CAS to operate a variable at the same time, only one will win and update successfully, and the rest will fail. The failed thread is not suspended. It is only informed of the failure and allowed to try again. Of course, the failed thread is also allowed to give up the operation. Based on this principle, even if CAS operation has no lock, it can find the interference of other threads to the current thread and handle it appropriately.
(5) In short, CAS requires you to give an additional expected value, that is, what you think this variable should look like now. If the variable is not what you think, it means that it has been modified by others. Just read it again and try to modify it again.
(6) At the hardware level, most modern processors already support atomized CAS instructions. After JDK 5.0, virtual machines can use this instruction to implement concurrent operations and concurrent data structures, and this operation can be said to be ubiquitous in virtual machines.
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
for (;;) {
//Get current value
int current = get();
//Set expectations
int next = current + 1;
//Call the Native method compareAndSet to perform CAS operations
if (compareAndSet(current, next))
//The expected value will be returned only after success, otherwise the wireless loop
return next;
}
}
Spin lock
Spin lock is realized by making the current thread execute in the loop body continuously. When the conditions of the loop are changed by other threads, it can enter the critical area. as follows
private AtomicReference<Thread> sign =new AtomicReference<>();
public void lock() {
Thread current = Thread.currentThread();
while (!sign.compareAndSet(null, current)) {
}
}
public void unlock() {
Thread current = Thread.currentThread();
sign.compareAndSet(current, null);
}
public class Test implements Runnable {
static int sum;
private SpinLock lock;
public Test(SpinLock lock) {
this.lock = lock;
}
/**
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
SpinLock lock = new SpinLock();
for (int i = 0; i < 100; i++) {
Test test = new Test(lock);
Thread t = new Thread(test);
t.start();
}
Thread.currentThread().sleep(1000);
System.out.println(sum);
}
@Override
public void run() {
this.lock.lock();
this.lock.lock();
sum++;
this.lock.unlock();
this.lock.unlock();
}
}
When a thread calls this non reentrant spin lock to lock, it is OK. When lock() is called again, because the holding reference of the spin lock is no longer empty, the thread object will mistakenly think that another thread holds the spin lock
CAS atomic operation is used. The lock function sets the owner as the current thread and predicts that the original value is null. The unlock function sets the owner to null and the predicted value is the current thread.
When the second thread calls the lock operation, because the owner value is not empty, the loop will be executed until the first thread calls the unlock function to set the owner to null, and the second thread can enter the critical area.
Because the spin lock just keeps the current thread executing the loop body without changing the thread state, the response speed is faster. However, when the number of threads keeps increasing, the performance decreases significantly, because each thread needs to execute and occupies CPU time. If the thread competition is not fierce, and the lock is maintained for a period of time. Suitable for spin lock.
Distributed lock
If you want to ensure data synchronization in different JVMs, use distributed locking technology.
There are database implementation, cache implementation and Zookeeper distributed lock