Multithreading
1. Thread overview
Process:
A process is a running activity of a program on a data set in a computer,
It is the basic unit of resource allocation and scheduling in the operating system.
A process can be simply understood as a program running in the operating system.
Thread:
A thread is an execution unit of a process,
A thread is a single sequential control flow in a process,
A thread is an executing branch of a process.
A process is a container for threads. A process has at least one process.
There can also be multiple threads in a process.
In the operating system, resources are allocated in the unit of process, such as virtual space, file descriptor and so on.
Each thread has its own thread stack, its own register environment and its own thread local storage.
Main and sub threads:
JVM When starting, a main thread will be created, which is mainly responsible for execution main method,
The main thread is running main Method's thread
Java Threads in are not isolated, and there are some connections between threads.
If in A Created in thread B Thread, called B Thread is A A child thread of a thread, A Thread is B The parent thread of the thread.
2. Serial, parallel and concurrent


Concurrency can improve the efficiency of transaction processing Parallelism is a more rigorous and ideal concurrency From a hardware perspective, if a single core CPU,When a processor can only execute one thread at a time, The processor can use time slice rotation technology to make CPU Quickly switch between threads, For users, it feels like three threads executing at the same time. If it is multi-core CPU,You can assign different to different threads CPU Kernel.
There are two ways to create threads:
1.definition Thread Subclass of class 2.Define a Runnable Implementation class of interface Note: there is no essential difference between the two ways of creating threads
package test.Thread;
/*
Define a class to inherit Thread
*/
public class MyThread extends Thread {
/*
Override the run() method in the parent class
run()The code in the method body is the task to be executed by the sub thread
*/
@Override
public void run(){
super.run();
System.out.println("This is what the child thread prints");
}
}
public class test {
public static void main(String[] args) {
System.out.println("JVM start-up main Threads, main Thread execution main method");
//Create child thread object
MyThread thread=new MyThread();
//Start thread
thread.start();
/*
Call the start() method of the thread to start the thread. The essence of starting the thread is to request the JVM to run the corresponding thread,
When this thread runs is determined by the thread Scheduler scheduler
Note: the end of the start() method call does not mean that the child thread starts running
The newly opened thread executes the run() method
If multiple threads are started, the order in which start() is called is not necessarily the order in which the threads are started
The result of multithreading is independent of the code call order
*/
System.out.println("main Other code behind the thread....");
}
}
Verify the randomness of multithreading results
package test.Thread.p2;
public class MyThread2 extends Thread{
@Override
public void run(){
try {
for(int i=0;i<=10;i++){
System.out.println("sub thread:"+i);
int time= (int) (Math.random()*1000);
Thread.sleep(time); //Thread sleep, in ms
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
package test.Thread.p2;
/*
Demonstrate the randomness of running results
*/
public class test {
public static void main(String[] args) {
MyThread2 thread2=new MyThread2();
thread2.start();//Open child thread
//The current is the main thread
try {
for(int i=0;i<=10;i++){
System.out.println("main---:"+i);
int time= (int) (Math.random()*1000);
Thread.sleep(time); //Thread sleep, in ms
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Create a thread by implementing the Runnable interface
package test.Thread.p3;
/*
When a Thread class already has a parent class, you cannot create a Thread in the form of inheriting the Thread class. You can use the form of implementing the Runnable interface
1.Define and implement Runnable interface
*/
public class MyRunnable implements Runnable{
//2. Rewrite the run method in the Runnable interface. The run method is the code to be executed by the child thread
@Override
public void run() {
for(int i=1;i<=100;i++){
System.out.println("sub thread --> "+i);
}
}
}
package test.Thread.p3;
public class test {
public static void main(String[] args) {
//3. Create the implementation class object of Runnable interface
MyRunnable runnable=new MyRunnable();
//Create thread object
Thread thread=new Thread(runnable);
//Open thread
thread.start();
//The current is the main thread
for (int i=1;i<=100;i++){
System.out.println("main -->"+i);
}
//Sometimes, when calling the Thread(Runnable) constructor, the argument will also pass the anonymous inner class object
Thread thread2=new Thread(new Runnable() {
@Override
public void run() {
for (int i=1;i<=100;i++){
System.out.println("sub--->"+i);
}
}
});
thread2.start();
}
}
The same piece of code may be executed by different threads, so the current thread is relative
The return value of the currentThread method of the current thread is the thread object when the code is running
Note: the current thread is the thread that calls this code
package test.Thread.p4;
/*
Define thread class
Print the current thread name in the constructor method and run() method respectively
*/
public class SubThread1 extends Thread{
public SubThread1(){
System.out.println("The constructor prints the name of the current thread:"+Thread.currentThread().getName());
}
@Override
public void run(){
System.out.println("run Method to print the name of the current thread:"+Thread.currentThread().getName());
}
}
package test.Thread.p4;
/*
Just pay attention to one thing: the current thread is the thread that calls this code
*/
public class test01CurrentThread {
public static void main(String[] args) {
System.out.println("main Method to print the current thread"+Thread.currentThread().getName());
//Create a sub thread and call the SubThread1 construction method,
// Call the constructor in main thread, so the output thread in the method is main thread.
SubThread1 s1=new SubThread1();
s1.start();//Start the child thread, and the child thread will call the run() method, so the current thread output in the run method is thread-0 (child thread)
s1.run();//The run method is called directly in the main method without starting a new thread, so the current thread output in the run method is the main thread
}
}
A complex case of currentThread
package test.Thread.p5;
public class SubThread2 extends Thread{
public SubThread2(){
System.out.println("In the construction method, Thread.currentThread().getName() :"+Thread.currentThread().getName());
System.out.println("Construction method,this.getName() :"+this.getName());
}
@Override
public void run(){
System.out.println("run In the method, Thread.currentThread().getName() :"+Thread.currentThread().getName());
System.out.println("run method,this.getName() :"+this.getName());
}
}
package test.Thread.p5;
public class test02currentThread {
public static void main(String[] args) throws InterruptedException {
//Create child thread object
SubThread2 t2 = new SubThread2();
t2.setName("t2");//Set thread name
t2.start();
Thread.sleep(500);
//The formal parameter of Thread(Runnable) construction method is the Runnable interface, and the actual parameter passed during call is the implementation class object of the interface
// Thread class is the implementation class of Runnable interface
Thread t3=new Thread(t2);//This is actually the Runnable interface implementation class object passed
// t2 is the parent class of t3. The construction method of the parent class will not be executed when it is created
t3.start();//After the thread is started, this in the run method is the t2 implementation class object we passed. Why?
//From the source code of Thread class, we can see that the run() method of Thread class has a judgment. If the target parameter is passed when implementing the class and is not empty
//Execute the run method of target, so this we see here is t2
System.out.println("t3 : "+t3.getName());//The name of t3 is Thread-1, not t2
}
}
Operation results:
In the construction method, Thread.currentThread().getName() :main
Construction method,this.getName() :Thread-0
run In the method, Thread.currentThread().getName() :t2
run method,this.getName() :t2
t3 : Thread-1
run In the method, Thread.currentThread().getName() :Thread-1
run method,this.getName() :t2
public
class Thread implements Runnable {
@Override
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
@Override
public void run() {
if (target != null) {
target.run();
}
}
}
Setname() / getname() of Thread
thread.setName(Thread name)//Set thread name thread.setName()//Return thread name Setting the thread name is helpful to program debugging and improve the readability of the program. It is suggested to set a name for each thread that can reflect the thread function
The isAlive method tests the thread activity state
thread. isAlive()//Determines whether the current thread is active The active state is that the thread is started and not terminated
sleep method
Thread.sleep(Msec );//Lets the current thread sleep for the specified number of milliseconds The current thread refers to Thread.currentThread()Thread returned //In the run method of the sub thread, if there are no detected exceptions (compile time exceptions) to be processed, only capture processing can be selected, and processing cannot be thrown //Because the Thread we inherit overrides the run method of the Thread class, and the Thread class is capture, we can only choose capture processing
Simple timer
package test.Thread.sleep;
/*
A simple completion timer
*/
public class SimpleTimer {
public static void main(String[] args) throws InterruptedException {
int remaining = 10; //Start timing from 60 seconds
// //Read main method parameters
// if (args.length==1){
// remaining = Integer.parseInt(args[0]);
// }//You can set parameters in the Argument of editconfiguration of run
while(true){
System.out.println("also:"+remaining+"second");
if(remaining<0){
break;
}
remaining--;
Thread.sleep(1000);//Thread sleep
}
System.out.println("Timing complete!!");
}
}
getId() method
thread.getId( )You can get the unique identification of the thread Note: after a thread with a certain number runs, the number may be used by subsequent threads restart JVM After, the number of the same thread may be different
yieId() method
thread.yieId( ) // Discard current CPU resources
setPriority() method
thread.setPriority( )//Set thread priority java The value range of thread priority is 1~10,If it exceeds this range, an exception will be thrown IllegalArgumentException. In the operating system, the higher priority thread gets CPU The greater the probability of resources Thread priority is essentially a prompt message to the thread scheduler, so that the scheduler can decide which threads to schedule first, Note: there is no guarantee that priority threads will run first Java Improper priority setting or abuse may cause some threads to never run, that is, thread starvation The priority of threads is not set as high as possible. In general, ordinary priority is used(The default value is 5)That is, it is not necessary to set the priority of threads during development The priority of threads is inherited, B Thread inherits A Thread, then B Thread priority and A Same thread
interrupt method ()
//You can interrupt a thread, just mark the thread as an interrupt, and the thread has no real interrupt
//Note: calling the interrupt() method only prints a stop flag on the current thread, not really stopping the thread
//The thread has an isinterrupted() method, which returns the thread interrupt flag
@override
public void run(){
for(int i=1;i<=10000;i++){
if(this.isinterrupted()){
sout("The flag of the current thread interrupt is true,I'm quitting")
//break; // Interrupt the loop, the run() method is executed, and the sub thread runs
return; //Directly end the execution of the current run() method
}
}
}
setDaemon() method
/*
Function: set the thread as a daemon thread
Java Threads in are divided into user threads and daemon threads
A daemon thread is a thread that provides services to other threads. For example, garbage collection (GC) is a typical daemon thread
The daemon thread cannot run alone. When there are no other user threads in the JVM and there are only daemon threads, the daemon thread will be automatically destroyed and the JVM will exit
Note: it takes some time to destroy the daemon thread. The daemon thread will still run before it is completely destroyed
The code for setting the daemon thread should be before the thread starts
*/
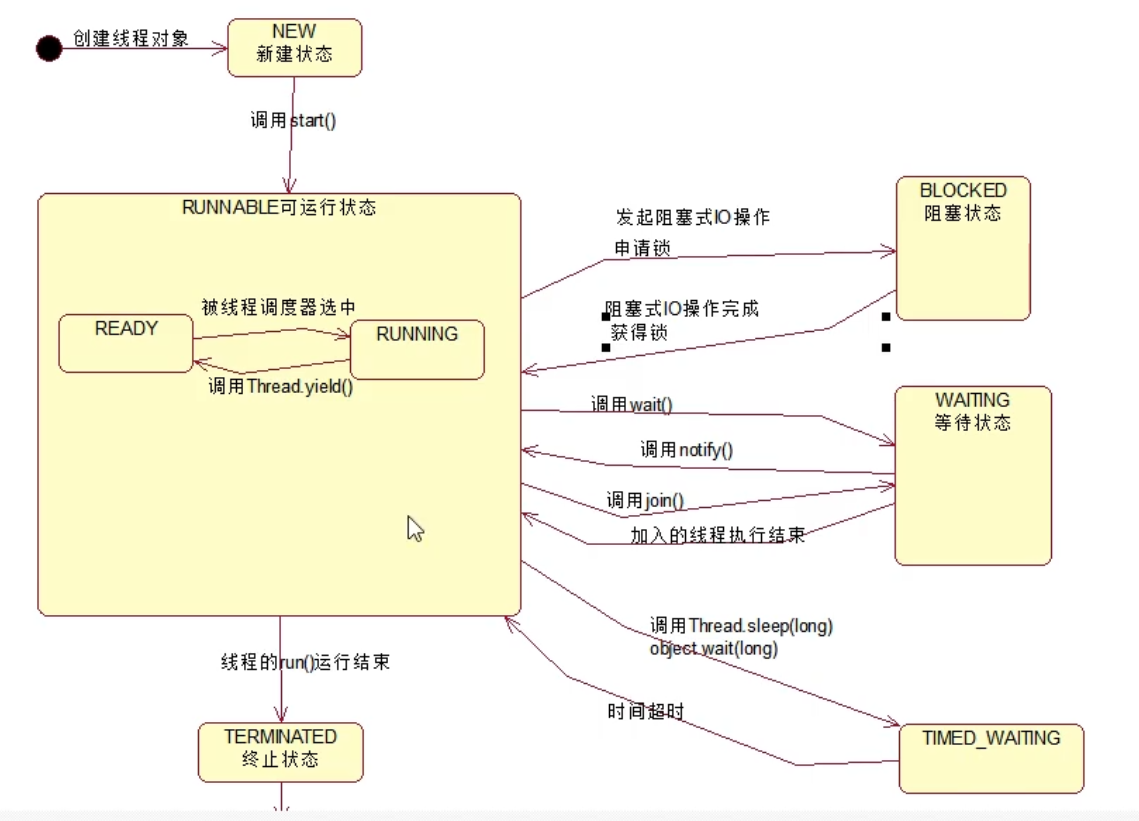
Thread life cycle
The life cycle of a thread is the birth and death of the thread, that is, the state of the thread
Thread life cycle can be getState()Method to obtain
The status of the thread is Thread.State Enumeration types are defined in the following ways:
//NEW status,
Create a new state, create a thread object, and call start()Status before startup
//RUNNABLE status,
Runnable state, which is a composite state, including: READY and RUNNING Two states.
//READY status,
The thread can be scheduled by the thread scheduler to make it in RUNNING Status.
//RUNNING status,
Indicates that the thread is executing.
Tread.yieId()Method can transfer the thread from RUNNING State transition to READY state
//BLOCKED blocking status,
Thread initiates a blocked I/O Operation, or apply for exclusive resources occupied by other threads, and the thread will be converted to BLOCKED Blocking state
Threads that are blocked do not occupy CPU Resources, when blocked I/O After the operation is completed, or the thread obtains the resources it applies for, the thread can turn to RUNNABLE.
//WAITING state,
Thread executed object.wait(),thread.join()Method converts the thread to WAITING Waiting state,
implement object.notify()Method, or after the added thread is executed, the current thread will be converted to RUNNABLE state
//TIME_WAITING status,
And WAITING The status is similar. They are all waiting. The difference is that the thread in this state will not wait indefinitely,
If the thread does not complete the desired operation within the specified time range, the thread will automatically convert to RUNNABLE.
//TERMINATED status
The thread is in a terminated state
Thread state diagram
Advantages and risks of multithreading
Advantages:
1.Improve system throughput(Throught), Multithreaded programming can make a process have more than one concurrency(concurrent,That is, at the same time)Operation of
2.Improve responsiveness(Responsiveness), Web The server will use some special threads to handle users' requests,
Shorten the waiting time of users.
3.Make full use of multi-core(Multicore)Processor resources, Multithreading can make full use of CPU Resources can avoid resource waste
Risk:
1.Thread safety(Thread safe)problem, When multithreading shares data, if correct concurrent access control measures are not taken,
Data consistency problems may arise, such as reading dirty data(Expired data)Problems, such as missing data updates.
2.Thread activity issues, Due to the defects of the program itself or the scarcity of resources, the thread has been in a non-stop state RUNNABLE State, which is the problem of thread activity,
Common active faults are as follows:
1.deadlock(Deadlock), Like fighting between Snipes and mussels
2.Lock up(Lockout), Similar to the sleeping beauty story, if the prince dies, the sleeping beauty has been in a deep sleep
3.Livelock(LiveLock), It's like a kitten biting its tail in circles
4.hunger(Starvation),Similar to the strong chicks always grab food from the mother bird's mouth, the weak chicks can't grab food and starve to death
3.Context switching(Context Switch), The processor switches from executing one thread to executing another thread
4.Reliability, A thread may cause JVM Unexpected termination, and other threads cannot execute.
Thread safety issues
Non thread safety: it mainly refers to that when multiple threads operate on the instance variable of the same object, the value will be changed and the value will not be synchronized
Thread safety is mainly manifested in three aspects: atomicity, visibility and order
1.Atomicity
atom(Atomic)It means indivisibility. The indivisibility of atomic operation has two meanings:
1.visit(Read, write)For the operation of a shared variable, from the perspective of other threads, the operation is either completed or has not yet occurred,
That is, other threads cannot see the intermediate result of the current operation.
2.Atomic operations that access the same set of variables cannot be interleaved
For example: from real life ATM Machine withdrawal, for users, either the operation is successful, the user's balance is reduced, and a transaction record is added;
Or you didn't get the money, which is equivalent to that the withdrawal operation didn't happen.
Java There are two ways to achieve atomicity: 1.Use lock
2.Using processor CAS(Compare and Swap)instructions
Locks are exclusive, ensuring that shared variables can only be accessed by one thread at a time.
CAS Instructions are directly in hardware(Processor and memory)Atomic operation is realized at the level of hardware lock.
//A thread safe AtomicInteger class is provided in Java to ensure the atomicity of operation
static class MyInt{
//int num;
AtomicInteger num=new AtomicInteger();
public int getNum(){
return num.getAndIncrement();//First return and then add one
//return num++;
/*
Implementation steps of auto increment operation:
Read num value
num Self increasing
Assign the self increasing value to the num variable
*/
}
}
2.visibility
In a multithreaded environment, after a thread updates a shared variable, other subsequent threads may not be able to read the updated results immediately,
This is another form of thread safety: visibility(visibility).
If a thread updates a shared variable, other threads accessing the variable can read the updated result,
Call this thread's updates to shared variables visible to other threads; otherwise, call this thread's updates to shared variables invisible to other threads.
Multithreaded programs may cause other threads to read old data because of visibility problems(Dirty data).
package test.Thread.threadsafe;
import java.util.Random;
/*
Test thread visibility
*/
public class Test02 {
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
new Thread(task).start();
Thread.sleep(3000);
//The main thread cancels the child thread after 3 seconds
task.cancel();
/*
The following situations may occur:
In the main thread, the task. is called. The cancel () method modifies the toCancel variable of the task object to true
It is possible that the child thread cannot see the modification made by the main thread to toCancel. In the child thread, the toCancel variable is always false
The reason why the toCancel sub variable of the thread cannot be seen is as follows:
1.JIT The compiler optimizes the method in the while loop, which may be:
if(!toCancel){
while(true){
if(doSometing()){
......
}
}
}
Conditions that may lead to an endless cycle
2.It may be related to the storage system of the computer. Suppose there are two cpu cores running main threads and sub threads respectively,
The cpu running the sub thread may not be able to read the data of the cpu of the main thread immediately
*/
}
static class MyTask implements Runnable{
private boolean toCancel=false;
@Override
public void run() {
while(!toCancel){
if (doSometing()){
}
if (toCancel){
System.out.println("Task cancelled");
}
else {
System.out.println("The task ends normally");
}
}
}
private boolean doSometing(){
System.out.println("Perform a task");
try {
Thread.sleep(new Random().nextInt(1000));//Time to simulate task execution
} catch (InterruptedException e) {
e.printStackTrace();
}
return true;
}
public void cancel(){
toCancel=true;
System.out.println("Received a message to cancel the thread");
}
}
}
3.Order
Order(Ordering)It refers to the memory access operation performed by a thread running on a processor under what circumstances
Other threads running on another processor appear to be out of order(Out of Order).
Out of order means that the order of memory access operations appears to have changed
The concept of reordering:
In the environment of multi-core processors, the order of operation execution may not be guaranteed by the written sequential structure:
1.The compiler may change the order of the two operations;
2.The processor may not execute in the order of the object code;
This is the order of multiple operations performed on one processor when viewed by other processors,
The order specified by the object code may be different, which is called reordering.
Reordering is an optimization of orderly operation of memory access, which can improve the performance of single threaded programs without affecting the correctness of single threaded programs.
However, it may affect the correctness of multithreaded programs, which can lead to thread safety problems.
Reordering is similar to the visibility problem and is not inevitable.
Several concepts related to memory operation sequence:
Source code order: the memory access order specified in the source code.
Program order: the order of memory access specified by the object code running on the processor
Execution order: the actual execution order of memory access operations on the processor
Perceptual order: the order of memory access operations perceived by a given processor and other processors
Reordering can be divided into instruction reordering and storage subsystem reordering.
Instruction reordering mainly consists of JIT Compiler, caused by processor, refers to that the program order is different from the execution order
The reordering of storage subsystem is caused by cache and write buffer, and the perceived order is inconsistent with the execution order
---------------------------------------------------------------------------------------------------------------
4.Instruction reordering
When the source code sequence is inconsistent with the program sequence, or the program sequence is inconsistent with the execution sequence,
Let's say there was an instruction reordering(Instruction Reorder).
Instruction rearrangement is an action. It does adjust the order of instructions. The object of reordering is instructions.
1)Javac Editors generally do not perform instruction reordering, and JIT The editor may perform instruction reordering.
2)The processor may also perform instruction reordering, making the execution order inconsistent with the program order.
//Instruction rearrangement will not affect the correctness of the results of single threaded programs, but may lead to unexpected results of multiple threads
5.Storage subsystem reordering
Storage subsystem refers to write buffer and cache.
Cache(Cache)yes CPU A cache designed in order to match the processing speed of main memory.
Write buffer(Store buffer,Writer buffer)Used to improve the efficiency of write cache operations
Even if the processor performs two memory access operations strictly in the order of the program, under the action of the storage subsystem,
The perceived order of these two operations by other processors is inconsistent with the program order, that is, the order of these two operations looks different
It seems to have changed(illusion),This phenomenon is called storage subsystem reordering.
//The reordering of storage subsystem does not really adjust the order of instruction execution, but creates an illusion that the order of instruction execution is adjusted.
The objects reordered by the storage subsystem are the result of memory operations
From the processor's point of view, reading memory is from the specified RAM Loading data into a register from an address is called Load operation;
Write memory is represented by storing data to a specified address RAM In the storage unit, it is called Store operation;
There are four possibilities for memory reordering:
1.LoadLoad Reordering, a processor that performs two read operations successively L1 and L2,
Other processors may perceive these two memory operations in the same order L2->L1
2.StoreStore Reordering, a processor performs two write operations successively W1 and W2,
Other processors may perceive two memory operations in the same order W2->W1
3.LoadStore To reorder, a processor reads memory first L1,Then perform the write memory operation W1,
Other processors may perceive these two memory operations in the same order W1->L1
4.StoreLoad To reorder, a processor performs a write memory operation first W1,Then read the memory L1,
Other processors may perceive these two memory operations in the same order L1->W1
Memory reordering is related to the specific processor microarchitecture. Processors of different architectures allow different memory reordering
Memory reordering can cause thread safety problems, assuming that there are two shared variables
int data=0; boolean ready=false;
---------------------------------------------------------
Processor 1 || Processor 2
---------------------------------------------------------
data=1; //s1 ||
ready=true; //s2 ||
----------------------------------------------------------
|| while(!ready){} //L3 operation
|| sout(data); //L4 operation
----------------------------------------------------------
Seemingly serial semantics
JIT The compiler, processor and storage subsystem execute instructions according to certain rules, The results of memory operations are reordered, and single threaded programs create an illusion, Instructions are executed in the order of the source code. This illusion is called seemingly serial semantics. It does not guarantee the correctness of the program in a multithreaded environment. /* In order to ensure that seemingly serial semantics, statements with data dependencies will not be reordered, Only statements that do not have data dependencies are reordered. If two operations(instructions)Access the same variable and one of the operations(instructions)For write operations, Then there is a data dependency between the two operations(Data dependency). For example: x=1; y=x+1; The operand of the latter statement, Contains the execution result of the previous statement; y=x; x=1; Read first x Variable, update again x The value of the variable. x=1;x=2; Two statements write to a variable at the same time If there is no data dependency, it may be reordered, such as: double price = 45.8; int quantity = 10; The first two may be rearranged double sum=price*quentity; However, statements with control dependencies allow rearrangement: A statement(instructions)The execution result of determines another statement(instructions)Whether it can be implemented, These two statements(instructions)There are control dependencies(Control Dependency). If in if Statement, rearrangement is allowed, and the processor may execute first if Code block, Re judgment if Is the condition true It can be understood as: single thread, first get the results of both parts(Boolean and real results),Then judge whether the real results are displayed
Ensure the order of memory access
have access to Volatile keyword synchronized Keyword order means that the perceived order is consistent with the source order
Java Memory Model

1.Each thread has its own stack space
2.Each thread can access heap memory
3.Computer CPU Do not read data directly from main memory, CPU When reading data,
First read the data of main memory to Cache Cache, and then Cache Data read in Register Register
4.JVM Shared data in may be assigned to Register Register,
each CPU Have their own Register register
One CPU Cannot read other CPU The contents of the register,
If two threads run on different CPU Up,
This shared data is allocated to registers, which will cause visibility problems.
5.even if JVM The shared data in is allocated to main memory, and the visibility of the data cannot be guaranteed,
CPU Do not access main memory directly, but through Cache Caching,
A thread running on a processor may update data
Just update to the processor's write buffer(Store Buffer),Not yet Cache Cache,
Not to mention main memory.
Another processor cannot read the contents of the write buffer of the processor,
A thread running on another processor cannot see the processor's updates to the shared data.
6.One processor Cache(Cache)Cannot read from another processor Cache,
However, a processor can pass the cache consistency protocol(Cache Cocherence Protocol)
To read the data in the cache of other processors and update the read data to the cache of the processor Cache Yes.
This process is called cache synchronization.
Cache synchronization enables threads running on a processor to read
In addition, the thread running on another processor updates the shared data to ensure visibility.
In order to ensure visibility, it is necessary for a processor's updates to the shared data to be finally written to the processor Cache, This process is called flushing processor cache */
The Java memory model can be abstracted as:
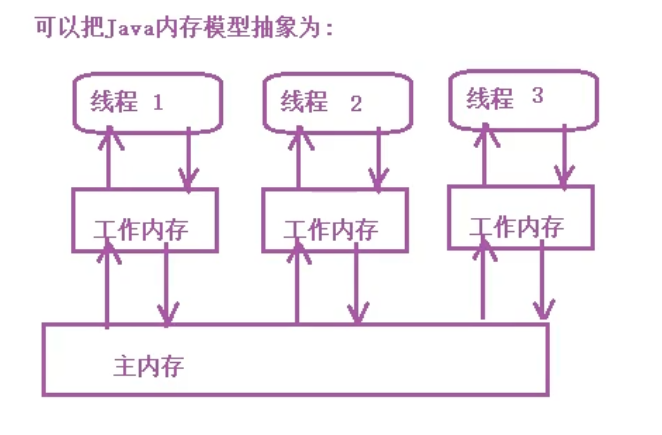
regulations: The shared data between each thread is stored in main memory Each thread has a private local memory(Working memory),The working memory of a thread is an abstract concept, It is not real. It covers the optimization of buffers, registers and other hardware. Each thread reads the data from the main memory to the local working memory and saves a copy of the shared data Threads process data in their own working memory, which is only visible to the current thread and not to other threads.
Thread synchronization
Introduction to thread synchronization mechanism
Thread synchronization mechanism is a mechanism for coordinating data access between threads, which can ensure thread safety. Java The thread synchronization mechanisms provided by the platform include:lock,Volatile keyword, final keyword, static Keywords and related API,as Object.wait()/Object.notify()etc.
3. Lock overview
The premise of thread safety problem is that multiple threads access shared data concurrently. Converting concurrent access of multiple threads to shared data into serial access, That is, a shared data can only be accessed by one thread, A lock is a lock that reuses this idea to ensure thread safety. It can be understood as a license for the protection of shared data input, For shared data protected by the same license, any thread wants to access these shared data, You must hold the license first. A thread can only hold the license, To access these shared data, and a license can only be held by one thread; The license thread must release the license it holds after ending access to shared data. A thread must obtain a lock before accessing shared data, The thread that obtains the lock is called the thread that holds the lock. A lock can only be held by one thread at a time, The lock holding thread obtains the lock and releases the lock, During this time, the code executed by the lock is called the critical area(Critical Section)Locks are exclusive(Exclusive), A lock can only be held by one thread at a time. This lock is called exclusive lock or mutex lock(Mutex). JVM The lock is divided into internal lock and display lock sychronized Keyword implementation; Show lock pass java.concurrent.locks.Lock Interface implementation class.

Function of lock
Lock can realize the safe access to shared data and ensure the atomicity, visibility and order of threads.
Atomicity is guaranteed through mutual exclusion. A lock can only be held by one thread,
This ensures that the code in the critical area can only be executed by one thread at a time,
The operation performed by the critical area code is naturally indivisible,
That is, it has atomicity.
The guarantee of visibility is to flush the processor's cache through the write thread
And the read thread refreshing the cache of the processor,
stay java In the platform, the acquisition of the lock implies the action of refreshing the processor cache,
The release of the lock implies an action to flush the processor cache.
The lock can guarantee the order, and the operation performed by the write thread in the critical area,
In the critical area of read thread execution, it seems that it is executed completely in the order of source code.
Note: to use locks to ensure thread security, the following conditions must be met:
These threads must use the same lock when accessing shared data.
Even threads reading shared data need to use synchronization locks,
Lock related concepts
1.Reentrant reentrant(Reentrancy)Describe a problem: When a thread holds the lock, it can be locked again(many times)Apply for the lock If a thread can continue to successfully apply for a lock when it holds it, Call the lock reentrant, otherwise call the lock non reentrant. 2.Lock contention and scheduling Java The internal lock in the platform belongs to unfair lock, which is displayed Lock Locks support both fair and non fair locks. three.Lock granularity the number of shared data that a lock can protect is called lock granularity. Lock protection has a large amount of shared data. It is said that the granularity of the lock is coarse, otherwise it is said that the granularity of the lock is fine. If the lock granularity is too thick, the thread will wait unnecessarily when applying for a lock. If the granularity of the lock is too fine, it will increase the overhead of the granularity of the lock.
Internal lock: synchronized keyword
Java Each object in has an internal lock associated with it(Intrinsic lock).
This lock is also called a monitor(Monitor),This lock is an exclusive lock,
It can guarantee atomicity, visibility and order. The lock is internal synchronized keyword
Realized.synchronized Keyword to modify the method.
Syntax for decorating code blocks:
synchronized( Object lock ){
Synchronization code block, you can share data in the synchronization code block
}
Modifying instance methods is called synchronous instance methods, and modifying static methods is called synchronous static methods
synchronized code block
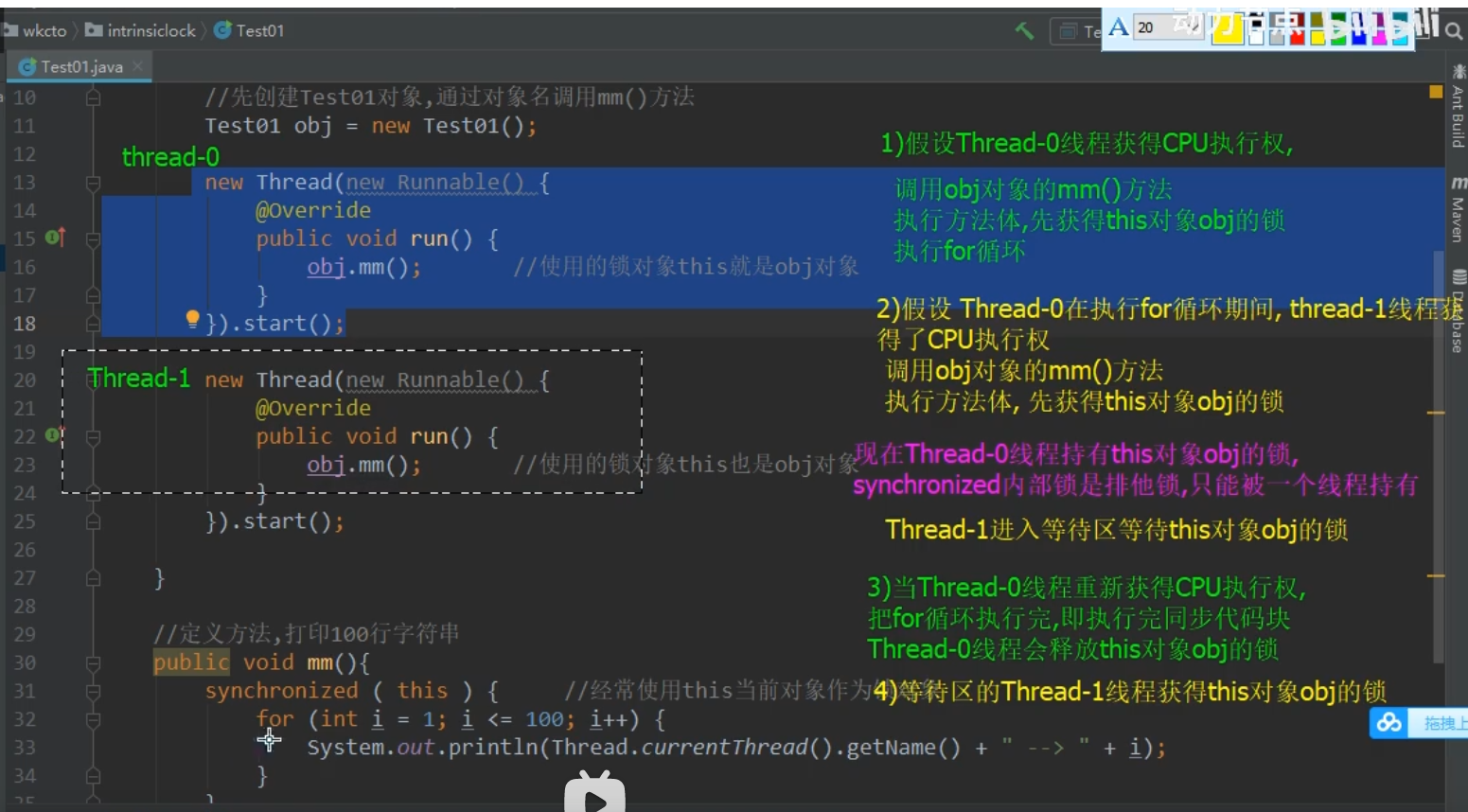
If the lock objects of threads are different, synchronization cannot be realized. If you want to synchronize, you must use the same lock object Use a constant as the lock object. If the lock object is a constant, It doesn't matter which object you use to call. Whether it is an instance method or a static method, as long as it is the same lock object, it can be synchronized. Note: synchronization is serial, Synchronization is a serial operation that enables the thread executing the code in the critical area to execute relative to the critical area of other threads use synchronized Modify instance method, synchronize instance method, default this As a lock object. //Using a constant object as the lock object, the synchronization code blocks in different methods can also be synchronized
synchronized instance method
//Take the whole method body as a synchronous code block
//The default object is this object
public void m(){
synchronized(this){.....}
}
public synchronized void m2(){....}//The two are equivalent
synchronized static method
//Take the whole method body as a synchronous code block
//The default lock object is the runtime class object of the current class, test06 class,
Some people call it class lock
public void m1(){
//Using the runtime class object of the current class as the lock object, you can
//It is simply understood that the bytecode file of Test06 class is taken as the lock object
synchronized(Test06.class){...}
}
//Using synchronized to modify static methods,
//Default runtime test06 Class as lock object
public synchronized static void sm2(){ ....}
How to choose synchronization method and synchronization code block?
Synchronous code block

Synchronization method

The lock granularity of the synchronization method is coarse and the execution efficiency is low. The lock granularity of the synchronization code block is fine and the execution efficiency is high
Dirty reading
There are some exceptions in reading the attribute value. The intermediate value is read instead of the modified value
Reason for dirty reading: the modification of shared data is not synchronized with the reading of shared data
Solution: synchronize not only the code blocks that modify the data, but also the code blocks that read the data.
If an exception occurs in the thread, the lock will be released automatically
deadlock
In multithreaded programs, multiple locks may be required during synchronization,
If the order of obtaining locks is inconsistent, it may lead to deadlock
For example: snipe and clam fight
How to avoid deadlock: when multiple locks need to be obtained, all threads can obtain locks in the same order.
Lightweight synchronization mechanism: volatile keyword
Role of volatile
Make variables visible between multiple threads
You can force a thread to read the value of a variable from common memory (main memory) instead of working memory
Comparison between volatile and synchronized
1) volatile Keyword is a lightweight implementation of thread synchronization, so volatile Performance ratio synchronized Better, volatile Can only modify variables, and synchronized You can modify methods and code blocks. along with JDK The release of the new version, synchronized The execution efficiency of has also been greatly improved. Use in development synchronized The ratio is still large. 2)Multithreaded access volatile Variables are not blocked, and synchronized May block 3)volatile The visibility of data can be guaranteed, but atomicity cannot be guaranteed; synchronized It can ensure atomicity and visibility. (volatile That is, it only scours the memory, and synchronized Not only Memory flushing and locking for serial) 4)keyword volatile The solution is the visibility of variables among multiple threads, synchronized Keyword solves the synchronization of accessing common resources between multiple threads.
Nonatomicity of volatile
volatile keyword increases the visibility of instance variables among multiple threads,
But it is not atomic
Common atomic classes are used for self increasing and self decreasing operations
We know that i + + operations are not atomic operations. In addition to using synchronized for synchronization,
It can also be implemented using the AtomicInteger/AtomicLong atomic class.
CAS introduction
CAS(Compare And Swap)It is implemented by hardware. CAS Can read-modify-write Such operations are converted to atomic operations. i++The auto increment operation includes three sub operations: read i Variable value pair i Add 1 to the value of, and then save the value after adding 1 to the main memory CAS Principle: when updating the data to the main memory, read the value of the main memory variable again, If the current value of the variable is different from the expected value (The value read at the beginning of the operation)Update as soon as possible.

Using CAS to implement a thread safety counter
public class CASTest{
public void main(String args[]){
CAScounter cascounter=new CAScounter();
for(int i=0;i<1000;i++){
new Thread(new Runnable()){
@overwrite
public void run(){
sout(casCounter.incrementAndGet());
}
}.start();
}
}
}
class CAScounter{
//Modify the value value with volatile to make the thread visible
volatile private long value;
public long getvalue(){
return value;
}
//Define a compare and swap method
private boolean compareAndSwap(long expectedValue,long newValue){
//If the current value is the same as the expected value, replace the current value field with the newValue value
synchronized(this){
if(value == expectValue){
value = newValue;
return true;
}else{
return false;
}
}
}
//Define autoincrement method
public long incrementAndGet(){
long oldvalue;
long newValue;
do{
oldvalue = value;
newValue = oldvalue+1;
}while(!compareAndSwap(oldvalue,newValue));
return value;
}
}
ABA problem of CAS
CAS There is an assumption behind the implementation of atomic operations: the current value of the shared variable is the same as the expected value provided by the current thread Variables have not been modified by other threads. In fact, this assumption is not always true, such as shared variables count=0; A Thread pair count Change the value to 10 B Thread pair count Change the value to 20 C Thread pair count Change the value to 30 The current thread sees count The value of the variable is now 0. Do you think now count Is the value of the variable not updated by other threads? Is this result acceptable? This is it. CAS Medium ABA The problem is that shared variables have experienced A->B->A Is the update acceptable ABA problem It is related to the algorithm implemented. /* If we want to avoid the ABA problem, it is not difficult. We can introduce a revision number (timestamp) for the shared variable, Each time the shared variable is modified, the corresponding revision number will increase by 1 ABA The variable update process changes to: [a, 0] - > [b, 1] - > [a, 2]. Each modification of the shared variable will lead to the increase of the revision number, The revision number can still accurately determine whether the variable has been modified by other threads. */
Atomic variable class
CAS It is assumed that the thread provides the same expected value as the current operation Variables have not been modified by other threads. In fact, this assumption is not always true, such as shared variables count=0; A Thread pair count Change the value to 10 B Thread pair count Change the value to 20 C Thread pair count Change the value to 30 The current thread sees count The value of the variable is now 0. Do you think now count Is the value of the variable not updated by other threads? Is this result acceptable? This is it. CAS Medium ABA The problem is that shared variables have experienced A->B->A Is the update acceptable ABA problem It is related to the implementation of the algorithm. /* If we want to avoid the ABA problem, it is not difficult. We can introduce a revision number (timestamp) for the shared variable, Each time the shared variable is modified, the corresponding revision number will increase by 1 ABA The variable update process changes to: [a, 0] - > [b, 1] - > [a, 2]. Each modification of the shared variable will lead to the increase of the revision number, The revision number can still accurately determine whether the variable has been modified by other threads. */
There are 12 atomic variable classes, such as:
| grouping | Atomic variable class |
|---|---|
| Basic data type | AtomicInteger,AtomicLong,AtomicBoolean |
| Array type | AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray |
| Field Updater | AtomicIntegerFieldUpdater,AtomicLongFieldupdater,AtomicReferenceFieldUpdater |
| Reference type | AtomicReference,AtomicStampedReference,AtomicMarkableReference |
AtomicLong
/*
Use the atomic variable class to define a counter
This counter can be used in the whole program, and it is used everywhere,
This counter can be designed as a single example
*/
public class Indicator {
//Privatization of construction methods
private Indicator(){}//Define a private static object of this class
private static final Indicator INSTANCE = new Indicator();
//3) Provide a public static method that returns a unique instance of this class
public static Indicator getInstance(){
return INSTANCE;
}
//Use atomic variable class to save the total number of requests, successes and failures
private final AtomicLong requestCount = new AtomicLong(0);//Total record requests
private final AtomicLong successCount = new AtomicLong0);//Total number of successful processing
private final AtomicLong fialureCount = new AtomicLong(0);//Total processing failures
//There are new requests
public void newRequestReceive(){
requestCount.incrementAndGet();
}
//Successful processing
public void requestProcessSuccess(){
successCount.incrementAndGet();
}
//Processing failed
public void requestProcessFailure(){
fialureCount.incrementAndGet();
}
//View the total number, successes and failures
public long getRequestCount(){
return requestCount.get();
}
public long getSuccessCount(){
return successCount.get();
}
public long getFailureCount(){
return fialureCount.get():
}
Basic operations of AtomicIntegerArray
//Creates an atomic array of the specified length AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10); //[0,0,0,0,0,0,0,0,0,0] get(Specifies the element subscript) //Returns the element at the specified location set(Specifies the element subscript) //Sets the specified location element getAndSet(Specifies the subscript of the element and the value to be set) //When setting the new value of an array element, the old value of the element is returned at the same time addAndGet(Specifies the subscript of the element and the value to be added) //Modify before returning //Modify the value of the array element and add a value to the array element getAndAdd(Specifies the subscript of the element and the value to be added) //Return first and then modify compareAndSet(Specifies the element subscript, expected value, and modified value) //CAS operation: if the specified element is equal to the expected value, it will be modified; otherwise, it will not be modified incrementAndGet(Specifies the element subscript) //Add first and return again getAndIncrement(Specifies the element subscript) //Return first and then add one decrementAndGet(Specifies the element subscript)//Reduce first and return again getAndDecrement(Specifies the element subscript)//Return first and then subtract one
Using AtomicIntegerArray atomic arrays in multithreading
//Using AtomicIntegerArray atomic arrays in multithreading
public class Test02 {
//Define atomic array
static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
public static void main(String[ ] args){
//Define thread array
Thread[] threads = new Thread[10];
//Assign values to thread array elements
for(int i=0;i<threads.length;i++){
thread[i]=new AddThread();
}
//Open child thread
for(Thread thread:threads){
thread.start();
}
//View the value of each element in the thread array after the increment in the main thread,
//In the main thread, you need to view it after all sub threads are executed
//Merge all child threads into the current main thread
for(Thread thread:threads){
try{
thread.join();
}catch(InterruptedException e){
e.printStackTrace();
}
}
sout(atomicIntegerArray);
}
//Define a thread class and modify the atomic array in the thread class
static class AddThread extends Thread{
@Override
public void run() {
//Increase each element of the atomic array by 1000 times
for (int i =0; i <1000; i++){
for (int i = 0; i< atomicIntegerArray.length(); i++) {
atomicIntegerArray.getAndIncrement(i % atomicIntegerArray.length());
} //Add one to each element of the array
}
/* for (int i = e; i < 10000; i++) {
atomicIntegerArray.getAndIncrement(i % atomicIntegerArray.length());
}
*/
}
}
AtomicIntegerFieldUpdater
AtomicIntegerFieldUpdater The atomic integer field can be updated, requirement: 1)Characters must be used volatile Decoration to make visible between threads 2)It can only be an instance variable, not a static variable, nor can it be used final modification
AtomicReference
You can read and write an object atomically
AtomicStampedReference
AtomicStampedReference Atomic classes can solve CAS Medium ABA problem stay AtomicStampedReference There is an integer tag value in the atomic class stamp Every execution CAS All operations need to be compared stamp Value of(edition)
Communication between threads
Waiting / notification mechanism
In single thread programming, the operation to be executed can only be executed when certain conditions are met. You can put this operation in if In the statement block,
In multithreaded programming, it is possible to A The condition of the thread is not satisfied. It is only temporary. Other threads will be later B Conditions may be updated so that A Threaded
Conditions will be met A The thread is suspended until its conditions are met A Thread wakeup.
Pseudo code:
atomics{
//Atomic operation
while(The condition is not tenable){
wait for
}
After the current thread is awakened and the conditions are met, continue to perform the following operations
}
Implementation of waiting / notification mechanism
//The wait() method in the Object class can wait for the thread executing the current code and pause the execution
//Until notified or interrupted.
call wait()Method, the current thread will wait, release the lock object, and the current thread will enter blocking(wait for)State, need to be awakened,
If you are not awakened, you will wait all the time.
be careful:
1) wait()Method can only be called by a lock object in a synchronized code block
2) call wait()Method, the current thread will release the lock
The pseudo code is as follows:
//Obtain the internal lock of the object before calling the wait() method
synchronized(Lock object){
while(The condition is not tenable){
//Call the wait() method through the lock object to pause the thread and release the lock object
Lock object.wait();
}
//If the conditions of the thread are met, continue to execute downward.
}
------------------------------------------------------------------------------------
//The notify() of the Object class can wake up the thread, and this method must also be called by the lock Object in the synchronization code block,
//Calling wait()/notify() without a lock object throws an illegalmonitorstateexception.
If there are multiple waiting threads, notify()Method can wake up only one of them
Invoke in synchronous code block notify()Method does not immediately release the lock object,
You need to wait for the current synchronization code block to execute before releasing the lock object,
General will notify()At the end of the synchronization block.
Its pseudo code is as follows:
synchronized(Lock object){
//Execute the code that modifies the protection condition
//Wake up other threads
Lock object.notify();
}
------------------------------------------------------------------------------------
//The Interrupt() method interrupts wait()
When the thread is in wait()When waiting, the of the thread object is called interrupt()method
Will interrupt the waiting state of the thread and generate interruptedException Abnormal.
------------------------------------------------------------------------------------
//notify() and notifyAll()
notify() Only one thread can be awakened randomly
notifyAll() Wake up all waiting threads
Call once notify()Only one thread can be awakened, and other waiting threads are still waiting,
For other threads, the notification signal is missed, which is also known as signal loss.
------------------------------------------------------------------------------------
//Use of wait(long)
wait(long)have long Type parameter wait()Wait,
If you are not awakened within the time specified by the parameter,
It will wake up automatically after timeout.
Premature notification
thread wait()After waiting, you can call notify Wake up the thread if notify Early awakening, Called before waiting notify,It may disrupt the normal execution logic of the program. Actually call start Tell the scheduler that the thread is ready, When the thread scheduler starts this thread is not necessarily, Namely call start The order in which threads are started is not necessarily the order in which threads are actually started. In most cases, t1 Wait first, t2 Again t1 Wake up. If t2 First t1 The thread wakes up and then t1 If the thread waits again, a t1 Wait for no notification. How to solve: t1 After waiting, let t2 Thread wakeup, if t2 The thread wakes up first t1 Thread, don't let t1 The thread is waiting. Define a static variable as the flag of whether to run the first thread. If the current thread is the first thread opened, wait. If t2 Wake up first t1,Change the value of the flag of the first thread to false.
The wait condition has changed
in use wait/notify When in mode, pay attention to wait Waiting conditions have changed, which may also cause logical confusion.


Producer consumer design model
Producer: the module responsible for generating data
Consumer: module responsible for using data
Producers and consumers solve the problem of data balance, that is, they have data before they can use it
When there is no data, consumers need to wait.
1.Producer consumer operation value
Single producer and single consumer
//Producers and consumers operate alternately
Multi producer and multi consumer
After the producer produces the data, wake up the consumer to get the data,
Consumers wait when they can't get the data.
Suppose there are multiple consumer threads fetching data and waiting without data,
//In order to avoid consumers getting empty data in the case of multiple production and multiple consumers,
// After waking up the consumer thread, it cannot be retrieved directly. You should come back again to judge whether it is empty
//We need to change the judgment method of the previous consumer to get data from if to while
//Fake death: consumers wake up after consumers get data, while producers wait for consumers to get data, but consumers have no data to take. Consumers and producers wait for each other.
//How to solve the problem of false death: change the wake-up notify after the producer's production data to notifyAll,
// The wake-up notify after the consumer fetches the data is also changed to notifyAll
2.Producer consumer operation stack
Enable producers to store data in: List Collection, consumers from List Collect data.
use List Set simulation stack.
Single production and single consumption
//Producers and consumers operate alternately
More production and more consumption
//In order to avoid consumers getting empty data in the case of multiple production and multiple consumers,
// After waking up the consumer thread, it cannot be retrieved directly. You should come back again to judge whether it is empty
//We need to change the judgment method of the previous consumer to get data from if to while
//How to solve the problem of false death: change the wake-up notify after the producer's production data to notifyAll,
// The wake-up notify after the consumer fetches the data is also changed to notifyAll
The communication between threads is realized through pipeline
stay java.io In the bag PipeStream Pipeline flow is used to transfer data between threads, One thread sends data to the output pipeline, and another thread reads data from the input pipeline. Related classes: PipedInputStream and PipedOutputStream, PipedReader and PipedWriter PipedInputStream inputStream=new PipedInputStream(); PipedOutputStream outputStream=new PipedOutputStream(); //Establish a connection between the input pipe and the output pipe inputStream.connect(outputStream);
Use of ThreadLocal
In addition to controlling the access of resources, you can also ensure thread safety by adding resources,
//ThreadLocal is mainly used to bind its own value for each thread.
ThreadLocal Application of
In a multithreaded environment, convert a string to a date object
Multiple threads use the same SimpleDateFormat Object may cause thread safety problems with exceptions
Specify your own for each thread SimpleDateFormat Objects, using ThreadLocal
ThreadLocal Initial value, definition ThreadLocal Class, overridden in subclasses initialValue()Method to specify the initial value,
Call again get()Method does not return null.
Lock display lock
ReentrantLock Lock is called reentrant lock, and its function is better than synchronized many Lock reentry: when a thread obtains an object lock and requests the object lock again, it can obtain the lock of the object. Reentrant lock: refers to the lock that can be obtained repeatedly If the lock cannot be re entered, it will cause deadlock
ReentrantLock
lock() method and unlock() method
//Define display lock
static Lock lock = new ReentrantLock();//It is generally defined as static and can share a lock object
//Acquire lock
lock.lock();
//Release lock
lock.unlock();
//The Lock lock is often obtained in the try code block and released in the finally clause
try{
lock.lock();//Acquire lock
.....
}catch(InterruptedException e){
e.printStackTrace()
}finally{
lock.unlock();//Release lock
}
lockInterruptibly() method
effect:If the current thread is not interrupted, the lock is obtained. If the current thread is interrupted, an exception occurs. lock.lock();//Get the lock, even if the thread's interrupt() method is used, there is no real interrupt thread. //lock.lock(); lock.lockInterruptibly();//If the thread is interrupted, the lock will not be obtained and an exception will be generated /* For synchronized internal locks, if a thread is waiting for a lock, there are only two results Either get the lock and continue to execute, or keep waiting. For ReentrantLock, it provides another possibility, While waiting for the lock, the program can cancel the request for the lock as needed. */ /* Resolve deadlock issues: In the main thread, wait for 3 seconds. If the thread does not end, interrupt the thread (Change the lock here to lock interruptible) Deadlock can be avoided through the lockinterruptible () method of ReentrantLock lock */
trylock() method
/*
tryLock(long time,TimeUnit unit)Role of:
The lock is not held by another thread within a given waiting time,
If the current thread is not interrupted, the lock is obtained.
Through this method, the time limited waiting of objects can be realized.
tryLock() Locks that are not held by other threads are locked only when called,
If the lock object is held by another thread when the method is called, it is discarded.
Call the method to try to get the lock,
If the lock is not occupied by other threads, return true, indicating that the lock is successful,
If the lock is occupied by other threads, false is returned without waiting.
tryLock()Deadlock can be avoided
*/
newCondition() method
/*
The keyword synchronized is used with the wait()/notify() methods to implement the wait / notify mode.
Lock The newCondition() method of the lock returns the Condition object, and the Condition class can also implement the wait / notify mode.
When using notify() notification, the JVM will wake up a waiting thread at random,
The Condition class can be used for selective notification.
Condition There are two common methods:
await()It will make the current thread wait and release the lock,
When other threads call signal(), the thread will regain the lock and continue to execute.
signal()Used to wake up a waiting thread.
Note: before calling the await()/signal() method of Condition, the thread also needs to hold the relevant Lock lock.
After await() is called, the thread will release the lock, and after signal() is called, it will be from the waiting queue of the current Condition object
Wake up a thread. The awakened thread will try to obtain the lock. Once the lock is obtained successfully, it will continue to execute.
*/
/*
Note: for many to many, in order to solve unnecessary troubles, change the awakened one to All,
For example, nofity -- > notifyAll signal -- > signalall
*/
Fair lock and unfair lock
In most cases, the application for lock is unfair, If both thread 1 and thread 2 are requesting locks A,When lock A When available, The system just randomly selects a thread from the blocking queue, and its fairness cannot be guaranteed. The fair lock will be in chronological order to ensure first come, first served, The feature of fair lock will not lead to thread starvation. synchronized Internal locks are unfair, ReentrantLock Lock default is unfair, however ReentrantLock Reentry locks provide a construction method:ReentrantLock(boolean fair), When creating a lock object, the arguments are passed true,The lock can be set as a fair lock. /* It seems fair to implement a lock, but it is necessary to maintain a fair system, Fair locks have high implementation cost and low performance, so non fair locks are selected by default, It is not a special requirement. Generally, fair locks are not used. If it is an unfair lock, the system will tend to let a thread obtain the lock already held again, This allocation strategy is efficient and unfair. If it is a fair lock, multiple threads will not have the possibility that the same thread can obtain the lock continuously, so as to ensure the fairness of the lock */
Several common methods of ReentrantLock
int getHoldCount() //Returns the number of times the lock() method was called by the current thread
int getQueueLength() //Returns the estimated number of threads waiting to acquire a lock
int getWaitQueueLength(Condition condition) //Returns the estimated number of threads waiting related to the Condition condition
boolean hasQueuedThread(Thread thread) //Query whether the thread specified by the parameter is waiting to obtain the lock
boolean hasQueuedThreads() //Query whether there are any threads waiting to acquire the lock
boolean hasWaiters(Condition condition) //Queries whether a thread is waiting for the specified condition
boolean isFair() //Judge whether it is fair lock
boolean isHeldByCurrentThread() //Determine whether the current thread holds the lock
boolean isLocked() //Query whether the current lock is held by the thread
ReentrantReadWriteLock
ReentrantReadWriteLock Read write lock is an improved exclusive lock, which can also be called sharing lock/Exclusive lock. Multiple threads are allowed to read the shared data at the same time, but only one thread is allowed to update the shared data at a time. The read-write lock completes the read-write operation through the read lock and write lock. The thread must obtain the read lock before reading the shared data, The read lock can be held by multiple threads, that is, it is shared, Threads must hold write locks before modifying shared data. Write locks are exclusive, When one thread holds a write lock, other threads cannot obtain the corresponding lock. /* Read locks are only shared among read threads. When any thread holds a read lock, other threads cannot obtain a write lock, Ensure that no other thread updates the data during data reading, so that the reading thread can read the latest value of the data, Ensure that shared variables are not modified during data reading. */
| Acquisition conditions | exclusiveness | effect | |
|---|---|---|---|
| Read lock | The write lock is not held by any thread | Read threads are shared and write threads are exclusive | Multiple reading threads are allowed to read the shared data at the same time to ensure that no other thread modifies the shared data when reading the shared data |
| Write lock | The write lock is not held by other threads, and the corresponding read lock is not held by other threads | Read or write threads are exclusive | Ensure that the writer thread modifies the shared data exclusively |
The read-write lock allows read sharing, read-write mutual exclusion and write mutual exclusion.
java.util.concurrent.locks In package ReadWriteLock Interface
readLock() //Return read lock
writeLock() //Return write lock
The implementation class is ReentrantReadWriteLock
/*
Note: the readLock() and writeLock() methods return lock objects
Are two different roles of the same lock,
Instead of getting two different locks.
ReadWriteLock Interface instances can play two roles,
*/
Basic usage of read-write lock
//Define read / write lock
ReadWriteLock rwlock = new ReentrantReadwriteLock();
//Acquire read lock
Lock readLock =new rwLock.readLock();
//Obtain write lock
Lock writeLock =new rwLock.writeLock();
//Read data
readLock.lock();//Apply for read lock
try{
Read shared data
}finally{
readLock.unlock();//Always release the lock in the finally clause
}
//Write data
writeLock.lock(); //Apply for write lock
try{
Update and modify shared data
}finally{
writeLock.unlock();//Always release the lock in the finally clause
}
Reading sharing
ReadwriteLock The read-write lock enables multiple threads to read shared data at the same time, That is, reading sharing can improve the reading efficiency of the program.
Write mutually exclusive
adopt ReadWriteLock The write lock in the read-write lock allows only one thread to execute lock()The code behind.
Read write mutual exclusion
The write lock is exclusive and exclusive. The read thread and the write thread are mutually exclusive.
Thread management
Thread group (brief introduction)
Similar to using folders to manage files on a computer, you can also use thread groups to manage threads.
Define a group of similar threads in a thread group(relevant)In the thread group, you can also define sub thread groups.
Thread Class has several constructors that allow you to specify a thread group when creating a thread,
If no thread group is specified when creating a thread, the thread belongs to the thread group of the parent thread.
JVM Creating main A thread group will be assigned to the thread when it is,
So each java Each thread has a thread group associated with it,
Thread can be called getThreadGroup()Method returns the thread group.
/*
Thread groups were originally designed for security reasons to distinguish between different applets,
However, ThreadGroup does not achieve this goal. Thread group is not commonly used in the newly developed system.
Now, a group of related threads are generally stored in an array or a collection,
If it is only used to distinguish threads, the thread name can be used to distinguish them,
Thread groups can be ignored in most cases.
*/
/*
Define a thread group. If the thread group is not specified, it will automatically belong to the thread group to which the current thread belongs.
If no thread group is specified when creating a thread, the default thread belongs to the thread group of the parent thread.
*/
Basic operations of thread group
int activeCount() //Return the number (approximate value) of active threads in the current thread group and sub thread group int activeGroupCount() / / return the number (approximate value) of active thread groups in the current thread group and sub thread group int enumerate(Thread[] list) / / copy the active threads in the current thread group to the parameter array int enumerate(ThreadGroup[] list) //Copy the active thread group in the current thread group to the parameter array int getMaxPriority() / / returns the maximum priority of the thread group, The default is 10String getName() / / return the name of the thread group ThreadGroup getParent() / / return the parent thread group void interrupt() / / interrupt all threads in the thread group boolean isDaemon() / / judge whether the current thread group is a daemon thread group void list() / / print out the active threads in the current thread group boolean parentOf(ThreadGroup g) //Judge whether the current thread group is the parent thread group of the parameter thread group void setDaemon(boolean daemon) / / set the thread group as the daemon thread group


/*be careful: 1.main The parent thread group of the thread group is system 2.The thread group is also its own parent thread group */
Copy threads and sub thread groups in a thread group
enumerate(Thread[] list) //Copy all threads in the current thread group and sub thread group to the parameter array enumerate(Thread[] list,boolean recursive) //If the second parameter is set to false, only all threads in the current thread group will be copied, and the threads in the child thread group will not be copied enumerate(ThreadGroup[] list)//Copy all thread groups in the current thread group and sub thread group to the parameter array enumerate(ThreadGroup[] list,boolean recurse) //If the second parameter is set to false, only the child thread groups of the current thread group are copied
Batch interrupt of thread group
Thread group interrupt() You can add interrupt flags to all active threads in this thread group. //If the thread in sleep is interrupted, an interrupt exception will be generated and the interrupt flag will be cleared
Set daemon group
Daemon threads provide services for other threads,
When JVM When there are only daemon threads in the, the daemon threads will be automatically destroyed, JVM Will exit.
Calling thread group setDameon(true)You can set the thread group as a daemon thread group,
When there are no active threads in the daemon group, the daemon group will be automatically destroyed.
be careful:
The daemon attribute of the thread group does not affect the daemon attribute of the threads in the thread group,
In other words, the threads in the daemon thread group can be non daemon threads.
Catch thread execution exception
At the end of the thread run In the method, if there is a detected exception, it must be captured,
If you want to get run()Method,
You can call back UncaughtExceptionHandler Interface to get which thread has encountered a runtime exception.
stay Thread Methods related to handling operation exceptions in class include:
static Thread.UncaughtExceptionHandler getDefaultUncaughtExceptionHandler()
//You can get a global (default) uncapped exception handler
Thread.UncaughtExceptionHandler getUncaughtExceptionHandler()
//Gets the unhandled exception handler for the current thread
static void setDefaultUncaughtExceptionHandler(Thread.UncaughtExceptionHandler eh)
//Set global uncapped exception handler
void setUncaughtExceptionHandler(Thread.UncaughtExceptionHandler eh)
//Sets the unhandled exception handler for the current thread
When an exception occurs while the thread is running, JVM Will call Thread Class dispatchUncaughtExceptionHandler(Throwable e)method,
This method calls getUncaughtExceptionHandler().uncaughtException(this,e);
If you want to get the exception information in the thread, you need to set the thread's UncaughtExceptionHandler Callback interface
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler(){
@override
public void uncaughtException(Thread t,Throwable e){
//The t parameter receives the thread where the exception occurs, and e is the exception generated in the thread
System.out.println(t.getName()+"The thread generated an exception"+e.getMessage());
}
});
In actual development, this method of designing exception handling is still commonly used, especially the method of asynchronous execution.
/*
If an exception occurs, the JVM will call the dispatchUncaughtExceptionHandler() method of the Thread class,
In this method, getUncaughtExceptionHandler () is called. uncaughtException(this,e);
If the current thread has set the UncaughtExceptionHandler callback interface, it will directly use its own uncaughtException method,
If it is not set, the callback interface of the thread group UncaughtExceptionHandler in which the current thread is located will be called
uncaughtException method,
If the thread group does not set a callback interface, the stack information of the exception is directly directed to system In error
*/
Inject Hook thread
Now a lot of software Mysql,Zookeeper,kafka All exist Hook Thread verification mechanism, The purpose is to verify whether the process has been started and prevent repeated startup procedures. Hook Thread is also called hook thread, when JVM When you exit, it will be executed Hook Thread. Often create one when the program starts.lock File, with.lock Whether the file verification program is started, Exit after program(JVM sign out)Delete on.lock Documents, stay Hook In the thread, in addition to preventing the restart of the process, it can also release resources, Try to avoid Hook Complex operations in threads.
/*
Prevent repeated program startup through Hook thread
*/
public class Test{
public static void main(String[] args){
//1) Inject Hook thread and delete it when the program exits lock file
Runtime.getRuntime().addShutdownHook(new Thread(){
@override
public void run(){
System.out.println("JVM Exit will start the current Hook Thread, in Hook Delete from thread.lock file");
getLockFile().toFile().delete();
}
});
//2) Check when the program is running Whether the lock file exists, if If the lock file exists, an exception is thrown
if(getLockFile().toFile()){
throw new RuntimeException("Program started");
}else{
try{
//The file does not exist, indicating that the program is started for the first time. Create one lock file
getLockFile().toFile().createNewFile();
}catch(IOException e){
e.printStackTrace();
}
}
//Simulation program running
for(int i=0;i<100;i++){
sout("The program is running");
try{
TimeUnit.SECONDS.sleep(1);
}catch(InterruptedException e){
e.printStackTrace();
}
}
private static Path getLockFile(){
return Path.get("","tmp.lock");
}
}
}
Thread pool
What is a thread pool
Can be new Thread(()->{Tasks performed by threads}).start();Start a thread in this form,
When run The thread is terminated and the method is executed GC(Garbage collector)Release.
In a real production environment, multiple threads may be required to support the entire application,
When the number of threads is very large, they will be exhausted CPU resources,
If you do not control and manage threads, it will affect the performance of the program.
Thread overhead mainly includes:
1)The cost of creating and starting threads;
2)The cost of thread destruction;
3)The overhead of thread scheduling;
4)Number of threads
5)be limited to CPU Number of processors
Thread pool is a common way to use threads effectively,
A certain number of working threads can be created in the thread pool in advance,
The client code directly submits the task to the thread pool as an object,
The thread pool caches these tasks in the work queue,
The worker threads of the thread pool constantly take out tasks from the queue and execute them.

JDK support for thread pool
JDK Provides a set of Executor Framework, which can help developers use thread pool effectively.

Basic use of thread pool
public class test{
public static void main(String args){
//Create a thread pool with 5 thread sizes
ExecutorService fixedThreadPool = Excutors.newFixedThreadPool(5);
//Submit 18 tasks to the thread pool, which are stored in the blocking queue of the thread pool. The five threads in the thread pool take tasks from the blocking queue for execution
for(i=0;i<18;i++){
fixedThreadPool.execute(new Runnable(){
@override
public void run(){
sout(Thread.currentThread().getId()+"The numbered thread is executing a task. Start time:"+System.currentTimeMillis());
}
});
try{
Thread.sleep(3000); //Simulation task execution duration
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
}
Scheduled tasks for thread pool
//Create a thread pool with scheduling function
ScheduledExecutorService scheduledExecutorService = Excutors.newScheduledThreadPool(5);
//Three common methods:
//(1) Execute the task after 2 seconds delay, schedule(Runnable task, delay length, time unit)
scheduledExecutorService.schedule(new Runnable(){
@Override
public void run(){
sout(Thread.currentThread.getId()+"----------"+System.currentTimeMills());
}
},2,TimeUnit.SECONDS);
//(2) Execute the task at a fixed frequency. The time to start the task is fixed. Execute the task after 3 seconds, and then re execute it every 2s
scheduledExecutorService.scheduleAtFixedRate(new Runnable(){
@Override
public void run(){
sout(Thread.currentThread.getId()+"----Fixed frequency start task-----"+System.currentTimeMills());
try{
TimeUnit.SECONDS.sleep(3);//Sleep simulates the task execution time. If the task execution time exceeds the time interval, the next task will be started immediately after the task is completed
}catch{
e.printStackTrace();
}
}
},3,2,TimeUnit.SECONDS);
//(3) After the end of the last task and after a fixed delay, execute the task again. No matter how long it takes to execute the task, always start a new task again 2 seconds after the end of the task
scheduledExecutorService.scheduleWithFixedDelay(new Runnable(){
@Override
public void run(){
sout(Thread.currentThread.getId()+"----Fixed frequency start task-----"+System.currentTimeMills());
try{
TimeUnit.SECONDS.sleep(3);
}catch{
e.printStackTrace();
}
}
}3,2,TimeUnit.SECONDS);
Bottom implementation of core thread pool
see Executor Tool class newCachedThreadPool(),newSingleThreadExecutor(),newFixedThreadPool()Source code:
//(1) newCachedThreadPool()
/*
In extreme cases, this thread will create a new thread to execute every time it submits a new task, which is suitable for executing tasks with short time and frequent submission
*/
public static ExecutorService newCachedThreadPool(){
return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
------------------------------------------------------------------------------------------------------------------------------------
//(2) newFixedThreadPool()
/*
The number of core threads is equal to the maximum number of threads. The number of threads in the thread pool is the specified number, which will not increase. If it exceeds, it will be put into the unbounded queue
*/
public static ExecutorService newFixedThreadPool(int nThreads){
return new ThreadPoolExecutor(nThreads,nThreads,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
--------------------------------------------------------------------------------------------------------------------------------------
//(3) newSingleThreadExecutor()
/*
It can be used in a single producer consumer model
*/
public static ExecutorService newSingleThreadExecutor(){
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
---------------------------------------------------------------------------------------------------------------------------------------
/*
Resolution: ThreadPoolExecutor thread pool is used at the bottom of the method that returns thread pool in Executor tool class,
These methods are encapsulated by ThreadPoolExecutor thread pool.
*/
//Construction method of ThreadPoolExecutor:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,RejectedExecutionHandler handler)
//Meaning of each parameter:
corePoolSize: "Specifies the number of core threads in the thread pool“
maximumPoolSize: "Specifies the maximum number of threads in the thread pool"
keepAliveTime: "When the number of threads in the thread pool exceeds corePoolSize The survival time of redundant idle threads, that is, the time within which idle threads are destroyed."
unit: "yes keepAliveTime Duration unit"
workQueue: "Task queue: submit the task to the task queue for execution"
threadFactory: "Thread factory for creating threads"
handler: "Reject strategy: how to reject when there are too many tasks to handle."
//explain:
workQueue Work queue refers to the queue that submits unexecuted tasks. It is BlockingQueue Interface, used only for storage Runnable task
According to the classification of queue function, in ThreadPoolExecutor In the construction method
The following types of blocking queues can be used:
1.Submit task queue directly
from SynchronousQueue Object, the queue has no capacity, and the tasks submitted to the thread will not be saved,
Always submit new tasks to the thread for execution. If there is no idle thread, try to create a new thread,
If the number of threads reaches the specified maximum, the reject policy is executed.
2.Bounded task queue
from ArrayBlockingQueue Implementation, creating ArrayBlockingQueue Object, you can specify a capacity,
When a task needs to be executed, if the number of threads in the thread pool is less than corePoolSize Number of core threads,
Create a new thread. If the number of threads is greater than the number of core threads, join the waiting queue. If the queue is full, you cannot join,
At this time, if the number of threads is less than the specified maximum number of threads, a new thread will be created to execute,
If the number of threads is greater than the specified maximum number of threads, the reject policy is executed.
3.Unbounded task queue
from LinkedBlockingQueue Object implementation, compared with bounded queues,
Unless the system resources are exhausted, there is no task queue failure in the unbounded queue,
When there is a new task, if the number of system threads is less than the number of core threads, a new thread is created to execute the task;
When the number of threads in the thread pool is greater than the number of core threads, the task is added to the blocking queue
4.Priority task queue
Yes PriorityBlockingQueue The implementation is a queue with task priority, which is a special unbounded queue.
Whether it is ArrayBlockingQueue still LinkedBlockingQueue,All tasks are processed according to the first in first out algorithm,
stay PriorityBlockingQueue The queue can be executed according to the priority of tasks.

Rejection policy of thread pool
ThreadPoolExecutor The last parameter of the construction method of specifies the rejection policy,
How to handle when the amount of tasks submitted to the thread pool exceeds the actual carrying capacity?
That is, the threads in the thread pool have been used up and the waiting queue is full, so it cannot serve the newly submitted tasks. You can deal with this problem through the rejection policy.
//Four rejection strategies:
1.AbortPolicy Strategy: an exception will be thrown
2.CallerRunPolicy Strategy: as long as the thread pool is not closed, the currently discarded tasks will be run in the caller thread
3.DiscardOldestPolicy Policy: discard the oldest task in the task queue and try to submit a new task again
4.DiscardPolicy Strategy: directly discard tasks that cannot be processed
// The default rejection policy of the thread pool returned by the static method provided by the Executor tool class is AbortPolicy, and an exception is thrown
// If the built-in policy cannot meet the actual requirements, the RejectedExecutionHandler interface can be extended
ThreadFactory
Threads in thread pool ThreadFactory production Thread Is an interface with only one method for creating threads:Thread newThread(Runnable r); This method is called when a thread needs to be created in the thread pool.
Monitor thread pool
//ThreadPoolExecutor provides several sets of methods for monitoring thread pools
int getActiveCount() //Gets the number of currently active threads in the thread pool
long getCompletedTaskCount() //Returns the number of tasks completed by the thread pool
int getCorePoolSize() //Number of core threads in the thread pool
int getLargestPoolSize() //Returns the maximum number of threads that the thread pool has reached
int getMaximumPoolSize() //Returns the maximum capacity of the thread pool
int getPoolSize() //Current thread pool size
BlockingQueue<Runnable> getQueue() //Return blocking queue
long getTaskCount() //Returns the total number of tasks received by the thread pool
Extended thread pool
Sometimes you need to extend the thread pool
Such as monitoring the start and end time of each task, or customizing some other enhanced functions.
//ThreadPoolExecutor thread pool provides two methods:
protected void afterExecute(Runnable r,Throwable t)
protected void beforeExecute(Thread t, Runnable r)
Called before the thread pool executes a task beforeExecute()method,
At the end of the task(Or the task exits abnormally)Will execute afterExecute()method
see ThreadPoolExecutor Source code,An inner class is defined in this class Worker,
ThreadPoolExecutor The worker thread in the thread pool is Worker Class,
Worker The instance will call when executing beforeExecute()And afterExecute()method
//Define task class
private static class MyTask implements Runnable{
private string name;
public MyTask(String name) {
this.name F name;
}
@Override
public void run() {
System.out . println(name +"Task is being by thread“+Thread.currentThread( ). getId() +"implement");
try {
Thread.sLeep(100e);//Simulation task execution duration
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
public static void main(String[] args) {
//Define the extended thread pool. You can define the thread pool class, inherit the ThreadPoolExecutor, and override the beforeExecute()/afterExecute() method in the subclass
//You can also use the inner class of ThreadPoolExecutor directly
ExecutorService executorService = new ThreadPoolExecutor(5,5,0,TimeUnit.SECONDS,newLinkedBlockingQueue<>())
{
//Override the task start method in the inner class
@override
protected void beforeExecute( Thread t,Runnable r){
System.out . println(t.getId() +"The thread is ready to execute the task:" +((MyTask)r).name);
}
@Override
protected void afterExecute(Runnable r,Throwable t){
System.out.println(((MyTask)r).name +"The task is completed");
}
@Overrideprotected void terminated() i
System.out.println("Thread pool exit");
};
//Add tasks to the thread pool
for(int i=0;i<5;i++){
MyTask task = new MyTask("task-" +i);
executorService.execute(task);
}
//Close thread pool
executorService.shutdown();//Closing the thread pool only means that the thread pool will no longer receive new tasks, and the received tasks in the thread pool will be executed normally
Number of thread pools optimized
```java Thread pool size has a certain impact on system performance. Too large or too small can not give full play to the optimal system performance. The size of the thread pool does not need to be very precise, as long as the maximum or minimum conditions are avoided, In general, thread size needs to be considered CPU Quantity, memory size and other factors. In< Java Concurrency Practice>In the book A formula for estimating the size of thread pool is given: " Thread pool size = CPU Number of * target CPU Utilization rate of *(1 + Ratio of waiting time to calculation time) "
Thread pool deadlock
### Thread pool deadlock
```java
If the task performed in the thread pool A During execution, the task is submitted to the thread pool B,
task B Added to the waiting queue of the thread pool, if the task A You need to wait for the task to finish B The results of the implementation of,
This is possible:
/* All working threads in the thread pool are waiting for task processing results,
These tasks are waiting to be executed in the blocking queue
There are no threads in the thread pool that can process tasks in the blocking queue,
This wait will continue, resulting in deadlock */
resolvent:
" Submit independent tasks to the thread pool instead of dependent tasks For tasks that depend on each other, you can consider submitting them to different thread pools for execution "
Exception handling in thread pool
in use ThreadPoolExecutor conduct submit When submitting a task, some tasks throw exceptions, but the thread pool does not prompt,
That is, the thread pool eats up the exceptions in the task.
The thread pool may eat up exceptions in the program, such as arithmetic exceptions
/*Several solutions:
1.Change the submit() submission method to execute();
2.Extend the ThreadPoolExecutor thread pool and wrap the submit() method;
*/
-----------------------------------------------------------------------------------------------------------------------------------------
//Custom thread pool class
private static class TraceThreadPollExecutor extends ThreadPoolExecutor{
public TraceThreadPollExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable>workQueue) {
super(corePoolSize, maximumPoolSize,keepAliveTime,unit,workQueue);
//Define a method, wrap the task to be executed, and receive two parameters. The first parameter receives the task to be executed, and the second parameter is an Exception
public Runnable wrap( Runnable task, Exception exception){
return new Runnable(){
@override
public void run(){
try {
task.run();
}catch (Exception e ){
exception.printstackTrace();
throw e;
}
}
}
//Override the submit method @ override
public Future<?> submit( Runnable task) {
return super.submit(wrap(task, new Exception("Customer tracking exception")));
}
@Override
public void execute(Runnable command){
super.execute(wrap(command,new Exception("Customer tracking exception")));
}
}
ForkJoinPool thread pool


"Divide and conquer "is an effective way to deal with big data,famous MapReduce This is the idea of divide and rule. Simply put,If we need to process 1000 data, but we don't have the ability to process 1000 data,Only 10 data can be processed at a time, The 1000 data can be processed 100 times in stages,10 at a time,Synthesize the processing results of 100 times,Form the processing result of the last 1000 data. Call a big task fork()The method is divided into several small tasks, and the processing results of small tasks are analyzed join()Merge the results of large tasks. System pair ForkJoinPool The thread pool is optimized. The number of tasks submitted and the number of threads are not necessarily one-to-one, In most cases, a physical thread actually needs to handle multiple logical tasks.
ForkJoinPool The most commonly used methods in thread pool are:
<T>ForkJoinTask<T>submit(ForkJoinTask<T>task) //Submit a ForkJoinTask task to the thread pool. The ForkJoinTask task supports fork() to decompose and join() to wait for tasks
ForkJoinTask There are two important subclasses:RecursiveAction,RecursiveTask
The difference between them is RecursiveAction The task has no return value, RecursiveTask Tasks can have return values.
//Calculate the sum of the sequence and return the result. You can define the task to inherit the recursive task
private static class CountTask extends RecursiveTask<Long>{
private static final int THRESHOLD = 10000;//Define the threshold value of data scale, and allow to calculate the sum of 100oe numbers. If the threshold value is exceeded, the number sequence needs to be decomposed
private static final int TASKNUM= 100; //Break down large tasks into 100 small tasks at a time
private long start;//Calculate the starting value of the sequence
private long end;
//Calculate the end value of the sequence
public CountTask( long start,long end){
this.start = start;
this.end = end;
}
//Rewrite the compute() method of the RecursiveTask class to calculate the result of the sequence
@override
protected Long compute() {
long sum=e ;//Save calculated results
//Judge whether the task needs to continue to decompose. If the number of the current sequence end and start ranges exceeds the THRESHOLD threshold THRESHOLD, it needs to continue to decompose
if ( end - start < THRESHOLD){
//Less than the threshold can be calculated directly
for (long i = start ; i<= end; i++){
sum += i;
}else {
//The range of the sequence exceeds the threshold and needs to be decomposed
//It is agreed that each time it is decomposed into 1ee small tasks, and the calculation amount of each task is calculated
long step = (start + end ) / 100;
//Start = 0, end = 200000, step = 2000. If the sum of the sequence within the range of [0200800] is calculated, the sequence within the range is decomposed into 100 small tasks, and 2000 tasks can be calculated for each task
//Note that if the level of task division is very deep, that is, the THRESHOLD of THRESHOLD threshold is too small, and the amount of calculation of each task is very small, the level division will be very deep,
//Two situations may occur:
"(1)The number of threads in the system will accumulate,Serious performance degradation;"
"(2)Too many decomposition times,Too many method calls may cause stack overflow;"
//Create a collection of storage tasks
ArrayList<CountTask> subTaskList = new ArrayList<>();
long pos = start;//Starting position of each task
for(int i=0; i<TASKNUM;i++){
long lastOne = pos + step;//End position of each task
//Adjust the end position of the last task
if(lastOne>end){
lastOne=end;
}
//Create subtasks
CountTask task =new CountTask(pos,lastOne);
//Add task to collection
subTaskList.add(task);
//Call fork() to submit the subtask
task.fork();
//Adjust the starting position of the next task
pos+=step+1;
}
//After all subtasks are completed, the calculation results will be consolidated
for(CountTask task:subTaskList){
sum+=Task.join(); //join() will wait until the subtask is completed and return the execution result
}
}
return sum;
}
public static void main(String[] args){
//Create ForkJoinPool thread pool
ForkJoinPool forkJoinPool = new ForkJoinPool();
//Create a big task
CountTask task = new CountTask(0L,200000);
//Submit large tasks to the thread pool
forkJoinPool.submit(task);
try{
long res = result.get();//Call the get() method of the task to return the result
}catch(InterruptedException e){
e.printStackTrace();
}catch(ExecutionException e){
e.printStackTrace();
}
}
}
Design technology to ensure thread safety
These technologies enable us to ensure thread safety without using locks, Avoid possible problems and overhead caused by locks.
Java runtime storage space
/* Java The Java runtime space can be divided into stack area, heap area and method area (non heap space). Stack space prepares a fixed size of storage space for thread execution. Each thread has an independent stack space, which is allocated to the thread when the thread is created. Every time a method is called in the process stack, a stack frame is allocated to the method. The stack frame is used to store private data such as local variables and return values of the method. That is, local variables are stored in stack space, basic variables are also stored in stack space, and reference type variable values are also stored in stack space, The referenced objects are stored in the heap. Since the thread stacks are independent of each other, one thread cannot access the stack space of another thread, Therefore, the thread has fixed thread safety for the operation of local variables and objects that can only be accessed through the local variables of the current thread. Heap space is used to store objects. It is a memory space that can be dynamically expanded when the JVM is started, When creating an object, allocate storage space to the object in the heap space, and the instance variable is stored in the heap space, Heap space is a space that can be shared by multiple threads, so instance variables can be shared by multiple threads. There may be a thread safety problem when multiple threads operate instance variables at the same time. Non heap space is used to store constants, metadata of classes, etc, Non heap space is also a storage space that can be dynamically expanded when the JVM is started, The metadata of the class includes static constants, which methods the class has and the metadata of these methods (method name, parameters, return value, etc.). Threads can access multiple variables in the heap that are not static, so there may also be a problem of non shared space. Heap space and non heap space are spaces that threads can share, that is, instance variables and static variables can be shared by threads, which may have thread safety problems. Stack space is the private space of threads. Local variables are stored in stack space. Local variables have inherent thread safety. */
Stateless object
An object is the encapsulation of data and data operations. The data contained in an object is called the state of the object(State),
Instance variables and static variables are called state variables,
If the same instance of a class is shared by multiple threads and does not make these threads store the shared state, the instance of the class is called a stateless object(Stateless Object).
On the contrary, if the instance of a class is shared by multiple threads, these threads will have a shared state, then the instance of this class is called a stateful object.
//In fact, stateless objects are objects that do not contain any instance variables or static variables.
The premise of thread safety is that multiple threads have shared data. One way to realize thread safety is to avoid sharing data among multiple threads,
This is the way to use stateless objects.
Immutable object
Immutable object:An object whose state remains unchanged once it is created. Immutable objects have inherent thread safety.
When the state of the real entity of the immutable object changes, the system will create a new immutable object, such as String String object.
/*
An immutable object needs to meet the following conditions:
1)The class itself uses final decoration to prevent changing its definition by creating children.
2)All fields are final modified. When creating an object, the final field must display initialization and cannot be modified.
3)If fields refer to other objects with variable state (collection, array), these fields must be private. */
/*
Main application scenarios of immutable objects:
1)The state of the modeling object changes infrequently
2)At the same time, writing a group of related data can apply immutable objects, which can not only ensure atomicity, but also avoid the use of locks.
3)The immutable object is used as a safe and reliable Map key. The storage location of HashMap key value pairs is related to the hashcode() of the key,
If the internal state of the key changes, the hash code of the key will be different, which may affect the storage location of the key value pair.
If the key of HashMap is an immutable object, the return value of hashcode() method is constant and the storage location is fixed.
*/
Thread specific object
We can choose not to share non thread safe objects. For non thread safe objects,
Each thread creates an instance of the object, and each thread accesses its own instance,
One thread cannot access an instance created by another thread,
In this way, each thread creates its own instance. An object that can only be accessed by one thread is called "Thread specific object"
/*
Thread specific objects not only ensure the thread safety of accessing non thread safe objects, but also avoid the cost of locks
Thread specific objects also have inherent thread safety.
ThreadLocal<T>Class is equivalent to a proxy for a thread to access its unique objects,
That is, each thread can create and access thread specific objects of its own thread through ThreadLocal object,
Generic T specifies the type of object specific to the thread,
A thread can use different ThreadLocal instances to create and access different thread specific objects.
*/
"ThreadLocal An instance is associated with a thread specific object for each thread accessing it,ThreadLocal Each instance has an association between the current thread and a unique instance."

Decorator mode
Decorator mode can be used to achieve thread safety,
The basic idea is to create a corresponding thread safe wrapper object for non thread safe objects,
Client code does not directly access non thread safe objects, but its wrapper objects.
Wrapper objects have the same interface as non thread safe objects,That is, the use of wrapper objects and non thread safety
Objects are used in the same way,The outer packaging object is usually locked inside,Call the method of the corresponding non thread safe object in a thread safe manner.
stay java.util.Collections A set of tools is provided in the tool class synchronizedXXX(xxx)You can put it that is not thread safe xxx Convert collection to thread safe collection,It adopts this decorator mode.
The returned value of the specified collection is also called the outer value of the specified collection.
Benefits:"Separation of concerns",In this design, two versions of objects that implement the same set of functions:Non thread safe objects and thread safe objects
For non thread safe objects, only the functions to be implemented are concerned in the design, and for thread safe objects, only thread safety is concerned.
Suggestions for improving lock performance
Reduce lock holding time
For applications that use locks for concurrency control
If a single thread holds a lock for a long time, it will lead to more fierce lock competition and affect the performance of the system.
In the program, it is necessary to reduce the holding time of the lock as much as possible,
As shown in the following code:
public synchronized void syncMethod(){
othercode1();
mutexMethod();
othercode2();
}
stay syncMethod Synchronization method,Suppose only mutexMethod()Methods need to be synchronized, otHercode1()Method and othercode2()Method does not need to be synchronized.
If othercode1()And othercode2()These two methods take a long time. In the case of large concurrency, this synchronization scheme will lead to a large increase of waiting threads.
//A better optimization scheme is to synchronize only when necessary, which can reduce the holding time of the lock and improve the throughput of the system,
If the above code is changed to:
public voidsyncMethod(){
othercode1();
synchronized (this){
mutexMethod();
}
othercode2();
}
//Only mutemethod () method is synchronized, which can reduce the lock holding time, reduce the possibility of lock conflict and improve the concurrency of the system
Reduce lock granularity
Lock granularity:The number and size of shared data protected by a lock If the number of shared data protected by a lock is large, we call the granularity of the lock coarse; otherwise, we call the granularity of the lock fine; The coarse-grained lock will cause the thread to wait unnecessarily. //Reducing lock granularity is a means to weaken multi-threaded lock competition, //Before JDK7, Java util. concurrent. The concurrenthashmap class adopts the segmented lock protocol, which can improve the concurrency of the program
Use read-write split locks instead of exclusive locks
use ReadWriteLock The read-write separation lock can improve the system performance, Using read-write separation lock is also a special case of reducing lock granularity. The second suggestion is to divide the data structure to reduce the granularity of locks,Then read-write lock is the division of system function points. //In most cases, multiple threads are allowed to read at the same time. Exclusive lock is used in writing. In the case of more reading and less writing, the use of read-write lock can greatly improve the concurrency of the system
Lock separation
//The further extension of the idea of read - write lock is lock separation The read-write lock separates the lock according to the different functions of the read-write operation. According to the characteristics of application functions,Exclusive locks can also be detached. as java.util.concurrent.LinkedBlockingQueue In class take()And put()method Get data from the head of the team respectively,Add data to the tail of the team.Although both methods modify the queue, Because the main body of the operation is a linked list,take()The operation is the head of the linked list,put()The operation is the tail of the linked list, The two do not conflict.If exclusive lock is used,These two operations cannot be concurrent at the same time,Lock separation is used in this class, take()There is a lock when retrieving data, put()You have your own lock when adding data,such take()And put()Independent of each other to achieve concurrency.
Coarse locking
Insert code slice here
JVM lock optimization
//In order to ensure the effective concurrency between multiple threads, each thread is required to hold the lock as short as possible
//However, everything has a degree. If the same lock is continuously requested, synchronized and released, it will also consume system resources
as:
public void method1(){
synchronized(lock){
Synchronization code block 1
}
synchronized(lock){
Synchronization code block 2
)
}
/*
JVM When encountering a series of requests and releases for the same lock,
It will integrate all locks into one request for locks,
So as to reduce the number of requests for locks. This operation is called lock coarsening,
The above code will be integrated into:
*/
public void method1(){
synchronized(lock){
Synchronization code block 1
Synchronization code block 2
)
}
//During the development process, we should also consciously roughen the lock on reasonable occasions, especially when the lock is requested in the loop, such as:
for(int i = 0 ; i< 100; i++){
synchronized(lock){}
}
//In this case, it means that lock application and lock release are required for each cycle, so a more reasonable approach is to request a lock outside the cycle, such as:
synchronized(lock){
for(int i = 0 ; i< 100; i++){}
}
Lock bias
Lock bias is an optimization for lock operation
If a thread acquires a lock,Then the lock enters the bias mode,
When this thread requests the lock again,No more synchronization operation is required,
This saves time on lock requests,The performance of the program is improved.
Lock bias can have better optimization effect when there is no lock competition,
For the scenes with fierce lock competition,Poor effect,
When lock competition is fierce, it may be that different threads request locks every time,At this time, the bias mode fails.
Lightweight Locking
If lock deflection fails,JVM Threads will not be suspended immediately,An optimization tool called lightweight locks will also be used. The header of the shared object is used as a pointer,Point to the inside of the thread stack that holds the lock to judge whether a thread holds the object lock. If the thread obtains the lightweight lock successfully,Enter the critical zone. If obtaining a lightweight lock fails,Indicates that another thread has robbed the lock,Then the lock request of the current thread expands into a heavyweight lock. The current thread goes to the blocking queue and becomes blocked. Bias lock,Lightweight locks are optimistic locks,Heavyweight locks are pessimistic locks When an object is first instantiated,No thread accesses it,It is biased, That is, when it thinks that only one thread can access it, it will favor this thread. Bias to the first thread,This thread is used when modifying the object header to become a biased lock CAS operation, Place the object in the header Threadld,Change to your own ID,When accessing this object later,Just compare ID that will do, Once a second thread accesses the object,Because the deflection lock will not be released actively,Therefore, the second thread can view the bias state of the object, When the second thread accesses the object,Indicates that there is already competition on this object, Check whether the thread that originally held the object lock survived,If it hangs, the object becomes unlocked,Then re favor the new thread; If the original thread is still alive,The stack of the original thread is executed immediately,Check the usage of the object,If the deflection lock is still required,The bias lock is upgraded to a lightweight lock. Lightweight locks think competition exists,However, the degree of competition is very light. Generally, two threads will stagger the operation of the same lock, or wait a little(spin),Another thread releases the lock. When the spin exceeds a certain number of times,Or a thread holds a lock,A thread is spinning,When the third thread accesses again, the lightweight lock will expand into a heavyweight lock,Heavyweight locks, except for the thread holding the lock,Other threads are blocked