Distributed ID Project
Main functions:
- Distributed Project Acquisition ID Unique
- Implement high availability and dynamic scaling
- How to squeeze server resources
1. How to Keep ID Unique
Determining that the primary key ID is obtained is the only global need to ensure that the ID contains these elements:
- Timestamp, globally unique and self-increasing in a single node
- Node ID, each service has a distribution ID that is not unique when the application service is load balanced
- Self-Increasing Random Number, Adjusted to Business Requirements

Explanation:
Node IDs are globally unique in a cluster environment. The timestamp is unique in each node and locally unique. The self-increasing random number is the self-increasing number, which is the increasing number of business scenarios. These three conditions are met before it can become a distributed ID.
2. Process for Generating Distributed ID s
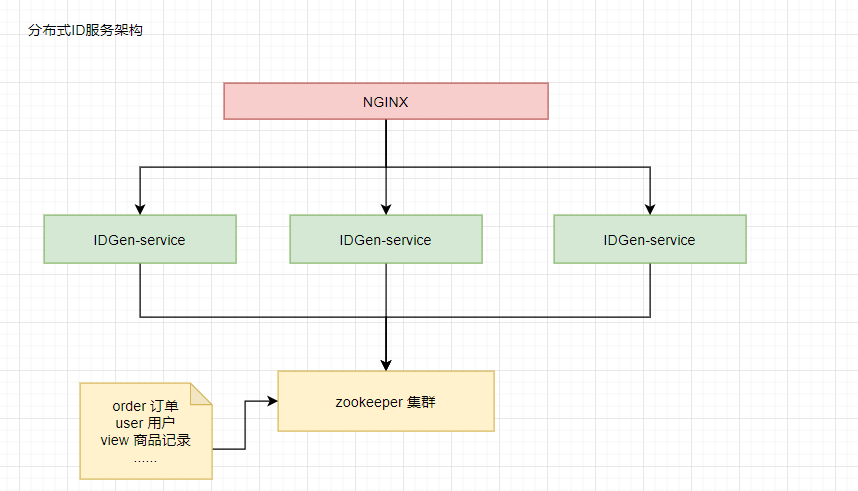
2.1 Architecture Diagram
- IDGen-service is a distributed ID service
- NGINX Support Services Horizontal Extension
- zookeeper accomplishes three main functions:
Business primary key registration (recording maximum self-increment for each business), nodeId for distribution services (guaranteeing inconsistency of nodeId for each service), and clock checking for each node (preventing clock callback for services)
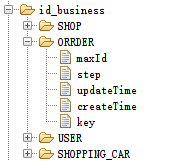
2.2 Business parameter components
As mentioned above, each business needs to be registered with zookeeper, mainly with these parameters:
- maxId Maximum Self-Increment
- Step size, ID does not need to be generated every time, there will be an ID pool in the service, step size is the capacity of the ID pool
- Time update time and creation time, when different nodes apply for the same business resource, update time after the application is completed; Creation time is just a record
- key represents the identity used for different businesses
2.3 ID Cache Objects
ID-Gen interface
public interface IDGen {
/**
* @Param
* key Business id
* */
String get(String key);
}
Realization:
Get the corresponding business primary key from the cache, without which the business generation primary key is not supported; Each business key in a cache operates atomically.
/**
* JVM Cache for Business key
* */
private final Map<String, SegmentBuffer> cache;
@Override
public String get(String businessId) {
if (cache.containsKey(businessId)) {
SegmentBuffer buffer = cache.get(businessId);
// Atomic operation to get id, lock the business
synchronized (buffer) {
// segmentBuffer updates zookeeper persistent data
return this.getIdFromBufferPool(buffer);
}
}
throw new ServiceErrorException("service zk There is no primary key for this business component");
}
buffer object (with ID pool, production ID policy, and lock on resource operation)
- The setIdInPool method sets the thread pool of step length when the project is initialized
- The bufferQueue queue is the new ID pool. Be careful to lock and update the zk resource when loading
- idPool is the current object's ID pool, when the ID pool reaches a certain threshold it is possible to add a new ID to the bufferQueue
public class SegmentBuffer {
public void init(){
this.nextBufferIsReady = false;
this.lock = new ReentrantReadWriteLock();
this.threadRunning = new AtomicBoolean(false);
/*
* Set up id pool
* */
this.setIdInPool();
}
/***
* buffer Queue, run out of one, next
* */
private Queue<SegmentBuffer> bufferQueue;
/**
* id pool
*/
private Queue<String> idPool;
public int getPoolSize() {
return idPool.size();
}
/**
* buffer Group, pre-loaded buffer (joining multiple threads will not affect the speed of the object)
*/
private SegmentBuffer[] segments;
/**
* Is the next id pool finished loading
*/
private volatile boolean nextBufferIsReady = false;
/**
* zk Recording parameters
*/
private String key;
private Long step;
private Long maxId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
/**
* id currently in use
*/
private static volatile AtomicInteger currentIndex = new AtomicInteger(0);
/***
* Current maximum id
* */
private static volatile AtomicReference<String> currentIdString = new AtomicReference<>();
/**
* Lock when getting id, only one thread can get ID
*/
private ReadWriteLock lock;
/***
* Is the thread running
* */
private AtomicBoolean threadRunning;
/**************
* Generate Policy Related
* **
* */
/**
* node id
*/
private Long serverNodeNumber = 0L;
private Long nowTimeStamp() {
return System.currentTimeMillis();
}
/**
* id Generate Policy
* (The algorithm also considers the policy mode import method, policy class + implementation)
*/
private IdGenStrategy idGen;
/***
* Required parameters:
* - Timestamp + serverNodeNumber of distributed nodes + current index
* */
public void setIdInPool() {
idPool = new ConcurrentLinkedQueue<>();
bufferQueue = new ConcurrentLinkedQueue<>();
CommonThreadUtil.execute(() -> {
for(int i = 0; i < step; i++) {
if (Objects.isNull(idGen)) {
throw new IdCreateErrorException("id Empty Generation Policy");
}
String nowId = idGen.createId(nowTimeStamp(), serverNodeNumber, currentIndex.getAndIncrement());
idPool.add(nowId);
currentIdString.set(nowId);
}
});
}
/**
*
* */
public void setNewSegmentBufferInQueue(SegmentBuffer buffer) {
bufferQueue.add(buffer);
this.nextBufferIsReady = true;
}
public boolean hasNextId() {
return !idPool.isEmpty();
}
public String nextId() {
return idPool.poll();
}
}
Preload of 2.4 Business ID
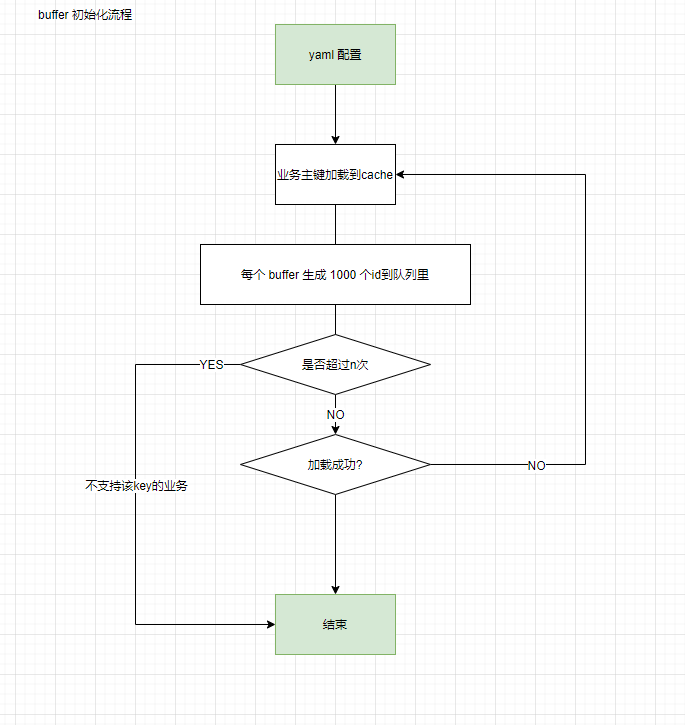
businessKeys is the node information configured in yaml. This setting also has the problem of dynamically expanding the business key. However, new keys can be added to the new cluster to host the new business. Using the same zk cluster is not conflicting.
@Configuration
@Slf4j
public class BusinessConfig {
@Autowired
private BusinessKeyConfigBean businessKeys;
@Autowired
private InitializeServiceImpl initializeService;
/**
* cache Initialized components use application.yaml's business. Value initialization in key
*/
@Bean("cache")
public Map<String, SegmentBuffer> getCache(){
Map<String, SegmentBuffer> cache = new ConcurrentHashMap<>();
log.info("Load number of business components {}", businessKeys.getKey().size());
int size = businessKeys.getKey().size();
for (int i = 0; i < size; i++) {
String key = businessKeys.getKey().get(i);
if (!cache.containsKey(key)) {
cache.put(key, initializeService.setBufferInZk(key, businessKeys.getNode()));
}
}
return cache;
}
}
// .... yaml configuration
@Data
@Component
@ConfigurationProperties(prefix = "business")
public class BusinessKeyConfigBean {
private Long node;
private List<String> key;
}
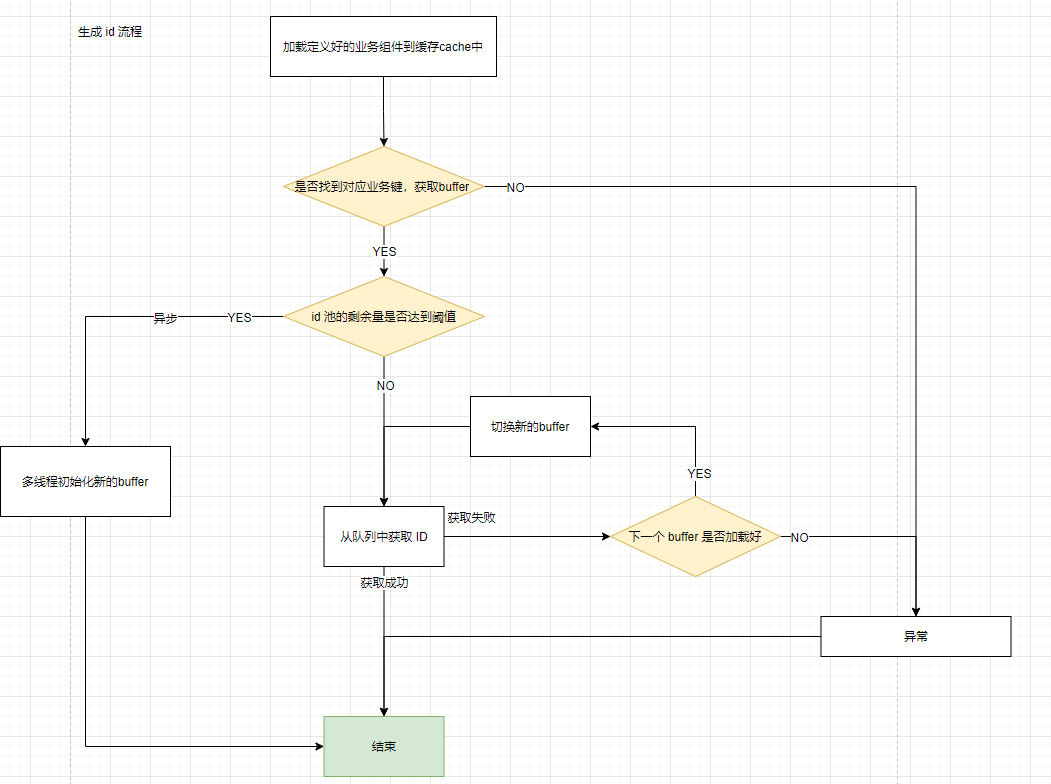
2.5 Main process to get ID
Main flow charts:
3. How to squeeze the server process
- Object locks need to be fine-grained
- Lock only business resources, then use multithreading to complete the remaining code logic
- Optimize your code with no locks, which can improve efficiency but consume server resources
Final: Optimize points, how to increase the concurrency of distributed ID s
- Optimize business parameters (capacity of ID pool and load threshold of next ID pool)
- Start multithreading to load a new thread pool (to solve the problem, the ID pool is empty before the new ID pool is loaded)