Mybatis
brief introduction
MyBatis is an excellent persistence layer framework, which supports custom SQL, stored procedures and advanced mapping. MyBatis eliminates almost all JDBC code and the work of setting parameters and obtaining result sets. MyBatis can configure and map primitive types, interfaces and Java POJO s (Plain Old Java Objects) to records in the database through simple XML or annotations.
Summary:
- Mybatis is a persistence layer framework that works with databases
- Simplifies JDBC operations
- Separation of SQL and code
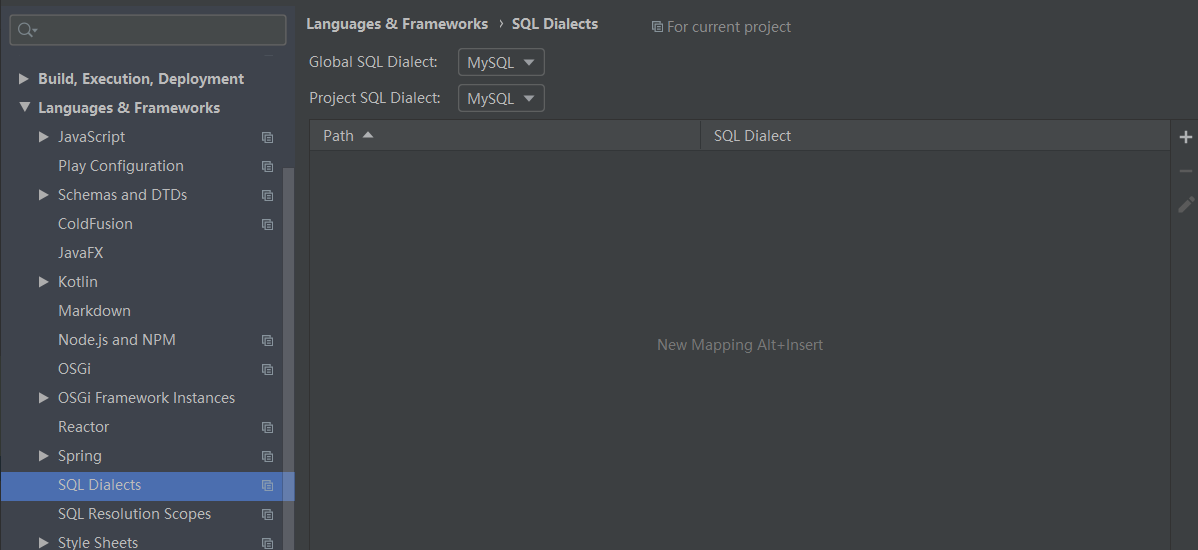
The database table name of idea does not prompt the solution:
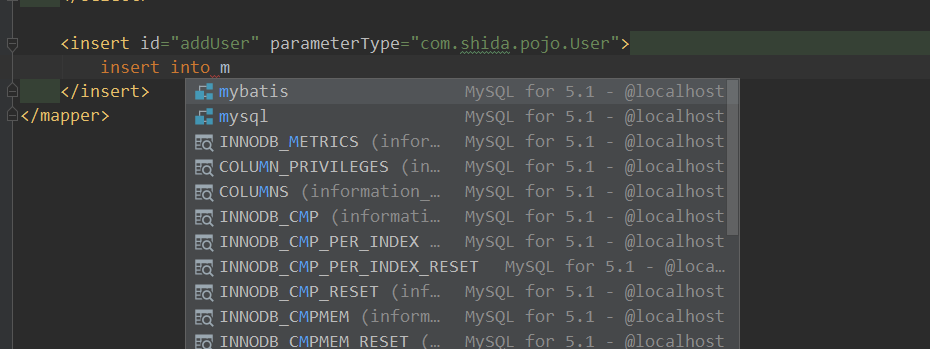
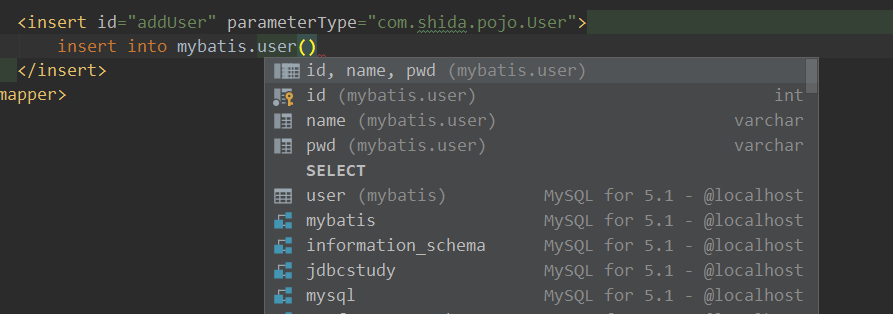
effect
The first Mybatis program
1. Build environment
Create database
CREATE DATABASE `mybatis`; USE `mybatis`; CREATE TABLE `user`( `id` INT(20) NOT NULL , `name` VARCHAR(30) DEFAULT NULL, `pwd` VARCHAR(30) DEFAULT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB DEFAULT CHARSET=UTF8 INSERT INTO `user`(`id`,`name`,`pwd`) VALUES(1,'La La La','123456'), (2,'Zhang San','123456'), (3,'Mad God','123456');
New project
-
Create a normal maven project
-
Delete src directory
-
Import pom dependencies
<dependencies> <!-- mysql drive--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <!-- mybatis--> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.5</version> </dependency> <!-- junit--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
2. Create a module
-
Write Mybatis core configuration file
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!-- configuration Is the core configuration file--> <configuration> <!--Environment configuration default Property to set the database environment to be used by default--> <environments default="development"> <!--Unique identification of environment name id--> <environment id="development"> <!--The default is jdbc Transaction manager--> <transactionManager type="JDBC"/> <!--Use connection pool by default--> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=false&useUnicode=true&characterEncoding=UTF-8"/> <property name="username" value="root"/> <property name="password" value="123456"/> </dataSource> </environment> </environments> </configuration> -
Write Mybatis tool class
public class MybatisUtils { private static SqlSessionFactory sqlSessionFactory; static{ String resource = "mybatis-config.xml"; try { //Get sqlsessionfactory object using Mybatis InputStream inputStream = Resources.getResourceAsStream(resource); sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); } catch (IOException e) { e.printStackTrace(); } } //sqlsession is an object that can execute sql public static SqlSession getSqlsession(){ return sqlSessionFactory.openSession(); } }
3. Write code
Entity class member variables must be consistent with database fields!!!
-
Create entity class
package com.hou.pojo; public class User { private int id; private String name; private String pwd; public User() { } public User(int id, String name, String pwd) { this.id = id; this.name = name; this.pwd = pwd; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getPwd() { return pwd; } public void setPwd(String pwd) { this.pwd = pwd; } } -
Dao interface
public interface UserDao { List<User> getUserList(); } -
The interface implementation class is changed from the original UserDaoImpl to usermapper XML file
-
Namespace is used to bind interfaces
-
resultType automatically encapsulates the result set, so you only need to write the real type of the return value
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!--select Query statement--> <mapper namespace="com.hou.dao.UserDao"> <!--The fully qualified name writes the interface you want to bind--> <select id="getUserList" resultType="com.hou.pojo.User"> <!--id:Method name in interface resultType:return type--> select * from user </select> </mapper>
4. Testing
-
Register mappers in the core configuration file (Only registered mappers will take effect, so don't forget after writing!!)
<mappers> <!--Note that the file path here is/Delimited directory--> <mapper resource="com/hou/dao/UserMapper.xml"/> </mappers> -
Use Junit to test. Note: sqlsession is not thread safe and must be closed after use
@Test public void test(){ //Get sqlsession object SqlSession sqlsession = MybatisUtils.getSqlsession(); //Execute sql UserMapper userMapper = sqlsession.getMapper(UserMapper.class); List<User> userList = userMapper.getUserList(); for (User user : userList) { System.out.println(user); } sqlsession.close(); }
Addition, deletion, modification and query of Mybatis (CRUD)
1. Namespace (namespace) must be fully qualified. For example: com xxx. xxx. XXX (fully qualified class name of the corresponding interface)
2. Add, delete and modify transactions that need to be submitted. Transactions are automatically enabled by default!!!!!!!
3,select
Select query statement;
- id: is the method name of the corresponding namespace;
- resultType: return value type of Sql statement execution
- parameterType: parameter type
#The difference between {} and ${}
1) #{} is a parameter placeholder?, sql precompiling
2) ${} is replaced by string, that is, sql splicing
- Write mapper interface
- In mapper Writing sql in XML
- test
<select id="getUserList" resultType="com.hou.pojo.User">
select * from user
</select>
<select id="getUserByID" resultType="com.hou.pojo.User" parameterType="int">
select * from user where id = #{id}
</select>
4,insert
<insert id="addUser" parameterType="com.hou.pojo.User">
insert into user (id,name,pwd) values (#{id},#{name},#{pwd})
</insert>
5,updata
<update id="updataUser" parameterType="com.hou.pojo.User">
update user set name=#{name},pwd=#{pwd} where id = #{id};
</update>
6,delete
ditto
About some mistakes
- There is a problem of Chinese garbled code in the output XML file!
- maven resource cannot be exported. Problem!
- NullPointerException, no registered resource!
Universal Map
Assuming that there are too many entity classes and tables, fields and parameters in the database, we should consider using map
Throw any parameter you need into the map
@Test
public void addUser(){
SqlSession sqlsession = MybatisUtils.getSqlsession();
UserMapper mapper = sqlsession.getMapper(UserMapper.class);
Map<String, Object> map = new HashMap<String, Object>();
map.put("id",5);
map.put("name","La La La");
map.put("pwd","222222");
mapper.addUser2(map);
sqlsession.commit();
}
<insert id="addUser2" parameterType="map">
insert into user (id,name,pwd) values (#{id},#{name},#{pwd})
</insert>
You only need to write the key in sql directly to pass the parameters of map! [ parameterType=“map”]
Transfer parameters to the object and directly take out the object attributes in sql!
Only when only one parameter is a basic type can it be retrieved directly from sql
Two ways of fuzzy query
[the external chain image transfer fails. The source station may have anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-3qgdyyjn-1619259358443) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200910144237480. PNG)]
! Configuration resolution
Core profile
-
mybatis-config.xml
-
Mybatis's configuration file contains settings and attribute information that will deeply affect mybatis's behavior
configuration(Configuration) properties(Properties) settings(Settings) typeAliases(Type alias) typeHandlers(Type (processor) objectFactory(Object factory) plugins(Plug in) environments(Environment configuration) environment(Environment variables) transactionManager(Transaction manager) dataSource((data source) databaseIdProvider(Database (manufacturer identification) mappers(Mapper)
(environments) environment configuration
-
MyBatis can be configured to adapt to a variety of environments. This mechanism helps to apply SQL mapping to a variety of databases
-
Although multiple environments can be configured, only one environment can be selected for each SqlSessionFactory instance.
-
The default transaction manager of Mybatis is JDBC, and the default connection pool is pooled
-
properties
- These properties can be configured externally and can be replaced dynamically. You can configure these properties either in a typical Java properties file or in a child element of the properties element.
<!--Import external files, and then mybatis-config.xml The attributes in the referenced file can be referenced in the configuration file, and this label can be self closed-->
<properties resource="db.properties">
<!--You can write some parameters here-->
</properties>
-----------------------------------------------------------------------------------------------------------------------------------------
or
<properties resource="db.properties">
<property name="username" value="root"/>
<property name="password" value="123456"/>
</properties>
_________________________________________________________________________________________________________________________________________
<!--Use of reference properties ${}To quote, xml Represents a replacement splice string in-->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
- You can import external files directly, as shown above
- Some properties can be added in the configuration
- If the internal attribute and the external attribute have the same field, the external configuration file is preferred, because the attribute configuration in XML is read first, and then the external file will be read, so the external attribute will overwrite the internal attribute value
Type aliases
Type alias sets an abbreviated name for a Java type. It is only used for XML configuration and is intended to reduce redundant fully qualified class name writing
At present, there are two setting methods to choose from. Method 1 is recommended when there are few entity classes and method 2 is recommended when there are many entity classes!
Method 1: customize the alias for a single entity class
<typeAliases> <typeAlias alias="Author" type="domain.blog.Author"/> <typeAlias alias="Blog" type="domain.blog.Blog"/> <typeAlias alias="Comment" type="domain.blog.Comment"/> <typeAlias alias="Post" type="domain.blog.Post"/> <typeAlias alias="Section" type="domain.blog.Section"/> <typeAlias alias="Tag" type="domain.blog.Tag"/> </typeAliases>
When configured in this way, blog can be used in any domain blog. Blog place.
Method 2: batch setting alias
Scan all classes under the package and alias them all. If there is no annotation, the initial lowercase unqualified class name of the Bean will be used as its alias. For example, domain blog. The alias of author is author.
<typeAliases> <package name="domain.blog"/> </typeAliases>
If annotation is used, its alias is annotation value:
@Alias("author")
public class Author {
...
}
settings
These are extremely important tuning settings in MyBatis, which will change the runtime behavior of MyBatis.
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-lutko6ji-1619259358444) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200910164401282. PNG)]
[the external chain image transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-etfpm13t-1619259358444) (C: \ users \ Hou \ appdata \ roaming \ typora \ typora user images \ image-20200910164438903. PNG)]
mappers
We need to tell MyBatis where to find these statements. Java does not provide a good solution for automatically finding resources, so the best way is to directly tell MyBatis where to find the mapping file. You can use resource references relative to the classpath, or fully qualified resource locators or class and package names, that is, tell MyBatis where to find the mapping file
<!-- Use resource references relative to Classpaths --> <mappers> <mapper resource="org/mybatis/builder/AuthorMapper.xml"/> <mapper resource="org/mybatis/builder/BlogMapper.xml"/> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers> <!-- Use fully qualified resource locators( URL) --> <mappers> <mapper url="file:///var/mappers/AuthorMapper.xml"/> <mapper url="file:///var/mappers/BlogMapper.xml"/> <mapper url="file:///var/mappers/PostMapper.xml"/> </mappers> <!-- Use the mapper interface to implement the fully qualified class name of the class --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> <mapper class="org.mybatis.builder.BlogMapper"/> <mapper class="org.mybatis.builder.PostMapper"/> </mappers> <!-- Register all the mapper interface implementations in the package as mappers --> <mappers> <package name="org.mybatis.builder"/> </mappers>
Note: in addition to the first method, other methods need to be noted:
- Interface and its Mapper configuration file must have the same name!
- Interface and its Mapper configuration file must be in the same package!
- If you want to separate xml from the interface, you need to create the same directory as the package where the interface is located in the resources directory, and put the mapper corresponding to the interface into it
Lifecycle and scope
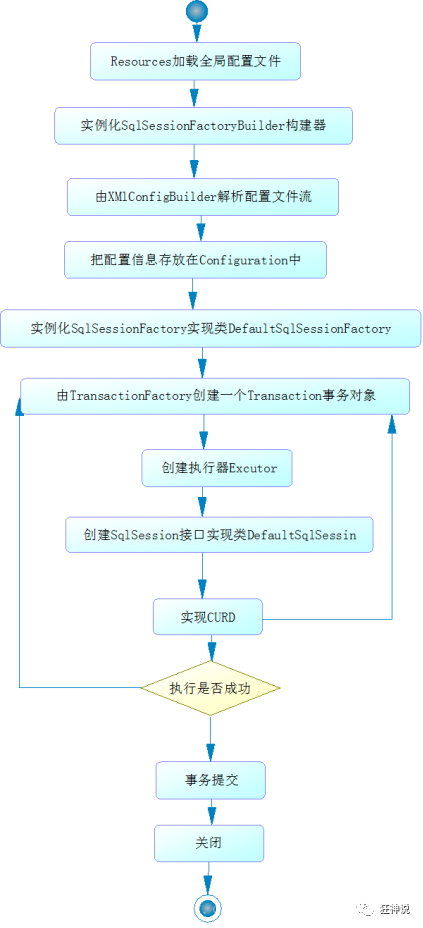
Mybatis process:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-tl5gm77y-1619259358445) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200910170901085. PNG)]
SqlSessionFactoryBuilder:
This class can be instantiated, used and discarded. Once SqlSessionFactory is created, it is no longer needed.
SqlSessionFactory:
Once SqlSessionFactory is created, it should always exist during the operation of the application. There is no reason to discard it or recreate another instance. The best practice of using SqlSessionFactory is not to create multiple times during application operation. The best scope of SqlSessionFactory is application scope. It is recommended to use singleton mode or static singleton mode.
SqlSession:
Each thread should have its own SqlSession instance. The instance of SqlSession is not thread safe, so it cannot be shared, so its best scope is the request or method scope.
Never put the reference of SqlSession instance in the static field of a class, or even the instance variable of a class. You must never place a reference to a SqlSession instance in any type of managed scope
Consider putting SqlSession in a scope similar to HTTP requests. In other words, every time you receive an HTTP request, you can open a SqlSession and close it after returning a response.
Click: https://mybatis.org/mybatis-3/zh/getting-started.html
If SqlSessionFactory is equivalent to a database Connection pool, SqlSession is equivalent to a database Connection (Connection object),
You can execute multiple SQL statements in a transaction, and then commit or roll back the transaction through its commit, rollback and other methods. So it should survive in a business request,
After processing a complete request, you should close the connection and return it to SqlSessionFactory, otherwise the database resources will be consumed quickly and the system will be paralyzed. Therefore, use the try... catch... Properly statement to ensure that it is closed correctly.
The name of the property and the name of the field are inconsistent
Solution:
Scheme 1: alias in sql statement example: user_id as id;
Scheme 2: modify the mapping name by using resultMap of result set mapping
column: corresponds to the field in the database
Property: the property of the corresponding entity class
[the external chain image transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-4zhhgs6ti-1619259358446) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200910180720968. PNG)]
journal
1. Log factory
If an exception occurs in a database operation and we need to troubleshoot it, we need to use the log
journal:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-ftmpxbxd-1619259358447) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200912153705622. PNG)]
- SLF4J
- LOG4J [Master]
- LOG4J2
- JDK_LOGGING
- COMMONS_LOGGING
- STDOUT_LOGGING [mastering]
- NO_LOGGING
The specific log implementation used in Mybatis is set in the settings!
STDOUT_LOGGING: standard log output
Configuration method: directly configure key value pairs in settings in the configuration file (available in the official document)
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
Log4j: Log4j is Apache An open source project
By using Log4j, we can control the destination of log information delivery Console , documents GUI Components, even socket servers NT Event recorder UNIX SyslogDaemon Etc;
We can also control the output format of each log
Configuration method:
-
Import the dependency of log4j
<!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> -
Write configuration file
#Output the log information with the level of DEBUG to the two destinations of console and file. The definitions of console and file are in the following code log4j.rootLogger=DEBUG,console,file #Relevant settings of console output log4j.appender.console = org.apache.log4j.ConsoleAppender log4j.appender.console.Target = System.out log4j.appender.console.Threshold=DEBUG log4j.appender.console.layout = org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=[%c]-%m%n #Relevant settings for file output log4j.appender.file = org.apache.log4j.RollingFileAppender log4j.appender.file.File=./log/hou.log log4j.appender.file.MaxFileSize=10mb log4j.appender.file.Threshold=DEBUG log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n #Log output level log4j.logger.org.mybatis=DEBUG log4j.logger.java.sql=DEBUG log4j.logger.java.sql.Statement=DEBUG log4j.logger.java.sql.ResultSet=DEBUG log4j.logger.java.sql.PreparedStatement=DEBUG -
Configure settings in the configuration file
<settings> <setting name="logImpl" value="LOG4J"/> </settings> -
Simple use of log4j. Use log4j to output logs in the program
//Be careful not to lead the package wrong: org apache. log4j. The logger method parameter is the class of the current class static Logger logger = Logger.getLogger(MyTest.class); @Test public void selectUser() { logger.info("info: get into selectUser method"); logger.debug("debug: get into selectUser method"); logger.error("error: get into selectUser method"); SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); List<User> users = mapper.selectUser(); for (User user: users){ System.out.println(user); } session.close(); }
paging
Why pagination?
Paging at the back end is to reduce the amount of data processing, because if you do not page, it is a great burden for the program to find out all the data at once
--paging sql: select * from user limit Start bit
Steps:
1. Write mapper xml
<select id="selectUser" parameterType="map" resultType="user">
select * from user limit #{startIndex},#{pageSize}
</select>
2. Mapper corresponds to the interface, and the parameter is map
//Select all users to implement paging List<User> selectUser(Map<String,Integer> map)
3. Pass in the parameter test in the test class
- Infer: start position = (current page - 1) * page size
//Paging query, two parameters: StartIndex and PageSize
@Test
public void testSelectUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int currentPage = 1; //Page number
int pageSize = 2; //How many are displayed per page
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("startIndex",(currentPage-1)*pageSize);
map.put("pageSize",pageSize);
List<User> users = mapper.selectUser(map);
for (User user: users){
System.out.println(user);
}
session.close();
}
Using annotation development
Using annotation development
-
The initial configuration information of MyBatis is based on XML, and the mapping statement (SQL) is also defined in XML. MyBatis 3 provides a new annotation based configuration. Unfortunately, the expressiveness and flexibility of Java annotations are very limited. The most powerful MyBatis mapping cannot be built with annotations
-
sql types are mainly divided into:
-
- @select ()
- @update ()
- @Insert ()
- @delete ()
**Note: * * mapper is not required for annotation development XML Mapping file
1. We add annotations to our interface
//Query all users
@Select("select id,name,pwd password from user")
public List<User> getAllUser();
2. Inject in the core configuration file of mybatis
<!--use class Binding interface--> <mappers> <mapper class="com.kuang.mapper.UserMapper"/> </mappers>
3. Let's go and test
@Test
public void testGetAllUser() {
SqlSession session = MybatisUtils.getSession();
//In essence, it makes use of the dynamic proxy mechanism of jvm
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> users = mapper.getAllUser();
for (User user : users){
System.out.println(user);
}
session.close();
}
4. Use Debug to see the essence
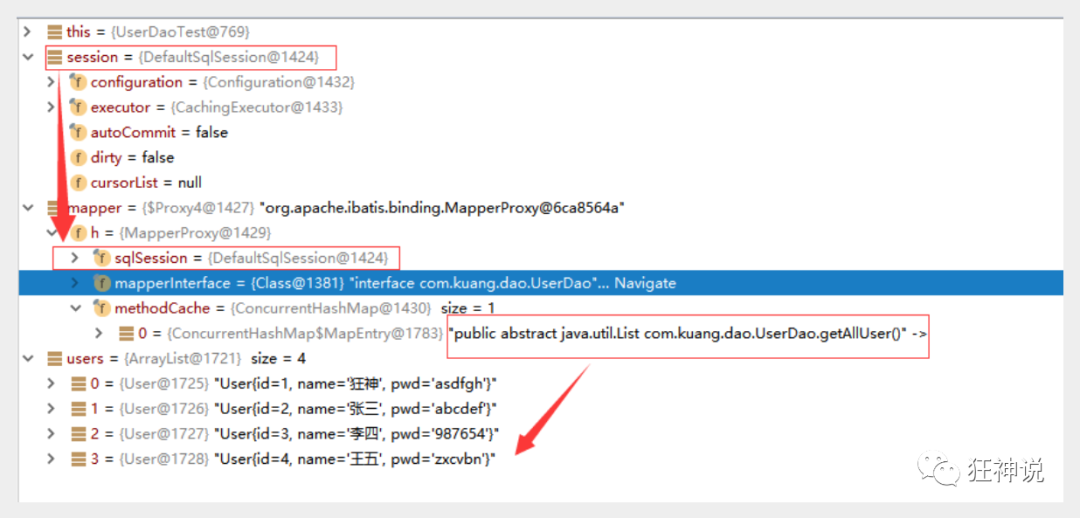
5. In essence, it makes use of the dynamic proxy mechanism of jvm
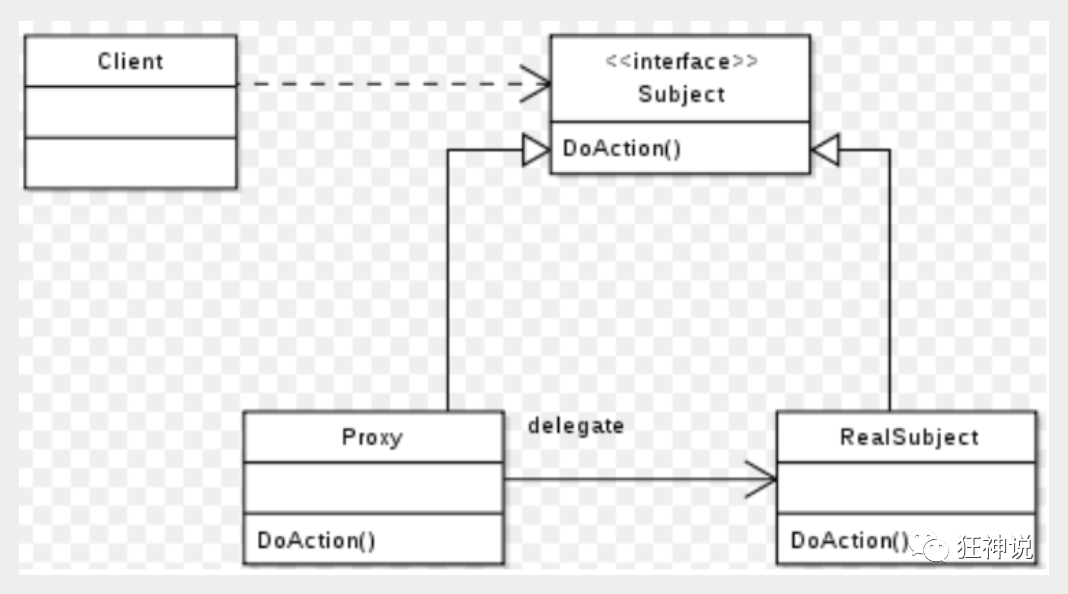
6. Detailed execution process of Mybatis
Addition, deletion and modification of notes
Transform the getSession() method of MybatisUtils tool class and overload the implementation.
//Get SqlSession connection
public static SqlSession getSession(){
return getSession(true); //Transaction auto commit
}
public static SqlSession getSession(boolean flag){
return sqlSessionFactory.openSession(flag);
}
[note] ensure that the entity class corresponds to the database field
Query:
1. Write interface method annotation
//Query user by id
@Select("select * from user where id = #{id}")
User selectUserById(@Param("id") int id);
2. Testing
@Test
public void testSelectUserById() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
session.close();
}
newly added:
1. Write interface method annotation
//Add a user
@Insert("insert into user (id,name,pwd) values (#{id},#{name},#{pwd})")
int addUser(User user);
2. Testing
@Test
public void testAddUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = new User(6, "Qin Jiang", "123456");
mapper.addUser(user);
session.close();
}
Modification:
1. Write interface method annotation
//Modify a user
@Update("update user set name=#{name},pwd=#{pwd} where id = #{id}")
int updateUser(User user);
2. Testing
@Test
public void testUpdateUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = new User(6, "Qin Jiang", "zxcvbn");
mapper.updateUser(user);
session.close();
}
Delete:
1. Write interface method annotation
//Delete by id
@Delete("delete from user where id = #{id}")
int deleteUser(@Param("id")int id);
2. Testing
@Test
public void testDeleteUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
mapper.deleteUser(6);
session.close();
}
[Note: remember to deal with the transaction when adding, deleting or modifying]
About @ Param
@The Param annotation is used to give a name to a method parameter. The following are the principles for the use of the summary:
- When the method accepts only one parameter, @ Param may not be used.
- When the method accepts multiple parameters, it is recommended to use the @ Param annotation to name the parameters.
- If the parameter is a JavaBean, @ Param cannot be used.
- When @ Param annotation is not used, there can only be one parameter and it is a java bean.
#Difference from $
-
#The function of {} is mainly to replace the placeholder in the preparestatement? [recommended, with the feature of preventing sql injection]
INSERT INTO user (name) VALUES (#{name}); INSERT INTO user (name) VALUES (?); -
The function of ${} is to replace the string directly
INSERT INTO user (name) VALUES ('${name}'); INSERT INTO user (name) VALUES ('kuangshen');
Using annotations and configuration files for collaborative development is the best practice of MyBatis!
Use of lombook plug-in
Laziness is the ladder of scientific and technological progress
Use steps:
-
Install Lombok plug-in in IDEA!
-
Import the jar package of lombok in the project
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.10</version> </dependency> -
Just annotate the entity class!
@Data @AllArgsConstructor @NoArgsConstructor
@Getter and @Setter @FieldNameConstants @ToString @EqualsAndHashCode @AllArgsConstructor, @RequiredArgsConstructor and @NoArgsConstructor @Log, @Log4j, @Log4j2, @Slf4j, @XSlf4j, @CommonsLog, @JBossLog, @Flogger @Data @Builder @Singular @Delegate @Value @Accessors @Wither @SneakyThrows
explain:
@Data: Generation: parameterless construction, get,set,tostring,hashcode,equals @AllArgsConstructor: Generation: the structure with parameters, but the corresponding structure without parameters is gone @NoArgsConstructor: Generation: parameterless construction, which can cooperate with the above one AllArgsConstructor Use, so that there is no parameter and there are both parameters @EqualsAndHashCode @ToString @Getter
Be careful when using. Sometimes there are some inexplicable bug s when using
Many to one processing
Many to one:
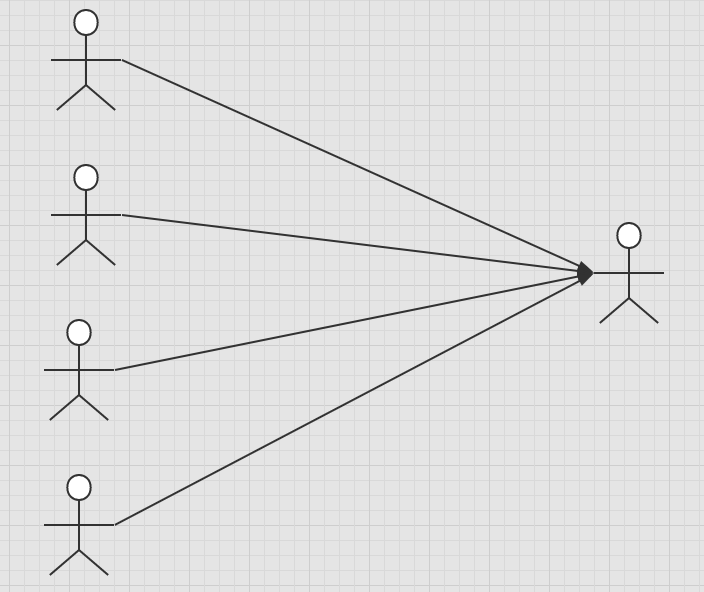
- Multiple students correspond to one teacher
- For students, it is related to... Multiple students and one teacher [many to one]
- For teachers, a collection, a teacher, has many students [one to many]
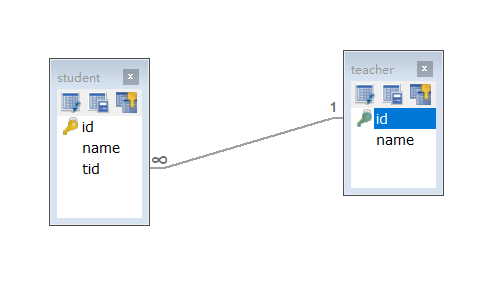
Requirements: find all students and find the corresponding teacher according to the foreign key tid in the student table
SQL:
CREATE TABLE `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO teacher(`id`, `name`) VALUES (1, 'Miss Qin');
CREATE TABLE `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teacher` (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('1', 'Xiao Ming', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('2', 'Xiao Hong', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('3', 'Xiao Zhang', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('4', 'petty thief', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('5', 'Xiao Wang', '1');
nested queries
Idea:
- Query all student information
- According to the student's tid, check the corresponding teacher
<mapper namespace="com.hou.dao.StudentMapper">
<select id="getStudent" resultMap="StudentTeacher">
select * from mybatis.student
</select>
<resultMap id="StudentTeacher" type="com.hou.pojo.Student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--
Complex attributes need to be handled separately
If it is an object: association
If it is a set: collection
-->
<association property="teacher" column="tid" javaType="com.hou.pojo.Teacher" select="getTeacher"/>
</resultMap>
<select id="getTeacher" resultType="com.hou.pojo.Teacher">
select * from mybatis.teacher where id = #{tid}
</select>
</mapper>
understand:
-
First, query all the student table information, including the field tid
-
Then nest the query and use (Association) to associate the query. select a query
-
In the sub query, follow the tid found to find the corresponding teacher!
-
Here, the parameter passed in the getTeacher query statement is the tid in the queried student information, because there is only one parameter, which will be automatically matched and obtained
Result query (recommended)
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-kfhiy2ik-1619259358449) (C: \ users \ Hou \ appdata \ roaming \ typora user images \ image-20200915182233355. PNG)]
One to many processing
Demand: find out the teacher and the student information under the teacher's name!
A teacher with multiple students is a one to many relationship for teachers!
A single object uses: javaType to specify the type of the attribute
The collection specifies the generic type of the collection with the confliction: oftepe attribute
But they are all used for complex environment queries
Method 1. Result query
public class Teacher {
private int id;
private String name;
//Students under the teacher's name
private List<Student> students;
}
//Get the information of all students and teachers under the designated teacher
Teacher getTeacher(@Param("tid") int id);
<select id="getTeacher" resultMap="TeacherStudent">
select s.id sid,s.name sname,t.id tid,t.name tname from mybatis.student s,mybatis.teacher t
where s.tid=t.id and t.id = #{tid}
</select>
<!---->
<resultMap id="TeacherStudent" type="com.hou.pojo.Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="com.hou.pojo.Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
Test:
@Test
public void test(){
SqlSession sqlsession = MybatisUtils.getSqlsession();
TeacherMapper mapper = sqlsession.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacher(3);
System.out.println(teacher);
sqlsession.commit();
sqlsession.close();
}
//test result
Teacher(id=3, name=Miss Zhang, students=[Student(id=3, name=Xiao Zhang, tid=3), Student(id=5, name=Xiao Wang, tid=3)])
2. Query nesting
Nested processing by query
1. TeacherMapper interface writing method
public Teacher getTeacher2(int id);
2. Write Mapper configuration file corresponding to the interface
<select id="getTeacher2" resultMap="TeacherStudent2">
select * from teacher where id = #{id}
</select>
<resultMap id="TeacherStudent2" type="Teacher">
<!--column Is a one to many foreign key , Write the column name of a primary key-->
<collection property="students" javaType="ArrayList" ofType="Student"column="id" select="getStudentByTeacherId"/>
</resultMap>
<select id="getStudentByTeacherId" resultType="Student">
select * from student where tid = #{id}
</select>
3. Register Mapper file in mybatis config file
4. Testing
@Test
public void testGetTeacher2(){
SqlSession session = MybatisUtils.getSession();
TeacherMapper mapper = session.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacher2(1);
System.out.println(teacher.getName());
System.out.println(teacher.getStudents());
}
Summary
1. association Association
2. collection -
3. Therefore, association is used for one-to-one and many to one relationships, while collection is used for one to many relationships
4. Both JavaType and ofType are used to specify the object type
- JavaType is used to specify the type of property in pojo
- ofType specifies the type mapped to pojo in the list collection attribute and the type of constraint in the generic type.
Note:
1. Ensure the readability of SQL and make it easy to understand as much as possible
2. According to the actual requirements, try to write SQL statements with higher performance
3. Pay attention to the inconsistency between attribute name and field
4. Pay attention to the correspondence between fields and attributes in one to many and many to one
5. Try to use Log4j and check your errors through the log
Dynamic Sql
What is dynamic SQL: dynamic SQL refers to generating different SQL statements according to different conditions
introduce
What is dynamic SQL: dynamic SQL refers to generating different SQL statements according to different query conditions
Official website description: MyBatis One of its powerful features is its dynamics SQL. If you use JDBC Or other similar framework experience, you can experience splicing according to different conditions SQL The pain of the sentence. For example, when splicing, make sure you don't forget to add the necessary spaces, and pay attention to removing the comma of the last column name in the list. Utilization dynamics SQL This characteristic can completely get rid of this pain. Although dynamic was used before SQL It's not easy, but it is MyBatis Provided can be used in any SQL Powerful dynamic mapping in statements SQL Language can improve this situation. dynamic SQL Element and JSTL Or based on similar XML Similar to our text processor. stay MyBatis In previous versions, there were many elements that took time to understand. MyBatis 3 The element types have been greatly simplified. Now you only need to learn half of the original elements. MyBatis Adopt powerful based OGNL To eliminate most of the other elements. ------------------------------- - if - choose (when, otherwise) - trim (where, set) - foreach -------------------------------
The SQL statements we wrote before are relatively simple. If there are complex businesses, we need to write complex SQL statements, which often need to be spliced. If we don't pay attention to splicing SQL, errors may be caused due to the lack of quotation marks, spaces and so on.
So how to solve this problem? This requires the use of mybatis dynamic SQL. Through tags such as if, choose, when, otherwise, trim, where, set and foreach, it can be combined into very flexible SQL statements, which not only improves the accuracy of SQL statements, but also greatly improves the efficiency of developers.
1. Build environment
Create a new database table: blog
Fields: id, title, author, create_time,views
CREATE TABLE `blog` ( `id` varchar(50) NOT NULL COMMENT 'Blog id', `title` varchar(100) NOT NULL COMMENT 'Blog title', `author` varchar(30) NOT NULL COMMENT 'Blogger', `create_time` datetime NOT NULL COMMENT 'Creation time', `views` int(30) NOT NULL COMMENT 'Views' ) ENGINE=InnoDB DEFAULT CHARSET=utf8
1. Create Mybatis foundation project
2. IDutil utility class
public class IDUtil {
public static String genId(){
return UUID.randomUUID().toString().replaceAll("-","");
}
}
3. Entity class preparation [pay attention to the function of set method]
import java.util.Date;
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
//set,get....
}
4. Write Mapper interface and xml file
public interface BlogMapper {
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.BlogMapper">
</mapper>
5. mybatis core configuration file, underline Hump Automatic Conversion
<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <setting name="logImpl" value="STDOUT_LOGGING"/> </settings> <!--register Mapper.xml--> <mappers> <mapper resource="mapper/BlogMapper.xml"/> </mappers>
6. Insert initial data
Write interface
//Add a new blog int addBlog(Blog blog);
sql configuration file
<insert id="addBlog" parameterType="blog">
insert into blog (id, title, author, create_time, views)
values (#{id},#{title},#{author},#{createTime},#{views});
</insert>
Initialize blog method
@Test
public void addInitBlog(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = new Blog();
blog.setId(IDUtil.genId());
blog.setTitle("Mybatis So simple");
blog.setAuthor("Madness theory");
blog.setCreateTime(new Date());
blog.setViews(9999);
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Java So simple");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Spring So simple");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Microservices are so simple");
mapper.addBlog(blog);
session.close();
}
Initialization data completed!
2. if statement
Demand: according to the author's name and blog name to query the blog! If the author's name is empty, query only according to the blog name; otherwise, query according to the author's name
1. Writing interface classes
//Demand 1 List<Blog> queryBlogIf(Map map);
2. Writing SQL statements
<!--Requirement 1:
According to the author's name and blog name to query the blog!
If the author's name is empty, query only according to the blog name; otherwise, query according to the author's name,If none, query all
select * from blog where title = #{title} and author = #{author}
-->
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog where 1=1
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
3. Testing
@Test
public void testQueryBlogIf(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, String> map = new HashMap<String, String>();
map.put("title","Mybatis So simple");
map.put("author","Madness theory");
List<Blog> blogs = mapper.queryBlogIf(map);
System.out.println(blogs);
session.close();
}
In this way, we can see that if the identity 1 = 1 is not written, if the author is equal to null, the query statement is select * from user where title=#{title}, but what if the title is empty? Then the query statement is select * from user where and author=#{author}. This is a wrong SQL statement. How to solve it? Please see the following where statement!
Where
Modify the above SQL statement;
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</where>
</select>
The "where" tag will know that if it contains a return value in the tag, it will insert a "where". In addition, if the content returned by the tag starts with AND OR, it will be eliminated.
3. set statement
Similarly, the above query SQL statement contains the where keyword. If the update operation contains the set keyword, how can we deal with it?
1. Write interface method
int updateBlog(Map map);
2. sql configuration file
<!--be careful set Are separated by commas-->
<update id="updateBlog" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author}
</if>
</set>
where id = #{id};
</update>
3. Testing
@Test
public void testUpdateBlog(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, String> map = new HashMap<String, String>();
map.put("title","dynamic SQL");
map.put("author","Qin Jiang");
map.put("id","9d6a763f5e1347cebda43e2a32687a77");
mapper.updateBlog(map);
session.close();
}
4. choose statement
Sometimes, we don't want to use all the query conditions. We just want to select one of them. If one of the query conditions is satisfied, we can use the choose tag to solve such problems, which is similar to the switch statement in Java
1. Write interface method
List<Blog> queryBlogChoose(Map map);
2. sql configuration file
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>
</select>
3. Test class
@Test
public void testQueryBlogChoose(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("title","Java So simple");
map.put("author","Madness theory");
map.put("views",9999);
List<Blog> blogs = mapper.queryBlogChoose(map);
System.out.println(blogs);
session.close();
}
5. SQL fragment
Sometimes we may use a certain sql statement too much. In order to increase the reusability of the code and simplify the code, we need to extract these codes and call them directly when using them.
Extract SQL fragment:
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
Reference SQL fragment:
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<!-- quote sql Clip, if refid If the specified is not in this document, it needs to be preceded by namespace -->
<include refid="if-title-author"></include>
<!-- Other can be quoted here sql fragment -->
</where>
</select>
be careful:
① . it is better to define sql fragments based on a single table to improve the reusability of fragments
② . do not include where in the sql fragment
6,Foreach
Modify the id of the first three data in the database to 1,2,3;
Requirement: we need to query the blog information with id 1, 2 and 3 in the blog table
1. Write interface
List<Blog> queryBlogForeach(Map map);
2. Writing SQL statements
<select id="queryBlogForeach" parameterType="map" resultType="blog">
select * from blog
<where>
<!--
collection:Specifies the collection properties in the input object
item:The generated object is traversed each time
open:Splice string at the beginning of traversal
close:String spliced at the end
separator:Traverse the strings that need to be spliced between objects
select * from blog where 1=1 and (id=1 or id=2 or id=3)
-->
<foreach collection="ids" item="id" open="and (" close=")" separator="or">
id=#{id}
</foreach>
</where>
</select>
3. Testing
@Test
public void testQueryBlogForeach(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap map = new HashMap();
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(3);
map.put("ids",ids);
List<Blog> blogs = mapper.queryBlogForeach(map);
System.out.println(blogs);
session.close();
}
Summary: in fact, the compilation of dynamic sql statements is often a problem of splicing. In order to ensure the accuracy of splicing, we'd better first write the original sql statements, and then change them through the dynamic sql of mybatis to prevent errors. It is the skill to master it by using it in practice.
-
In mybatis, if there are multiple parameters, the @ param annotation should be added to name the parameters. Then, if there are parameters that are reference objects and want to use its attributes in xml, the @ param annotation should be used
Parameter name The attribute name is as follows:
public int modifyUser(@Param("user")User user,@Param("id")int id);<update id="modifyUser"> update smbms.smbms_user <set> <if test="user.userName !=null and user.userName != ''">userName = #{user.userName},</if> <if test="user.userRole != null and user.userRole !=''">userRole = #{user.userRole},</if> <if test="user.gender != null and user.gender != ''">gender = #{user.gender},</if> <if test="user.birthday != null">birthday = #{user.birthday},</if> <if test="user.phone != null and user.phone != ''">phone = #{user.phone},</if> <if test="user.address != null and user.address != ''">address = #{user.address},</if> <if test="user.modifyBy != null and user.modifyBy !=''">modifyBy = #{user.modifyBy},</if> <if test="user.modifyDate != null">modifyDate = #{user.modifyDate}</if> </set> where id = #{id} </update>
Dynamic SQL is widely used in development. You must master it skillfully!
cache
brief introduction
- What is a Cache?
- Temporary data in memory
- Put the data frequently queried by users in the cache, and when users query the data, they do not need to query from the disk (relational database data file), but from the cache, so as to improve the query efficiency and solve the performance problem of high concurrency system.
- Why cache
- Reduce the number of interactions with the database, reduce system overhead and improve system efficiency
- What kind of data can be cached
- Data that is frequently queried and not frequently changed.
1. mybatis cache
- Mybatis contains a very powerful query caching feature, which can easily customize and configure the cache. Caching can greatly improve query efficiency.
- Mybatis provides two levels of default cache: the first level cache and the second level cache
- By default, only L1 cache is on. (sqlSession level cache, also known as local cache)
- L2 cache needs to be started and configured manually. It is based on namespace level cache.
- In order to improve scalability, MyBatis defines the Cache interface Cache. We can customize the L2 Cache by implementing the Cache interface
Cache:
-
The results of all select statements in the mapping statement file will be cached.
-
All insert, update, and delete statements in the mapping statement file flush the cache. (because the original data may be changed, the whole cache will be refreshed ~)
-
The cache will use the least recently used (LRU) algorithm to clear the unnecessary cache.
-
The cache is not refreshed regularly (that is, there is no refresh interval).
-
The cache holds 1024 references to a list or object, regardless of what the query method returns.
-
The cache is treated as a read / write cache, which means that the acquired object is not shared and can be safely modified by the caller without interfering with potential modifications made by other callers or threads.
2. L1 cache
Whenever we use MyBatis to open a session with the database, MyBatis will create a SqlSession object to represent a database session.
In a conversation with the database, we may repeatedly execute the same query statements. If we do not take some measures, each query will query the database. If we do the same query in a very short time, their results are likely to be identical. Because it is very expensive to query the database once, This may cause a great waste of resources.
In order to solve this problem and reduce the waste of resources, MyBatis will establish a simple cache in the SqlSession object representing the session to cache the results of each query. When the next query, if it is judged that there is an identical query before, it will directly take the results out of the cache and return them to the user, There is no need to query the database again.
As shown in the following figure, MyBatis will create a local cache in a SqlSession object, the representation of a session. For each query, it will try to find out whether it is in the cache according to the query conditions. If it is in the cache, it will be directly taken out of the cache and returned to the user; Otherwise, read the data from the database, store the query results in the cache and return them to the user.
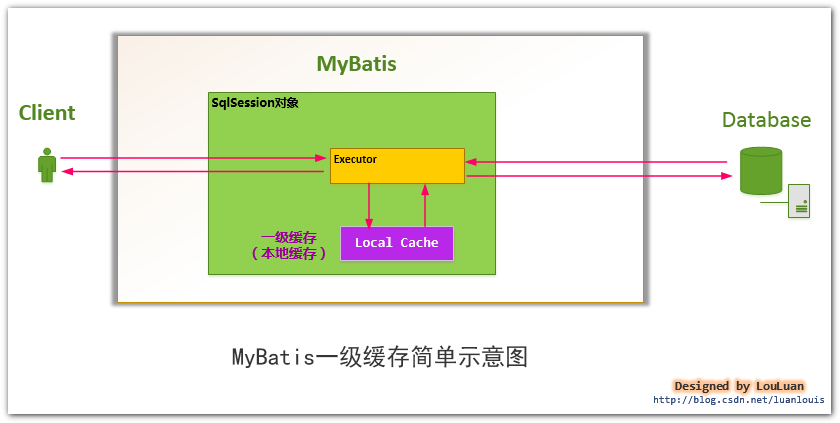
For Session level data cache, we call it level-1 data cache, which is called level-1 cache for short
The L1 cache is turned on by default and is only valid in one sqlSession, that is, get the connection to close this interval.
The L1 cache can be cleaned up manually: sqlsession clearCache();
3. L2 cache
-
L2 cache is a global cache. Because the scope of L1 cache is too low, L2 cache was born
-
Cache based on namespace level. A namespace corresponds to a L2 cache
-
Working mechanism:
- When a session queries a statement, the data will be placed in the first level cache of the current session;
- If the current session is closed, the L1 cache corresponding to this session is gone; But what we want is that when the session is closed, the data in the L1 cache will be saved to the L2 cache; That is, after the L1 cache fails, the cache content will be delivered from the L1 cache to the L2 cache.
- The new session query information can get the content from the L2 cache;
- The data found by different mapper s will be placed in their corresponding cache (map);
Steps:
-
Turn on global cache
<!--Display enable L2 global cache--> <setting name="cacheEnabled" value="true"/> -
In mapper Using L2 cache in XML
<!--Use L2 cache--> <cache/>
These attributes of the cache can be modified through the attributes of the cache element. For example:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
This more advanced configuration creates a FIFO cache, which is refreshed every 60 seconds. It can store up to 512 references of the result object or list, and the returned objects are considered read-only. Therefore, modifying them may conflict with callers in different threads.
Available purge strategies are:
- LRU – least recently used: removes objects that have not been used for the longest time.
- FIFO – first in first out: remove objects in the order they enter the cache.
- SOFT – SOFT reference: removes objects based on garbage collector status and SOFT reference rules.
- WEAK – WEAK references: remove objects more actively based on garbage collector status and WEAK reference rules.
The default purge policy is LRU.
The flush interval property can be set to any positive integer. The set value should be a reasonable amount of time in milliseconds. The default is not set, that is, there is no refresh interval. The cache will only be refreshed when the statement is called.
The size (number of references) attribute can be set to any positive integer. Pay attention to the size of the object to be cached and the memory resources available in the running environment. The default value is 1024.
The readOnly property can be set to true or false. A read-only cache returns the same instance of the cache object to all callers. Therefore, these objects cannot be modified. This provides a significant performance improvement. The read-write cache returns a copy of the cached object (through serialization). It will be slower, but safer, so the default value is false.
Indicates that the L2 cache is transactional. This means that when SqlSession completes and commits, or completes and rolls back, but the insert/delete/update statement with flushCache=true is not executed, the cache will be updated.
-
Summary:
- As long as the L2 cache is enabled, it is effective under the same Mapper
The secondary cache of MyBatis is the Application level cache, which can improve the efficiency of database query and improve the performance of Application.
Check out the blog: https://louluan.blog.csdn.net/article/details/41408341
ps://img-blog.csdn.net/20141121213425390)
For Session level data cache, we call it level-1 data cache, which is called level-1 cache for short
The L1 cache is turned on by default and is only valid in one sqlSession, that is, get the connection to close this interval.
The L1 cache can be cleaned up manually: sqlsession clearCache();
3. L2 cache
-
L2 cache is a global cache. Because the scope of L1 cache is too low, L2 cache was born
-
Cache based on namespace level. A namespace corresponds to a L2 cache
-
Working mechanism:
- When a session queries a statement, the data will be placed in the first level cache of the current session;
- If the current session is closed, the L1 cache corresponding to this session is gone; But what we want is that when the session is closed, the data in the L1 cache will be saved to the L2 cache; That is, after the L1 cache fails, the cache content will be delivered from the L1 cache to the L2 cache.
- The new session query information can get the content from the L2 cache;
- The data found by different mapper s will be placed in their corresponding cache (map);
Steps:
-
Turn on global cache
<!--Display enable L2 global cache--> <setting name="cacheEnabled" value="true"/> -
In mapper Using L2 cache in XML
<!--Use L2 cache--> <cache/>
These attributes of the cache can be modified through the attributes of the cache element. For example:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
This more advanced configuration creates a FIFO cache, which is refreshed every 60 seconds. It can store up to 512 references of the result object or list, and the returned objects are considered read-only. Therefore, modifying them may conflict with callers in different threads.
Available purge strategies are:
- LRU – least recently used: removes objects that have not been used for the longest time.
- FIFO – first in first out: remove objects in the order they enter the cache.
- SOFT – SOFT reference: removes objects based on garbage collector status and SOFT reference rules.
- WEAK – WEAK references: remove objects more actively based on garbage collector status and WEAK reference rules.
The default purge policy is LRU.
The flush interval property can be set to any positive integer. The set value should be a reasonable amount of time in milliseconds. The default is not set, that is, there is no refresh interval. The cache will only be refreshed when the statement is called.
The size (number of references) attribute can be set to any positive integer. Pay attention to the size of the object to be cached and the memory resources available in the running environment. The default value is 1024.
The readOnly property can be set to true or false. A read-only cache returns the same instance of the cache object to all callers. Therefore, these objects cannot be modified. This provides a significant performance improvement. The read-write cache returns a copy of the cached object (through serialization). It will be slower, but safer, so the default value is false.
Indicates that the L2 cache is transactional. This means that when SqlSession completes and commits, or completes and rolls back, but the insert/delete/update statement with flushCache=true is not executed, the cache will be updated.
-
Summary:
- As long as the L2 cache is enabled, it is effective under the same Mapper
The secondary cache of MyBatis is the Application level cache, which can improve the efficiency of database query and improve the performance of Application.
Check out the blog: https://louluan.blog.csdn.net/article/details/41408341
This article is partly quoted from madness, and there are some other blog things, which may be a little messy