Mybatis - Basics
⭐ sketch
Mybatis – MyBatis 3 | introduction - official address
You can learn from the official address, and most of the content of this article is also quoted here
1 what is mybatis
A persistence layer framework, which is also a semi ORM (semi automated) framework, encapsulates JDBC code at the bottom, so that programmers can focus more on business and don't waste time on redundant architecture code
2 what is ORM
ORM (Object Relational Mapping), Object Relational Mapping, is a technology to solve the mapping relationship between relational database data and simple Java objects (POJO s). In short, ORM is to automatically persist the objects in the program to the relational database by using the metadata describing the mapping between the object and the database.
3 difference between hibernate and MyBatis
Same point
The bottom layer encapsulates JDBC and is the persistence layer framework
difference
Mapping relationship
- Hibernate is a fully automatic ORM framework. Java objects are associated with database tables. It is more complex to deal with multi table relationships
- Mybatis is a semi-automatic ORM framework. Java objects are associated with SQL execution results. It is relatively easier to deal with multi table relationships than Hibernate
Performance and portability
- Hibernate encapsulates SQL statements (without manual programming by programmers) and supports most types of databases on the market, but the performance consumption is greater than that of Mybatis, especially in more complex scenarios
- Mybatis needs to write SQL manually. The development workload is relatively large, but the optimization space is also relatively large. It can carry out dynamic SQL splicing, reverse engineering and third-party cache support, and does not support database independence
summary
MyBatis is a compact, convenient, efficient, simple, direct and semi-automatic persistence layer framework
Hibernate is a powerful, convenient, efficient, complex, indirect and fully automated persistence layer framework
⭐ Introductory case
hello world demo
1. XML based construction method
The more common construction method is to write SQL code in XML text
1.1 basic process
- Connection information of db.properties database
- mybatis-config.xml data source configuration
- Java entity class
- Dao interface
- Mapper.xml SQL statement writing
1.2 code example
db.properties
jdbc.driver=com.mysql.cj.jdbc.Driver jdbc.url=jdbc:mysql://47.120.146.140:3306/book jdbc.username=*** jdbc.password=****
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- environments Represents the configuration Mybatis Multiple environments can be configured,
In many specific environments, use default Property specifies the environment to use when actually running -->
<properties resource="dbconfig/db.properties"></properties>
<settings>
<!--Globally turns on or off any cache that has been configured by all mappers in the configuration file. -->
<setting name="cacheEnabled" value="true"/>
</settings>
<environments default="mysql">
<!-- environment Represents the configuration Mybatis A specific environment -->
<environment id="mysql">
<!-- Mybatis Built in transaction manager -->
<transactionManager type="JDBC"/>
<!-- Configure data sources -->
<dataSource type="POOLED">
<!--
There are three data sources
UNPLLED: That is, a new link is created each time without using the connection pool method
POOLED: Use connection pool
JNDI: use JNDI Mode link
-->
<!-- Specific information for establishing database connection -->
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- appoint Mybatis The specific location of the mapping file is where you write it sql The file you want-->
<mapper resource="sql/UserMapper.xml"/>
</mappers>
</configuration>
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--SQL Statement configuration file mybatis Load in configuration file-->
<!--mapper Label for SQL Mapping between statements and methods-->
<mapper namespace="main.UserDao">
<select id="getAll" resultType="main.User">
select USERNAME from USER;
</select>
<insert id="insert" parameterType="main.User">
INSERT INTO USER VALUES (#{id},#{userName},#{jobS},#{phone});
</insert>
<delete id="deleteUser" parameterType="int">
DELETE FROM USER WHERE id = #{id};
</delete>
</mapper>
UserDao.java
import java.util.List;
public interface UserDao {
List<User> getAll();
int insert(User userName);
int deleteUser(Integer id);
List<USER> findByName(String value);
}
User.java
@Data
public class User {
private Integer id;
private String userName;
private String jobS;
private String phone;
}
Test method
public class Run {
public static void main(String[] args) throws IOException {
String configPath = "mybatis-config.xml";
// Read XML file through input stream
// Create factory object for sql session
InputStream resourceAsStream = Resources.getResourceAsStream(configPath);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// Using the factory object, open an SQL session
SqlSession sqlSession = sqlSessionFactory.openSession();
// Use reflection to read the bytecode file of the interface and return the interface object
UserDao mapper = sqlSession.getMapper(UserDao.class);
// Call the method through this object, and this method will be associated with Mapper.xml
List<User> UserList = mapper.getAll();
UserList.forEach(System.out::println);
}
}
2 annotation based construction
Since the annotation construction method is not common in enterprises, it is not described too much here, and the relevant annotation development support is rarely introduced on the official website, so I introduced this blog written by other bloggers to learn about it
⭐ Configuration / mapping file resolution
This chapter mainly briefly describes the elements in the daily Mapper mapping / configuration file
1 configuration file
The configuration here is complex and will be replaced by the SpringBoot application.yaml file later
1.1 properties
The attributes here represent the following points, one of which is the connection information of the database
db.properties
jdbc.driver=com.mysql.cj.jdbc.Driver jdbc.url=jdbc:mysql://47.120.146.140:3306/book jdbc.username=root jdbc.password=szsti@123
mybatis-config.xml
<!-- dataSource:Data source configuration -->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
If a property is configured in more than one place, MyBatis will be loaded in the following order:
- First read the properties specified in the properties element body
- Then read the property file under the classpath according to the resource attribute in the properties element, or read the property file according to the path specified by the url attribute, and overwrite the previously read property with the same name
- Finally, read the attribute passed as a method parameter and overwrite the previously read attribute with the same name
Therefore, the attributes passed through the method parameters have the highest priority, followed by the configuration file specified in the resource/url attribute, and the attributes specified in the properties element have the lowest priority
Even, you can add placeholder parameters to the attribute configuration to specify the default value, but I don't think it's very useful. I won't explain it here
1.2 setting
Example
<settings>
<!-- Enable L2 cache -->
<setting name="cacheEnabled" value="true"/>
<!-- Delayed loading -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- Monolingual sentences return multiple result sets -->
<setting name="multipleResultSetsEnabled" value="true"/>
<!-- Use column labels instead of column names -->
<setting name="useColumnLabel" value="true"/>
<!-- Primary key self generation -->
<setting name="useGeneratedKeys" value="false"/>
<!-- Automatic field mapping -->
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
Attribute description
| Set name | describe | Effective value | Default value |
|---|---|---|---|
| cacheEnabled | Globally turn on or off any cache configured in all mapper profiles. | true | false | true |
| lazyLoadingEnabled | Global switch for delayed loading. When on, all associated objects are loaded late. In a specific association, the switch state of the item can be overridden by setting the fetchType property. | true | false | false |
| aggressiveLazyLoading | When on, the call of any method will load all deferred load properties of the object. Otherwise, each deferred load attribute is loaded on demand (see lazyLoadTriggerMethods). | true | false | false (true by default in versions 3.4.1 and earlier) |
| multipleResultSetsEnabled | Whether to allow a single statement to return multiple result sets (database driver support is required). | true | false | true |
| useColumnLabel | Use column labels instead of column names. The actual performance depends on the database driver. For details, refer to the relevant documents of the database driver or observe through comparative tests. | true | false | true |
| useGeneratedKeys | Allow JDBC to support automatic generation of primary keys, which requires database driver support. If set to true, automatic generation of primary keys will be enforced. Although some database drivers do not support this feature, they can still work normally (such as Derby). | true | false | False |
| autoMappingBehavior | Specifies how MyBatis should automatically map columns to fields or properties. NONE means to turn off automatic mapping; PARTIAL will automatically map only fields that do not have nested result mappings defined. FULL will automatically map any complex result sets, whether nested or not. | NONE, PARTIAL, FULL | PARTIAL |
| autoMappingUnknownColumnBehavior | Specifies the behavior of discovering unknown columns (or unknown attribute types) for automatic mapping targets. NONE: do nothing WARNING: output WARNING log ('org.apache.ibatis.session.AutoMappingUnknownColumnBehavior 'log level must be set to WARN) FAILING: mapping failed (throw SqlSessionException) | NONE, WARNING, FAILING | NONE |
| defaultExecutorType | Configure the default actuator. SIMPLE is an ordinary actuator; The REUSE executor will REUSE the prepared statement; BATCH executors not only REUSE statements, but also perform BATCH updates. | SIMPLE REUSE BATCH | SIMPLE |
| defaultStatementTimeout | Set the timeout, which determines the number of seconds the database driver waits for a database response. | Any positive integer | Not set (null) |
| defaultFetchSize | Set a recommended value for the fetchSize of the driven result set. This parameter can only be overridden in query settings. | Any positive integer | Not set (null) |
| defaultResultSetType | Specifies the default rollover policy for the statement. (added to 3.5.2) | FORWARD_ ONLY | SCROLL_ SENSITIVE | SCROLL_ Intrinsic | default (equivalent to not set) | Not set (null) |
| safeRowBoundsEnabled | Whether paging (rowboundaries) is allowed in nested statements. Set to false if allowed. | true | false | False |
| safeResultHandlerEnabled | Whether the result handler is allowed in nested statements. Set to false if allowed. | true | false | True |
| mapUnderscoreToCamelCase | Whether to enable automatic hump naming mapping, that is, from the classic database column name A_COLUMN maps to the classic Java property name aColumn. | true | false | False |
| localCacheScope | MyBatis uses the Local Cache mechanism to prevent circular references and accelerate repeated nested queries. The default value is SESSION, which caches all queries executed in a SESSION. If the value is set to state, the Local Cache will only be used to execute statements, and different queries of the same SqlSession will not be cached. | SESSION | STATEMENT | SESSION |
| jdbcTypeForNull | When no specific JDBC type is specified for the parameter, the default JDBC type of NULL value. Some database drivers need to specify the JDBC type of the column. In most cases, they can directly use the general type, such as NULL, VARCHAR or OTHER. | JdbcType constant, common values: NULL, VARCHAR or OTHER. | OTHER |
| lazyLoadTriggerMethods | Specifies which methods of the object trigger a deferred load. | Comma separated list of methods. | equals,clone,hashCode,toString |
| defaultScriptingLanguage | Specifies the default scripting language used for dynamic SQL generation. | A type alias or fully qualified class name. | org.apache.ibatis.scripting.xmltags.XMLLanguageDriver |
| defaultEnumTypeHandler | Specifies the default TypeHandler used by Enum. (added to 3.4.5) | A type alias or fully qualified class name. | org.apache.ibatis.type.EnumTypeHandler |
| callSettersOnNulls | Specifies whether to call the setter (put) method of the mapping object when the value in the result set is null, which is useful when relying on Map.keySet() or null value for initialization. Note that basic types (int, boolean, etc.) cannot be set to null. | true | false | false |
| returnInstanceForEmptyRow | When all columns of the returned row are empty, MyBatis returns null by default. When this setting is enabled, MyBatis will return an empty instance. Note that it also applies to nested result sets, such as collections or associations. (added to 3.4.2) | true | false | false |
| logPrefix | Specifies the prefix that MyBatis adds to the log name. | Any string | Not set |
| logImpl | Specify the specific implementation of the log used by MyBatis. If it is not specified, it will be found automatically. | SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING | Not set |
| proxyFactory | Specifies the proxy tool used by Mybatis to create deferred loading objects. | CGLIB | JAVASSIST | JAVASSIST (MyBatis 3.3 up) |
| vfsImpl | Specify the implementation of VFS | Fully qualified names of classes for the implementation of custom VFS, separated by commas. | Not set |
| useActualParamName | It is allowed to use the name in the method signature as the statement parameter name. In order to use this feature, your project must be compiled in Java 8 with the - parameters option. (added to 3.4.1) | true | false | true |
| configurationFactory | Specify a class that provides a Configuration instance. The returned Configuration instance is used to load the deferred load property value of the deserialized object. This class must contain a method with the signature static Configuration getConfiguration(). (added to 3.2.3) | A type alias or fully qualified class name. | Not set |
| shrinkWhitespacesInSql | Remove extra space characters from SQL. Note that this also affects text strings in SQL. (added to 3.5.5) | true | false | false |
| defaultSqlProviderType | Specifies an sql provider class that holds provider method (Since 3.5.6). This class apply to the type(or value) attribute on sql provider annotation(e.g. @SelectProvider), when these attribute was omitted. | A type alias or fully qualified class name | Not set |
These are the materials introduced into the official website. To sum up, they are mainly for the relevant configurations of the database, such as caching, timeout control, and third-party integration
1.3 type alias
When filling in the type name in xml, it is usually written with the fully qualified class name, and the type alias is to simplify the amount of code and the writing of the fully qualified class name. In addition, Mybatis also has a built-in type alias for general data types. I think it's a chicken's rib, but this varies from person to person, so I won't elaborate here, See official website
1.4 processor type
When we call select to query a single object, the fields queried from the database can always be automatically assigned to the JavaBean, which is the use of the type processor. Of course, we usually complete the manual mapping through resultMap. I think there are many methods. If we can customize the type processor for the data types that cannot be processed by Mybatis
The specific methods are as follows: implement the org.apache.ibatis.type.TypeHandler interface, or inherit a convenient class org.apache.ibatis.type.BaseTypeHandler
Re learn Mybatis: type processor, you have to be able to play this- Zhihu (zhihu.com)
Mybatis – MyBatis 3 | configuration | type processor
1.5 target factory
"When we use MyBatis to execute query statements, we usually have a return type. This is to add a resultType (or resultMap) attribute to sql in the mapper file for control. Both resultType and resultMap can control the return type. As long as this configuration is defined, we can automatically return the results I want." a new instance of the returned results is created by the object factory
1.6 plug in
It is also called interceptor. The responsibility chain mode is adopted to dynamically organize multiple plug-ins (interceptors) to form links. By default, custom plug-ins are allowed to intercept
-
Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
Actuator
-
ParameterHandler (getParameterObject, setParameters)
Parameter processing
-
ResultSetHandler (handleResultSets, handleOutputParameters)
Result set processing
-
StatementHandler (prepare, parameterize, batch, update, query)
SQL syntax build processing
1.7 environment configuration
1
1.8 database manufacturer identification
1
1.9 mapper
1
2 mapping file
This chapter mainly describes xxxMapper.xml, namely the SQL file
2.1 top level elements of SQL mapping file
- Cache – the cache configuration for this namespace.
- Cache ref – refers to the cache configuration of other namespaces.
- resultMap – describes how to load objects from the database result set. It is the most complex and powerful element.
- Resulttype - return type of SQL statement result
- parameterMap – old style parameter mapping. This element has been discarded and may be removed in the future! Please use inline parameter mapping. This element is not described in the document.
- parameterType - SQL statement input parameter type
- sql – a repeatable sentence block that can be referenced by other statements.
- Insert – map insert statements.
- Update – map update statements.
- Delete – map delete statements.
- select – map query statements.
2.2 Select
An example of the select element of a simple query
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
This statement, named selectPerson, accepts an int (or Integer) parameter and returns an object of HashMap type. The key is the column name and the value is the corresponding value in the result row.
Note the parameter symbol:
#{id}
This tells MyBatis to create a PreparedStatement parameter. In JDBC, such a parameter will be identified by a placeholder "?" in SQL and passed to a new preprocessing statement.
Properties of the Select element
| attribute | describe |
|---|---|
| id | A unique identifier in the namespace that can be used to reference this statement. |
| parameterType | The fully qualified name or alias of the class that will be passed into the parameters of this statement. This property is optional because MyBatis can infer the parameters of the specific incoming statement through the type handler. The default value is unset. |
| parameterMap | The property used to reference an external parameterMap is currently obsolete. Please use inline parameter mapping and parameterType property. |
| resultType | The fully qualified name or alias of the class that you expect to return results from this statement. Note that if a collection is returned, it should be set to the type contained in the collection, not the type of the collection itself. Only one can be used between resultType and resultMap at the same time. |
| resultMap | A named reference to an external resultMap. Result mapping is the most powerful feature of MyBatis. If you understand it thoroughly, many complex mapping problems can be solved. Only one can be used between resultType and resultMap at the same time. |
| flushCache | When it is set to true, as long as the statement is called, the local cache and L2 cache will be emptied. The default value is false. |
| useCache | Setting it to true will cause the results of this statement to be cached by the secondary cache. The default value is true for the select element. |
| timeout | This setting is the number of seconds the driver waits for the database to return the requested result before throwing an exception. The default value is unset (database driven). |
| fetchSize | This is a recommended value for the driver. Try to make the number of result lines returned by the driver in batch each time equal to this setting value. The default value is unset (drive dependent). |
| statementType | Optional status, PREPARED or CALLABLE. This will make MyBatis use statement, PreparedStatement or CallableStatement respectively. The default value is PREPARED. |
| resultSetType | FORWARD_ONLY,SCROLL_ SENSITIVE, SCROLL_ Either intrinsic or DEFAULT (equivalent to unset). The DEFAULT value is unset (dependent on database driver). |
| databaseId | If the database vendor ID (databaseIdProvider) is configured, MyBatis will load all statements without databaseId or matching the current databaseId; If there are statements with and without, the statements without are ignored. |
| resultOrdered | This setting is only applicable to nested result select statements: if it is true, it will be assumed that nested result sets or groups are included. When a main result row is returned, there will be no reference to the previous result set. This makes it possible to get nested result sets without running out of memory. Default: false. |
| resultSets | This setting applies only to multiple result sets. It will list the result sets returned after the statement is executed, and give each result set a name, separated by commas. |
2.3 insert, update and delete
Play the same way as Select. Next, check the attributes of insert, update and delete elements
| attribute | describe |
|---|---|
| id | A unique identifier in the namespace that can be used to reference this statement. |
| parameterType | The fully qualified name or alias of the class that will be passed into the parameters of this statement. This property is optional because MyBatis can infer the parameters of the specific incoming statement through the type handler. The default value is unset. |
| parameterMap | The property used to reference an external parameterMap is currently obsolete. Please use inline parameter mapping and parameterType property. |
| flushCache | When it is set to true, as long as the statement is called, the local cache and L2 cache will be emptied. The default value is (for insert, update and delete statements) true. |
| timeout | This setting is the number of seconds the driver waits for the database to return the requested result before throwing an exception. The default value is unset (database driven). |
| statementType | Optional status, PREPARED or CALLABLE. This will make MyBatis use statement, PreparedStatement or CallableStatement respectively. The default value is PREPARED. |
| useGeneratedKeys | (only applicable to insert and update) this will make MyBatis use the getGeneratedKeys method of JDBC to retrieve the primary key generated inside the database (such as the auto increment field of relational database management systems such as MySQL and SQL Server). The default value is false. |
| keyProperty | (only applicable to insert and update) specify the attribute that can uniquely identify the object. MyBatis will use the return value of getGeneratedKeys or the selectKey sub element of the insert statement to set its value. The default value is unset. If more than one column is generated, multiple attribute names can be separated by commas. |
| keyColumn | (only applicable to insert and update) set the column name of the generated key value in the table. In some databases (such as PostgreSQL), it must be set when the primary key column is not the first column in the table. If more than one column is generated, multiple attribute names can be separated by commas. |
| databaseId | If the database vendor ID (databaseIdProvider) is configured, MyBatis will load all statements without databaseId or matching the current databaseId; If there are statements with and without, the statements without are ignored. |
2.4 SQL reuse
This element can be used to define reusable SQL code fragments for use in other statements. Parameters can be determined statically (when loaded), and different parameter values can be defined in different include elements. For example:
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
This SQL fragment can be used in other statements, for example:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
(this is too complicated and I don't think it is often used.) you can also use the attribute value in the refid attribute or internal statement of the include element, for example:
<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>
2.5 primary key return
Usually, we set the primary key id of the database table to self increment
When inserting a record, we do not set its primary key id, but let the database automatically generate the primary key id of the record
After inserting a record, how to get the primary key id of the record automatically generated by the database?
- Using useGeneratedKeys and keyProperty properties
<insert id="insert" parameterType="com.yogurt.po.Student" useGeneratedKeys="true" keyProperty="id">
INSERT INTO student (name,score,age,gender) VALUES (#{name},#{score},#{age},#{gender});
</insert>
- Use < selectkey > sub Tags
<insert id="insert" parameterType="com.yogurt.po.Student">
INSERT INTO student (name,score,age,gender) VALUES (#{name},#{score},#{age},#{gender});
<selectKey keyProperty="id" order="AFTER" resultType="int" >
SELECT LAST_INSERT_ID();
</selectKey>
</insert>
If you use a database such as mysql that supports self incrementing primary keys, you can simply use the first method;
For databases that do not support self incrementing primary keys, such as oracle, there is no concept of primary key return, and a primary key needs to be generated BEFORE insertion. At this time, you can use the tag, set its order attribute to BEFORE, and write the SQL statement generating the primary key in the tag body. In this way, BEFORE inserting, it will be processed to generate the primary key, and then perform the real insertion operation.
The tag is actually an SQL. The execution of this SQL can be placed before or after the execution of the main SQL, and the results of its execution will be encapsulated on the specified properties of the Java object entered into the parameter. Note that sub tags can only be used in and tags. Last above_ INSERT_ id () is actually a function provided by MySQL, which can be used to obtain the primary key id of the recently inserted or updated record.
Attributes of the selectKey element
| attribute | describe |
|---|---|
| keyProperty | The target property to which the result of the selectKey statement should be set. If more than one column is generated, multiple attribute names can be separated by commas. |
| keyColumn | Returns the column name of the generated column property in the result set. If more than one column is generated, multiple attribute names can be separated by commas. |
| resultType | Type of result. Usually MyBatis can be inferred, but for more accuracy, there will be no problem writing it. MyBatis allows any simple type to be used as the type of primary key, including string. If you generate more than one column, you can use an Object or Map that contains the desired attributes. |
| order | Can be set to BEFORE or AFTER. If it is set to BEFORE, it will first generate the primary key, set the keyProperty, and then execute the insert statement. If it is set to AFTER, the insert statement is executed first, and then the statement in the selectKey - this is similar to the behavior of Oracle database. There may be embedded index calls inside the insert statement. |
| statementType | As before, MyBatis supports mapping statements of state, PREPARED and CALLABLE types, representing Statement, PreparedStatement and CallableStatement types respectively. |
2.6 parameters of occupancy
Let's start with an example
<insert id="insertUser" parameterType="User">
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
</insert>
If a parameter object of User type is passed into the statement, the id, username and password attributes are looked up, and their values are passed into the parameters of the preprocessing statement.
This is a neat way to pass statement parameters. However, the function of parameter mapping is much more than that.
The following are less used. Just have a look
First, like other parts of MyBatis, parameters can specify a special data type.
# { property , javaType = int , jdbcType = NUMERIC }
Note that JDBC requires that if a column allows null values and will use null parameters, the JDBC type must be specified
To further customize type handling, you can specify a special type processor class (or alias), such as:
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
It seems that the configuration of parameters is becoming more and more cumbersome, but in fact, such cumbersome configuration is rarely required.
For numeric types, you can also set numericScale to specify the number of digits to be retained after the decimal point.
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
Finally, the mode attribute allows you to specify IN, OUT, or INOUT parameters. If the mode of the parameter is OUT or INOUT, the property value of the parameter object will be modified to return as an output parameter. If the mode is OUT (or INOUT) and the JDBC type is CURSOR (that is, Oracle's REFCURSOR), you must specify a ResultMap reference to map the result set ResultMap to the type of the parameter. Note that the javaType attribute here is optional. If it is left blank and the JDBC type is CURSOR, it will be automatically set to ResultMap.
#{department, mode=OUT, jdbcType=CURSOR, javaType=ResultSet, resultMap=departmentResultMap}
MyBatis also supports many advanced data types, such as structures, but when using the out parameter, you must explicitly set the name of the type. For example (prompt again, in practice, it should be like this, and line breaks are not allowed):
#{middleInitial, mode=OUT, jdbcType=STRUCT, jdbcTypeName=MY_TYPE, resultMap=departmentResultMap}
Although the above options are powerful, most of the time, you just need to specify the attribute name, specify the JDBC type for the column that may be empty, and leave the rest to MyBatis to infer.
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
2.7 string substitution
${columnName}
It is easy to be attacked by SQL. Try not to use it. I like to use the function concat('%', XXXX, '%')
⭐ Result mapping
It mainly explains the usage of resultMap. For some complex result returns, ordinary JavaBean s may not be able to receive them, and deal with the scenario of multi table associated query
1 configuration description
Main label:
-
resultMap: used for mapping, similar to solving the problem of aliasing
-
association: object name
-
Collection: collection name
-
Discriminator: discriminator
Sub label:
- Property: class property name
- column: database field name
- javaType: result type. Write the package path of this class. Use it with association or discriminator
- ofType: generic class in a collection, used with collection
- select:
2 ordinary mapping (one-to-one)
java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class TestDao {
private String studentName;
private String courseName;
}
xml
<select id="arrayTestDaoList" resultMap="TestDemo01">
SELECT b.stu_name as studentname,
a.cou_name as coursename
FROM curricula x
JOIN course a ON a.cou_id = x.cou_id
JOIN student b ON b.stu_id = x.stu_id
</select>
<resultMap id="TestDemo01" type="JavaBean.TestDao">
<result property="studentName" column="studentname"/>
<result property="courseName" column="coursename"/>
</resultMap>
Or you can use alias in SQL statement to make mybatis map for us automatically
3 association (one-to-one)
It's too simple to write. It's probably a mapping of object names, similar to the above
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="main.StudentMapper">
<!-- Multi table Association processing method I -->
<!-- resultMap You can name it casually. The follow-up needs to be on this ID For configuration -->
<select id="getStu" resultMap="StudentUser">
select *
from Student;
</select>
<!-- property:JavaBean
column:DataBase -->
<resultMap id="StudentUser" type="main.Student">
<id property="" column="Primary key">
<result property="studentId" column="StudentId"/>
<result property="studentName" column="StudentName"/>
<result property="teacherId" column="TeacherId"/>
<!-- association:object column:Database corresponding column name javaType:Result type
collection:aggregate -->
<association property="sUser" column="TeacherId" javaType="main.User" select="main.UserMapper.getId"/>
</resultMap>
<!-- Multi table Association processing method 2: nested processing according to the results -->
<select id="getStuUserResult" resultMap="StudentUser2">
select StudentName,
TeacherId,
ID,
USERNAME
from Student,
USER
where Student.TeacherId = USER.ID;
</select>
<resultMap id="StudentUser2" type="main.Student">
<result property="studentName" column="StudentName" />
<result property="teacherId" column="TeacherId" />
<!-- association:object column:Database corresponding column name javaType:Result type property: Attribute name
collection:aggregate ofType: Generic classes in Collections
-->
<association property="sUser" column="main.User" javaType="main.User">
<result property="id" column="ID" />
<result property="userName" column="USERNAME" />
</association>
</resultMap>
</mapper>
4 collection (many to many)
First of all, let's talk about the logic of the results after my experiment
It is a one to many scenario. For example, a student chooses many courses, as follows
Student number student name course number course name
101 three 11 big data
101 three 12 artificial intelligence
102 Li Si 12 artificial intelligence
102 Li Si 15 Internet of things
102 Li Si 16 Chef
103 Wang Wu 13 cloud computing
103 Wang Wu 14 routing switching
Zhang San chose three and two courses, and Li Si chose three courses, so he needs to use a list to receive data. One object course is not enough
Let's take a look at the code
Student.java
public class Student {
private Integer stuId;
private String stuName;
private List<Course> courseList;
// A student class that contains the student's name, number, and a list of courses he has selected
}
public class Course {
private Integer couId;
private String couName;
}
StudentMapper interface
public interface StudentMapper {
List<Student> studentList();
}
xml file
<select id="studentList" resultMap="TestDemo01">
SELECT b.stu_id as stuId,
b.stu_name as stuName,
a.cou_id as couId,
a.cou_name as couName
FROM curricula x
JOIN course a ON a.cou_id = x.cou_id
JOIN student b ON b.stu_id = x.stu_id
ORDER BY b.stu_id
</select>
<resultMap id="TestDemo01" type="JavaBean.Student">
<id property="stuId" column="stuId"/>
<result property="stuName" column="stuName"/>
<collection property="courseList" ofType="JavaBean.Course">
<id property="couId" column="couId"/>
<result property="couName" column="couName"/>
</collection>
</resultMap>
5 step by step query
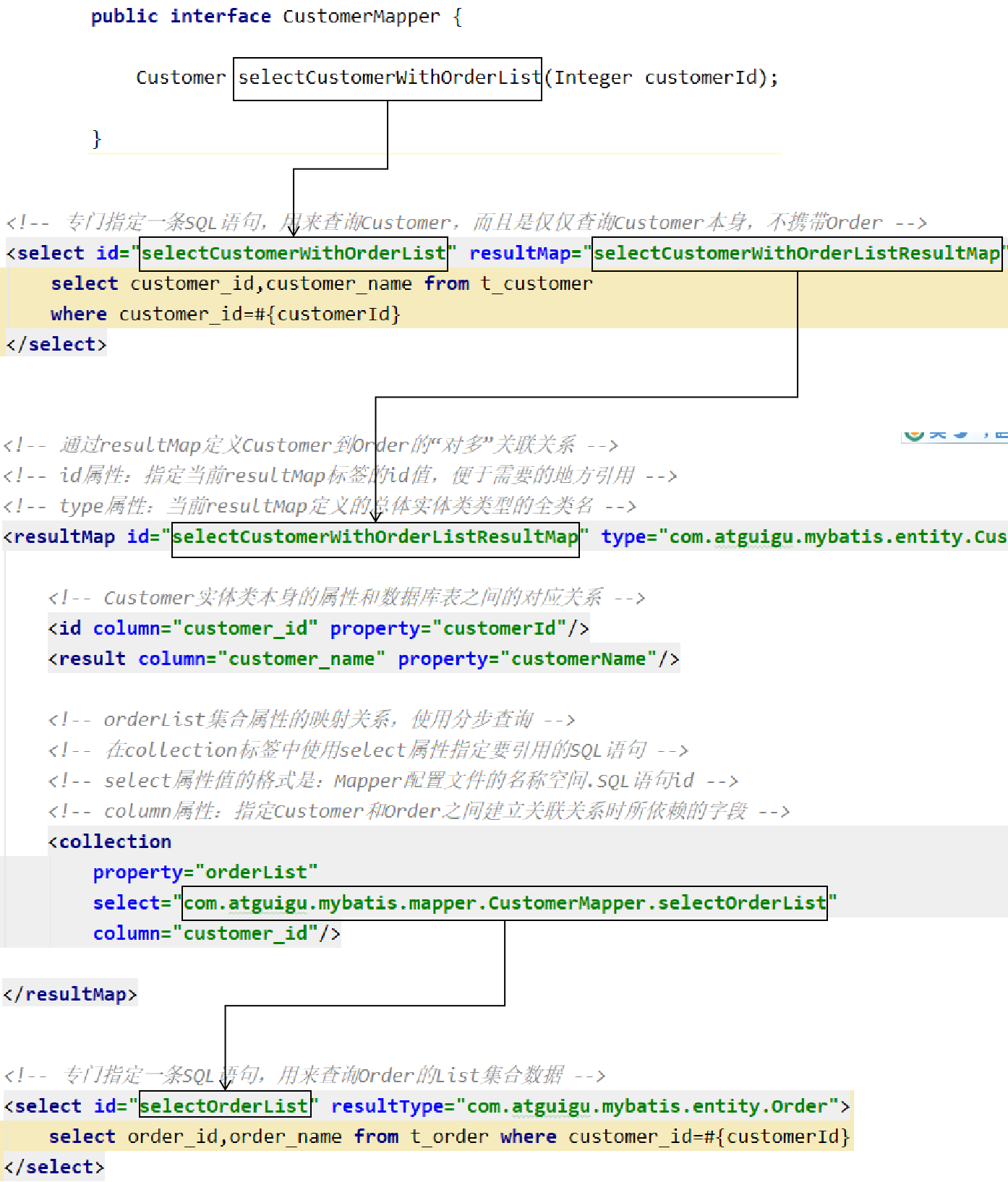
6 automatic mapping
We'll see..... I think it means the same type as hibernate
7 discriminator
(2 messages) MyBatis cascade discussion part 2 - discriminator_ ykzhen2015 column - CSDN blog
It feels like a chicken rib. It is a supplement to many to many queries. Nest and judge according to the query results, and supplement later
⭐ Dynamic SQL
It is mainly used for string splicing. Here I quote the fragment of the official website
Including the following parameters
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
1 basic gameplay
if
The most common scenario for using dynamic SQL is to include part of the where clause based on conditions. For example:
<select id="findActiveBlogWithTitleLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE state = 'ACTIVE'
<if test="title != null">
AND title like #{title}
</if>
</select>
This statement provides an optional function to find text. If "title" is not passed in, all blogs in "ACTIVE" status will be returned; If the "title" parameter is passed in, the "title" column will be vaguely searched and the corresponding BLOG results will be returned (careful readers may find that the parameter value of "title" needs to contain search mask or wildcard characters).
What if you want to perform an optional search through the "title" and "author" parameters? First of all, I want to change the statement name to the actual name of renaming; Next, just add another condition.
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = 'ACTIVE'
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
choose,when,otherwise
Sometimes, we don't want to use all the conditions, but just want to choose one from multiple conditions. In this case, MyBatis provides a choose element, which is a bit like a switch statement in Java.
This is the same as the above example, but the policy changes to the case where "title" is passed in and "author" is passed in. If neither is passed in, the blog marked as featured will be returned (this may be because the administrator thinks that instead of returning a large number of meaningless random blogs, it is better to return some blogs selected by the administrator).
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = 'ACTIVE'
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
where
The previous examples have conveniently solved a notorious dynamic SQL problem. Now back to the previous "if" example, this time we set "state =" ACTIVE "as a dynamic condition to see what happens.
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
What happens if there are no matching conditions? Finally, this SQL will become like this:
SELECT * FROM BLOG WHERE
This will cause the query to fail. What if only the second condition matches? This SQL will look like this:
SELECT * FROM BLOG WHERE AND title like 'someTitle'
This query will also fail. This problem cannot be solved simply by conditional elements. This problem is so difficult to solve that people who have solved it will no longer want to encounter this problem.
MyBatis has a simple solution that fits most scenarios. In other scenarios, you can customize it to meet your needs. This requires only one simple change:
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
The WHERE element inserts the "WHERE" clause only if the child element returns anything. Moreover, if clause starts with the "AND" OR ", WHERE element removes them.
trim
If the where element is different from what you expect, you can also customize the function of the where element by customizing the trim element. For example, the user-defined trim element equivalent to the where element is:
<trim prefix="WHERE" prefixOverrides="AND |OR "> ... </trim>
The prefixOverrides property ignores text sequences separated by pipe characters (note that spaces are necessary in this example). The above example will remove all the contents specified in the prefixOverrides attribute and insert the contents specified in the prefix attribute.
set
A similar solution for dynamically updating statements is called set. The set element can be used to dynamically include columns that need to be updated and ignore other columns that do not need to be updated. For example:
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
In this example, the SET element will dynamically insert the SET keyword at the beginning of the line and delete additional commas (which are introduced when assigning values to columns using conditional statements).
Take a look at the custom trim element equivalent to the set element:
<trim prefix="SET" suffixOverrides=","> ... </trim>
Note that we have overridden the suffix value setting and customized the prefix value.
foreach
Another common use scenario for dynamic SQL is traversal of collections (especially when building IN conditional statements). For example:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
</foreach>
</select>
The foreach element is very powerful. It allows you to specify a collection and declare collection items and index variables that can be used in the element body. It also allows you to specify the beginning and end strings and the separator between collection item iterations. This element also does not incorrectly add extra delimiters.
Tip: you can pass any iteratable object (such as List, Set, etc.), Map object or array object to foreach as a Set parameter. When using an iteratable object or array, index is the sequence number of the current iteration, and the value of item is the element obtained in this iteration. When using a Map object (or a collection of Map.Entry objects), index is the key and item is the value.
The alias of each element in the item collection when iterating,
index indicates the location of each iteration in the iteration process,
What does the open statement begin with,
What symbol does the separator use as a separator between each iteration,
What does close end with,
When using foreach, the most critical and error prone attribute is the collection attribute,
This attribute must be specified, but the value of this attribute is different in different cases,
There are three main situations:
-
If a single parameter is passed in and the parameter type is a List When I was young, collection The attribute value is list
-
If a single parameter is passed in and the parameter type is a array Array, collection The attribute value of is array
-
If there are multiple parameters passed in, we need to encapsulate them into one Map Yes
2 others
sql
Extract repeated SQL fragments using SQL Tags
<!-- use sql Duplicate tag extraction SQL fragment -->
<sql id="empSelectColumns">
emp_id empId,emp_name empName ,emp_salary empSalary
</sql>
Use the include tag to reference the declared SQL fragment
<!-- use include Label reference declared SQL fragment -->
<select id="findEmp" resultType="employee">
select <include refid="empSelectColumns"></include> from t_emp where 1=1
<if test="empName!=null and empName !=''">
and emp_name like concat("%",#{empName},"%")
</if>
<if test="minSalary>0">
and emp_salary>=#{minSalary}
</if>
</select>
script (annotation)
To use dynamic SQL in an annotated mapper interface class, you can use the script element. such as
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);
bind(OGNL)
The bind element allows you to create a variable outside the OGNL expression and bind it to the current context. such as
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>
Multi database support
If databaseIdProvider is configured, you can use a variable named "_databaseId" in dynamic code to build specific statements for different databases. For example, the following example
<insert id="insert">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
<if test="_databaseId == 'oracle'">
select seq_users.nextval from dual
</if>
<if test="_databaseId == 'db2'">
select nextval for seq_users from sysibm.sysdummy1"
</if>
</selectKey>
insert into users values (#{id}, #{name})
</insert>
Insert script language in dynamic SQL
MyBatis supports insert scripting language from version 3.2, which allows you to insert a language driver and write dynamic SQL query statements based on this language.
You can insert a language by implementing the following interfaces
public interface LanguageDriver {
ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql);
SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType);
SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType);
}
After implementing the custom language driver, you can set it as the default language in the mybatis-config.xml file:
<typeAliases> <typeAlias type="org.sample.MyLanguageDriver" alias="myLanguage"/> </typeAliases> <settings> <setting name="defaultScriptingLanguage" value="myLanguage"/> </settings>
Alternatively, you can use the lang attribute to specify the language for a specific statement:
<select id="selectBlog" lang="myLanguage"> SELECT * FROM BLOG </select>
Or, add @ Lang annotation on your mapper interface:
public interface Mapper {
@Lang(MyLanguageDriver.class)
@Select("SELECT * FROM BLOG")
List<Blog> selectBlog();
}
Tips: you can use Apache Velocity as a dynamic language. For more details, please refer to the mybatis velocity project.
All the xml tags you saw earlier are provided by the default MyBatis language, which is provided by the language driver org.apache.ibatis.scripting.xmltags.XmlLanguageDriver (alias xml).
⭐ cache
L1 cache
Basic description
There are only two kinds of cache for mybatis
- class a
- second level
Under the L1 cache, if data modification is involved, it will be erased by default
- The results of all select statements in the mapping statement file will be cached.
- All insert, update, and delete statements in the mapping statement file flush the cache.
- The cache will use the least recently used (LRU) algorithm to clear the unnecessary cache.
- The cache does not refresh regularly (that is, there is no refresh interval).
- The cache holds 1024 references to a list or object, regardless of what the query method returns.
- The cache is treated as a read / write cache, which means that the obtained objects are not shared and can be safely modified by the caller without interfering with potential modifications made by other callers or threads.
The L1 cache cannot be closed because some key features of mybatis are based on the L1 cache. The result mapping heavily depends on the L1 cache, so it is not allowed to be closed, but the configuration can be modified
MyBatis provides a configuration parameter localCacheScope to control the level of L1 cache
The values of this parameter are SESSION and state. When the value of localCacheScope parameter is specified as SESSION, the cache is valid for the whole SqlSession. The cache will be cleared only when DML statements (update statements) are executed. When the localCacheScope value is state, the cache is only valid for the currently executed STATEMENT. After the STATEMENT is executed, the cache will be emptied.
So I mainly explain L2 cache
View cache effect
After adding the log, if you directly query twice, you will find that there is only one query statement in the log because the cache is called the second time
[19:14:03.417] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Preparing: select empno, ename, job, mgr, hiredate, sal, comm, deptno from emp] [19:14:03.443] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Parameters: ] [19:14:03.480] [DEBUG] [main] [mapper.EmpMapper.selectAll] [<== Total: 14]
This effect will occur when we add the forced refresh parameter flushCache="true" to this sql statement in the sql file
[19:10:47.424] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Preparing: select empno, ename, job, mgr, hiredate, sal, comm, deptno from emp] [19:10:47.450] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Parameters: ] [19:10:47.477] [DEBUG] [main] [mapper.EmpMapper.selectAll] [<== Total: 14] [19:10:47.479] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Preparing: select empno, ename, job, mgr, hiredate, sal, comm, deptno from emp] [19:10:47.479] [DEBUG] [main] [mapper.EmpMapper.selectAll] [==> Parameters: ] [19:10:47.490] [DEBUG] [main] [mapper.EmpMapper.selectAll] [<== Total: 14]
summary
- In the same SqlSession, Mybatis will generate cached key values for the executed methods and parameters through the algorithm, and store the key values and results in a Map. If the subsequent key values are the same, Mybatis will directly obtain data from the Map
- Caches between different sqlsessions are isolated from each other
- With a SqlSession, you can configure to empty the cache before querying
- Any update, insert or delete statement will empty the cache
2. Enable the built-in L2 cache of mybatis
Basic description
Open the global L2 cache after the properties parameter in mybatis-config.xml
<settings>
<!--Globally turns on or off any cache that has been configured by all mappers in the configuration file. -->
<setting name="cacheEnabled" value="true"/>
</settings>
Turn on the L2 cache method (let the entity class inherit the serialization interface)
<!-- stay mapper.xml Add under namespace cache Tag enables L2 caching --> <cache/>
You can also configure cache policy, cache refresh frequency, cache capacity and other attributes
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
This more advanced configuration creates a FIFO cache, which is refreshed every 60 seconds. It can store up to 512 references of the result object or list, and the returned objects are considered read-only. Therefore, modifying them may conflict with callers in different threads.
Available purge strategies are:
- LRU – least recently used: removes objects that have not been used for the longest time.
- FIFO – first in first out: remove objects in the order they enter the cache.
- SOFT – SOFT reference: removes objects based on garbage collector status and SOFT reference rules.
- WEAK – WEAK references: remove objects more actively based on garbage collector status and WEAK reference rules.
The default purge policy is LRU.
The flush interval property can be set to any positive integer. The set value should be a reasonable amount of time in milliseconds. The default is not set, that is, there is no refresh interval. The cache will only be refreshed when the statement is called.
The size (number of references) attribute can be set to any positive integer. Pay attention to the size of the object to be cached and the memory resources available in the running environment. The default value is 1024.
The readOnly property can be set to true or false. A read-only cache returns the same instance of the cache object to all callers. Therefore, these objects cannot be modified. This provides a significant performance improvement. The read-write cache returns (through serialization) a copy of the cache object. It will be slower, but safer, so the default value is false.
Indicates that the L2 cache is transactional. This means that when SqlSession completes and commits, or completes and rolls back, but the insert/delete/update statement with flushCache=true is not executed, the cache will be updated
Sample code
mybatis.xml
<configuration>
<!-- environments Represents the configuration Mybatis Multiple environments can be configured,
In many specific environments, use default Property specifies the environment to use when actually running -->
<properties resource="dbconfig/db.properties">
</properties>
<settings>
<!--Globally turns on or off any cache that has been configured by all mappers in the configuration file. -->
<setting name="cacheEnabled" value="true"/>
</settings>
<environments default="mysql">
mapper.xml
<mapper namespace="mapper.EmpMapper">
<!-- L2 cache switch -->
<cache/>
After opening, the effect is as follows (hit rate 0)
[19:33:55.425] [DEBUG] [main] [mapper.EmpMapper] [Cache Hit Ratio [mapper.EmpMapper]: 0.0]
6.2 MyBatis uses Redis cache
In fact, Mybatis is also very smart. I know that most users will use the third-party cache, so there is little official explanation on the native L2 cache
- Add the JAR package of mybatis redis
- Add cache configuration in Mapper's XML configuration file
(1 message) integration of mybatis and redis_ Snail learning notes - CSDN blog_ mybatis redis
6.3 Mybatis uses EHCache
(1 message) Mybatis integrates third-party cache ehcache_ Lin Haijing's blog - CSDN blog
1. Add dependent package
2. Provide profile
3. cache type add L2 cache as EHCache
4. Add log bridge
5. Run test
⭐ journal
After adding, you can view the executed SQL statements and efficiency related information
1 Description
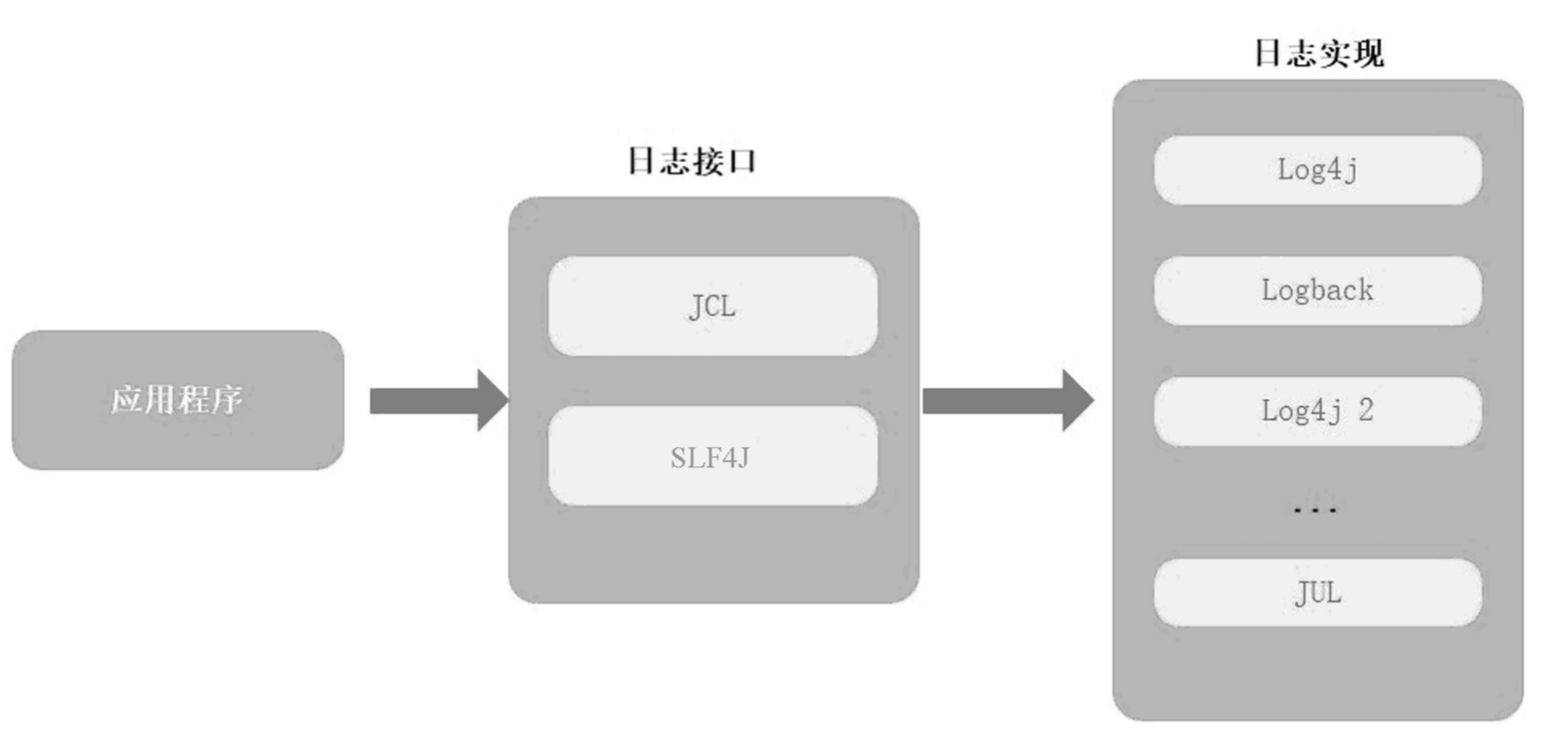
2 log4j
Operation process
- Guide Package
- Write configuration file log4j
- Remember to put log4j in the resource root directory
Sample code
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>03_mybatis</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
</dependencies>
</project>
log4j.properties
#############
# Output to console
#############
# log4j.rootLogger log output category and level: only log information not lower than this level is output. Debug < info < warn < error < fatal
# WARN: log level CONSOLE: a name defined by the output location itself logfile: a name defined by the output location itself
log4j.rootLogger=DEBUG,CONSOLE,logfile
# Configure CONSOLE output to CONSOLE
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
# Configure CONSOLE to set to custom layout mode
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
# Configure the output format of CONSOLE log [frame] 2019-08-22 22:52:12000% R milliseconds consumed% p priority of log% t thread name% C class name is usually the full class name% L line number in code% x NDC associated with thread% m log% n line feed
log4j.appender.CONSOLE.layout.ConversionPattern=[frame] %d{yyyy-MM-dd HH:mm:ss,SSS} - %-4r %-5p [%t] %C:%L %x - %m%n
################
# Output to log file
################
# Configure logfile output to a file. When the file size reaches the specified size, a new log file will be generated
log4j.appender.logfile=org.apache.log4j.RollingFileAppender
# Save encoding format
log4j.appender.logfile.Encoding=UTF-8
# The output file location is in the logs folder under the root directory of the project
log4j.appender.logfile.File=logs/root.log
# The suffix can be KB,MB,GB. After reaching this size, a new log file is created
log4j.appender.logfile.MaxFileSize=10MB
# Setting the maximum value of roll file 3 means that four log files can be generated: root.log.1, root.log.2, root.log.3 and root.log
log4j.appender.logfile.MaxBackupIndex=3
# Configure logfile as custom layout mode
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %F %p %m%n
##########################
# Output different log files for different classes
##########################
# The logs under the club.bagedate package are output separately
#log4j.logger.club.bagedate=DEBUG,bagedate
# If set to false, the log information will not be added to the rootLogger
#log4j.additivity.club.bagedate=false
# The following configuration is the same as the above configuration
log4j.appender.bagedate=org.apache.log4j.RollingFileAppender
log4j.appender.bagedate.Encoding=UTF-8
log4j.appender.bagedate.File=logs/bagedate.log
log4j.appender.bagedate.MaxFileSize=10MB
log4j.appender.bagedate.MaxBackupIndex=3
log4j.appender.bagedate.layout=org.apache.log4j.PatternLayout
log4j.appender.bagedate.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %F %p %m%n
3 logback
Example
Add jar package
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
Configure logback.xml
Remember to put the file under the resource root
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<!-- Specify the location of the log output -->
<appender name="STDOUT"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- Format of log output -->
<!-- In order, they are: time, log level, thread name, print log class, log body content, line feed -->
<pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger] [%msg]%n</pattern>
</encoder>
</appender>
<!-- Set the global log level. The log levels are as follows: DEBUG,INFO,WARN,ERROR -->
<!-- If you specify any log level, only the logs of the current level and subsequent levels will be printed. -->
<root level="DEBUG">
<!-- Specifies the of the print log appender,Here through“ STDOUT"Reference to the previously configured appender -->
<appender-ref ref="STDOUT"/>
</root>
<!-- Specify the local log level according to special requirements -->
<logger name="mapper.EmpMapper" level="DEBUG"/>
</configuration>
⭐ reverse engineering
A very practical thing. When creating a new project, there are many tables in the database, and we need to build classes in Java
If you build one by one, you will be very tired, so the baby of reverse engineering is derived
1. Operation process
It is very simple. There are two methods and three steps. The key lies in XML configuration
Method 1: class based execution
-
Import JAR package
-
Configuration XML file
-
Execute test class
Method 2: Based on Maven plug-in
- Import JAR package
- Configure Maven plug-in
- Configuration XML file
- Execute Maven plug-in
You can also use the mybatis plus plug-in, which I intend to explain in another md
2 code example
I just want to demonstrate method one
Import JAR package
<!-- reverse engineering -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.0</version>
</dependency>
XML configuration
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--
targetRuntime: Execute the generated reverse engineered version
MyBatis3Simple: Generate basic CRUD(Fresh and concise version)
MyBatis3: Generate conditional CRUD(Luxury Edition)
-->
<context id="DB_Ailyn" targetRuntime="MyBatis3">
<!-- Database connection information -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://47.106.207.254:3306/mybatis"
userId="root"
password="szsti@123">
</jdbcConnection>
<!-- javaBean Generation strategy for-->
<javaModelGenerator targetPackage="JavaBean" targetProject=".\src\main\java">
<!-- Generate sub package -->
<property name="enableSubPackages" value="true"/>
<!-- Remove the front and back spaces -->
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- SQL Generation strategy of mapping file -->
<sqlMapGenerator targetPackage="sql" targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- Mapper Generation strategy of interface -->
<javaClientGenerator type="Mapper" targetPackage="mapper" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- Table for reverse analysis -->
<!-- tableName Set to*Number, which can correspond to all tables. It is not written at this time domainObjectName -->
<!-- domainObjectName Property specifies the class name of the generated entity class -->
<table tableName="course" domainObjectName="CourseDao"/>
<table tableName="student" domainObjectName="StudentDao"/>
<table tableName="curricula" domainObjectName="CurriculaDao"/>
</context>
</generatorConfiguration>
Class execution
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.exception.InvalidConfigurationException;
import org.mybatis.generator.exception.XMLParserException;
import org.mybatis.generator.internal.DefaultShellCallback;
import java.io.File;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class Run {
public static void main(String[] args) throws XMLParserException, IOException, InvalidConfigurationException, SQLException, InterruptedException {
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
File configFile = new File("src/main/resources/config/generatorConfiguration.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
}
}