Mybatis plus common annotations and plug-ins (II)
1, @ TableName
value attribute
The name of the entity class is User and the name of the database table is t_user
@TableName(value = "t_user")
public class User {
//...
}
2, @ TableId
1. Snowflake algorithm
By default, the id column of the database is generated by the strategy based on the snowflake algorithm
background
With the continuous expansion of business scale, it is necessary to choose appropriate solutions to cope with the growth of data scale, so as to cope with the increasing access pressure and data volume.
Database expansion methods mainly include: business sub database, master-slave replication, and database sub table.
Database sub table
The decentralized storage of different business data to different database servers can support the business of millions or even tens of millions of users. However, if the business continues to develop, the single table data of the same business will also reach the processing bottleneck of a single database server. For example, if all the hundreds of millions of user data of Taobao are stored in one table of a database server, it will certainly not meet the performance requirements. At this time, it is necessary to split the single table data.
There are two ways to split single table data: vertical table splitting and horizontal table splitting. The schematic diagram is as follows:
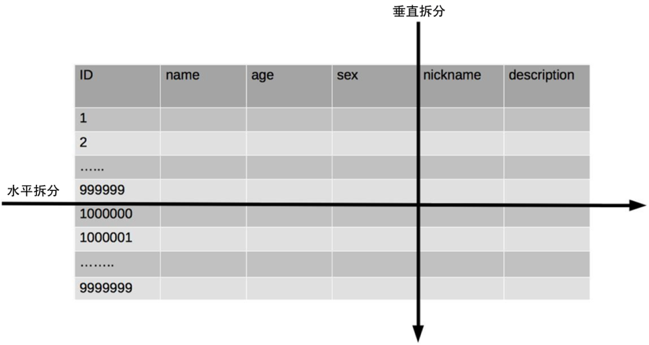
Vertical sub table:
- Vertical split table is suitable for splitting some columns that are not commonly used and occupy a lot of space in the table.
- **For example, * * for the nickname and description fields in the previous diagram, suppose we are a love and marriage website. When filtering other users, users mainly use the age and Sex fields for query, while the nickname and description fields are mainly used for display and are generally not used in business query. Description itself is relatively long, so we can separate these two fields into another table, which can bring some performance improvement when querying age and sex.
Horizontal sub table:
- Horizontal tables are suitable for tables with a large number of rows. Some companies require that tables must be divided when the number of rows in a single table exceeds 50 million. This number can be used as a reference, but it is not an absolute standard. The key is to see the access performance of the table. For some complex tables, more than 10 million tables may be divided; For some simple tables, even if more than 100 million rows of data are stored, there can be no tables.
- However, when you see that the data volume of the table reaches tens of millions, you should be alert as an architect, because this is likely to be a performance bottleneck or hidden danger of the architecture.
Compared with vertical tables, horizontal tables introduce more complexity, such as data id:
Primary key auto increment:
- Taking the most common user ID as an example, it can be segmented according to the range size of 1000000, 1 ~ 999999 in Table 1, 1000000 ~ 1999999 in Table 2, and so on.
- Complex point: selection of segment size. Too small segmentation will lead to too many sub tables after segmentation and increase maintenance complexity; Too large segmentation may cause performance problems in a single table. Generally, it is recommended that the segmentation size be between 1 million and 20 million. Specifically, the appropriate segmentation size should be selected according to the business.
- Advantages: new tables can be expanded smoothly with the increase of data. For example, the current number of users is 1 million. If it is increased to 10 million, you only need to add a new table, and the original data does not need to be moved.
- Disadvantages: uneven distribution. If the table is divided according to 10 million, it is possible that there is only one piece of data actually stored in a segment, while there are 10 million pieces of data actually stored in another segment.
Hash :
- Similarly, taking the user ID as an example, if we planned 10 database tables at the beginning, we can simply use user_ The value of ID% 10 indicates the database table number to which the data belongs. The user with ID 985 is placed in the sub table with ID 5, and the user with ID 10086 is placed in the sub table with ID 6.
- Complex points: determine the number of initial tables. Too many tables are troublesome to maintain. Too few tables may lead to performance problems in a single table.
- Advantages: the surface distribution is relatively uniform.
- Disadvantages: it is troublesome to expand new tables, and all data must be redistributed.
*Snowflake algorithm:*
Snowflake algorithm is a distributed primary key generation algorithm published by Twitter. It can ensure the non repetition of primary keys of different tables and the ordering of primary keys of the same table.
-
Core idea:
-
- The total length is 64bit (a long type).
- The first is a sign bit, 1bit identification. Because the basic type of long is signed in Java, the highest bit is the sign bit, the positive number is 0 and the negative number is 1, so the id is generally a positive number and the highest bit is 0.
- 41bit time cut (millisecond level), which stores the difference of time cut (current time cut - start time cut), and the result is about 69.73 years.
- 10bit is used as the ID of the machine (5 bits are the data center, and 5 bits are the machine ID, which can be deployed in 1024 nodes).
- 12bit is used as the serial number within milliseconds (meaning that each node can generate 4096 ID S per millisecond).
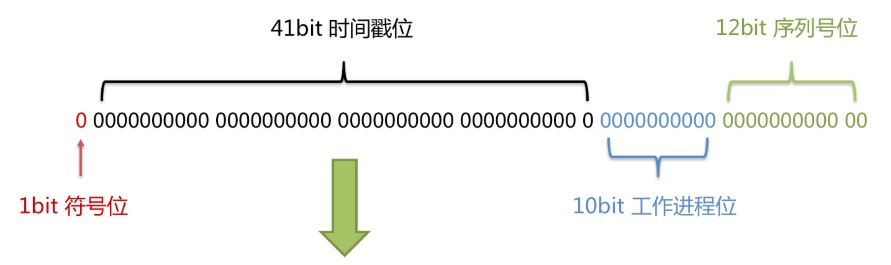
- Advantages: on the whole, it is sorted according to the time increment, and there is no ID collision in the whole distributed system, and the efficiency is high.
2. Specify primary key column
- Test: change the id column in the database table to uid, change the id attribute in the entity class to uid, and perform data insertion. The following errors are reported

- Reason: because MP thinks id is the primary key column by default, the attribute MP of other names cannot be filled automatically by default
- Solution: add @ TableId annotation to the primary key column
3. type attribute
The type attribute is used to define the primary key policy
- **IdType.ASSIGN_ID: * * use the policy based on snowflake algorithm to generate data id
@TableId(type = IdType.ASSIGN_ID) private Long id;
Note: when the id of the object is explicitly assigned, the snowflake algorithm will not be used
- **IdType.AUTO: * * Auto increment strategy using database
@TableId(type = IdType.AUTO) private Long id;
Note: for this type, please ensure that the database is set with ID auto increment, otherwise it is invalid
- **Global configuration: * * to affect the configuration of all entities, you can set the global primary key configuration
#Global setting primary key generation policy mybatis-plus.global-config.db-config.id-type=auto
3, @ TableField
1. value attribute
The function is the same as the value attribute of TableId
Note: MP will automatically convert the underline naming style in the database into the hump naming style in the entity class
**For example, * * column create in database_ Time and update_time automatically corresponds to createTime and updateTime in the entity class

private LocalDateTime createTime; private LocalDateTime updateTime;
Extended knowledge: why do you recommend using LocalDateTime instead of Date? https://zhuanlan.zhihu.com/p/87555377
- java. util. Most methods of date are outdated
- java. util. The readability of date output is poor
- java. util. The format class SimpleDateFormat corresponding to date is thread unsafe. The static modifier SimpleDateFormat is disabled in Alibaba development manual.
- The format class DateTimeFormatter corresponding to LocalDateTime is thread safe
2. Auto fill
Requirement Description:
Some data are often encountered in the project, which are filled in the same way every time, such as the creation time and update time of the record. We can use the auto fill function of MyBatis Plus to complete the assignment of these fields.
**For example, * * Alibaba's development manual suggests that each database table must have a create_time and update_time field, which we can maintain using the auto fill function
- **step1: * * add fill attribute
@TableField(fill = FieldFill.INSERT) private LocalDateTime createTime; @TableField(fill = FieldFill.INSERT_UPDATE) private LocalDateTime updateTime;
- **Step 2: * * Implement meta object processor interface - > create handler package and create MyMetaObjectHandler class
Note: don't forget to add @ Component annotation
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ....");
this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now());
this.strictInsertFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now());
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now());
}
}
3. Testing
-
Test add
-
Test modification
-
To avoid excessive overhead during automatic filling, judge whether there are relevant attributes in the current object before filling
4, @ TableLogic
1. Logical deletion
- Physical delete: real delete, delete the corresponding data from the database, and then query the deleted data
- Logical deletion: false deletion. Change the status of the field representing whether to delete in the corresponding data to deleted status. After that, you can still see this data record in the database
Usage scenario: data recovery can be performed
2. Implement logical deletion
- **Step 1: * * create a logical deletion status column in the database

- **Step 2: * * add logical deletion attribute to entity class
@TableLogic @TableField(value = "is_deleted") private Integer deleted;
3. Testing
- Test delete: the delete function is changed to the update function
-- Actually implemented SQL update user set is_deleted=1 where id = 1 and is_deleted=0
- Test query: logically deleted data will not be queried by default
-- Actually implemented SQL select id,name,is_deleted from user where is_deleted=0
5, Paging plug-in
MyBatis Plus comes with a paging plug-in, which can realize paging function with simple configuration
1. Add configuration class
Create the config package and create the MybatisPlusConfig class
@Configuration
@MapperScan("com.atguigu.mybatisplus.mapper") //Annotations in the main class can be moved here
public class MybatisPlusConfig {
}
2. Add paging plug-in
Add @ Bean configuration to configuration class
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
3. Test paging
Create class InterceptorTests
@SpringBootTest
public class InterceptorTests {
@Resource
private UserMapper userMapper;
@Test
public void testSelectPage(){
//Create paging parameters
Page<User> pageParam = new Page<>(1,5);
//Execute paging query
userMapper.selectPage(pageParam, null);
//View members of paging parameters
System.out.println(pageParam);
}
}
6, XML custom paging
1. Interface methods defined in UserMapper
/**
* Query: query the user list according to age and display it in pages
*
* @param page Paging object, from which values can be obtained in xml. Pass the parameter Page, that is, automatic paging, which must be placed first
* @param age Age
* @return Paging object
*/
IPage<User> selectPageByPage(Page<?> page, Integer age);
2. Define XML
<select id="selectPageByPage" resultType="com.atguigu.mybatisplus.entity.User">
SELECT <include refid="Base_Column_List"/> FROM user WHERE age > #{age}
</select>
3. Testing
@Test
public void testSelectPageVo(){
Page<User> pageParam = new Page<>(1,5);
userMapper.selectPageByPage(pageParam, 18);
List<User> users = pageParam.getRecords();
users.forEach(System.out::println);
}
7, Optimistic lock
1. Scene
The cost price of a commodity is 80 yuan and the selling price is 100 yuan. The boss first informed Xiao Li that you should increase the commodity price by 50 yuan. Xiao Li was playing a game and was delayed for an hour. Just one hour later, the boss felt that the commodity price increased to 150 yuan, and the price was too high, which might affect the sales volume. Also inform Xiao Wang that you have reduced the commodity price by 30 yuan.
At this time, Xiao Li and Xiao Wang operate the commodity background system at the same time. When Xiao Li operates, the system first takes out the commodity price of 100 yuan; Xiao Wang is also operating. The price of the goods taken out is also 100 yuan. Xiao Li added 50 yuan to the price and stored 100 + 50 = 150 yuan in the database; Xiao Wang reduced the commodity by 30 yuan and stored 100-30 = 70 yuan in the database. Yes, if there is no lock, Xiao Li's operation will be completely covered by Xiao Wang's.
Now the commodity price is 70 yuan, 10 yuan lower than the cost price. A few minutes later, the product quickly sold more than 1000 items, and the boss lost more than 10000.
Next, we will demonstrate this process:
Step 1: add commodity table in database
CREATE TABLE product
(
id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'Primary key ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT 'Trade name',
price INT(11) DEFAULT 0 COMMENT 'Price',
version INT(11) DEFAULT 0 COMMENT 'Optimistic lock version number',
PRIMARY KEY (id)
);
INSERT INTO product (id, NAME, price) VALUES (1, 'notebook', 100);
Step 2: create entity class
@Data
public class Product {
private Long id;
private String name;
private Integer price;
private Integer version;
}
step3: create Mapper
public interface ProductMapper extends BaseMapper<Product> {
}
Step 4: Test
@Resource
private ProductMapper productMapper;
@Test
public void testConcurrentUpdate() {
//1. Xiao Li
Product p1 = productMapper.selectById(1L);
//2. Xiao Wang
Product p2 = productMapper.selectById(1L);
//3. Xiao Li added 50 yuan to the price and stored it in the database
p1.setPrice(p1.getPrice() + 50);
int result1 = productMapper.updateById(p1);
System.out.println("Xiao Li's modification result:" + result1);
//4. Xiao Wang reduced the commodity by 30 yuan and stored it in the database
p2.setPrice(p2.getPrice() - 30);
int result2 = productMapper.updateById(p2);
System.out.println("Xiao Wang's modification result:" + result2);
//Final results
Product p3 = productMapper.selectById(1L);
System.out.println("Final results:" + p3.getPrice());
}
2. Optimistic lock scheme
Add version field to the database: get the current version when taking out records
SELECT id,`name`,price,`version` FROM product WHERE id=1
When updating, version + 1. If the version in the where statement is incorrect, the update fails
UPDATE product SET price=price+50, `version`=`version` + 1 WHERE id=1 AND `version`=1
Next, we will introduce how to use optimistic lock in mybatis plus project:
3. Optimistic lock implementation process
*step1: modify entity class*
Add @ Version annotation
@Version private Integer version;
Step 2: add optimistic lock plug-in
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());//Optimistic lock
Step 3: re execute the test
Xiao Wang's modification failed!
4. Optimize process
Retry after failure
if(result2 == 0){//Update failed, please try again
System.out.println("Xiao Wang, try again");
//Retrieve data
p2 = productMapper.selectById(1L);
//to update
p2.setPrice(p2.getPrice() - 30);
productMapper.updateById(p2);
}