preface
stay Mybatis source code - SqlSession access It has been known in the article that when obtaining SqlSession in Mybatis, the Executor will be created and stored in SqlSession. The dynamic proxy object of the mapping interface can be obtained through SqlSession, and the generation of dynamic proxy object can be referred to Mybatis source code - load mapping file and dynamic agent , it can be summarized in the figure below.
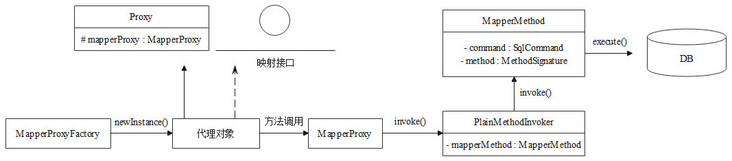
Therefore, when the dynamic proxy object of the mapping interface actually executes the method, the executed request will eventually be completed by the execute() method of MapperMethod. This article will take the execute() method of MapperMethod as the starting point to explain an actual execution request in Mybatis, and explain the principle of the Executor combined with the source code. This article will not explain the cache in Mybatis. The related contents of the L1 cache and L2 cache in Mybatis will be analyzed separately in subsequent articles. In order to shield the interference of the L2 cache in Mybatis, the following configuration needs to be added to the Mybatis configuration file to disable the L2 cache.
<settings>
<setting name="cacheEnabled" value="false"/>
</settings>text
This section will illustrate an actual execution request of Mybatis by using a practical query example, single-step tracking and combined with the source code. The given mapping interface is shown below.
public interface BookMapper {
Book selectBookById(int id);
}The given mapping file is shown below.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
</mapper>The execution code of Mybatis is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
//Get SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
//Gets the dynamic proxy object of the mapping interface
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
//Perform a query operation
System.out.println(bookMapper.selectBookById(1));
}
}Based on the above mapping interface, mapping files and execution code, when finally executing the query operation, it will call the execute() method of MapperMethod and enter the logical branch of the query. This part of the source code is as follows.
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
......
case SELECT:
//Enter different logical branches according to the return value of the actually executed method
if (method.returnsVoid() && method.hasResultHandler()) {
//No return value
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
//When the return value is a collection
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
//The return value is map
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
//When the return value is an iterator
result = executeForCursor(sqlSession, args);
} else {
//Other than the above
//Converts an input parameter of a method to a parameter of a Sql statement
Object param = method.convertArgsToSqlCommandParam(args);
//Call the selectOne() method of DefaultSqlSession to perform the query operation
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
......
}
......
return result;
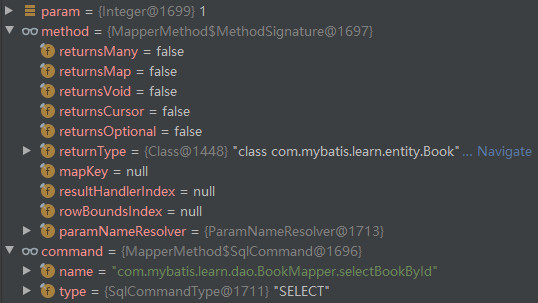
}It is known that each method in the mapping interface will correspond to a MapperMethod, the SqlCommand in MapperMethod will indicate the MappedStatement information and type information (SELECT, UPDATE, etc.) corresponding to the method, and the MethodSignature in MapperMethod will store the parameter information and return value information of the method, so in the execute() method of MapperMethod above, First, enter different logical branches according to the type indicated by SqlCommand. In this example, you will enter the logical branch of SELECT, and then enter different query branches according to the method return value indicated in MethodSignature. The method return value in this example is neither a collection, map or iterator, nor empty, so you will enter the query branch of querying a piece of data. When you step here in this example, the data is as follows.
In the execute() method in MapperMethod, the selectOne() method of DefaultSqlSession will be called to execute the query operation. The implementation of this method is as follows.
@Override
public <T> T selectOne(String statement) {
return this.selectOne(statement, null);
}
@Override
public <T> T selectOne(String statement, Object parameter) {
//The query operation will be completed by selectList()
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
//When there is only one query result, the query result is returned
return list.get(0);
} else if (list.size() > 1) {
//When the query result is greater than one, an error is reported
throw new TooManyResultsException(
"Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}In the selectOne() method of DefaultSqlSession, the query request will be completed by the selectList() method of DefaultSqlSession. If there is only one return value in the result set returned by the selectList() method, the return value will be returned. If there are more than one return value, an error will be reported. The selectlist () method of DefaultSqlSession is as follows.
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//Get MappedStatement from mappedStatements cache in Configuration
MappedStatement ms = configuration.getMappedStatement(statement);
//Call the query() method of the Executor to perform the query operation
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
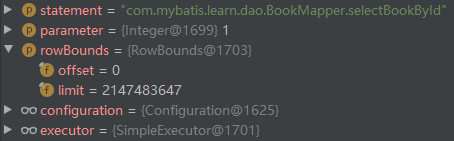
}In the selectList() method of DefaultSqlSession, MappedStatement will be obtained in the mapedstatements cache in Configuration according to the statement parameter value. The statement parameter value is actually the name field of SqlCommand in MapperMethod and the unique identification of MappedStatement in the mapedstatements cache. After obtaining the MappedStatement, the query() method of the Executor will be called to perform the query operation. Because the L2 cache is disabled, the Executor here is actually SimpleExecutor. When you step here in this example, the data is as follows.
The class diagram of simpleexecution is shown below.
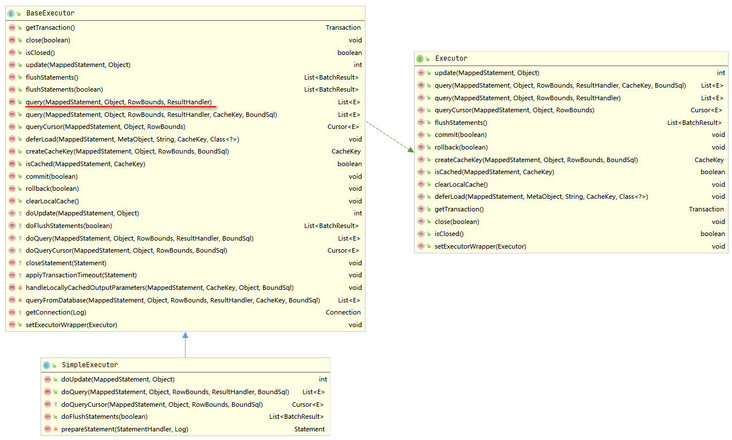
The template design pattern is used between simpleexecution and BaseExecutor. When the query() method of simpleexecution is called, the query() method of BaseExecutor will be called, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
//Get Sql statement
BoundSql boundSql = ms.getBoundSql(parameter);
//Generate CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//Call the overloaded query() method
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}Continue to look at the overloaded query() method in BaseExecutor, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//First hit the query result from the L1 cache according to the CacheKey
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//If it is hit successfully, the query results in the cache are returned
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//If it is missed, the database will be queried directly
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}Most of the logic of the above query() method is to serve the first level cache in Mybatis. It will not be analyzed here for the time being. Apart from the cache logic, what the above query() method does can be summarized as follows: first obtain the query results from the cache, and then return the query results in the cache, otherwise directly query the database. The logic of directly querying the database is analyzed below. The implementation of the queryFromDatabase() method is as follows.
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//Call doQuery() to query
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//Add query results to L1 cache
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
//Return query results
return list;
}In the above queryFromDatabase() method, the abstract method doQuery() defined by BaseExecutor will be called to query. In this example, the doQuery() method is implemented by simpleexecution, as shown below.
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//Create RoutingStatementHandler
StatementHandler handler = configuration.newStatementHandler(
wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//Instantiate Statement
stmt = prepareStatement(handler, ms.getStatementLog());
//Execute query
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}In the above doQuery() method, three things are done. The first thing is to create a RoutingStatementHandler. In fact, the RoutingStatementHandler, as its name indicates, is only used for routing forwarding. When creating a RoutingStatementHandler, According to the statementType attribute on the CURD tag in the mapping file, the StatementHandler will be created and assigned to the delegate field in RoutingStatementHandler. All subsequent operations on RoutingStatementHandler will be forwarded to delegate. In addition, when initializing simplestationhandler, PreparedStatementHandler and CallableStatementHandler are also initialized together with ParameterHandler and ResultSetHandler. The corresponding relationship between the statementType attribute on the CURD tag in the mapping file and the StatementHandler is as follows.
| statementType property | Corresponding StatementHandler | effect |
|---|---|---|
| STATEMENT | SimpleStatementHandler | Directly operate SQL without precompiling |
| PREPARED | PreparedStatementHandler | Precompiled SQL |
| CALLABLE | CallableStatementHandler | Execute stored procedure |
The relationship between RoutingStatementHandler and simplestationhandler, PreparedStatementHandler and CallableStatementHandler can be illustrated in the figure below.
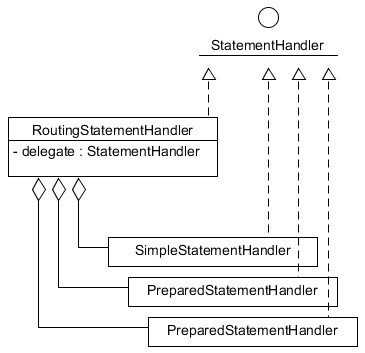
After the RoutingStatementHandler is created, plug-in logic is also implanted into the RoutingStatementHandler. The newStatementHandler() method of Configuration is implemented as follows.
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement,
Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//Create RoutingStatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(
executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//Implanting plug-in logic for RoutingStatementHandler
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}Continue to analyze the second thing in the doQuery() method, that is, instantiating the Statement. The prepareStatement() method is implemented as follows.
private Statement prepareStatement(StatementHandler handler, Log statementLog)
throws SQLException {
Statement stmt;
//Get the Connection object and generate a dynamic proxy object for the Connection object
Connection connection = getConnection(statementLog);
//Instantiate the Statement through the dynamic proxy object of the Connection object
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}In the prepareStatement() method, the database Connection object Connection object will be obtained from the Transaction and a dynamic proxy object will be generated for it to enhance the log printing function, then the Statement will be instantiated through the dynamic proxy object of the Connection, and finally the placeholder in the Statement will be processed, such as? Replace with the actual parameter value.
Continue to analyze the third thing in the doQuery() method, which is to execute the query. In the example in this article, the CURD tag of the mapping file does not set the statementType property, so the query operation will eventually be forwarded by the RoutingStatementHandler route to the query() method of PreparedStatementHandler, as shown below.
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//Call the logic of JDBC
ps.execute();
//Call ResultSetHandler to process query results
return resultSetHandler.handleResultSets(ps);
}As shown above, in the query() method of PreparedStatementHandler, JDBC logic will be called to query the database. Finally, ResultSetHandler that has been initialized and embedded with plug-in logic will be used to process the query results and return them.
So far, this is the end of the description of an actual execution request of Mybatis. The examples in this article take query as an example. The additions, deletions and modifications are generally similar, so they will not be repeated.
summary
The Executor in Mybatis will be created and stored in SqlSession when creating SqlSession. If L2 cache is disabled, the Executor is actually simpleexecution, otherwise it is cacheingexecution. An actual execution in Mybatis will be completed by the execute() method of MapperMethod corresponding to the executed method. In the execute() method, the corresponding methods in SqlSession will be called according to the type of operation (addition, modification, deletion and query), such as insert(), update(), delete() and select(), The role of MapperMethod is that MapperMethod is associated with the SQL Statement corresponding to the method executed this time, as well as the input and output parameters. In SqlSession's insert(), update(), delete(), select() and other methods, SqlSession will entrust the database operations to the Executor. Whether in simpleexecution or cacheingexecution, if cache related logic is put aside, these executors will first create corresponding StatementHandler according to the statementType field of CURD tag in the mapping file, In the process of creating StatementHandler, ParameterHandler and ResultSetHandler for processing parameters and results will be created together. After the StatementHandler is created, the Statement will be instantiated based on the StatementHandler. Finally, the StatementHandler will complete the interaction with the database based on the instantiated Statement, Process the interaction result based on the created ResultSetHandler and return the result.