Introduction
Canal is a high-performance data synchronization system based on MySQL binary log. It is an open source project of Alibaba. It is implemented based on java. It has been widely used in many large Internet project production environments, including Alibaba and meituan. It is an unusually mature database synchronization scheme. The basic use only needs simple configuration, To provide a reliable low latency incremental data pipeline.
Characteristics of Canal
- All platforms are supported.
- Supports fine-grained system monitoring supported by Prometheus.
- MySQL Binlog can be parsed and subscribed in different ways (for example, through GTID).
- Support high performance, real-time data synchronization. (see more performance)
- Both the Canal Server and the Canal Client support HA / scalability supported by Apache ZooKeeper
- Docker support.
Canal implementation principle
Canal synchronizes MySQL data to Elasticsearch based on the master-slave replication principle of MySQL.
1.MySQL master-slave replication principle
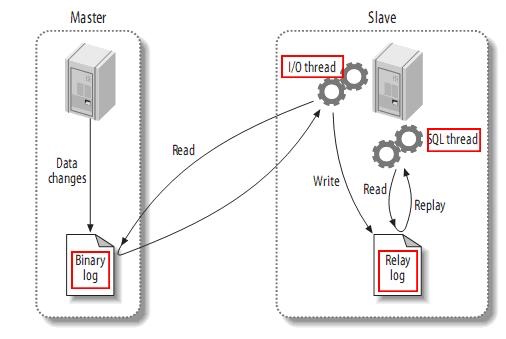
- The master server records the addition, deletion and modification operations in binlog. These records are called binlog events. You can view show binary events through.
- The slave server establishes a connection with the binlog log of the master server through the I/O thread and reads it. The read binlog log is written to the local Relay log intermediate log.
- After the slave server reads the Relay log through its own SQL thread, it executes the operation record of the master server locally.
2. Implementation principle of canal
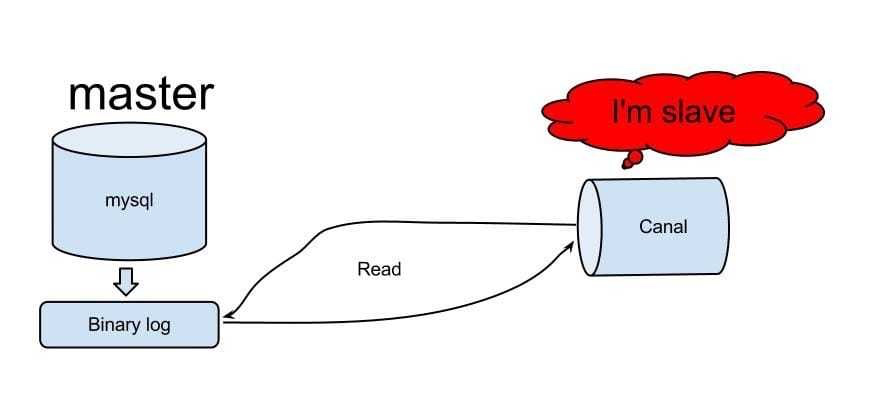
- Canal sends dump protocol to MySQL Master by simulating the interaction protocol as MySQL Slave and pretending to be MySQL Slave.
- The MySQL Master receives the dump request and starts pushing binlog to Slave, that is, Canal.
- Canal parses binlog objects (originally byte streams)
3.C/S architecture
Canal is a C/S architecture, which is divided into Server side and Client side
- The package name of the server is canal deployer. After the server side is deployed, it can directly listen to mysql binlog. Because the server side simulates itself as mysql slave, it can only accept data without any logical processing. The specific logical processing needs to be processed by the client side.
- The package name of the Client is Canadian adapter. The Client can automatically develop or use the official Canadian adapter. The adapter can convert the data obtained by the Canadian server into several common middleware data sources. Now it supports kafka, rocketmq, hbase and elasticsearch. For the support of these middleware, it can be configured directly without development.
4.Canal Admin
Since version 1.1.4 of canal, Alibaba has launched the WEB management UI of canal. The version must be > = Canal1.1.4 or above before deployment. The design of canal admin is to provide overall configuration management, node operation and maintenance and other operation and maintenance oriented functions for canal, provide a relatively friendly WEB UI operation interface, and facilitate more users' fast and safe operation.
Configuration environment
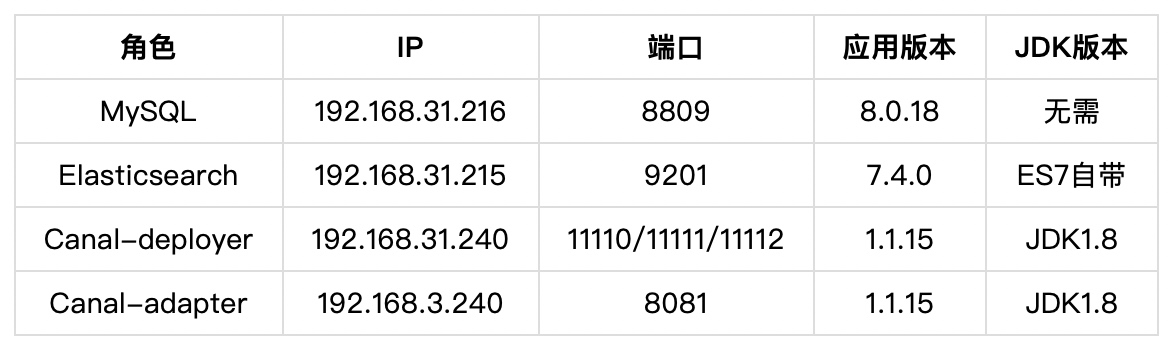
Deploy MySQL 8.0.18
1. MySQL 8.0.18 deployment
See: MySQL 8.0.18 deployment
2. Enable binlog log
be careful
The following options must be opened in the / etc/my.cnf file:
[mysqld] log-bin=/usr/local/mysql/binlogs/mysql-bin #Enable binlog binlog-format=ROW #Select ROW mode, which must be ROW mode server_id=1 #MySQL replacement configuration needs to be defined. It should not duplicate the slaveId of canal
3. Create authorization
mysql> create user canal identified by 'Canal@2019!'; #Create canal account Query OK, 0 rows affected (0.08 sec) mysql> grant select,replication slave,replication client on *.* to 'canal'@'%'; #Authorization to query and copy canal account Query OK, 0 rows affected (0.02 sec) mysql> flush privileges; #Refresh authorization Query OK, 0 rows affected (0.00 sec)
4. Check whether binlog is started correctly
mysql> show variables like 'binlog_format%'; #View binlog mode +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set (0.06 sec)
5. Create the database to be synchronized
mysql> create database canal_tsdb character set utf8;
Query OK, 1 row affected, 1 warning (0.04 sec)
mysql> use canal_tsdb;
Database changed
mysql> CREATE TABLE `canal_table` ( #Create canal_table, the field is id age name address
-> `id` int(11) NOT NULL,
-> `age` int(11) NOT NULL,
-> `name` varchar(200) NOT NULL,
-> `address` varchar(1000) DEFAULT NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Query OK, 0 rows affected, 2 warnings (0.30 sec)
mysql> INSERT INTO `canal_tsdb`.`canal_table`(`id`, `age`, `name`, `address`) VALUES (1, 24, 'Xu Weiliang', 'Pudong New Area, Shanghai');
Query OK, 1 row affected (0.02 sec)
mysql> select * from canal_table;
+----+-----+-----------+-----------------------+
| id | age | name | address |
+----+-----+-----------+-----------------------+
| 1 | 24 | Xu Weiliang | Pudong New Area, Shanghai |
+----+-----+-----------+-----------------------+
1 row in set (0.01 sec)
Deploy Elasticsearch
Select one of the following two methods according to your needs
For cluster deployment, see: Elasticsearch7.4 cluster deployment and security authentication
For single point deployment, see: Elasticsearch7.4 single point deployment and security authentication
Deploy the canal deployer server
1. Download and unzip
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.deployer-1.1.5-SNAPSHOT.tar.gz mkdir /usr/local/canal-deployer tar xf canal.deployer-1.1.5-SNAPSHOT.tar.gz -C /usr/local/canal-deployer/
2. Modify the configuration file
vim /usr/local/canal-deployer/conf/example/instance.properties canal.instance.mysql.slaveId=3 #The modified ID cannot be consistent with the MySQL database canal.instance.gtidon=false canal.instance.master.address=192.168.31.216:8809 #Specify the mysql database address and port canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= canal.instance.tsdb.enable=true canal.instance.dbUsername=canal #Specify replication account canal.instance.dbPassword=Canal@2019! #Specify replication password canal.instance.connectionCharset = UTF-8 #The character set format needs to be consistent with mysql canal.instance.enableDruid=false canal.instance.filter.regex=.*\\..* #Regular table name monitoring canal.instance.filter.black.regex= canal.mq.topic=example canal.mq.partition=0
3. Start canal deployer
Because the canal deployer is developed in java, a jdk environment is required, and the jdk version needs to be greater than 1.5
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 -y /usr/local/canal-deployer/bin/startup.sh
4. View logs and ports
1) View server logs

Canal deployer listens to three ports by default, 11110, 11111 and 11112
11110: admin management port
11111: Port occupied by the canal deployer server
11112: drop-down port for indicator
2) View the log of instance

Deploying the Canadian adapter client
1. Download and unzip
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.adapter-1.1.5-SNAPSHOT.tar.gz mkdir /usr/local/canal-adapter tar xf canal.adapter-1.1.5-SNAPSHOT.tar.gz -C /usr/local/canal-adapter/
2. Add mysql8.0.18 connector
There is only mysql5.x connector in the lib of the default Canadian adapter
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.18/mysql-connector-java-8.0.18.jar mv mysql-connector-java-8.0.18.jar /usr/local/canal-adapter/lib/ chmod 777 /usr/local/canal-adapter/lib/mysql-connector-java-8.0.18.jar #Permission modification is consistent with other lib libraries chmod +st /usr/local/canal-adapter/lib/mysql-connector-java-8.0.18.jar
3. Modify application.yml
vim /usr/local/canal-adapter/conf/application.yml
server:
port: 8081 #Specify the listening port of the Canadian adapter
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss #Time format
time-zone: GMT+8 #time zone
default-property-inclusion: non_null
canal.conf: #canal configuration
canalServerHost: 192.168.31.240:11111 #Specify the address and port that the canal deployer server listens to
batchSize: 500 #The batch size of each data acquisition, in K
syncBatchSize: 1000 #Number of batches per synchronization
retries: 0 #Number of attempts, - 1 is infinite retry, 0 is failure, no retry
timeout: #Synchronization timeout, in milliseconds. For example, when data is synchronized es, if the time exceeds this value for various reasons, it is considered timeout
srcDataSources: #Source database configuration
defaultDS: #Custom name
url: jdbc:mysql://192.168.31.216:8809/canal_tsdb? useUnicode = true #jdbc URL, specify the address and port of the database, canal_tsdb is the password above mysql and encoded in useUnicode
username: canal #Specify database account
password: Canal@2019! #Specify database password
canalAdapters: #Adapter list
groups: #Group list
- groupId: g1 #Packet id, which will be used if the adapter is in MQ mode
outerAdapters: #List of adapters in the group
- name: logger #Log print adapter
- name: es7 #The cluster version supports es6 and es7
hosts: 192.168.31.215:9201,192.168.31.215:9202,192.168.31.215:9203 #elasticsearch cluster addresses separated by commas
properties:
mode: rest #Transport mode or rest mode can be specified. In the rest mode, the hosts parameter specifies that the port must be es external port, and in the transport mode, the hosts parameter specifies that the port must be cluster communication port
security.auth: elastic:26tBktGolYCyZD2pPISW #Specify elasticsearch cluster account password
cluster.name: elastic_cluster #Specify the elasticsearch cluster name
4. Modify the adapter mapping file
vim /usr/local/canal-adapter/conf/es7/mytest_user.yml
dataSourceKey: defaultDS #Specifies the name of the srcDataSources data source customization in the application.yml file
destination: example #For instance of cannal or topic of MQ, we synchronize the data to es, so we don't need to modify it or use it here
groupId: g1 #Corresponding to the groupId in MQ mode, only the data of the corresponding groupId will be synchronized
esMapping: #Mapping settings in
_index: canal_tsdb #Specify index name
_id: _id #Specify the document id_ id this value assigns the document id automatically by es
sql: "select a.id as _id,a.age,a.name,a.address from canal_table a" #sql mapping
etlCondition: "where a.c_time>={}" #Conditional parameters of etl
commitBatch: 3000 #Submit batch size
After configuring the Canadian adapter, don't start it in a hurry. You need to define the index and mapping specified in es in advance
Elasticsearch create index
Open the Kibana interface, find the "development tool" on the left, and then create an index and specify Mapping
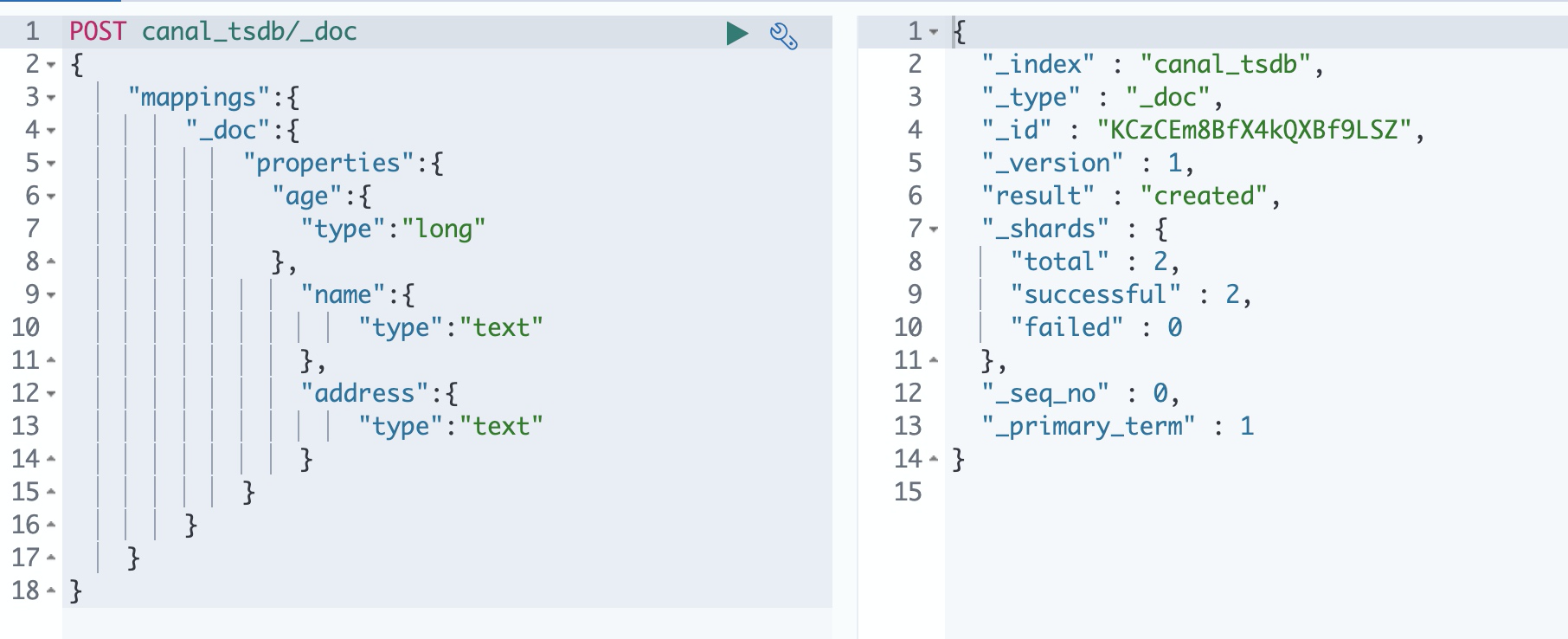
The syntax is as follows:
POST canal_tsdb/_doc
{
"mappings":{
"_doc":{
"properties":{
"age":{
"type":"long"
},
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
}
}
}
View the created index and Mapping
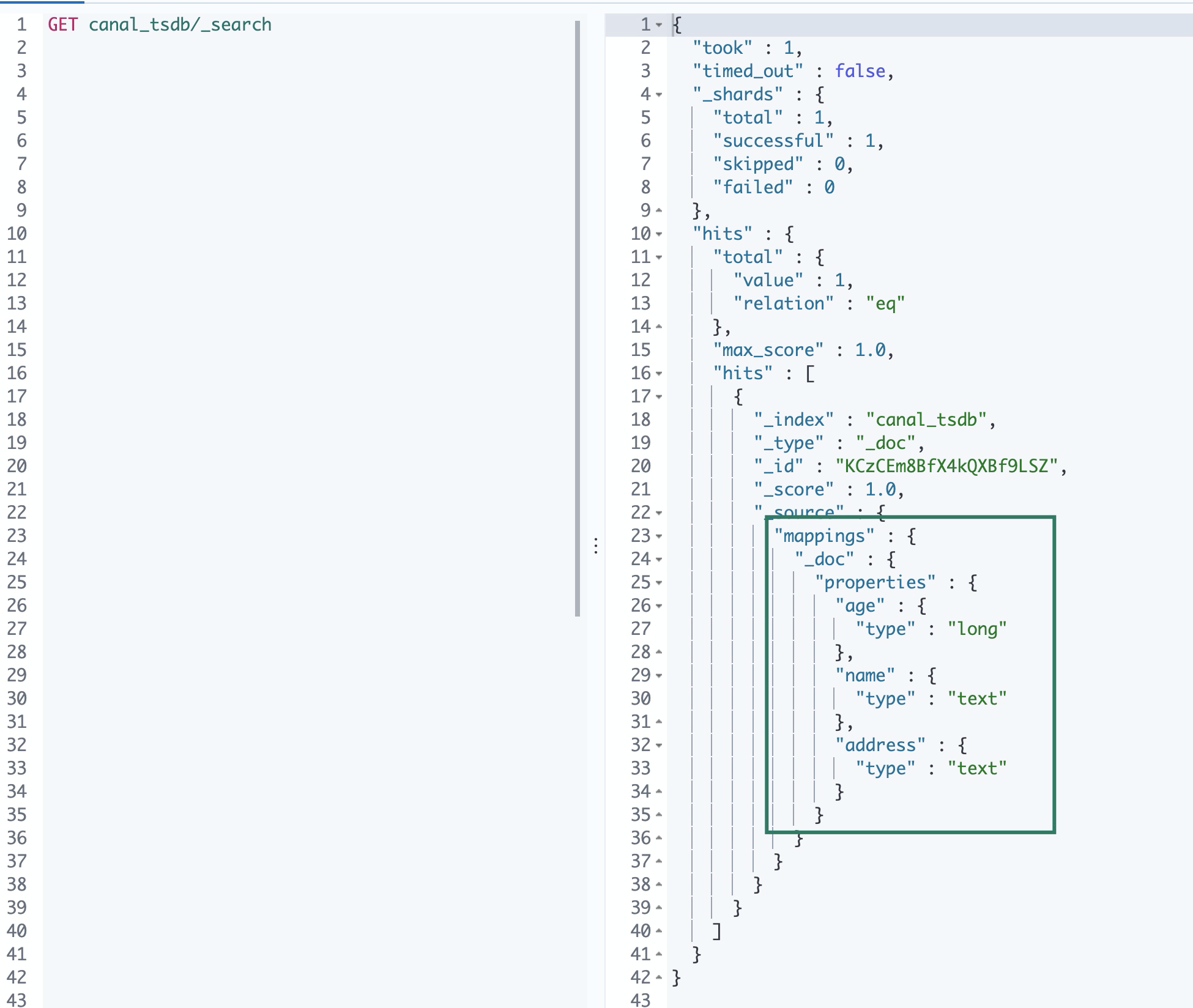
Start the Canadian adapter and write data
1. Start the process on the Canadian adapter machine and view the log
/usr/local/canal-adapter/bin/startup.sh tail -f /usr/local/canal-adapter/logs/adapter/adapter.log
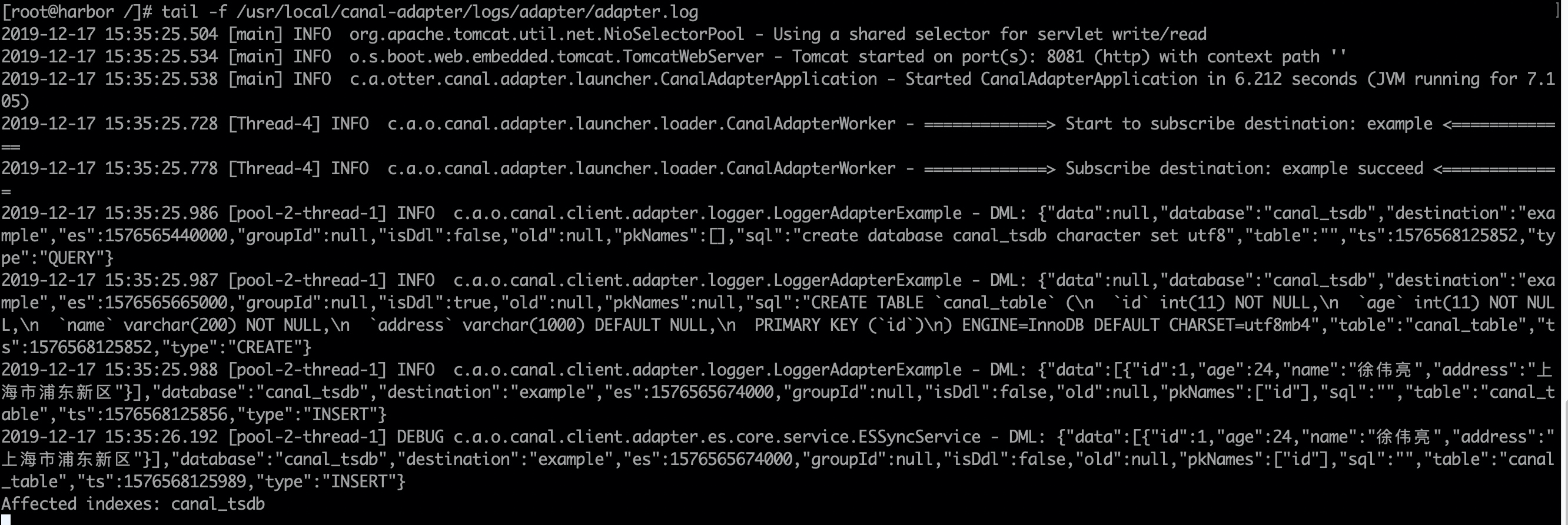
2. Insert a piece of data in MySQL again and view the log
mysql> INSERT INTO `canal_tsdb`.`canal_table`(`id`, `age`, `name`, `address`) VALUES (2, 24, 'abcops.cn', 'Pudong New Area, Shanghai'); Query OK, 1 row affected (0.01 sec)
3. View the log of the canal deployer server
tail -f /usr/local/canal-deployer/logs/example/meta.log 2019-12-17 15:48:47.457 - clientId:1001 cursor:[mysql-bin.000005,2125,1576568901000,2,] address[192.168.31.216/192.168.31.216:8809]
4. View the log of the canal apter client
tail -f /usr/local/canal-adapter/logs/adapter/adapter.log
2019-12-17 15:48:47.060 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"id":2,"age":24,"name":"abcops.cn","address":"Pudong New Area, Shanghai"}],"database":"canal_tsdb","destination":"example","es":1576568901000,"groupId":null,"isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"canal_table","ts":1576568927060,"type":"INSERT"}
2019-12-17 15:48:47.062 [pool-2-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: {"data":[{"id":2,"age":24,"name":"abcops.cn","address":"Pudong New Area, Shanghai"}],"database":"canal_tsdb","destination":"example","es":1576568901000,"groupId":null,"isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"canal_table","ts":1576568927061,"type":"INSERT"}
Affected indexes: canal_tsdb
5. View the document in Kibana
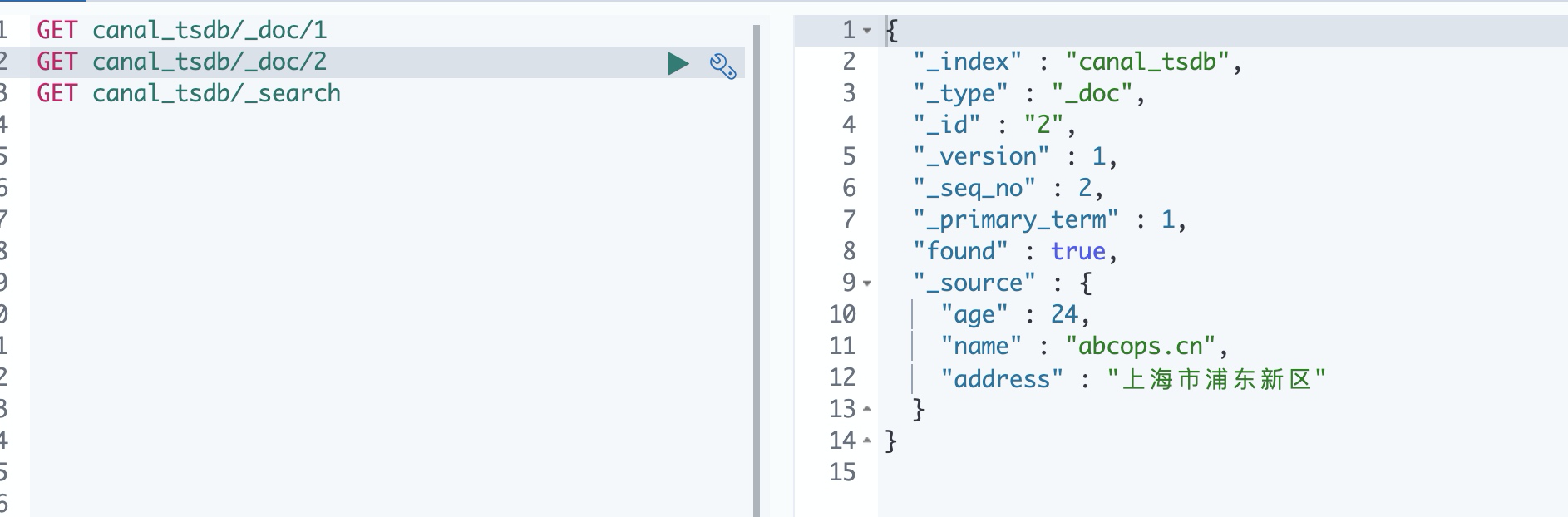
6. Update data in MySQL
mysql> update canal_table set name='goblogs.cn',address='Hongkou District, Shanghai' where id=2; Query OK, 1 row affected (0.06 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from canal_table; +----+-----+------------+-----------------------+ | id | age | name | address | +----+-----+------------+-----------------------+ | 1 | 24 | Xu Weiliang | Pudong New Area, Shanghai | | 2 | 24 | goblogs.cn | Hongkou District, Shanghai | +----+-----+------------+-----------------------+ 2 rows in set (0.00 sec)
Then go to Kibana to check whether the document has been updated
7. Delete data in MySQL
mysql> delete from canal_table where id=2; Query OK, 1 row affected (0.02 sec) mysql> select * from canal_table; +----+-----+-----------+-----------------------+ | id | age | name | address | +----+-----+-----------+-----------------------+ | 1 | 24 | Xu Weiliang | Pudong New Area, Shanghai | +----+-----+-----------+-----------------------+ 1 row in set (0.00 sec)
Check whether the document has been deleted in Kibana
Note: when the data is synchronized to Elasticsearch, Elasticsearch has CURD permission to synchronize the data
Deploy Canal Admin
Qualified dependency of canal admin:
1.MySQL is used to store configuration, node and other related data
2.canal version, which requires > = 1.1.4 (it needs to rely on canal server to provide admin oriented dynamic operation and maintenance management interface)
1. Download and unzip canal admin
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.admin-1.1.5-SNAPSHOT.tar.gz mkdir /usr/local/canal-admin tar xf canal.admin-1.1.5-SNAPSHOT.tar.gz -C /usr/local/canal-admin
2. Modify the configuration file
vim /usr/local/canal-admin/conf/application.yml
server:
port: 8089 #Canal Admin listening port
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss #Time format
time-zone: GMT+8 #time zone
spring.datasource: #database information
address: 192.168.31.216:8809 #Specify the database address and port used by the Canal Admin
database: canal_manager #Specify the database name
username: cadmin #Specify database account
password: Cadmin@2019! #Specify database password
driver-class-name: com.mysql.jdbc.Driver #Specify database driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal: #Default account and password of Canal UI interface
adminUser: admin
adminPasswd: admin
3. Create database and authorized users
Create a canal on the database node_ Manager database and authorize the cadmin user to all permissions of this database
mysql> create database canal_manager character set utf8; Query OK, 1 row affected, 1 warning (0.01 sec) mysql> create database canal_manager character set utf8; Query OK, 1 row affected, 1 warning (0.01 sec) mysql> create user cadmin identified by 'Cadmin@2019!'; Query OK, 0 rows affected (0.21 sec) mysql> grant all on canal_manager.* to 'cadmin'@'%'; Query OK, 0 rows affected (0.03 sec) mysql> flush privileges; Query OK, 0 rows affected (0.01 sec)
4. Import SQL to MySQL database
mysql -u cadmin -h 192.168.31.216 -P 8809 -p mysql> use canal_manager; Database changed mysql> source /usr/local/canal-admin/conf/canal_manager.sql; mysql> show tables; +-------------------------+ | Tables_in_canal_manager | +-------------------------+ | canal_adapter_config | | canal_cluster | | canal_config | | canal_instance_config | | canal_node_server | | canal_user | +-------------------------+ 6 rows in set (0.03 sec)
5. Start Canal Admin
/usr/local/canal-admin/bin/startup.sh
View log and listening port
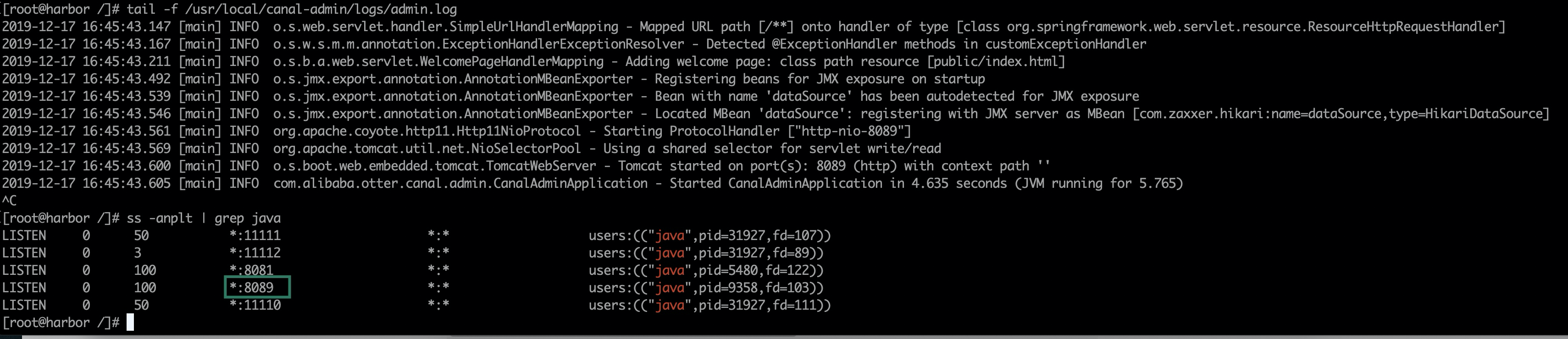
6. Access the Canal Admin UI
Access link: http://192.168.31.240:8089
The default account password is admin/123456
Canal can synchronize multiple tables to Elasticsearch
**Requirement: * * now you need to create a new canal in MySQL_ tab01,canal_tab02,canal_03, these three tables, and synchronize the data of these three tables to Elasticsearch
1. Create multiple adapter mapping files in the canal adapter
Canada adapter client operation
touch /usr/local/canal-adapter/conf/es7/{canal_tab01.yml,canal_tab02.yml,canal_tab03.yml}
chmod 777 /usr/local/canal-adapter/conf/es7/canal_tab0*
2. Create the corresponding table in MySQL database
CREATE TABLE `canal_tab01` ( `id` int(11) NOT NULL, `age` int(11) NOT NULL, `name` varchar(200) NOT NULL, `address` varchar(1000) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
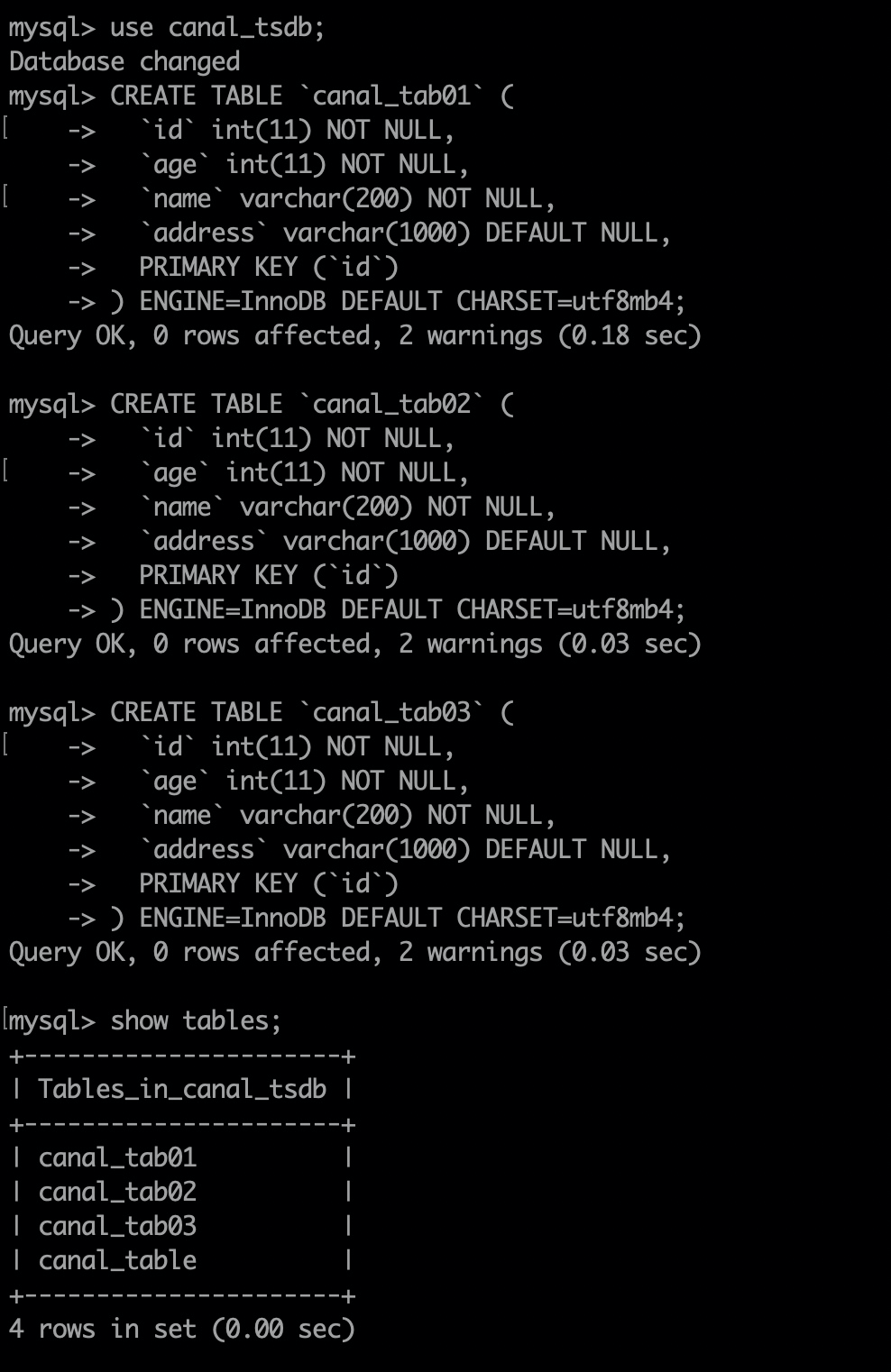
3. In canal_ Insert the corresponding field in tab01-03
mysql> INSERT INTO `canal_tsdb`.`canal_tab01`(`id`, `age`, `name`, `address`) VALUES (1, 20, 'abcops.cn', 'Jing'an District, Shanghai'); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO `canal_tsdb`.`canal_tab02`(`id`, `age`, `name`, `address`) VALUES (1, 21, 'k8sops.cn', 'Huangpu District, Shanghai'); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO `canal_tsdb`.`canal_tab03`(`id`, `age`, `name`, `address`) VALUES (1, 22, 'elk.abcops.cn', 'Changning District, Shanghai'); Query OK, 1 row affected (0.01 sec)
4. Write adapter file
Only canal is listed below_ The configuration of tab01 library. Other libraries only need to be modified_ Index index value, and canal_tab01 query the table name
cat /usr/local/canal-adapter/conf/es7/canal_tab01.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: canal_tab01 #The other two configuration files only need to put canal_ Replace tab01 index with canal_tab02 and canal_tab03 is enough
_id: _id
sql: "select a.id as _id,a.age,a.name,a.address from canal_tab01 a" #The other two configuration files need to change the name of the query table to the corresponding one
etlCondition: "where a.c_time>={}"
commitBatch: 3000
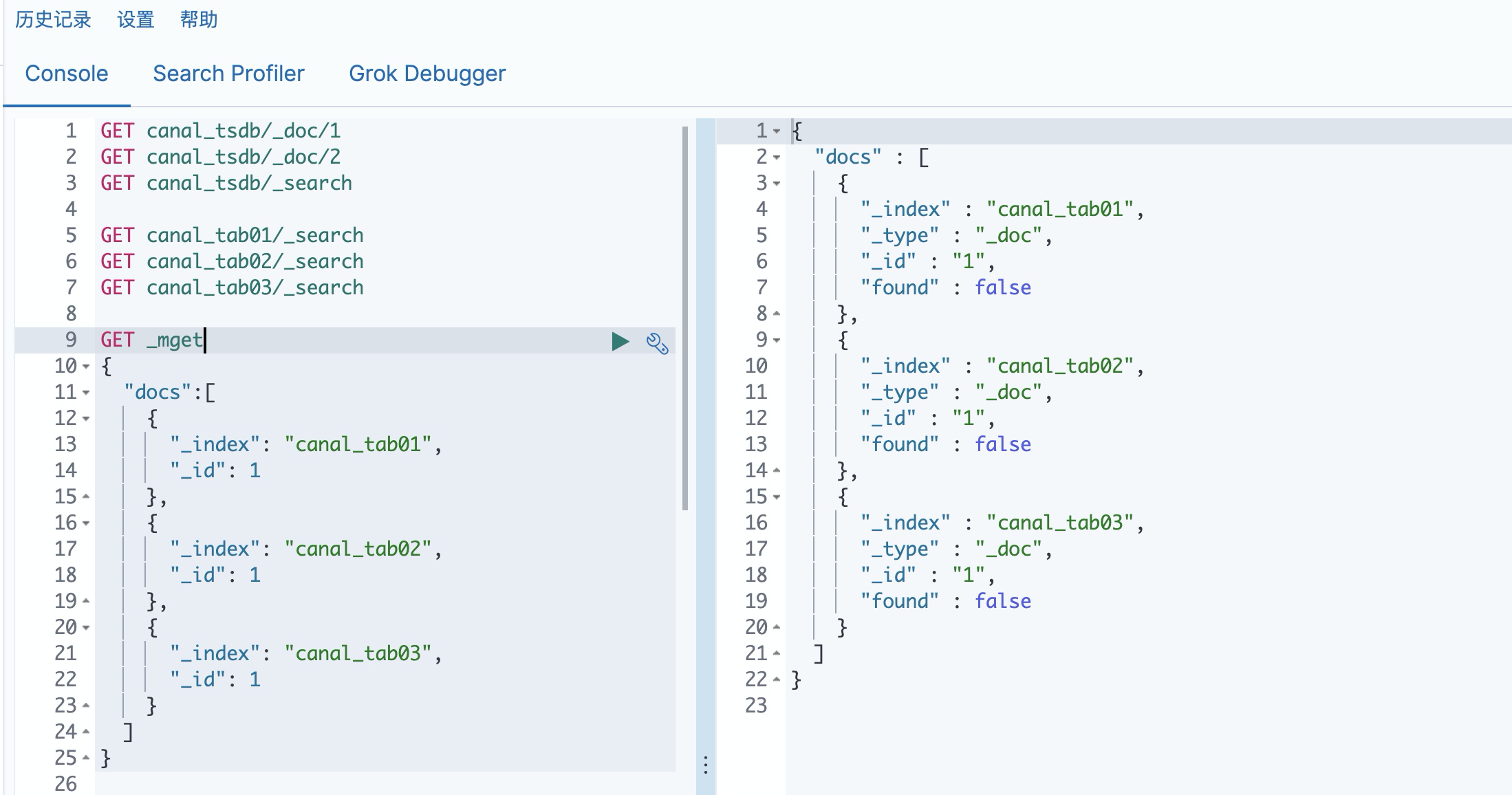
5. Create index and Mapping in Kibana
POST canal_tab01/_doc
{
"mappings":{
"_doc":{
"properties":{
"age":{
"type":"long"
},
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
}
}
}
POST canal_tab02/_doc
{
"mappings":{
"_doc":{
"properties":{
"age":{
"type":"long"
},
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
}
}
}
POST canal_tab03/_doc
{
"mappings":{
"_doc":{
"properties":{
"age":{
"type":"long"
},
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
}
}
}
6. Restart the canal adapter
/usr/local/canal-adapter/bin/stop.sh /usr/local/canal-adapter/bin/startup.sh
7. Check whether there is any error information in the Canada adapter log
8. The biggest disadvantage of Canal is that it is unable to fully synchronize the data, so the fields we just inserted in the table will not be synchronized to ES
9. Insert new data and test whether it is synchronized to Elasticsearch
The following only modifies the ID and inserts it
mysql> INSERT INTO `canal_tsdb`.`canal_tab01`(`id`, `age`, `name`, `address`) VALUES (2, 20, 'abcops.cn', 'Jing'an District, Shanghai'); Query OK, 1 row affected (0.23 sec) mysql> INSERT INTO `canal_tsdb`.`canal_tab02`(`id`, `age`, `name`, `address`) VALUES (2, 21, 'k8sops.cn', 'Huangpu District, Shanghai'); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO `canal_tsdb`.`canal_tab03`(`id`, `age`, `name`, `address`) VALUES (2, 22, 'elk.abcops.cn', 'Changning District, Shanghai'); Query OK, 1 row affected (0.00 sec)
10. Check whether Elasticsearch data is synchronized successfully
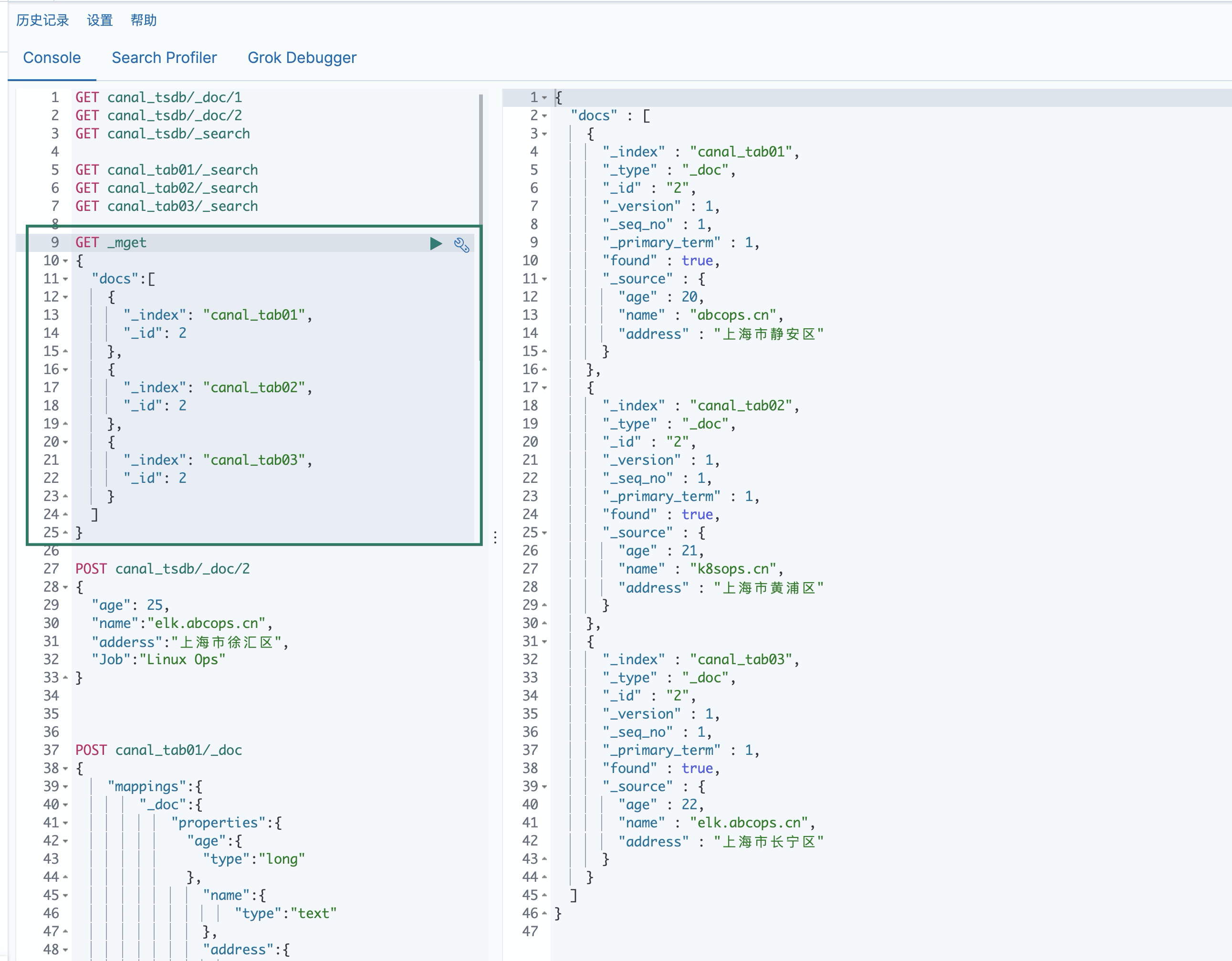
MySQL realizes multi database data synchronization to Elasticsearch through Canal
1. Modify the configuration of the canal adapter
vim /usr/local/canal-adapter/conf/application.yml
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.31.216:8809/canal_tsdb?useUnicode=true
username: canal
password: Canal@2019!
crmdb: #User defined names. I'll use them as library names to distinguish them
url: jdbc:mysql://192.168.31.216:8809/crmdb?useUnicode=true # specify JDBC URI
username: canal #Specify replication account
password: Canal@2019! #Copy password
Add the following figure
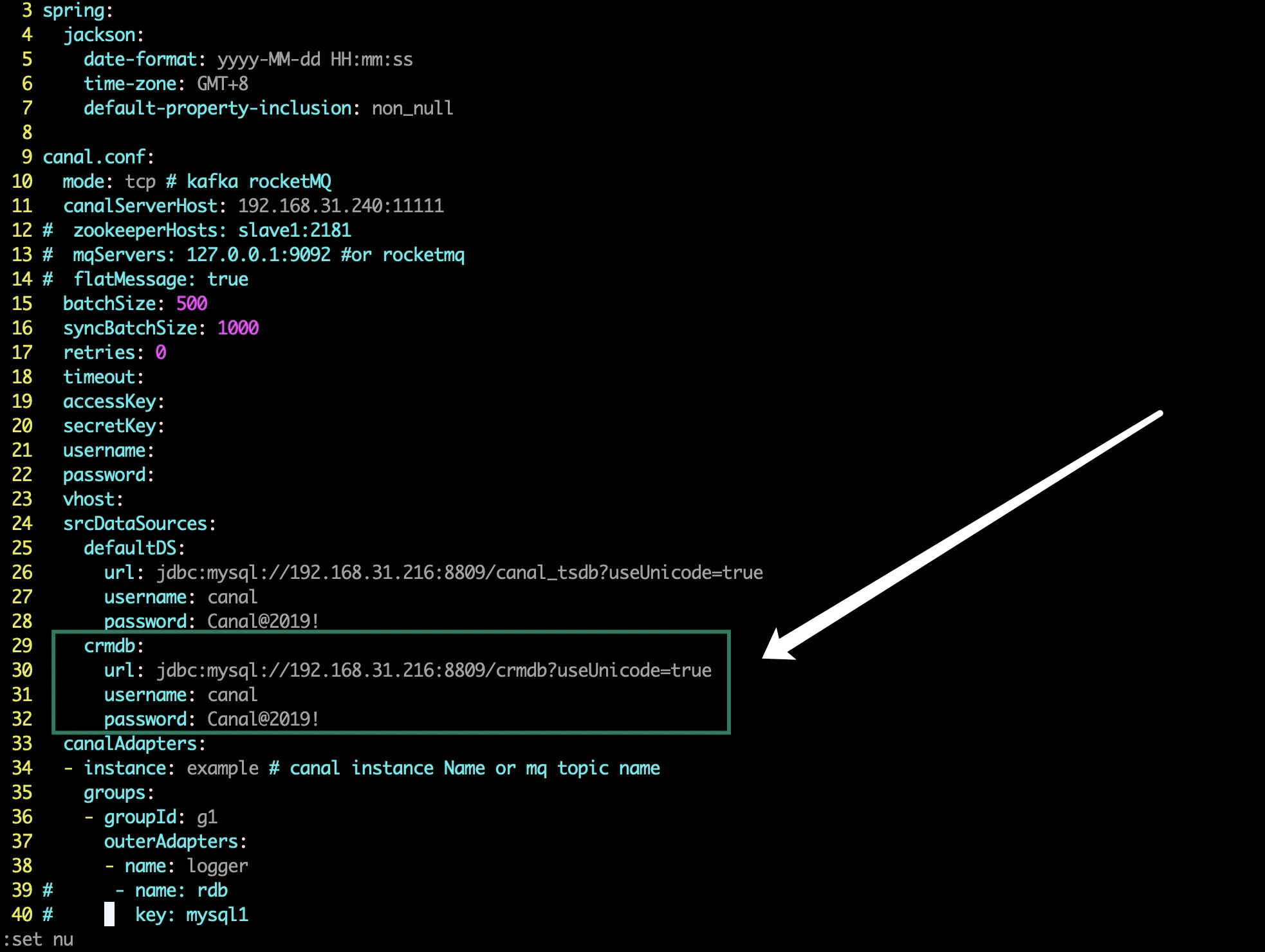
2. Create adapter file
vim /usr/local/canal-adapter/conf/es7/crmdb_tab01.yml #For the first table in the crmdb library, create a file according to the table name
dataSourceKey: crmdb #The data source key must be consistent with the user-defined name of the configuration modified above
destination: example
groupId: g1
esMapping:
_index: crmdb_tab01 #A table has an index, and the index name is named according to the table name
_id: _id
sql: "select a.id as _id,a.age,a.name,a.address from crmdb_tab01 a" #Table name mapping sql
etlCondition: "where a.c_time>={}"
commitBatch: 3000
3. Create libraries and tables
Create a crmdb library. Skip here and create a crmdb_ Table tab01 is also omitted
4. Create index and Mapping in Kibana
The index creation should be consistent with the index name in the adapter file, and the field type should be consistent with that in MySQL. If you forget, please see the above article and create it yourself
5. Restart the canal adapter
/usr/local/canal-adapter/bin/stop.sh /usr/local/canal-adapter/bin/startup.sh
6. Crmdb in crmdb Library_ Self inserting data in tab01 table
Process strategy...
7. View the Canadian adapter log
Process strategy
8. View the index and synchronized documents in Kibana
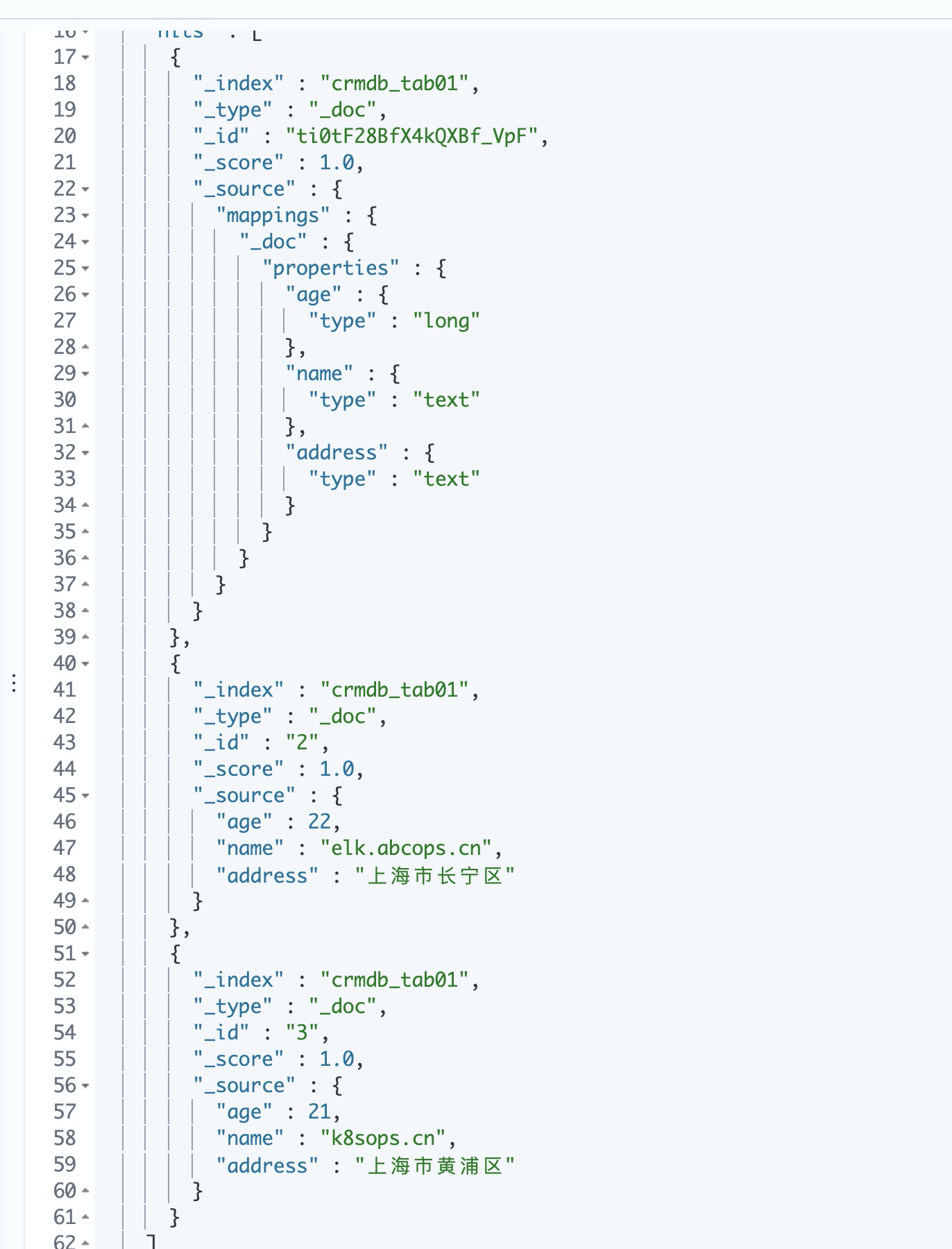
summary
Disadvantages:
- Full synchronization is not supported
- You must first create the Mapping of the corresponding index in ES