This part is mainly aimed at the basic operation, but also a skilled application of learning knowledge.
I. concept of database
First, what is a database? What does the database do? If only to store data, we can use file storage. Why get a database? To answer this question, first of all, we need to know the insecurity of storing data with files.
1. Insecurity of documents
2. Files are not conducive to data storage and management
3. The file is not able to store massive data.
4. It is inconvenient to control the document procedure.
Therefore, in order to solve the above problems, we developed the database and introduced the related concepts. Where are the database storage files stored? There are two types of database storage media:
1.
magnetism
disc
2.
within
Save
\color{red}{1. Disk 2. Memory}
1. Disk 2. Memory
Databases can be roughly divided into two types, relational database and non relational database.
Relational database
The so-called relational database refers to:
A database that uses a relational model to organize data. In short, relational model refers to two-dimensional table model, and a relational database is a data organization composed of two-dimensional tables and their relationships. Standard based SQL is only different from some internal implementations. Common relational databases, such as:
- Oracle: Oracle products are suitable for large projects and complex business logic, such as ERP, OA and other enterprise information system charges.
- MySQL: it belongs to Oracle and is not suitable for complex business. Open source free.
- SQL Server: Microsoft product, installed and deployed on windows server, suitable for medium and large projects. Charge.
Non relational database
The so-called non relational database refers to:
SQL based implementation is not specified. Now it refers more to NoSQL database, such as:
- Based on key value pairs: such as memcached and redis
- Document based: such as mongodb
- Based on column family: such as hbase
- Based on Schema: e.g. neo4j
II. Database related operations
Enter database
First, there are two ways to enter the database. The first is to enter directly through the start menu bar:
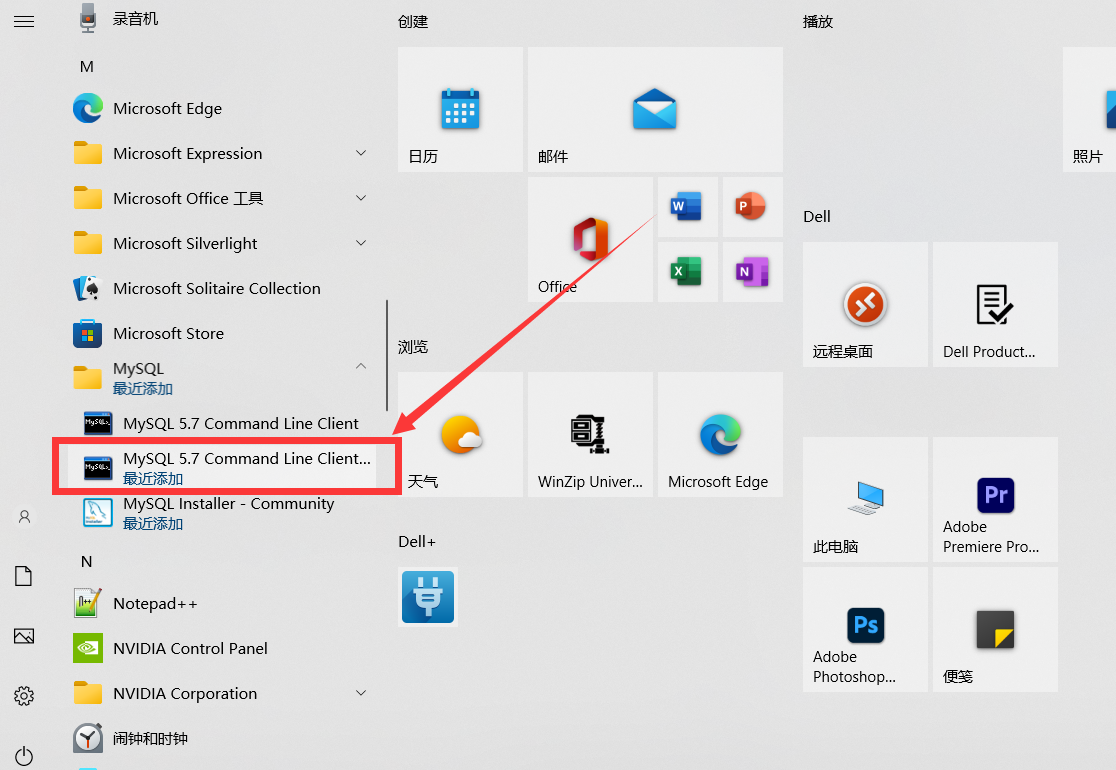
However, if you configure the relevant path, you can open it directly through the DOS window. Enter the command: mysql -u root -p, and then enter the password to enter your database
increase
New database
The increase here is not only to increase the database, but also to increase the corresponding tables, step by step.
First, enter the database and then enter the command: show databases;

Then we use the command create database test, Create a new database named test.
Note here that we try to add a character set utf8mb4, so that Chinese can be received in the database. Full command:
create database test character set utf8mb4;
After the establishment, we enter the command show databases again to view the database
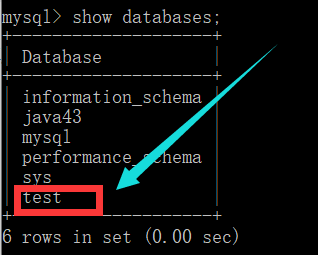
It can be found that it has been built.
New table
Then we enter the command use test to enter the current database.
Then we are ready to create a table, but before we create a table, we need to think about the attributes we need in the table.
For example, here:
We create a student table. First, students need an id to sort students, and then students have names, student numbers and their own qq email
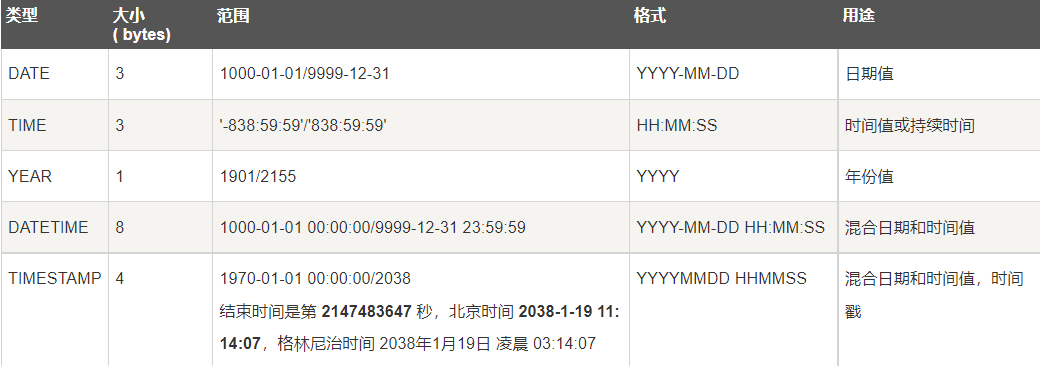
About data types
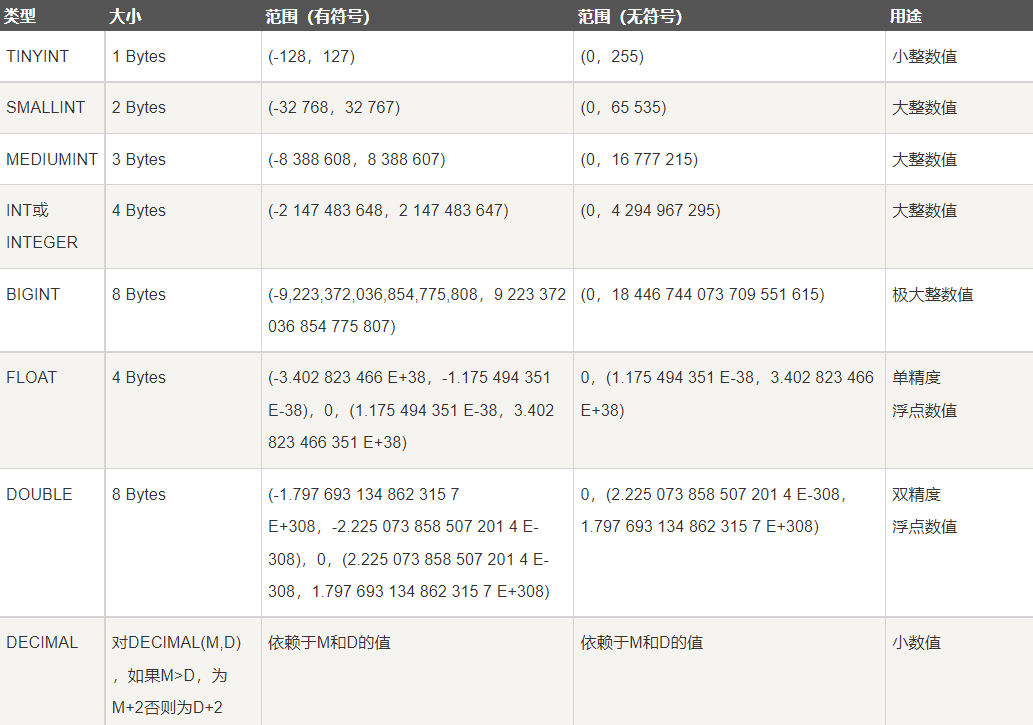
There are data types in java and mysql. After all, there are a variety of data types saved. Among them, the general types are:
number
value
class
type
\color{red} {numeric type}
value type
day stage and Time between class type \color{red} {date and time type} Date and time type
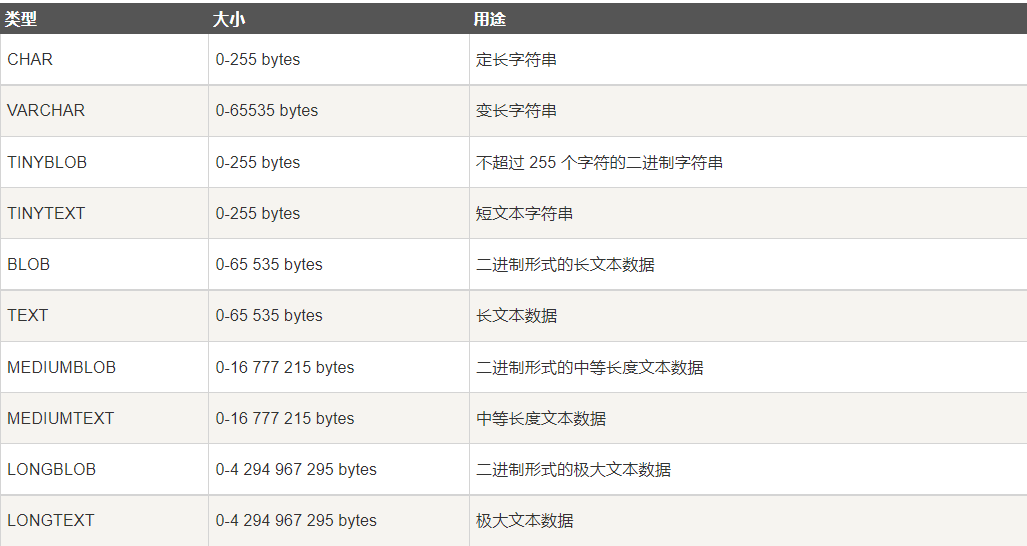
word
symbol
strand
class
type
\color{red} {string type}
String type
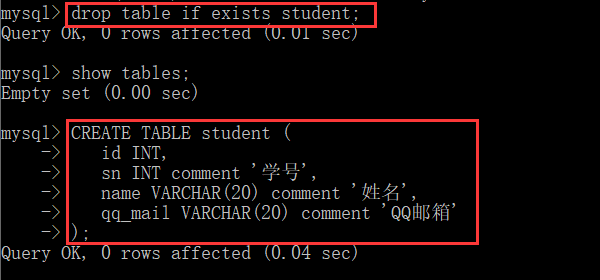
Add new table
After understanding the general data types, we can start to create a table. The general format of creating a table is as follows:
CREATE TABLE table_name ( field1 datatype, field2 datatype, field3 datatype );
But before that, we can add a new statement to prevent us from not updating the corresponding data when we really use the database in the future.
drop table if exists student
Specific practices are as follows:
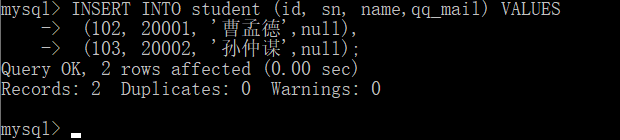
Add data
So here we can use the command:
insert into student(id,sn,name,qq_mail) values(insert data);
ID, Sn, name, QQ here_ Mail refers to the member attributes in the current table, and then we can directly insert data through the above statements, as shown below:
You can also use the abbreviated version because it is inserted by specifying the attribute. We can also insert the default attribute without specifying the attribute, that is:

After insertion, it looks like this:
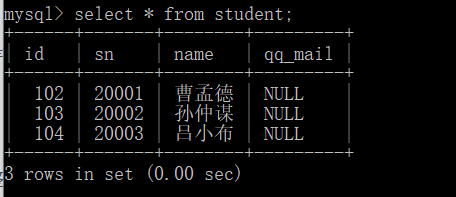
check
For query, we still go down one by one.
Here, we will create a new table to facilitate the explanation of the following contents.
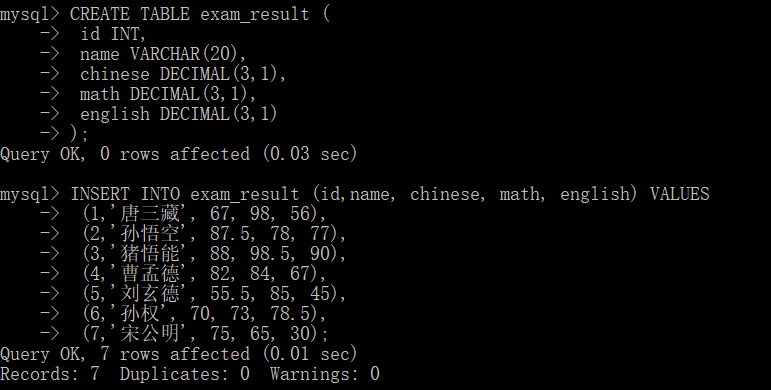
Full column query
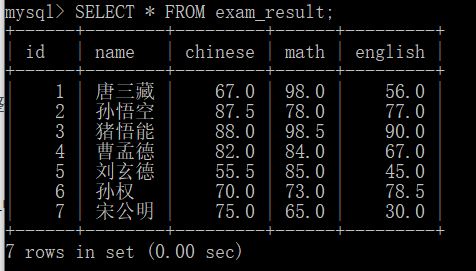
Full column query is to query the whole table:
SELECT * FROM exam_result;
The performance is as follows:
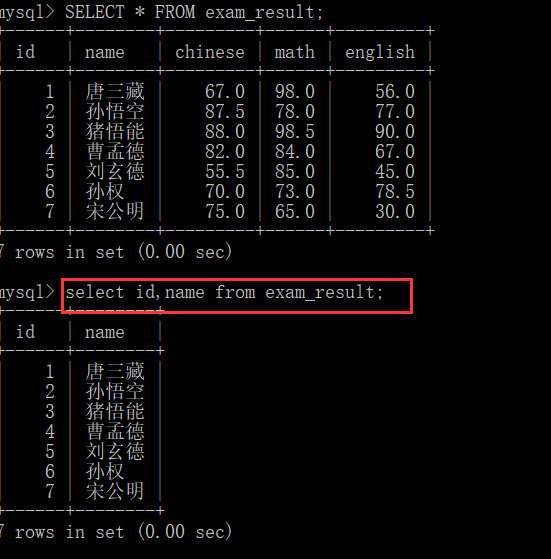
Specify column query
To specify a column query is to slightly change the above query statement:
select id,name from exam_result;
The performance in the database is as follows:
Query field is keyword
It can be divided into the following categories:
surface reach type no package contain word paragraph \color{red} {expression does not contain field} The expression does not contain a field
SELECT id, name, 10 FROM exam_result;
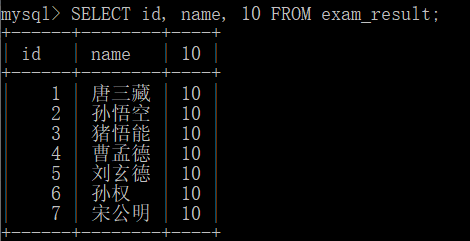
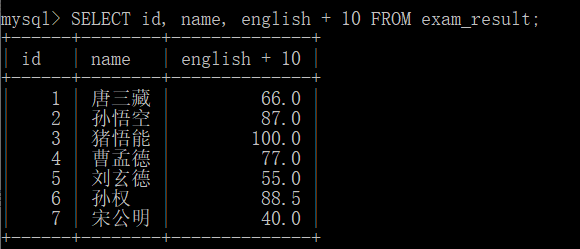
surface reach type package contain one individual word paragraph \The color{red} {expression contains a field} The expression contains a field
SELECT id, name, english + 10 FROM exam_result;
The database is as follows:
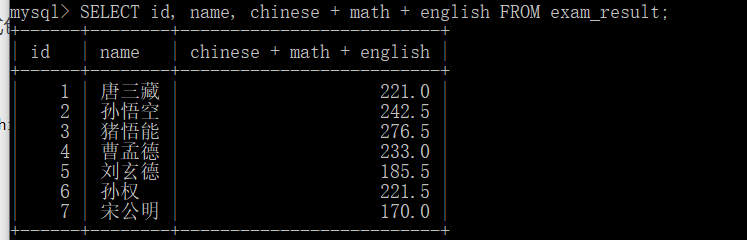
surface reach type package contain many individual word paragraph \color{red} {expression contains multiple fields} The expression contains multiple fields
SELECT id, name, chinese + math + english FROM exam_result;
The database is as follows:
Alias
This operation is to specify an alias for the column in the query, which means that the alias is used as the name of the changed column in the returned result set. Syntax:
SELECT column [AS] alias_name [...] FROM table_name;
The specific performance in the database is as follows:
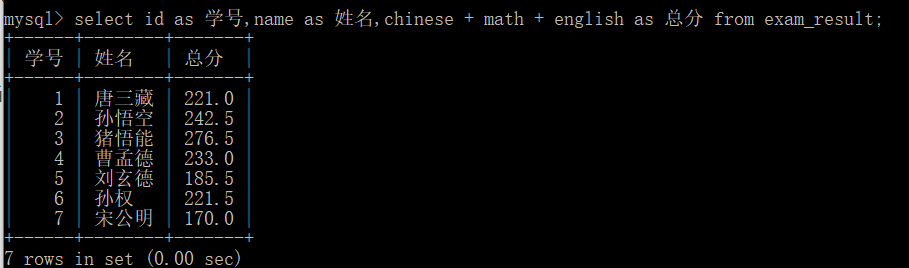
After being proficient, this as can be removed, but at present, the author is a novice on the road and is still a little stable.
Weight removal: DISTINCT
Here, the distinct keyword is used to de duplicate a column of data.
SELECT DISTINCT math FROM exam_result;
sort
-- ASC In ascending order (from small to large) -- DESC In descending order (from large to small) -- Default to ASC SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
The key points of use are as follows:
1.first order by It must be written 2.remember Null Data, such as any data, should be small. 3.You can sort using expressions and aliases 4.Multiple fields can be sorted, and the specific sorting order is determined by the keyword order
Let's demonstrate in the database:
The first is ascending sort
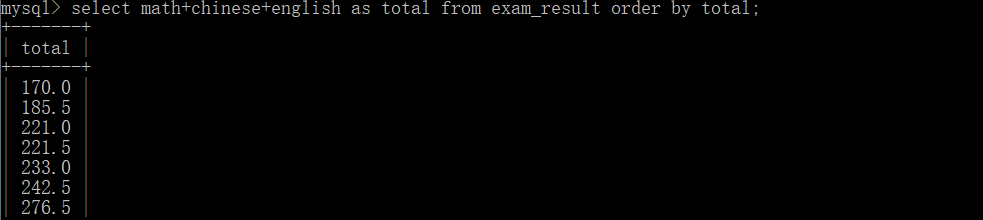
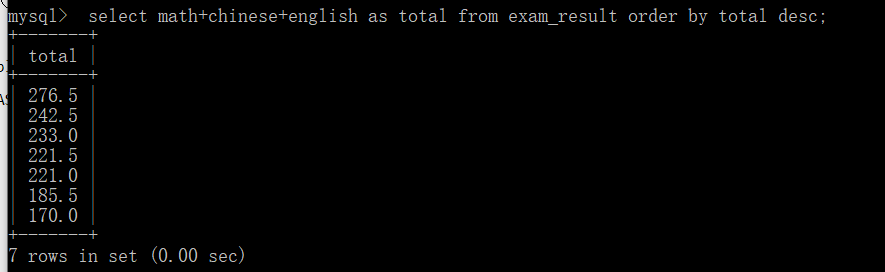
Another descending sort:
Query criteria: Where
For conditional query, the main functions of operators are:
first
before
yes
than
relatively
transport
count
symbol
\color{red} {first is the comparison operator}
The first is the comparison operator
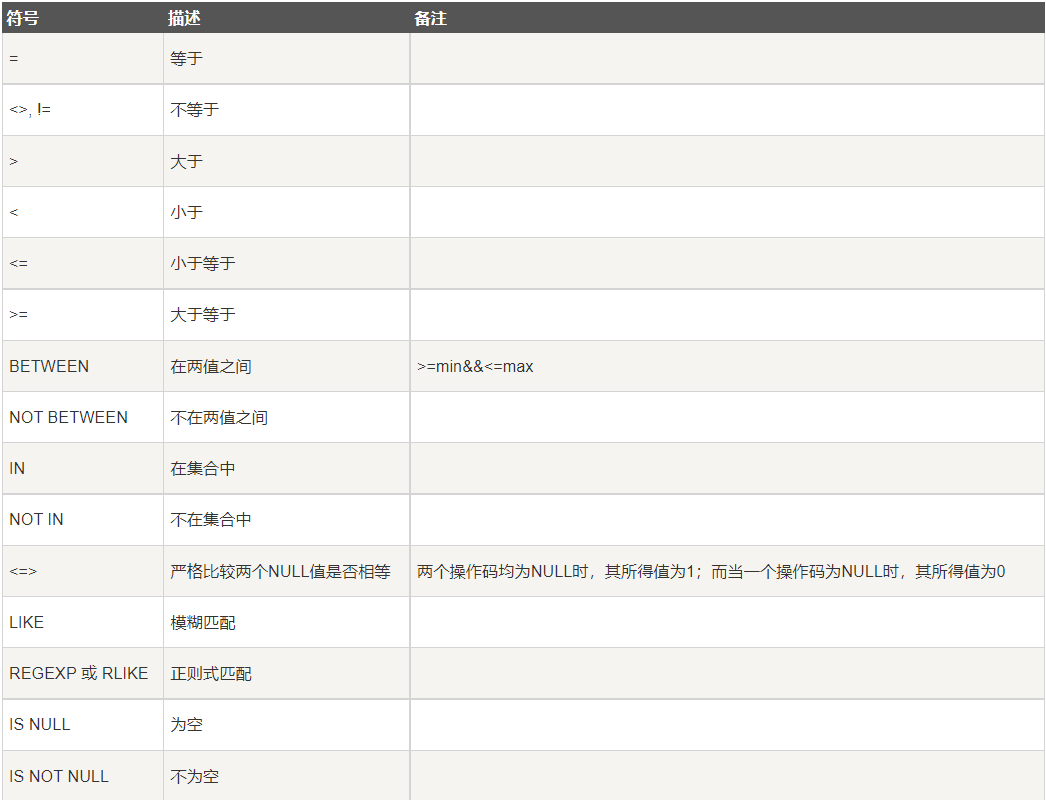
meet
means
yes
Logic
Compilation
transport
count
symbol
\color{red} {followed by the logical operator}
Then logical operators
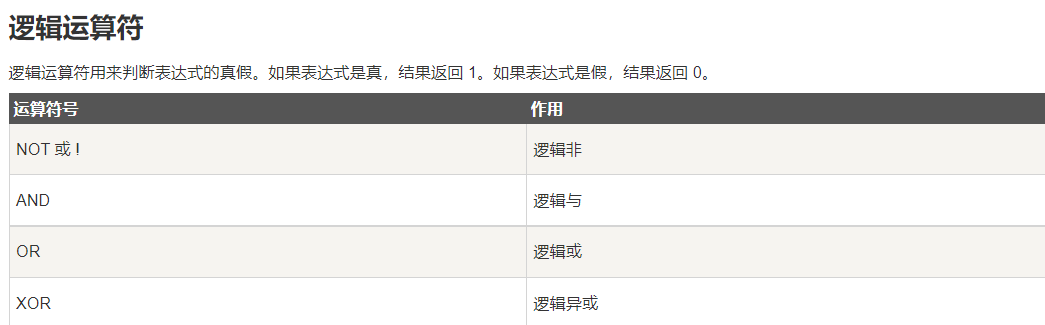
Then, we use these operators to query our table.
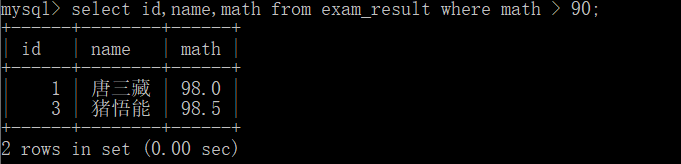
first before yes shut to base book check Inquire \color{red} {the first is about the basic query} The first is about basic queries
The basic query is based on the most basic greater than less than.
select id,name,math from exam_result where math > 90;
a n d And o r \color{red}{and and or} And and or
In fact, it means making some modifications to the where statement
select id,name,math,english from exam_result where math > 90 and english >= 90;
The details are as follows:

Range query
Range query is actually the expansion of the above condition query. Specifically, the following statements are used.
b e t w e e n . . . a n d . . . . \color{red}{between...and....} between...and....
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
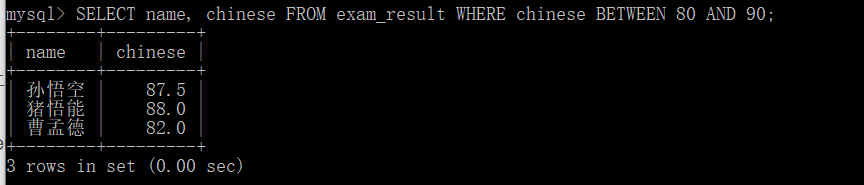
Remember that the scope here is:
[80,90], 80 and 90 are available
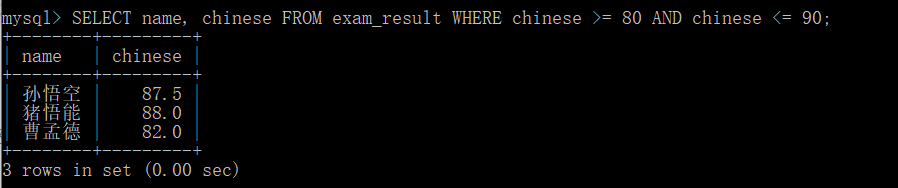
However, the above statement can also be implemented with and.
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
i
n
\color{red}{in}
in
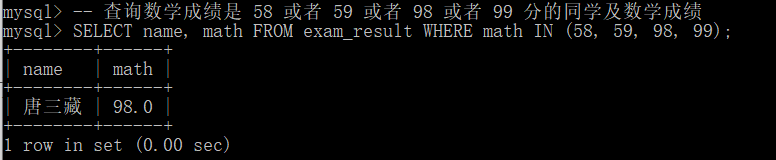
About in query is to specify a set and query the elements in the set. For example:
-- Query students whose math scores are 58 or 59 or 98 or 99 and their math scores SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
The implementation is as follows:
This statement can be implemented with or:
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99;
Fuzzy query: LIKE
Fuzzy query is mainly about two characters% and_ Use of.
1.% indicates that it can be 0 ~ any character
2._ Can only be one character
Its specific meaning is like this:
-- % Match any number (including 0) characters SELECT name FROM exam_result WHERE name LIKE 'Sun%';-- Match to Sun Wukong and Sun Quan
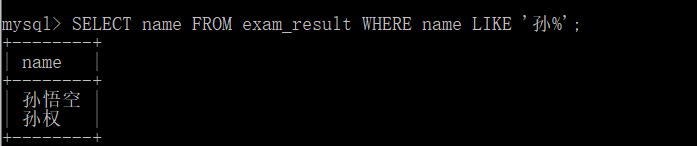
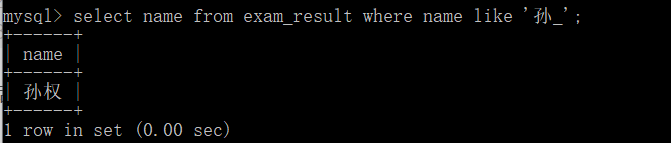
But if you use_ If so, there is only one result:
-- _ Match a strict arbitrary character SELECT name FROM exam_result WHERE name LIKE 'Sun_';-- Match to Sun Quan
null query
There is nothing special to say here, that is, whether the data is Null or not.
-- query qq_mail Names of known students SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL; -- query qq_mail Unknown classmate name SELECT name, qq_mail FROM student WHERE qq_mail IS NULL;
Paging query
-- The starting subscript is 0 -- Filter from 0 n Article results SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n; -- from s Start, filter n Article results SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n; -- from s Start, filter n The result is more explicit than the second usage, and it is recommended to use SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
Here, we use an example to demonstrate. For example, we want to take the second to third place in English.
Do you want to sort in descending order first? After descending sorting, use limit to get the value of data.
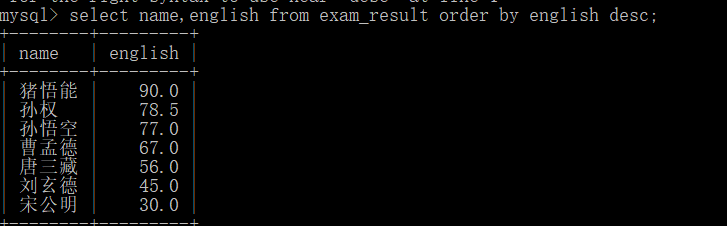
After the descending order is completed, then take 2 ~ 3 data. Here are two ways to write them. Try both:


change
For changes, we usually change the values in the table. Here, use the update keyword to modify.
The syntax is as follows:
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
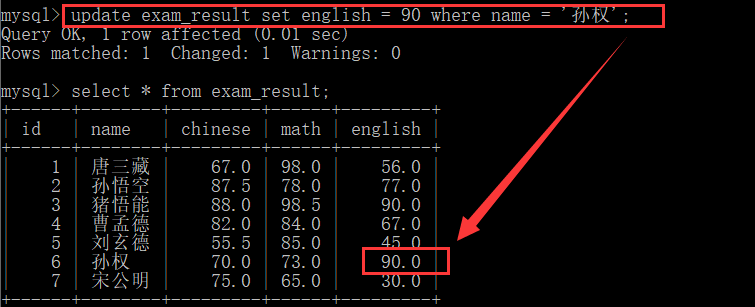
For example, we changed Sun Quan's English score to 90. Before the change:
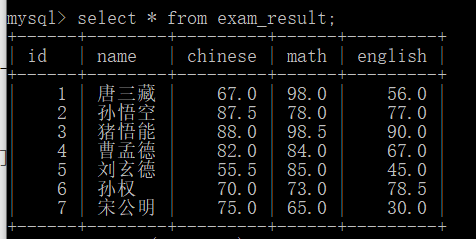
Modify with modify statement:
update exam_result set english = 90 where name = 'Sun Quan';
delete
The overall statement of delete operation is as follows:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
Delete single line data
Then, according to the above statement, we delete a line of data, for example, we delete the grades of Sun Quan.
delete from exam_result where name = 'Sun Quan';
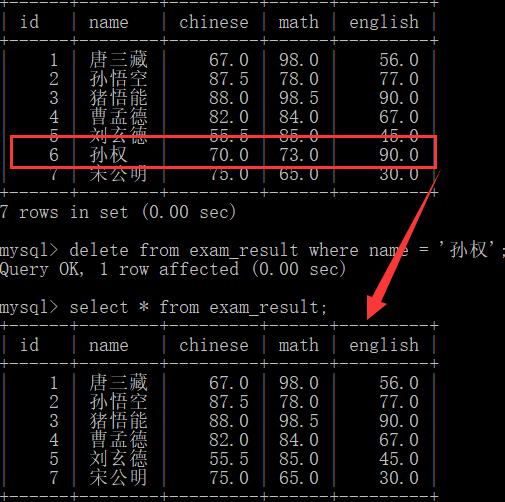
It can be seen that Sun Quan's achievements have disappeared.
Empty entire table
If we don't add where, we are clearing the data of the table.
delete from exam_result;
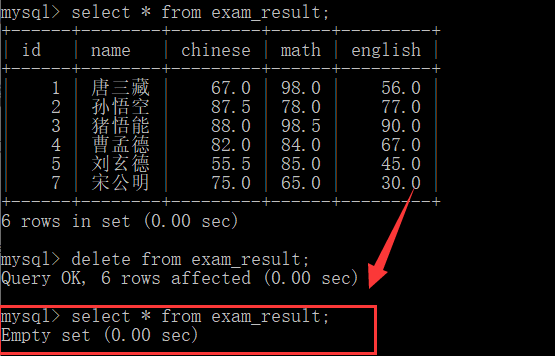
Delete Table + delete database
We use the drop keyword to delete here.
drop table exam_result;
After deletion, you can see that the current table has disappeared.
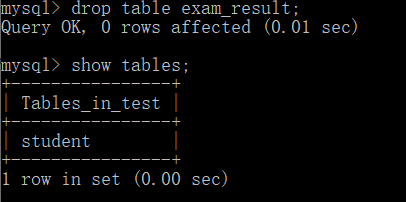
Then continue to delete the database:
drop datebase test;
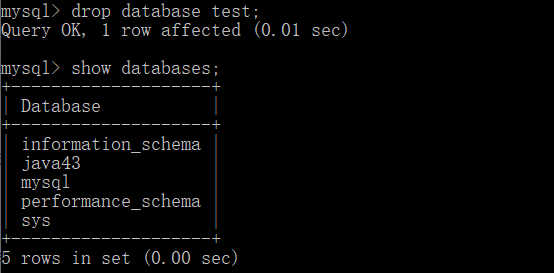
Finally, you can see that the test database has also disappeared.