Index optimization analysis
1, Reasons for SQL performance degradation
-
Poor writing of query statements
-
Index failure: the index is built but not used
-
Too many join (design defect or unavoidable requirement) for association query
-
Server tuning and setting of various parameters (buffer, number of threads, etc.)
2, Common common Join queries
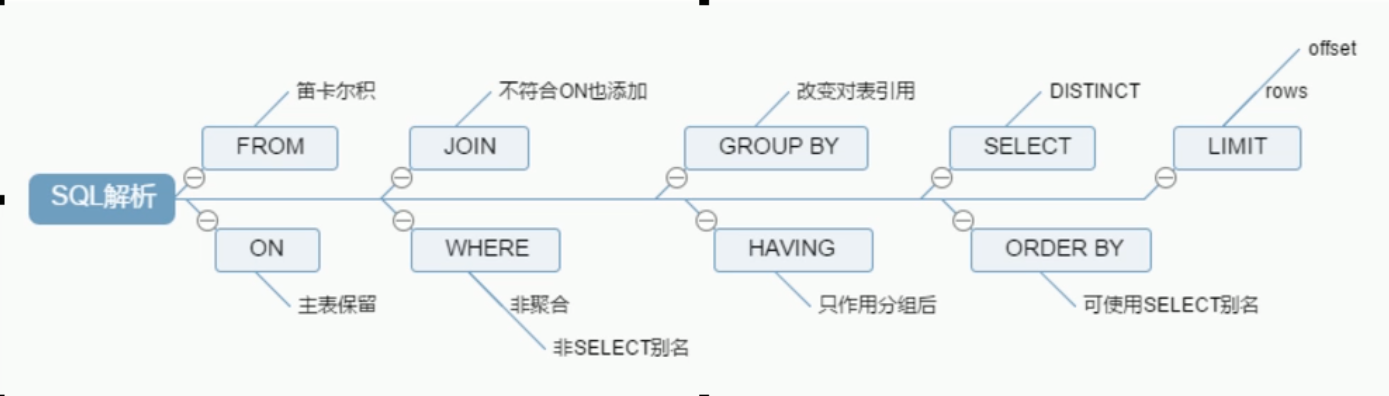
SQL execution order
Handwritten
SELECT DISTANCT <select_list> FROM <left_table> <join_type> join <right _table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit number>
Machine reading
FROM <left_table> ON <join_condition> <join_type> join <right _table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTANCT <select_list> ORDER BY <order_by_condition> LIMIT <limit number>
summary
Join graph
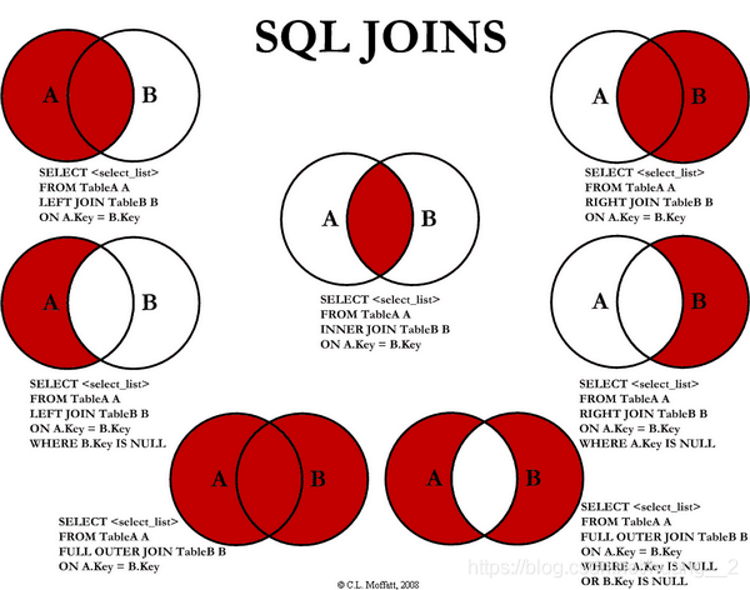
Note: FULL OUTER JOIN MySQL does not support
Using union
SELECT * from tbl_emp a left join tbl_dept b on a.deptId = b.id union SELECT * from tbl_emp a right join tbl_dept b on a.deptId = b.id
A. B. replace with
SELECT * from tbl_emp a left join tbl_dept b on a.deptId = b.id where b.id is null union SELECT * from tbl_emp a right join tbl_dept b on a.deptId = b.id where a.id is null
Table building test
CREATE TABLE `tbl_emp` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `deptId` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `fk_dept_id`(`deptId`) )ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8; CREATE TABLE `tbl_dept` ( `id` int(11) NOT NULL AUTO_INCREMENT, `deptName` varchar(30) DEFAULT NULL, `locAdd` varchar(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8; insert into tbl_dept values(null,'RD',1); insert into tbl_dept values(null,'HR',12); insert into tbl_dept values(null,'MK',13); insert into tbl_dept values(null,'MIS',14); insert into tbl_dept values(null,'FD',15); insert into tbl_emp values(null,'z3',1); insert into tbl_emp values(null,'z4',1); insert into tbl_emp values(null,'z5',1); insert into tbl_emp values(null,'w5',2); insert into tbl_emp values(null,'w6',2); insert into tbl_emp values(null,'s7',3); insert into tbl_emp values(null,'s8',4); insert into tbl_emp values(null,'s9',51);
3, Introduction to index
1. What is it
MySQL's official definition of INDEX is: INDEX is the data result that helps MySQL obtain data efficiently
You can get the essence of an index: an index is a data structure.
It can be simply understood as "ordered fast search data structure"
In addition to the data itself, the database also maintains a data structure that meets the specific search algorithm. These data structures point to the data in some way, so that the advanced search algorithm can be realized on the basis of these data structures. This data structure is index. The following figure is an example of a possible indexing method
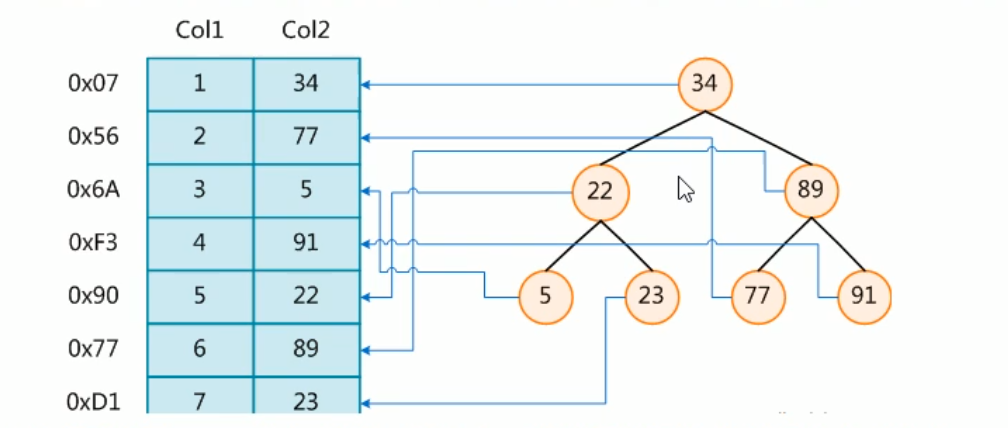
On the left is the data table, which has two columns and seven records. On the far left is the physical address of the data record.
In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used to obtain the corresponding data within a certain complexity, so as to quickly retrieve the qualified records.
Generally speaking, the index itself is too large to be stored in memory, so the index is often stored on disk in the form of index file.
The index we usually call, if not specified, All refer to the indexes organized by the B-tree (multi-channel search tree, not necessarily binary) structure. The clustered index, secondary index, overlay index, composite index, prefix index and unique index all use the B + tree index by default, collectively referred to as the index. Of course, in addition to the data structure index of B + tree, there are Hash Index, etc.
2. Advantages
- Search: similar to the bibliographic index of university library, improve the efficiency of data retrieval and reduce the IO cost of database
- Sorting: sorting data by index reduces the cost of data sorting and CPU consumption
3. Disadvantages
-
In fact, the index is also a table, which saves the primary key and index fields and points to the records of the entity table, so the index column also takes up space
-
Although the index greatly improves the query speed, it will also reduce the UPDATE speed of the table, such as frequent INSERT, UPDATE and DELETE of the table. When updating a table, MySQL should not only save the data, but also save the index file. Each time the fields of the added index column are updated, the index information after the key value changes caused by the UPDATE will be adjusted.
-
Indexing is only a factor to improve efficiency. If MySQL has a large amount of tables, you need to spend time studying and establishing the best index.
4. Index classification
-
Single value index: an index contains only a single column, and a table can have multiple single column indexes.
-
Unique index: the value of the index column must be unique, but null values are allowed.
-
Composite index: an index contains multiple fields.
Suggestion: the index of a table should not exceed 5!
5. Basic grammar
/*The creation plus [UNIQUE] indicates a UNIQUE index columnName(length). Multiple fields are composite indexes, and a single field is a single value index*/ CREATE [UNIQUE] INDEX indexName ON tabName(columnName(length)); ALTER TABLE tabName ADD [UNIQUE] INDEX indexName ON (columnName(length)); /* 2,Delete index */ DROP INDEX [indexName] ON tabName; /* 3,View index */ /* If you add \ G, you can view it in the form of column. If you don't add \ G, you can view it in the form of table */ SHOW INDEX FROM tabName \G;
Using the alter command
/* 1,This statement adds a primary key, which means that the index value must be unique and cannot be NULL */ ALTER TABLE tabName ADD PRIMARY KEY(column_list); /* 2,The key value of the index created by this statement must be unique (NULL may occur multiple times except NULL) */ ALTER TABLE tabName ADD UNIQUE indexName(column_list); /* 3,This statement creates a normal index, and the index value can appear multiple times */ ALTER TABLE tabName ADD INDEX indexName(column_list); /* 4,This statement specifies that the index is FULLTEXT, which is used for full-text retrieval */ ALTER TABLE tabName ADD FULLTEXT indexName(column_list);
6. mysql index structure
Index data structure:
-
B+Tree index
-
Hash index
-
Full text index
-
R-Tree index
BTree index retrieval principle
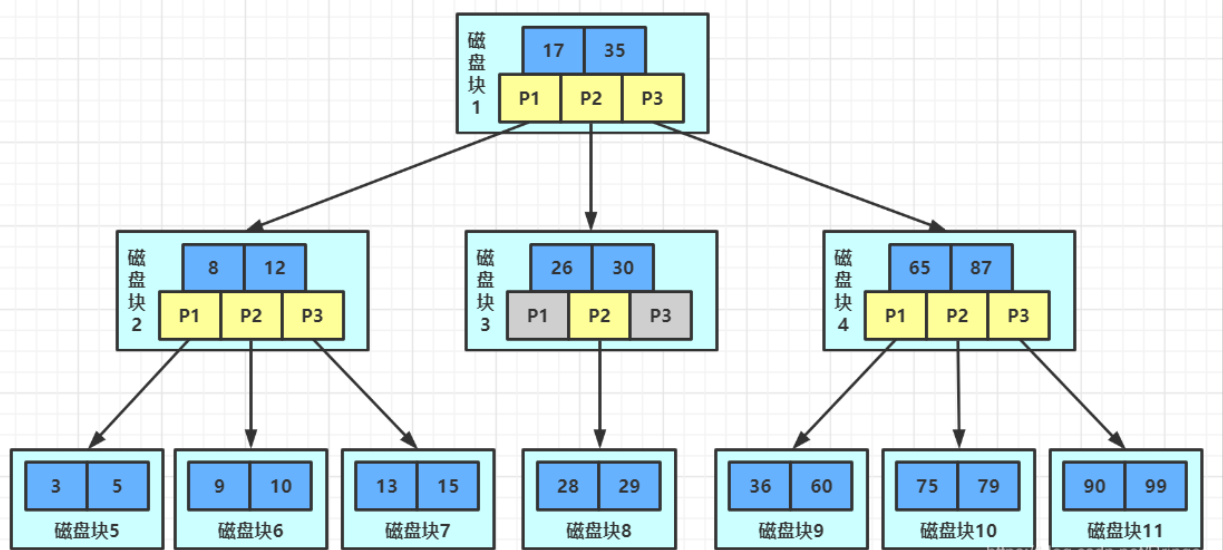
Initialization introduction
A b + tree, light blue fast, we call it a disk block. You can see that each disk block contains several data items (shown in dark blue) and pointers (shown in yellow). For example, disk block 1 contains data items 17 and 35, including pointers P1, P2 and P3
P1 represents a disk block less than 17, P2 represents a disk block between 17 and 35, and P3 represents a disk block greater than 35
Real data exists in leaf nodes, i.e. 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90 and 99
Non leaf nodes do not store real data, but only store data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
Search process
If you want to find the data item 29, first load the disk block 1 from the disk into the memory. At this time, an IO occurs. Use the binary search in the memory to determine that the 29 is between 17 and 35, and lock the P2 pointer of this judgment 1, Memory time is very short (compared with disk IO), it can be ignored. Load the disk of disk block 3you into memory through the disk address of P2 pointer of disk block 1, and the second IO occurs. 29 is between 26 and 30. Lock the P2 pointer of disk block 3, load disk block 8 into memory through the pointer, and the third IO occurs. At the same time, do a binary search in memory, find 29, and end the query. There are three IOS in total.
The real situation is that the three-tier b + tree can represent millions of data. If millions of data lookup only needs three IO, the performance improvement will be huge. If there is no index and each data item needs one IO, a total of millions of IO are required. Obviously, the cost is very, very high.
7. Which situations require index creation
-
The primary key automatically creates a unique index
-
Fields frequently used as query criteria should be indexed
-
The fields associated with other tables in the query are indexed by foreign key relationships
-
Single value / combined index selection problem. (tend to create composite indexes under high parallel distribution)
-
For the sorted fields in the query, if the sorted fields are accessed through the index, the sorting speed will be greatly improved
-
Statistics or grouping fields in query (group by is also related to index)
8. Under what circumstances do not create an index
-
Tables with too few records.
-
Frequently added, delete d and modified tables. (the index improves the query speed, but reduces the speed of updating the table, such as insert ing, updating and deleting the table, because MySQL needs to save not only the data but also the index file when updating the table.)
-
Frequently updated fields are not suitable for index creation.
-
No index is created for fields that are not used in the Where condition.
-
The table fields with repeated data and evenly distributed data should be indexed by the data columns most frequently queried and sorted. Note that if each data column contains a lot of duplicate content, indexing it will not have much practical effect.
If A table has 100000 rows of records, A field A has only true and false values, and the distribution probability of each value is about 50%, indexing field A generally will not improve the query speed of the database. Index selectivity refers to the ratio of the number of different values in the index column to the number of records in the table. If there are 2000 records in A table and the table index column has 1980 different values, the selectivity of the index is 1980 / 2000 = 0.99. The closer the selectivity of an index is to 1, the higher the efficiency of the index.
Selectivity of index = number of different data in index column / total number of data in index column
4, Performance analysis
1. MySQL Query Optimizer
The optimizer module in MySQL is specifically responsible for optimizing the SELECT statement
Main function: through calculating and analyzing the statistical information collected in the system, provide the Query requested by the client with the execution plan it considers the best (it considers the best data retrieval method, but it is not necessarily the best one considered by the DBA, which is the most time-consuming part)
When the client requests a Query like mysql, the command parser module completes the request classification, distinguishes it from SELECT and forwards it to MySQL Query Optimizer. MySQL Query Optimizer will first optimize the whole Query, deal with the budget of some constant expressions and directly convert it into constant values. And simplify and transform the Query conditions in Query, such as removing some useless or obvious conditions, structural adjustment, etc. Then analyze the Hint information (if any) in the Query to see whether the Hint information can completely determine the execution plan of the Query. If there is no Hint or the Hint information is not enough to completely determine the execution plan, the statistical information of the objects involved will be read, the corresponding calculation and analysis will be written according to the Query, and then the final execution plan will be obtained.
2. Common MySQL bottlenecks
CPU: CPU re saturation usually occurs when data is loaded into memory or read from disk
IO: the disk IO bottleneck occurs when the loaded data is much larger than the memory capacity
Performance bottleneck of server hardware: top free iostat and vmstat to view the performance status of the system
3. explain
3.1 what is it
EXPLAIN: the SQL execution plan. Use the EXPLAIN keyword to simulate the optimizer to execute SQL query statements, so as to know how MySQL handles your SQL statements. Analyze the performance bottleneck of your query statement or table structure
3.2 what can I do
- Read order id of the table
- Operation type of data read operation select_type
- Those indexes can use possible_keys
- Which indexes are actually used
- References between tables ref
- How many rows per table are queried by the optimizer rows
3.3 how to use
Explain + SQL statement
Information contained in the execution plan

3.4 explanation of each field
3.4.1 id
The sequence number of the select query, including a set of numbers, indicating the order in which the select clause or operation table is executed in the query
Value situation
- The id is the same, and the execution order is from top to bottom
- The id is different. If it is a sub query, the id sequence number will increase. The larger the id value, the higher the priority, and the earlier it will be executed
- The IDs are the same but different and exist at the same time. The priority is always the highest if the id is large. When the IDs are equal, they are executed in sequence
3.4.2 select_type
The type of data query is mainly used to distinguish complex queries such as general query, joint query and sub query.
-
SIMPLE: a SIMPLE SELECT query that does not contain subqueries or unions.
-
PRIMARY: if the query contains any complex sub parts, the outermost query is marked as PRIMARY.
-
SUBQUERY: contains a SUBQUERY * * in the * * SELECT or WHERE clause.
-
DERIVED: the subqueries * * contained in the * * FROM clause are marked as DERIVED. MySQL will recursively execute these subqueries and put the results in the temporary table.
-
UNION: if the second SELECT appears after UNION, it is marked as UNION; If UNION is included in subquery of the FROM clause, outer SELECT is marked as DERIVED.
-
UNION RESULT: SELECT to get the result from the UNION table.
3.4.3 table
The data displayed in this row is about that table
3.4.4 type
Access type arrangement
The order from the best to the worst is: system > const > Eq_ ref>ref>range>index>ALL.
-
System: the table has only one row of records (equal to the system table). This is a special case of const type. It usually does not appear. This can be ignored.
-
const: indicates that the index can be found once. const is used to compare the primary key or unique index. Because only one row of data is matched, it is very fast. If the primary key is placed in where, MySQL can convert the query into a constant
-
eq_ref: unique index scanning. For each index key, only one record in the table matches it, which is common in primary key or unique index scanning. This is the best join type besides the system and const types.
-
ref: non unique index scan, which returns all rows matching a value in this table and the associated table, and multiple records are found.
-
Range: only rows in a given range are retrieved. Generally, queries such as BETWEEN, < >, in, etc. appear in the WHERE statement. This range scan index is better than full table scan because it only needs to start at one point of the index tree and end at another point without scanning all the indexes.
-
Index: full index scan. The difference between index and ALL is * * index type only traverses the index tree * *.
That is, although both * * ALL and index read the whole table, index is read from the index and ALL * * is read from the disk.
- ALL: Full Table Scan, without index, Full Table Scan.
Note: Generally speaking, it is necessary to ensure that the query reaches at least range level, preferably ref
3.4.5 possible_keys
Displays one or more indexes that may be applied to this table.
If there is an index on the field involved in the query, the index will be listed, but it may not be actually used by the query.
3.4.6 key
The index actually used. If it is NULL, the index is not built or used, that is, the index is invalid.
If an overlay index is used in a query, the index overlaps with the select field of the query
3.4.7 key_len
Represents the number of bytes used in the index. This column can be used to calculate the length of the index used in the query.
key_ The value displayed by Len is the maximum possible length of the index field, not the actual length, that is, key_len is calculated according to the table definition, not retrieved from the table. The shorter the length, the better without loss of accuracy.
3.4.8 ref
Displays which column of the index is used, if possible, as a constant. Which columns or constants are used to find values on indexed columns.

3.4.9 rows
According to table statistics and index selection, roughly estimate the number of rows to read to find the required records.
3.4.10 Extra
Contains additional information that is not suitable for display in other columns but is important.
- Using filesort
Note MySQL will use an external index to sort the data instead of reading according to the index order in the table.
The sort operation that cannot be completed by index in MySQL is called "intra file sort".
- Using temporary
Temporary tables are used to save intermediate results, and MySQL uses temporary tables when sorting query results. It is commonly used in sorting order by and grouping query group by. The temporary meter has a great loss on the system performance.
- Using index
It indicates that the overlay index is used in the corresponding SELECT operation to avoid accessing the data rows of the table. The efficiency is good!
If * * Using where appears at the same time, it means that the index is used to search the index key value * *;
If Using where does not appear at the same time, it indicates that the index is used to read data rather than perform a lookup action.
-
Using where: indicates WHERE filtering is used.
-
Using join buffer: connection cache is used.
-
impossible where: the value of the WHERE clause is always false and cannot be used to obtain any tuples.
-
select tables optimized away: if there is no group by clause, the MIN/MAX operation based on index optimization or the COUNT(*) operation based on MyISAM storage engine optimization do not have to wait until the execution stage for calculation. The optimization is completed at the stage of query execution plan generation
-
Distinct: optimize the distinct operation and stop finding the same value after finding the first matching tuple
3.5 examples
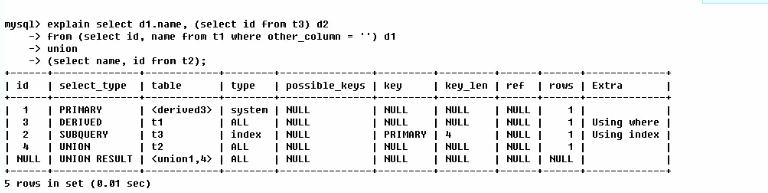

5, Index optimization
5.1 single table index analysis
CREATE TABLE IF NOT EXISTS `article`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `author_id` INT (10) UNSIGNED NOT NULL, `category_id` INT(10) UNSIGNED NOT NULL , `views` INT(10) UNSIGNED NOT NULL , `comments` INT(10) UNSIGNED NOT NULL, `title` VARBINARY(255) NOT NULL, `content` TEXT NOT NULL ); INSERT INTO `article`(`author_id`,`category_id` ,`views` ,`comments` ,`title` ,`content` )VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (3,3,3,3,'3','3'), (1, 1, 3, 3, '3', '3'), (1, 1, 4, 4, '4', '4'); SELECT * FROM ARTICLE;
Case: query category_ When ID is 1 and comments is greater than 1, the articles with the most views_ id.
- Write sql
SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
- View the SQL execution plan.
explain SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;

You can see from the table that the index is not used in the current sql, and the access type is full table search. To improve performance, try adding indexes
- For the field category used in where_ ID, comments, views Add Index
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);
When reviewing the execution plan, it is found that the index is used, but the access type is retrieval within the range, and there is still sorting within the using filesort file

conclusion
- type becomes range, which is tolerable, but using filesort in extra is still unacceptable.
- Why is indexing useless?
- Because according to the working principle of Btree index. Sort category first_ ID, and then encounter the same category_id is used to sort comments. If the same comments are encountered, it is used to sort views. When the comments field is in the middle position in the joint index, MySQL cannot use the index to retrieve the following views because the condition of comments > 1 is a range value (so-called range), that is, the index behind the range type query field is invalid
- Modify index
We delete the index of the comments field that invalidates the index
drop index idx_article_ccv on article; /* Create index idx_article_cv */ CREATE INDEX idx_article_cv ON article(category_id,views);

You can see that the type is changed to ref, and there is no using filesort
5.2 index analysis of two tables
test case
CREATE TABLE IF NOT EXISTS `class`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); CREATE TABLE IF NOT EXISTS `book`( `bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
SQL execution plan for two table join query
1. The execution plan of SQL without creating an index.
explain select * from book left join class on book.card = class.card;

You can see that the type on both tables is all, and instead of using an index, you perform a full table search
- Try to add an index and build an index in the left table
alter table book add index idx_c(card);
Query again

We can see that the type of book is changed to index, but the number of search lines is still 20, which has not been greatly optimized.
- Delete the left table index and create an index on the right table
drop index idx_c on book;alter table class add index idx_c(card);
Test again

You can see that the class field type is changed to ref and the number of search rows is also changed to 1, which improves the performance.
conclusion
- For LEFT JOIN, the LEFT JOIN condition is used to determine how to search rows from the right table. There must be rows on the left. So the right side is our key point. We must establish an index.
- For right links, on the contrary, the RIGHT JOIN condition is used to determine how to search rows from the left table. There must be rows on the left. So on the left is our key point. We must establish an index.
5.3 three table index analysis
test data
CREATE TABLE IF NOT EXISTS `phone`(`phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL)ENGINE = INNODB;INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
1. View the SQL execution plan without any index.
explain select * from class left join book on class.card = book.card left join phone on book.card = phone.card;

- According to the experience of the scale, the left connection adds an index on the right, and the indexes of book and phone are added
create index idx_c on book(card);create index idx_c on phone(card);
Test again, you can find a lot of optimization

Therefore, it is best to set the index in the field that needs to be queried frequently
Join statement optimization conclusion
-
Minimize the total number of NestedLoop loops in the join statement; "Always drive large result sets with small result sets"
-
Optimize the inner loop of NestedLoop first
-
Ensure that the join condition field on the driven table in the join statement has been indexed
-
When it is impossible to ensure that the join condition field of the driven table is indexed and the memory resources are sufficient, do not be too stingy with the setting of JoinBuffer
6, Index failure
test data
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'full name',
`age` INT NOT NULL DEFAULT 0 COMMENT'Age',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'position',`
add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'Entry time'
)CHARSET utf8 COMMENT'Employee record form';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`)
6.1 index failure
- Full value matches my favorite.
- Best left prefix rule—— If multiple columns are indexed, the leftmost prefix rule should be followed, which means that the query starts from the leftmost front row of the index and does not skip the columns in the index
- Failure to do any operation (calculation, function, (automatic or manual) type conversion) on the index column will lead to index failure and turn to full table scanning.
- All fields to the right of the range condition in the index will be invalidated.
- Try to use the overlay index (only the query accessing the index, and the index column is consistent with the query column) and reduce the SELECT *.
- MySQL is in use= Or < >, the failure to use the index will lead to full table scanning.
- is null and is not null cannot use indexes.
- like starts with a wildcard.% abc if the index fails, it will become a full table scan (if you use an overlay index, it will not be a full table scan).
- The string index is invalid without single quotation marks.
- Use less or, which will invalidate the index when using it to connect.
6.1. 1 full value matching
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';

6.1. 2 best left prefix rule
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo'; EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18; EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager'; EXPLAIN SELECT * FROM `staffs` WHERE `age` = 18 AND `pos` = 'manager'; EXPLAIN SELECT * FROM `staffs` WHERE `pos` = 'manager'; EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `pos` = 'manager';
test result
The first three indexes are valid

The last three indexes, the first two indexes are invalid, and the last index is partially invalid
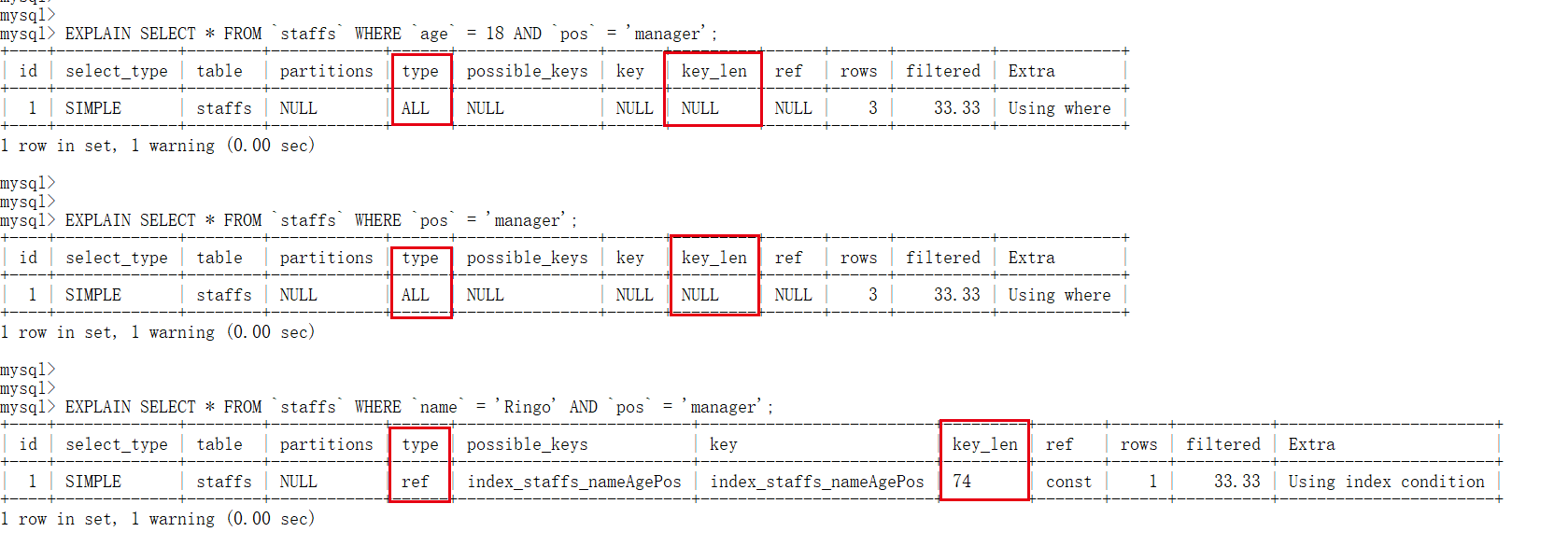
Pithy formula: the leading brother can't die, and the middle brother can't break.
6.1. 3 do not calculate on index column
#Now to query the records with 'name' ='july ', there are two ways to query! # 1. Directly use the method of field = value to calculate explain SELECT * FROM `staffs` WHERE `name` = 'July'; # 2. Use MySQL built-in functions explain SELECT * FROM `staffs` WHERE LEFT(`name`, 4) = 'July';
test result

You can see that the index using the built-in function will become invalid and become a full table scan
Pithy formula: do not calculate on index column.
6.1. Full failure after 4 ranges
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager'; EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Zhang San' AND `age` > 18 AND `pos` = 'dev';
test result
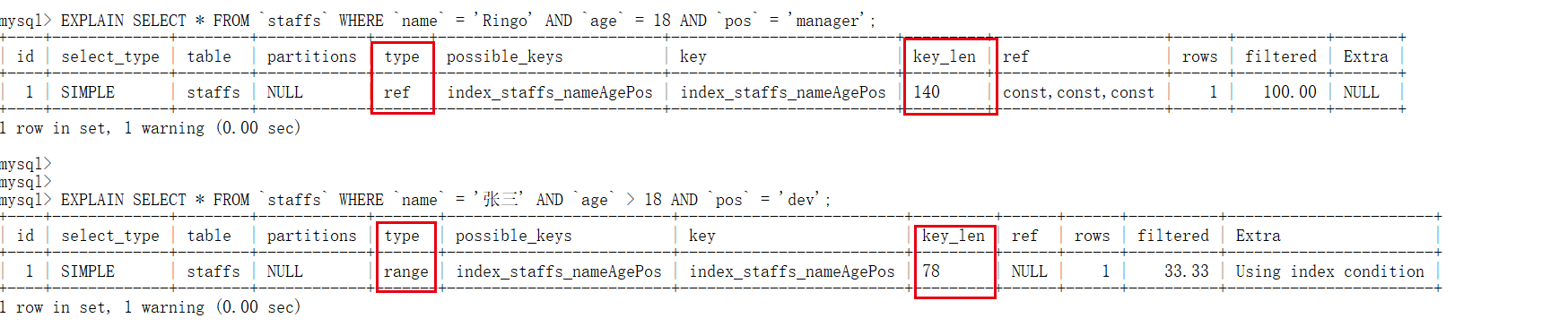
As you can see, the index behind the range will fail. In this example, pos will fail
Pithy formula: all failure after range.
6.1. 5. Try to use the overlay index
/* No overlay index is used */ EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager'; /* Overlay index is used */ EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
test result
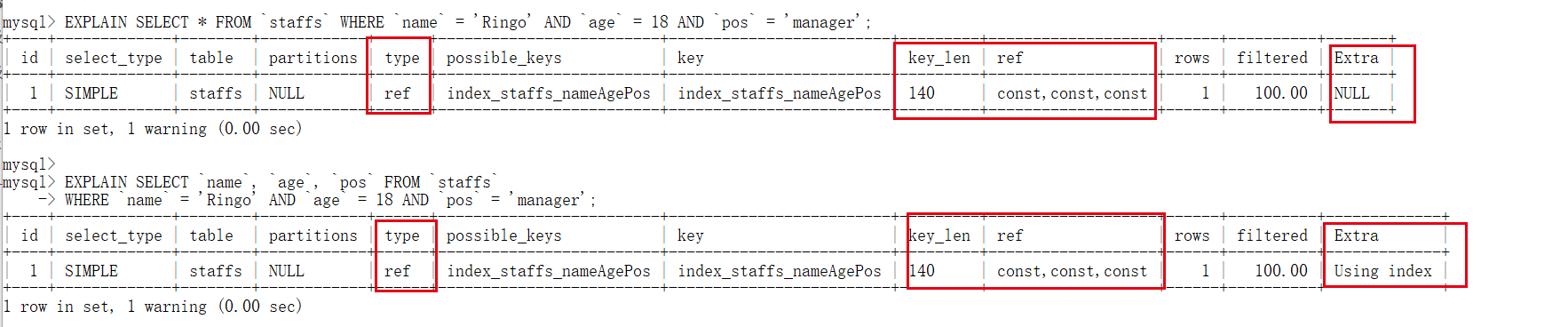
You can see that using an overlay index will increase the use index
Pithy formula: query must not *.
6.1. 6. It sometimes fails
/* Overwrite index will be used */ EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` != 'Ringo'; /* Index invalidation full table scan */ EXPLAIN SELECT * FROM `staffs` WHERE `name` != 'Ringo';
test result

6.1.7 is null will invalidate the index
explain select * from staffs where name is null; explain select * from staffs where name is not null;

6.1.8 like percent plus right
/* Index invalidation full table scan */ EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%July%'; /* Index invalidation full table scan */ EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%July'; /* Use index range query */ EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE 'July%';
test result
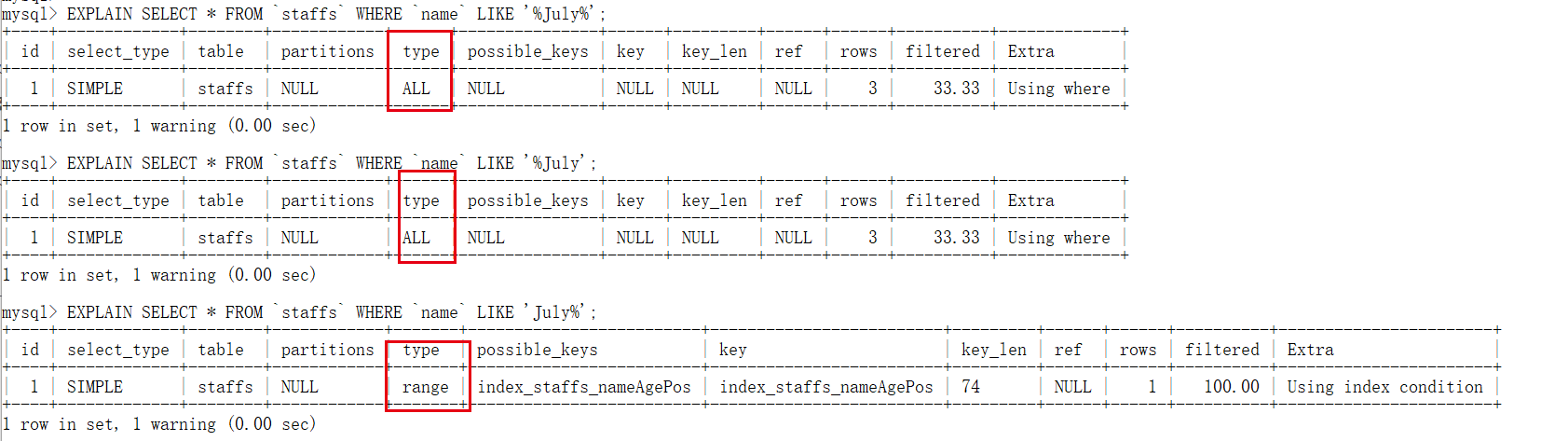
Formula: like percentage plus right.
If you must use the like% string% and ensure that the index does not become invalid, use the overwrite index to write SQL.
CREATE TABLE `tbl_user`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age`INT(11) DEFAULT NULL,
`email` VARCHAR(20) DEFAULT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('1aa1',21,'a@163.com');
INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('2bb2',23,'b@163.com');
INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('3cc3',24,'c@163.com');
INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('4dd4',26,'d@163.com');
CREATE INDEX idx_user_nameAge on tbl_user(Name,age);
Effective EXPLAIN SELECT ID FROM TBL_USER WHERE NAME LIKE '%aa%'; EXPLAIN SELECT NAME FROM TBL_USER WHERE NAME LIKE '%aa%'; EXPLAIN SELECT AGE FROM TBL_USER WHERE NAME LIKE '%aa%'; Effective EXPLAIN SELECT ID,NAME FROM TBL_USER WHERE NAME LIKE '%aa%'; EXPLAIN SELECT ID,NAME,AGE FROM TBL_USER WHERE NAME LIKE '%aa%'; EXPLAIN SELECT NAME,AGE FROM TBL_USER WHERE NAME LIKE '%aa%'; invalid EXPLAIN SELECT * FROM TBL_USER WHERE NAME LIKE '%aa%'; EXPLAIN SELECT ID,NAME,AGE,EMAIL FROM TBL_USER WHERE NAME LIKE '%aa%';
test result

Pithy formula: cover index and protect both sides
6.1. 9 characters should be enclosed in single quotation marks
EXPLAIN SELECT * FROM `staffs` WHERE `name` = '2000'; /* Index invalidation full table scan */ EXPLAIN SELECT * FROM `staffs` WHERE `name` = 2000;
test result

Pithy formula: characters should be enclosed in single quotation marks.
6.1.10 or sometimes fails
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'July' or name = 'z3';
test result

Little practice
Suppose index(a,b,c)
| Where statement | Is the index used |
|---|---|
| where a = 3 | Y. Use to a |
| where a = 3 and b = 5 | Y. Use a, b |
| where a = 3 and b = 5 | Y. Use a, b, c |
| Where b = 3 or where b = 3 and c = 4 or where c = 4 | N. The a field is not used |
| where a = 3 and c = 5 | Use a, but not c, because b is broken |
| where a = 3 and b > 4 and c = 5 | Use a, b, but not c, because c is after the range |
| where a = 3 and b like 'kk%' and c = 4 | Y. a, b, c are used |
| where a = 3 and b like '%kk' and c = 4 | Only a |
| where a = 3 and b like '%kk%' and c = 4 | Only a |
| where a = 3 and b like 'k%kk%' and c = 4 | Y. a, b, c are used |
6.2 analysis of interview questions
test data
create table test03(
id int primary key not null auto_increment,
c1 char(10),
c2 char(10),
c3 char(10),
c4 char(10),
c5 char(10)
);
insert into test03(c1,c2,c3,c4,c5) values ('a1','a2','a3','a4','a5');
insert into test03(c1,c2,c3,c4,c5) values ('b1','b2','b3','b4','b5');
insert into test03(c1,c2,c3,c4,c5) values ('c1','c2','c3','c4','c5');
insert into test03(c1,c2,c3,c4,c5) values ('d1','d2','d3','d4','d5');
insert into test03(c1,c2,c3,c4,c5) values ('e1','e2','e3','e4','e5');
create index idx_test03_c1234 on test03(c1,c2,c3,c4);
1
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` = 'a3' AND `c4` = 'a4';

From the results, it can be seen that the indexable c1, c2, c3 and c4 all belong to full value matching
2
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' AND `c3` = 'a3';

You can see that although we changed the order of the where field, it still uses all the indexes c1, c2, c3 and c4. Because the query optimizer of MySQL will optimize the order of SQL statements
Conclusion it's best to use the index as it is created, and use it in order to avoid allowing MySQL to translate it again
3
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` > 'a3' AND `c4` = 'a4';

You can see that the index c1 c2 c3 field is used, the c4 field is invalid, and all fields after the range are invalid
4
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` > 'a4' AND `c3` = 'a3';

You can see that the index c1 c2 c3 c4 full field is used, because the MySQL query optimizer will optimize the order of SQL statements
5
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' ORDER BY `c3`;

The index c1, c2 and c3 fields are used. The c1 and c2 fields are used for searching, and the c3 field is used for sorting, but the key is not counted_ In len, c4 field is invalid
6
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c3`;

The index c1, c2 and c3 fields are used. The c1 and c2 fields are used for searching, and the c3 field is used for sorting, but the key is not counted_ In len
7
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c4`;

The index c1 and c2 fields are used. c4 is invalid. The c1 and c2 fields are used for searching. The sorting of c4 fields produces Using filesort, indicating that the sorting does not use c4 fields
8
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c2`, `c3`;

Three fields of index c1, c2 and c3 are used. c1 is used for searching and c2 and c3 are used for sorting
9
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c3`, `c2`;

A field c1 is used for searching. The indexes of c3 and c2 are invalid, resulting in Using filesort
10
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY c2, c3;

Three fields C1, C2 and C3 are used. C1, C2 are used for searching, C2 and C3 are used for sorting
11
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c2, c3;

Three fields C1, C2 and C3 are used. C1, C2 are used for searching, C2 and C3 are used for sorting
12
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c3, c2;

The three fields C1, c2 and C3 are used. C1, c2 and C3 are used for searching, c2 and C3 are used for sorting. Using filesort is not generated because the field c2 has been determined to be 'a2', which is a constant. Go to ORDER BY c3,c2. At this time, c2 does not need to be sorted! Therefore, using filesort and (9) are not generated for comparative learning
13
EXPLAIN SELECT c1,c2,c3 FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c2`,`c3`;

Three fields c1, C2 and C3 are used. c1 is used for searching, C2 and C3 are used for sorting, and c4 is invalid
14
EXPLAIN SELECT c1,c2,c3 FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c3`,`c2`;

Using the c1 field, c4 fails, c2 and c3 fail to sort, resulting in Using temporary
**The current version (after 5.7) of group by cannot use select***
1: For the select statement using group by, the column found must be the column declared after group by, or the column in the aggregate function has such a database table
2: When group by id (id is the primary key), there is no problem with select, including aggregation functions
3: When group by role (non primary key), select can only be aggregate function and role (field of group by), otherwise an error is reported
conclusion
First, it depends on whether the field is fixed value, range or sorting. Generally, order by gives a range. group by basically needs to be sorted, and temporary tables will be generated.
7, General recommendations
-
For single valued indexes, try to select indexes with better filtering for the current query.
-
When selecting a composite index, the fields with the best filtering performance in the current query are in the index field order. The higher the position, the better.
-
When selecting a composite index, try to select an index that can contain more fields in the where clause of the current query.
-
Try to select the appropriate index by analyzing the statistical information and adjusting the writing method of query.
Pithy formula
Full value matching is my favorite, and the leftmost prefix should be observed;
The leading brother cannot die, and the middle brother cannot break;
The index column is less calculated, and the range is invalid;
Like 100% is written to the right, and the coverage index does not write stars;
Unequal null values and or, index invalidation should be used less;
VAR quotation marks cannot be lost, and SQL advanced is not difficult!