5. SQL optimization
1.1 mass insert data
Environmental preparation:
CREATE TABLE `tb_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(45) NOT NULL, `password` varchar(96) NOT NULL, `name` varchar(45) NOT NULL, `birthday` datetime DEFAULT NULL, `sex` char(1) DEFAULT NULL, `email` varchar(45) DEFAULT NULL, `phone` varchar(45) DEFAULT NULL, `qq` varchar(32) DEFAULT NULL, `status` varchar(32) NOT NULL COMMENT 'User status', `create_time` datetime NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
When using the load command to import data, appropriate settings can improve the efficiency of import.
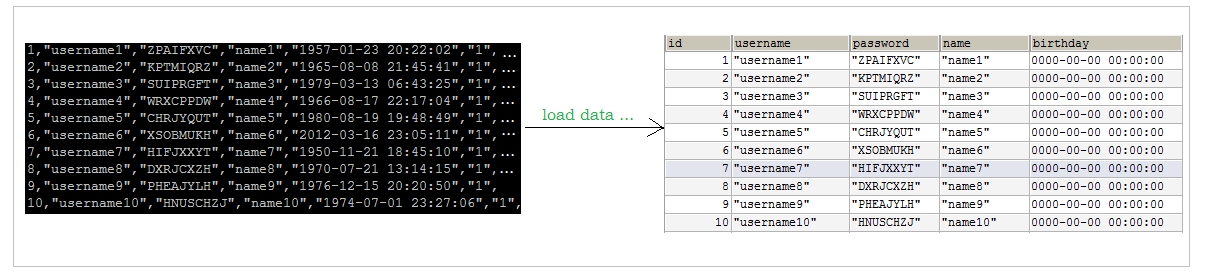
For InnoDB type tables, there are several ways to improve the import efficiency:
1) Primary key sequential insertion
Because InnoDB tables are saved in the order of primary keys, arranging the imported data in the order of primary keys can effectively improve the efficiency of importing data. If the InnoDB table does not have a primary key, the system will automatically create an internal column as the primary key by default. Therefore, if you can create a primary key for the table, you can use this to improve the efficiency of importing data.
Introduction to script file:
sql1. Log - > ordered primary key
sql2. Log - > primary key out of order
Insert ID sequence data:
load data local infile '/root/sql1.log' into table `tb_user` fields terminated by ',' lines terminated by '\n';

Insert ID unordered data:
load data local infile '/root/sql2.log' into table `tb_user` fields terminated by ',' lines terminated by '\n';

Comparison shows that it is faster to import data orderly
2) Turn off uniqueness check
Execute set unique before importing data_ Checks = 0, turn off uniqueness verification, and execute set unique after import_ Checks = 1, restore uniqueness verification, which can improve the efficiency of import.
3) Manually commit transactions
If the application uses automatic submission, it is recommended to execute SET AUTOCOMMIT=0 before import, turn off automatic submission, and then execute SET AUTOCOMMIT=1 after import to turn on automatic submission, which can also improve the efficiency of import.
2.2 optimizing insert statements
When insert ing data, the following optimization schemes can be considered.
-
If you need to insert many rows of data into a table at the same time, you should try to use the insert statement of multiple value tables. This method will greatly reduce the consumption of connection and closing between the client and the database. This makes it faster than a single insert statement executed separately.
Example, the original method is:
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry');
The optimized scheme is:
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
-
Insert data in a transaction.
start transaction; insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); commit;
-
Orderly data insertion
insert into tb_test values(4,'Tim'); insert into tb_test values(1,'Tom'); insert into tb_test values(3,'Jerry'); insert into tb_test values(5,'Rose'); insert into tb_test values(2,'Cat');
After optimization
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); insert into tb_test values(4,'Tim'); insert into tb_test values(5,'Rose');
1.3 optimizing the order by statement
1.3.1 environmental preparation
CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL, `age` int(3) NOT NULL, `salary` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300'); insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800'); insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200'); insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300'); insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700'); insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400'); insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100'); insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900'); insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500'); create index idx_emp_age_salary on emp(age,salary);
1.3.2 two sorting methods
1). The first is to sort the returned data, that is, filesort sorting. All sorts that do not directly return the sorting results through the index are called filesort sorting.

2). The second method directly returns ordered data through sequential scanning of ordered index. This is using index, which does not need additional sorting and has high operation efficiency.

Multi field sorting

After understanding the sorting method of MySQL, the optimization goal is clear: minimize additional sorting and directly return ordered data through index. The where condition uses the same index as order by, the order of order by is the same as the index order, and the fields of order by are in ascending or descending order. Otherwise, additional operations must be required, and FileSort will appear.
1.3.3 optimization of filesort
Creating an appropriate index can reduce the occurrence of Filesort, but in some cases, conditional restrictions can not make Filesort disappear, so it is necessary to speed up the sorting operation of Filesort. For Filesort, MySQL has two sorting algorithms:
1) Twice scanning algorithm: MySQL4 Before 1, use this method to sort. First, get the sorting field and row pointer information according to the conditions, and then sort in the sort buffer in the sorting area. If the sort buffer is not enough, the sorting results are stored in the temporary table. After sorting, read the records back to the table according to the row pointer. This operation may lead to a large number of random I/O operations.
2) One scan algorithm: take out all the fields that meet the conditions at one time, and then sort them in the sort buffer of the sorting area, and then directly output the result set. The memory cost of sorting is large, but the sorting efficiency is higher than the two scan algorithm.
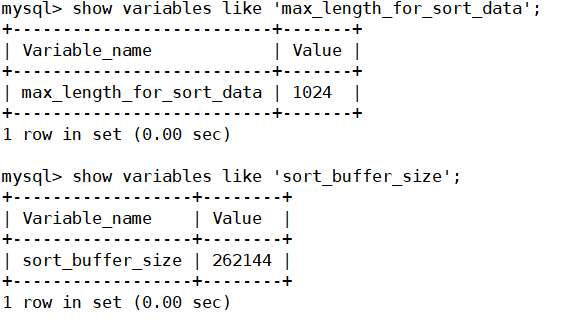
MySQL compares the system variable max_ length_ for_ sort_ The size of the data and the total size of the fields taken out by the Query statement to determine whether the sorting algorithm is, if max_ length_ for_ sort_ If the data is larger, use the second optimized algorithm; Otherwise, use the first one.
Sort can be improved appropriately_ buffer_ Size and max_length_for_sort_data system variable to increase the size of the sorting area and improve the efficiency of sorting.
1.4 optimizing group by statements
In fact, GROUP BY also performs sorting operations, and compared with ORDER BY, GROUP BY mainly only has more grouping operations after sorting. Of course, if other aggregate functions are used in grouping, some aggregate function calculations are required. Therefore, in the implementation of GROUP BY, the index can also be used like ORDER BY.
If the query contains group by but the user wants to avoid the consumption of sorting results, order by null can be executed to prohibit sorting. As follows:
drop index idx_emp_age_salary on emp; explain select age,count(*) from emp group by age;

After optimization
explain select age,count(*) from emp group by age order by null;

I just want to group, not sort
As can be seen from the above example, the first SQL statement needs "Filesort", while the second SQL statement does not need "Filesort" because order by null. As mentioned above, Filesort is often very time-consuming.
Create indexes to further optimize:
create index idx_emp_age_salary on emp(age,salary);

1.5 optimizing nested queries
Mysql4. After version 1, SQL subqueries are supported. This technique can use the SELECT statement to create a single column query result, and then use the result as a filter condition in another query. Using subquery can complete many SQL operations that logically require multiple steps at one time. At the same time, it can avoid transaction or table locking, and it is easy to write. However, in some cases, subqueries can be replaced by more efficient joins.
For example, find all user information with roles:
explain select * from t_user where id in (select user_id from user_role );
The implementation plan is:

After optimization:
explain select * from t_user u , user_role ur where u.id = ur.user_id;

Join queries are more efficient because MySQL does not need to create temporary tables in memory to complete this logically two-step query.
1.6 optimized OR conditions
For query clauses containing OR, if you want to use indexes, indexes must be used for each condition column between ors, and composite indexes cannot be used; If there is no index, you should consider increasing the index.
Get all indexes in emp table:

Example:
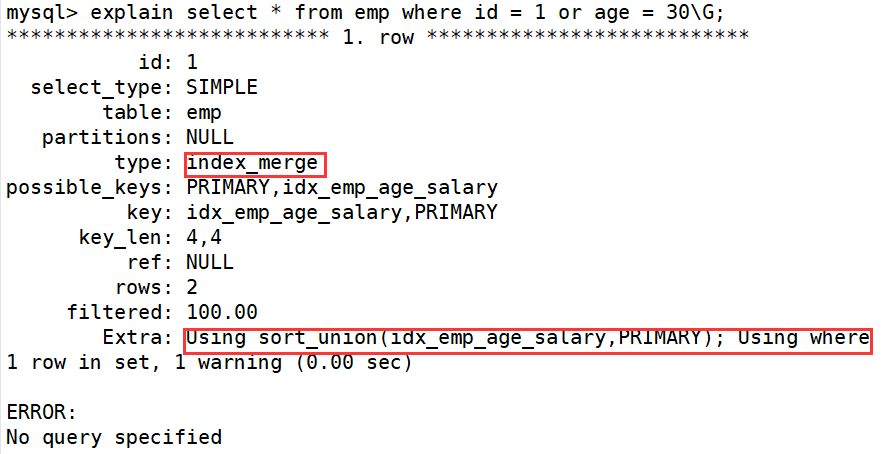
explain select * from emp where id = 1 or age = 30;
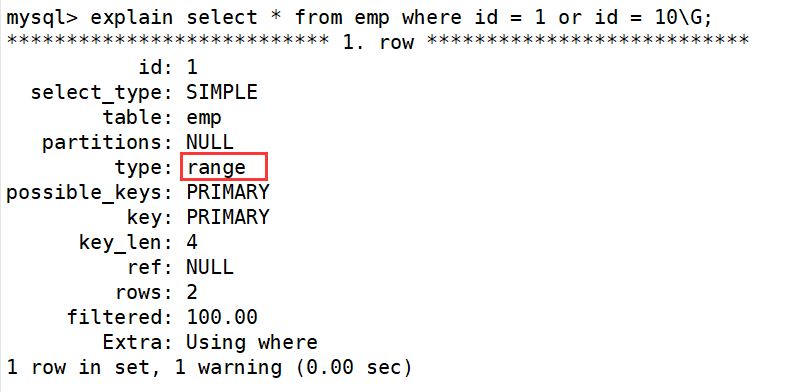
It is recommended to replace or with union:

Let's compare the important indicators and find that the main differences are type and ref
Type shows the access type, which is an important indicator. The result values are as follows from good to bad:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
The type value of the UNION statement is ref and the type value of the OR statement is range. You can see that this is an obvious gap
The ref value of the UNION statement is const, and the type value of the OR statement is null. Const indicates that it is a constant value reference, which is very fast
The difference between the two shows that UNION is better than OR.
1.7 optimize paging query
In general paging queries, the performance can be improved by creating an overlay index. A common and troublesome problem is the limit 2000000,10. At this time, MySQL needs to sort the top 2000010 records, only return 2000000 - 2000010 records, discard other records, and the cost of querying and sorting is very high.
5.7.1 optimization idea I
Complete sorting and paging operations on the index, and finally associate other column contents required by the original table query according to the primary key.
5.7.2 optimization idea II
This scheme is applicable to tables with self incremented primary keys. You can convert the Limit query into a query at a certain location.
5.8 tips for using SQL
SQL prompt is an important means to optimize the database. In short, it is to add some artificial prompts to the SQL statement to achieve the purpose of optimizing the operation.
5.8.1 USE INDEX
After the table name in the query statement, add use index to provide the index list you want Mysql to refer to, so that MySQL can no longer consider other available indexes.
create index idx_seller_name on tb_seller(name);
5.8.2 IGNORE INDEX
If users simply want MySQL to ignore one or more indexes, they can use ignore index as hint.
explain select * from tb_seller ignore index(idx_seller_name) where name = 'Xiaomi technology';
5.8.3 FORCE INDEX
To force MySQL to use a specific index, use force index as hint in the query.
create index idx_seller_address on tb_seller(address);