Course notes Day28
-
Database paradigm
-
Database transaction
-
Database view
-
Backup and restore
Chapter I database paradigm
Section 01 basic theory
What is the database paradigm?
When designing a table, we need to follow some database design specifications.
Why use paradigms?
In order to reduce the data redundancy in the database. (reduce data duplication in the same table)
Classification of data paradigms
(1) First paradigm 1 NF (2) Second paradigm 2 NF (3) Third paradigm 3 NF (4) Barcock paradigm BCNF (5) Fourth paradigm 4 NF (6) Fifth paradigm 5 NF interpretative statement: If you want to meet the second paradigm, you must first meet the first paradigm. If you want to meet the third paradigm, you must first meet the second paradigm.
Common table structure
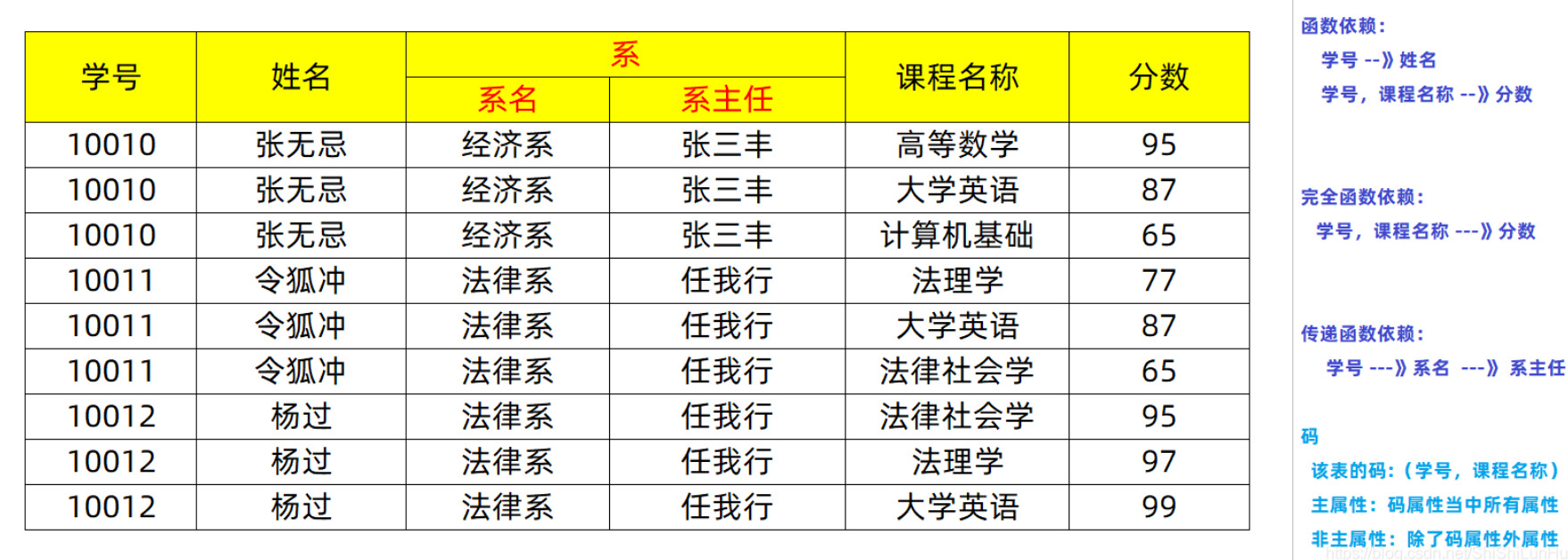
Description of several professional words
1. Functional dependency: Through the current column, you can find and determine the data values of other columns. Divided into: Complete functional dependency and transfer functional dependency. Complete functional dependency: Scores can only be determined through (student number and course name). Transfer function dependency: Dean of Department: You need to determine the Department name through the student number first, and determine the Dean through the Department name. 2. Primary and non primary attributes: Main attribute: Through which columns, you can completely determine the information in the table. (e.g: The column in the main attribute of student number and course name) is also called code Non primary attribute: Columns other than codes
Section 02 first paradigm
design sketch
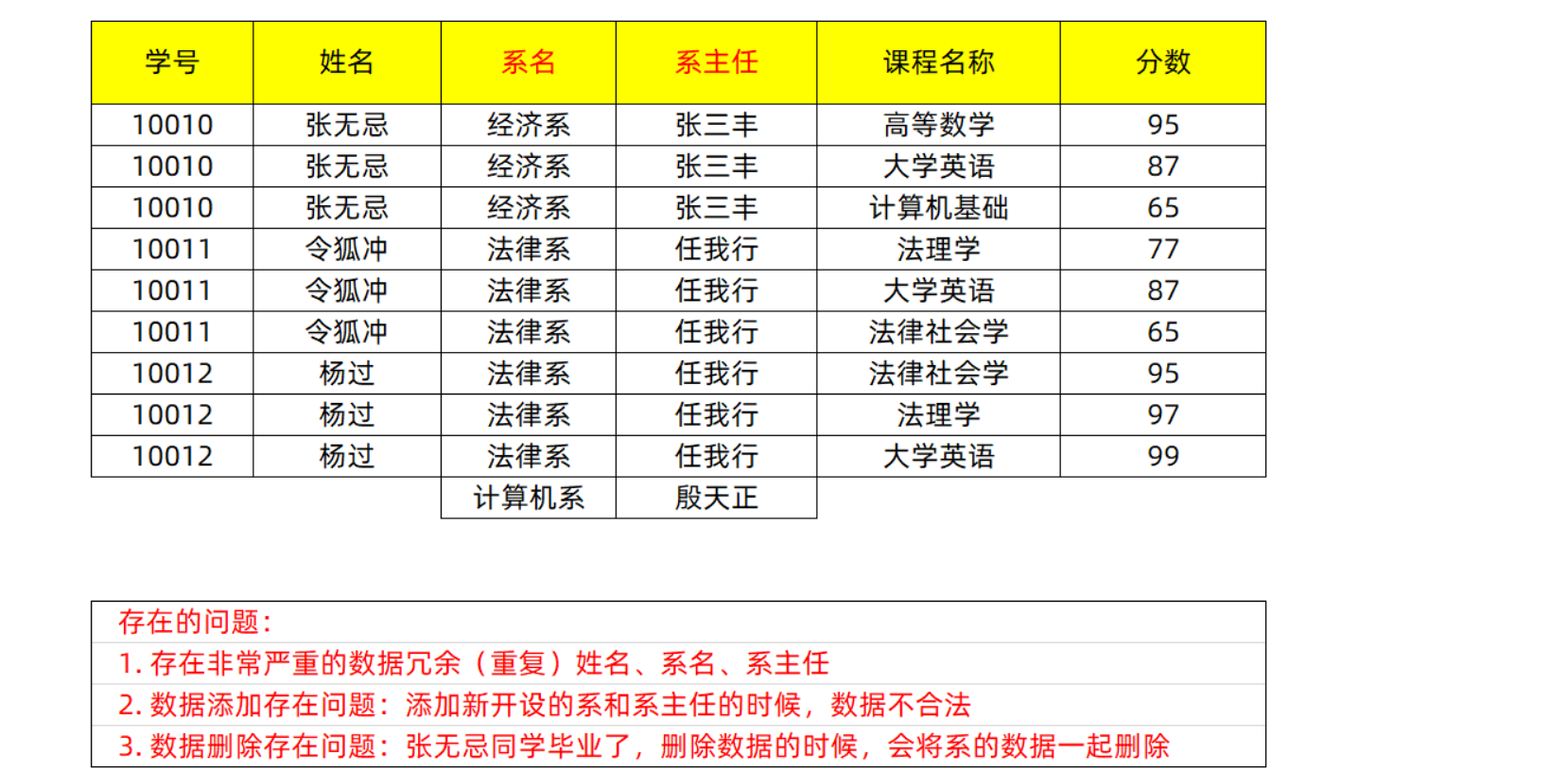
explain
In the first paradigm, there is no merge item. The previous department name and department head have merged departments
Section 03 second paradigm
design sketch
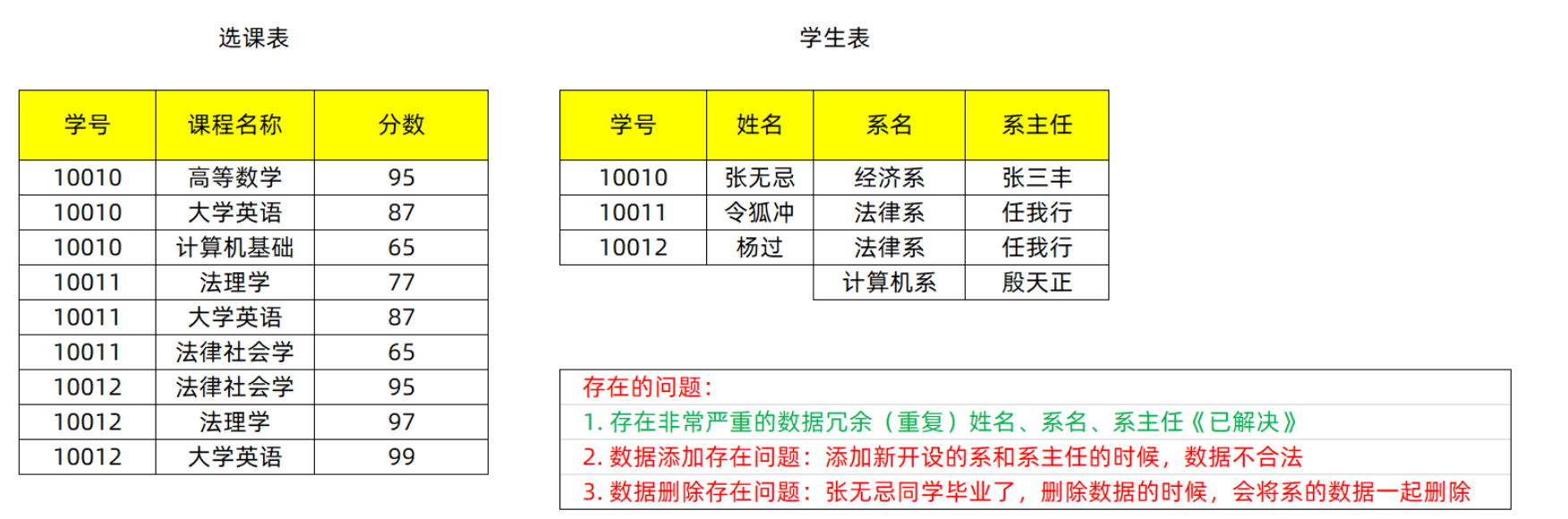
explain
Split table: split duplicate data and redundant data to form a new multi table structure Problem solving: the problem of duplicate data and redundant data is solved. Problem found: add or delete data, the data is illegal
Section 04 third paradigm
design sketch
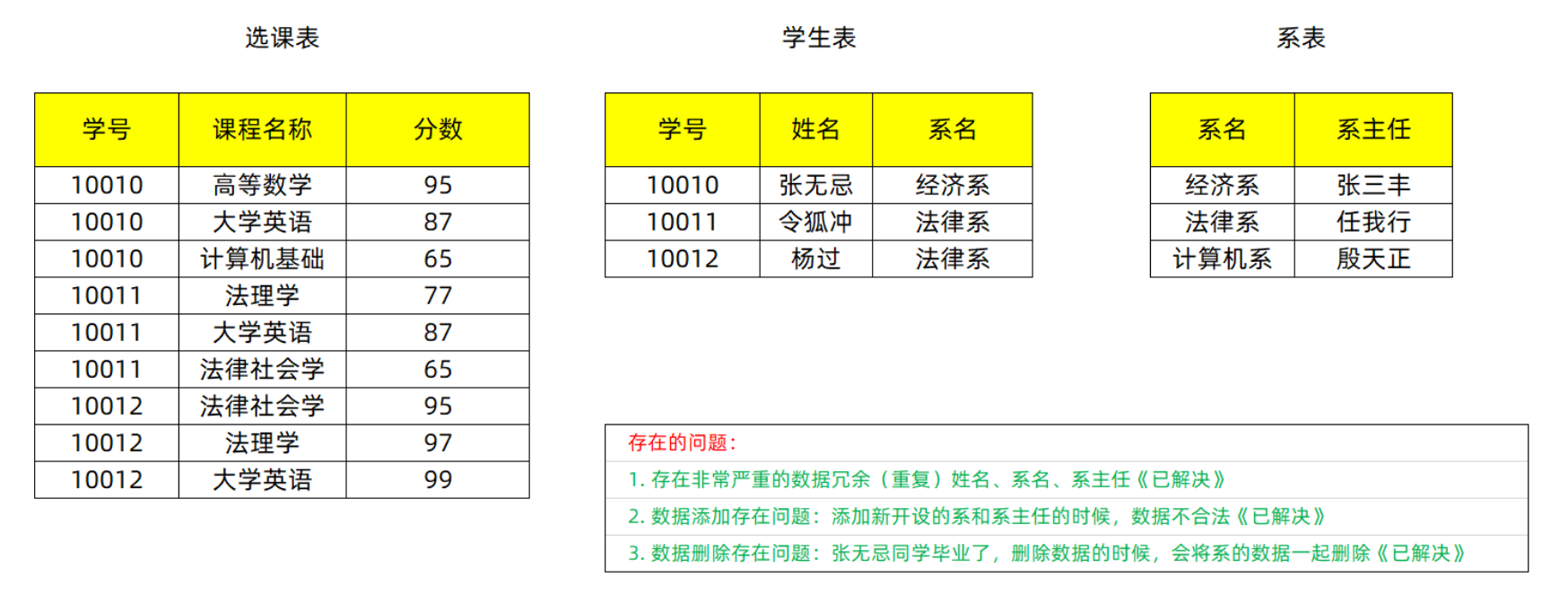
explain
Split tables, which are not particularly closely related, are split into multiple tables. (student number and Dean) transfer dependency For example, the student number needs to find the dean. First find the Department name, and then find the dean. For the third paradigm, the main function is to eliminate transitive dependence.
Chapter II database transactions
Section 01 basic theory
What is a transaction?
Transaction: In a group of multiple SQL Statement, for database operations, they either succeed or fail at the same time. give an example: In the process of bank transfer. Zhang San transferred 1000 yuan to Li Si. UPDATE account SET money=money-1000 WHERE name='Zhang San'; UPDATE account SET money=money+1000 WHERE name='Li Si';
Three operations of SQL transaction
(1) Open transaction SQL Statement writing: START TRANSACTION; Timing of statement operation: When we need to put multiple SQL When the statement is managed by a transaction, the transaction is started (2) Rollback transaction SQL Statement writing: ROLLBACK; Timing of statement operation: When we fail, rollback is performed (3) Commit transaction SQL Statement writing: COMMIT; Timing of statement operation: When we succeed, we execute the commit
Four characteristics of transactions (frequently asked questions in interviews) ACID
1. Atomicity: multiple SQL In the process of statement operation, Unity is indivisible. (atoms are the smallest unit in chemistry and can't be divided) 2. Consistency: multiple SQL In the process of statement operation, The sum of the data will not change. 3. Persistence: when a transaction is executed COMMIT Submit or ROLLBACK After rollback, the data will be permanently stored in the database. 4. Isolation: multiple transactions should be as independent as possible without affecting each other.
Section 02 getting started
Code preparation
-- 1. Create database, create data table DROP DATABASE IF EXISTS mydb07; CREATE DATABASE IF NOT EXISTS mydb07; USE mydb07; DROP TABLE IF EXISTS account; CREATE TABLE IF NOT EXISTS account( uid INT, uname VARCHAR(20), money INT ); -- 2. insert data INSERT INTO account VALUES (1,'Zhang San',10000),(2,'Li Si',10000); -- 3. Query data SELECT * FROM account; -- 4. Modify data UPDATE account SET money = 10000;
Demo case 1: normal and abnormal
-- 1. Transfer operation (Zhang San transfers 1000 yuan to Li Si) UPDATE account SET money = money - 1000 WHERE uname = 'Zhang San'; Error ,Hee hee UPDATE account SET money = money + 1000 WHERE uname = 'Li Si'; -- 2. View data sheet SELECT * FROM account;
Demo case 2: transaction management
-- 1. Transfer operation (Zhang San transfers 1000 yuan to Li Si) -- set up MySQL The transaction submission method of is manual submission, mySQL The default is auto submit SET AUTOCOMMIT = 0; -- Set the submission method, 1 submit automatically, 0 submit manually SELECT @@AUTOCOMMIT; -- View how transactions are committed -- You need to start the transaction before you start the transfer START TRANSACTION; UPDATE account SET money = money - 1000 WHERE uname = 'Zhang San'; Error ,Hee hee -- If an error occurs, the transaction is rolled back ROLLBACK; UPDATE account SET money = money + 1000 WHERE uname = 'Li Si'; -- When the transfer is over, You need to commit the transaction COMMIT; -- 2. View data sheet SELECT * FROM account;
Section 03 isolation level
Content introduction (the higher the isolation level, the higher the security, and the lower the efficiency)
| Serial number | Isolation level | Chinese name | Dirty reading | Non repeatable reading | Unreal reading | Database default |
|---|---|---|---|---|---|---|
| 1 | READ UNCOMMITTED | Read uncommitted | YES | YES | YES | |
| 2 | READ COMMITTED | Read committed | NO | YES | YES | Oracle default |
| 3 | REPEATABLE READ | Repeatable reading | NO | NO | YES | MySQL default |
| 4 | SERIALIZABLE | Serialization | NO | NO | NO |
Introduction to professional vocabulary
1. Dirty reading: In transaction A In the process of processing, the transaction is read B Data. Read the data that has not yet been committed, resulting in incorrect data. The results of multiple queries may be inconsistent. 2. Non repeatable: In transaction A In the process of processing, the transaction is read B Data. Read that the transaction has committed data, resulting in incorrect data. The results of multiple queries may be inconsistent. 3. Unreal reading: system administrator A Change the scores of all students in the database from specific scores to ABCDE Grade, But the system administrator B At this time, a record of specific scores was inserted, As a system administrator A After the change, it is found that there is another record that has not been changed, which is like an illusion. This is called illusory reading.
Introduction to related SQL statements
-- 1. View the isolation level of the transaction SELECT @@TX_ISOLATION; -- 2. Modify the isolation level of a transaction SET GLOBAL TRANSACTION ISOLATION LEVEL String for isolation level; -- For example: (after modifying the isolation level, you need to restart SQLyog To take effect) -- Read uncommitted READ UNCOMMITTED SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- Read committed READ COMMITTED SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED; -- Repeatable reading REPEATABLE READ SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- Serialization SERIALIZABLE SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Demonstrate transaction isolation levels
-- 1. Three operations of transaction (start, commit, rollback) START TRANSACTION; COMMIT; ROLLBACK; -- 2. View data sheet SELECT * FROM account; -- 3. Modify operation UPDATE account SET money = money - 1000 WHERE uname = 'Zhang San'; Something went wrong. There was a power failure and the computer exploded UPDATE account SET money = money + 1000 WHERE uname = 'Li Si'; -- 4. Return to the original state UPDATE account SET money = 10000; SELECT * FROM account; -- 5. Modify the transaction submission method and view the transaction submission method SET AUTOCOMMIT = 0; SELECT @@AUTOCOMMIT;
Chapter 3 database view
Section 01 basic theory
Why are there views?
We explained the process of multi table query two days ago, saying that sub queries can be performed. Subquery (the result of one query is the condition of the next query) SQL Statements, statements appear longer and more. In order to simplify the operation of multi table query, we can complete it through view.
Data preparation
-- Create table DROP TABLE IF EXISTS country; CREATE TABLE IF NOT EXISTS country( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); INSERT INTO country VALUES (NULL,'China'),(NULL,'U.S.A'),(NULL,'island country'); SELECT * FROM country; -- Create table DROP TABLE IF EXISTS city; CREATE TABLE IF NOT EXISTS city( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), cid INT ); -- Create foreign key ALTER TABLE city ADD FOREIGN KEY (cid) REFERENCES country(id); -- Add data INSERT INTO city VALUES (NULL,'Beijing',1); INSERT INTO city VALUES (NULL,'Shanghai',1); INSERT INTO city VALUES (NULL,'Wuhan',1); INSERT INTO city VALUES (NULL,'Washington',2); INSERT INTO city VALUES (NULL,'San Francisco',2); INSERT INTO city VALUES (NULL,'Tokyo',3); INSERT INTO city VALUES (NULL,'Osaka',3); SELECT * FROM city;
Demand: query the city information corresponding to the country
-- Internal connection query SELECT t1.name 'Country name', t2.name 'City name' FROM country t1, city t2 WHERE t1.id = t2.cid;
Section 02 creating views
Syntax format
-- Syntax format: CREATE VIEW View name (Column name of view 1,Column name of view 2,View column name 3) AS former SQL sentence;
Examples
CREATE VIEW city_country (country_name,city_name) AS SELECT t1.name 'Country name', t2.name 'City name' FROM country t1, city t2 WHERE t1.id = t2.cid;
Section 03 modifying views
Syntax format
-- Syntax format: (Modify view data) UPDATE View name SET The column name of the view=value WHERE condition; -- Syntax format: (Modify the structure of the view) ALTER VIEW View name (Column name 1,Column name 2,Column name 3) AS Previous queries SQL sentence;
Case code
-- 1. Modify the structure of the view ALTER VIEW city_country (country_name,city_name,city_id) AS SELECT t1.name,t2.name,t2.id FROM country t1,city t2 WHERE t1.id = t2.cid; -- 2. Query view SELECT * FROM city_country; -- 3. Modify data -- To bring the island country, city_id=7 According to the data, the name of Osaka City was renamed Osaka UPDATE city_country SET city_name = 'Osaka' WHERE city_id = 7; -- 4. Query original table SELECT * FROM city; /** Note: modifying the contents of the view will also synchronously modify the contents of the original table **/
Section 04 delete view
Syntax format
-- 1. Delete view syntax (simplified format) DROP VIEW Name of the view; -- 2. Delete view syntax (full format) DROP VIEW IF EXISTS Name of the view;
Case code
-- 1. Create view CREATE VIEW city_country (country_name,city_name,city_id) AS SELECT t1.name,t2.name,t2.id FROM country t1,city t2 WHERE t1.id = t2.cid; -- 2. Query view SELECT * FROM city_country; -- 3. Delete view DROP VIEW city_country; DROP VIEW IF EXISTS city_country;
Section 05 precautions
/*
Problem: Tokyo City in the view is deleted_ This record with id = 6
Does it affect the original table?
It has no effect and cannot be deleted
*/
-- 1. Query view
SELECT * FROM city_country;
-- 2. In the view, delete city_id=6 Record of
DELETE FROM city_country WHERE city_id=6;
-- 3. In the view, insert data
INSERT INTO city_country VALUES ('britain','London',8);
/*
Note: the view cannot be deleted or added.
Note: the view can be modified. After modification, the data of the original table will be affected.
Note: the view is mainly used for query operations to simplify multi table queries.
*/
Summary:
Views can be queried and modified.
If modification is performed, the data of the original table will be affected.
Chapter IV backup and restore
Section 01 code mode
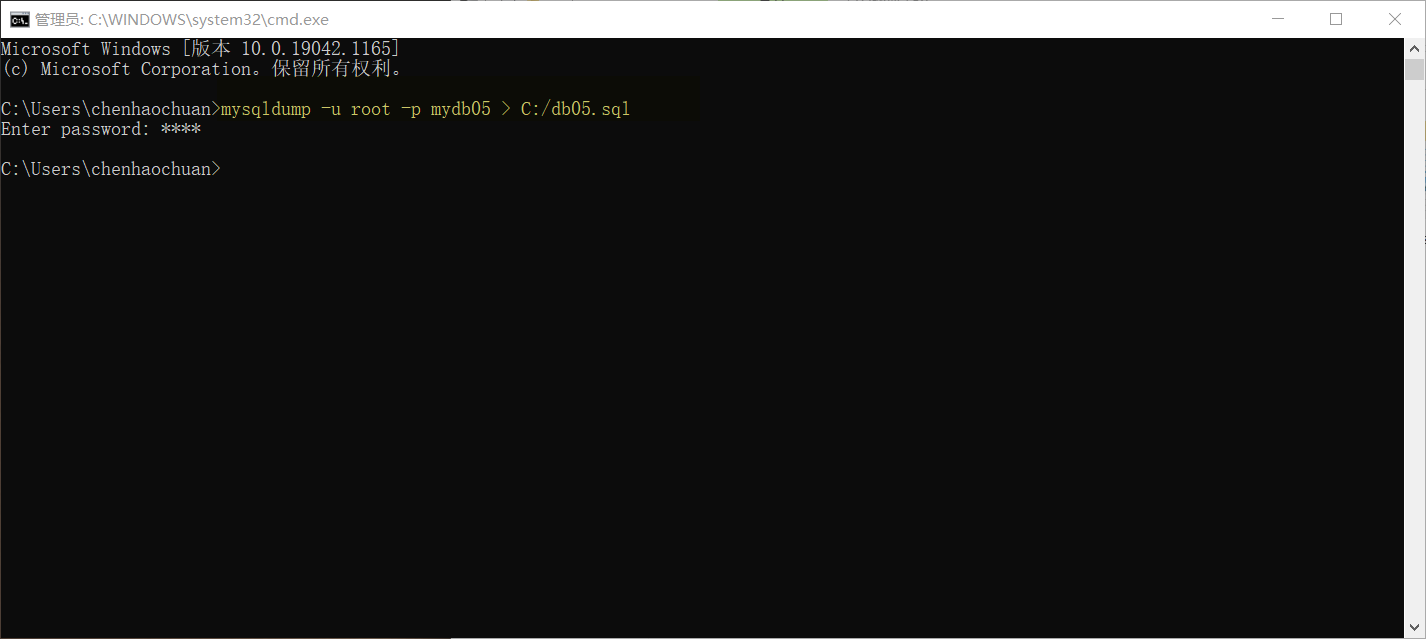
backups
mysqldump -u root -p mydb05 > C:/db05.sql
Case code (implemented in the small black window, close SQLyog)
reduction
1,Delete the previous database 2,Create an empty database with the same name as before. 3,Empty database created using 4,Execute instruction SOURCE C:/db05.sql
Case code (start the small black window to complete and close SQLyog)
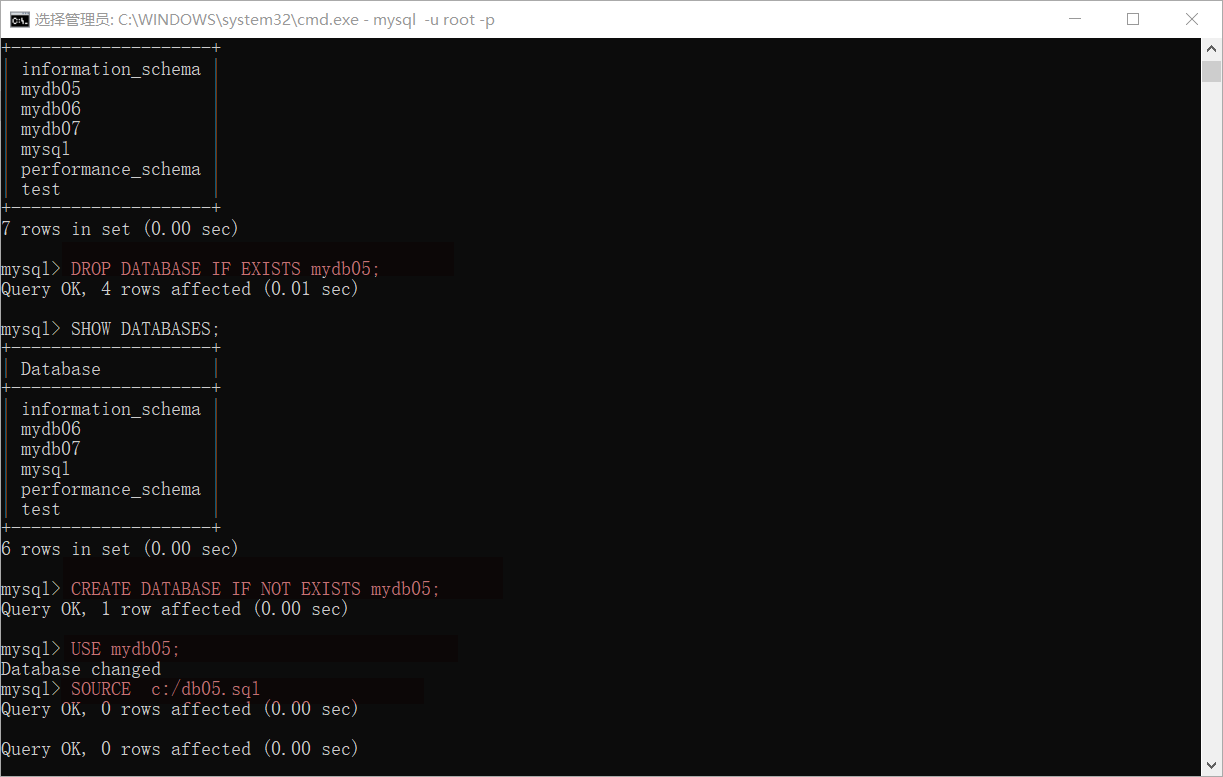
Section 02 visual interface
backups
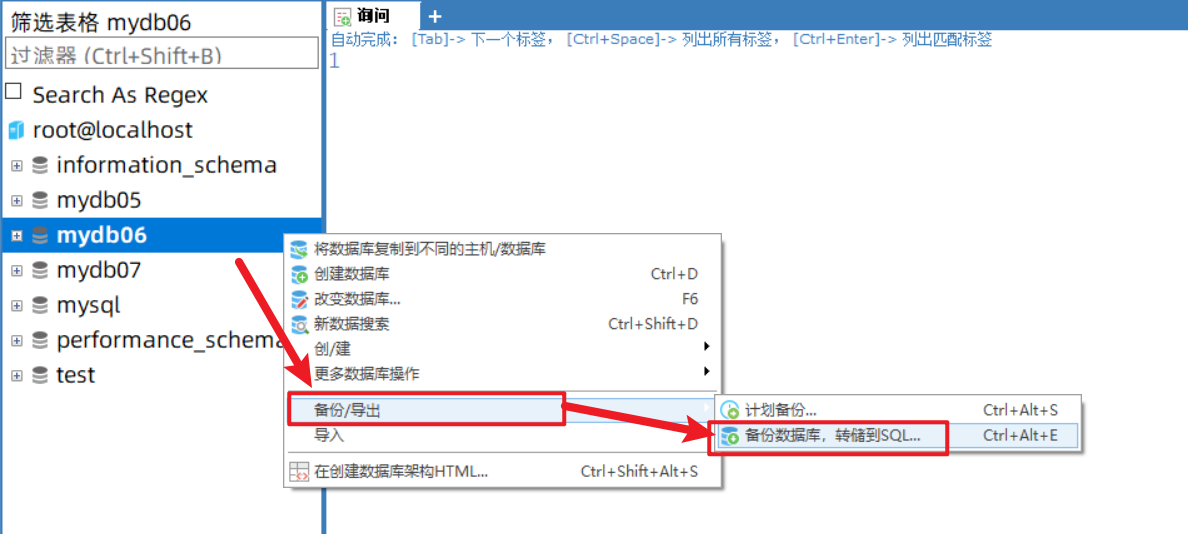
reduction
1,Delete the previous database contents 2,Create an empty database with the same name as before 3,Right click and select import
design sketch
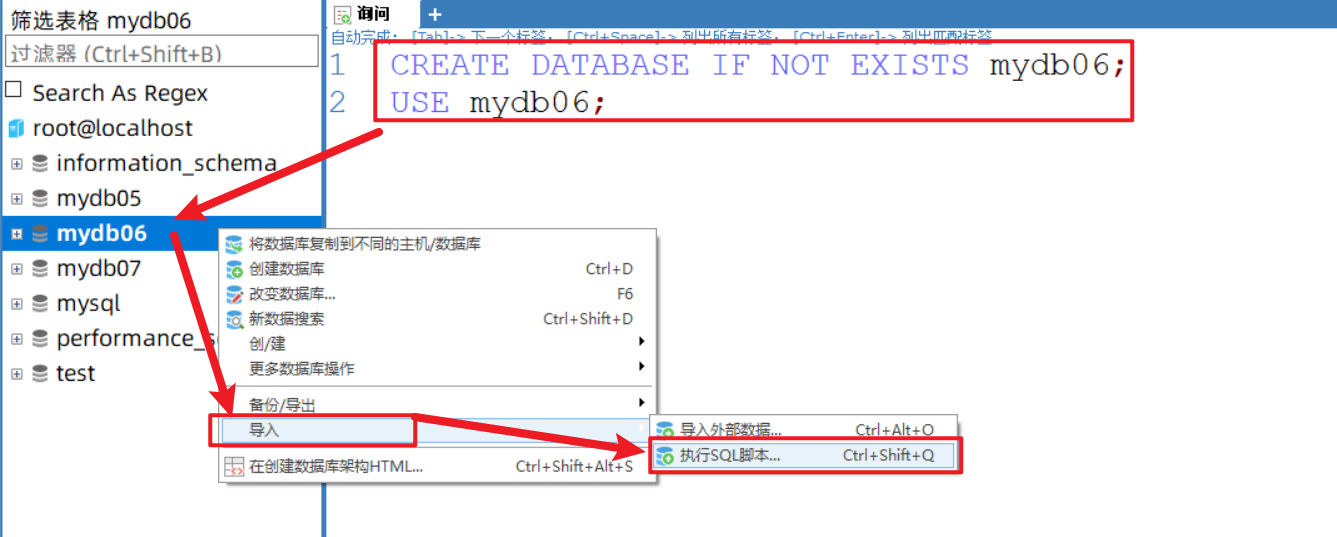
Today's summary: four characteristics of paradigm function and transaction
1. Why use paradigms?
In order to reduce the data redundancy in the database. (reduce data duplication in the same table)
2. Three operations of SQL transaction
(1) Open transaction SQL Statement writing: START TRANSACTION; Timing of statement operation: When we need to put multiple SQL When the statement is managed by a transaction, the transaction is started (2) Rollback transaction SQL Statement writing: ROLLBACK; Timing of statement operation: When we fail, rollback is performed (3) Commit transaction SQL Statement writing: COMMIT; Timing of statement operation: When we succeed, we execute the commit
Four characteristics of transactions (frequently asked questions in interviews) ACID
Atomicity( Atomicity) Atomicity means that a transaction is an indivisible unit of work, and operations in a transaction either occur or do not occur. Consistency( Consistency) Data integrity must be consistent before and after a transaction. Isolation( Isolation) Transaction isolation is that when multiple users access the database concurrently, the transactions opened by the database for each user cannot be disturbed by the operation data of other transactions. Multiple concurrent transactions should be isolated from each other. Persistence( Durability) Persistence means that once a transaction is committed, its changes to the data in the database are permanent. Then, even if the database fails, it should not have any impact on it