1, Introduction
- Query specification
- Each command is in; Or \ g or \ g end
- It is recommended to use single quotation marks' 'for string type and date time type data, and double quotation marks'' for column alias, and omitting AS is not recommended
- Annotation specification
- Single line annotation: # annotation text (MySQL specific method)
- Single line comment: - comment text (- - must be followed by a space.)
- Multiline note: / * note text*/
2, Regular matching
Regular expressions are usually used to retrieve or replace the text content that conforms to a certain pattern, and match the special strings that meet the requirements in the text according to the specified matching pattern.
| Name | Description |
|---|---|
| REGEXP | Whether string matches regular expression |
| NOT REGEXP | Negation of REGEXP |
| REGEXP_INSTR() | Starting index of substring matching regular expression |
| REGEXP_REPLACE() | Replace substrings matching regular expression |
| REGEXP_SUBSTR() | Return substring matching regular expression |
3, Multi table query
- JOIN
- UNION
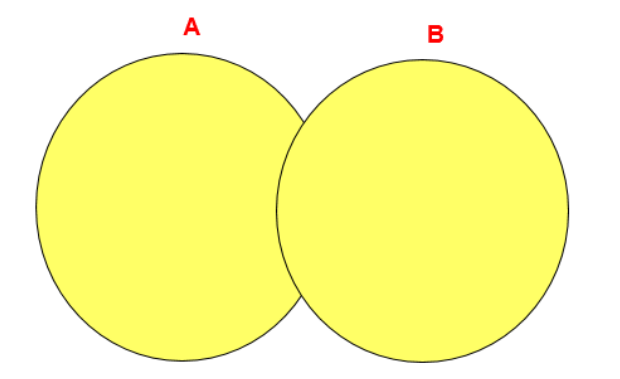
-
The UNION operator returns the UNION of the result sets of two queries to remove duplicate records.
-
The UNION ALL operator returns the union of the result sets of two queries. For the duplicate parts of the two result sets, the duplicate is not removed.
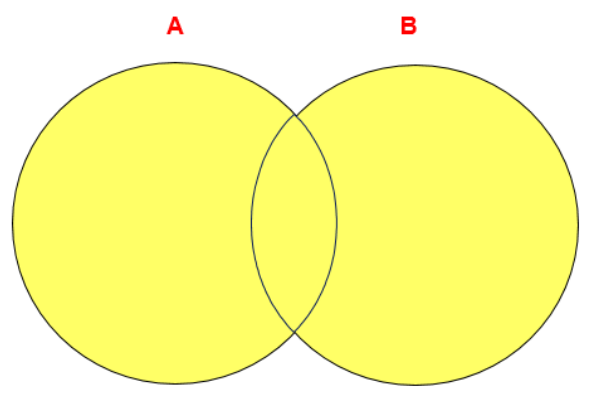
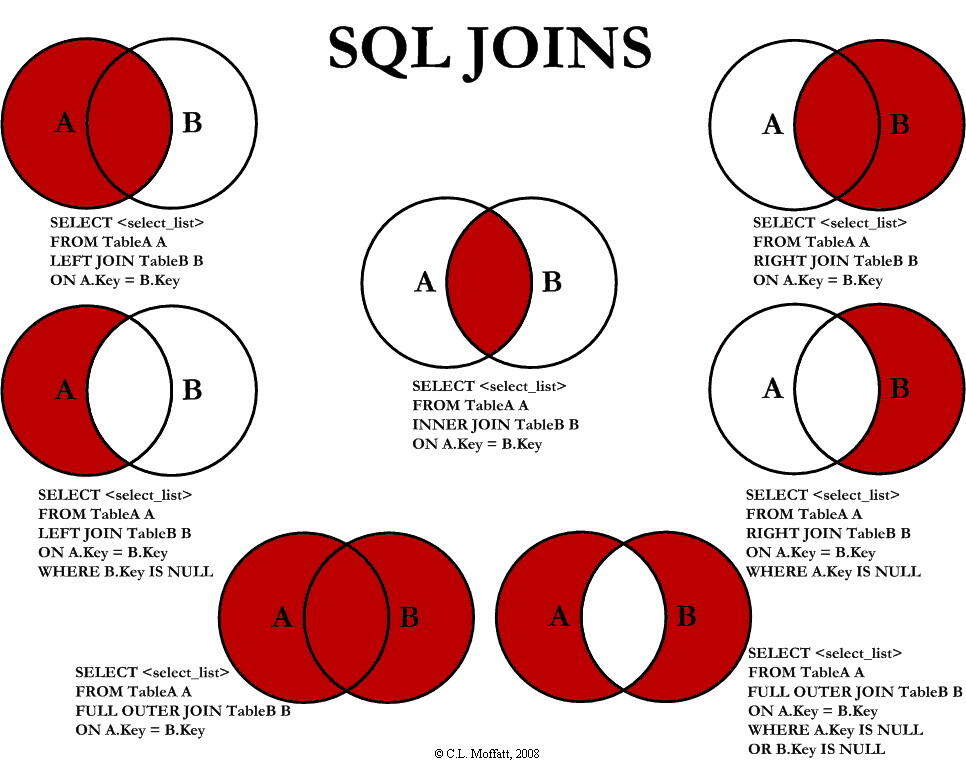
- Implementation of Join in 7
- Middle figure: inner connection A ∩ B
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id`;
- Top left: left outer connection
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id`;
- Top right: right outer connection
SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
- Middle left: A - A ∩ B
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL;
- Middle right: B - A ∩ B
SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL;
- Lower left figure: full external connection (middle left figure + upper right figure A ∪ B)
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL #No weight removal operation, high efficiency SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id`;
- Lower right figure: middle left figure + middle right figure A ∪ B - A ∩ B or (A - A ∩ B) ∪ (B - A ∩ B)
SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL UNION ALL SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL;
- NATURAL JOIN
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id` AND e.`manager_id` = d.`manager_id`;
Automatically query all the same fields in the two connection tables, and then conduct equivalent connection.
SELECT employee_id,last_name,department_name FROM employees e NATURAL JOIN departments d;
- USING
SELECT employee_id,last_name,department_name FROM employees e ,departments d WHERE e.department_id = d.department_id;
Use USING to specify the fields with the same name in the data table for equivalent connection
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d USING (department_id);
4, Aggregate query
4.1 COUNT
count(*), count(1) directly reads rows and counts the rows with NULL value, while count (column name) does not count the rows with NULL value.
4.2 GROUP BY
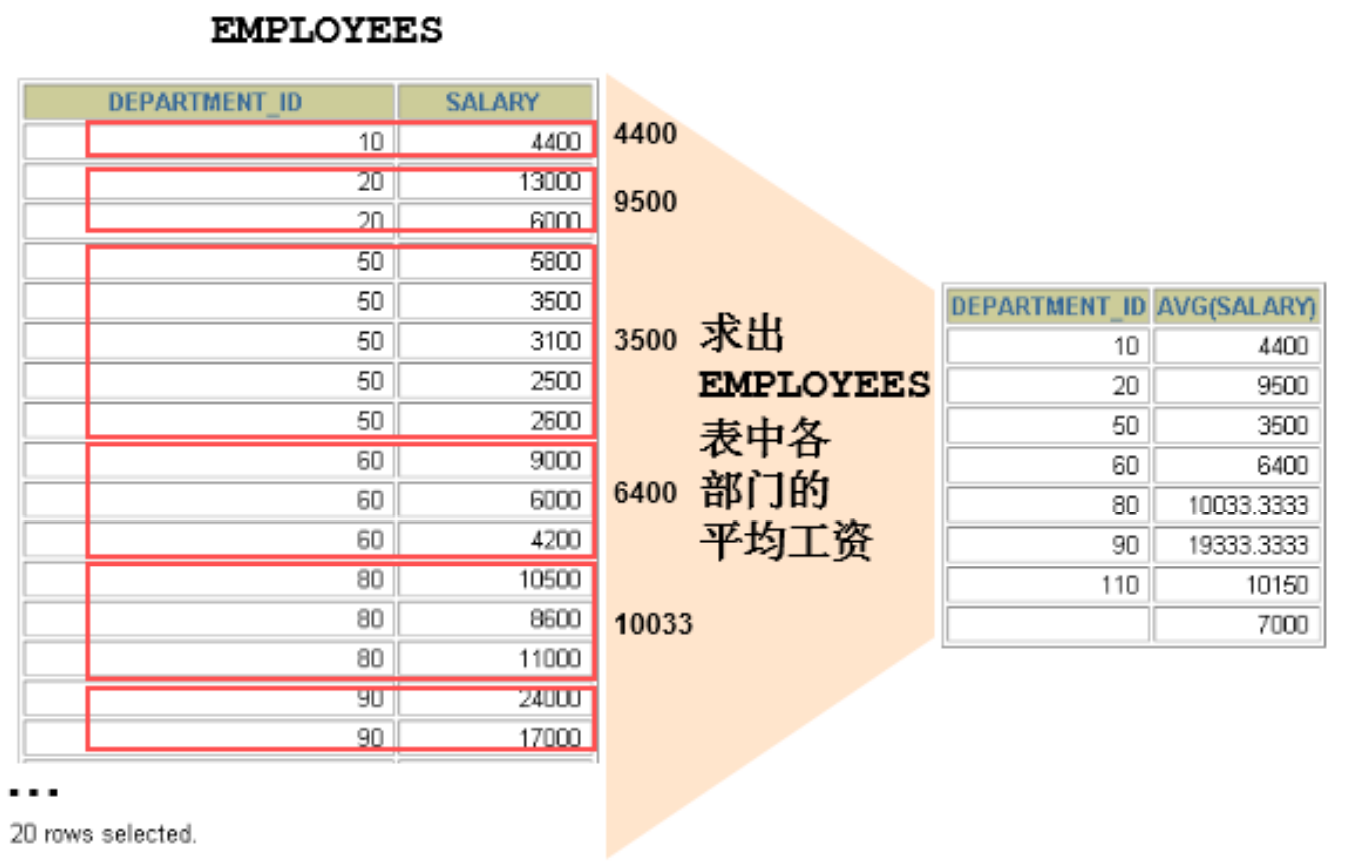
In the SELECT list, all columns not included in the group function should be included in the GROUP BY clause
mysql> SELECT department_id, AVG(salary)
-> FROM employees
-> GROUP BY department_id ;
+---------------+--------------+
| department_id | AVG(salary) |
+---------------+--------------+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| 40 | 6500.000000 |
| 50 | 3475.555556 |
| 60 | 5760.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
+---------------+--------------+
12 rows in set (0.00 sec)
mysql>
After using the WITH ROLLUP keyword, add a record after all the queried grouping records. The record calculates the sum of all the queried records, that is, the number of statistical records.
mysql> SELECT department_id,COUNT(*)
-> FROM employees
-> WHERE department_id > 80
-> GROUP BY department_id WITH ROLLUP;
+---------------+----------+
| department_id | COUNT(*) |
+---------------+----------+
| 90 | 3 |
| 100 | 6 |
| 110 | 2 |
| NULL | 11 |
+---------------+----------+
4 rows in set (0.00 sec)
mysql> SELECT department_id,SUM(salary)
-> FROM employees
-> WHERE department_id > 80
-> GROUP BY department_id WITH ROLLUP;
+---------------+-------------+
| department_id | SUM(salary) |
+---------------+-------------+
| 90 | 58000.00 |
| 100 | 51600.00 |
| 110 | 20300.00 |
| NULL | 129900.00 |
+---------------+-------------+
4 rows in set (0.00 sec)
mysql> SELECT department_id,AVG(salary)
-> FROM employees
-> WHERE department_id > 80
-> GROUP BY department_id WITH ROLLUP;
+---------------+--------------+
| department_id | AVG(salary) |
+---------------+--------------+
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
| NULL | 11809.090909 |
+---------------+--------------+
4 rows in set (0.00 sec)
mysql>
4.3 HAVING
HAVING cannot be used alone. It must be used together with GROUP BY.
mysql> SELECT department_id, MAX(salary)
-> FROM employees
-> GROUP BY department_id
-> HAVING MAX(salary)>10000 ;
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+-------------+
6 rows in set (0.00 sec)
mysql>
- Comparison between WHERE and HAVING
- WHERE can directly use the fields in the table as the filter criteria, but cannot use the calculation function in the grouping as the filter criteria;
- HAVING must be used together with GROUP BY. You can use grouping calculation functions and grouping fields as filtering conditions.
- If you need to obtain the required data from the associated table through connection, WHERE is filtering before connection, and HAVING is connecting before filtering.
4.4 query execution sequence
- Writing order
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
- Execution sequence
From - > where - > group by - > having - > selected fields - > distinct - > order by - > limit
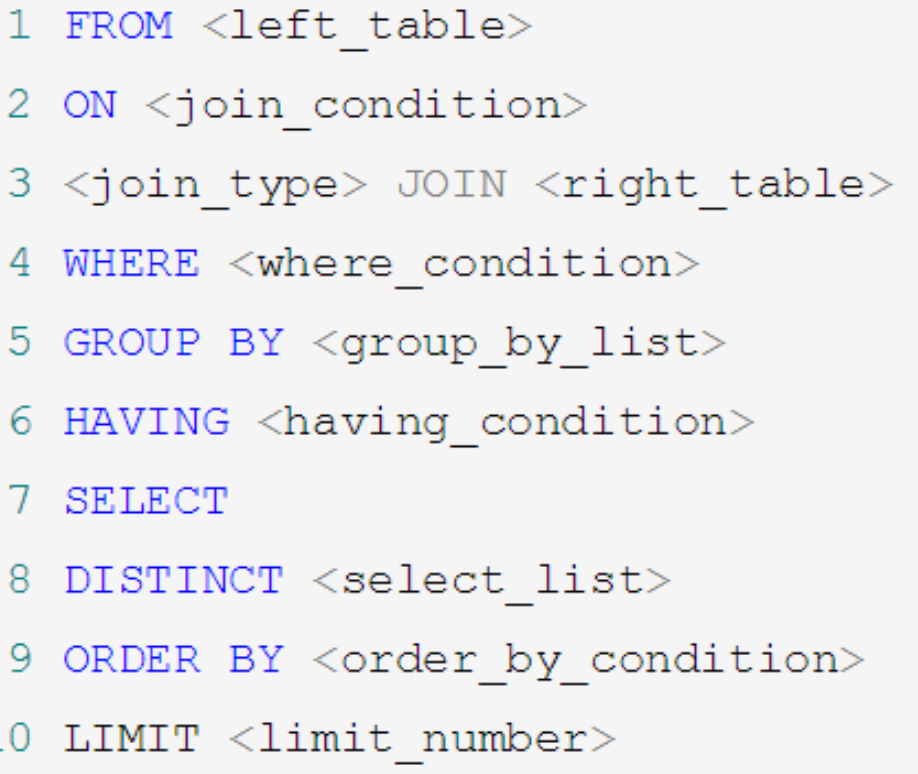
When the SELECT statement executes these steps, each step will generate a virtual table, and then pass this virtual table into the next step as input.
SELECT DISTINCT player_id, player_name, count(*) as num # Sequence 5 FROM player JOIN team ON player.team_id = team.team_id # Sequence 1 WHERE height > 1.80 # Sequence 2 GROUP BY player.team_id # Sequence 3 HAVING num > 2 # Sequence 4 ORDER BY num DESC # Sequence 6 LIMIT 2 # Sequence 7
5, Subquery
- extraction
Whose salary is higher than Abel?
- First query Abel's salary, and then query accordingly.
mysql> SELECT salary
-> FROM employees
-> WHERE last_name = 'Abel';
+----------+
| salary |
+----------+
| 11000.00 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT last_name,salary
-> FROM employees
-> WHERE salary > 11000;
+-----------+----------+
| last_name | salary |
+-----------+----------+
| King | 24000.00 |
| Kochhar | 17000.00 |
| De Haan | 17000.00 |
...
+-----------+----------+
10 rows in set (0.00 sec)
mysql>
- Subquery
mysql> SELECT last_name,salary
-> FROM employees
-> WHERE salary > (
-> SELECT salary
-> FROM employees
-> WHERE last_name = 'Abel'
-> );
+-----------+----------+
| last_name | salary |
+-----------+----------+
| King | 24000.00 |
| Kochhar | 17000.00 |
| De Haan | 17000.00 |
...
+-----------+----------+
10 rows in set (0.00 sec)
mysql>
5.1 single line sub query
| Operator | meaning |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
- Subquery in HAVING
Query the Department id and the minimum wage of the Department whose minimum wage is greater than the minimum wage of No. 50 department
mysql> SELECT department_id, MIN(salary)
-> FROM employees
-> GROUP BY department_id
-> HAVING MIN(salary) > (
-> SELECT MIN(salary)
-> FROM employees
-> WHERE department_id = 50
-> );
+---------------+-------------+
| department_id | MIN(salary) |
+---------------+-------------+
| NULL | 7000.00 |
| 10 | 4400.00 |
| 20 | 6000.00 |
...
+---------------+-------------+
11 rows in set (0.02 sec)
mysql>
- Subquery in CASE
Explicit employee_id,last_name and location. Where, if the employee department_id and location_ Department with ID 1800_ If the ID is the same, the location is' Canada ', and the rest is' USA'.
mysql> SELECT employee_id, last_name,
-> (CASE department_id
-> WHEN
-> (SELECT department_id FROM departments
-> WHERE location_id = 1800)
-> THEN 'Canada' ELSE 'USA' END) location
-> FROM employees;
+-------------+-------------+----------+
| employee_id | last_name | location |
+-------------+-------------+----------+
...
| 201 | Hartstein | Canada |
| 202 | Fay | Canada |
| 203 | Mavris | USA |
| 204 | Baer | USA |
...
+-------------+-------------+----------+
107 rows in set (0.00 sec)
mysql>
- Null value problem in subquery
mysql> SELECT job_id
-> FROM employees
-> WHERE last_name = 'Haas';
Empty set (0.00 sec)
mysql> SELECT last_name, job_id
-> FROM employees
-> WHERE job_id =
-> (SELECT job_id
-> FROM employees
-> WHERE last_name = 'Haas');
Empty set (0.00 sec)
mysql>
- Illegal use of subquery
mysql> SELECT MIN(salary)
-> FROM employees
-> GROUP BY department_id;
+-------------+
| MIN(salary) |
+-------------+
| 7000.00 |
| 4400.00 |
| 6000.00 |
...
+-------------+
12 rows in set (0.00 sec)
mysql> SELECT employee_id, last_name
-> FROM employees
-> WHERE salary =
-> (SELECT MIN(salary)
-> FROM employees
-> GROUP BY department_id);
ERROR 1242 (21000): Subquery returns more than 1 row
mysql>
5.2 multi line sub query
| Operator | meaning |
|---|---|
| IN | Equal to any one in the list |
| ANY | It needs to be used together with the single line comparison operator to compare with a value returned by the sub query |
| ALL | It needs to be used together with the single line comparison operator to compare with all the values returned by the sub query |
| SOME | In fact, it is an alias of ANY, which has the same function. Generally, ANY is often used |
- IN
Query the manager of employee 141 or 174_ ID and department_ Employees of other employees with the same ID_ id,manager_id,department_id
mysql> SELECT employee_id, manager_id, department_id FROM employees WHERE employee_id IN (141,174);
+-------------+------------+---------------+
| employee_id | manager_id | department_id |
+-------------+------------+---------------+
| 141 | 124 | 50 |
| 174 | 149 | 80 |
+-------------+------------+---------------+
2 rows in set (0.00 sec)
mysql> SELECT employee_id, manager_id, department_id
-> FROM employees
-> WHERE (manager_id, department_id) IN (
-> SELECT manager_id, department_id
-> FROM employees
-> WHERE employee_id IN (141,174))
-> AND employee_id NOT IN (141,174);
+-------------+------------+---------------+
| employee_id | manager_id | department_id |
+-------------+------------+---------------+
...
| 198 | 124 | 50 |
| 199 | 124 | 50 |
| 175 | 149 | 80 |
...
+-------------+------------+---------------+
11 rows in set (0.01 sec)
mysql>
- ALL
Query the Department id with the lowest average wage
mysql> SELECT department_id
-> FROM employees
-> GROUP BY department_id
-> HAVING AVG(salary) <= ALL (
-> SELECT AVG(salary) avg_sal
-> FROM employees
-> GROUP BY department_id
-> );
+---------------+
| department_id |
+---------------+
| 50 |
+---------------+
1 row in set (0.00 sec)
mysql>
- ANY
Return other jobs_ Job in ID_ ID is' it '_ Prog 'employee number, name and job of any employee with low salary (MAX(salary) is OK)_ ID and salary
mysql> SELECT employee_id, last_name, job_id, salary
-> FROM employees
-> WHERE salary < ANY (
-> SELECT salary
-> FROM employees
-> WHERE job_id = 'IT_PROG'
-> )
-> AND job_id <> 'IT_PROG';
+-------------+-------------+------------+---------+
| employee_id | last_name | job_id | salary |
+-------------+-------------+------------+---------+
| 110 | Chen | FI_ACCOUNT | 8200.00 |
| 111 | Sciarra | FI_ACCOUNT | 7700.00 |
| 112 | Urman | FI_ACCOUNT | 7800.00 |
...
+-------------+-------------+------------+---------+
76 rows in set (0.00 sec)
mysql>
5.3 related sub query
If the execution of a sub query depends on an external query, it is usually because the tables in the sub query use external tables and are conditionally associated. Therefore, every time an external query is executed, the sub query must be recalculated. Such a sub query is called an associated sub query.
- Examples
If employees in the employees table_ ID and job_ Employee in history table_ The number of employees with the same ID is not less than 2, and the employees of these employees with the same ID are output_ id,last_ Name and its job_id
mysql> SELECT e.employee_id, last_name,e.job_id
-> FROM employees e
-> WHERE 2 <= (
-> SELECT COUNT(*)
-> FROM job_history
-> WHERE employee_id = e.employee_id);
+-------------+-----------+---------+
| employee_id | last_name | job_id |
+-------------+-----------+---------+
| 101 | Kochhar | AD_VP |
| 176 | Taylor | SA_REP |
| 200 | Whalen | AD_ASST |
+-------------+-----------+---------+
3 rows in set (0.00 sec)
mysql>
- Using subqueries in FROM
Query the last of employees whose salary is greater than the average salary of the Department_ Name, salary and its department_id
mysql> SELECT last_name,salary,e1.department_id
-> FROM employees e1,(
-> SELECT department_id,AVG(salary) dept_avg_sal
-> FROM employees GROUP
-> BY department_id) e2
-> WHERE e1.`department_id` = e2.department_id
-> AND e2.dept_avg_sal < e1.`salary`;
+-----------+----------+---------------+
| last_name | salary | department_id |
+-----------+----------+---------------+
| Hartstein | 13000.00 | 20 |
| Raphaely | 11000.00 | 30 |
| Weiss | 8000.00 | 50 |
...
+-----------+----------+---------------+
38 rows in set (0.01 sec)
mysql>
- Using subqueries in ORDER BY
Query the employee's id and salary according to department_name sort
mysql> SELECT employee_id,salary
-> FROM employees e
-> ORDER BY (
-> SELECT department_name
-> FROM departments d
-> WHERE e.`department_id` = d.`department_id`
-> );
+-------------+----------+
| employee_id | salary |
+-------------+----------+
| 178 | 7000.00 |
| 205 | 12000.00 |
| 206 | 8300.00 |
...
+-------------+----------+
107 rows in set (0.02 sec)
mysql>
- EXISTS and NOT EXISTS keywords
The associated subquery is usually used together with the EXISTS operator to check whether there are qualified rows in the subquery.
# Employee's manager_ id,last_name,job_id,department_id information
mysql> SELECT employee_id, last_name, job_id, department_id
-> FROM employees e1
-> WHERE EXISTS (
-> SELECT *
-> FROM employees e2
-> WHERE e2.manager_id = e1.employee_id);
+-------------+-----------+---------+---------------+
| employee_id | last_name | job_id | department_id |
+-------------+-----------+---------+---------------+
| 100 | King | AD_PRES | 90 |
| 101 | Kochhar | AD_VP | 90 |
| 102 | De Haan | AD_VP | 90 |
...
+-------------+-----------+---------+---------------+
18 rows in set (0.00 sec)
mysql>
- Related updates
Add a department in employees_ Name field, the data is the Department name corresponding to the employee
# 1) ALTER TABLE employees ADD(department_name VARCHAR2(14)); # 2) UPDATE employees e SET department_name = ( SELECT department_name FROM departments d WHERE e.department_id = d.department_id);
- Related deletion
DELETE FROM table1 alias1
WHERE column operator (
SELECT expression
FROM table2 alias2
WHERE alias1.column = alias2.column);
6, Window function
Official website: https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
Function OVER ([PARTITION BY field name ORDER BY field name ASC|DESC])
| Function classification | function | Function description |
|---|---|---|
| Ordinal function | ROW_NUMBER() | Sequential sorting |
| RANK() | In parallel sorting, repeated sequence numbers will be skipped, such as 1, 1 and 3 | |
| DENSE_RANK() | In parallel sorting, duplicate serial numbers will not be skipped, such as 1, 1 and 2 | |
| distribution function | PERCENT_RANK() | Grade value percentage |
| CUME_DIST() | Cumulative integral distribution value | |
| Before and after function | LAG(expr, n) | Returns the expr value of the first n rows of the current row |
| LEAD(expr, n) | Returns the value of expr in the next n lines of the current line | |
| Head and tail function | FIRST_VALUE(expr) | Returns the value of the first expr |
| LAST_VALUE(expr) | Returns the value of the last expr | |
| Other functions | NTH_VALUE(expr, n) | Returns the value of the nth expr |
| NTILE(n) | Divide the ordered data in the partition into n buckets and record the bucket number |
- Data preparation
CREATE TABLE goods( id INT PRIMARY KEY AUTO_INCREMENT, category_id INT, category VARCHAR(15), NAME VARCHAR(30), price DECIMAL(10,2), stock INT, upper_time DATETIME ); INSERT INTO goods(category_id,category,NAME,price,stock,upper_time) VALUES (1, 'Women's wear/Women's Boutique', 'T Shirt', 39.90, 1000, '2020-11-10 00:00:00'), (1, 'Women's wear/Women's Boutique', 'Dress', 79.90, 2500, '2020-11-10 00:00:00'), (1, 'Women's wear/Women's Boutique', 'Sweater', 89.90, 1500, '2020-11-10 00:00:00'), (1, 'Women's wear/Women's Boutique', 'Jeans', 89.90, 3500, '2020-11-10 00:00:00'), (1, 'Women's wear/Women's Boutique', 'Pleated skirt', 29.90, 500, '2020-11-10 00:00:00'), (1, 'Women's wear/Women's Boutique', 'Woolen coat', 399.90, 1200, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Bicycle', 399.90, 1000, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Mountain Bike', 1399.90, 2500, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Alpenstocks', 59.90, 1500, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Riding equipment', 399.90, 3500, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Sport coat', 799.90, 500, '2020-11-10 00:00:00'), (2, 'outdoor sport', 'Skate', 499.90, 1200, '2020-11-10 00:00:00');
6.1 serial number function
- ROW_NUMBER()
ROW_ The number() function can display the sequence numbers in the data in order.
# Query the information of the three commodities with the highest price under each commodity category in the goods data table. SELECT * FROM ( SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods) t WHERE row_num <= 3;

- RANK()
RANK() function can be used to sort serial numbers in parallel and skip repeated serial numbers, such as 1, 1 and 3.
# Use the RANK() function to obtain the information of each commodity with the price ranking from high to low in the goods data table. SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods;
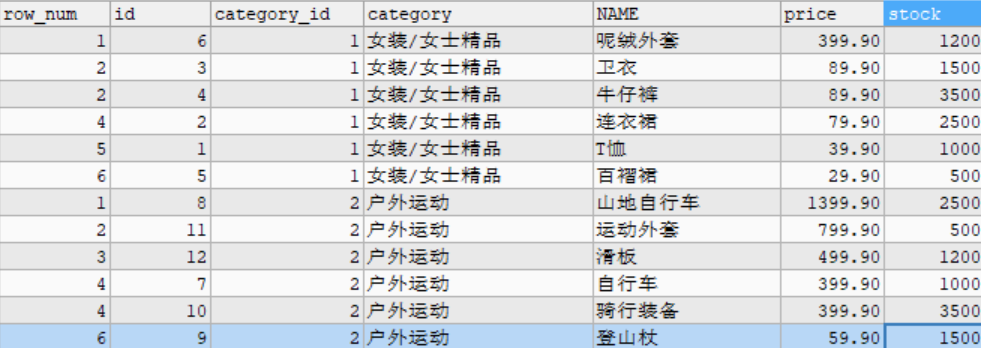
- DENSE_RANK()
DENSE_RANK() function sorts serial numbers in parallel, and does not skip duplicate serial numbers, such as 1, 1 and 2.
# Use DENSE_RANK() function obtains the commodity information sorted from high to low price of each category in the goods data table. SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods;
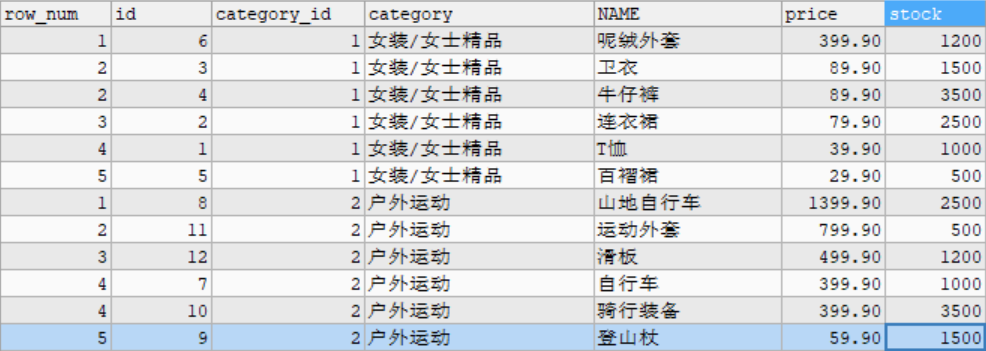
6.2 distribution function
- PERCENT_RANK()
Grade value percentage function_ RANK() = (Rank - 1) / (rows - 1), where the value of rank is the sequence number generated by the RANK() function, and the value of rows is the total number of records in the current window.
# For example: calculate the percentage of goods under the category named "women's clothing / women's boutique" in the goods data sheet_ Rank value. SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r, PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr, id, category_id, category, NAME, price, stock FROM goods WHERE category_id = 1; # or SELECT RANK() OVER w AS r, PERCENT_RANK() OVER w AS pr, id, category_id, category, NAME, price, stock FROM goods WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);

- CUME_DIST(): query the proportion less than or equal to a value.
# Example: query the proportion in the goods data table that is less than or equal to the current price. SELECT RANK() OVER w AS r, CUME_DIST() OVER w AS cd, id, category_id, category, NAME, price, stock FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);
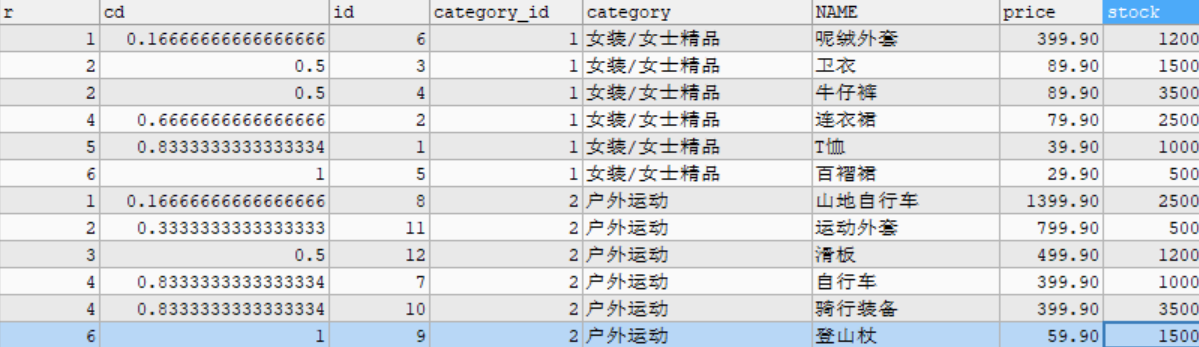
6.3 front and back functions
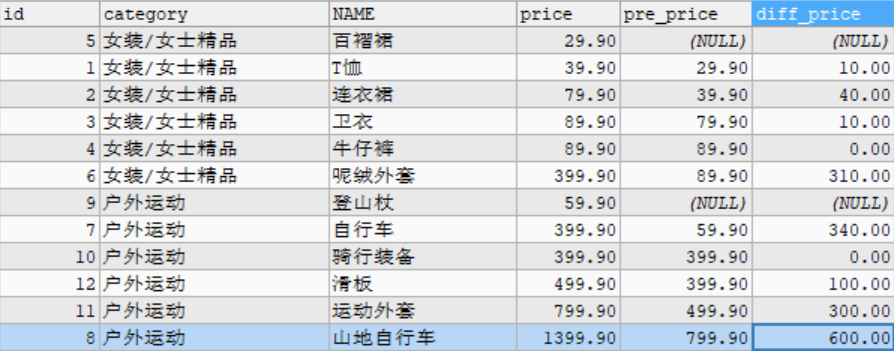
- LAG(expr, n): returns the expr value of the first n rows of the current row
# Example: query the difference between the previous commodity price and the current commodity price in the goods data table. SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price FROM ( SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price) ) t;
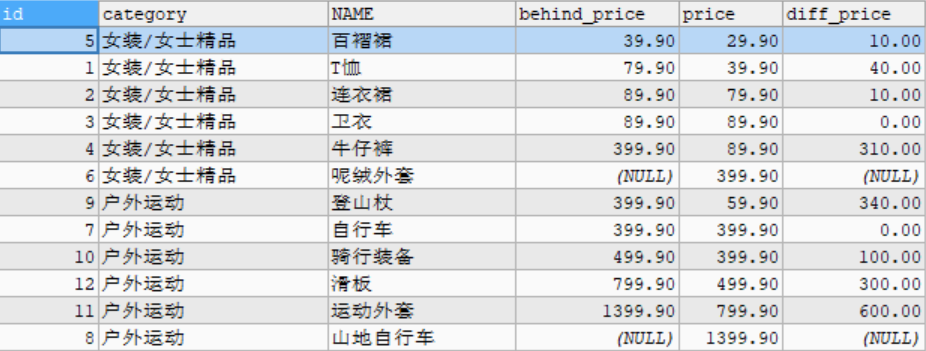
- LEAD(expr,n): returns the expr value of the next N lines of the current line
# Example: query the difference between the last commodity price and the current commodity price in the goods data table. SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price FROM ( SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price) ) t;
6.4 head and tail functions
- FIRST_VALUE(expr): returns the first value of expr
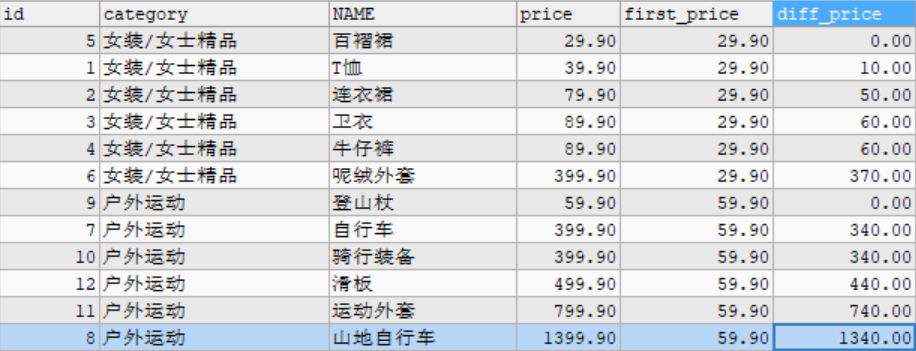
# For example: sort by price and query the difference between the price of the current commodity and the first commodity in the goods data table. SELECT id, category, NAME, price, first_price, price - first_price AS diff_price FROM ( SELECT id, category, NAME, price,FIRST_VALUE(price) OVER w AS first_price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price) ) t;
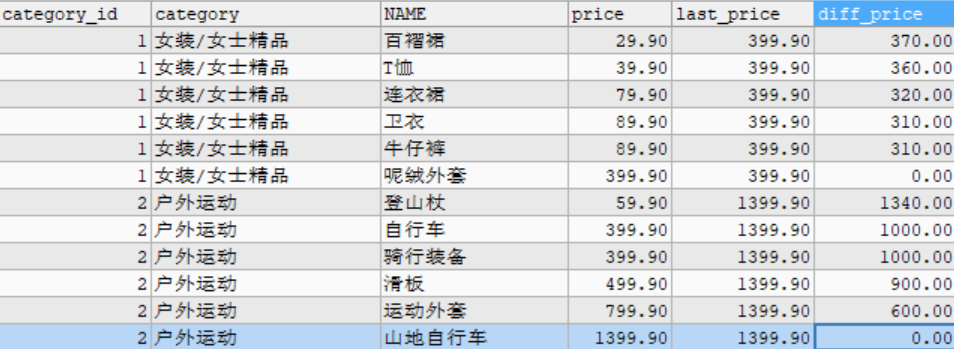
- LAST_VALUE(expr): returns the last value of expr
# For example: sort by price and query the difference between the price of the current commodity and the last commodity in the goods data table.
/**
* The default frame specification is as follows:
* RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
* This means that the framework starts at the first row and ends at the current row of the result set.
*
* Therefore, in order to obtain the employees with the longest overtime, we changed the frame specification to the following:
* RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
*/
SELECT category_id, category, NAME, price, last_price, last_price - price AS diff_price
FROM (
SELECT category_id, category, NAME, price, LAST_VALUE(price) OVER w AS last_price
FROM goods WINDOW w AS (
PARTITION BY category_id
ORDER BY price
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
) t;
6.5 other functions
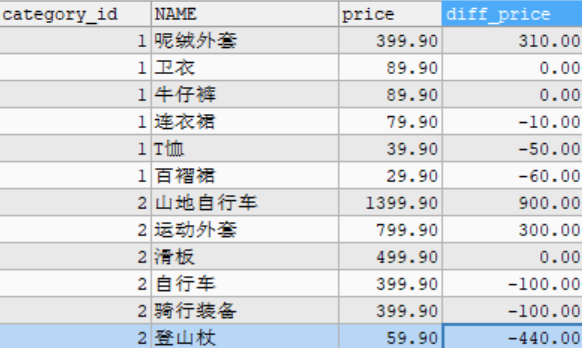
- NTH_VALUE(expr,n): returns the nth value of expr
# For example: sort by price and query the price difference between the current commodity and the third commodity in the goods data table.
SELECT category_id, NAME, price,
price - third_price AS diff_price
FROM (
SELECT category_id, NAME, price, NTH_VALUE(price,3) OVER w AS third_price
FROM goods WINDOW w AS (
PARTITION BY category_id
ORDER BY price DESC
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
) t;
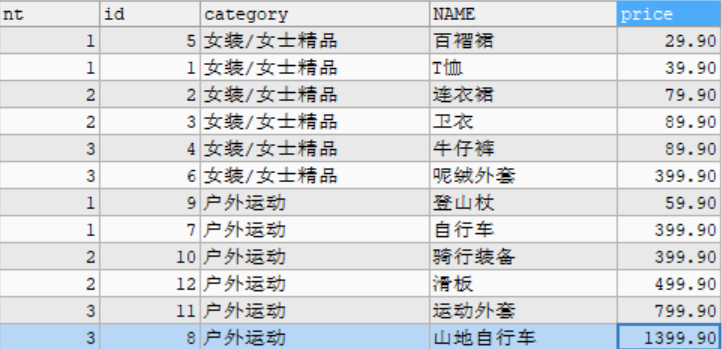
- NTILE(n): divide the ordered data in the partition into n buckets and record the bucket number
# For example: sort according to the price, and divide the goods in the goods table into three groups according to the price. SELECT NTILE(3) OVER w AS nt, id, category, NAME, price FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);