One: MySQL master-slave configuration
1: MySQL master-slave backup
1.1: Master-slave backup concept
What is master-slave backup: a database application of master-slave mode. Master data is identical with Slave data, which can realize multiple backup of data and ensure data security. Different database engines can be used in Master[InnoDB] and Slave[MyISAM] to separate reading from writing.
1.1.1: MySQL itself supports master-slave backup after version 5.5
In the old version of MySQL database system, master-slave backup is not supported and additional RPM packages need to be installed. If RPM needs to be installed, it can only be installed at one location node.
1.1.2: Master-slave backup purposes
1.1.2.1: Implementing the master-backup mode
Guarantee the security of data and try to avoid the possibility of data loss.
1.1.2.2: Separation of reading and writing
Use different database engines to achieve read-write separation and improve the efficiency of all operations. InnoDB uses DML grammar operations. MyISAM uses DQL grammar operations.
1.1.3: Master-slave backup effect
1.1.3.1: The main library operation is synchronized to the standby
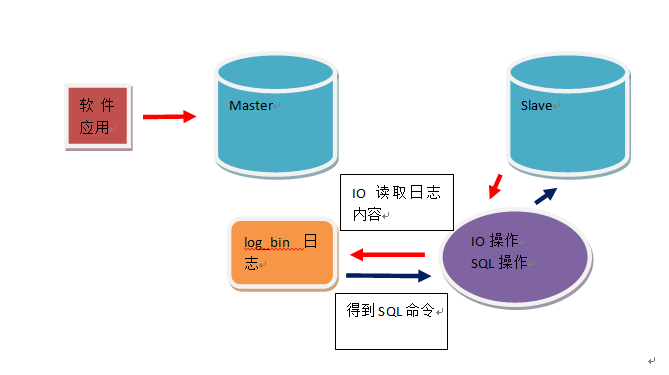
All Master operations are synchronized to Slave. If Master and Salve are naturally different environments, then the operation of Master may make mistakes in Slave, such as: before creating master-slave mode, Master has database: db1, db2, db3. Slave has database: db1, db2. Create master-slave mode. Master and Slave are different by nature. After the master-slave mode is successfully created, drop database db3. in Master. The database SQL exception is thrown in Slave, and all subsequent commands cannot be synchronized. Once an error occurs, the master-slave mode can only be re-implemented.
1.2: Install MySQL
Find: https://blog.csdn.net/qq_36297434/article/details/99185559
1.3: Master-slave backup configuration
The main operations are configuration files in Master and Slave and configuration of DBMS. Configuration file: Basic information for defining master-slave patterns. For example: log, command, etc. DBMS configuration: Provide master-slave access to users, basic information [location of Master and Slave, username, password, log file name, etc.] Suggestion: Establish multiple MySQL backups from master to slave, preferably in the same original environment. Database, table and data are identical.
1.3.1: Master [main library] configuration
1.3.1.1: Modify Master configuration file / etc/my.cnf
It needs to be modified. It is recommended that a backup file be copied before modification. The modified my.cnf configuration file refers to the following:
[client] port = 3306 default-character-set = utf8mb4 [mysqld] port = 3306 user = mysql bind-address = 0.0.0.0 server-id = 1 init-connect = 'SET NAMES utf8mb4' character-set-server = utf8mb4 skip-name-resolve skip-external-locking #skip-networking back_log = 300 max_connections = 1000 max_connect_errors = 6000 open_files_limit = 65535 table_open_cache = 128 max_allowed_packet = 4M binlog_cache_size = 1M max_heap_table_size = 8M tmp_table_size = 16M read_buffer_size = 2M read_rnd_buffer_size = 8M sort_buffer_size = 8M join_buffer_size = 8M key_buffer_size = 4M thread_cache_size = 8 query_cache_type = 1 query_cache_size = 8M query_cache_limit = 2M ft_min_word_len = 4 log_bin = mysql-bin binlog_format = mixed expire_logs_days = 10 slow_query_log = 1 long_query_time = 1 performance_schema = 0 explicit_defaults_for_timestamp lower_case_table_names = 1 default_storage_engine = InnoDB #default-storage-engine = MyISAM innodb_file_per_table = 1 innodb_open_files = 500 innodb_buffer_pool_size = 64M innodb_write_io_threads = 4 innodb_read_io_threads = 4 innodb_thread_concurrency = 0 innodb_purge_threads = 1 innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 2M innodb_log_file_size = 32M innodb_log_files_in_group = 3 innodb_max_dirty_pages_pct = 90 innodb_lock_wait_timeout = 120 bulk_insert_buffer_size = 8M myisam_sort_buffer_size = 8M myisam_max_sort_file_size = 10G myisam_repair_threads = 1 interactive_timeout = 28800 wait_timeout = 28800 [mysqldump] quick max_allowed_packet = 16M [myisamchk] key_buffer_size = 8M sort_buffer_size = 8M read_buffer = 4M write_buffer = 4M
1.3.1.1.1: server-id
In this environment, server-id is 1, MySQL service unique identity, unique identity is the natural number, there are requirements when configuring.
1.3.1.1.1.1: Single-machine use
Any server-id configuration, as long as the number can be
1.3.1.1.1.2: Master-slave use
Ser-id Master Unique Identification Number must be less than Slave Unique Identification Number.
1.3.1.1.2: log_bin
log_bin value in this environment: master_log, log file name, open log function. This log is a command log. It records all the SQL commands executed in the main library.
1.3.1.1.2.1: Open logs
MySQL log_bin is not execution log, status log. It is operation log. It is not necessary for all SQL commands in DBMS. It is only necessary to configure master-slave backup.
1.3.1.1.2.2: Log file configuration
The value of the variable is the name of the log file. It is the body of the log file name. MySQL database automatically adds file name suffixes and file types.
1.3.1.2: Restart MySQL
CentOS6:service mysqld restart CentOS7:systemctl restart mysqld.service
1.3.1.3: Configure Master
1.3.1.3.1: Access MySQL
mysql -uusername -ppassword
1.3.1.3.2: Creating Users
In MySQL database, authorization for non-existent users is to create users synchronously and authorize them. This user is the user who accesses the main library from the library. The ip address cannot be written as% because the user currently created in the master-slave backup is used by Slave to access the master library Master. Users must have a specified access address, not a generic address.
grant all privileges on *.* to 'username'@'ip' identified by 'password' with grant option; flush privileges; //I use the following: grant all privileges on *.* to 'slave'@'192.168.199.133' identified by 'slave' with grant option; flush privileges;
1.3.1.3.3: View Users
use mysql; select host, name from user;
1.3.1.3.4: View Master Information
show master status;
1.3.2: Slave [slave library] configuration
1.3.2.1: Modify Slave configuration file/etc/my.cnf
1.3.2.1.1: server_id
Unique ID, configured in this environment: 2
1.3.2.1.2: log_bin
You can use default configurations or annotations.
1.3.2.2: Optional: Modify uuid
Master-slave mode requires that multiple MySQL physical names should not be the same, that is, according to the physical flag generated automatically by Linux in the process of installing MySQL, the only physical flag is named uuid. The storage location is the data storage location of the MySQL database. By default, it is in the / var/lib/mysql directory and the file name is auto.cnf. Modify the UUID data in auto.cnf file at will. It is not recommended to change the length of the data. It is suggested to change the content of the data.
1.3.2.3: Restart MySQL Service
CentOS6: service mysqld restart CentOS7: systemctl restart mysqld.service
1.3.2.4 Configure Slave
1.3.2.4.1 Access mysql
mysql -uusername -ppassword
1.3.2.4.2: Stop Slave functionality
stop slave
1.3.2.4.3: Configure the main library information
The data needed to be modified is based on Master information. IP is the IP of Master's physical machine. User name and password are Slave access user name and password provided by Master. The log file is provided by the main library information viewed in Master: use the command show master status to view the log file name and position in Master.
change master to master_host='ip', master_user='username', master_password='password', master_log_file='log_file_name',MASTER_LOG_POS=position; //I am as follows: change master to master_host='192.168.126.21', master_user='slave', master_password='slave', master_log_file='master_log.000001',MASTER_LOG_POS=2159;
1.3.2.4.4: Start Slave
start slave;
1.3.2.4.5: View Slave configuration
show slave status \G;
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.120.139
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-log.000001
Read_Master_Log_Pos: 427
Relay_Log_File: mysqld-relay-bin.000002
Relay_Log_Pos: 591
Relay_Master_Log_File: master-log.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 427
Relay_Log_Space: 765
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0 Last wrong IO Request number
Last_IO_Error:
Last_SQL_Errno: 0 Last wrong execution SQL Command number.
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 9ee988ac-8751-11e7-8a95-000c2953ac06
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00 sec)
1.3.3: Test group from
Create a database in Master to see if it will be synchronized to Slave.
1.4: Logic Diagram in Master-Slave Mode
II: MySQL+MyCat sub-database sub-table
1: Introduction to MyCat
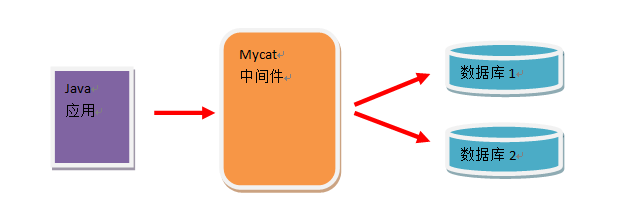
Java-written database middleware, MyCat runtime environment needs JDK. Mycat is middleware. It runs between code application and MySQL database. After using MyCat, all SQL statements written must strictly comply with the standard specification of SQL. The structure of MyCat middleware is as follows:
2: MyCat Terminology
2.1: segmentation
Logical segmentation. At the physical level, it is achieved by using multi-database and multi-table.
2.1.1: Longitudinal Segmentation
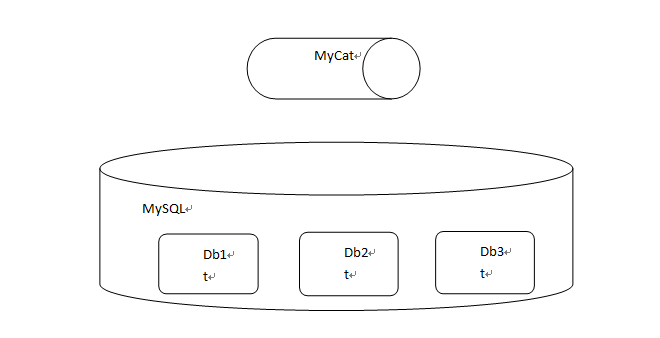
Dividing a database into several databases makes it easy to configure and can only realize table join query of two tables. The data in a table is dispersed into the same structure tables of several databases. The data set of multiple tables is the data of the current table.
2.1.2: Horizontal segmentation
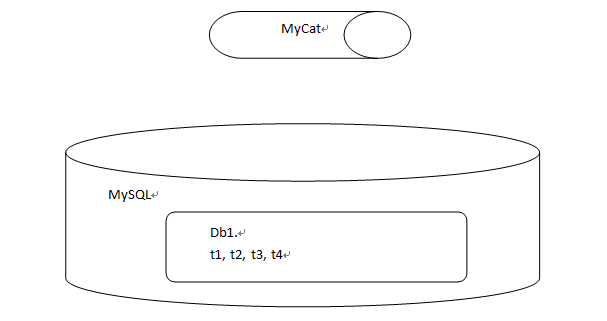
Dividing a table into multiple tables makes it more difficult to query table joins than vertical tangent. It is the complete data of the current table that the fields of a table are dispersed into several tables and several tables are joined together.
2.2: Logic Library
The database defined in MyCat exists logically, but not physically. This paper mainly focuses on the concept of vertical segmentation. To visit MyCat is to use MyCat as MySQL. Db database is defined in MyCat. When accessing DB libraries in MyCat through SQL, it corresponds to db1, DB2 and db3 libraries in MySQL. The physical database is db1, db2, db3. The logical database is db.
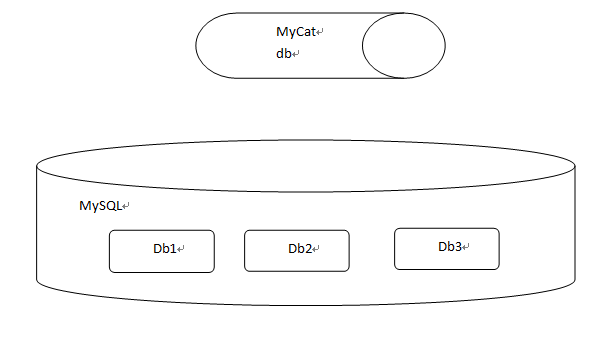
2.3: Logic Table
The table defined in Mycat exists logically, but not physically. It mainly aims at the concept of horizontal segmentation. The tables in MyCat, whose fields are scattered in tables 1, 2 and 3 of MySQL database.
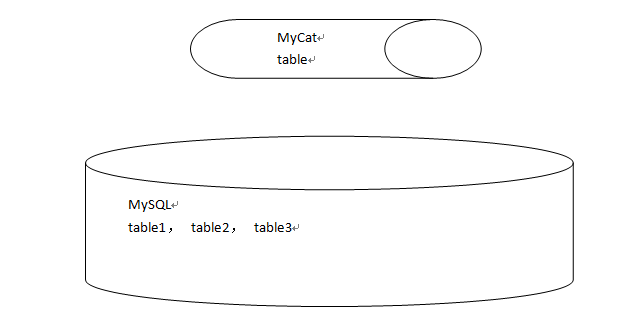
2.4: Default port
MyCat default port is 8066
2.5: Data Host
Physical MySQL hosting address. Host name, IP, domain name definition can be used.
2.6: Data Node - dataNode
What is a physical database? The physical node for data storage. That's database.
2.7: Fragmentation rule
How to access physical database s and table s when controlling data. It's an algorithm for accessing dataHost and dataNode. How to access the algorithms of dataHost and dataNode when MCAT processes specific data CRUD? For example: Hash algorithm, crc16 algorithm and so on.
3: Mycat Construction
3.1: Install JDK
Simple operation, self-Baidu.
3.2: Master-slave backup is completed
See above
3.4: Master provides users accessible by Mycat
Access Master database through root user of Master database in MCAT.
grant all privileges on *.* to 'username'@'ip' identified by 'password' with grant option;
3.5: Upload mycat
Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
3.6: Decompression
tar -zxf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
3.7: Mycat Profile Details
All Mycat configuration files are in the conf directory of the application.
3.7.1: rule.xml
Configuration files for defining fragmentation rules. Mainly view, rarely modify. mycat default fragmentation rules: 5 million as a unit to achieve fragmentation rules. Logic library A corresponds to dataNode-db 1 and db2.1-5 million saved in db1, 5 million to 10 million saved in db2, 10 million to 15 million saved in db1, and so on.
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
crc32slot rule: When CRUD is operated, the data should be stored in which dataNode according to the crc32 algorithm of specific data. The algorithm is similar to modular operation.
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
3.7.2: schema.xml
Configuration files for defining logical libraries and logical tables. In configuration files, information such as read-write separation, logical libraries, logical tables, dataHost,dataNode can be defined. Configuration file interpretation:
3.7.2.1: Label schema
Label of Configuration Logic Library
3.7.2.1.1: attribute name
Logical Library Name
3.7.2.1.2: Attribute checkSQL schema
Whether to detect schema information in SQL grammar. For example: Mycat logical library name A, dataNode name B.
For example, MyCat executes SQL: select * from A. table;
The checkSQL schema value is true, and the SQL that Mycat sends to the database is:
select * from table;
The checkSQL schema value is false, and the SQL of the database sent by Mycat is:
select * from A.table;
3.7.2.1.3: sqlMaxLimit
When Mycat executes SQL, if there is no limit clause in the SQL grammar. Automatically add limit clause. Avoid getting too much data at one time, which affects efficiency. The limit clause is configured to be 100 by default. If there is a specific limit clause in SQL, the current attribute is invalid.
SQL: select * from table; after MYCAT parses: select * from table limit 100 SQL: select * from table limit 10; MYCAT does not modify anything.
3.7.2.2: Tag table
Define labels for logical tables, and write multiple table labels if multiple logical tables need to be defined. The table names of logical tables are required to be consistent with those of physical tables (real tables in MySQL database).
3.7.2.2.1: attribute name
Logical table name
3.7.2.2.2: Attribute dataNode
Data node names. Labels that need to be defined later in the configuration file (i.e. database names in physical databases). Multiple names are separated by commas. After multiple database definitions, they represent the repository.
3.7.2.2.3: Attribute rule
Fragmentation rule name. Specific rule name refers to rule.xml configuration file. After the SQL statement is sent to Mycat, how does Mycat calculate which physical database management system or physical database should the current SQL be sent to?
3.7.2.3: Label dataNode
Define the label of the data node and the specific physical database information.
3.7.2.3.1: attribute name
The name of the data node, which is the logical name defined, corresponds to the specific physical database database.
3.7.2.3.2: Attribute dataHost
Refer to the name value of the dataHost tag to represent the location and configuration information of the physical database used.
3.7.2.3.3: Attribute database
In the dataHost physical machine, the specific physical database database database name.
3.7.2.4: dataHost tag
Define the label of the data host, which is where the physical MYSQL is actually installed.
3.7.2.4.1: attribute name
Define the logical name of the data host
3.7.2.4.2: Attribute maxCon/minCon
max connections
Minimum connection number, min connections
3.7.2.4.3: Attribute dbType
Database type: mysql database
3.7.2.4.4: Attribute dbDriver
The database driver type, native, uses the local driver provided by mycat.
3.7.2.5: dataHost subtag writeHost
The database definition tag of write data is used to realize read-write separation.
3.7.2.5.1: Attribute host
Database Naming
3.7.2.5.2: attribute url
Database access path
3.7.2.5.3: Attribute user
Database Access User Name
3.7.2.5.4: Attribute password
Access User Password
3.7.2.6: Test configuration file
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_user" dataNode="dn1,dn2,dn3" rule="crc32slot" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.11.138:3306" user="root"
password="root"/>
</dataHost>
</mycat:schema>
3.7.3: server.xml
Configure Mycat service information. For example: Mycat users, users can access the logical library, can access the logical table, the port number of services and so on. Common modifications:
<property name="serverPort">8066</property> <!-- Mycat Service port number -->
<property name="managerPort">9066</property><!-- Mycat Management port number -->
<user name="root"><!-- mycat User name -->
<property name="password">Password</property>
<property name="schemas">User Access Logic Library Name</property>
<!-- Table level DML Permission settings -->
<!-- Do not check permissions
<privileges check="false">
<schema name="Logical library name" dml="0110" >
<table name="Logical table name" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user"><!-- Other usernames -->
<property name="password">Password</property>
<property name="schemas">Accessible Logical Library Name</property>
<property name="readOnly">readOnly</property>
</user>
3.7.4: Start the Mycat command
bin/mycat start
3.7.5: Stop Order
bin/mycat stop
3.7.6: Restart order
bin/mycat restart
3.7.7: View Mycat status
bin/mycat status
3.7.8: Access Mode
You can use command line access or client software access.
3.7.8.1: Command-line access
Mysql-u username-p password-hmycat host IP-P8066
Once the link is successful, it can be used as a MySQL database. Once the access is successful, it cannot be used directly. Because Mycat can only access the schema (database) of MYSQL, it can not automatically create the physical library corresponding to the logical library. The physical tables corresponding to logical tables cannot be created automatically. The master database must be manually linked to create the database manually. Tables can be created in the MYCAT console. Note: The tables created in the MYCAT console must be logical tables defined in the schema.xml configuration file. After startup, after testing, the crc32slot fragmentation rule is invalid, and only db1 and db2 can be recognized when executing DML statements. DDL statement, you can identify db3. Modify the conf/rule.xml configuration file to find tags:
<function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot"> <property name="count">2</property><!--The number of database nodes to be fragmented must be specified, otherwise it cannot be fragmented--> </function>
Modify the count parameter. Modify to the corresponding number of physical database s.
Note: When using crc32slot fragmentation rules, it is necessary to set up fragmentation rules before starting mycat. If MYCAT is started first and then the fragmentation rules are set, the fragmentation rules will be invalid. The ruledata subdirectory in the conf directory needs to be deleted. The fragmentation node of crc32slot is recorded in the rule data directory, and the log file naming rule is crc32slot_table name.
3.7.9: Access Constraints
3.7.9.1: Table Constraints
Cannot create logical tables that are not configured in schema.xml
3.7.9.2: DML constraints
Especially new: All field names must be carried after insert into grammar. At least the primary key name. Because of the fragmentation rule, most of the data fragmentation rules are calculated through the primary key field.
3.7.10 Check Mycat logs
logs/wrapper.log, which records all mycat operations. Look at the exception information caused by information.
Three: MyCat Configuration Read-Write Separation
Modify the conf/schema.xml configuration file as follows:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_user" dataNode="dn1,dn2,dn3" rule="crc32slot" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.11.138:3306" user="root"
password="root">
<readHost host="hostS2" url="192.168.1.139:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
Fourth: MyCat Configuration Database Cluster
All cluster configurations must be in multi-master and multi-slave mode. That is, multiple master nodes configure master and slave to each other. For example, master 1 and slave 1 are the first group of masters and slaves, Master 2 and slave 2 are the second group of masters and slaves, and master 1 and master 2 are each other's masters and slaves.
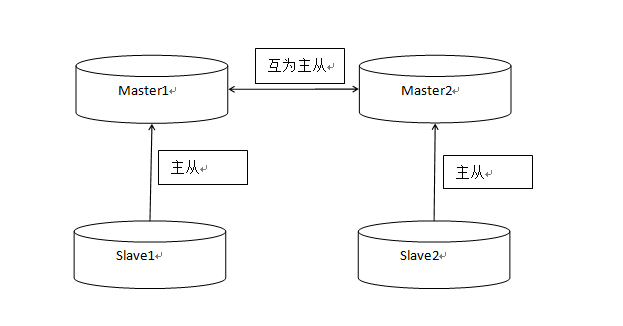
Five: Database Cluster Load Strategy
1: Configuration scheme
1.1: The first option (possible IO delay)
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_user" dataNode="dn1,dn2,dn3" rule="crc32slot" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.126.21:3306" user="root"
password="root">
<readHost host="hostS2" url="192.168.126.22:3306" user="root" password="root" />
</writeHost>
<writeHost host="hostM1" url="192.168.126.23:3306" user="root"
password="root">
<readHost host="hostS2" url="192.168.126.24:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
1.2: The second configuration
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB1" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_user" dataNode="dn1,dn2,dn3" rule="crc32slot" />
<table name="t_admin" dataNode="dn4,dn5,dn6" rule="crc32slot1" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost2" database="db1" />
<dataNode name="dn5" dataHost="localhost2" database="db2" />
<dataNode name="dn6" dataHost="localhost2" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="192.168.126.21:3306" user="root"
password="root">
</writeHost>
<writeHost host="hostS1" url="192.168.126.22:3306" user="root" password="root" />
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM2" url="192.168.126.23:3306" user="root"
password="root">
</writeHost>
<writeHost host="hostS2" url="192.168.126.24:3306" user="root" password="root" />
</dataHost>
</mycat:schema>
Note: In mycat, the fragmentation rules defined in the rule.xml configuration file can only be used for one table. If multiple tables use the same fragmentation rule, you need to define a fragmentation rule for each table in the rule.xml configuration file. Such as:
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot1">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
2: Attribute Explanation
2.1: balance attribute
balance="0", without opening the read-write separation mechanism, all read operations are sent to the currently available writeHost.
balance="1", all readHost and stand by writeHost participate in load balancing of select statements.
balance ="2", all reading operations are randomly distributed on writeHost and readhost.
balance ="3", all read requests are randomly distributed to the readhost corresponding to the writeHost to execute, and the writerHost does not bear reading pressure.
2.2: writeType attribute
writeType="0". All write operations are sent to the first writeHost in the configuration. The first writeHost is hung to the second surviving writeHost. After restarting, the switching records are recorded in the configuration file: conf/dnindex.properties (data node index).
writeType="1", all write operations are randomly sent to the configurable writeHost, and discarded after 1.5 is not recommended.
2.3: switchType attribute
It also involves the separation of read and write, which can solve the problem of IO delay.
switchType='-1'means no automatic switching
The default value of switchType='1'indicates automatic switching
switchType='2'determines whether to switch between read and write hosts based on the status of MySQL master-slave synchronization. The heartbeat statement is show slave status. When IO delays are detected in heartbeat monitoring data, the read operation is automatically located in the writeHost. If there is no IO delay in heartbeat monitoring data, the read operation is automatically located in the readHost. It is recommended that different dataHost nodes be located for different tables.