MySQL high availability scheme
Low read and write concurrency and low data volume scheme
Scheme I: dual computer high availability scheme
(1) Database schema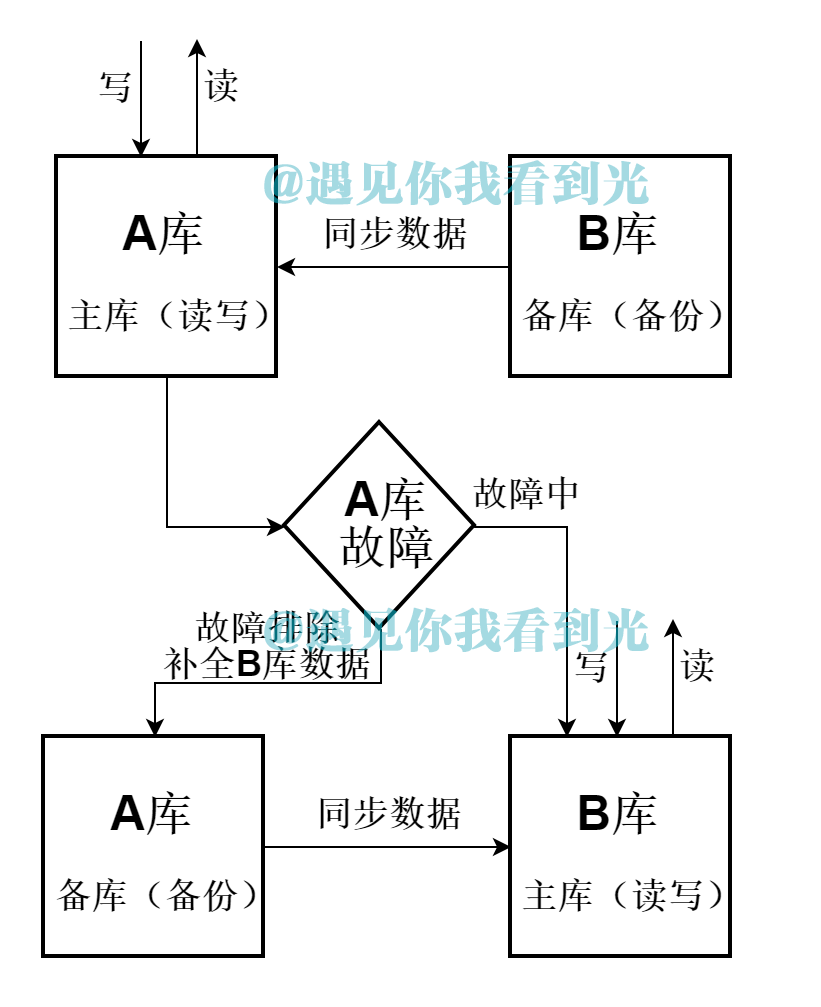
(2) Features
One machine A is used as the read-write library, the other B is used as the backup library; Library B is used as the read-write library after the failure of library A; library A is used as the backup library after the recovery of Library A.
(3) Development instructions
In this case, the virtual IP address can be used for the database IP address in the data source configuration. The virtual IP address is configured by keepalive on two database machines, and heartbeat is detected between them. When one of them fails, the virtual IP address will automatically drift to another normal library.
http://lizhenliang.blog.51cto.com/7876557/1362313
http://gaoke.iteye.com/blog/2283890
(4) Adapt to the scene
In the scenario where both reading and writing are not high (single table data is less than 5 million), dual computers are highly available.
(5) Advantages and disadvantages
The advantage is that when a machine fails, it can switch automatically; the disadvantage is that there is only one library working, the read and write are not separated, and the concurrency is limited.
Scheme II: master-slave structure scheme
(1) Database schema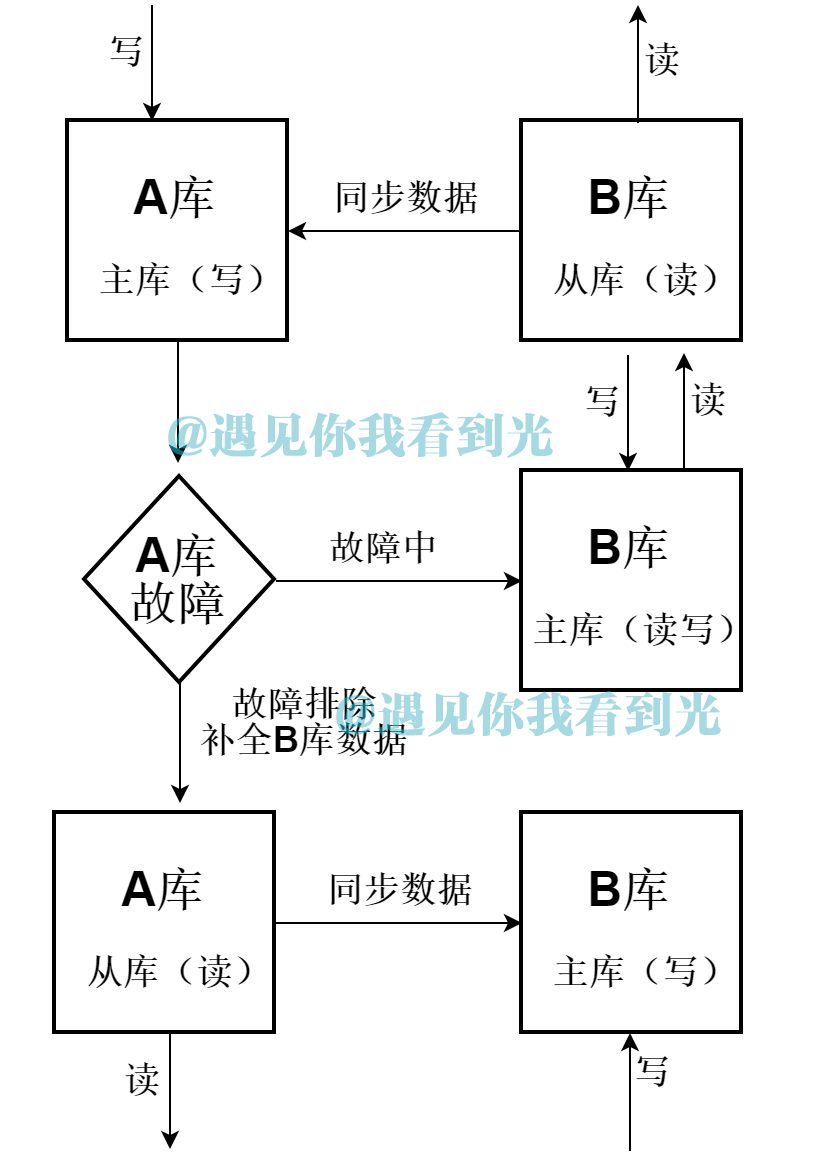
(2) Features
One machine A is used as the write library, the other B is used as the read library; Library B is used as the read-write library after the failure of library A, Library B is used as the write library after the repair of library A, and library A is used as the read library.
(3) Development instructions
The implementation of this scheme needs to be realized with the help of the database middleware Mycat. The datahost configuration of Mycat is as follows (note the settings of balance and writetype)
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!--Master, for writing--> <writeHost host="hostM1" url="192.168.1.135:3306" user="root" password="123" /> <!--Main 2, for reading,hostM1 down It's automatic switching. It can read and write--> <writeHost host="hostM2" url="192.168.1.136:3306" user="root" password="123" /> </dataHost>
In project development, Mycat data source should be configured and data operation to Mycat data source should be realized. Database A and database B should be master and slave to each other. The main configuration, troubleshooting and data completion of the database still need DBA and operation and maintenance personnel to maintain.
(4) Adapt to the scene
Reading and writing are not very high scenarios (single table data is less than 10 million), highly available. It is much higher than the concurrency of scheme I.
(5) Advantages and disadvantages
The advantage is that when a machine breaks down, it can switch automatically; read and write are separated, and concurrency is greatly improved. The disadvantage is that a MYCAT node is introduced, and at least two MYCAT nodes need to be introduced for high availability. The general solution is to introduce haproxy and keepalive to cluster MYCAT.
High read and low write concurrency and low data volume scheme
Scheme 3: one master and many slaves + read-write separation
(1) Database schema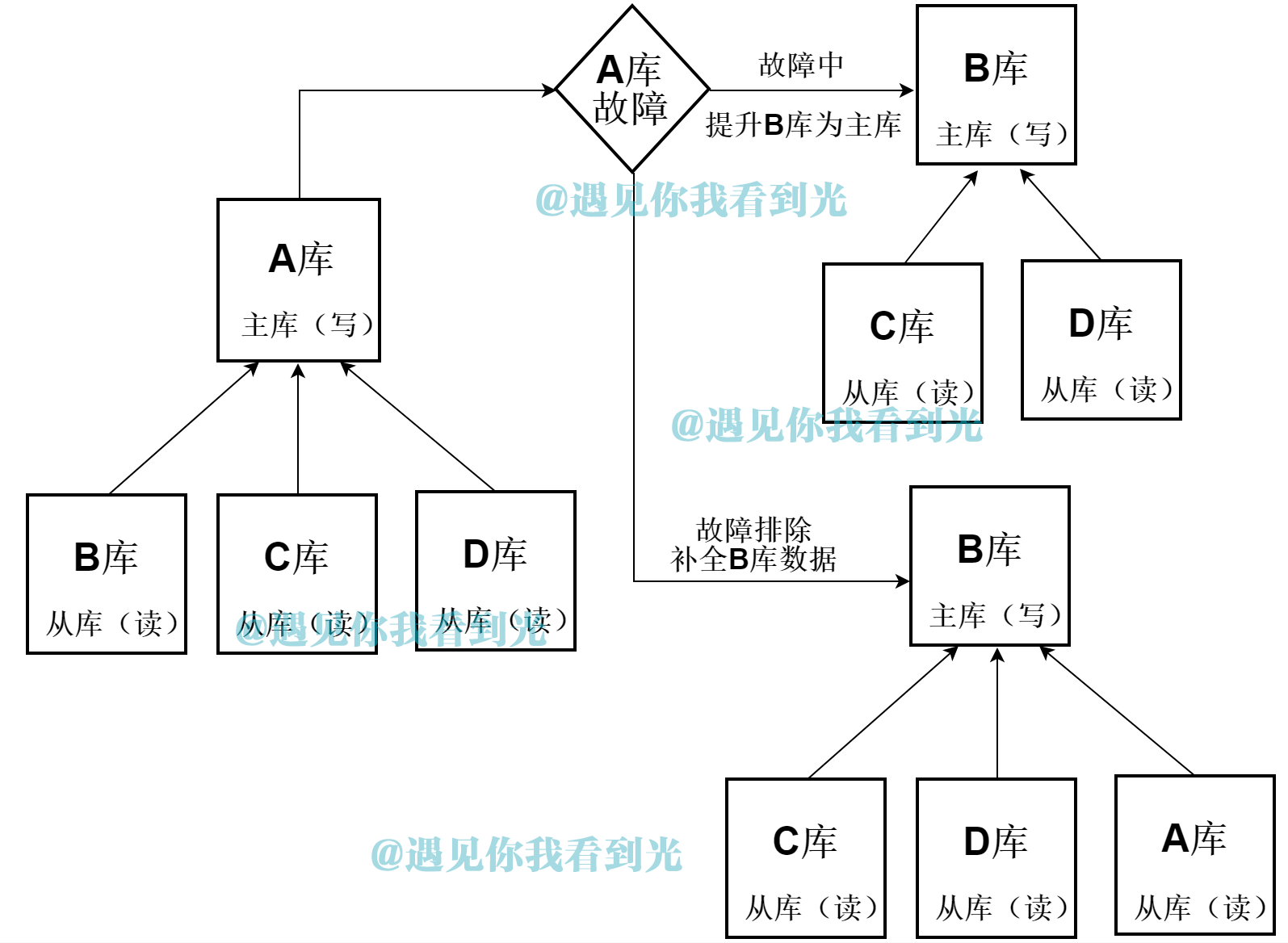
(2) Features
There are multiple slave databases in a primary write library A. when the primary write library a fails, upgrade the slave database B to the primary write library, and modify the C and D databases to the slave database B. After a fault is repaired, it is used as the slave Library of B.
(3) Development instructions
In the project development, Mycat needs to be used as the middleware to configure the master database and the slave database. The core configuration is as follows:
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!--main A,Used for writing--> <writeHost host="hostM1" url="192.168.1.135:3306" user="root" password="123" /> <!—from B,Used for reading,hostM1 down Yes, automatic switching--> <writeHost host="hostM2" url="192.168.1.136:3306" user="root" password="123456" /> <!—from C,Used for reading--> <writeHost host="hostM3" url="192.168.1.137:3306" user="root" password="123" /> <!—from D,Used for reading--> <writeHost host="hostM4" url="192.168.1.138:3306" user="root" password="123" /> </dataHost>
After the main library A fails, Mycat will automatically upgrade from B to write library. While C and D slave libraries can be automatically modified to B through MHA and other tools. And then realize the destination of automatic switching.
MHA Manager can be deployed on a single machine to manage multiple master slave clusters, or on a slave node. The MHA Node runs on each MySQL server, and the MHA Manager will regularly detect the master node in the cluster. When the master fails, it can automatically promote the slave of the latest data to the new master, and then point all other slave to the new master again. The entire failover process is completely transparent to the application.
(4) Adapt to the scene
This architecture is suitable for very large scenarios with low write concurrency but high read concurrency
(5) Advantages and disadvantages
Due to the configuration of multiple read nodes, the ability of read concurrency has been improved. Theoretically, there can be multiple read nodes, which can load a high level of read concurrency. Of course, Mycat still needs to design a highly available solution.
High read-write concurrency and low data volume scheme
Scheme four: MariaDB Galera Cluster scheme
(1) Database schema
(2) Features
Multiple databases can be written and read at the same time under the function of load balancing. Among the databases, the
Method to synchronize data, that is to say, the data of each database is completely consistent in theory.
(3) Development instructions
When reading and writing a database, you only need to modify the virtual node whose reading and writing IP is keepalive. The database configuration is relatively complex
Miscellaneous, various plug-ins and configurations such as haproxy, keepalive, Galaera need to be introduced.
(4) Applicable scenarios
This scheme is suitable for scenarios with large read-write concurrency and small data volume.
(5) Advantages and disadvantages
Advantage:
1) Can be read on any node 2) Automatic removal of faulty nodes 3) Auto join new node 4) True parallel replication, based on row level 5) The experience of client connection is consistent with that of operation sheet database 6) Synchronous replication for high performance and reliability
Disadvantages:
1) DELETE operation does not support tables without primary key. Tables without primary key will have different order in different nodes 2) When processing a transaction, a coordination authentication program will be run to ensure the global consistency of the transaction. If the transaction runs for a long time, all related tables in the node will be locked, resulting in stuck insertion (this is the same as single table insertion) 3) The write throughput of the whole cluster is limited by the weakest node. If one node becomes slow, the whole cluster will be slow. For stable and high performance requirements, all nodes should use unified hardware 4) If there is a problem with the DDL statement, it will destroy the cluster. It is recommended to disable 5) Mysql database 5.7.6 and later supports this scheme
High read / write concurrency and high data volume scheme
Scheme 5 database middleware
(1) Database schema
(2) Features
Using Mycat for partition storage can solve the problem of write load balance and too much data; each partition is configured with multiple read-slave databases, which can reduce the reading pressure of a single library.
(3) Development instructions
In this case, Haproxy, keepalive and mycat clusters need to be configured, and each partition needs to be configured with a primary and multiple secondary cluster. For the complete configuration on each partition, please refer to scheme 3 for details. Scheme 3 can be simply understood as a partition structure. Therefore, the amount of configuration and maintenance is large.
(4) Applicable scenarios
Scenarios with large read-write concurrency and large amount of data.
(5) Advantages and disadvantages
Advantages: the ultimate solution to high concurrency and data volume.
Disadvantages: configuration and maintenance are troublesome, requiring a large number of hardware and software equipment resources.
MySQL replication technology
MySQL master-slave replication concept
MySQL master-slave replication means that data can be copied from a MySQL database server master node to one or more slave nodes. MySQL uses asynchronous replication by default, so that the slave node does not need to visit the master server all the time to update its data. The data can be updated on a remote connection. The slave node can copy all databases or specific databases or specific tables in the master database.
Main purpose of MySQL master-slave replication
(1) Separation of reading and writing
In the development work, sometimes an sql statement needs to lock the table, resulting in the temporary inability to use the read service, which will affect the existing
For business, master-slave replication is used to make the master database write and the slave database read. In this way, even if the master database is locked, the master database can read from the slave database
It can ensure the normal operation of the business.
(2) Data real-time backup, when a node in the system fails, it can facilitate the failover
(3) High availability HA
With the increase of business access in the system, if the database is deployed on a single machine, the frequency of I/O access will be too high. With master-slave replication, multiple data storage nodes are added, the load is distributed on multiple slave nodes, the frequency of I/O access of single disk is reduced, and the I/O performance of a single machine is improved.
Reset database:
service mysqld stop rm -rf /usr/local/mysql/data/* #Initialize mysql mysql_secure_installation #Modify uuid vim /usr/local/mysql/data/auto.cnf
Principle of mysql master-slave replication
(1) The IO thread on the Slave connects to the Master and requests the log content after the specified location (or the first log) of the specified Binary log file;
(2) After the Master receives the request from the IO thread of Slave, it reads the log information after the specified log location through the IO thread responsible for copying according to the request information and returns it to the IO thread of Slave. In addition to the information contained in the log, the returned information also includes the name of the Binary log file on the Master side and its location in the Binary log;
(3) After receiving the information, the IO thread of Slave writes the received log content to the end of the RelayLog file (mysql-relay-lin.xxxxx) on the Slave side, and records the file name and location of the bin log on the master side to the master info file, so that the next time I read it, I can clearly tell the master "where do I need to start a bin log?" Please send me the contents of future logs "
(4) Relay detected by SQL thread of Slave After the new content is added to the Log, the content in the Log file will be parsed as the executable query or operation statement when the master is actually executing, and the query or operation statement will be executed by itself. In fact, the same query or operation statement is executed at the master and Slave, so the data at both ends is exactly the same.
In the main warehouse:
Binlog output thread. Whenever a slave database is connected to the master database, the master database will create a thread and send binlog content to the slave database. For each sql event to be sent to the slave database, the binlog output thread locks it. Once the event is read by the thread, the lock will be released, even when the event is completely sent to the slave library.
In the slave database, when replication starts, two threads will be created for processing:
From the library I/O thread. After the START SLAVE statement is executed from the database, an I/O thread is created from the database. The thread connects to the main database and requests the main database to send the update records in the binlog to the slave database. Read the updates sent by the binlog output thread of the main library from the library I/O thread and copy them to the local file, including the relay log file.
SQL thread from the library. Create a SQL thread from the library, which reads and executes the update events written to the relay log from the library I/O thread.
As you can see, there are three threads for each master-slave replication connection. The master database with multiple slave databases creates a binlog output thread for each slave database connected to the master database. Each slave database has its own I/O thread and SQL thread. By creating two independent threads from the library, the read and write from the library are separated when copying. Therefore, even if the thread responsible for execution runs slowly, the thread responsible for reading the update statement does not slow down. For example, if the slave database hasn't been running for a while, when it starts here, its I/O thread can quickly read all binlog contents from the main database, even though its SQL thread is slow to execute. In this way, even if the slave database stops running before the SQL thread finishes executing all the read statements, the I/O thread at least reads all the contents completely, and backs it up safely in the relay log local to the slave database, ready to execute the statements at the next start of the slave database at any time.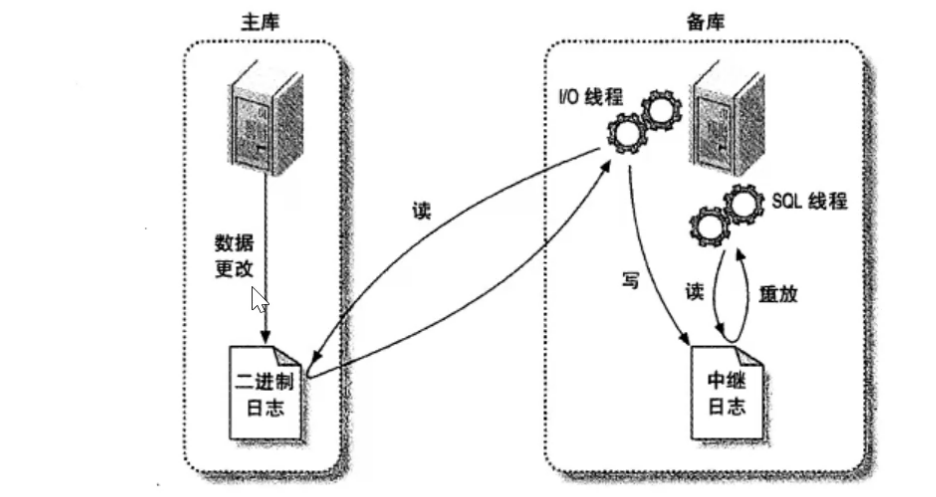
- Record data changes to Binary Log on the main database.
- The standby database copies the logs on the primary database to its Relay Log.
- The standby database reads the events in the relay log and puts them back on the standby database.
Master-slave replication implementation
The primary / standby databases are just the initial ones
Single master to multi standby: Master multislave
(1) Node planning
| Host | IP | Server_ID |
|---|---|---|
| Master: mysql | 192.168.213.124 | 1 |
| Slave1: mysql-1 | 192.168.213.127 | 2 |
| Slave2: mysql-2 | 192.168.213.128 | 3 |
(2) Initialize environment
Synchronization time
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
hwclock --systohc
Turn off firewall
systemctl stop firewalld systemctl disable firewalld sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0
(2) Configure main library
Modify the master database configuration file: turn on the log bin function and specify the server [ID] as 1. Here, log bin must be specified. Otherwise, the bin log will be named according to the host name. If the host name of the master database changes, the master-slave replication will fail
vim /etc/my.cnf [mysqld] server_id=1 log-bin=mysql-bin log-bin-index=master-bin.index
Restart service
[root@localhost ~]# systemctl stop mysqld [root@localhost ~]# systemctl start mysqld
Create a user to connect from the database (note that Mysql8 is licensed differently from the old version)
mysql> create user 'copy'@'%' identified with mysql_native_password by 'Cloudbu@123'; mysql> grant replication slave on *.* to 'copy'@'%'; mysql> flush privileges; Refresh authorization table information
Test whether the user's client can log in normally on the slave database
[root@mysql-1 ~]# mysql -h192.168.213.124 -ucopy -pCloudbu@123
Get the current binary log file name and position of the primary node
[root@mysql ~]# mysql -uroot -pCloudbu@123 mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 825 | | | | +------------------+----------+--------------+------------------+-------------------+
(4) Configure the slave database (the configuration method of the two slave databases is the same, only the server? ID in the configuration file needs to be modified)
To modify the configuration file, you must specify the name of the relay log
[mysqld] server_id=2 relay-log=relay-log relay-log-index=relay-log.index [root@localhost ~]# systemctl stop mysqld [root@localhost ~]# systemctl start mysqld
Set master parameters on Slave node
[root@mysql-1 ~]# mysql -uroot -pZhao123@com mysql> CHANGE MASTER TO MASTER_HOST='192.168.213.124',#IP address of the main library MASTER_USER='copy', #Copy account created on the main database MASTER_PASSWORD='Cloudbu@123',#Copy account password created on the main database MASTER_LOG_FILE='mysql-bin.000001',#The name of the binary file to start copying (obtained from the main library query result //Take) MASTER_LOG_POS=825;#Location of the binary file to start copying (obtained from the main library query results //Take)
Start master slave synchronization start slave;
View master slave synchronization status
mysql> show slave status\G` Slave_IO_Running: Yes Slave_SQL_Running: Yes #If both IO thread and SQL thread are YES, the configuration is successful
(5) Testing
If a database is created on the main database and the content of the created database can be synchronized on the repository, the data synchronization is successful
[root@mysql ~]# mysql -uroot -pZhao123@com mysql> create database bbs; Query OK, 1 row affected (0.01 sec) mysql> create table bbs.t1(id int); Query OK, 0 rows affected (0.00 sec) mysql> insert into bbs.t1 value(1); Query OK, 1 row affected (0.08 sec) mysql> select * from bbs.t1; +------+ | id | +------+ | 1 | +------+ 1 row in set (0.00 sec)
View whether the data created on the main library exists from the library
[root@mysql-1 ~]# mysql -uroot -pZhao123@com mysql> show databases; +--------------------+ | Database | +--------------------+ | bbs | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.01 sec) mysql> select * from bbs.t1; +------+ | id | +------+ | 1 | +------+ 1 row in set (0.00 sec) #If the creation content exists, data synchronization succeeds
Implement active / standby for the main database that has been running for a period of time
Single master to multi standby: Master multislave
(1) Node planning
| Host | IP | Server_ID |
|---|---|---|
| Master: mysql | 192.168.213.124 | 1 |
| Slave1: mysql-1 | 192.168.213.127 | 2 |
| Slave2: mysql-2 | 192.168.213.128 | 3 |
(2) Initialize environment
Synchronization time
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
hwclock --systohc
Turn off firewall
systemctl stop firewalld systemctl disable firewalld sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0
(3) Configure main library
Modify the master database configuration file: turn on the log bin function and specify the server [ID] as 1. Here, log bin must be specified. Otherwise, the bin log will be named according to the host name. If the host name of the master database changes, the master-slave replication will fail
vim /etc/my.cnf [mysqld] server_id=11 log-bin=mysql-bin log-bin-index=master-bin.index
Restart service
[root@localhost ~]# systemctl stop mysqld [root@localhost ~]# systemctl start mysqld
Create a user to connect from the database (note that Mysql8 is licensed differently from the old version)
mysql> create user 'copy'@'%' identified with mysql_native_password by 'Cloudbu@123'; mysql> grant replication slave on *.* to 'copy'@'%'; mysql> flush privileges; Refresh authorization table information
(4) Initialize the standby database (make it consistent with the primary database data): logical backup, physical backup
Back up the master database data and copy it to the slave database.
Note: lock the table before backing up data to ensure data consistency.
mysql> flush tables with read lock; [root@master ~]# mysqldump -uroot -p --default-character-set=gbk --singletransaction -F -B school |gzip > all_$(date +%F).sql.tar.gz [root@master ~]# scp all_2019-07-21.sql.tar.gz 192.168.213.127:/root [root@master ~]# scp all_2019-07-21.sql.tar.gz 192.168.213.128:/root [root@master ~]# mysql -e 'show master status'
Extract and import data from the library
[root@localhost ~]# gunzip all_2019-11-04.sql.tar.gz [root@localhost ~]# mysql -uroot -pCloudbu@123 <all_2019-07-21.sql.tar
(4) Configure from library
To modify the configuration file, you must specify the name of the relay log
[mysqld] server_id=22 relay-log=relay-log relay-log-index=relay-log.index
[root@localhost ~]# systemctl stop mysql [root@localhost ~]# systemctl start mysql
Set master parameters on Slave node
[root@mysql-1 ~]# mysql -uroot -pZhao123@com mysql> CHANGE MASTER TO MASTER_HOST='192.168.213.124', MASTER_USER='copy', MASTER_PASSWORD='Cloudbu@123', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=825;
Start master slave synchronization start slave;
View master slave synchronization status
mysql> show slave status\G` Slave_IO_Running: Yes Slave_SQL_Running: Yes #If both IO thread and SQL thread are YES, the configuration is successful
(5) Testing
#Test on the main database mysql> unlock tables; mysql> create database mmp; #View creation information on from library mysql> show databases;
Status monitoring of MySQL master-slave replication
Main parameters of master-slave condition monitoring
Slave_IO_Running: IO Whether the thread is open YES/No/NULL
Slave_SQL_Running: SQL Whether the thread is open YES/No/NULL
Seconds_Behind_Master: NULL #Number of seconds of delay to synchronize with the master
Factors that may cause master-slave delay
Whether master-slave clock is consistent Whether there is delay in network communication Is binlog enabled for slave database performance Query whether to optimize from the library
Troubleshooting common status errors
(1) Find the IO process error, check the log and troubleshoot:
[root@mysql ~]# tail /var/log/mysql-error.log ...2015-11-18 10:55:50 3566 [ERROR] Slave I/O: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. Error_code: 159
Find out the reason: since 5.6, the concept of uuid has been introduced into replication, and the server uuid in each replication structure must be different
Solution: (the slave library is the clone machine) modify the uuid of the slave Library
[root@localhost ~]# find / -name auto.cnf /var/lib/mysql/auto.cnf [root@localhost ~]# cd /var/lib/mysql/ [root@localhost ~]# rm auto.cnf [root@localhost ~]# systemctl stop mysqld [root@localhost ~]# systemctl start mysqld
(2) show slave status; Error xxx doesn't exist
resolvent:
mysql> stop slave; mysql> set global sql_slave_skip_counter = 1; mysql> start slave;
(3) Replication start failed due to Relay log
mysql> start slave; ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
From the above error report, we can know that the previous replication information is reserved in mysql.slave ﹣ relay ﹣ log ﹣ info table, so the corresponding file cannot be found when the new slave is started
Solution
mysql> reset slave; mysql> CHANGE MASTER TO ...
After restoring an instance with a cold backup, reset the slave to clear the old information before starting the slave

