2. Mysql database - index
2.1 index overview
MySQL index: it is a data structure that helps MySQL obtain data efficiently, so the essence of index is data structure!
In addition to the table data, the database system also maintains the data structures that meet the specific search algorithm. These data structures point to the data in some way, so that the advanced search algorithm can be realized on these data structures. This data structure is the index.
As shown in the following diagram:
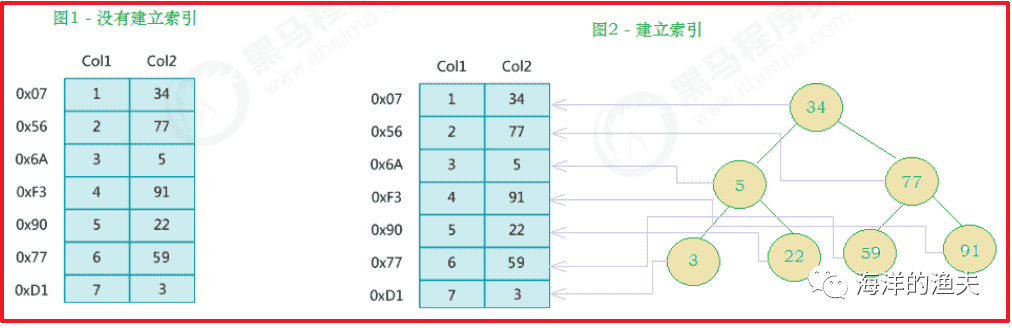
image-20200612173720877
On the left is the data table, with two columns and seven records. On the left is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used to quickly obtain the corresponding data.
Generally speaking, the index itself is too large to be stored in memory, so the index is often stored on disk in the form of index file. Index is the most commonly used tool in database to improve performance.
2.2 index strengths and weaknesses
2.2.1 advantages
1) Similar to the Catalog Index of books, it improves the efficiency of data retrieval and reduces the IO cost of the database. 2) Sort the data through the index column to reduce the cost of data sorting and CPU consumption.
2.2.2 disadvantages
1) In fact, the index is also a table, which saves the primary key and index fields and points to the records of entity classes, so the index column also takes up space. 2) Although the index greatly improves the query efficiency, it also reduces the speed of updating the table, such as INSERT, UPDATE and DELETE. When updating a table, MySQL should not only save the data, but also save the index file. Every time the field with index column is updated, the index information after the key value changes caused by the UPDATE will be adjusted.
# 1. What is the index? Data structure # 2. Advantages and disadvantages of index a. benefit: Improve query efficiency b. Disadvantages: Reduce the efficiency of addition, deletion and modification(Indexes are also tables,Maintenance is also required,Data addition, deletion and modification, Indexes are also affected,It also needs to be adjusted)
2.3 index structure
If indexes are divided by data structure, there are three common types:
- BTREE index: one of the most frequently used index data structures in MySQL is the default index type of InnoDB and MyISAM storage engines. The underlying layer is based on B+Tree data structure (mysql5.6 is used by default)
- HASH index: the index type supported by the Memory storage engine in MySQL by default.
- R-tree index (spatial index): spatial index is a special index type of MyISAM engine. It is mainly used for geospatial data types. It is usually less used and will not be introduced in particular.
It should be noted that MySQL software may use different storage engines (InnoDB is used by default), and each storage engine may support different indexes:

1595768231103
The index we usually refer to, if not specified, refers to the index organized by B+Tree (multi-channel search tree, not necessarily binary) structure.
2.3.1 principle of B + tree
- The index is implemented in the storage engine, and different storage engines support different indexes. Here we mainly introduce the BTree index of InnoDB engine
- BTree index type is based on B+Tree data structure, and B+Tree data structure is a variant of BTree data structure The file system usually used in database and operating system is characterized by maintaining data stability and order
# To understand the principle of BTree indexing, we need to learn in turn 1. Characteristics of disk storage 2. BTree Characteristics of 3. B+Tree Characteristics of
2.3.1.1 characteristics of disk storage
- When the system reads data from disk to memory, it takes disk block as the basic unit
- The data in the same disk block will be read out at one time instead of what you need
- InnoDB storage engine has the concept of page, which is the smallest unit of disk management The default size of each in the InnoDB storage engine is 16KB
- The InnoDB engine links several addresses to disk blocks to achieve a page size of 16KB. When querying data, if each data in a page can help locate the data location, it will reduce I/0 times and improve query efficiency
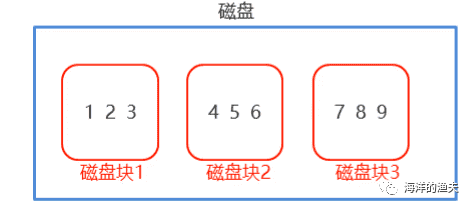
1595770094498
"For example, in the figure above, I want to query the number 5. After reading disk block 2, the system reads the data of the whole disk block 2 instead of just one 5. After reading it, it is (4,5,6), and then filter and retain 5 according to the conditions "
2.3.1.2 diagram of BTREE
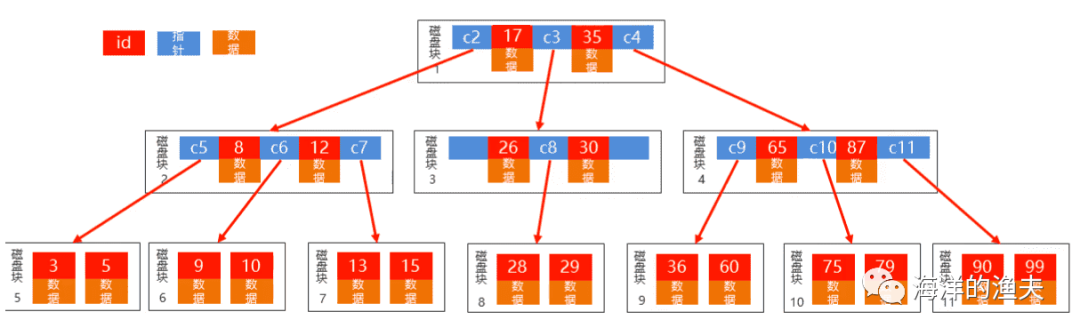
1595770311097
In the figure, we can see that under the BTree tree, this is a multi fork tree, not a separate binary tree.
Each node is equivalent to a disk block. Each disk block contains not only the key value (id and pointer in the figure above), but also data
However, if we want to query data 10, let's take a look at the query process:
- 1. Start from the root node [disk block 1] and judge whether 10 is greater than 17. If it is less than 17, go down one node from the c2 pointer
- 2. Go to [disk block 2] and query and judge that 10 is greater than 8 If it is less than 12, it will go to the c6 pointer and go down one node
- 3. Go to [disk block 6] and finally find the data with id 10.
You can see that during the overall execution process, a total of 3 queries were made.
However, the data of id 17 of [disk block 1] and the data of id 8 and id 12 of [disk block 2] are also read out in the query process, which is a waste. Because for the data that you want to read id 10, what really works is the pointer and id number.
Therefore, in order to improve efficiency, B+Tree will remove the id data in each node. Each node only retains the id and pointer, and the data is saved in the leaf node.
2.3.1.3 diagram of B + tree
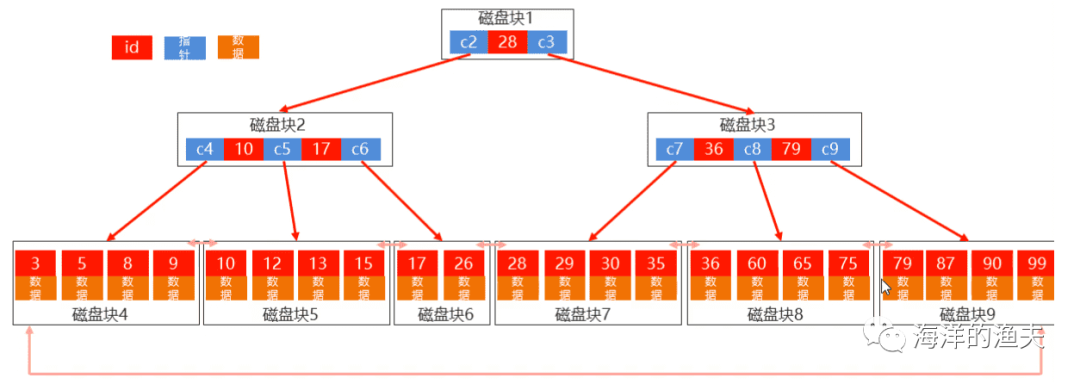
1595770623965
# summary
1. BTree data structure
Each node contains not only key value(Above id And pointer),And data.
2. B+Tree data structure
a. Non leaf nodes store only key value
b. All data is stored in the leaf node
c. There are connection pointers between leaf nodes, Convenient range search
3. B+Tree Benefits of
a. More stable query efficiency:Because the data is saved on the leaf node,This means that the leaf node must be found in every query,So relative BTree More stable query efficiency
b. Small data structure
2.3.2 data structure of B + tree
2.3.2.1 BTREE structure
BTree is also called multi-channel balanced search tree. The BTree characteristics of an m-fork are as follows:
- Each node in the tree contains up to m children.
- Except for the root node and leaf node, each node has at least [ceil(m/2)] children.
- If the root node is not a leaf node, there are at least two children.
- All leaf nodes are on the same layer.
- Each non leaf node consists of N key s and n+1 pointers, where [ceil (M / 2) - 1] < = n < = M-1
Taking 5-fork BTree as an example, the number of key s: formula derivation [ceil (M / 2) - 1] < = n < = M-1. SO 2 < = n < = 4. When n > 4, the intermediate node splits to the parent node and the two nodes split.
Insert 3 14 7 1 8 5 11 17 13 6 23 12 20 26 4 16 18 24 25 19 data as an example
The evolution process is as follows:
1). Insert the first 4 digits 3 14 7 1

image-20200615195740625
2). Insert 8, n > 4, and the intermediate element 7 splits up to the new node
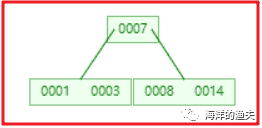
image-20200615203540712
3). Insert 5, 11, 17 without splitting
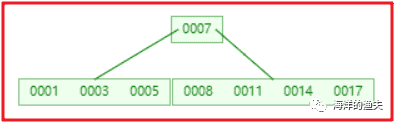
image-20200615203627953
4). Insert 13, and the intermediate element 13 splits up to the parent node 7
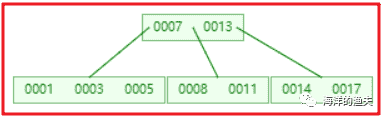
image-20200615203743627
5). Insertion 6, 23, 12, 20 does not require splitting
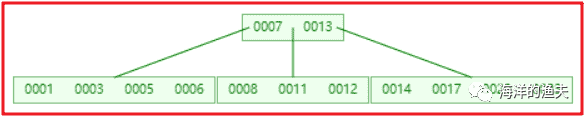
image-20200615203840191
6). Insert 26 and the intermediate element 20 splits up into the parent node
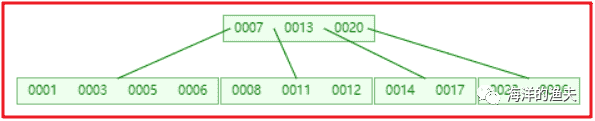
image-20200615203918124
7). Insert 4, and the intermediate element 4 splits up into the parent node. Then insert 16, 18, 24, 25 without splitting

image-20200615204157525
8). Finally, insert 19, 14, 16, 17, 18 nodes n > 5, and the intermediate node 17 splits upward, but after splitting, the n > 5 of the parent node 4, 7, 13, 20, and the intermediate node 13 splits upward
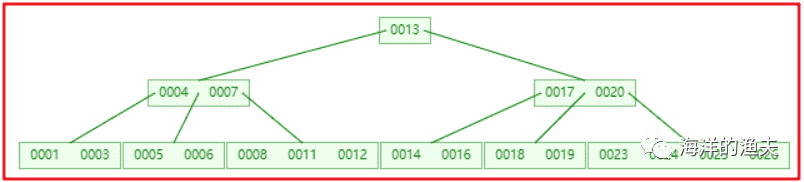
image-20200615204225776
At this point, the BTREE tree has been built. Compared with the binary tree, the BTREE tree is more efficient in querying data, because for the same amount of data, the hierarchical structure of BTREE is smaller than the binary tree, so the search speed is fast.
2.3.2.2 B+TREE structure
B+Tree is a variant of BTree. B+Tree is different from B-Tree in several aspects:
- Non leaf nodes only store key value information.
- There is a linked list pointer between all leaf nodes. (MySql optimizes B+Tree to facilitate range query)
- Data records are stored in leaf nodes.
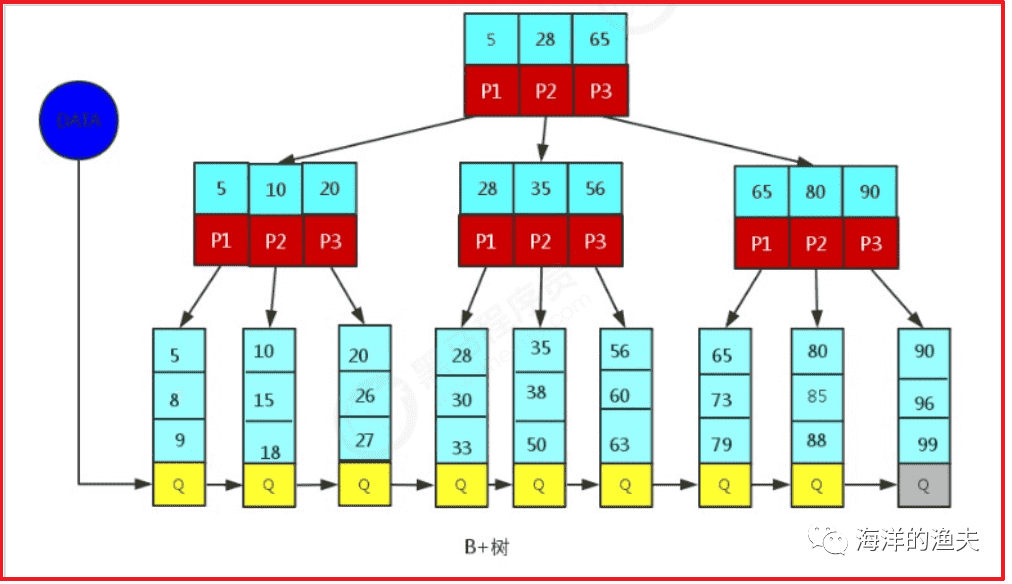
image-20200612174506653
Since only the leaf node of B+Tree stores key information, any key query must go from root to leaf. Therefore, the query efficiency of B+Tree is more stable.
2.4 classification of index
* Primary key (constraint) index
1. Primary key constraint(Unique not empty)+Improve query efficiency
2. remarks: When creating a primary key,Automatic generation
* Unique (constrained) index
1. Unique constraint(Can be empty)+Improve query efficiency
2. remarks: When creating a unique constraint,Automatic generation
* Foreign key index
1. only InnoDB The engine supports foreign key indexing,It is used to ensure the consistency and integrity of data and cascade operation.
2. remarks: When creating a foreign key,Automatic generation
* General index
Improve query efficiency only
* Combined (Federated) index
Multiple fields form an index
* Full text index
How to quickly match all documents,mysql5.6 Full text indexing is not supported until
2.5 index syntax
Indexes can be created at the same time when creating tables, or new indexes can be added at any time.
2.5.0 preparation environment:
create database indxdb; use indxdb; -- Create student table CREATE TABLE student( id INT, `name` VARCHAR(32), telephone VARCHAR(11) );
2.5.1 index creation
① Create [understand] directly
-- Create normal index create index Index name on Table name(field); -- Create unique index create unique index Index name on Table name(field); -- Create common composite index create index Index name on Table name(Field 1,Field 2); -- Create unique composite index create unique index Index name on Table name(Field 1,Field 2);
The test is performed as follows:
-- 1.name What index is a field suitable for? General index CREATE INDEX idx_name ON student(`name`); -- The implementation is as follows: mysql> CREATE INDEX idx_name ON student(`name`); Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 2.telephone What index is suitable for setting? unique index CREATE UNIQUE INDEX idx_uni_telephone ON student(telephone); -- The implementation is as follows: mysql> CREATE UNIQUE INDEX idx_uni_telephone ON student(telephone); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
② Specify [understand] when modifying the table
-- Add a primary key, which means that the index value must be unique and cannot be empty NULL alter table Table name add primary key(field); --Default index name: primary -- Add unique index (except NULL Outside, NULL May occur multiple times) alter table Table name add unique Index name(field); -- Add a normal index, and the index value can appear multiple times. alter table Table name add index Index name(field); -- The statement specifies that the index is FULLTEXT, For full-text indexing(understand) alter table Table name add fulltext Index name(field);
The test is performed as follows:
-- appoint id Index for primary key ALTER TABLE student ADD PRIMARY KEY(id); -- appoint name Is a normal index ALTER TABLE student ADD INDEX idx_name(`name`); -- appoint telephone Is a unique index ALTER TABLE student ADD UNIQUE idx_uni_telephone(telephone);
③ Specify master when creating a table
-- Create teacher table -- Create teacher table CREATE TABLE teacher( id INT PRIMARY KEY AUTO_INCREMENT, -- primary key `name` VARCHAR(32), telephone VARCHAR(11) UNIQUE, -- unique index sex VARCHAR(5), birthday DATE, student_id INT, INDEX(`name`), -- General index CONSTRAINT fk_01 FOREIGN KEY (student_id) REFERENCES student(id) -- Foreign key index );
2.5.2 query index
show index from Table name;
show index from teacher;

1595776746438
#Query result description 1. table : surface 2. Non_unique: Is it unique(0 express true,1 express false) 3. Key_name : Name of index 4. Column_name : The column in which the index is located 5. Null : Allow null(YES Indicates permission,Nothing said no) 6. Index_type: Data structure type of index
2.5.3 delete index
-- Delete directly drop index Index name on Table name; -- Delete master when modifying the table alter table Table name drop index Index name;
The test is performed as follows:
-- delete name General index DROP INDEX idx_name ON student; -- delete telephone unique index ALTER TABLE student DROP INDEX idx_uni_telepphone;
2.6 million level data efficiency demonstration
2.6.1 data preparation
-- 1. Preparation table
CREATE TABLE `user`(
id INT,
username VARCHAR(32),
`password` VARCHAR(32),
sex VARCHAR(6),
email VARCHAR(50)
);
-- 2. Create a stored procedure to insert records in batches
DELIMITER $$ -- Declare that the end symbol of the stored procedure is $$
CREATE PROCEDURE auto_insert()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION; -- Open transaction
WHILE(i<=1000000)DO
INSERT INTO `user` VALUES(i,CONCAT('jack',i),MD5(i),'male',CONCAT('jack',i,'@qq.com'));
SET i=i+1;
END WHILE;
COMMIT; -- Submit
END$$ -- End of statement
DELIMITER ; -- Redeclare semicolon as closing symbol
-- 3. Call stored procedure: It takes a long time to wait
CALL auto_insert();
-- 4. View the total amount of data in the table: 100 ten thousand
select count(*) from user;
The implementation is as follows:
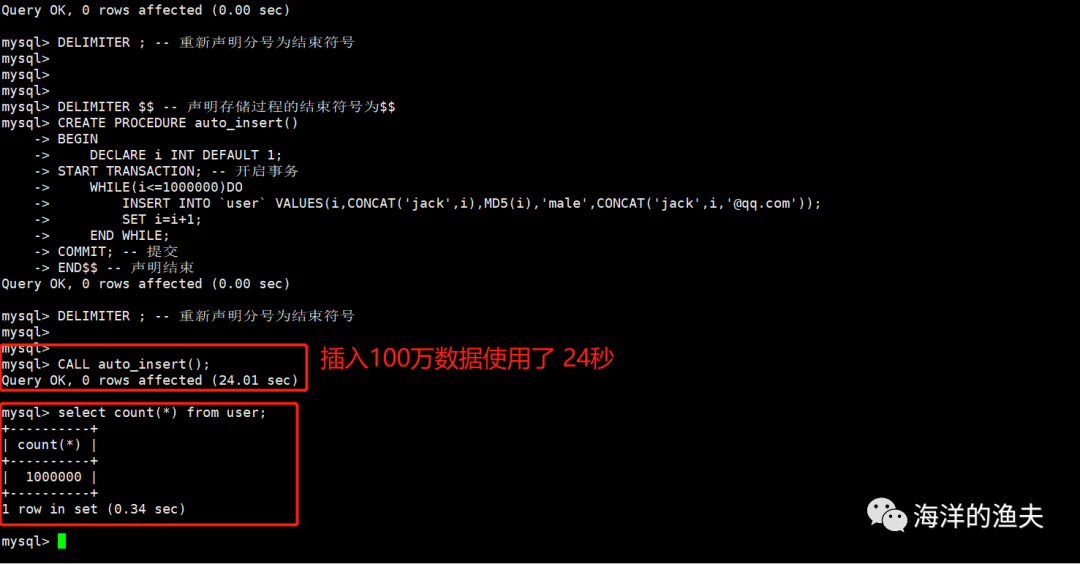
image-20210213095401442
2.6.2 first, test the query without index
-- 1.appoint id query mysql> select * from user where id = 888888; +--------+------------+----------------------------------+------+-------------------+ | id | username | password | sex | email | +--------+------------+----------------------------------+------+-------------------+ | 888888 | jack888888 | 21218cca77804d2ba1922c33e0151105 | male | jack888888@qq.com | +--------+------------+----------------------------------+------+-------------------+ 1 row in set (0.47 sec) -- Execution time: 0.47s -- 2.appoint username Accurate query mysql> select * from user where username = 'jack123456'; +--------+------------+----------------------------------+------+-------------------+ | id | username | password | sex | email | +--------+------------+----------------------------------+------+-------------------+ | 123456 | jack123456 | e10adc3949ba59abbe56e057f20f883e | male | jack123456@qq.com | +--------+------------+----------------------------------+------+-------------------+ 1 row in set (0.61 sec) -- Execution time: 0.61s -- 3.appoint email Fuzzy query mysql> select * from user where email like 'jack123456%'; +--------+------------+----------------------------------+------+-------------------+ | id | username | password | sex | email | +--------+------------+----------------------------------+------+-------------------+ | 123456 | jack123456 | e10adc3949ba59abbe56e057f20f883e | male | jack123456@qq.com | +--------+------------+----------------------------------+------+-------------------+ 1 row in set (0.54 sec) -- Execution time: 0.54s mysql>
It can be seen that under the condition of millions of data, it takes a long time. Let's build an index to see the efficiency.
2.6.3 add indexes to these three fields
-- appoint id Index for primary key ALTER TABLE user ADD PRIMARY KEY(id); -- appoint username Is a normal index ALTER TABLE user ADD INDEX(username); -- appoint email Is a unique index ALTER TABLE user ADD UNIQUE(email);
The implementation is as follows:
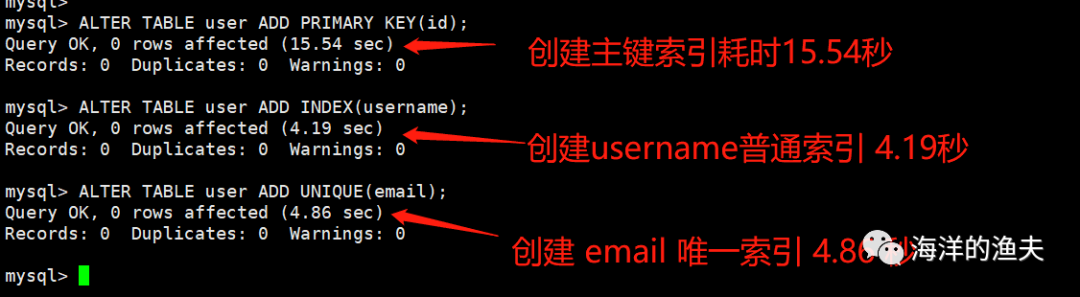
image-20210213095911772
2.6.4 retest query with index
-- 1.appoint id query select * from user where id = 888888; -- Execution time: 0.02s -- 2.appoint username Accurate query select * from user where username = 'jack123456'; -- Execution time: 0.01s -- 3.appoint email Fuzzy query select * from user where email like 'jack123456%'; -- 0.00s
The implementation is as follows:
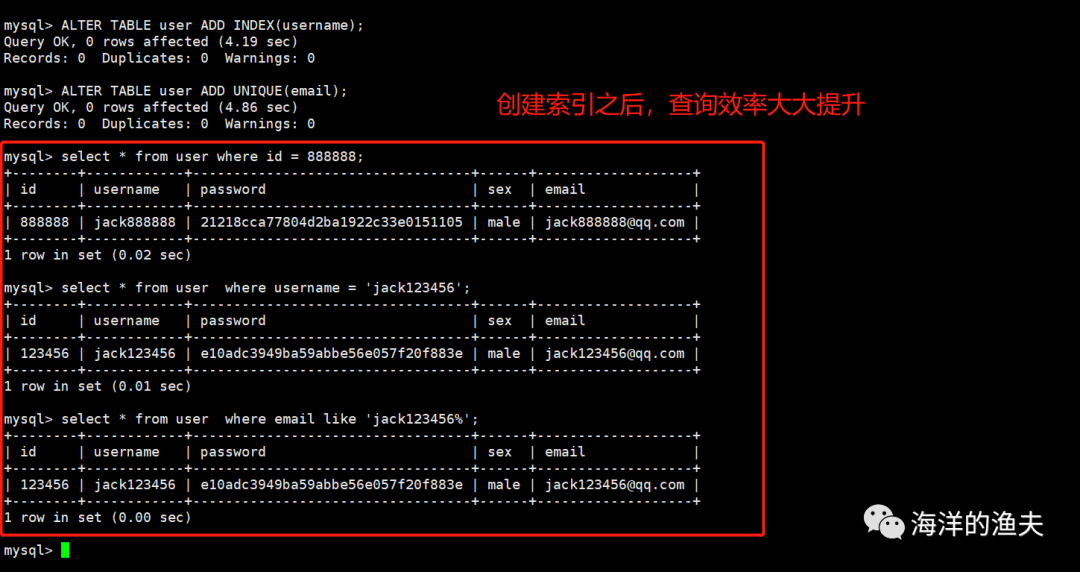
image-20210213100150804
2.7 design principle of index
# Summary of index characteristics 1. The index itself is a table, It also needs to be on disk 2. advantage: Reduce disk IO,Improve query efficiency 3. shortcoming: Index space,When adding, deleting or modifying,The maintenance of the index will increase the cost,May degrade server performance # Design principles of index 1. The query frequency is high,The table with large amount of data is indexed 2. Use unique index,The higher the degree of discrimination,The more efficient it is to use indexes(Accurate query is faster than fuzzy query) 3. Selection of index fields,The best candidate column should be from where Conditional extraction of words and sentences 4. Don't create indexes at will,Because maintaining the index also requires costs

1595778628989