MySQL database optimization
1, Storage principle of Mysql
Index correlation
essence
Index is help MySQL Ordered data structure for efficient data acquisition
Build index to improve the efficiency of data retrieval and reduce the IO cost of database; Sorting data by index column reduces the cost of data sorting and CPU consumption.
Index classification
- Primary key index: the primary key has its own index effect and good performance
- Normal index: an index created for normal columns
-- format create index Index name on Table name(Listing); -- Example create index idx_name on user(name);
- Unique index: the value of the index column must be unique, but null values are allowed. Better performance than ordinary indexes
-- format create unique index Index name on Table name(Listing); -- Example create unique index uniq_name on user(name);
-
Joint index( Development common ): create indexes for multiple columns in the table at one time (it is recommended that a joint index should not exceed 5 fields)
(leftmost prefix rule: how to hit index columns in a federated index)
-- format create index Index name on Table name(Column name 1,Column name 2); -- Example create index idx_name_age_password on user(name,age,password);
-
Full text index: when querying, data sources may come from different fields or tables
MyISAM The storage engine supports full-text indexing. Instead of using it in actual development, it uses search engine middleware
summary
-- Create index create [unique] index Index name on Table name(Listing) -- Delete index drop index [Index name] on Table name -- View index show index from Table name\G
Add index to data table

Indexed data structure
- Binary tree (linked list)
- Red black tree (too many levels)
- Hash table
- The key of the index can be hash ed once to locate the data storage location
- Many times, Hash index is more efficient than B + tree index
- Only "=" and "IN" can be satisfied, and range query is not supported
- hash conflict problem
- B Tree
- The leaf node has the same depth, and the pointer of the leaf node is null
- All index elements are not duplicate
- The data indexes in the node are arranged incrementally from left to right
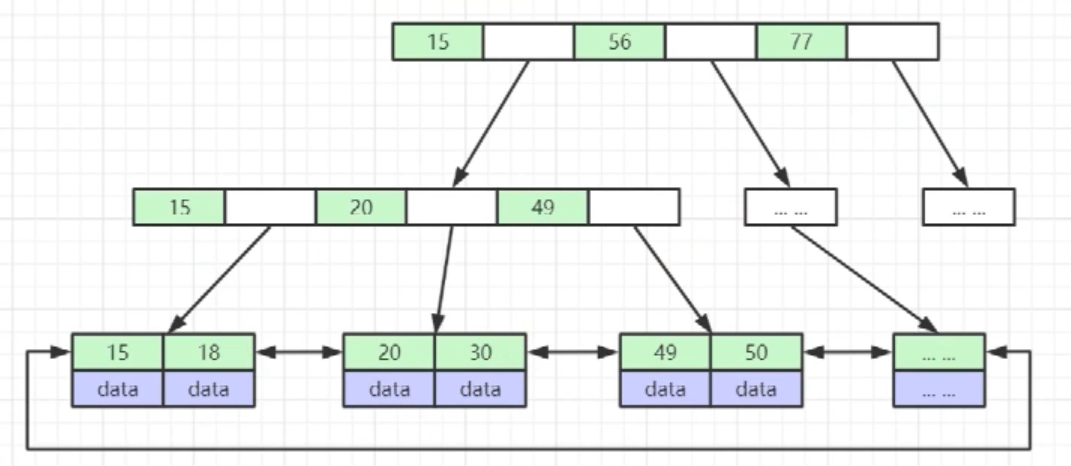
- B+Tree (ground floor)
- Non leaf nodes do not store data, only store indexes (redundant), and can put more indexes
- The leaf node contains all index fields
- Leaf nodes are connected with pointers to improve the performance of interval access
Recommend a foreign data structure online demonstration website: Data Structure Visualization
Differences between INNODB and MYISAM types
1,INNODB engine----Clustered index The index and data are stored in a file. After finding the index, the complete data can be obtained directly in the leaf node on the index tree. Row lock can be implemented/Watch lock 2,MYISAM----Nonclustered index Store the index and data in two files. After finding the index, you have to find data in another file. The performance will be slower. besides, MylSAM Naturally, it supports table locks and full-text indexing.
Index creation
- To create an index:
1,The primary key automatically creates a unique index 2,Fields frequently used as query criteria should be indexed 3,The fields associated with other tables in the query are indexed by foreign key relationships 4,Single bond/Selection of composite index ?( Create composite index in high and low tendency ) 5,The sorted fields in the query can be accessed through the index, which will greatly improve the sorting speed 6,Statistics or grouping fields in query
- When index creation is not required:
1,Frequently updated fields are not suitable for index creation 2,Frequently added, deleted and modified tables 3,where No index is created for fields that are not used in the condition 4,Too few table records 5,If a data column contains many duplicate contents, indexing it will not have much effect
Tip: the closer the selectivity of an index is to 1, the higher the efficiency of the index!
Joint index
Use one index to achieve the index effect of fields in multiple tables.
Storage method:
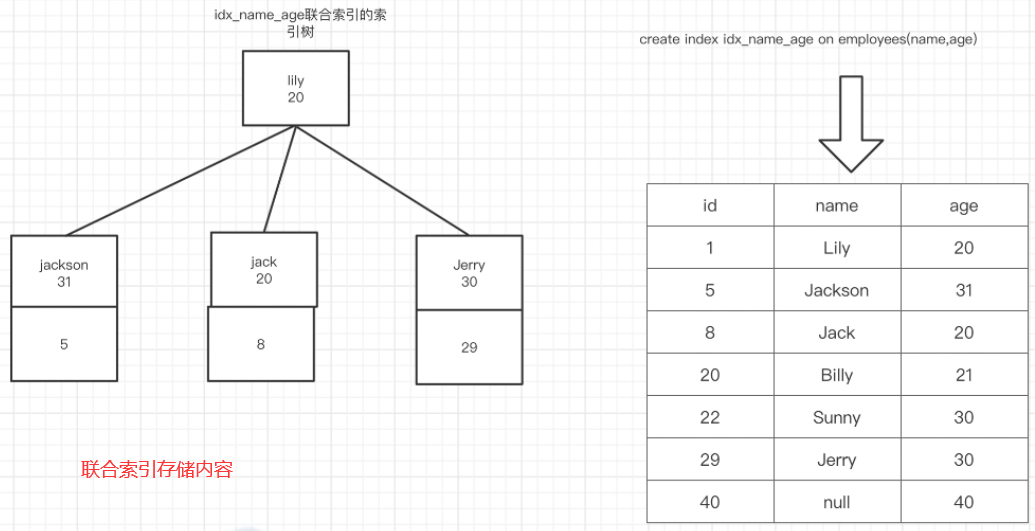
Index leftmost prefix principle
The leftmost prefix rule indicates whether an sql statement is indexed in the union index (hit the index / not scan the whole table)
What does the underlying storage structure of a federated index look like?
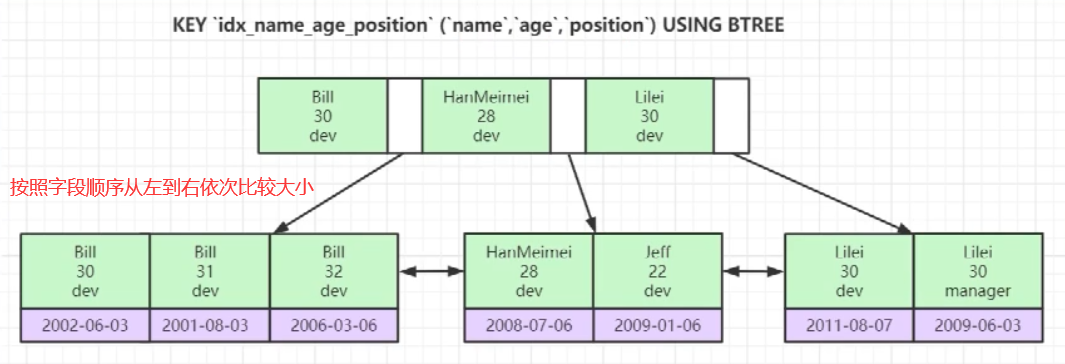
Slow sql reason
- The query statement is not well written
- Index failure
- Too many associated join (design defects or unavoidable requirements)
- Server tuning and parameter setting
2, Mysql performance query

The purpose of SQL optimization is to make SQL statements have excellent query performance. There are many ways to achieve this purpose:
- How to realize engineering optimization: database standard, table structure standard, field standard and index creation Ali: MySQL database specification
- Optimization of SQL statement: whether the current SQL statement hits the index.
explain
brief introduction
Use the EXPLAIN keyword to simulate the optimizer to execute SQL query statements, so as to know how MySQL handles your SQL statements. Analyze the performance bottleneck of your query statement or table structure
Explain in detail
effect
Read order of table Operation type of data read operation Which indexes can be used Which indexes are actually used References between tables How many rows per table are queried by the optimizer
Use format: explain + sql statement
information
Explain in detail
-
id column: the larger the id, the earlier it will be executed. If the IDs are the same, the above will be executed first
-
select_type column
| type | describe |
|---|---|
| simple | Simple query |
| primary | External primary query |
| devived | The sub query after from generates a derived table |
| subquery | Subquery before from |
| union | Federated queries performed |
Turn off mysql merge optimization for derived tables (Demo)
set session optimizer_switch = 'derived_merge=off';
-
Table column: this column indicates which table the sql is accessing. You can also see the derived table being accessed
-
type column
The type column can intuitively judge the performance of the current sql statement. The order of value and performance in type is as follows:
null > system > const > eq_ref > range > index > all
-- null The performance is the best. Generally, aggregate functions are used to operate index columns, and the results can be obtained directly from the index tree -- system It is rare to match a record directly -- const The performance is also good when using a primary key index or a unique index to compare with constants -- eq_ref During connection query, the primary key of this table is used for association in the conditions of connection query -- ref -- Simple query Use common columns as query criteria -- Complex query In connection query, the common index column of this table is used in the conditions of connection query -- range Range lookup is used on the index column, and the performance is ok of -- index All records in the query table, but all records can be obtained directly from the index tree,(All fields in the table are indexed) -- ALL Full table scan. Is to scan the data in the table from beginning to end. This query performance must be optimized.
-
possible_keys column
Displays the indexes that may be used in this query. The mysql optimizer will judge the query, and the internal optimizer will scan the whole table of the query -- we can view it through the trace tool
-
key column: the index actually used by the sql statement
-
rows column: the number of data that the sql statement may query
-
key_len column
By looking at the value of this column, you can infer which columns in the joint index this sql hit. key_ Calculation rules of len

-
extra column
The extra column provides additional information that can help us determine whether the current sql uses overlay index, file sorting, index query criteria, etc.
-- unsing index Overlay index is used (which means that all data fields in the current query are index columns, which means that data can be obtained directly from the index columns without looking up the table. Using overlay index for performance optimization is the next step sql Optimization is often used.) -- using where where The condition for does not use index columns. This performance is not acceptable ok , if conditions permit, we can set the index for the column, and also use the overlay index as much as possible. -- using index condition The columns of the query are not completely overwritten by the index, and where Use normal index in condition -- using temporary A temporary table will be created for execution. For example, the de duplication operation on a column without an index needs to be implemented by a temporary table. (this can be optimized by indexing the columns.) -- using filesort MySQL Sorting the data will be done by using disk. Memory may be used, which involves two concepts︰Single way sorting, double way sorting -- Select tables optimized away When using aggregate functions directly on index columns, it means that there is no need to operate on tables
3, mysql optimization details
Index optimization suggestions
Hit index recommendations:
-
For SQL optimization, try to ensure that the value of the type column belongs to range or above.
-
Unable to perform calculation, function and type conversion on the index column, which will lead to index invalidation
-
The processing of date and time is converted to range lookup
-
Use overlay indexes whenever possible
-
Using not equal to (! = or < >) will result in full table scanning
-
Using is null and is not null will cause a full table scan
-
Using like to start with a wildcard ('% xxx...') will result in a full table scan (using overlay index or search engine Middleware)
-
String without single quotation marks will cause a full table scan
-
Use less or or in, and the MySQL internal optimizer may not use indexes (using multithreading or search engine Middleware)
-
Range query optimization (large range split lookup)
Trace tool
In the execution plan, we found that some sql will go through the index, and some sql will not go through the index even if the index is explicitly used. mysql is based on the conclusion of Trace tool
-- open trace Set format to JSON,set up trace To avoid the inability to display the complete tracking process due to the size of the cache. set optimier_trace="enabled=on",end_markers_in_JSON=on; -- implement sql sentence -- get trace Analysis results select *from information_schema.optimizer_trace \G
Order by optimization
In Order by, if sorting will cause file sorting (if sorting is completed on disk, the performance will be poor), it means that sql does not hit the index. How to solve it? You can use the leftmost prefix rule to make the sorting follow the leftmost prefix rule and avoid file sorting.
Optimization means:
- If the sorted fields create a joint index, try to follow the leftmost prefix rule to write sorting statements without business conflict.
- If file sorting cannot be avoided, try to use overlay index. all->index
For Group by: it is essentially sorting before grouping, so for sorting optimization, refer to order by optimization.
Paging query optimization
-- original Explain select * from employees limit 10000,10 -- Optimize when the primary keys are continuous:(Rare) Explain select * from employees where id>10000 limit 10 -- By first searching the overlay index, and then using join Do connection query to get all data. This is faster than full table scanning EXPLAIN select * from employees a inner join (select id from employees order by name limit 1000000,10) b on a.id = b.id;
join query optimization

in, exstis optimization
In sql, if table A is A large table and table B is A small table, it is more appropriate to use in. Instead, use exists.
count optimization
The optimization of count should be at the architecture level, because the statistics of count often appear in a product and are accessed by each user. Therefore, it is recommended to maintain the data accessed too frequently in the cache.
4, mysql lock mechanism
Definition and classification of locks
definition
Lock is used to solve the data security problem caused by multiple tasks (threads, processes) accessing the same shared resource concurrently. Although using locks solves the problem of data security, it will bring performance impact. The performance of programs that use locks frequently is bound to be very poor.
For MySQL, a data management software, concurrent access to tasks is inevitable. So how does MySQL balance data security and performance—— MVCC design idea.
classification
-
In terms of performance:
- Pessimistic lock: pessimistic that the current concurrency is very serious, and any operation is mutually exclusive, which ensures the safety of the thread, but reduces the performance
- Optimistic lock: optimistic that the current concurrency is not serious. It can be locked when reading and when writing; Taking CAS spin lock as an example, it has high performance, but frequent spin will consume a lot of resources
-
Fine grained segmentation from data operations:
- Row lock: locks a row in a table
- Table lock: lock the whole table (basically not used)
-
Divided from the operation type of the database (wait-and-see lock):
- Read lock: it is called a shared lock. It can read the same data at the same time, but cannot write
- Write lock: it is called an exclusive lock. After locking and before releasing the lock, no concurrent operations can be performed in the whole process (other tasks cannot be read or written)
MylSAM only supports table locks, but does not support row locks. InnoDB can support row locks. In concurrent transactions, the addition, deletion and modification of each transaction is equivalent to row locks.
# Watch lock -- Read lock or write lock format on the table lock table Table name read/write; -- Release current lock unlock tables -- Check the locking of the table show open tables
# Row lock # MySQL enables automatic transaction submission by default SET autocommit = 0; # close SET autocommit = 1; # Turn on the default -- Open transaction begin; -- Uplink lock pair id = 8 This row of data is locked update `user` set name='Anterior degree' where id = 8; -- Mode 2 select * from `user` where id = 8 for update; -- Release lock commint;
MVCC design idea
MVCC, that is, multi version concurrency control. MVCC is a method of concurrency control. Generally, it realizes concurrent access to database in database management system and transaction memory in programming language.
Characteristics of transactions
- Atomicity: a transaction is the smallest unit of operation that either succeeds or fails
- Isolation: transactions opened by the database for each user cannot be affected by other transactions
- Consistency: the data before the transaction is committed and after the rollback is consistent
- Persistence: once a transaction is committed, it is irreversibly persisted to the database
Isolation level of transaction
- Read uncommitted: dirty reading occurs when a transaction reads data that has not been committed by another transaction
- Read committed: the problem of dirty reading has been solved. In one transaction, only the committed data of another transaction will be read, resulting in non repeatable reading
- Repeatable read: the default level is that the data read every time in a transaction is consistent. There will be no dirty read and non repeatable read problems. But it will be related to fantasy reading
- Serializable: the serialized isolation class directly does not allow the concurrency of transactions, and there is no concurrency. It is equivalent to locking the table, and its performance is very poor. Generally, uplink locking is not considered to solve the unreal reading problem
-- Set isolation level set session transaction isolation level Isolation level;
Some problems caused by isolation Dirty read: one transaction reads uncommitted data from another transaction Non repeatable reading: a row of data in a table is read in a transaction, and the reading results are different multiple times Virtual reading: refers to reading the data inserted by other transactions in one transaction, resulting in inconsistent reading before and after (generally affected by one more row)
In the read and write operations, MySQL guarantees the concurrency of the read performance, so that all reads are snapshot reads. When writing, version control is carried out. If the version of the real data is newer than the snapshot version, the version (snapshot) must be updated before writing, so as to not only improve the concurrency of reading, but also ensure the safety of writing data.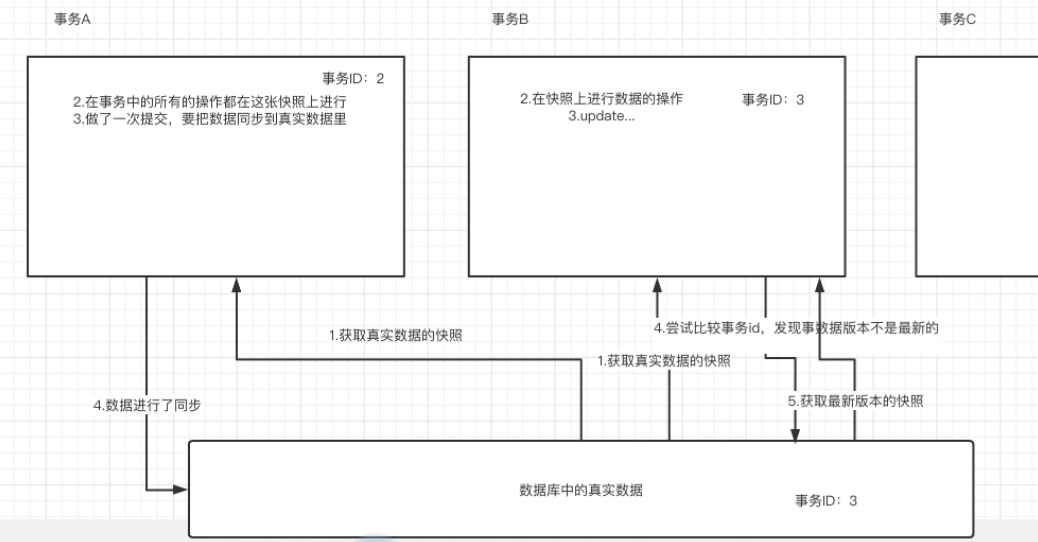
Deadlock and clearance lock
deadlock
The so-called deadlock means that the open lock cannot be closed, resulting in resource access being blocked because the lock cannot be obtained
Clearance lock
Row lock can only lock a row. If it is locked relative to a certain range, gap lock can be used. The conditions given by the gap lock where id > 13 and ID < 19 will lock the gap between 13 and 19.
5, Some interview questions
Why is the data stored in the leaf node of a non primary key index the primary key value?
If the primary key is not stored in the ordinary index, but the complete data is stored, it will cause:
-
Data redundancy improves query performance, but requires more space to store redundant data
-
Maintenance trouble: if you modify data in one place, you need to modify it on multiple index trees.
Why is it recommended that the InnoDB table must have a primary key, and it is recommended to use an integer self incrementing primary key?
Why does mysql suggest that the innodb table should have a primary key?
-
If you have a primary key, you can directly use the primary key to build an index
-
If there is no primary key, a column with different values will be selected from the first column as the index column
-
If no index column with unique value is selected, mysql will create a hidden column and maintain a unique id to organize the index
Why is shaping recommended as the primary key?
-
Reduce the performance of the comparison when finding data in the index.
-
Using integer as the primary key can save the space of data page compared with character type.
-
When constructing index b + tree, in order to ensure the order of index, using shaping can avoid page splitting.
Why should primary keys be self incremented?
-
Index structure b + tree, with orderly characteristics.
-If the primary key is not self incremented, when adding or deleting data, it will judge the location where the data should be stored, insert and delete. In order to maintain balance, it will split the data page and move the data, which will seriously affect the performance. Therefore, the primary key needs to be self incremented. When inserting, it will be inserted at the end of the index data page.