1. Index
1.1 index overview
MySQL's official definition of index is: index is a data structure (orderly) that helps MySQL obtain data efficiently. In addition to the data, the database system also maintains the data structure that meets the specific search algorithm. These data structures refer to (point to) the data in some way, so that the advanced search algorithm can be realized on these data structures. This data structure is the index. As shown in the following diagram:
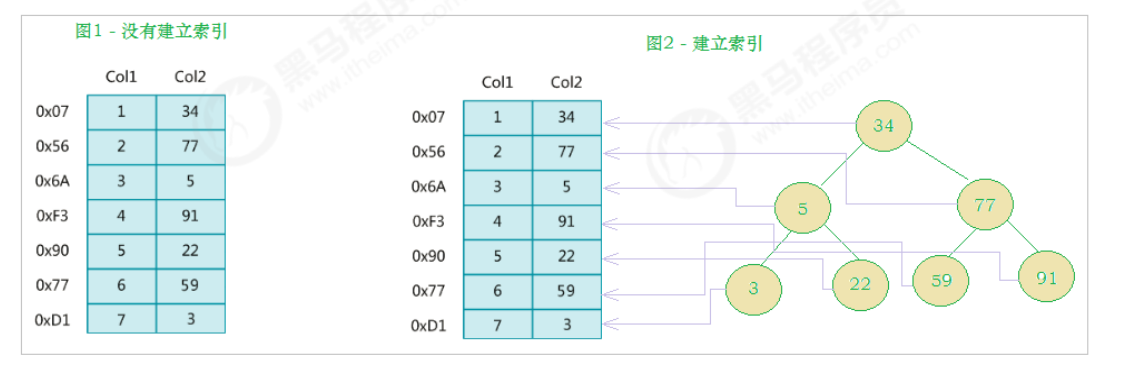
On the left is the data table, with two columns and seven records in total. On the far left is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used to quickly obtain the corresponding data.
Generally speaking, the index itself is also large, and it is impossible to store it all in memory, so the index is often stored on disk in the form of index file. Index is the most commonly used tool in database to improve performance.
1.2 index strengths and weaknesses
advantage
1) Similar to the Catalog Index of books, it improves the efficiency of data retrieval and reduces the IO cost of the database.
2) Sort the data through the index column to reduce the cost of data sorting and CPU consumption.
inferiority
1) In fact, the index is also a table, which saves the primary key and index fields and points to the records of entity classes, so the index column also takes up space.
2) Although the index greatly improves the query efficiency, it also reduces the speed of updating the table, such as INSERT, UPDATE and DELETE. Every time the index column of the MySQL file is updated, the value of the index column will be updated as well as the index value.
1.3 index structure
Indexing is implemented in the storage engine layer of MySQL, not in the server layer. Therefore, the indexes of each storage engine are not necessarily the same, and not all storage engines support all index types. MySQL currently provides the following four indexes:
-
BTREE index: the most common index type. Most indexes support B-tree index.
-
HASH index: it is only supported by Memory engine, and the usage scenario is simple.
-
R-tree index (spatial index): spatial index is a special index type of MyISAM engine. It is mainly used for geospatial data types and is usually less used.
-
Full text index: full text index is also a special index type of MyISAM, which is mainly used for Full-text index. InnoDB starts from mysql5 Version 6 supports Full-text indexing.
MyISAM, InnoDB and Memory support various index types:
| Indexes | InnoDB engine | MyISAM engine | Memory engine |
|---|---|---|---|
| BTREE index | support | support | support |
| HASH index | I won't support it | I won't support it | support |
| R-tree index | I won't support it | support | I won't support it |
| Full-text | Supported after version 5.6 | support | I won't support it |
The index we usually refer to, if not specified, refers to the index organized by B+tree (multi-channel search tree, not necessarily binary) structure. Among them, clustered index, composite index, prefix index and unique index all use B+tree index by default, which is collectively referred to as index.
1.3.1 BTREE structure
BTree is also called multi-channel balanced search tree. The BTree characteristics of an m-fork are as follows:
-
Each node in the tree contains up to m children.
-
Except for the root node and leaf node, each node has at least [ceil(m/2)] children.
-
If the root node is not a leaf node, there are at least two children.
-
All leaf nodes are on the same layer.
-
Each non leaf node consists of N key s and n+1 pointers, where [ceil (M / 2) - 1] < = n < = m-
Taking 5-fork BTree as an example, the number of key s: formula derivation [ceil (M / 2) - 1] < = n < = M-1. SO 2 < = n < = 4. When n > 4, the intermediate node splits into the parent node and the two nodes split.
Insert C N G A H E K Q M F W L T Z D P R X Y S data as an example.
The evolution process is as follows:
1). Insert the first 4 letters C N G A
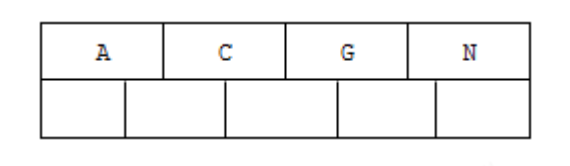
2). Insert H, n > 4, and the middle element G letter splits upward to a new node
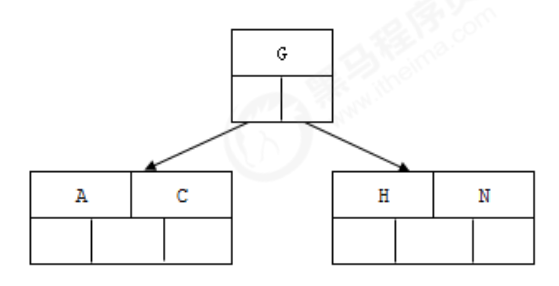
3). Inserting E, K, Q does not require splitting
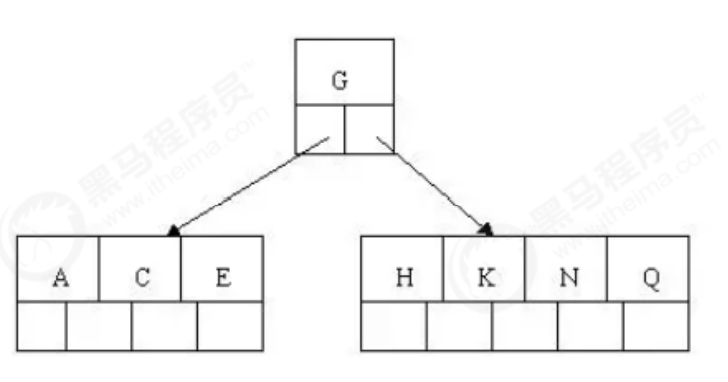
4). Insert m, and the middle element M letter splits upward to the parent node G
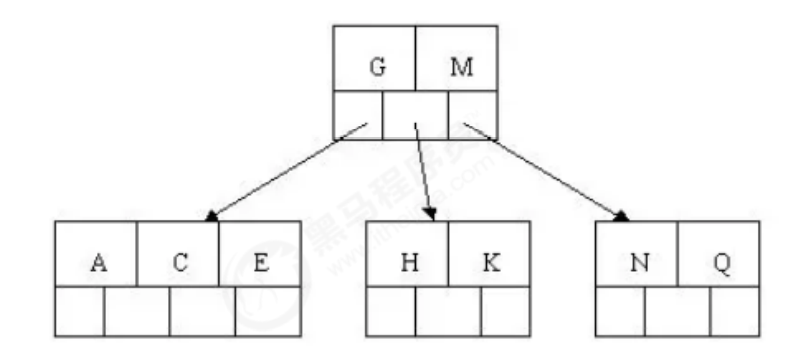
5). Inserting F, W, L, T does not require splitting
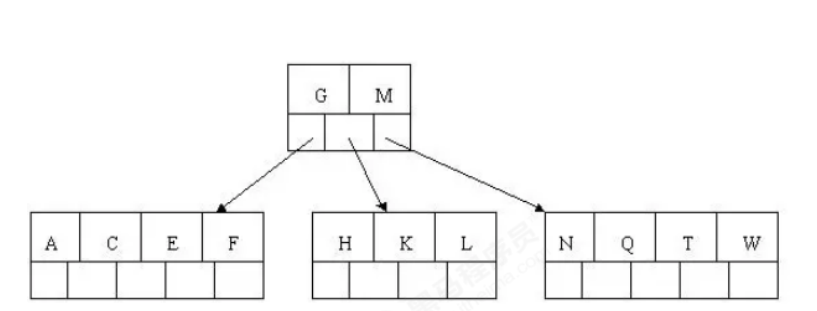
6). Insert Z, and the middle element T splits up into the parent node
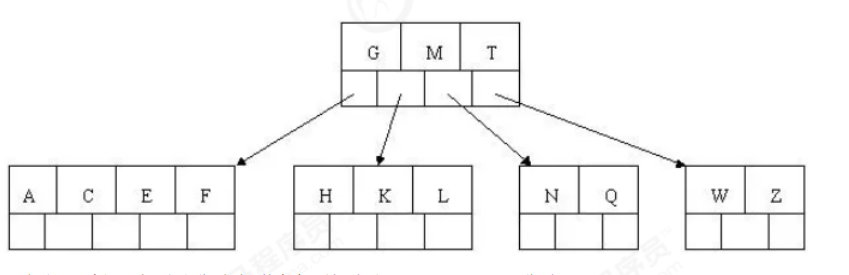
7). Insert D, and the intermediate element D splits up into the parent node. Then insert P, R, X, Y without splitting
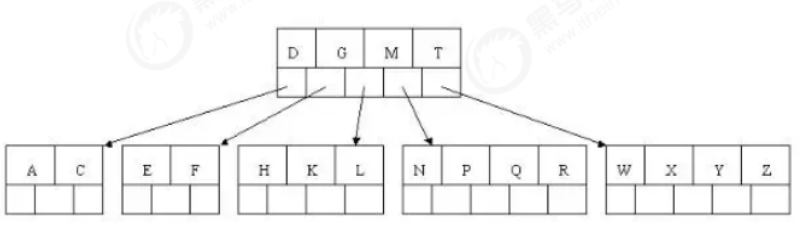
8). Finally, insert S, NPQR node n > 5, and the intermediate node Q splits upward, but after splitting, the parent node DGMT n > 5, and the intermediate node M splits upward
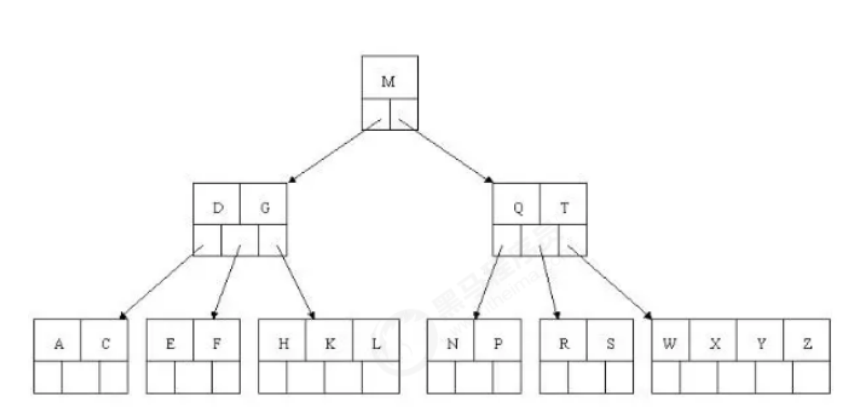
At this point, the BTREE tree has been built. Compared with the binary tree, the BTREE tree is more efficient in querying data, because for the same amount of data, the hierarchical structure of BTREE is smaller than the binary tree, so the search speed is fast.
1.3.3 B+TREE structure
B+Tree is a variant of BTree. The difference between B+Tree and BTree is:
1). n-fork B+Tree contains at most N keys, while BTree contains at most n-1 keys.
2). The leaf node of B + tree stores all key information, which is arranged in order of key size.
3). All non leaf nodes can be regarded as the index part of the key.
Since only leaf nodes in B+Tree store key information, any key query must go from root to leaf. Therefore, the query efficiency of B+Tree is more stable.
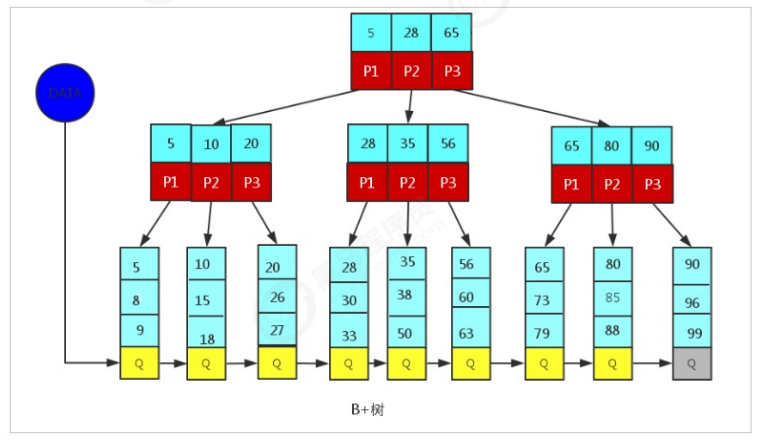
1.3.3 B+Tree in MySQL
MySql index data structure optimizes the classic B+Tree. On the basis of the original B+Tree, a linked list pointer pointing to adjacent leaf nodes is added to form a B+Tree with sequential pointer to improve the performance of interval access.
Schematic diagram of B+Tree index structure in MySQL:
1.4 index classification
1) Single value index: that is, an index contains only a single column, and a table can have multiple single column indexes
2) Unique index: the value of index column must be unique, but null value is allowed
3) Composite index: that is, an index contains multiple columns
1.5 index syntax
Indexes can be created at the same time when creating tables, or new indexes can be added at any time.
Preparation environment:
CREATE TABLE `city` ( `city_id` int(11) NOT NULL AUTO_INCREMENT, `city_name` varchar(50) NOT NULL, `country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `country` ( `country_id` int(11) NOT NULL AUTO_INCREMENT, `country_name` varchar(100) NOT NULL, PRIMARY KEY (`country_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'Xi'an',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2); insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'Beijing',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'Shanghai',1); insert into `country` (`country_id`, `country_name`) values(1,'China'); insert into `country` (`country_id`, `country_name`) values(2,'America'); insert into `country` (`country_id`, `country_name`) values(3,'Japan'); insert into `country` (`country_id`, `country_name`) values(4,'UK');
1.5.1 create index
Syntax:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...) index_col_name : column_name[(length)][ASC | DESC]
Example: City in the city table_ Create an index for the name field;
create index idx_city_name on city(city_name);
1.5.2 view index
Syntax:
show index from table_name;
1.5.3 delete index
Syntax:
DROP INDEX index_name ON tbl_name;
1.5.4 ALTER command
1). alter table tb_name add primary key(column_list); This statement adds a primary key, which means that the index value must be unique and cannot be null NULL 2). alter table tb_name add unique index_name(column_list); The value of the index created by this statement must be unique (except NULL Outside, NULL May occur multiple times) 3). alter table tb_name add index index_name(column_list); Add a common index, and the index value can appear multiple times. 4). alter table tb_name add fulltext index_name(column_list); The statement specifies that the index is FULLTEXT, For full-text indexing
1.6 index design principles
The design of the index can follow some existing principles. Please try to comply with these principles when creating the index, so as to improve the efficiency of the index and use the index more efficiently.
-
Index tables with high query frequency and large amount of data.
-
For the selection of index fields, the best candidate columns should be extracted from the conditions of the where clause. If there are many combinations in the where clause, the combination of the most commonly used columns with the best filtering effect should be selected.
-
Using a unique index, the higher the discrimination, the higher the efficiency of using the index.
-
Index can effectively improve the efficiency of query data, but the number of indexes is not the more the better. The more indexes, the higher the cost of maintaining the index. For tables with frequent DML operations such as insert, update and delete, too many indexes will introduce a high maintenance cost, reduce the efficiency of DML operations and increase the time consumption of corresponding operations. In addition, if there are too many indexes, MySQL will also suffer from selection difficulties. Although an available index will still be found in the end, it undoubtedly increases the cost of selection.
-
Using a short index also uses a hard disk to store the index after it is created. Therefore, improving the I/O efficiency of index access can also improve the overall access efficiency. If a given I/O length is used to store more valid indexes in MySQL, the efficiency can be improved.
-
Using the leftmost prefix and the combined index composed of N columns is equivalent to creating n indexes. If the first few fields constituting the index are used in the where clause during the query, the SQL query can use the combined index to improve the query efficiency.
Create composite index: CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS); It's equivalent to yes name Create index ; yes name , email Index created ; yes name , email, status Index created ;
2. Use of index
Indexing is one of the most commonly used and important means of database optimization. Indexing can usually help users solve most of the performance optimization problems of MySQL.
2.1 verifying indexes to improve query efficiency
In our prepared table structure TB_ 3 million records are stored in item;
A. Query by ID
select * from tb_item where id = 1999\G;
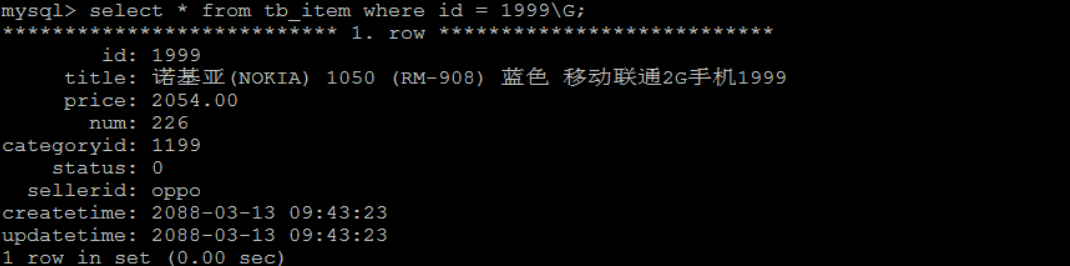
The query speed is very fast, close to 0s. The main reason is that the id is the primary key and there is an index;
2). Accurate query according to title
select * from tb_item where title = 'iphoneX Move 3 G 32G941'\G;
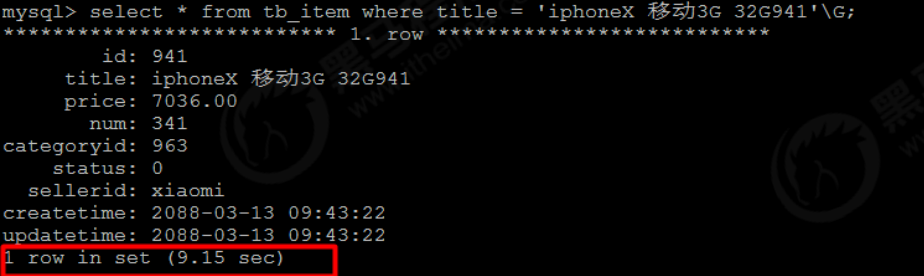
You can see that the query speed according to the title field is very slow, and you can create an index for the title field:
create index idx_item_title on tb_item(title);
After the index is created, query again and view the execution plan through explain. The index just created is used when executing SQL
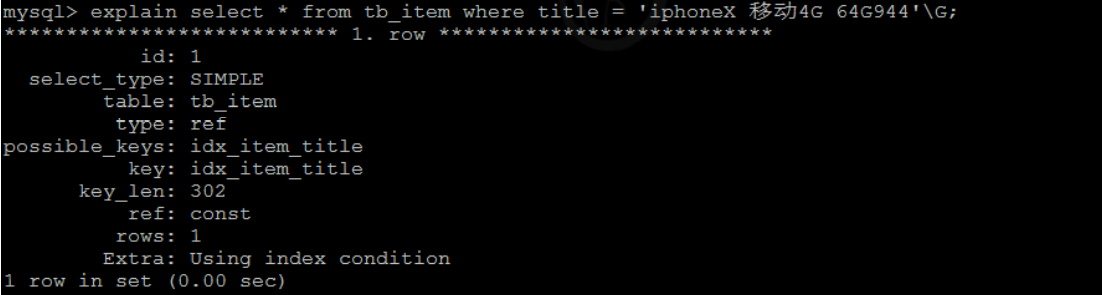
2.2 use of index
2.2.1 environment preparation
create table `tb_seller` (
`sellerid` varchar (100),
`name` varchar (100),
`nickname` varchar (50),
`password` varchar (60),
`status` varchar (1),
`address` varchar (100),
`createtime` datetime,
primary key(`sellerid`)
)engine=innodb default charset=utf8mb4;
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('alibaba','Alibaba','Ali Xiao
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('baidu','Baidu Technology Co., Ltd','Baidu small
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('huawei','Huawei Technology Co., Ltd','Huawei small
store','e10adc3949ba59abbe56e057f20f883e','0','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('luoji','Logitech Technology Co., Ltd','Logitech small
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('oppo','OPPO Technology Co., Ltd','OPPO Official flagship
store','e10adc3949ba59abbe56e057f20f883e','0','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('ourpalm','Zhangqu Technology Co., Ltd','Small palm interest
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('qiandu','QIANDU Technology','Thousand degrees small
store','e10adc3949ba59abbe56e057f20f883e','2','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('sina','Sina Technology Co., Ltd','Official flagship of sina
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('xiaomi','Xiaomi Tech ','Millet official flagship
store','e10adc3949ba59abbe56e057f20f883e','1','Xi'an','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`,
`address`, `createtime`) values('yijia','IKEA home','IKEA flagship
store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
--Create composite index create index idx_seller_name_sta_addr on tb_seller(name,status,address);
2.2.2 avoid index failure
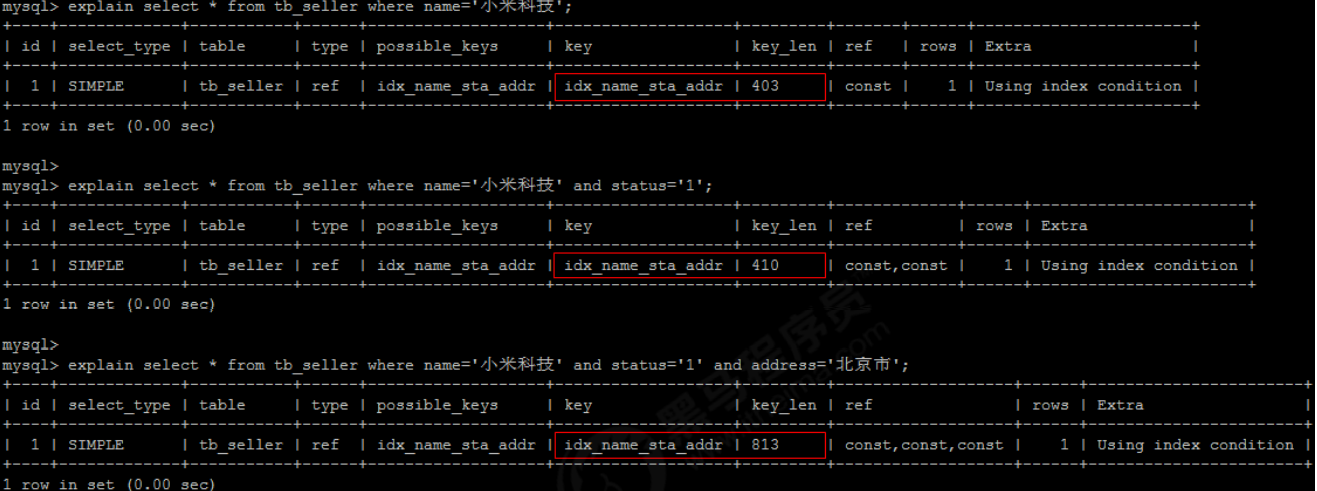
1). Full value matching: specify specific values for all columns in the index. If you change the query order, the index will still take effect.
explain select * from tb_seller where name='Xiaomi Tech ' and status='1' and address='Beijing';

2). Leftmost prefix rule
If multiple columns are indexed, follow the leftmost prefix rule. It means that the query starts from the top left of the index and does not skip the columns in the index.
- Match the leftmost prefix rule and take the index
- Illegal leftmost prefix rule, index invalid
- If the leftmost rule is met, but a column jumps, only the leftmost column index takes effect:
3). The column on the right of range query cannot use index.
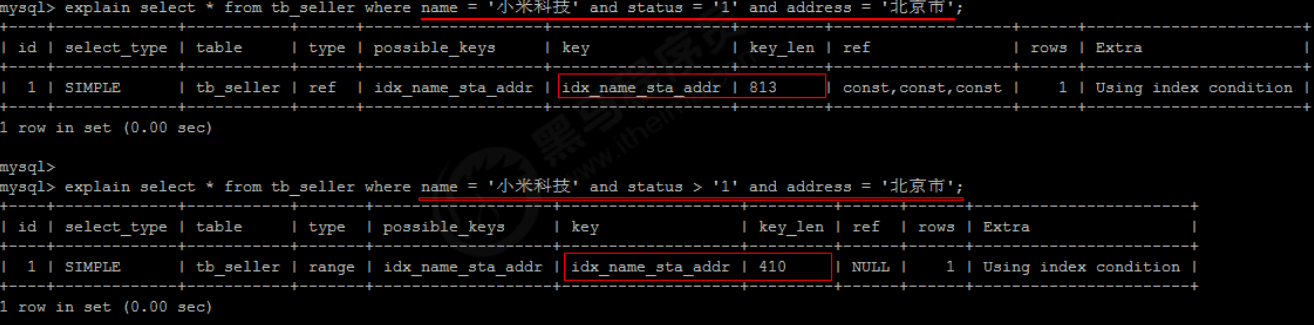
According to the first two fields name and status, the query is indexed, but the last condition address does not use the index.
4). Do not operate on the index column. The index will become invalid.
5). The string is not enclosed in single quotation marks, resulting in index invalidation.
Because no single quotation marks are added to the string during query, MySQL query optimizer will automatically perform type conversion, resulting in index failure.
6). Try to use overlay indexes to avoid selecting * from table names
- Try to use the overlay index (only the query accessing the index (the index column completely contains the query column)), and reduce the select *, for example: select name from table name.
- If the query column exceeds the index column, the performance will also be reduced.
tip: using index : It will appear when using overlay index using where: When the index is used for searching, you need to go back to the table to query the required data using index condition: The index is used in the search, but the data needs to be queried back to the table using index ; using where: The search uses the index, but the required data can be found in the index column, so there is no need to query the data back to the table
7). For the condition separated by or, if the column in the condition before or has an index, but there is no index in the subsequent column, the involved index will not be used.
8). Like fuzzy query starting with%, index invalid.
If it is only tail fuzzy matching, the index will not fail. If it is a header fuzzy match, the index is invalid.
Solution: it can be solved by overwriting the index
9). If MySQL evaluation uses indexes more slowly than full tables, indexes are not used.
10). is NULL, is NOT NULL. Sometimes the index fails.
11). in index, not in index is invalid.
12). Single column index and composite index.
Tip: try to use composite indexes instead of single column indexes.
Create composite index:
create index idx_name_sta_address on tb_seller(name, status, address); This is equivalent to creating three indexes: name name + status name + status + address
Create a single column index
create index idx_seller_name on tb_seller(name); create index idx_seller_status on tb_seller(status); create index idx_seller_address on tb_seller(address);
The database will select an optimal index (the most recognizable index) to use, and will not use all indexes.
2.3 view index usage
show status like 'Handler_read%'; show global status like 'Handler_read%';
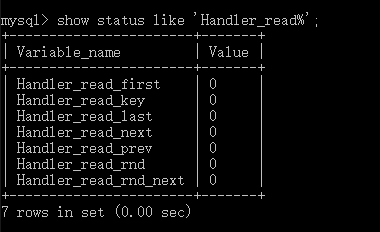
Handler_read_first: the number of times the first entry in the index is read. A high value indicates that the server is performing a large number of full index scans (the lower the value, the better)
Handler_read_key: if the index is working, this value represents the number of times a row is read by the index value. If the value is lower, it means that the performance improvement of the index is not high, because the index is not often used (the higher the value, the better)
Handler_read_next: the number of requests to read the next line in key order. This value is incremented if you use range constraints or if you perform an index scan to query index columns
Handler_read_prev: the number of requests to read the previous line in key order. This method is mainly used to optimize ORDER BY... DESC
Handler_read_rnd: the number of requests to read a row according to a fixed position. If you are executing a large number of queries and need to sort the results, this value is higher. You may have used a lot of queries that require MySQL to scan the entire table, or your connection does not use keys correctly. This value is high, which means that the operation efficiency is low, and an index should be established to remedy it
Handler_read_rnd_next: the number of requests to read the next line in the data file. This value is higher if you are doing a large number of table scans. Your query table does not usually write the index correctly.