background
MySQL has become the first choice for most companies with low-cost and rich Internet resources. Although the performance is excellent, how to better use the so-called "good horse with good saddle" has become a compulsory course for development engineers. We often see requirements such as "proficient in MySQL", "SQL statement optimization" and "understanding database principle" from the job description. We know that in general application systems, the read-write ratio is about 10:1, and there are few performance problems in insert operations and general update operations. The most common and most prone to problems are some complex query operations, so the optimization of query statements is obviously the top priority.
Since July 2013, I have been doing the optimization of slow query in meituan core business system department. There are more than ten systems in total, and hundreds of slow query cases have been solved and accumulated. With the increasing complexity of the business, the problems encountered are strange and unimaginable. This paper aims to explain the principle of database index and how to optimize slow query from the perspective of development engineers.
Reflections on a slow query
select count(*) from task where status=2 and operator_id=20839 and operate_time>1371169729 and operate_time<1371174603 and type=2;
System users responded that a function was getting slower and slower, so the engineer found the SQL above.
And found me with interest, "this SQL needs to be optimized. Add indexes to every field for me".
I was surprised and asked, "why do you need to index every field?"
"It will be faster to index all the query fields", the engineer was full of confidence.
"In this case, a joint index can be built, because it is the leftmost prefix matching, so the operate_time needs to be put last, and other relevant queries need to be brought, so a comprehensive evaluation needs to be done."
"Joint index? Leftmost prefix matching? Comprehensive evaluation?" The engineer was lost in thought.
In most cases, we know that indexing can improve query efficiency, but how to build an index? What is the order of indexes? Many people only know about it. In fact, it is not difficult to understand these concepts, and the principle of index is far less complex than expected.
MySQL index principle
Index purpose
The purpose of index is to improve query efficiency. It can be compared with dictionary. If we want to look up the word "mysql", we must locate the letter M, then find the letter y from bottom to bottom, and then find the remaining sql. If there is no index, you may need to look through all the words to find what you want. What if I want to find the word beginning with m? Or the word that begins with ze? Do you think this can't be done without an index?
Index principle
In addition to dictionaries, examples of indexes can be seen everywhere in life, such as train number tables at railway stations, catalogues of books, etc. Their principles are the same. We filter out the final desired results by constantly narrowing the range of data we want to obtain, and turn random events into sequential events, that is, we always lock the data through the same search method.
Database is the same, but it is obviously much more complex, because it is faced with not only equivalent query, but also range query (>, <, between, in), fuzzy query (like), union query (or), etc. How should the database deal with all the problems? Let's recall the example of the dictionary. Can we divide the data into segments and then query them in segments? In the simplest way, if 1000 pieces of data are divided into the first segment from 1 to 100, the second segment from 101 to 200, and the third segment from 201 to 300... In this way, you can find the third segment for the 250 pieces of data, and 90% of the invalid data is removed at once. But if it's a record of 10 million, how many paragraphs are better? Students with a little basic algorithm will think of the search tree. Its average complexity is lgN and has good query performance. But here we ignore a key problem. The complexity model is based on the same operation cost every time. The implementation of the database is relatively complex, and the data is saved on the disk. In order to improve the performance, we can read part of the data into the memory for calculation every time, because we know that the cost of accessing the disk is about 100000 times that of accessing the memory, Therefore, a simple search tree is difficu lt to meet complex application scenarios.
Disk IO and read ahead
As mentioned earlier, disk IO and pre reading are briefly introduced here. Disk data reading depends on mechanical movement. The time spent reading data each time can be divided into three parts: seek time, rotation delay and transmission time. Seek time refers to the time required for the magnetic arm to move to the specified track. Mainstream disks are generally less than 5ms; Rotation delay is the disk speed we often hear about. For example, 7200 revolutions of a disk means 7200 revolutions per minute, that is, 120 revolutions per second. The rotation delay is 1/120/2 = 4.17ms; Transmission time refers to the time to read or write data from or to the disk. It is generally a few tenths of a millisecond, which can be ignored relative to the first two times. So the time to access a disk, that is, the time to io on a disk is about 5+4.17 = 9ms, which sounds pretty good, but you should know that a 500 MIPS machine can execute 500 million instructions per second, because the instructions rely on the nature of electricity. In other words, the time to execute an IO can execute 400000 instructions, and the database is prone to 100000 or even tens of millions of data, Nine milliseconds at a time is obviously a disaster. The following figure is a comparison diagram of computer hardware delay for your reference:

various-system-software-hardware-latencies
Considering that disk IO is a very expensive operation, the computer operating system has made some optimization. During an IO, not only the data of the current disk address, but also the adjacent data are read into the memory buffer, because the principle of local pre reading tells us that when the computer accesses the data of an address, the data adjacent to it will also be accessed quickly. The data read by each IO is called a page. The specific data size of a page is related to the operating system, generally 4k or 8k, that is, when we read the data in a page, there is actually only one io. This theory is very helpful for the data structure design of the index.
Indexed data structure
We talked about the example of index in life, the basic principle of index, the complexity of database, and the relevant knowledge of operating system. The purpose is to let you know that any kind of data structure is not produced out of thin air, and there must be its background and use scenario. Now let's summarize what we need this data structure to do, which is actually very simple, That is: control the disk IO times to a small order of magnitude, preferably a constant order of magnitude, every time you look for data. So we think that if a highly controllable multi-channel search tree can meet the demand? In this way, b + tree came into being.
Detailed explanation of b + tree
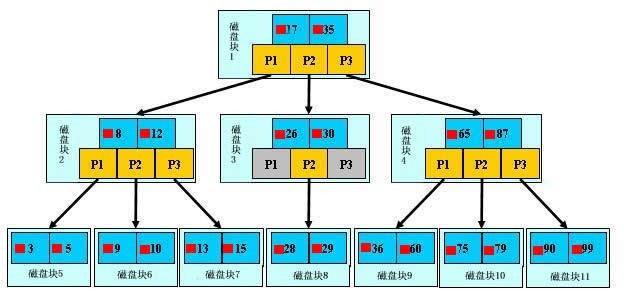
b + tree
As shown in the figure above, it is a b + tree. For the definition of b + tree, see B + tree , here are just some key points. The light blue block is called a disk block. You can see that each disk block contains several data items (shown in dark blue) and pointers (shown in yellow). For example, disk block 1 contains data items 17 and 35, including pointers P1, P2 and P3. P1 represents the disk block smaller than 17, P2 represents the disk block between 17 and 35, and P3 represents the disk block greater than 35. Real data exists in leaf nodes, i.e. 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90 and 99. Non leaf nodes do not store real data, but only data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
Search process of b + tree
As shown in the figure, if you want to find the data item 29, first load the disk block 1 from the disk into the memory. At this time, an IO occurs. Use the binary search in the memory to determine that the 29 is between 17 and 35, lock the P2 pointer of disk block 1, and the memory time is negligible because it is very short (compared with the IO of the disk), Load disk block 3 from disk to memory through the disk address of P2 pointer of disk block 1, and the second IO occurs. When 29 is between 26 and 30, lock the P2 pointer of disk block 3, load disk block 8 to memory through the pointer, and the third IO occurs. At the same time, do binary search in memory to find 29, and end the query. There are three IOS in total. The real situation is that the three-tier b + tree can represent millions of data. If millions of data searches only need three IO, the performance improvement will be huge. If there is no index and each data item needs one IO, then a total of millions of IO are required. Obviously, the cost is very high.
b + tree properties
1. Through the above analysis, we know that the number of IO depends on the height h of the number of b +. Assuming that the data in the current data table is N and the number of data items in each disk block is m, there is h = ㏒ (m+1)N. when the amount of data N is certain, the larger m, the smaller h; M = size of disk block / size of data item. The size of disk block, that is, the size of a data page, is fixed. If the space occupied by data item is smaller, the number of data items is more, and the height of tree is lower. This is why each data item, that is, the index field should be as small as possible. For example, int takes up 4 bytes, which is half less than bigint8 bytes. This is why the b + tree requires that the real data be placed in the leaf node instead of the inner node. Once placed in the inner node, the data items of the disk block will decrease significantly, resulting in the increase of the tree. When the data item is equal to 1, it will degenerate into a linear table.
2. When the data item of the b + tree is a composite data structure, such as (name,age,sex), the b + number establishes the search tree from left to right. For example, when data such as (Zhang San, 20,F) is retrieved, the b + tree will give priority to comparing the name to determine the search direction in the next step. If the name is the same, then compare age and sex in turn to get the retrieved data; However, when there is no name data like (20,F), the b + tree does not know which node to check next, because name is the first comparison factor when establishing the search tree. You must search according to name first to know where to query next. For example, when retrieving data such as (Zhang San, F), the b + tree can use name to specify the search direction, but the next field age is missing, so we can only find the data whose name is equal to Zhang San, and then match the data whose gender is F. this is a very important property, that is, the leftmost matching feature of the index.
Slow query optimization
The principle of MySQL indexing is a boring thing. We only need to have a perceptual understanding, and we don't need to understand it very thoroughly and deeply. Let's look back at the slow query we talked about at the beginning. After understanding the indexing principle, do you have any ideas? First summarize the basic principles of indexing:
Several principles of indexing
1. The leftmost prefix matching principle is a very important principle. mysql will match to the right until it meets the range query (>, <, between and like). For example, a = 1 and B = 2 and C > 3 and d = 4. If the index of (a,b,c,d) order is established, D can not be indexed. If the index of (a,b,d,c) order is established, it can be used. The order of a,b,d can be adjusted arbitrarily.
2. = and in can be out of order. For example, a = 1 and b = 2 and c = 3. The establishment of (a,b,c) indexes can be in any order. The query optimizer of mysql will help you optimize them into a form that can be recognized by the index.
3. Try to select the column with high discrimination as the index. The formula of discrimination is count(distinct col)/count(*), which indicates the proportion of fields that are not repeated. The larger the proportion, the fewer records we scan, and the discrimination of the unique key is 1. Some status and gender fields may have a discrimination of 0 in front of big data. Someone may ask, what is the empirical value of this proportion? It is also difficult to determine this value in different usage scenarios. Generally, the fields that need to be join ed are required to be more than 0.1, that is, an average of 10 records per scan.
4. The index column cannot participate in the calculation. Keep the column "clean", such as from_unixtime(create_time) = '2014-05-29' can't use the index. The reason is very simple. All the field values in the data table are stored in the b + tree, but when searching, you need to apply functions to all elements to compare. Obviously, the cost is too high. So the statement should be written as create_time = unix_timestamp(’2014-05-29’).
5. Try to expand the index instead of creating a new index. For example, if there is already an index of a in the table and you want to add an index of (a,b), you only need to modify the original index.
Back to the beginning of the slow query
According to the leftmost matching principle, the index of the initial sql statement should be status and operator_id,type,operate_ Joint index of time; Including status and operator_ The order of ID and type can be reversed, so I will say that all relevant queries in this table will be found and analyzed comprehensively; For example, there are the following queries:
select * from task where status = 0 and type = 12 limit 10;
select count(*) from task where status = 0 ;
Then the index establishment (status,type,operator_id,operate_time) is very correct, because it can cover all situations. This makes use of the leftmost matching principle of the index
Query optimization artifact - explain command
I believe you are not unfamiliar with the explain command. For specific usage and field meaning, please refer to the official website explain-output Here, we need to emphasize that rows is the core indicator, and most of the small rows statements must execute very quickly (with exceptions, which will be discussed below). Therefore, the optimization statements are basically optimizing rows.
Basic steps of slow query optimization
0. Run it first to see if it is really slow. Pay attention to setting SQL_NO_CACHE
1. Check the where condition sheet and lock the minimum return record table. The meaning of this sentence is to apply the where of the query statement to the table with the smallest number of records returned in the table. Start to query each field of a single table to see which field has the highest discrimination
2.explain to check whether the execution plan is consistent with 1 expectation (query from the table with few locked records)
3. The sql statement in the form of order by limit gives priority to the sorted table
4. Understand the usage scenarios of the business party
5. When adding an index, refer to several principles of index building
6. If the observation results do not meet the expectations, continue to analyze from 0
Several slow query cases
The following examples explain in detail how to analyze and optimize slow queries.
Complex statement writing
In many cases, we write SQL only to realize functions, which is only the first step. Different statement writing methods often have essential differences in efficiency, which requires us to have a very clear understanding of mysql execution plan and indexing principles. Please see the following statement:
select
distinct cert.emp_id
from
cm_log cl
inner join
(
select
emp.id as emp_id,
emp_cert.id as cert_id
from
employee emp
left join
emp_certificate emp_cert
on emp.id = emp_cert.emp_id
where
emp.is_deleted=0
) cert
on (
cl.ref_table='Employee'
and cl.ref_oid= cert.emp_id
)
or (
cl.ref_table='EmpCertificate'
and cl.ref_oid= cert.cert_id
)
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00';
0. Run it first, 53 records for 1.87 seconds, and there is no aggregation statement, which is relatively slow
53 rows in set (1.87 sec)
1.explain
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where; Using temporary | | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 63727 | Using where; Using join buffer | | 2 | DERIVED | emp | ALL | NULL | NULL | NULL | NULL | 13317 | Using where | | 2 | DERIVED | emp_cert | ref | emp_certificate_empid | emp_certificate_empid | 4 | meituanorg.emp.id | 1 | Using index | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
Briefly describe the execution plan. First, mysql is based on idx_last_upd_date index scan cm_ 379 records were obtained from the log table; Then, 63727 records are scanned by looking up the table, which is divided into two parts. derived represents the construction table, that is, the non-existent table, which can be simply understood as the result set formed by a statement, and the following number represents the ID of the statement. derived2 indicates that the query with ID = 2 constructed a virtual table and returned 63727 records. Let's take a look at what the statement with ID = 2 has done and returned such a large amount of data. First, scan the whole table for 13317 records in the employee table, and then use the index emp_certificate_empid Association EMP_ In the certificate table, rows = 1 indicates that only one record is locked for each association, which is more efficient. After obtaining, and cm_ 379 records of log are associated according to rules. From the execution process, we can see that too much data is returned, and most of the returned data is cm_log can't be used because cm_log only locks 379 records.
How to optimize it? You can see that we still need to communicate with cm after running_ Log as a join, so can we talk to cm before_ What about joining? Careful analysis of the sentence is not difficult to find that its basic idea is if cm_ Ref of log_ If table is EmpCertificate, it is associated with emp_certificate table, if ref_table is the employee table associated with employee. We can completely split it into two parts and connect it with union. Note that union is used here instead of union all because the primitive sentence has "distinct" to obtain the unique record, and union just has this function. If there is no distinct in the primitive sentence and there is no need for de duplication, we can directly use union all, because the de duplication action required to use union will affect the SQL performance.
The optimized statements are as follows:
select
emp.id
from
cm_log cl
inner join
employee emp
on cl.ref_table = 'Employee'
and cl.ref_oid = emp.id
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00'
and emp.is_deleted = 0
union
select
emp.id
from
cm_log cl
inner join
emp_certificate ec
on cl.ref_table = 'EmpCertificate'
and cl.ref_oid = ec.id
inner join
employee emp
on emp.id = ec.emp_id
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00'
and emp.is_deleted = 0
4. There is no need to understand the business scenario, but the modified statement and the statement before the transformation need to keep the result consistent
5. The existing index can meet the requirements, and there is no need to build an index
6. Experiment with the modified sentence. It only takes 10ms, which is reduced by nearly 200 times!
+----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 1 | PRIMARY | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | Using where | | 2 | UNION | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 2 | UNION | ec | eq_ref | PRIMARY,emp_certificate_empid | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | | | 2 | UNION | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.ec.emp_id | 1 | Using where | | NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ 53 rows in set (0.01 sec)
Clear application scenarios
The purpose of this example is to subvert our cognition of column discrimination. Generally, we believe that the higher the discrimination of columns, the easier it is to lock fewer records. However, in some special cases, this theory has limitations.
select
*
from
stage_poi sp
where
sp.accurate_result=1
and (
sp.sync_status=0
or sp.sync_status=2
or sp.sync_status=4
);
0. Let's see how long it takes. 951 pieces of data take 6.22 seconds. It's really slow.
951 rows in set (6.22 sec)
1. explain first, the number of rows reaches 3.61 million, and type = ALL indicates full table scanning.
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+ | 1 | SIMPLE | sp | ALL | NULL | NULL | NULL | NULL | 3613155 | Using where | +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
2. All fields should be queried to return the number of records, because it is a single table query 0, and 951 records have been made.
3. Let explain's rows approach 951 as close as possible.
Take a look at exact_ Number of records with result = 1:
select count(*),accurate_result from stage_poi group by accurate_result; +----------+-----------------+ | count(*) | accurate_result | +----------+-----------------+ | 1023 | -1 | | 2114655 | 0 | | 972815 | 1 | +----------+-----------------+
We see accurate_ The discrimination of the field result is very low. The whole table has only three values - 1,0,1. In addition, the index cannot lock a small amount of data.
Take another look at sync_status field:
select count(*),sync_status from stage_poi group by sync_status; +----------+-------------+ | count(*) | sync_status | +----------+-------------+ | 3080 | 0 | | 3085413 | 3 | +----------+-------------+
Similarly, the degree of discrimination is also very low, and according to theory, it is not suitable for indexing.
After analyzing the problem, it seems that this table cannot be optimized. The discrimination between the two columns is very low. Even if the index is added, it can only adapt to this situation. It is difficult to do universal optimization, such as sync_status 0 and 3 are evenly distributed, so the locked records are also at the level of millions.
4. Find the business party to communicate and see the usage scenario. This is how the business party uses the SQL statement. It will scan the qualified data every five minutes, and sync the data after processing_ The status field becomes 1. The number of qualified records in five minutes will not be too many, about 1000. After understanding the usage scenarios of the business side, it becomes simple to optimize this SQL, because the business side ensures the imbalance of data. If you add an index, you can filter out most of the unnecessary data.
5. According to the indexing rules, use the following statements to establish the index
alter table stage_poi add index idx_acc_status(accurate_result,sync_status);
6. Observe the expected results and find that it only takes 200ms, which is more than 30 times faster.
952 rows in set (0.20 sec)
Let's review the process of analyzing the problem. Single table query is relatively easy to optimize. Most of the time, we only need to index the fields in the where condition according to the rules. If it's just this kind of "mindless" optimization, it's obvious that some columns with very low discrimination and columns that should not be indexed will also be indexed, which will affect the insertion Update performance has a serious impact, and it may also affect other query statements. Therefore, the use scenario of SQL in step 4 is very critical. Only when we know this business scenario can we better assist us in better analyzing and optimizing query statements.
Statement that cannot be optimized
select
c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
c.last_modified_user_id
from
contact c
inner join
contact_branch cb
on c.id = cb.contact_id
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 10802
and oei.org_category = - 1
order by
c.created_time desc limit 0 ,
10;
Still a few steps.
0. Let's see how long the statement runs. It took 13 seconds for 10 records, which is unbearable.
10 rows in set (13.06 sec)
1.explain
+----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+ | 1 | SIMPLE | oei | ref | idx_category_left_right,idx_data_id | idx_category_left_right | 5 | const | 8849 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | bu | ref | PRIMARY,idx_userid_status | idx_userid_status | 4 | meituancrm.oei.data_id | 76 | Using where; Using index | | 1 | SIMPLE | cb | ref | idx_branch_id,idx_contact_branch_id | idx_branch_id | 4 | meituancrm.bu.branch_id | 1 | | | 1 | SIMPLE | c | eq_ref | PRIMARY | PRIMARY | 108 | meituancrm.cb.contact_id | 1 | | +----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+
From the perspective of execution plan, mysql first checks org_ emp_ Scan 8849 records in info table, and then index idx_ userid_ Branch status association_ User table and index idx_branch_id associated contact_branch table, and the last primary key is associated with the contact table.
rows returns very little, and you can't see any exceptions. When we look at the statement, we find that there is an order by + limit combination behind it. Is it because of too much sorting? So we simplify the SQL, remove the following order by and limit, and see how many records are used to sort.
select
count(*)
from
contact c
inner join
contact_branch cb
on c.id = cb.contact_id
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 10802
and oei.org_category = - 1
+----------+
| count(*) |
+----------+
| 778878 |
+----------+
1 row in set (5.19 sec)
It is found that 778878 records are locked before sorting. If sorting for 700000 result sets will be disastrous. No wonder it is so slow. Can we change our thinking and create according to the contact first_ Time sorting, will it be faster to join again?
So it can be transformed into the following sentence, or straight_join to optimize:
select
c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
c.last_modified_user_id
from
contact c
where
exists (
select
1
from
contact_branch cb
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 10802
and oei.org_category = - 1
where
c.id = cb.contact_id
)
order by
c.created_time desc limit 0 ,
10;
Verify that the effect is expected to increase by more than 13000 times in 1ms!
10 rows in set (0.00 sec)
I thought it was done, but we missed a detail in the previous analysis. In theory, the cost of sorting before joining is the same as that of joining before sorting. Why is it increased so much because there is a limit! The general execution process is as follows: mysql first gets the top 10 records by index, and then goes to join filter. When it finds that there are less than 10 records, go to 10 records again and join again. Obviously, when there are a lot of data filtered by the inner join, it will be a disaster. In extreme cases, one piece of data in the inner layer cannot be found, and mysql is foolish to take 10 records at a time, Almost traversed this data table!
Under SQL test with different parameters:
select
sql_no_cache c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
c.last_modified_user_id
from
contact c
where
exists (
select
1
from
contact_branch cb
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 2875
and oei.org_category = - 1
where
c.id = cb.contact_id
)
order by
c.created_time desc limit 0 ,
10;
Empty set (2 min 18.99 sec)
2 min 18.99 sec! Much worse than before. Due to the nested loop mechanism of mysql, it is basically impossible to optimize in this case. This statement can only be handed over to the application system to optimize its own logic.
Through this example, we can see that not all statements can be optimized, but often when we optimize, some extreme cases fall during the regression of SQL use cases, which will cause more serious consequences than before. Therefore, first: don't expect all statements to be optimized through SQL. Second: don't be too confident and optimize only for specific cases, ignoring more complex situations.
That's all for the analysis of slow query cases. The above are only some typical cases. In the optimization process, we have encountered more than 1000 rows of "garbage SQL" involving 16 table join s, online and offline database differences that lead to the application being directly dragged to death by slow queries, varchar equivalence comparison without single quotation marks, and Cartesian product queries that directly kill the slave database. No matter how many cases are, they are only the accumulation of experience. If we are familiar with the internal principles of query optimizer and index, it will be particularly simple to analyze these cases.
Words written later
This paper introduces the MySQL index principle and some methodologies to optimize slow query based on a case of slow query; The typical cases encountered are analyzed in detail. In fact, after doing sentence optimization for such a long time, I found that any database level optimization is not equal to the optimization of application system. MySQL can be used to support Google/FaceBook/Taobao applications, but it may not even support your personal website. Apply the recent popular words: "query is easy, optimization is not easy, and write and cherish!"
reference:
1. High performance MySQL 2 Data structure and algorithm analysis