1, Concept of index
An index is a sorted list in which the index value and the physical address of the row containing the data containing the value are stored (similar to the linked list of C language, which points to the memory address of the data record through a pointer).
After using the index, you can not scan the whole table to locate the data of a row, but first find the corresponding physical address of the row data through the index table, and then access the corresponding data, so it can speed up the query speed of the database.
An index is like a table of contents of a book. You can quickly find the required content according to the page numbers in the table of contents.
An index is a method of sorting the values of one or more columns in a table.
The purpose of indexing is to speed up the search or sorting of records in the table.
2, Function of index
After setting the appropriate index, the database can greatly speed up the query speed by using various fast positioning technologies, which is the main reason for creating all the databases.
When the table is large or the query involves multiple tables, using indexes can improve the query speed thousands of times.
It can reduce the IO cost of the database, and the index can also reduce the sorting cost of the database.
By creating a unique index, you can ensure the uniqueness of each row of data in the data table.
You can speed up the connection between tables.
When using grouping and sorting, the time of grouping and sorting can be greatly reduced.
Side effects of indexing
- Indexing requires additional disk space.
For MyISAM engine, index file and data file are separated, and index file is used to save the address of data record.
The table data file of InnoDB engine itself is an index file. - It takes more time to insert and modify data because the index changes with it.
3, Principles and basis for index creation
Indexing with can improve the speed of database queries, but it is not suitable for creating indexes in any case. Because the index itself will consume system resources, when there is an index, the database will first query the index and then locate the specific data row. If the index is not used properly, it will increase the burden of the database.
The primary key and foreign key of a table must have an index. Because the primary key is unique, the foreign key is associated with the primary key of the child table, which can be quickly located during query.
Tables with more than 300 rows of records should have indexes. If there is no index, you need to traverse the table, which will seriously affect the performance of the database.
For tables that often connect with other tables, an index should be established on the connection field.
Fields with poor uniqueness are not suitable for indexing.
Fields that are updated too frequently are not suitable for index creation.
The fields that often appear in the where clause, especially the fields of large tables, should be indexed.
Indexes should be built on highly selective fields.
The index should be built on small fields. For large text fields or even super long fields, do not build an index.
4, Classification and creation of indexes
1. General index
The most basic index type has no restrictions such as uniqueness.
- Create index directly
CREATE INDEX Index name ON Table name (Listing[(length)]);
#(column name (length)): length is optional. If the value of length is ignored, the value of the entire column is used as the index. If you specify to use the length characters before the column to create the index, it is helpful to reduce the size of the index file.
#It is recommended that index names end with "_index".
Example: create index phone_index on member (phone); select phone from member; show create table member;
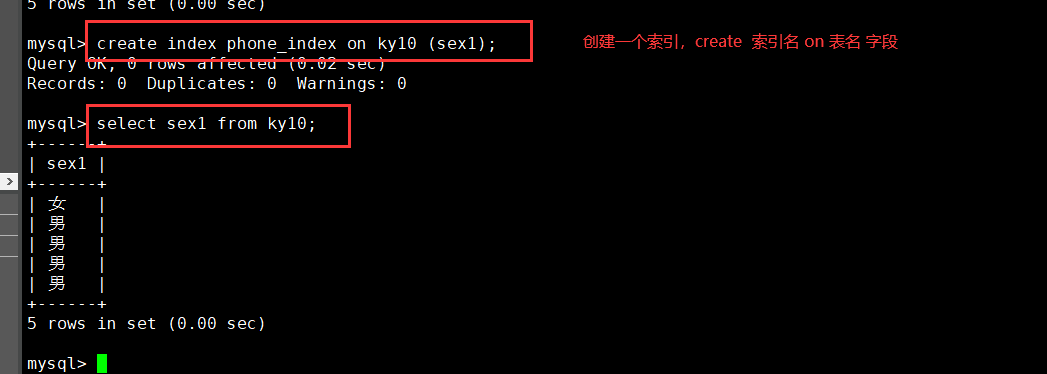

Modify table creation
ALTER TABLE Table name ADD INDEX Index name (Listing); Example: alter table member add index id_index (id); select id from member; select id,name from member;

Specify the index when creating the table
CREATE TABLE Table name ( Field 1 data type,Field 2 data type[,...],INDEX Index name (Listing)); Example: create table test(id int(4) not null,name varchar(10) not null,cardid varchar(18) not null,index id_index (id)); show create table test;

2. Unique index
It is similar to a normal index, but the difference is that each value of a unique index column is unique.
The unique index allows null values (note that it is different from the primary key). If you are creating with a composite index, the combination of column values must be unique. Adding a unique key automatically creates a unique index.
Create unique index directly
CREATE UNIQUE INDEX Index name ON Table name(Listing); Example: select * from member; create unique index address_index on member (address); create unique index name_index on member (name); show create table member;

Modify table creation
ALTER TABLE Table name ADD UNIQUE Index name (Listing); Example: alter table member add unique cardid_index (cardid);
Specify when creating a table
CREATE TABLE Table name (Field 1 data type,Field 2 data type[,...],UNIQUE Index name (Listing)); example:create table amd2 (id int,name varchar(20),unique id_index (id)); show creat table amd2;
3. Primary key index
Is a special unique index and must be specified as "PRIMARY KEY". A table can only have one PRIMARY KEY. Empty values are not allowed. Adding a PRIMARY KEY automatically creates a PRIMARY KEY index.
Specify when creating a table
CREATE TABLE Table name ([...],PRIMARY KEY (Listing)); Example: create table test1 (id int primary key,name varchar(20)); create table test2 (id int,name varchar(20),primary key (id)); show create table test1; show create table test2;
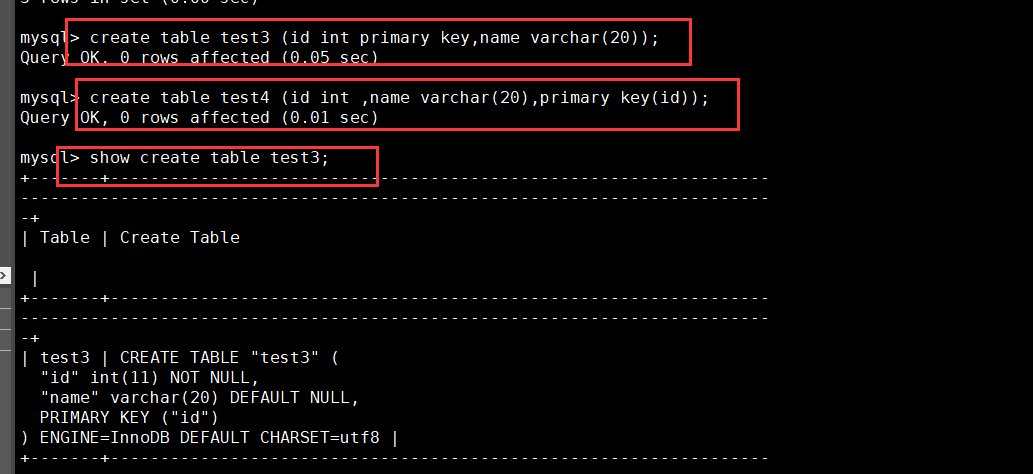
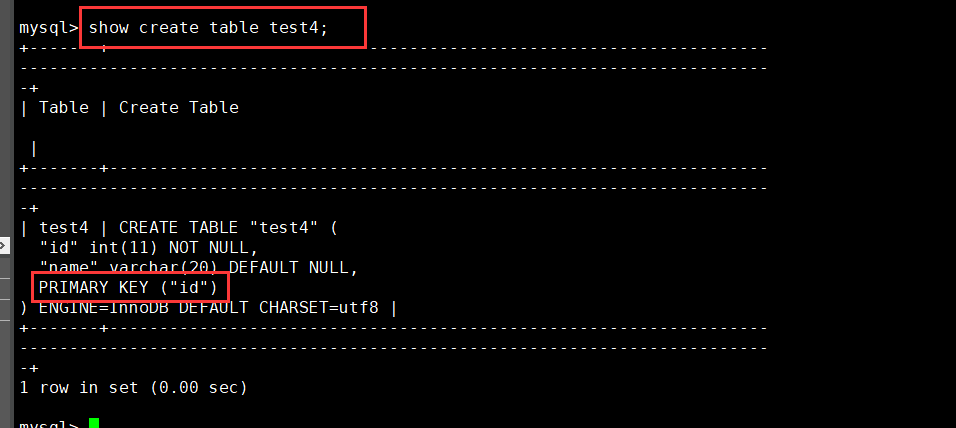
Modify table creation
ALTER TABLE Table name ADD PRIMARY KEY (Listing);
4. Composite index (single column index and multi column index)
It can be an index created on a single column or an index created on multiple columns.
CREATE TABLE Table name (Column name 1 data type,Column name 2 data type,Column name 3 data type,INDEX Index name (Column name 1,Column name 2,Column name 3)); select * from Table name where Column name 1='...' AND Column name 2='...' AND Column name 3='...'; example:create table amd1 (id int not null,name varchar(20),cardid varchar(20),index index_amd (id,name)); show create table amd1; insert into amd1 values(1,'zhangsan','123123'); select * from amd1 where name='zhangsan' and id=1;
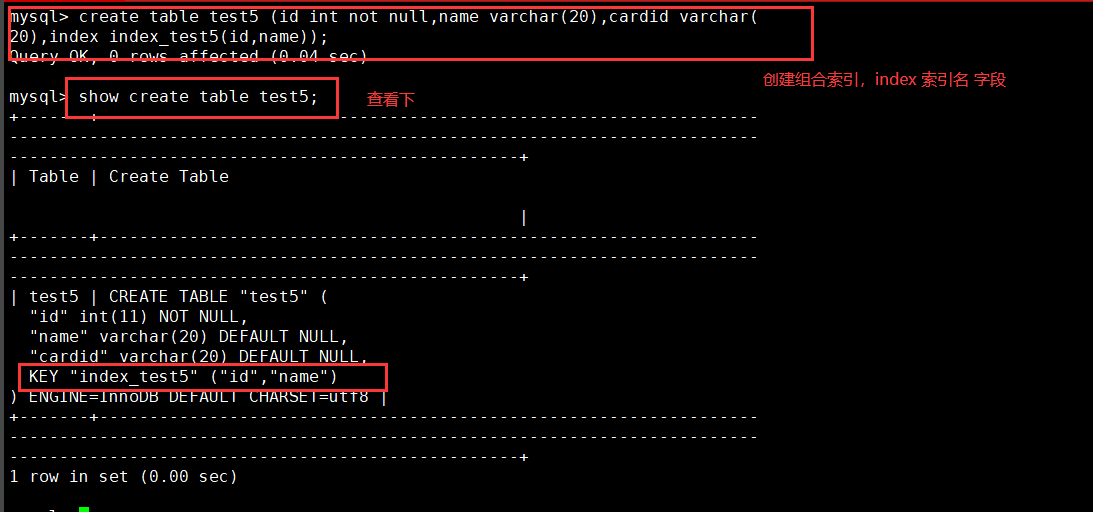
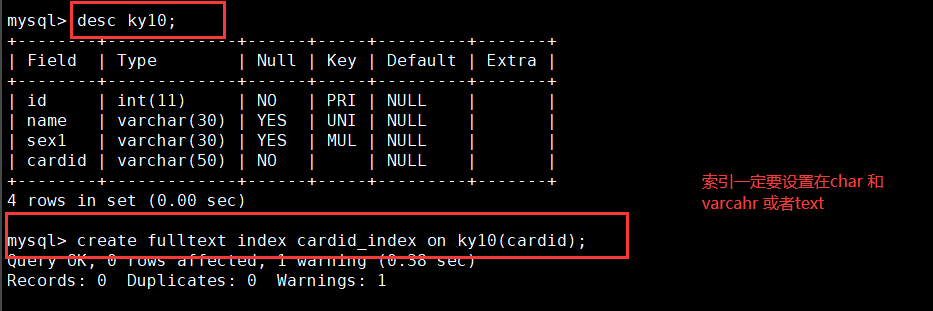
5. Full text index (FULLTEXT)
It is suitable for fuzzy query and can be used to retrieve text information in an article. On mysql5 FULLTEXT index before version 6 can only be used for MyISAM
Engine. After version 5.6, innodb engine also supports FULLTEXT index. Full TEXT indexes can be in CHAR, VARCHAR, or TEXT
Type. Only one full-text index is allowed per table.
Create index directly
CREATE FULLTEXT INDEX Index name ON Table name (Listing); Example: select * from member; create fulltext index remark_index on member (remark);
Modify table creation
ALTER TABLE Table name ADD FULLTEXT Index name (Listing);
Specify the index when creating the table
CREATE TABLE Table name (Field 1 data type[,...],FULLTEXT Index name (Listing));
#The data type can be CHAR, VARCHAR or TEXT
Using full-text index queries
SELECT * FROM Table name WHERE MATCH(Listing) AGAINST('Query content');
Example: select * from member where match(remark) against('this is vip');

5, View index
show index from Table name; show index from Table name\G; Vertical display of table index information show keys from Table name; show keys from Table name\G;
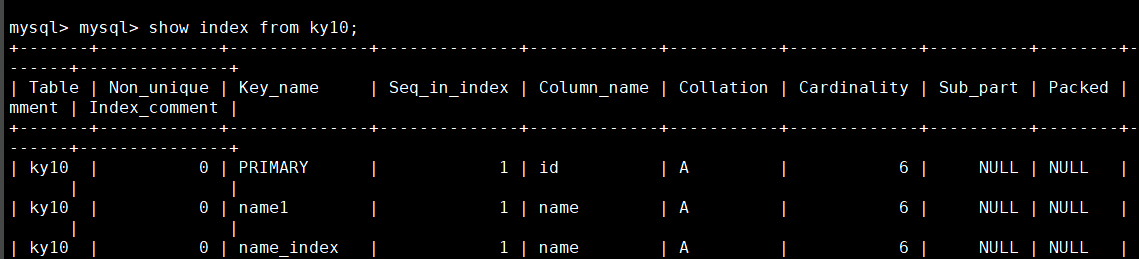
The meaning of each field is as follows:
| Table | Name of the table |
|---|---|
| Non_unique | 0 if the index cannot include duplicate words; 1 if yes |
| Key_name | The name of the index |
| Seq_in_index | Column ordinal in index, starting from 1 |
| Column_name | Column name |
| Collation | How columns are stored in the index. In MySQL, there are values' A '(ascending order) or NULL (no classification) |
| Cardinality | An estimate of the number of unique values in the index |
| Sub_part | If the column is only partially indexed, the number of characters indexed. NULL if the entire column is indexed |
| Packed | Indicates how keywords are compressed. NULL if not compressed |
| Null | If the column contains NULL, it contains YES. If not, the column contains NO |
| Index_type | Used indexing methods (BTREE, FULLTEXT, HASH, RTREE) |
| Comment | remarks |
6, Delete index
Delete index directly
DROP INDEX Index name ON Table name; Example: drop index name_index on member;
Delete index by modifying table mode
ALTER TABLE Table name DROP INDEX Index name; Example: alter table member drop id_index; show index from member;


Delete primary key index
ALTER TABLE Table name DROP PRIMARY KEY;
MySQL transaction
1, MySQL transaction concept
Transaction is a mechanism and an operation sequence, which contains a set of database operation commands, and submits or cancels the operation request to the system as a whole, that is, this set of database commands are either executed or not executed.
Transaction is an inseparable work logic unit. When performing concurrent operations on the database system, transaction is the smallest control unit.
Transactions are applicable to the scenario of database systems operated by multiple users at the same time, such as banks, insurance companies and securities trading systems.
Transaction is to ensure data consistency through transaction integrity.
To put it bluntly, the so-called transaction is a sequence of operations. These operations are either executed or not executed. It is an inseparable work unit.
2, ACID characteristics of transactions
ACID refers to the four characteristics that a transaction should have in a reliable database management system (DBMS): Atomicity, Consistency, Isolation and Durability. These are several characteristics of a reliable database.
- Atomicity: refers to that a transaction is an indivisible work unit, and all operations in the transaction either occur or do not occur.
A transaction is a complete operation, and the elements of a transaction are inseparable. All elements in a transaction must be committed or rolled back as a whole. If any element in the transaction fails, the entire transaction fails.
- Consistency: refers to that the integrity constraints of the database are not destroyed before and after the transaction.
When the transaction completes, the data must be in a consistent state. Before the transaction starts, the data stored in the database is in a consistent state. In an ongoing transaction, data may be in an inconsistent state.
When the transaction completes successfully, the data must return to the known consistent state again.
- Isolation: in a concurrent environment, when different transactions manipulate the same data at the same time, each transaction has its own complete data space.
All concurrent transactions that modify data are isolated from each other, indicating that the transaction must be independent and should not depend on or affect other transactions in any way.
A transaction that modifies data can access it before another transaction that uses the same data starts, or after another transaction that uses the same data ends.
- Persistence: after the transaction is completed, the changes made by the transaction to the database will be permanently saved in the database and will not be rolled back.
It means that the result of transaction processing is permanent regardless of whether the system fails or not. Once the transaction is committed, the effect of the transaction will be permanently retained in the database.
1. Interaction between transactions
The interaction between transactions can be divided into several types:
1. Dirty read: a transaction reads uncommitted data from another transaction, which may be rolled back.
2. Non repeatable reading: two identical queries in a transaction return different data. This is caused by the submission of other transaction modifications in the system during query.
3. Unreal reading: a transaction modifies the data in a table, which involves all data rows in the table. At the same time, another transaction also modifies the data in the table. This modification is to insert a new row of data into the table. Then, the user who operates the previous transaction will find that there are still unmodified data rows in the table, as if there was an illusion.
4. Lost update: two transactions read the same record at the same time. A modifies the record first, and B also modifies the record (B does not know that a has modified it). After B submits the data, B's modification result overwrites a's modification result.
3, Mysql and transaction isolation level
(1) Read uncommitted: read uncommitted data: dirty reads are not resolved
(2) Read committed: read committed data: dirty reads can be resolved
(3) Repeatable read: Reread read: can solve dirty read and non repeatable read - mysql default
(4) serializable: serialization: it can solve dirty reads, non repeatable reads and virtual reads - equivalent to locking tables
The default transaction level of mysql is repeatable read, while Oracle and SQL Server are read committed.
1. Query global transaction isolation level
show global variables like '%isolation%'; SELECT @@global.tx_isolation;

2. Query session transaction isolation level
show session variables like '%isolation%'; SELECT @@session.tx_isolation; SELECT @@tx_isolation;

3. Set global transaction isolation level
set global transaction isolation level read committed;
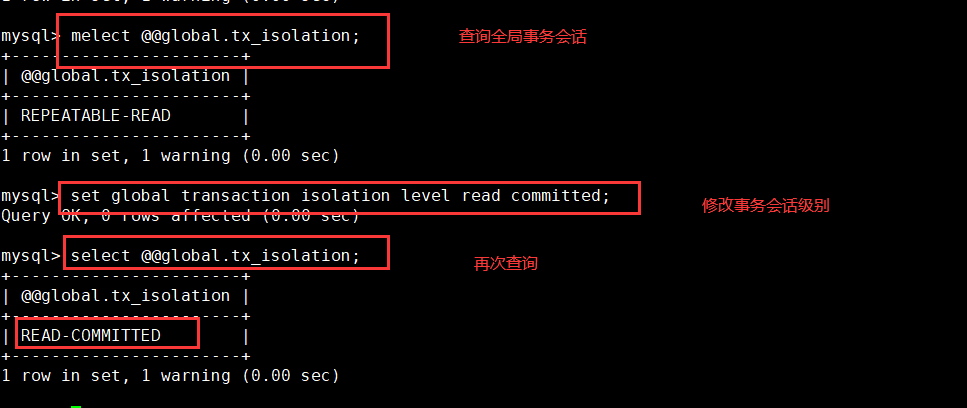
4. Set session transaction isolation level
set session transaction isolation level read committed;

4, Transaction control statement
BEGIN or START TRANSACTION: explicitly start a transaction.
COMMIT or COMMIT WORK: COMMIT the transaction and make all changes made to the database permanent.
ROLLBACK or ROLLBACK WORK: ROLLBACK will end the user's transaction and undo all uncommitted changes in progress.
SAVEPOINT S1: using SAVEPOINT allows you to create a rollback point in a transaction. There can be multiple rollback points in a transaction
SAVEPOINT; "S1" stands for the rollback point name.
ROLLBACK TO [SAVEPOINT] S1: rollback the transaction to the marked point.
case
create database SCHOOL; use SCHOOL; create table CLASS( id int(10) primary key not null, name varchar(40), money double ); insert into CLASS values(1,'A',1000); insert into CLASS values(2,'B',1000); select * from CLASS;

1. Test commit transaction
begin; update CLASS set money= money - 100 where name='A'; select * from CLASS; commit; quit mysql -u root -p use SCHOOL; select * from CLASS;
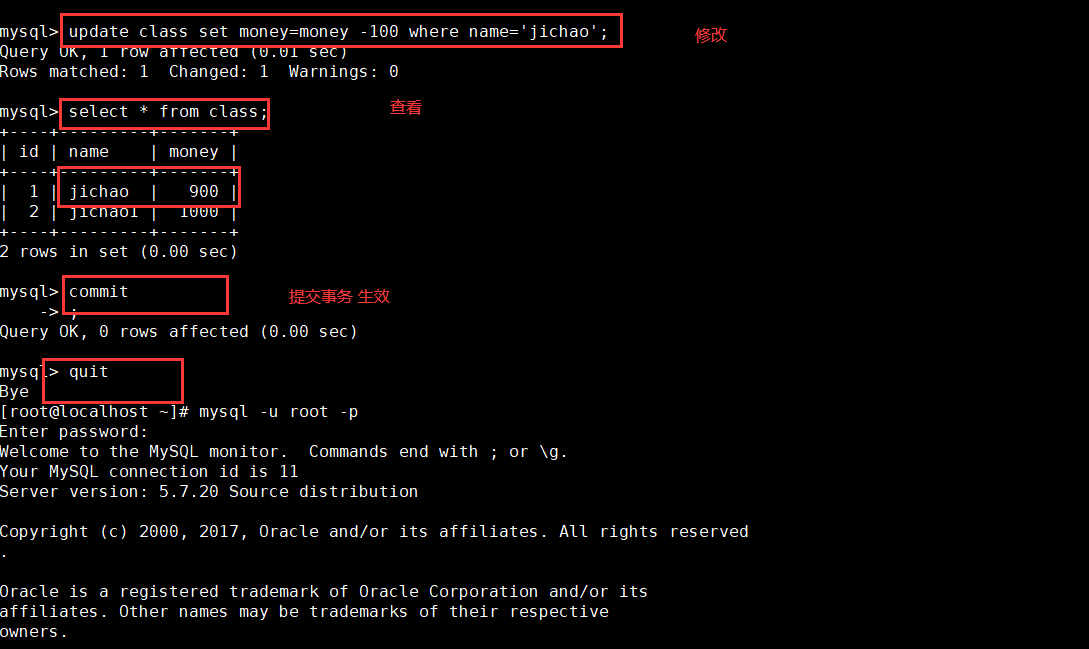

2. Test rollback transaction
begin; update CLASS set money= money + 100 where name='A'; select * from CLASS; rollback; End transaction, undo operation quit mysql -u root -p use SCHOOL; select * from CLASS;
3. Test multipoint rollback
begin; update CLASS set money= money + 100 where name='A'; select * from CLASS; SAVEPOINT S1; update CLASS set money= money + 100 where name='B'; select * from CLASS; SAVEPOINT S2; insert into CLASS values(3,'C',1000); select * from CLASS; ROLLBACK TO S1; select * from CLASS;
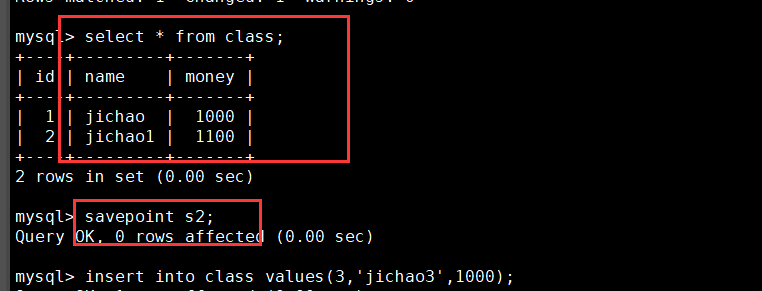
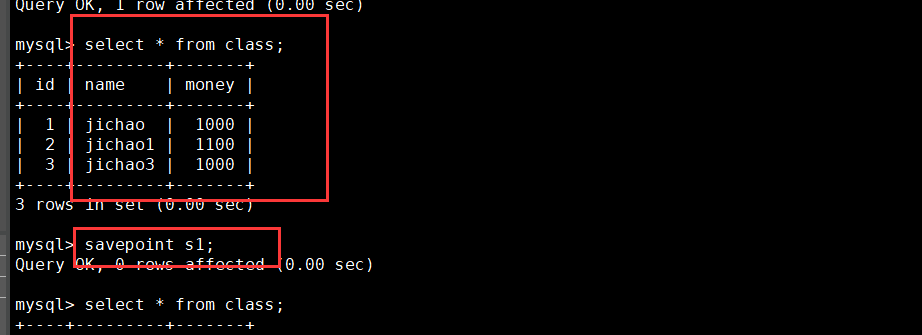
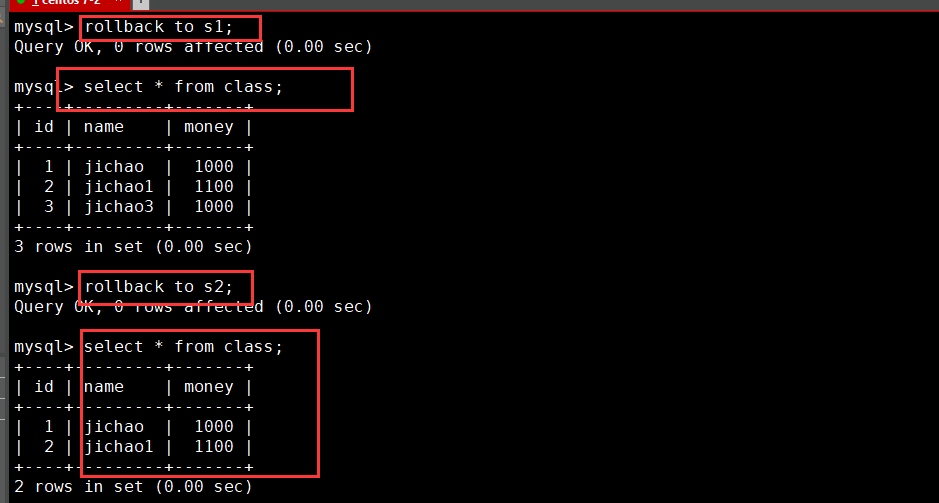
4. Control transactions using set settings
SET AUTOCOMMIT=0; #Disable automatic submission SET AUTOCOMMIT=1; #Enable automatic submission. Mysql defaults to 1 SHOW VARIABLES LIKE 'AUTOCOMMIT'; #View the AUTOCOMMIT value in Mysql
If Auto commit is not enabled, all mysql operations connected to the current session will be treated as a transaction until you enter rollback commit; The current transaction is over. Before the end of the current transaction, the operation results of any current session cannot be read when a new mysql connection is made.
If Auto commit is enabled, mysql will treat each sql statement as a transaction, and then automatically commit. Of course, whether it is turned on or not, begin;
commit|rollback; Are independent affairs.
use SCHOOL; select * from CLASS; SET AUTOCOMMIT=0; SHOW VARIABLES LIKE 'AUTOCOMMIT'; update CLASS set money= money + 100 where name='B'; select * from CLASS; quit mysql -u root -p use SCHOOL; select * from CLASS;
MySQL storage engine
1, Storage engine concept introduction
The data in MySQL is stored in files with various technologies. Each technology uses different storage mechanisms, indexing skills, locking levels, and finally provides different functions and capabilities. These different technologies and supporting functions are called storage engines in MySQL
The storage engine is the storage method or format in which MySQL stores data in the file system
1. Common MySQL storage engines:
1,MyISAM
2,InnoDB
Components in MySQL database are responsible for performing actual data I/O operations
In MySQL system, the storage engine is on top of the file system. The data will be transferred to the storage engine before being saved to the data file, and then stored according to the storage format of each storage engine
MyISAM
1. Characteristics of MyISAM
MyISAM does not support transactions or foreign key constraints. It only supports full-text indexing. Data files and index files are saved separately
Fast access speed and no requirement for transaction integrity. MyISAM is suitable for query and insert based applications
MyISAM is stored in three files on disk. The file name and table name are the same, but the extensions are: The frm file stores the definition of the table structure. The extension of the data file is MYD
The extension of the (MYData) index file is MYI (MYIndex)
In the form of table level locking, the entire table database is locked when the data is updated. It blocks each other in the process of reading and writing: it will block the reading of user data in the process of data writing
It will also block the user's data writing in the process of data reading. The data is written or read separately, which is fast and occupies relatively few resources
2. MyISAM table supports three different storage formats:
(1) Static (fixed length) table
Static tables are the default storage format. The fields in the static table are non variable fields, so each record is of fixed length. The advantages of this storage method are that it is stored very quickly, easy to cache, and easy to recover in case of failure; The disadvantage is that it usually occupies more space than dynamic tables.
(2) Dynamic table
Dynamic tables contain variable fields and records are not of fixed length. The advantage of this storage is that it takes less space, but frequent update and deletion of records will produce fragments. It is necessary to regularly execute the OPTIMIZE TABLE statement or myisamchk -r command to improve performance, and it is relatively difficult to recover in case of failure.
(3) Compression table
The compressed table is created by the myisamchk tool and occupies a very small space. Because each record is compressed separately, there is only a very small access expense.
3. Production scenarios applicable to MyISAM
The company's business does not need transaction support. For businesses that read or write data unilaterally, MyISAM storage engine has frequent data reading and writing. The scenario is not suitable for businesses with relatively low read-write concurrent access
Services with relatively few data modifications do not require very high data service consistency, and the hardware resources of the service server are relatively poor
InnoDB
1. InnoDB features
Supports transactions and four transaction isolation levels. MySQL starts from version 5.5.5, and the default storage engine is InnoDB
Read / write blocking is related to the transaction isolation level. It can cache indexes, data tables and primary keys very efficiently and store them in clusters. It supports partitions and table spaces, similar to oracle database
Foreign key constraints are supported. Full text indexing is not supported before 5.5 and after 5.5
Row level locking is still required when hardware resources are high, but full table scanning will still be table level locking, such as update table set a=1 where user
like '%lic%';
The number of rows of the table is not saved in InnoDB, such as select count() from table; InnoDB needs to scan the whole table to calculate the number of rows, but MyISAM just needs to simply read the number of saved rows. It should be noted that when the count () statement contains the where condition, MyISAM also needs to scan the entire table
For self growing fields, InnoDB must contain an index only for this field, but combined indexes can be established with other fields in MyISAM table
*When emptying the entire table, InnoDB is deleted row by row, which is very slow. MyISAM will rebuild the table
2, View the storage engines supported by the system
show engines;

3, View the storage engine used by the table
Method 1
show table status from Library name where name='Table name'\G; Example: show table status from SCHOOL where name='CLASS'\G;

Method 2
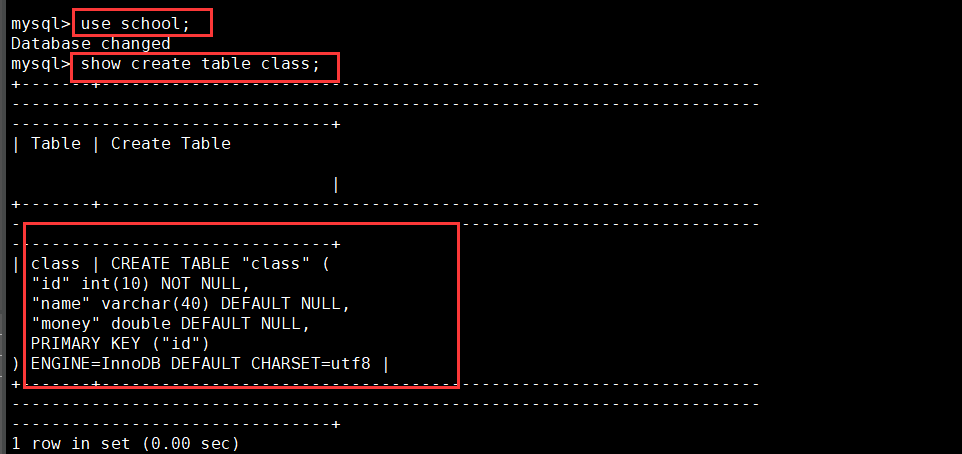
use Library name; show create table Table name; Example: use SCHOOL; show create table CLASS;

4, Modify storage engine
Method 1: modify through alter table
use Library name; alter table Table name engine=MyISAM; Example: use SCHOOL; alter table CLASS engine=myisam; show create table CLASS;

Method 2: modify / etc / my CNF configuration file, specify the default storage engine and restart the service
quit vim /etc/my.cnf [mysqld] default-storage-engine=INNODB systemctl restart mysqld.service #Note: this method is only valid for newly created tables after modifying the configuration file and restarting the mysql service. Existing tables will not be changed.

Method 3: specify the storage engine when creating a table through create table
use Library name; create table Table name(Field 1 data type,...) engine=MyISAM; Example: mysql -u root -p use SCHOOL; create table hellolic (name varchar(10),age char(4))engine=myisam;