MySQL is a must for programmers to master. In fact, the language is simple. As long as you practice more, you can master it.
1, MySQL Foundation
1. Database connection tool
1.1 Navicat tutorial
Navicat for MySQL tutorial (implementation of addition, deletion, modification and query)
2. DDL operation database
SHOW DATABASES;
The operation results are as follows:
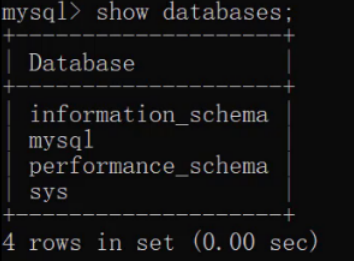
The databases queried above are self-contained databases installed with mysql. We will not operate these databases in the future.
2.1. Create a new database
CREATE DATABASE Database name;
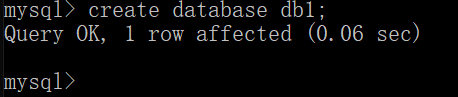
When creating the database, I don't know whether the db1 database has been created or not. If I directly create the database named db1 again, there will be an error.
 In order to avoid the above errors, make a judgment when creating the database. If it does not exist, create it again.
In order to avoid the above errors, make a judgment when creating the database. If it does not exist, create it again.
Create database (judge, create if it does not exist)
CREATE DATABASE IF NOT EXISTS Database name;

From the above effect, we can see that although the db1 database already exists, there is no error when creating db1 again, and the creation of db2 database is successful.
2.2. Delete database
Delete database
DROP DATABASE Database name;

Delete the database (judge and delete if it exists)
DROP DATABASE IF EXISTS Database name;

2.3. Using database
After the database is created, to create a table in the database, you must first specify which database to operate in. At this time, you need to use the database.
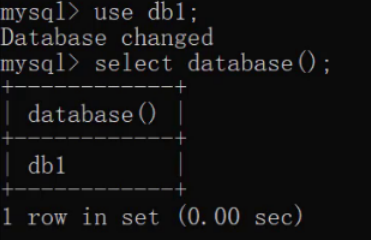
Use database
USE Database name;
View the database currently in use
SELECT DATABASE();
3. Cloud operation data table
The operation table is to add, Delete, Retrieve, Update and Delete the table.
3.1 query table
Query all table names under the current database
SHOW TABLES
There are no tables in the database we created, so we enter the mysql database that comes with mysql and execute the above statement to check
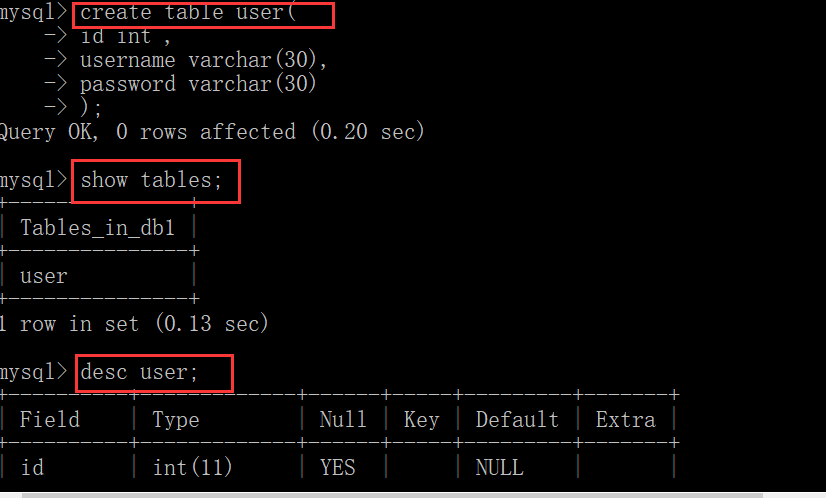
CREATE TABLE Table name ( Field name 1 data type 1, Field name 2 data type 2, ... Field name n data type n );
Note: no comma can be added at the end of the last line
example:
create table tb_user ( id int, username varchar(20), password varchar(32) );
3.2. Data type:
The data types of Mysql are divided into three categories: value, date and string.
Value:
tinyint: small integer type, accounting for one byte
int: large integer type, accounting for four bytes
-------------- eg : age int
double: floating point type
---------------Format used: field name double (total length, number of digits reserved after decimal point)
--------------- eg : score double(5,2)
Date:
Date: date value. Only include mm / DD / yy
----------eg : birthday
Date: datetime: mix date and time values. Including month, day, hour, minute and second
character string:
char: fixed length string.
Advantages: high storage performance
Disadvantages: waste of space
eg: name char(10) if the number of stored data characters is less than 10, it will also occupy 10 space
varchar: variable length string.
Advantages: space saving
Disadvantages: low storage performance
eg: name varchar(10) if the number of stored data characters is less than 10, the number of data characters will take up a few space
learn in order to practise:
Demand: design a student form, please pay attention to the rationality of data type and length
- number
- Name, with a maximum length of 10 Chinese characters
- Gender, because there are only two possible values, there is at most one Chinese character
- Birthday, value is mm / DD / yy
- Admission results, with two decimal places reserved
- Mail address, maximum length not exceeding 64
- Home contact number, not necessarily mobile phone number, may appear - and other characters
- Student status (in numbers, normal, suspension, graduation...)
The statement is created as follows:
Create table student ( id int, name varchar(10), gender char(1), birthday date, score double(5,2), email varchar(15), tel varchar(15), status tinyint );
3.3 delete table
Delete table:
DROP TABLE Table name;
Judge whether the table exists when deleting the table
DROP TABLE IF EXISTS Table name;
The operation results are as follows:

3.4 modification table
Modify table name
ALTER TABLE Table name RENAME TO New table name; -- Add table name student Change to stu alter table student rename to stu;
Add a column:
ALTER TABLE Table name ADD Column name data type; -- to stu Add a column to the table address,The field type is varchar(50) alter table stu add address varchar(50);
Modify data type
ALTER TABLE Table name MODIFY Column name new data type; -- take stu In table address Change the type of the field to char(50) alter table stu modify address char(50);
Modify column names and data types
ALTER TABLE Table name CHANGE Column name new column name new data type; --take stu In table address Change the field name to addr ,Data type changed to varchar(50); alter table stu change address addr varchar(50);
Delete column
ALTER TABLE Table name DROP Listing; --take stu In table addr Field deletion alter table stu drop addr;
3. DML operation on data
DML is mainly used to insert, delete and update data.
4.1. Add data
Adds data to the specified column
INSERT INTO Table name(Column name 1, column name 2,..)VALUES(Value 1,Value 2,..);
Add data to all columns
INSERT INTO Table name VALUES(Value 1,Value 2,...);
Batch add data
INSERT INTO Table name(Column name 1,Column name 2,....)VALUES(Value 1,Value 2,.....),(Value 1,Value 2,.....),(Value 1,Value 2,.....)..; INSERT INTO Table name VALUES(Value 1,Value 2,...),(Value 1, value 2,....)...;
practice:
In order to demonstrate whether the following addition, deletion and modification operations are successful, all data are provided here for your reference
select * from stu; -- Adds data to the specified column INSERT INTO stu (id, NAME) VALUES (1, 'Zhang San'); -- Add data to all columns, and the list of column names can be omitted INSERT INTO stu (id,NAME,sex,birthday,score,email,tel,STATUS) VALUES (2,'Li Si','male','1999-11- 11',88.88,'lisi@itcast.cn','13888888888',1); INSERT INTO stu VALUES (2,'Li Si','male','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1); -- Batch add data INSERT INTO stu VALUES (2,'Li Si','male','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1), (2,'Li Si','male','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1), (2,'Li Si','male','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1);
4.2. Modify data
Modify table data
UPDATE Table name SET Column name 1=Value 1,Column name 2=Value 2,... [WHERE condition] ;
If no condition is added in the modification statement, all data will be modified!
Like the brackets in the above statement, it means that this part can be omitted in writing sql statements
practice:
Zhang San's gender was changed to female
UPDATE STU SET SEX = 'female' WHERE NAME = 'Zhang San';
Change Zhang San's birthday to 1999-12-12 and the score to 99.99
update stu set sex = 'female';
Note: if the update statement does not add the where condition, all the data in the table will be modified!
update stu set sex = 'female';
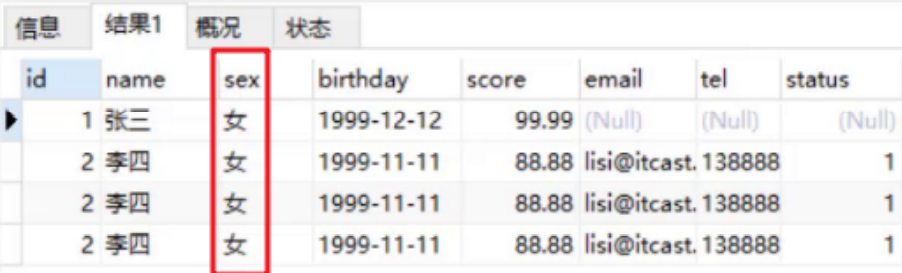
4.3. Delete data
Delete data
DELETE FROM Table name [WHERE condition];
practice:
-- Delete three records delete from stu where name = 'Zhang San'; -- delete stu All data in the table delete from stu;
5. DQL data query
Full syntax of the query
SELECT Field list FROM Table name list WHERE Condition list GROUP BY Grouping field HAVING Post grouping condition ORDER BY sort field LIMIT Paging limit
The data sheet used in the following exercise:
-- delete stu surface drop table if exists stu; -- establish stu surface CREATE TABLE stu ( id int, -- number name varchar(20), -- full name age int, -- Age sex varchar(5), -- Gender address varchar(100), -- address math double(5,2), -- Mathematics achievement english double(5,2), -- English achievement hire_date date -- Admission time ); -- Add data INSERT INTO stu(id,NAME,age,sex,address,math,english,hire_date) VALUES (1,'Ma Yun',55,'male','Hangzhou',66,78,'1995-09-01'), (2,'Ma Huatong',45,'female','Shenzhen',98,87,'1998-09-01'), (3,'Musk',55,'male','Hong Kong',56,77,'1999-09-02'), (4,'Liu Bai',20,'female','Hunan',76,65,'1997-09-05'), (5,'Liu Qing',20,'male','Hunan',86,NULL,'1998-09-01'), (6,'Liu Dehua',57,'male','Hong Kong',99,99,'1998-09-01'), (7,'Zhang Xueyou',22,'female','Hong Kong',99,99,'1998-09-01'), (8,'Demacia',18,'male','Nanjing',56,65,'1994-09-02');
5.1. Basic query
5.1.1 grammar
Query multiple fields
SELECT Field list FROM Table name; SELECT *FROM Table name ; --Query all data
Remove duplicate records
SELECT DISTINCT Field list FROM Table name;
Alias
as as It can also be omitted
5.1.2 small exercises:
Query name and age columns
select name, age from stu;
Query the data of all columns. The list of column names can be replaced by *
select * from stu;
Query address information:
select address from stul;
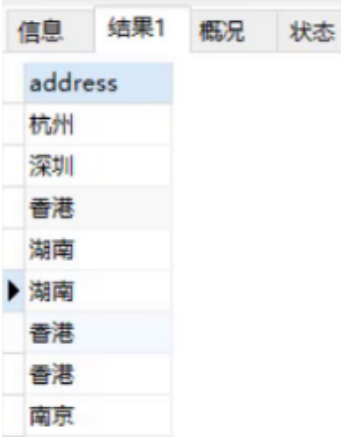
From the above results, we can see that there are duplicate data, and we can also use the distinct keyword to duplicate the duplicate data.
Remove duplicate data;
select distinct address from stu;
Query name, math score and english score. And alias math and english through as (the as keyword can be omitted)
select name,math as Mathematics achievement,english as English achievement from stu; select name,math Mathematics achievement,english English achievement from stu;
5.2. Condition query
5.2.1 Grammar:
SELECT Field list FROM Table name WHERE Condition list;
condition
The following operators can be used for condition lists
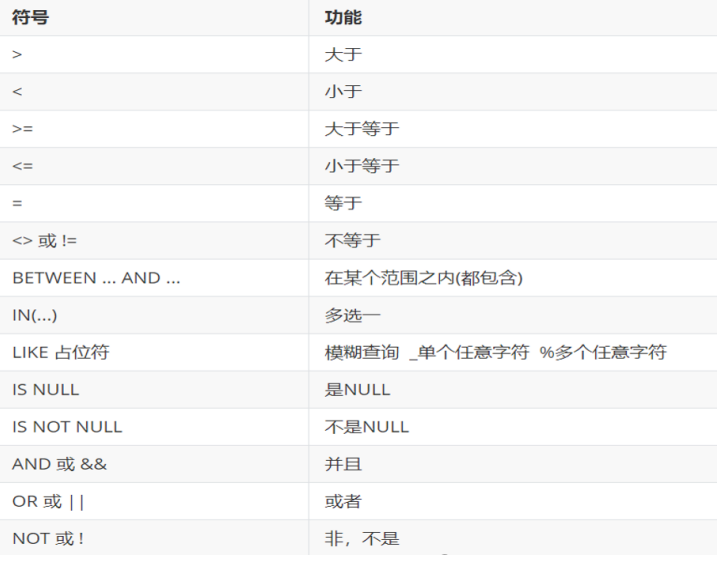
5.2.2 condition query exercise:
Query college information older than 20
select * from stu where age > 20;
Query college information aged 20 or older
select * from stu where age >=20;
Query the information of students who are over 20 years old and under 30 years old
select * from stu where age >=20 && age <=30; select * from stu where age >=20 and age <=30;
Both & & and and in the above sentence mean and. It is suggested to use and;
You can also use between... and to realize the above requirements;
select * from stu where age between 20 and 30;
Query the information of students whose enrollment date is between 'September 1, 1997' and 'September 1, 1999'
select * form stu where hire_date between '1997-09-01' and '1999.09.01';
Query the information of students whose age is equal to 18 years old
select * from stu where age = 18;
Query the college information whose age is equal to 18 years old, 20 years old or 22 years old
select * from stu where age = 18 or age = 20 or age =22; select * from stu where age in (18,20,22);
Query the information of students whose English score is null
null values cannot be compared with = or! =. You need to use is or is not
select * from stu where english =null ;— This grammar is wrong
select * from stu where english is null; select * from stu where english is not null;
5.2.3 fuzzy query exercise
like keyword is used in fuzzy query, and wildcards can be used to occupy positions;
(1)_: Represents a single arbitrary character;
(2) %: represents any number of characters;
Inquire about the information of the student surnamed 'ma'
select * from stu where name like 'horse%';
Query the student information whose second word is "flower"
select * from stu where name like '_flower%';
Query the information of students whose names contain 'de'
select * from stu where name = '%virtue%;
5.4 Sorting Query
5.4.1 grammar
SELECT Field list FROM Table name ORDER BY Sort field name 1 [Sort by 1], Sort field name 2[Sort by 2]......;
There are two sorting methods in the above syntax, namely:
ASC ascending order (default value);
DESC: descending order;
Note that there are multiple sorting conditions. When the condition value of the current edge is the same, the sorting will be carried out according to the second condition
5.4.2 practice:
Query student information, in ascending order of age
select * from stu order by age;
Query student information and arrange it in descending order according to math scores
select * from stu order by desc;
Query the student information and arrange it in descending order according to the math scores. If the math scores are the same, they are arranged according to the English scores.
select * from stu order by math desc , english asc;
5.5 aggregation function
5.5.1 concept
Take a column of data as a whole for longitudinal calculation.
How to understand? The following table is assumed
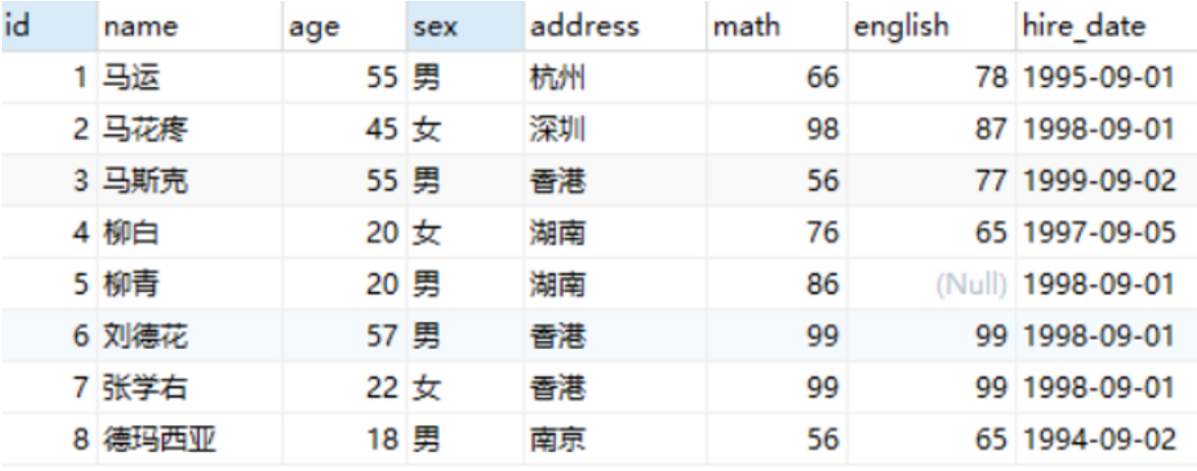
Now we need to sum up the math scores of all the data in the table. This is the vertical summation of the math field.
5.5.2 aggregation function classification
| Function name | function |
|---|---|
| Count (column name) | Statistical quantity (generally non null columns) |
| Max (column name) | Maximum |
| Min (column name) | minimum value |
| Sum (column name) | Sum |
| AVG (column name) | average value |
5.5.3 aggregate function syntax
SELECT Aggregate function name (column name) FROM surface;
Note: null values do not participate in all aggregate function operations
5.5.4 practice
Count the total number of students in the class
select count(id) from stu; select count(english) from stu;
The above statement makes statistics according to a field. If the value of a row of the field is null, it will not be counted. So it can be implemented in count(). Represents all field data, and it is impossible for all data in a row to be null, so it is recommended to use count(*)
select count(*) from stu;
Query the highest score of math scores
select max(math) from stu;
Query the lowest score of math scores
select sum(math) from stu;
Average score of query mathematics score
select * from avg(math) from stu;
Query the total score of math scores
select sum(math) from stu;
Query the lowest score of English score
select min(english) from stu;
5.6 group query
5.6.1 grammar
SELECT field list FROM table name [WHERE pre grouping condition restriction] GROUP BY grouping field name [HAVING post grouping condition filtering];
Note: after grouping, the fields queried are aggregate functions and grouping fields, and querying other fields is meaningless;
5.6.2 practice
Check the average math scores of male and female students
select sex,avg(math) from stu group by sex;
select name,sex,avg(math) from stu group by sex;
The query nanme field here has no meaning;
Check the average math scores of male and female students and their numbers
select sex,avg(math), count() from stu group by sex;
Query the average math scores of male and female students and their respective numbers. Requirements: those with scores lower than 70 will not participate in the grouping;
select sex,avg(math),count() from stu where math >70 group by sex;
Query the average math scores of male and female students and their respective numbers. Requirements: those with scores lower than 70 will not participate in the grouping, and those with numbers greater than 2 after grouping
select sex,avg(math),count() from where math >70 group by sex having count() >2;
The difference between where and having is that the execution time is different:
Where is defined before grouping. If the conditions of where are not met, it will not participate in grouping,
having is to filter the results after grouping
The conditions that can be judged are different:
where cannot judge aggregate function
having can
5.7 paging query
5.7.1 Grammar:
SELECT Field list FROM Table name LIMINT Starting index, number of query entries;
Note: the starting index in the above statement starts from 0
5.7.1 practice
Query from 0, query 3 pieces of data
select * from stu limit 0,3;
Display 3 pieces of data on each page and query the data on the first page
select * from stu limit 3,3;
Display 3 pieces of data on each page and query the data on page 3
select * from stu limit 6,3;
From the above exercise, you can deduce the index calculation formula:
Start index = (Current page number - 1) * Number of items displayed per page
2, Mysql advanced
Knowledge overview
1. Master the use of constraints
2. Master table relationship and table building principles
3. Focus on multi table query operation
4. Master transaction operation
1. Constraints
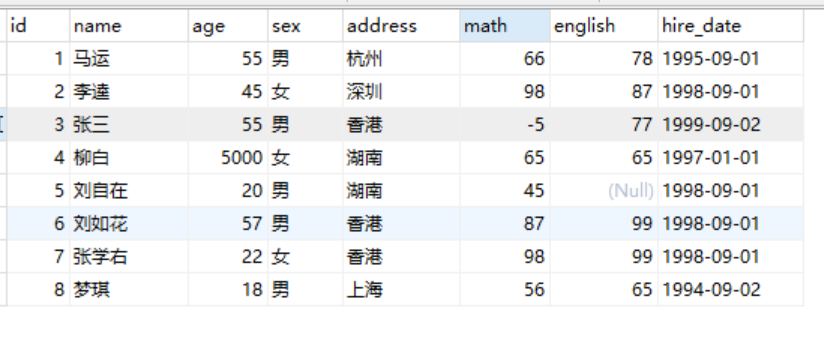
As can be seen from the above table, there are some problems with the data in the table:
-
The id column is generally used to mark the uniqueness of the data, while there are three pieces of data with id 1 in the above table, and Ma Huatong is not marked with id
-
The age column of Liu Bai's data is 5000, and people can't live to 5000
-
Zhang San's math score in this data is - 5, and no matter how bad he is in mathematics, he can't have a negative score
-
The english column (english score) value of Liu Qing's data is null, and the score is 0 even if there is no test
To solve the above data problems, we can restrict the addition of data from the database level. This is the constraint.
1.1 concept
-
Constraints are rules that act on columns in a table and are used to restrict the data added to the table
For example, we can restrict the id column so that its value cannot be repeated and cannot be null.
-
The existence of constraints ensures the correctness, effectiveness and integrity of data in the database
Adding constraints can limit incorrect data when adding data. The age is 5000 and the math score is - 5. This kind of invalid data can then ensure the integrity of the data.
1.2 classification
- Non NULL constraint: the keyword is NOT NULL
Ensure that all data in the column cannot have null values.
For example, the id column cannot be added successfully when adding three pieces of data.
-
UNIQUE constraint: the keyword is UNIQUE
Ensure that all data in the column is different.
For example, the value of three pieces of data in the id column is 1. Such data is absolutely not allowed to be added.
-
PRIMARY KEY constraint: the keyword is PRIMARY KEY
The primary key is the unique identifier of a row of data. It must be non empty and unique. Generally, we will add a primary key column to each table to uniquely identify the data.
For example, the id in the chart above can be used as the primary key to identify each data. In this way, the value of id in the data cannot be repeated and cannot be null.
-
CHECK constraints: the keyword is CHECK
Ensure that the values in the column meet a certain condition.
For example, we can add a range to the age column. The minimum age can be set to 1 and the maximum age can be set to 300. Only in this way can the data be more reasonable.Note: MySQL does not support checking constraints.
Is there no way to ensure that the age is within the specified range? It cannot be guaranteed from the database level. It can be limited in java code in the future, and the requirements can also be realized.
-
DEFAULT constraint: the keyword is DEFAULT
When saving data, if no value is specified, the default value is adopted.
For example, when we add this constraint to the english column, we specify that the default value is 0, so when we add data without specifying a specific value, the default given 0 will be adopted.
-
FOREIGN KEY constraint: the keyword is FOREIGN KEY
Foreign keys are used to establish links between the data of two tables to ensure the consistency and integrity of the data.
1.3 non null constraints
-
concept
Non NULL constraints are used to ensure that all data in a column cannot have NULL values
-
grammar
-
Add constraint
-- Add non empty constraint when creating table CREATE TABLE Table name( Column name data type NOT NULL, ... );
-- Add a non empty constraint after the table is created ALTER TABLE Table name MODIFY Field name data type NOT NULL;
-
Delete constraint
ALTER TABLE Table name MODIFY Field name data type;
-
1.4 unique constraints
-
concept
Unique constraints are used to ensure that all data in the column is different
-
grammar
-
Add constraint
-- Add unique constraints when creating tables CREATE TABLE Table name( Column name data type UNIQUE [AUTO_INCREMENT], -- AUTO_INCREMENT: Automatically grow when no value is specified ... ); CREATE TABLE Table name( Column name data type, ... [CONSTRAINT] [Constraint name] UNIQUE(Listing) );
-- Add unique constraint after creating table ALTER TABLE Table name MODIFY Field name data type UNIQUE;
-
Delete constraint
ALTER TABLE Table name DROP INDEX Field name;
-
1.5 primary key constraints
-
concept
The primary key is the unique identifier of a row of data. It must be non empty and unique
A table can only have one primary key
-
grammar
-
Add constraint
-- Add primary key constraint when creating table CREATE TABLE Table name( Column name data type PRIMARY KEY [AUTO_INCREMENT], ... ); CREATE TABLE Table name( Column name data type, [CONSTRAINT] [Constraint name] PRIMARY KEY(Listing) );
-- Add primary key constraint after creating the table ALTER TABLE Table name ADD PRIMARY KEY(Field name);
-
Delete constraint
ALTER TABLE Table name DROP PRIMARY KEY;
-
1.6 default constraints
-
concept
When saving data, if no value is specified, the default value is adopted
-
grammar
-
Add constraint
-- Add default constraints when creating tables CREATE TABLE Table name( Column name data type DEFAULT Default value, ... );
-- Add default constraints after creating the table ALTER TABLE Table name ALTER Listing SET DEFAULT Default value;
-
Delete constraint
ALTER TABLE Table name ALTER Listing DROP DEFAULT;
-
1.7 restraint exercise
Add appropriate constraints to the table as needed
-- Employee table
CREATE TABLE emp (
id INT, -- staff id,Primary key and self growth
ename VARCHAR(50), -- Employee name, non empty and unique
joindate DATE, -- Entry date; not blank
salary DOUBLE(7,2), -- Salary, non empty
bonus DOUBLE(7,2) -- Bonus, if not nearly, the default is 0
);
The specific requirements must be given above. We can create this table according to the requirements and add corresponding constraints for each column. The table creation statement is as follows:
DROP TABLE IF EXISTS emp; -- Employee table CREATE TABLE emp ( id INT PRIMARY KEY, -- staff id,Primary key and self growth ename VARCHAR(50) NOT NULL UNIQUE, -- Employee name, non empty and unique joindate DATE NOT NULL , -- Entry date; not blank salary DOUBLE(7,2) NOT NULL , -- Salary, non empty bonus DOUBLE(7,2) DEFAULT 0 -- Bonus. If there is no bonus, it defaults to 0 );
Through the above statement, you can create an emp table with constraints. Can constraints work. Next, let's verify one by one and add a piece of data without problems
INSERT INTO emp(id,ename,joindate,salary,bonus) values(1,'Zhang San','1999-11-11',8800,5000);
- Verify that the primary key constraint is non empty and unique
INSERT INTO emp(id,ename,joindate,salary,bonus) values(null,'Zhang San','1999-11-11',8800,5000);
The results are as follows:

As can be seen from the above results, the field id cannot be null. Let's add another piece of data as follows:
INSERT INTO emp(id,ename,joindate,salary,bonus) values(1,'Zhang San','1999-11-11',8800,5000);
The results are as follows:

As can be seen from the above results, the value of 1 is repeated. Therefore, the primary key constraint is used to limit the non empty and unique data. Then let's add another piece of data that meets the requirements
INSERT INTO emp(id,ename,joindate,salary,bonus) values(2,'Li Si','1999-11-11',8800,5000);
The results are as follows:

- Verify non empty constraints
INSERT INTO emp(id,ename,joindate,salary,bonus) values(3,null,'1999-11-11',8800,5000);
The results are as follows:

From the above results, we can see that the non NULL constraint of the ename field has taken effect.
- Verify unique constraints
INSERT INTO emp(id,ename,joindate,salary,bonus) values(3,'Li Si','1999-11-11',8800,5000);
The results are as follows:

As can be seen from the above results, the unique constraint of the ename field has taken effect.
- Verify default constraints
INSERT INTO emp(id,ename,joindate,salary) values(3,'Wang Wu','1999-11-11',8800);
After executing the above statement, query the data in the table, as shown in the figure below. You can see that the bonus column of Wang Wu has the default value of 0.
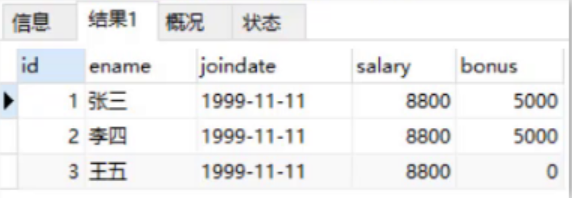
Note: the default constraint will only adopt the default value if no value is given. If NULL is given, the value is null.
As follows:
INSERT INTO emp(id,ename,joindate,salary,bonus) values(4,'Zhao Liu','1999-11-11',8800,null);
After executing the above statement, query the data in the table, as shown in the figure below. You can see that the value of the bonus column of Zhao Liu's data is null.
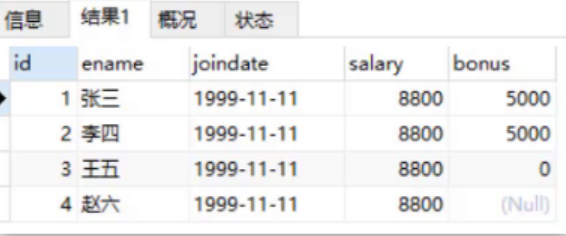
- Verify automatic growth: auto_increment when the column is numeric and uniquely constrained
Recreate the emp table and add automatic growth to the id column
-- Employee table CREATE TABLE emp ( id INT PRIMARY KEY auto_increment, -- staff id,Primary key and self growth ename VARCHAR(50) NOT NULL UNIQUE, -- Employee name, non empty and unique joindate DATE NOT NULL , -- Entry date; not blank salary DOUBLE(7,2) NOT NULL , -- Salary, non empty bonus DOUBLE(7,2) DEFAULT 0 -- Bonus. If there is no bonus, it defaults to 0 );
Next, add data to emp to verify whether the value of id column will increase automatically if no value is added to id column and null value is added to id column:
INSERT INTO emp(ename,joindate,salary,bonus) values('Zhao Liu','1999-11-11',8800,null);
INSERT INTO emp(id,ename,joindate,salary,bonus) values(null,'Zhao Liu2','1999-11-11',8800,null);
INSERT INTO emp(id,ename,joindate,salary,bonus) values(null,'Zhao liu3','1999-11-11',8800,null);
1.8 foreign key constraints
1.8.1 general
Foreign keys are used to establish links between the data of two tables to ensure the consistency and integrity of the data.
How to understand the above concept? As shown in the figure below, there are two tables, employee table and department table:
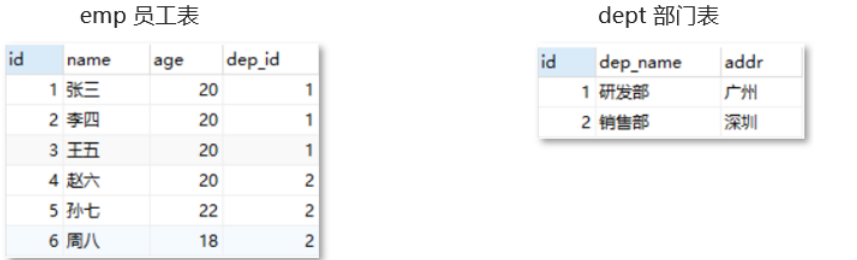
DEP in employee table_ The id field is associated with the id field of the Department table, that is, student No. 1 Zhang San belongs to the employee of the R & D Department of department No. 1. Now I want to delete Department 1, and there will be wrong data (the data belonging to department 1 in the employee table). The relationship between the two tables mentioned above is only that we think they are related. At this time, we need to use foreign keys to make the two tables generate database level relationship. In this way, the data of department 1 in the Department table you want to delete cannot be deleted.
1.8.2 grammar
- Add foreign key constraint
-- Add foreign key constraints when creating tables CREATE TABLE Table name( Column name data type, ... [CONSTRAINT] [Foreign key name] FOREIGN KEY(Foreign key column name) REFERENCES Main table(Main table column name) );
-- Add foreign key constraints after creating the table ALTER TABLE Table name ADD CONSTRAINT Foreign key name FOREIGN KEY (Foreign key field name) REFERENCES Main table name(Main table column name);
- Delete foreign key constraint
ALTER TABLE Table name DROP FOREIGN KEY Foreign key name;
1.8.3 practice
Create employee table and department table according to the above syntax, and add foreign key constraints:
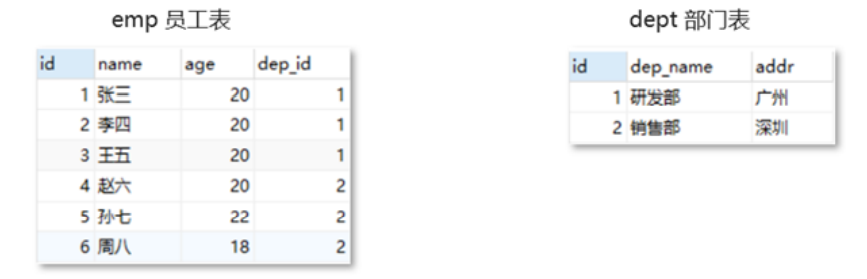
-- Delete table DROP TABLE IF EXISTS emp; DROP TABLE IF EXISTS dept; -- Department table CREATE TABLE dept( id int primary key auto_increment, dep_name varchar(20), addr varchar(20) ); -- Employee table CREATE TABLE emp( id int primary key auto_increment, name varchar(20), age int, dep_id int, -- Add foreign key dep_id,relation dept Tabular id Primary key CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES dept(id) );
Add data
-- Add 2 departments
insert into dept(dep_name,addr) values
('R & D department','Guangzhou'),('Sales Department', 'Shenzhen');
-- Add employee,dep_id Indicates the Department of the employee
INSERT INTO emp (NAME, age, dep_id) VALUES
('Zhang San', 20, 1),
('Li Si', 20, 1),
('Wang Wu', 20, 1),
('Zhao Liu', 20, 2),
('Sun Qi', 22, 2),
('Zhou Ba', 18, 2);
If you delete the data of the R & D department, you will find that it cannot be deleted.
Delete foreign key
alter table emp drop FOREIGN key fk_emp_dept;
Add foreign keys again
alter table emp add CONSTRAINT fk_emp_dept FOREIGN key(dep_id) REFERENCES dept(id);
2. Database design
2.1 introduction to database design
- Software development steps
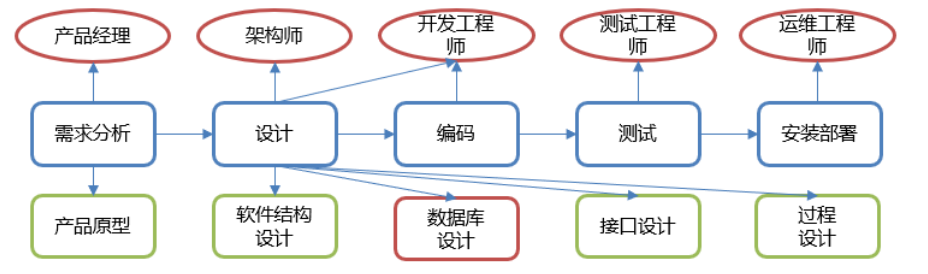
-
Database design concept
- Database design is to construct the optimal data storage model for the business system according to the specific requirements of the business system and the DBMS we choose.
- The process of establishing the table structure in the database and the association relationship between tables.
- What are the tables? What are the fields in the table? What is the relationship between tables?
-
Steps of database design
-
Demand analysis (what is the data? What attributes does the data have? What are the characteristics of data and attributes)
-
Logical analysis (logical modeling of the database through ER diagram, without considering the database management system we choose)
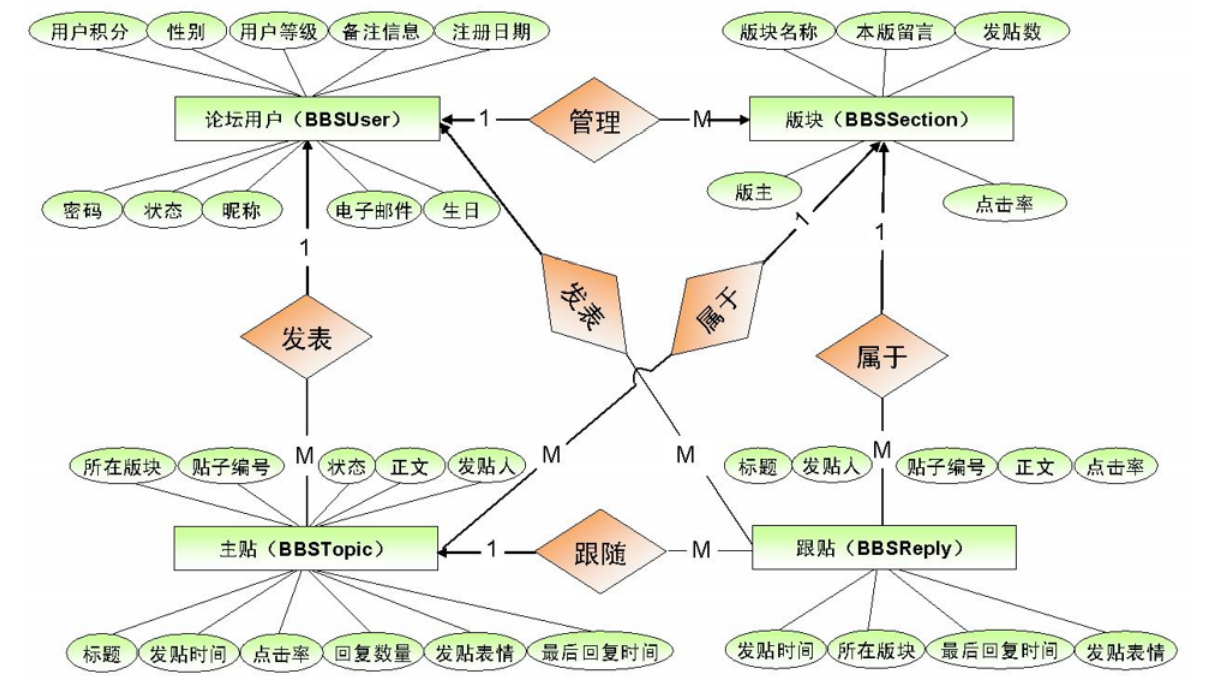
The following figure is the ER (entity / relationship) diagram:
-
Physical design (convert logical design into physical design according to the characteristics of the database)
-
Maintenance design (1. Create tables for new requirements; 2. Optimize tables)
-
-
Table relation
-
one-on-one
- E.g. user and user details
- The one-to-one relationship is mostly used for table splitting. The frequently used fields in an entity are placed in one table and the infrequently used fields are placed in another table to improve query performance
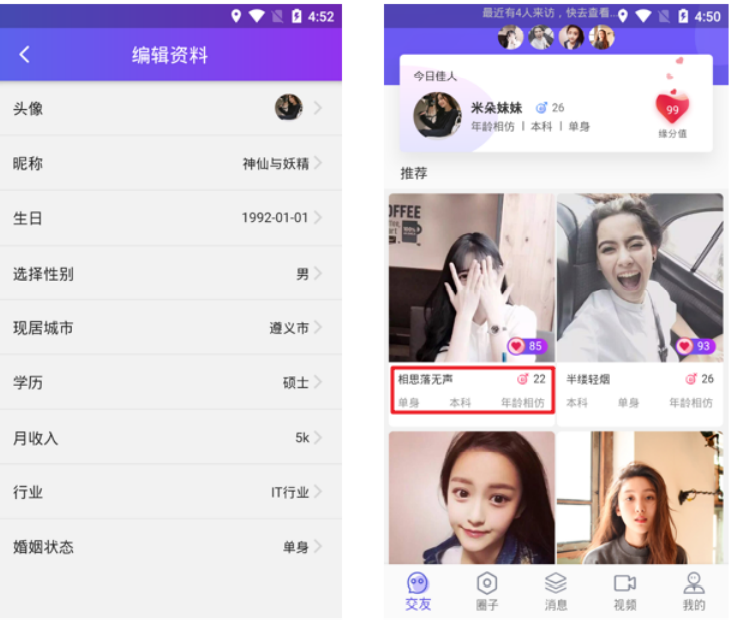
The left side of the figure above is the user's details, and the longest time we use to display the user's information is shown in the red box on the right side of the figure above, so we will check the details into two tables.
-
One to many
-
For example: departments and employees
-
One department corresponds to multiple employees, and one employee corresponds to one department. As shown below:
-
-
Many to many
-
E.g. goods and orders
-
One item corresponds to multiple orders, and one order contains multiple items. As shown below:
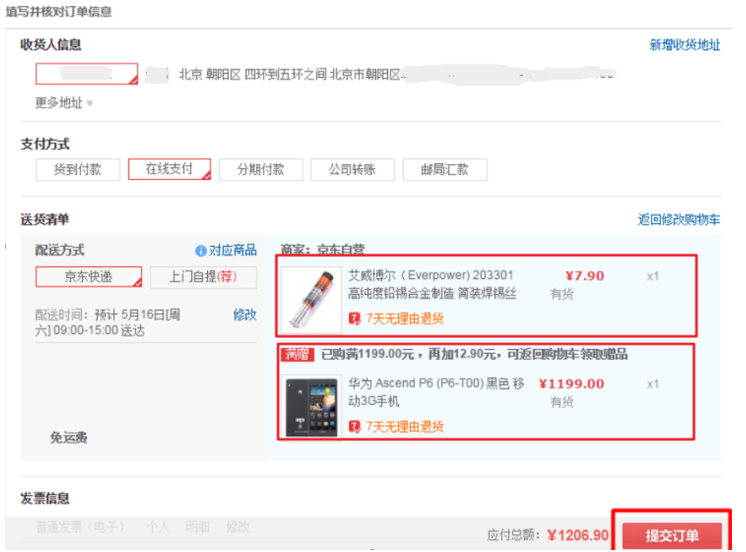
-
-
2.2 table relationship (one to many)
-
One to many
- For example: departments and employees
- One department corresponds to multiple employees, and one employee corresponds to one department.
-
Implementation mode
Establish a foreign key on the side with more than one, and point to the primary key of the side with one
-
case
Let's take employee table and department table as examples:

After analysis, it is found that the employee table belongs to more than one party and the Department table belongs to one party. At this time, we will add a column (dep_id) in the employee table, pointing to the primary key (ID) of the Department table:
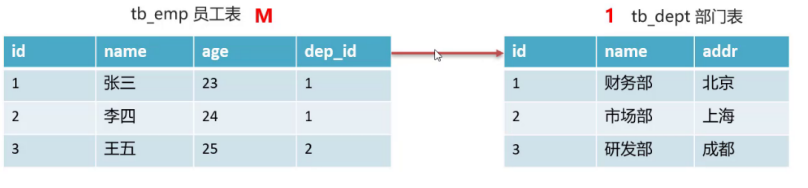
The table creation statement is as follows:
-- Delete table DROP TABLE IF EXISTS tb_emp; DROP TABLE IF EXISTS tb_dept; -- Department table CREATE TABLE tb_dept( id int primary key auto_increment, dep_name varchar(20), addr varchar(20) ); -- Employee table CREATE TABLE tb_emp( id int primary key auto_increment, name varchar(20), age int, dep_id int, -- Add foreign key dep_id,relation dept Tabular id Primary key CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES tb_dept(id) );
View table structure model diagram:
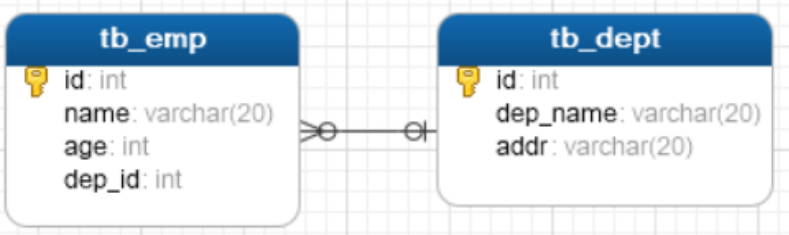
2.3 table relationship (many to many)
-
Many to many
- E.g. goods and orders
- One item corresponds to multiple orders, and one order contains multiple items
-
Implementation mode
Create the third intermediate table. The intermediate table contains at least two foreign keys, which are associated with the primary keys of the two parties
-
case
We take the order form and commodity form as examples:

After analysis, it is found that both the order table and the commodity table belong to more than one party. At this time, it is necessary to create an intermediate table in which the foreign key of the order table and the foreign key of the commodity table point to the primary keys of the two tables:
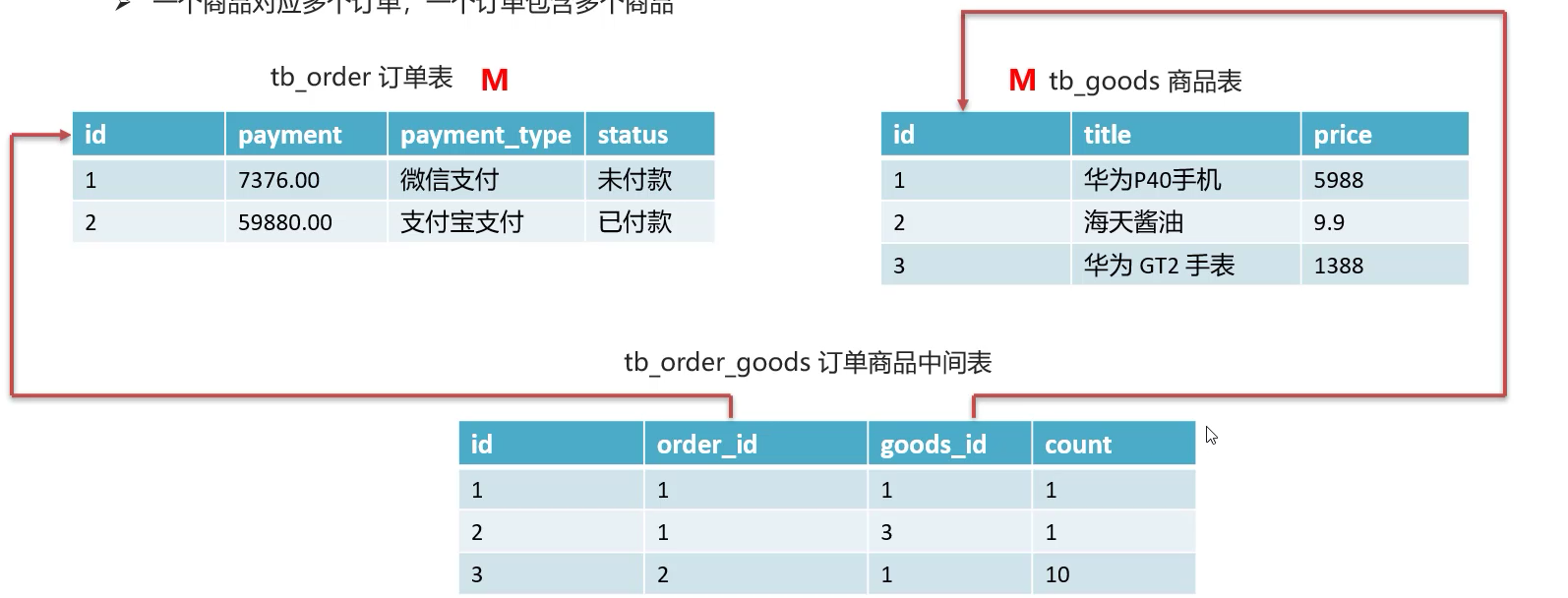
The table creation statement is as follows:
-- Delete table DROP TABLE IF EXISTS tb_order_goods; DROP TABLE IF EXISTS tb_order; DROP TABLE IF EXISTS tb_goods; -- Order form CREATE TABLE tb_order( id int primary key auto_increment, payment double(10,2), payment_type TINYINT, status TINYINT ); -- Commodity list CREATE TABLE tb_goods( id int primary key auto_increment, title varchar(100), price double(10,2) ); -- Order goods intermediate table CREATE TABLE tb_order_goods( id int primary key auto_increment, order_id int, goods_id int, count int ); -- After creating the table, add foreign keys alter table tb_order_goods add CONSTRAINT fk_order_id FOREIGN key(order_id) REFERENCES tb_order(id); alter table tb_order_goods add CONSTRAINT fk_goods_id FOREIGN key(goods_id) REFERENCES tb_goods(id);
View table structure model diagram:
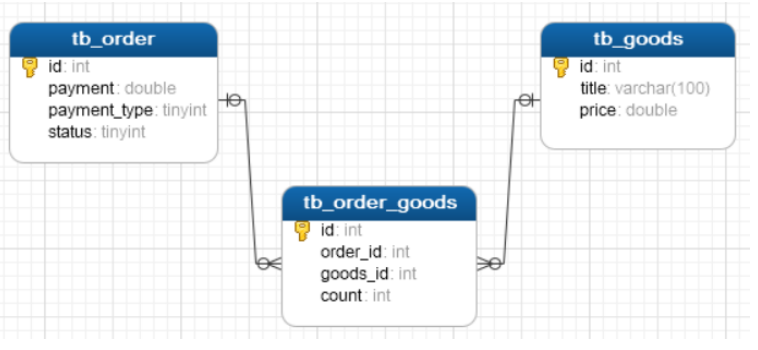
2.4 table relationship (one-to-one)
-
one-on-one
- E.g. user and user details
- The one-to-one relationship is mostly used for table splitting. The frequently used fields in an entity are placed in one table and the infrequently used fields are placed in another table to improve query performance
-
Implementation mode
Add a foreign key to either party, associate the primary key of the other party, and set the foreign key to be unique
-
case
We take the user table as an example:
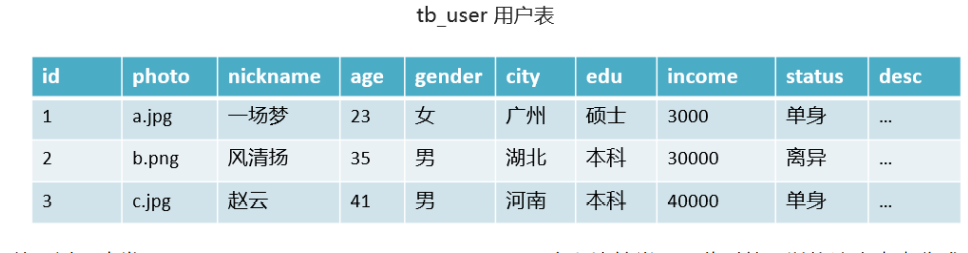
In the actual use process, it is found that the fields id, photo, nickname, age and gender are commonly used. At this time, this table can be divided into two tables.
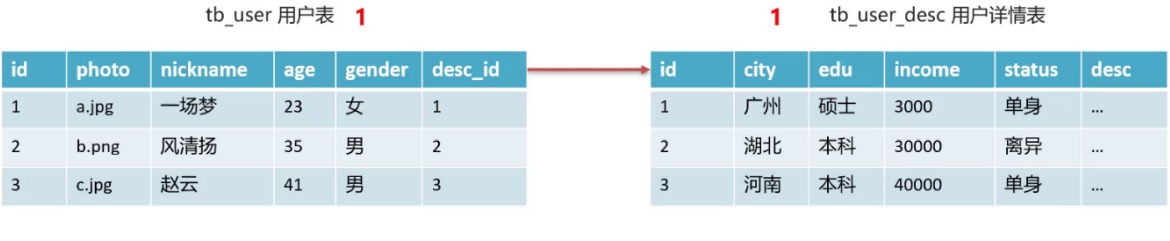
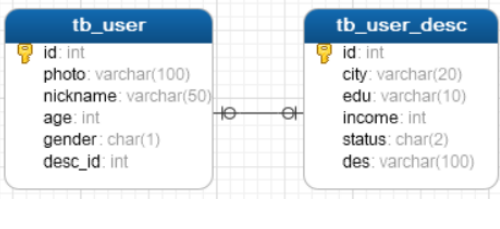
The table creation statement is as follows:
create table tb_user_desc ( id int primary key auto_increment, city varchar(20), edu varchar(10), income int, status char(2), des varchar(100) ); create table tb_user ( id int primary key auto_increment, photo varchar(100), nickname varchar(50), age int, gender char(1), desc_id int unique, -- Add foreign key CONSTRAINT fk_user_desc FOREIGN KEY(desc_id) REFERENCES tb_user_desc(id) );
View table structure model diagram:
2.5 database design cases
Design the table and the relationship between tables according to the following figure:

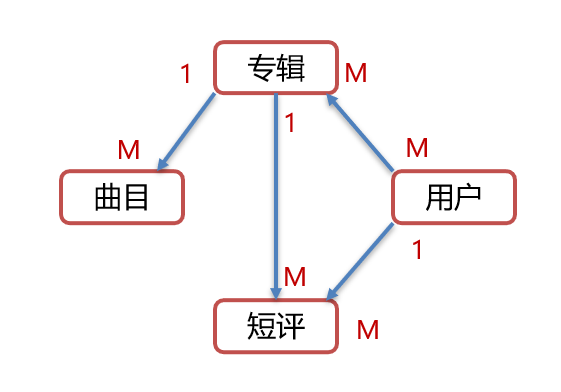
After analysis, we are divided into four tables: album table, track table, short comment table, user table.
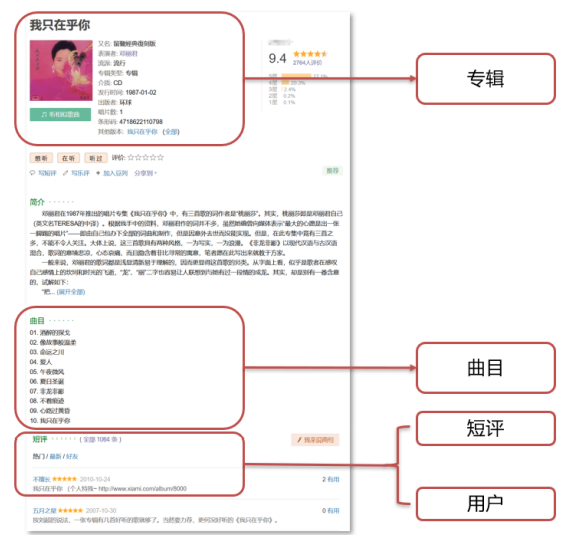
An album can have multiple tracks, and a track can only belong to one album, so the relationship between album list and track list is one to many.
An album can be commented by multiple users, and one user can comment on multiple albums, so the relationship between album table and user table is many to many.
A user can send multiple short comments. A short comment can only be sent by one person, so the relationship between user table and short comment table is one to many.
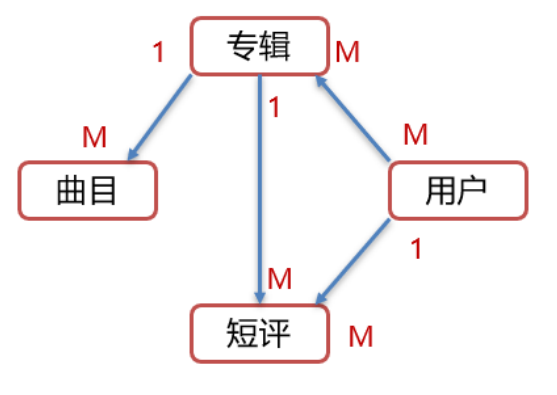
Each table is designed as follows:
A piece of music
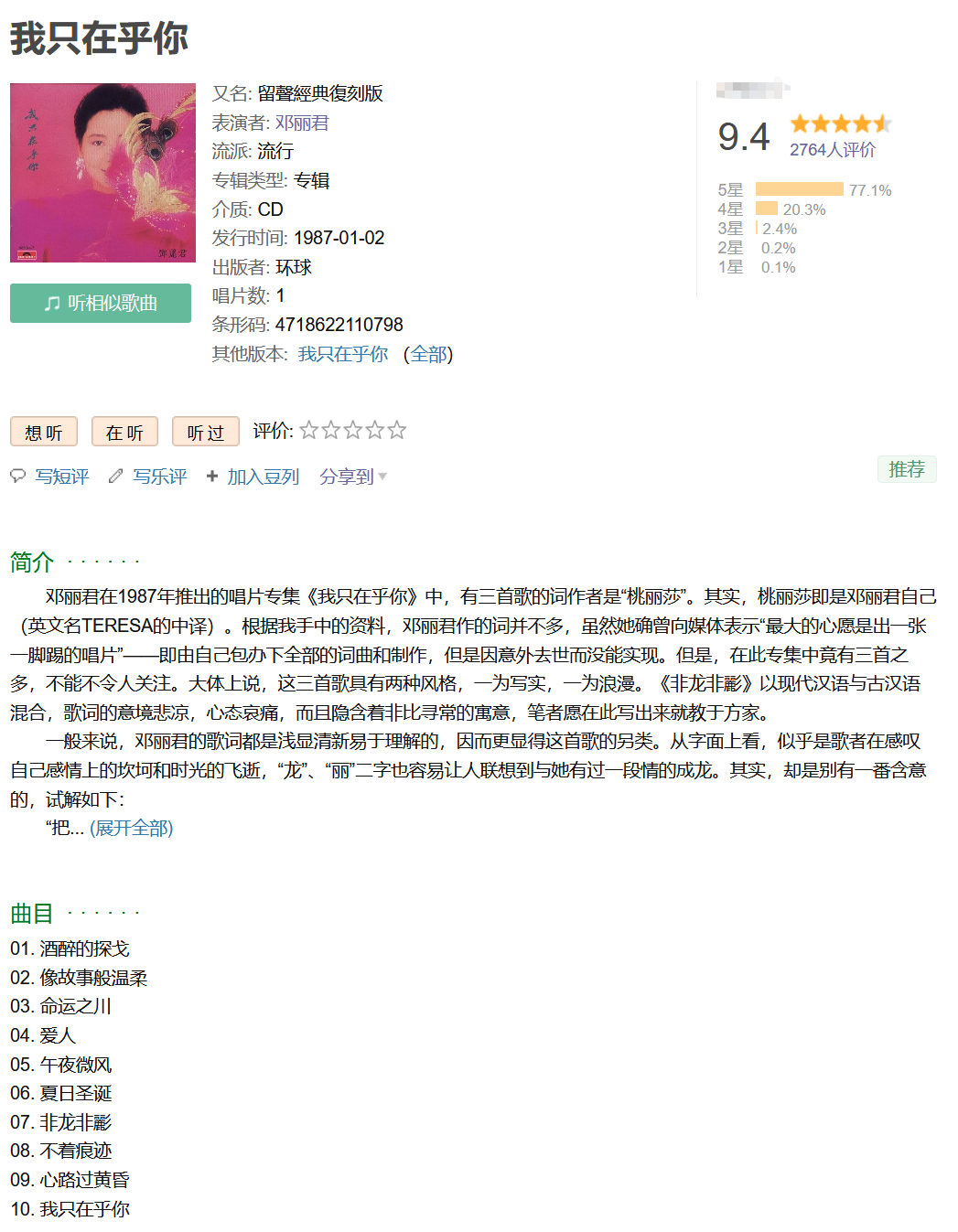
analysis
Music album table name: Music
| Field name | data type | explain |
|---|---|---|
| title | varchar(32) | Album name |
| alias | varchar(32) | Album alias |
| image | varchar(64) | cover photo |
| style | varchar(8) | Genres (such as classics, pop, ballads, electronics, etc.) |
| type | varchar(4) | Type (album, single, etc.) |
| medium | varchar(4) | Media (CD, black glue, digital, etc.) |
| publish_time | date | Release time |
| publisher | varchar(16) | publisher |
| number | tinyint | Number of records |
| barcode | bigint | bar code |
| summary | varchar(1024) | brief introduction |
| artist | varchar(16) | artist |
| id | int | Number (unique) |
Track list name: Song
| Field name | data type | explain |
|---|---|---|
| name | varchar(32) | Song name |
| serial_number | tinyint | Song serial number |
| id | int | Number (unique) |
Comment table name: Review
| Field name | data type | explain |
|---|---|---|
| content | varchar(256) | Comment content |
| rating | tinyint | Score (1 ~ 5) |
| review_time | datetime | Comment time |
User table name: user
| Field name | data type | explain |
|---|---|---|
| username | varchar(16) | User name (unique) |
| image | varchar(64) | User avatar picture address |
| signature | varchar(64) | Personal signature, e.g. (everything is perfect) |
| nickname | varchar(16) | User nickname |
| id | int | User number (primary key) |
Table relationship:
3. Multi table query
As the name suggests, multi table query is to query the data we want from multiple tables at one time. We will demonstrate to them through specific sql and prepare the environment first
DROP TABLE IF EXISTS emp;
DROP TABLE IF EXISTS dept;
# Create department table
CREATE TABLE dept(
did INT PRIMARY KEY AUTO_INCREMENT,
dname VARCHAR(20)
);
# Create employee table
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- Gender
salary DOUBLE, -- wages
join_date DATE, -- Entry date
dep_id INT,
FOREIGN KEY (dep_id) REFERENCES dept(did) -- Foreign key, related department table(Primary key of department table)
);
-- Add Department data
INSERT INTO dept (dNAME) VALUES ('R & D department'),('Marketing Department'),('Finance Department'),('Sales Department');
-- Add employee data
INSERT INTO emp(NAME,gender,salary,join_date,dep_id) VALUES
('Sun WuKong','male',7200,'2013-02-24',1),
('Zhu Bajie','male',3600,'2010-12-02',2),
('Tang Monk','male',9000,'2008-08-08',2),
('Baigujing','female',5000,'2015-10-07',3),
('spider goblin','female',4500,'2011-03-14',1),
('Little white dragon','male',2500,'2011-02-14',null);
Execute the following multi table query statement
select * from emp , dept; -- from emp and dept Query all field data in the table
The results are as follows:
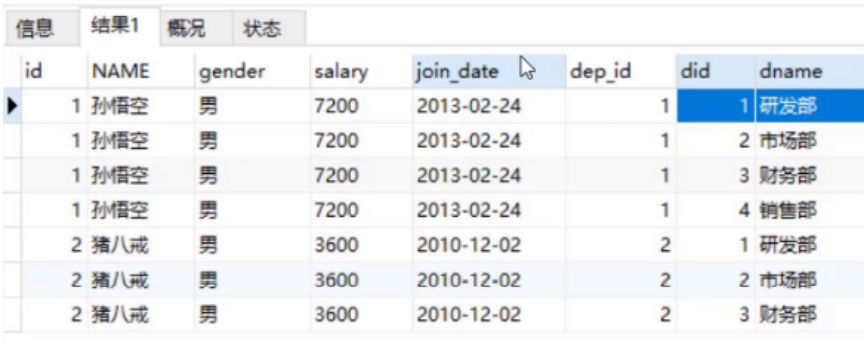
From the above results, we can see that there are some invalid data. For example, the monkey king belongs to department 1, but it is also associated with departments 2, 3 and 4. So we need to limit the DEP in the employee table_ The value of ID field is equal to the value of did field in department table to eliminate these invalid data,
select * from emp , dept where emp.dep_id = dept.did;
The results after implementation are as follows:
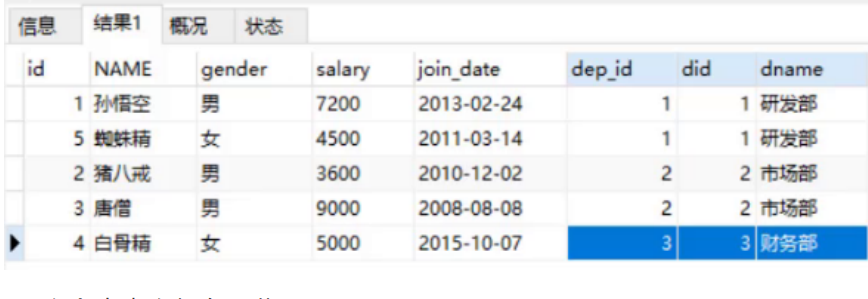
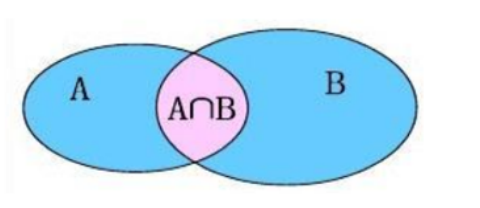
The above statement is a join query. What are the multiple table queries?
-
join query
- Inner join query: equivalent to querying AB intersection data
- External connection query
- Left outer connection query: it is equivalent to querying all data in table A and intersecting Department data
- Right outer connection query: it is equivalent to querying all data and intersection data in table B
-
Subquery
3.1 internal connection query
- grammar
-- Implicit inner connection SELECT Field list FROM Table 1,Table 2 WHERE condition; -- Show internal connections SELECT Field list FROM Table 1 [INNER] JOIN Table 2 ON condition;
Inner connection is equivalent to querying the intersection data of a and B
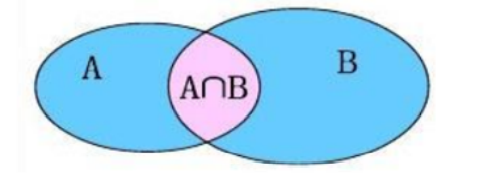
-
case
-
Implicit inner connection
SELECT * FROM emp, dept WHERE emp.dep_id = dept.did;
The result of executing the above statement is as follows:
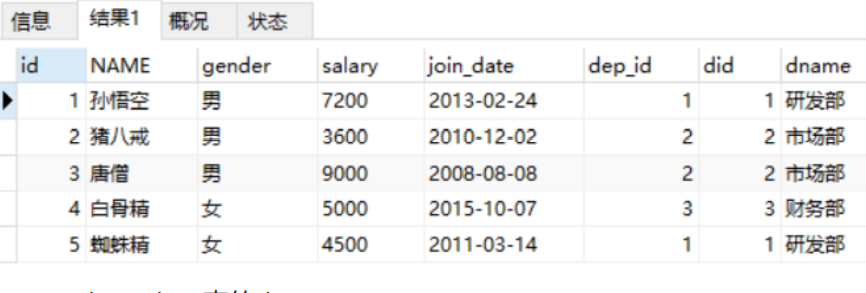
-
Query the name, gender and dname of emp table
SELECT emp. NAME, emp.gender, dept.dname FROM emp, dept WHERE emp.dep_id = dept.did;
The result of executing the statement is as follows:
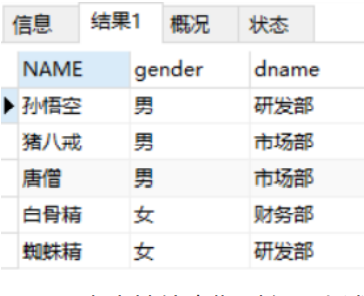
It is a bit troublesome to use the table name to specify the field in the above statement. sql also supports assigning aliases to tables. The above statement can be improved to
SELECT t1. NAME, t1.gender, t2.dname FROM emp t1, dept t2 WHERE t1.dep_id = t2.did;
-
Explicit inner join
select * from emp inner join dept on emp.dep_id = dept.did; -- In the above statement inner It can be omitted and written as the following statements select * from emp join dept on emp.dep_id = dept.did;
The results are as follows:
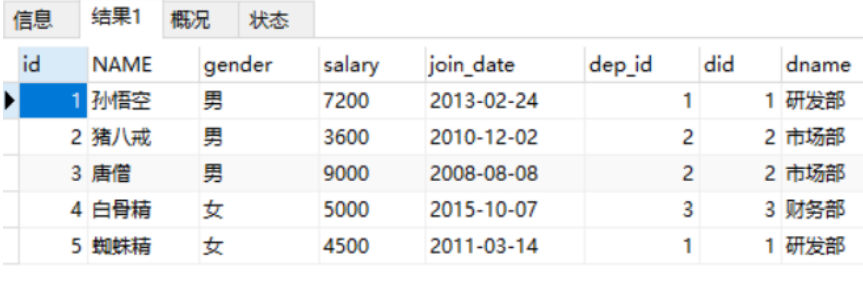
-
3.2 external connection query
-
grammar
-- Left outer connection SELECT Field list FROM Table 1 LEFT [OUTER] JOIN Table 2 ON condition; -- Right outer connection SELECT Field list FROM Table 1 RIGHT [OUTER] JOIN Table 2 ON condition;
Left outer connection: it is equivalent to querying all data and intersection data in table A
Right outer connection: it is equivalent to querying all data and intersection data in table B
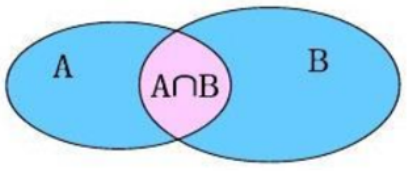
-
case
-
Query all data of emp table and corresponding department information (left outer connection)
select * from emp left join dept on emp.dep_id = dept.did;
The result of executing the statement is as follows:
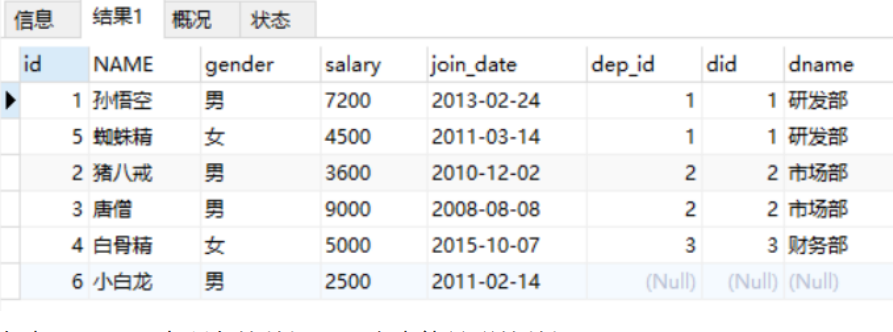
The results show that all the data in the left table (emp) and the data that can be associated with the two tables are queried.
-
Query all data of dept table and corresponding employee information (right outer connection)
select * from emp right join dept on emp.dep_id = dept.did;
The result of executing the statement is as follows:
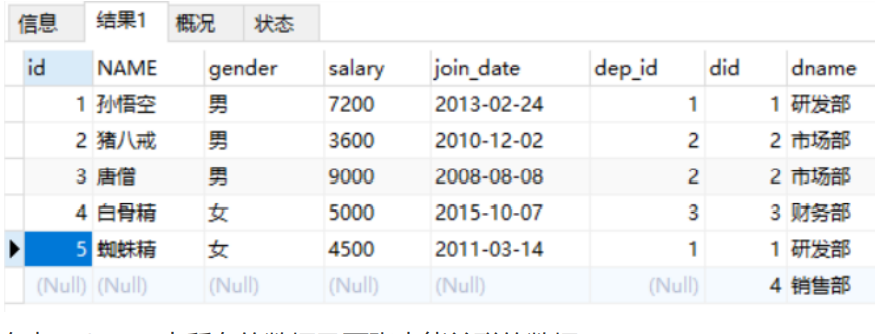
The results show that all the data in the right table (dept) and the data that can be associated with the two tables are queried.
To query all the data in the Department table, you can also use the left outer connection. You only need to exchange the positions of the two tables:
select * from dept left join emp on emp.dep_id = dept.did;
-
3.3 sub query
-
concept
Nested queries in queries are called sub queries.
What is nested query in query? Let's take an example:
Demand: query the information of employees whose salary is higher than Zhu Bajie.
To realize this demand, we can realize it in two steps. The first step is to query the salary of Zhu Bajie
select salary from emp where name = 'Zhu Bajie'
Step 2: query the employee information whose salary is higher than Zhu Bajie
select * from emp where salary > 3600;
The 3600 in the second step can be found through the sql query in the first step, so the 3600 is replaced with the sql statement in the first step
select * from emp where salary > (select salary from emp where name = 'Zhu Bajie');
This is the nested query statement in the query statement.
-
Sub queries have different functions according to different query results
- The result of sub query statement is single row and single column. The sub query statement is used as the condition value, using =! = >< And so on
- The result of sub query statement is multiple rows and single column. The sub query statement is used as the condition value, and the keywords such as in are used for condition judgment
- The result of subquery statement is multiple rows and columns, and the subquery statement is used as a virtual table
-
case
-
Query all employee information of 'finance department' and 'marketing department'
-- query 'Finance Department' perhaps 'Marketing Department' Department of all employees did select did from dept where dname = 'Finance Department' or dname = 'Marketing Department'; select * from emp where dep_id in (select did from dept where dname = 'Finance Department' or dname = 'Marketing Department');
-
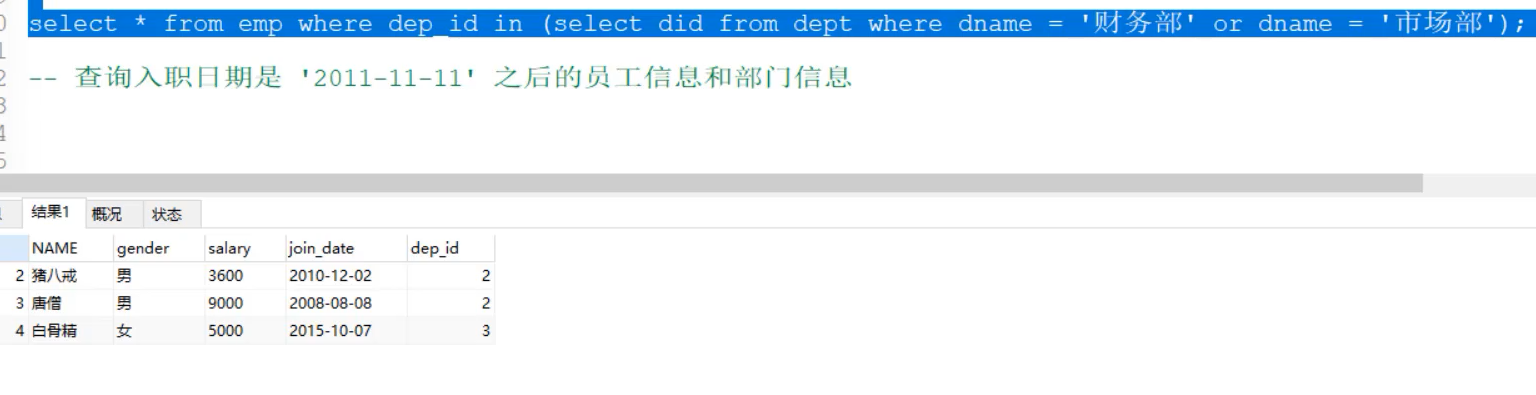
- Query employee information and department information whose employment date is after November 11, 2011
-- Query entry date is '2011-11-11' Employee information after select * from emp where join_date > '2011-11-11' ; -- Take the result of the above statement as a virtual table and dept Intra table join query select * from (select * from emp where join_date > '2011-11-11' ) t1, dept where t1.dep_id = dept.did;

3.4 cases
- Environmental preparation:
DROP TABLE IF EXISTS emp; DROP TABLE IF EXISTS dept; DROP TABLE IF EXISTS job; DROP TABLE IF EXISTS salarygrade; -- Department table CREATE TABLE dept ( did INT PRIMARY KEY PRIMARY KEY, -- department id dname VARCHAR(50), -- Department name loc VARCHAR(50) -- Location of Department ); -- Job table, job name, job description CREATE TABLE job ( id INT PRIMARY KEY, jname VARCHAR(20), description VARCHAR(50) ); -- Employee table CREATE TABLE emp ( id INT PRIMARY KEY, -- staff id ename VARCHAR(50), -- Employee name job_id INT, -- post id mgr INT , -- Superior leaders joindate DATE, -- Entry date salary DECIMAL(7,2), -- wages bonus DECIMAL(7,2), -- bonus dept_id INT, -- Department number CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id), CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id) ); -- Wage scale CREATE TABLE salarygrade ( grade INT PRIMARY KEY, -- level losalary INT, -- minimum wage hisalary INT -- Maximum wage ); -- Add 4 departments INSERT INTO dept(did,dname,loc) VALUES (10,'Teaching and Research Department','Beijing'), (20,'School Work Department','Shanghai'), (30,'Sales Department','Guangzhou'), (40,'Finance Department','Shenzhen'); -- Add 4 jobs INSERT INTO job (id, jname, description) VALUES (1, 'chairman', 'Manage the whole company and receive orders'), (2, 'manager', 'Management staff'), (3, 'salesperson', 'Promote products to customers'), (4, 'Clerk', 'Using office software'); -- Add employee INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES (1001,'Sun WuKong',4,1004,'2000-12-17','8000.00',NULL,20), (1002,'Lu Junyi',3,1006,'2001-02-20','16000.00','3000.00',30), (1003,'Lin Chong',3,1006,'2001-02-22','12500.00','5000.00',30), (1004,'Tang Monk',2,1009,'2001-04-02','29750.00',NULL,20), (1005,'Li Kui',4,1006,'2001-09-28','12500.00','14000.00',30), (1006,'Song Jiang',2,1009,'2001-05-01','28500.00',NULL,30), (1007,'Liu Bei',2,1009,'2001-09-01','24500.00',NULL,10), (1008,'Zhu Bajie',4,1004,'2007-04-19','30000.00',NULL,20), (1009,'Luo Guanzhong',1,NULL,'2001-11-17','50000.00',NULL,10), (1010,'Wu Yong',3,1006,'2001-09-08','15000.00','0.00',30), (1011,'Monk Sha',4,1004,'2007-05-23','11000.00',NULL,20), (1012,'Li Kui',4,1006,'2001-12-03','9500.00',NULL,30), (1013,'Little white dragon',4,1004,'2001-12-03','30000.00',NULL,20), (1014,'Guan Yu',4,1007,'2002-01-23','13000.00',NULL,10); -- Add 5 salary levels INSERT INTO salarygrade(grade,losalary,hisalary) VALUES (1,7000,12000), (2,12010,14000), (3,14010,20000), (4,20010,30000), (5,30010,99990);
Table structure: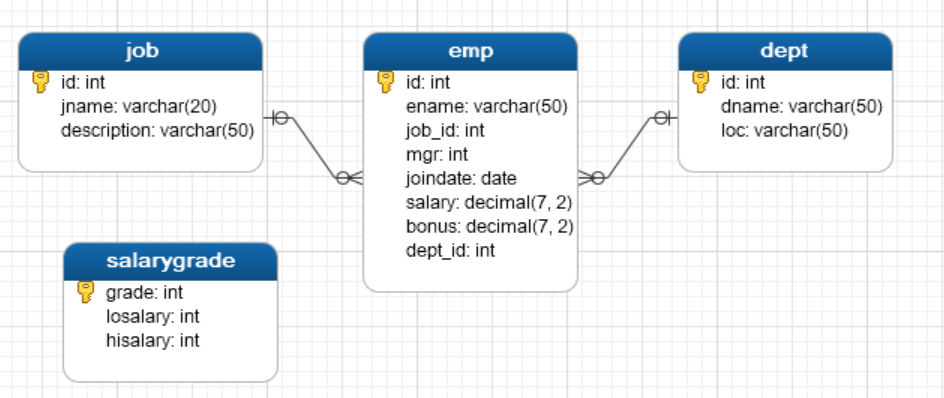
-
demand
-
Query all employee information. Query employee number, employee name, salary, job name and job description
/* analysis: 1. Employee number, employee name and salary information are in the emp employee table 2. The job name and job description information are in the job job table 3. job Job table and emp employee table are one to many relationships job_ id = job. id */ -- Method 1: implicit inner connection SELECT emp.id, emp.ename, emp.salary, job.jname, job.description FROM emp, job WHERE emp.job_id = job.id; -- Mode 2: explicit inner connection SELECT emp.id, emp.ename, emp.salary, job.jname, job.description FROM emp INNER JOIN job ON emp.job_id = job.id;
-
Query employee number, employee name, salary, job name, job description, department name and department location
/* analysis: 1. Employee number, employee name and salary information are in the emp employee table 2. The job name and job description information are in the job job table 3. job Job table and emp employee table are one to many relationships job_ id = job. id 4. Department name and department location are from department table dept 5. dept One to many relationship with emp dept.id = emp dept_ id */ -- Method 1: implicit inner connection SELECT emp.id, emp.ename, emp.salary, job.jname, job.description, dept.dname, dept.loc FROM emp, job, dept WHERE emp.job_id = job.id and dept.id = emp.dept_id ; -- Mode 2: explicit inner connection SELECT emp.id, emp.ename, emp.salary, job.jname, job.description, dept.dname, dept.loc FROM emp INNER JOIN job ON emp.job_id = job.id INNER JOIN dept ON dept.id = emp.dept_id
-
Query employee name, salary and salary grade
/* analysis: 1. The employee's name and salary information are in the emp employee table 2. Salary grade information is in salary grade table 3. emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary */ SELECT emp.ename, emp.salary, t2.* FROM emp, salarygrade t2 WHERE emp.salary >= t2.losalary AND emp.salary <= t2.hisalary
-
Query employee name, salary, job name, job description, department name, Department location and salary grade
/* analysis: 1. Employee number, employee name and salary information are in the emp employee table 2. The job name and job description information are in the job job table 3. job Job table and emp employee table are one to many relationships job_ id = job. id 4. Department name and department location are from department table dept 5. dept One to many relationship with emp dept.id = emp dept_ id 6. Salary grade information is in salary grade table 7. emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary */ SELECT emp.id, emp.ename, emp.salary, job.jname, job.description, dept.dname, dept.loc, t2.grade FROM emp INNER JOIN job ON emp.job_id = job.id INNER JOIN dept ON dept.id = emp.dept_id INNER JOIN salarygrade t2 ON emp.salary BETWEEN t2.losalary and t2.hisalary;
-
Find out the department number, department name, Department location and department number
/* analysis: 1. The department number, department name and department location are from the Department dept table 2. Number of people in department: in the emp table, it is calculated by dept_id is grouped, and then count(*) counts the quantity 3. Use the subquery to connect the Department table and the grouped table */ -- According to Department id Query each department in groups id And number of employees select dept_id, count(*) from emp group by dept_id; SELECT dept.id, dept.dname, dept.loc, t1.count FROM dept, ( SELECT dept_id, count(*) count FROM emp GROUP BY dept_id ) t1 WHERE dept.id = t1.dept_id
-
4. Transaction
4.1 General
Database Transaction is a mechanism and a sequence of operations, which contains a set of database operation commands.
The transaction submits or cancels the operation request to the system as a whole, that is, this group of database commands either succeed or fail at the same time.
Transaction is an inseparable logical unit of work.
These concepts are difficult to understand. Next, for example, as shown in the following figure, there is a table
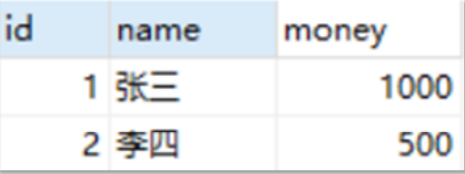
Zhang San and Li Si each have 100 yuan in their accounts. Now Li Si needs to convert 500 yuan to Zhang San. The specific transfer operation is
- Step 1: query the balance of Li Si account
- Step 2: from Li Si's account amount - 500
- Step 3: give Zhang San's account amount + 500
Now suppose that there is an exception after the completion of the second step in the transfer process, and the third step is not executed, which will result in the amount of Li Si's account being less than 500, while Zhang San's amount is not more than 500; Such a system is problematic. What if it's solved? Using transactions can solve the above problems
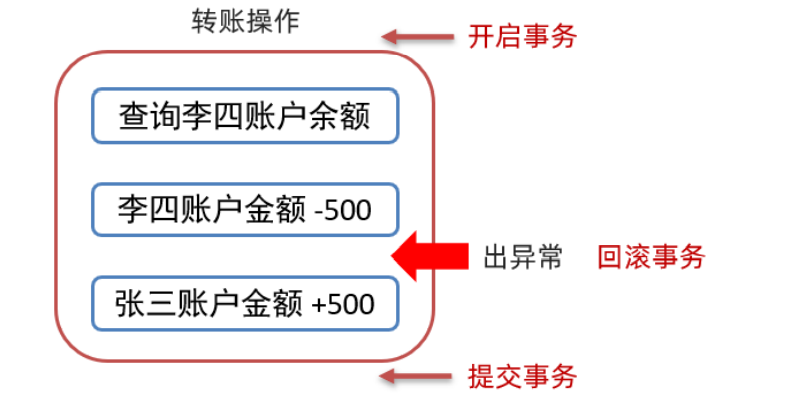
It can be seen from the above figure that the transaction is started before the transfer. If there is an abnormal rollback transaction, the transaction is committed after three steps of normal execution, which can perfectly solve the problem.
4.2 grammar
-
Open transaction
START TRANSACTION; perhaps BEGIN;
-
Commit transaction
commit;
-
Rollback transaction
rollback;
4.3 code verification
-
Environmental preparation
DROP TABLE IF EXISTS account; -- Create account table CREATE TABLE account( id int PRIMARY KEY auto_increment, name varchar(10), money double(10,2) ); -- Add data INSERT INTO account(name,money) values('Zhang San',1000),('Li Si',1000); -
No transaction demonstration problem
-- Transfer operation -- 1. Query whether the account amount of Li Si is greater than 500 -- 2. Li Si account -500 UPDATE account set money = money - 500 where name = 'Li Si'; Something's wrong... -- This is not a comment. There will be problems during the overall implementation. The following sql Do not execute -- 3. Zhang San account +500 UPDATE account set money = money + 500 where name = 'Zhang San';
There will certainly be problems in the overall implementation results. We query the data in the account table and find that Li Si's account is 500 less.
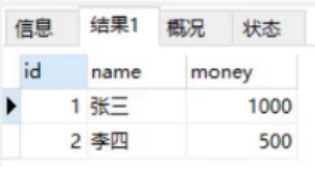
-
Add transaction sql as follows:
-- Open transaction BEGIN; -- Transfer operation -- 1. Query whether the account amount of Li Si is greater than 500 -- 2. Li Si account -500 UPDATE account set money = money - 500 where name = 'Li Si'; Something's wrong... -- This is not a comment. There will be problems during the overall implementation. The following sql Do not execute -- 3. Zhang San account +500 UPDATE account set money = money + 500 where name = 'Zhang San'; -- Commit transaction COMMIT; -- Rollback transaction ROLLBACK;
If the execution in the above sql is successful, select to execute the commit transaction, and if there is a problem, execute the statement of rolling back the transaction. It is definitely impossible for us to operate in this way in the future. Instead, we operate in java, where we can grab exceptions, commit transactions without exceptions, and roll back transactions with exceptions.
4.4 four characteristics of transaction
-
Atomicity: a transaction is the smallest and indivisible unit of operation. It either succeeds or fails at the same time
-
Consistency: when a transaction is completed, all data must be kept in a consistent state
-
Isolation: visibility of operations between multiple transactions
-
Durability: once a transaction is committed or rolled back, its changes to the data in the database are permanent
explain:
Transactions in mysql are automatically committed.
In other words, we do not add transactions to execute sql statements. After the statement is executed, the transaction will be submitted automatically.
You can query the default submission method through the following statement:
SELECT @@autocommit;
If the query result is 1, it means automatic submission, and if the result is 0, it means manual submission. Of course, you can also modify the submission method through the following statement
set @@autocommit = 0;
Thank you for seeing here. Welcome to leave a message and comment!