preface
When building a mysql Cluster, a single master makes master-slave replication, which greatly improves the reading and writing ability of the database, but once a single point of failure occurs, the whole cluster will be paralyzed. Therefore, we usually configure the master to improve the redundancy ability of the cluster.
1, What is MHA
- MHA (MasterHigh Availability) is a set of excellent software for failover and master-slave replication in MySQL high availability environment.
- The emergence of MHA is to solve the problem of MySQL single point.
- During MySQL failover, MHA can automatically complete the failover operation within 0-30 seconds.
- MHA can ensure the consistency of data to the greatest extent in the process of failover, so as to achieve high availability in the real sense.
2, Composition of MHA
-
MHA Node
The MHA Node runs on each MySQL server. -
MHA Manager (management node)
MHA Manager can be deployed on an independent machine to manage multiple master slave clusters; It can also be deployed on a slave node. -
The MHA Manager will periodically probe the master node in the cluster. When the master fails, it can automatically promote the slave of the latest data to the new master, and then point all other slave to the new master again. The entire failover process is completely transparent to the application.
3, Characteristics of MHA
- During automatic failover, MHA tries to save binary logs from the down primary server to ensure that data is not lost to the greatest extent
- Using semi synchronous replication can greatly reduce the risk of data loss. If only one slave has received the latest binary log, MHA can apply the latest binary log to all other slave servers, so it can ensure the data consistency of all nodes
- At present, MHA supports a master-slave architecture with at least three services, that is, one master and two slaves
MHA is to solve failover, save data as much as possible, and achieve the consistency of all node logs
4, Build MHA
1. Ideas
-
MHA architecture
1) Database installation
2) One master and two slaves
3) MHA construction -
fault simulation
1) Main library failure
2) The alternative master library becomes the master library
3) The original fault master database recovers and rejoins the MHA as a slave database
2. Environment
- MHA manager node server:
CentOS7.6(64 bit) manager/192.168.3.14, installing MHA node and manager components - Master node server: CentOS7.6(64 bit) MySQL 1 / 192.168.3.11. Install mysql 5.7 and MHA node components
- Slave1 node server: CentOS7.6(64 bit) mysql2/192.168.3.12. Install mysql 5.7 and MHA node components
Slave2 node server: CentOS7.6(64 bit) mysql3/192.168.3.13. Install mysql 5.7 and MHA node components
#Turn off firewall systemctl stop firewalld systemctl disable firewalld setenforce 0
3. Install mysql5.7 on master, Slave1 and Slave2 nodes
- My previous blog has some specific tutorials for installing mysql
mysql installation tutorial
4. Modify the host names of Master, Slave1 and Slave2 nodes
[root@c7-1 ~]# hostnamectl set-hostname Master [root@c7-1 ~]# su [root@master ~]#
[root@c7-2 ~]#hostnamectl set-hostname Slave1 [root@c7-2 ~]#su [root@slave1 ~]#
[root@c7-3 ~]# hostnamectl set-hostname Slave2 [root@c7-3 ~]# su [root@slave2 ~]#
5. Modify the Mysql main configuration file / etc/my.cnf of Master, Slave1 and Slave2 nodes
- Modify master, comment character set
#Edit the main configuration file and comment the character set, otherwise an error will be reported vim /etc/my.cnf [mysqld] server-id = 1 log_bin = master-bin log-slave-updates = true systemctl restart mysqld

- Modify Slavel 1 and annotate the character set as well
vim /etc/my.cnf server-id = 2 #The server IDs of the three servers cannot be the same log_bin = master-bin relay-log = relay-log-bin relay-log-index = slave-relay-bin.index systemctl restart mysqld
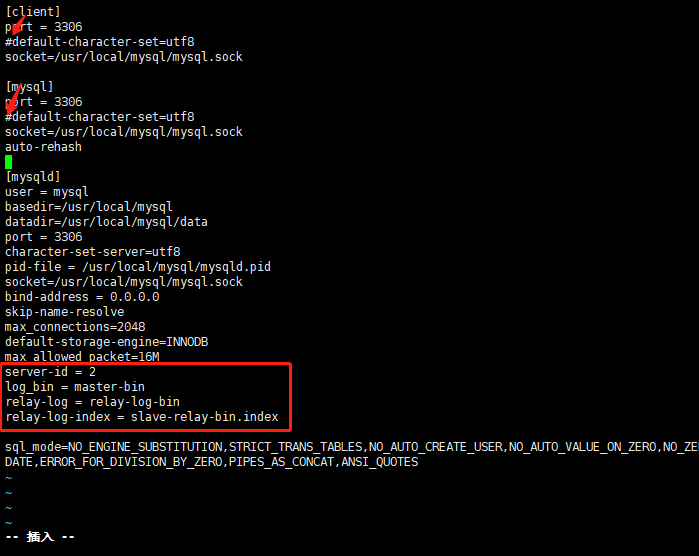
- Modify Slavel 2 and annotate the character set as well
vim /etc/my.cnf server-id = 3 #The server IDs of the three servers cannot be the same relay-log = relay-log-bin relay-log-index = slave-relay-bin.index systemctl restart mysqld
6. Create two soft links on the Master, Slave1 and Slave2 nodes
ln -s /usr/local/mysql/bin/mysql /usr/sbin/ ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
7. Configure mysql with one master and two slaves
7.1 mysql authorization for all database nodes
mysql -uroot -p grant replication slave on *.* to 'myslave'@'192.168.3.%' identified by '123456'; #Synchronize use from database grant all privileges on *.* to 'mha'@'192.168.3.%' identified by 'manager'; #manager usage grant all privileges on *.* to 'mha'@'master' identified by 'manager'; #Prevent the slave library from connecting to the master library through the host name grant all privileges on *.* to 'mha'@'slave1' identified by 'manager'; grant all privileges on *.* to 'mha'@'slave2' identified by 'manager'; flush privileges;
7.2 View binary files and synchronization points in the Master node
show master status; +-------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +-------------------+----------+--------------+------------------+-------------------+ | master-bin.000001 | 1743 | | | | +-------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
7.3 perform synchronization at Slave1 and Slave2 nodes
change master to master_host='192.168.3.11',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=1743; start slave;
7.4 view data synchronization results at Slave1 and Slave2 nodes
show slave status\G //Ensure that both IO and SQL threads are Yes, which means the synchronization is normal. Slave_IO_Running: Yes Slave_SQL_Running: Yes
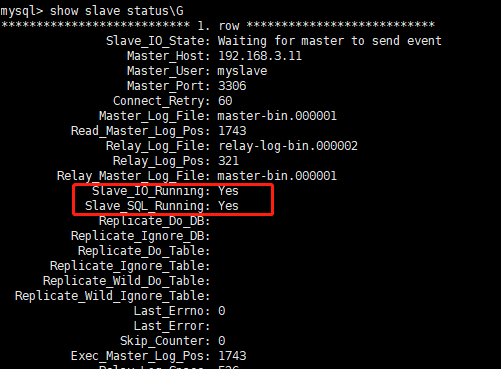
7.5 the two slave libraries must be set to read-only mode:
set global read_only=1;
7.6 insert data in the main database to test database synchronization
create database zone; use zone; create table dsj (id int(4),name varchar(20)); insert into dsj values(1,'zhangsan'); insert into dsj values(2,'lisi'); select * from dsj; +------+----------+ | id | name | +------+----------+ | 1 | zhangsan | | 2 | lisi | +------+----------+ 2 rows in set (0.00 sec)
- Query from server
select * from zone.dsj; +------+----------+ | id | name | +------+----------+ | 1 | zhangsan | | 2 | lisi | +------+----------+ 2 rows in set (0.00 sec)
8. Install MHA software
8.1 install MHA dependent environment on all servers. First install the epel source
yum install epel-release --nogpgcheck -y yum install -y perl-DBD-MySQL \ perl-Config-Tiny \ perl-Log-Dispatch \ perl-Parallel-ForkManager \ perl-ExtUtils-CBuilder \ perl-ExtUtils-MakeMaker \ perl-CPAN
8.2 to install MHA software package, node components must be installed on all servers first
- The version of each operating system is different. Here, CentOS 7.6 selects version 0.57.
- You must first install the node component on all servers, and finally install the manager component on the MHA manager node, because manager depends on the node component.
cd /opt tar zxvf mha4mysql-node-0.57.tar.gz cd mha4mysql-node-0.57 perl Makefile.PL make && make install
8.3 install the manager component on the MHA manager node
[root@c7-4 ~]# hostnamectl set-hostname manager [root@c7-4 ~]# su [root@manager ~]#
cd /opt tar zxvf mha4mysql-manager-0.57.tar.gz cd mha4mysql-manager-0.57 perl Makefile.PL make && make install
- After the manager component is installed, several tools will be generated under / usr/local/bin, mainly including the following:
masterha_check_ssh inspect MHA of SSH Configuration status masterha_check_repl inspect MySQL Replication status masterha_manger start-up manager Script for masterha_check_status Detect current MHA running state masterha_master_monitor testing master Is it down masterha_master_switch Control failover (automatic or manual) masterha_conf_host Add or remove configured server information masterha_stop close manager #After the node component is installed, several scripts will also be generated under / usr/local/bin (these tools are usually triggered by MHAManager scripts without manual operation). The main contents are as follows: save_binary_logs Save and copy master Binary log for apply_diff_relay_logs Identify differential relay log events and apply their differential events to other events slave filter_mysqlbinlog Remove unnecessary ROLLBACK Events( MHA (this tool is no longer used) purge_relay_logs Clear relay log (no blocking) SQL Thread)
9. Configure password less authentication on all servers
(1)stay manager Configure password less authentication to all database nodes on the node ssh-keygen -t rsa #Press enter all the way ssh-copy-id 192.168.3.11 //yes is required to confirm and enter the password ssh-copy-id 192.168.3.12 ssh-copy-id 192.168.3.13 (2)stay master Configure to database node on slave1 and slave2 Password less authentication ssh-keygen -t rsa #Press enter all the way ssh-copy-id 192.168.3.12 //yes is required to confirm and enter the password ssh-copy-id 192.168.3.13 (3)stay slave1 Configure to database node on master and slave2 Password less authentication ssh-keygen -t rsa #Press enter all the way ssh-copy-id 192.168.3.11 //yes is required to confirm and enter the password ssh-copy-id 192.168.3.13 (4)stay slave2 Configure to database node on master and slave1 Password less authentication ssh-keygen -t rsa #Press enter all the way ssh-copy-id 192.168.3.11 //yes is required to confirm and enter the password ssh-copy-id 192.168.3.12
10. Configure MHA on the manager node
10.1 on the manager node, copy the relevant scripts to the / usr/local/bin directory
cp -rp /opt/mha4mysql-manager-0.57/samples/scripts /usr/local/bin //After copying, there will be four execution files ll /usr/local/bin/scripts/ ---------------------------------------------------------------------------------------------------------- master_ip_failover #Script for VIP management during automatic switching master_ip_online_change #Management of vip during online switching power_manager #Script to shut down the host after a failure send_report #Script for sending alarms after failover ----------------------------------------------------------------------------------------------------------
10.2 copy the above script of VIP management during automatic switching to / usr/local/bin
Use here master_ip_failover Scripts to manage VIP And failover cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin
10.3 the modified contents are as follows: (delete the original contents, directly copy and modify vip related parameters)
vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#############################Add content section#########################################
my $vip = '192.168.3.200'; #Specify the address of the vip
my $brdc = '192.168.3.255'; #Specify the broadcast address of the vip
my $ifdev = 'ens33'; #Specify the network card bound by vip
my $key = '1'; #Specifies the serial number of the virtual network card bound by the vip
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; #Represents that the value of this variable is ifconfig ens33:1 192.168.3.200
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; #Represents that the value of this variable is ifconfig ens33:1 192.168.3.200 down
my $exit_code = 0; #Specifies that the exit status code is 0
#my $ssh_start_vip = "/usr/sbin/ip addr add $vip/24 brd $brdc dev $ifdev label $ifdev:$key;/usr/sbin/arping -q -A -c 1 -I $ifdev $vip;iptables -F;";
#my $ssh_stop_vip = "/usr/sbin/ip addr del $vip/24 dev $ifdev label $ifdev:$key";
##################################################################################
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
## A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
## Then in command mode % s/^#// Delete all#
#Go back to the first line/usr/bin/env perl Pre join #
10.4 create the MHA software directory and copy the configuration file. Here, use the app1.cnf configuration file to manage the mysql node server
mkdir /etc/masterha cp /opt/mha4mysql-manager-0.57/samples/conf/app1.cnf /etc/masterha vim /etc/masterha/app1.cnf #Delete the original content, directly copy and modify the IP address of the node server [server default] manager_log=/var/log/masterha/app1/manager.log manager_workdir=/var/log/masterha/app1 master_binlog_dir=/usr/local/mysql/data master_ip_failover_script=/usr/local/bin/master_ip_failover master_ip_online_change_script=/usr/local/bin/master_ip_online_change password=manager ping_interval=1 remote_workdir=/tmp repl_password=123456 repl_user=myslave secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.3.12 -s 192.168.3.13 shutdown_script="" ssh_user=root user=mha [server1] hostname=192.168.3.11 port=3306 [server2] candidate_master=1 check_repl_delay=0 hostname=192.168.3.12 port=3306 [server3] hostname=192.168.3.13 port=3306 ---------------------------------------------------------------------------------------------------------- [server default] manager_log=/var/log/masterha/app1/manager.log #manager log manager_workdir=/var/log/masterha/app1 #manager working directory master_binlog_dir=/usr/local/mysql/data/ #The location where the master saves binlog. The path here should be consistent with the path of binlog configured in the master so that MHA can find it master_ip_failover_script=/usr/local/bin/master_ip_failover #Set the switching script for automatic failover, that is, the script above master_ip_online_change_script=/usr/local/bin/master_ip_online_change #Set the switching script for manual switching password=manager #Set the password of the root user in mysql, which is the password of the monitoring user created in the previous article ping_interval=1 #Set the time interval for monitoring the main database and sending ping packets. The default is 3 seconds. When there is no response after three attempts, the failover will be carried out automatically remote_workdir=/tmp #Set the save location of binlog when remote mysql switches repl_password=123 #Set the password of the replication user repl_user=myslave #Set the user of the replication user report_script=/usr/local/send_report #Set the script of the alarm sent after switching secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.10.14 -s 192.168.10.15 #Specifies the IP address of the slave server to check shutdown_script="" #Set the script to close the fault host after the fault occurs (the main function of this script is to close the host to prevent brain crack, which is not used here) ssh_user=root #Set ssh login user name user=mha #Set monitoring user root [server1] hostname=192.168.3.11 port=3306 [server2] hostname=192.168.3.12 port=3306 candidate_master=1 #Set as the candidate master. After setting this parameter, the slave library will be promoted to the master library after the master-slave switch occurs, even if the slave library is not the latest slave in the cluster check_repl_delay=0 #By default, if a slave lags behind the master by more than 100M of relay logs, MHA will not select the slave as a new master, because the recovery of the slave takes a long time; By setting check_repl_delay=0, MHA triggers the switch. When selecting a new master, the replication delay will be ignored. This parameter is set to candidate_ The host with master = 1 is very useful because the candidate master must be a new master in the process of switching [server3] hostname=192.168.3.13 port=3306 ----------------------------------------------------------------------------------------------------------
11. For the first configuration, you need to manually start the virtual IP on the Master node
/sbin/ifconfig ens33:1 192.168.3.200/24
12. Test ssh password free authentication on the manager node
- If normal, it will finally output successfully, as shown below.
masterha_check_ssh -conf=/etc/masterha/app1.cnf

13. Test the mysql master-slave connection on the manager node
- Finally, MySQL Replication Health is OK appears, indicating that it is normal. As shown below
masterha_check_repl -conf=/etc/masterha/app1.cnf
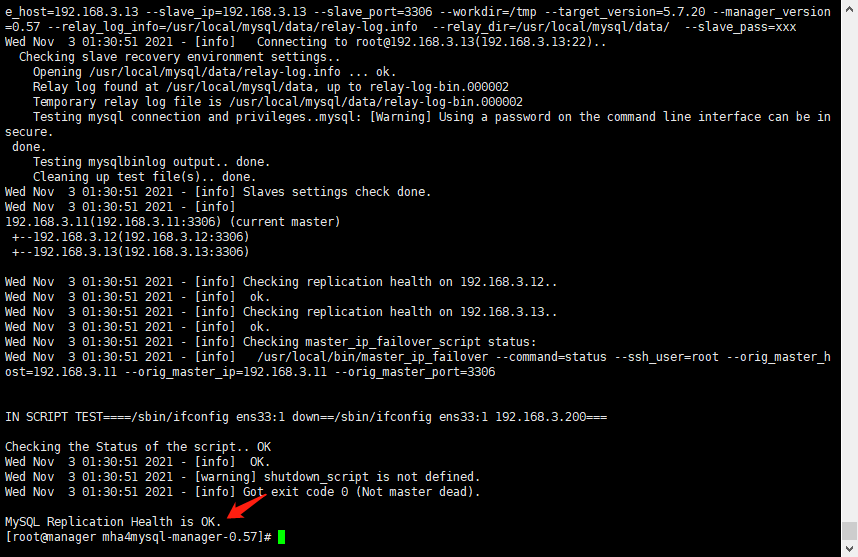
14. Start MHA on the manager node
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 & ---------------------------------------------------------------------------------------------------------- --remove_dead_master_conf: This parameter represents the of the old master database after master-slave switching ip Will be removed from the configuration file. --manger_log: Log storage location. --ignore_last_failover: By default, if MHA If continuous downtime is detected and the interval between two outages is less than 8 hours, it will not be Failover, The reason for this restriction is to avoid ping-pong effect. This parameter represents ignoring the last MHA Files generated by trigger switching. By default, MHA After switching, it will be recorded in the log, that is, the log set above app1.failover.complete File. If the file is found in this directory during the next switch, the switch is not allowed unless the file is deleted after the first switch. For convenience, it is set to--ignore_last_failover. ----------------------------------------------------------------------------------------------------------
15. Check MHA status
- You can see that the current master is the Mysql1 node.
masterha_check_status --conf=/etc/masterha/app1.cnf

16. View MHA log
- You can also see that the current master is 192.168.10.16, as shown below.
cat /var/log/masterha/app1/manager.log | grep "current master"

17. Check whether the VIP address 192.168.3.200 of Mysql1 exists
- This VIP address will not disappear because the manager node stops MHA service.
ifconfig
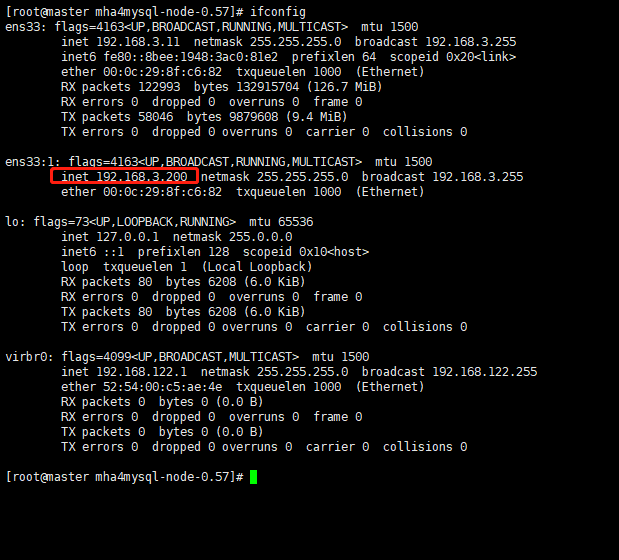
- To shut down the manager service, you can use the following command.
masterha_stop --conf=/etc/masterha/app1.cnf Or it can be used directly kill process ID Close by.
5, Simulated fault
- Monitor observation logging on the manager node
tail -f /var/log/masterha/app1/manager.log
- Stop the MySQL service on Master node Mysql1
systemctl stop mysqld or pkill -9 mysql
- After a normal automatic switching, the MHA process will exit. HMA will automatically modify the contents of the app1.cnf file and delete the down mysql1 node. Check whether mysql2 takes over VIP
ifconfig
- Algorithm of failover alternative master library:
1. Generally, the slave database is judged from (position/GTID). The data is different. It is closest to the slave of the master and becomes the alternative master.
2. If the data is consistent, select the alternative main database according to the sequence of configuration files.
3. Set the weight (candidate_master=1), and force to specify the alternative master according to the weight.
(1) By default, if a slave lags behind the master's 100m relay logs, even if it has a weight, it will become invalid.
(2) If check_ repl_ If delay = 0, even if it lags behind many logs, it is forced to select it as the alternative primary.
6, Troubleshooting steps
- Repair mysql
systemctl restart mysqld
- Repair master-slave
#View binary files and synchronization points on the current main database server Mysql2 show master status;
#Perform synchronization on the original master database server mysql1 change master to master_host='192.168.10.14',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=1745; start slave;
- Modify the configuration file app1.cnf on the manager node (add this record again, because it will disappear automatically when it detects failure)
vi /etc/masterha/app1.cnf ...... secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.10.14 -s 192.168.10.15 ...... [server1] hostname=192.168.80.11 port=3306 [server2] candidate_master=1 check_repl_delay=0 hostname=192.168.10.14 port=3306 [server3] hostname=192.168.10.15 port=3306
- Start MHA on the manager node
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
- Solve the problem of incompatible Chinese and English characters and error reporting
dos2unix /usr/local/bin/master_ip_failover