introduce
MHA (Master High Availability) is currently a relatively mature solution to MySQL high availability. It is a set of excellent high availability software as fault handover and master-slave promotion in MySQL high availability environment. In the process of MySQL fault switching, MHA can automatically complete the database fault switching operation within 0-30 seconds, and in the process of fault switching, MHA can ensure the consistency of data to the greatest extent, in order to achieve high availability in the true sense. It consists of two parts: MHA Manager (Management Node) and MHA Node (Data Node). MHA Manager can be deployed on a separate machine to manage multiple master-slave clusters, or on a slave node. MHA Node runs on each MySQL server, and MHA Manager regularly detects the master node in the cluster. When the master fails, it can automatically upgrade the slave of the latest data to the new master, and then redirect all other slaves to the new master. The whole failover process is completely transparent to the application. In the process of automatic failover of MHA, MHA tries to save binary logs from the downtime main server to ensure that data is not lost to the greatest extent, but this is not always feasible. For example, if the primary server hardware fails or can't be accessed through ssh, MHA can't save binary logs and only fail over and lose the latest data. Using MySQL 5.5 semi-synchronous replication can greatly reduce the risk of data loss. MHA can be combined with semi-synchronous replication. If only one slave has received the latest binary logs, MHA can apply the latest binary logs to all other slave servers, thus ensuring data consistency for all nodes.
principle

(1) Store binary log events from the downtime master;
(2) Identifying slave s with the latest updates;
(3) Apply relay log to other slave s;
(4) Apply binary log events saved from master;
(5) Promote a slave to a new master;
(6) Make other slave s connect to the new master for replication;
MHA software consists of two parts, Manager toolkit and Node toolkit.
The Manager Toolkit mainly includes the following tools:

Masha_check_ssh Checks the SSH configuration of MHA Masha_check_repl checks MySQL replication status Masha_manger starts MHA Masha_check_status detects the current MHA status Masha_master_monitor detects whether the master is down or not Master ha_master_switch control failover (automatic or manual) Masha_conf_host adds or deletes configuration server information
Node toolkits (which are usually triggered by MHA Manager scripts without human manipulation) mainly include the following tools:
save_binary_logs saves and replicates master's binary logs apply_diff_relay_logs identifies different relay log events and applies their different events to other slave s filter_mysqlbinlog removes unnecessary ROLLBACK events (MHA no longer uses this tool) purge_relay_logs clears relay logs (no blocking of SQL threads)
Installation of MHA
1. Create installation directory
Node Server Installation
mkdir -p /usr/local/mha
Management Server Installation
mkdir -p /usr/local/mha/ha1/fail_script
mkdir -p /usr/local/mha/ha1/workdir
/ usr/local/mha: Program Installation Directory
/ usr/local/mha/ha1: Used to distinguish each MHA scheme from the current scheme HA1
/ usr/local/mha/ha1/fail_script: The failover script save path for scheme HA1
/ usr/local/mha/ha1/workdir: Log of scheme HA1 and binlog save path generated by failover
2. Install epel plug-in
To install in yum mode, epel source needs to be installed
epel source
wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
All servers are installed (mananage needs to install all the following plug-ins, node only needs to install perl-DBD-MySQL,cpan)
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes cpan
perl can also be used to install
#!/bin/bash wget http://xrl.us/cpanm --no-check-certificate mv cpanm /usr/bin chmod 755 /usr/bin/cpanm cat > /root/list << EOF install DBD::mysql install Config::Tiny install Log::Dispatch install Parallel::ForkManager install Time::HiRes install CPAN install Digest::SHA EOF for package in `cat /root/list` do cpanm $package done
3. Install MHA Node package, all servers need to be installed
tar -xvf mha4mysql-node-0.54.tar.gz cd mha4mysql-node-0.54 perl Makefile.PL INSTALL_BASE=/usr/local/mha make && make install
4. Install the MHA Manager package, only on the Manager host
tar -xvf mha4mysql-manager-0.55.tar.gz cd mha4mysql-manager-0.55 perl Makefile.PL INSTALL_BASE=/usr/local/mha make && make install
cp samples/scripts/* /usr/local/mha/bin/
master_ip_failover: script for vip management in automatic handover
master_ip_online_change: script for manual switching
power_manager: A script to shut down the host after a failure occurs
send_report: A script to send an alarm.
5. Modifying environmental variables
Add / usr/local/mha/bin of MHA Manager host to environment variables
6. Add soft links
In order not to bother all servers to execute it, in fact, the last two mysql,mysqlbinlog soft links only need to be added by Node server, all other servers need to be added.
mkdir -p /usr/local/bin mkdir -p /usr/local/share/man/man1 mkdir -p /usr/local/share/perl5/MHA ln -s /usr/local/mha/bin/* /usr/local/bin; ln -s /usr/local/mha/man/man1/* /usr/local/share/man/man1; ln -s /usr/local/mha/lib/perl5/MHA /usr/local/share/perl5/MHA; ln -s /usr/local/mysql/bin/mysqlbinlog /usr/local/bin/mysqlbinlog; ln -s /usr/local/mysql/bin/mysql /usr/local/bin/mysql;
Configuration of MHA
1. Configure SSH passwordless login
(1) Password-free login configured to all Node nodes in manage ment
ssh-keygen -t rsa always enter,Will be in/root/.ssh/The following generation id_rsa.pub ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(2) No password login from Node 10 to Node 20,30
ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(3) No password login from Node 20 to Node 10,30
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10
ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(4) Password-free login from Node 30 to Node 10,20
ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20
2. Building a replication environment
The replication environment has been set up before, you can refer to the article I wrote earlier, the replication user and password are repl; every Node must create this repl account, unless Node is not a master of malfunction specialty.
1. Create Manage Monitor Users on all Node s
grant all privileges on *.* to 'root'@'192.168.137.%' identified by 'root';
Configuration of Manage
1. Configuration startup file
vim /usr/local/mha/ha1/ha1.cnf
[server default] manager_workdir=/usr/local/mha/ha1/workdir ##Home Catalogue of Projects manager_log=/usr/local/mha/ha1/workdir/manager.log ###mha log master_binlog_dir=/mysql/log ####The binlog storage path of the node server is configured separately under each server below if the binlog path of each node is inconsistent master_ip_failover_script=/usr/local/mha/ha1/fail_script/master_ip_failover ####Processing VIP configuration files when mha failover online automatically master_ip_online_change_script=/usr/local/mha/ha1/fail_script/master_ip_online_change ####VIP Processing Files for Manual master Switching Online secondary_check_script=/usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 ##Once there is a network problem between MHA and master, manager will try to log in from backup to masger #report_script=/usr/local/mha/ha1/fail_script/send_report ###Alarm script executed after handover shutdown_script="" ####The script to shut down the master host after the failure (mainly when using keepalive to do VIP, there will be brain fissure which will lead to frequent VIP switching, so the master of the failure will be shut down) ping_interval=1 ###Monitor the frequency of mater, ping remote_workdir=/tmp ###When a master switch occurs on a node server, the path maintained by the binlog will be saved in that directory for each node, unless there is no difference. repl_password=repl ##Replicate the username used, and each node server needs to exist repl_user=repl ##Copy passwords user=root ##mysql root user for mnager monitoring password=root ##root user password ssh_user=root ##ssh login user name [server1] hostname=192.168.137.10 port=3306 candidate_master=1 check_repl_delay=0 [server2] hostname=192.168.137.20 port=3306 #master_binlog_dir=/mysql/log candidate_master=1 ##Set it as a candidate master, and if this parameter is set, the slave library will be elevated to the master library after master-slave switching occurs, even if the master library is not the latest slave of events in the cluster. check_repl_delay=0 ##By default, if a slave lags behind relay logs of master 100M, MHA will not choose the slave as a new master because recovery of the slave takes a long time. By setting check_repl_delay=0, the MHA trigger switch will ignore the replication delay when selecting a new master. Number is very useful for hosts with candidate_master=1, because this candidate must be a new master in the process of switching. [server3] hostname=192.168.137.30 port=3306 ignore_fail=1 ####If this parameter is not added, when the slave host fails, mha will not be able to start. Adding this parameter will ignore whether the host is normal. When mha starts, add the parameter - ignore_fail_on_start. no_master=1 ###Do not convert this host to master
Note: For the above configuration, it is important to ensure that the binlog between server1 and server2 is the latest binlog. Generally, the binlog between server1 and server2 is a semi-synchronous duplication with two principals. This ensures that the binlog between them is the latest. Otherwise, it will take a very long time to apply the binlog with different application (if the delay between them and master is very large).
2.master_ip_failover
The configuration of VIP can use keepalived or script writing. The requirement of keepalived is very high on the network, otherwise it is easy to crack. I have talked about the method of building keepalived in the double main environment before me. I use script here.
#!/usr/bin/env perl use strict; use warnings FATAL => 'all'; use Getopt::Long; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password ); my $vip = '192.168.137.50/24'; ###VIP my $key = '1'; ###The eth0 used to distinguish itself my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, ); exit &main(); sub main { print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; exit 0; } else { &usage(); exit 1; } } sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; } sub stop_vip() { return 0 unless ($ssh_user); `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }
Note: You need to manually add VIP to the master server first
/sbin/ifconfig eth0:1 192.168.137.50/24
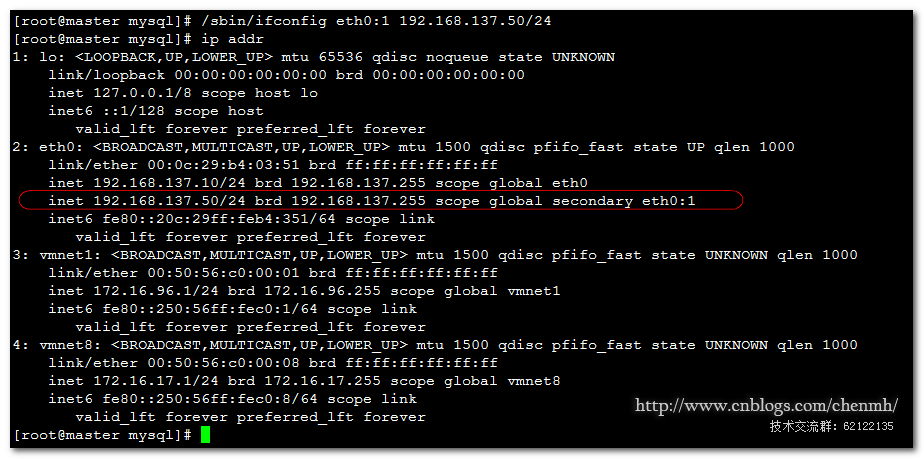
3.master_ip_online_change
perl script
#!/usr/bin/env perl use strict; use warnings FATAL =>'all'; use Getopt::Long; my $vip = '192.168.137.50/24'; # Virtual IP my $key = "1"; my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; my $exit_code = 0; my ( $command, $orig_master_is_new_slave, $orig_master_host, $orig_master_ip, $orig_master_port, $orig_master_user, $orig_master_password, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password, ); GetOptions( 'command=s' => \$command, 'orig_master_is_new_slave' => \$orig_master_is_new_slave, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'orig_master_user=s' => \$orig_master_user, 'orig_master_password=s' => \$orig_master_password, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, ); exit &main(); sub main { #print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { # $orig_master_host, $orig_master_ip, $orig_master_port are passed. # If you manage master ip address at global catalog database, # invalidate orig_master_ip here. my $exit_code = 1; eval { print "\n\n\n***************************************************************\n"; print "Disabling the VIP - $vip on old master: $orig_master_host\n"; print "***************************************************************\n\n\n\n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { # all arguments are passed. # If you manage master ip address at global catalog database, # activate new_master_ip here. # You can also grant write access (create user, set read_only=0, etc) here. my $exit_code = 10; eval { print "\n\n\n***************************************************************\n"; print "Enabling the VIP - $vip on new master: $new_master_host \n"; print "***************************************************************\n\n\n\n"; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; `ssh $orig_master_user\@$orig_master_host \" $ssh_start_vip \"`; exit 0; } else { &usage(); exit 1; } } # A simple system call that enable the VIP on the new master sub start_vip() { `ssh $new_master_user\@$new_master_host \" $ssh_start_vip \"`; } # A simple system call that disable the VIP on the old_master sub stop_vip() { `ssh $orig_master_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }
shell script
#/bin/bash #source /root/.bash_profile vip=`echo '192.168.137.50/24'` # Virtual IP key=`echo '1'` command=`echo "$1" | awk -F = '{print $2}'` orig_master_host=`echo "$2" | awk -F = '{print $2}'` new_master_host=`echo "$7" | awk -F = '{print $2}'` stop_vip=`echo "ssh root@$orig_master_host /sbin/ifconfig eth0:$key down"` start_vip=`echo "ssh root@$new_master_host /sbin/ifconfig eth0:$key $vip"` if [ $command = 'stop' ] then echo -e "\n\n\n***************************************************************\n" echo -e "Disabling the VIP - $vip on old master: $orig_master_host\n" $stop_vip if [ $? -eq 0 ] then echo "Disabled the VIP successfully" else echo "Disabled the VIP failed" fi echo -e "***************************************************************\n\n\n\n" fi if [ $command = 'start' -o $command = 'status' ] then echo -e "\n\n\n***************************************************************\n" echo -e "Enabling the VIP - $vip on new master: $new_master_host \n" $start_vip if [ $? -eq 0 ] then echo "Enabled the VIP successfully" else echo "Enabled the VIP failed" fi echo -e "***************************************************************\n\n\n\n" fi
4.send_report
mutt has to be installed here first. Installation method is not introduced here.#!/usr/bin/perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Mail::Sender; use Getopt::Long; #new_master_host and new_slave_hosts are set only when recovering master succeeded my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body ); my $smtp='smtp.163.com'; my $mail_from='xxxx'; my $mail_user='xxxxx'; my $mail_pass='xxxxx'; my $mail_to=['xxxx','xxxx']; GetOptions( 'orig_master_host=s' => \$dead_master_host, 'new_master_host=s' => \$new_master_host, 'new_slave_hosts=s' => \$new_slave_hosts, 'subject=s' => \$subject, 'body=s' => \$body, ); mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body); sub mailToContacts { my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_; open my $DEBUG, "> /tmp/monitormail.log" or die "Can't open the debug file:$!\n"; my $sender = new Mail::Sender { ctype => 'text/plain; charset=utf-8', encoding => 'utf-8', smtp => $smtp, from => $mail_from, auth => 'LOGIN', TLS_allowed => '0', authid => $user, authpwd => $passwd, to => $mail_to, subject => $subject, debug => $DEBUG }; $sender->MailMsg( { msg => $msg, debug => $DEBUG } ) or print $Mail::Sender::Error; return 1; } # Do whatever you want here exit 0;
4. Configure how relay_log is cleared (on each Node)
(1) All Node's cnf configuration files are added
relay_log_purge=0
In the process of switching, MHA relies on relay log information in the recovery process from the library, so the automatic clearance of relay log is set to OFF, and relay log is cleared manually.
By default, the relay log from the server is automatically deleted after the execution of the SQL thread. However, in MHA environment, these relay logs may be used to recover other slave servers, so automatic deletion of relay logs needs to be disabled. Regular removal of relay logs requires consideration of replication latency. Under ext3 filesystem, deleting large files takes a certain amount of time, which can lead to serious replication delay. In order to avoid replication delay, it is necessary to temporarily create hard links for relay logs, because it is very fast to delete large files through hard links in linux systems.
Tip: When deleting large tables in mysql database, hard links are usually established.
The MHA node contains the pure_relay_logs command tool, which can create hard links for relay logs, execute SET GLOBAL relay_log_purge=1, wait a few seconds for the SQL thread to switch to the new relay log, and then execute SET GLOBAL relay_log_purge=0.
The pure_relay_logs script parameters are as follows:
user mysql user name password mysql password Port port number Wordir specifies the location of the hard link to create relay log. The default is / var/tmp. Because the hard link files created by different partitions of the system will fail, the specific location of the hard link needs to be executed. After the script is executed successfully, the hard link relay log files are deleted. - disable_relay_log_purge By default, if relay_log_purge=1, the script will not clear up anything and automatically exit. By setting this parameter, relay_log_purge will be set to 0 when relay_log_purge=1. After cleaning up the relay log, the parameters are finally set to OFF.
(2) Create on each slave Node
vim /usr/local/mha/purge_relay_log.sh
#!/bin/bash
user=root
passwd=root ####Ensure that users and passwords can pass 127.0.0.1 Log in
host='127.0.0.1'
port=3306
work_dir='/mysql/data'
purge='/usr/local/mha/bin/purge_relay_logs'
$purge --user=$user --password=$passwd --host=$host --disable_relay_log_purge --port=$port --workdir=$work_dir >> /usr/local/mha/purge_relay_logs.log 2>&1
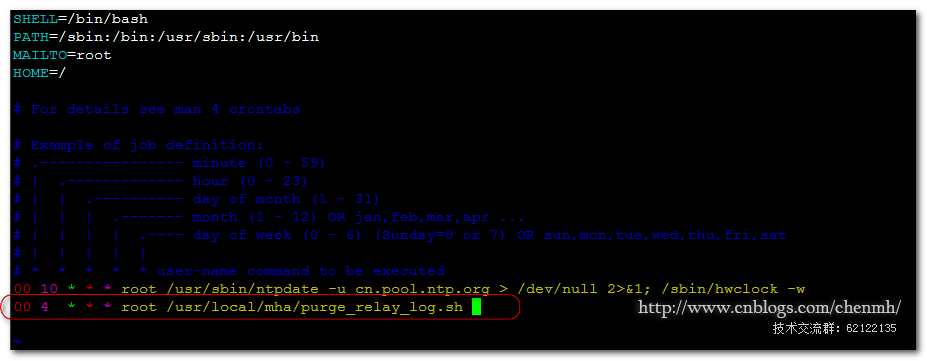
chmod u+x /usr/local/mha/purge_relay_log.sh
Add scripts to os timing tasks
V. Detection and start-up of MHA
1. Check ssh configuration
masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf
[root@monitor ha1]# masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf Thu Aug 25 14:53:30 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Aug 25 14:53:30 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Starting SSH connection tests.. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from root@192.168.137.20(192.168.137.20:22) to root@192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from root@192.168.137.20(192.168.137.20:22) to root@192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from root@192.168.137.30(192.168.137.30:22) to root@192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from root@192.168.137.30(192.168.137.30:22) to root@192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [debug] Thu Aug 25 14:53:30 2016 - [debug] Connecting via SSH from root@192.168.137.10(192.168.137.10:22) to root@192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:34 2016 - [debug] Connecting via SSH from root@192.168.137.10(192.168.137.10:22) to root@192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:35 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [info] All SSH connection tests passed successfully.
You can see that each Node is connected to the other Nodes.
2. Check the entire replication environment
masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf
[root@monitor ha1]# masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf Thu Aug 25 16:09:19 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Aug 25 16:09:19 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 16:09:19 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 16:09:19 2016 - [info] MHA::MasterMonitor version 0.55. Thu Aug 25 16:09:20 2016 - [info] Dead Servers: Thu Aug 25 16:09:20 2016 - [info] Alive Servers: Thu Aug 25 16:09:20 2016 - [info] 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.20(192.168.137.20:3306) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.30(192.168.137.30:3306) Thu Aug 25 16:09:20 2016 - [info] Alive Slaves: Thu Aug 25 16:09:20 2016 - [info] 192.168.137.20(192.168.137.20:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Thu Aug 25 16:09:20 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Primary candidate for the new Master (candidate_master is set) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Thu Aug 25 16:09:20 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Not candidate for the new Master (no_master is set) Thu Aug 25 16:09:20 2016 - [info] Current Alive Master: 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Checking slave configurations.. Thu Aug 25 16:09:20 2016 - [info] read_only=1 is not set on slave 192.168.137.20(192.168.137.20:3306). Thu Aug 25 16:09:20 2016 - [info] Checking replication filtering settings.. Thu Aug 25 16:09:20 2016 - [info] binlog_do_db= , binlog_ignore_db= Thu Aug 25 16:09:20 2016 - [info] Replication filtering check ok. Thu Aug 25 16:09:20 2016 - [info] Starting SSH connection tests.. Thu Aug 25 16:09:25 2016 - [info] All SSH connection tests passed successfully. Thu Aug 25 16:09:25 2016 - [info] Checking MHA Node version.. Thu Aug 25 16:09:26 2016 - [info] Version check ok. Thu Aug 25 16:09:26 2016 - [info] Checking SSH publickey authentication settings on the current master.. Thu Aug 25 16:09:27 2016 - [info] HealthCheck: SSH to 192.168.137.10 is reachable. Thu Aug 25 16:09:29 2016 - [info] Master MHA Node version is 0.54. Thu Aug 25 16:09:29 2016 - [info] Checking recovery script configurations on the current master.. Thu Aug 25 16:09:29 2016 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/mysql/log --output_file=/tmp/save_binary_logs_test --manager_version=0.55 --start_file=mysql-bin.000138 Thu Aug 25 16:09:29 2016 - [info] Connecting to root@192.168.137.10(192.168.137.10).. Creating /tmp if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /mysql/log, up to mysql-bin.000138 Thu Aug 25 16:09:30 2016 - [info] Master setting check done. Thu Aug 25 16:09:30 2016 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers.. Thu Aug 25 16:09:30 2016 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=192.168.137.20 --slave_ip=192.168.137.20 --slave_port=3306 --workdir=/tmp --target_version=5.6.15-log --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ --slave_pass=xxx Thu Aug 25 16:09:30 2016 - [info] Connecting to root@192.168.137.20(192.168.137.20:22).. Checking slave recovery environment settings.. Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000006 Temporary relay log file is /mysql/data/mysql-relay-bin.000006 Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Thu Aug 25 16:09:31 2016 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=192.168.137.30 --slave_ip=192.168.137.30 --slave_port=3306 --workdir=/tmp --target_version=5.6.15-log --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ --slave_pass=xxx Thu Aug 25 16:09:31 2016 - [info] Connecting to root@192.168.137.30(192.168.137.30:22).. Checking slave recovery environment settings.. Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000002 Temporary relay log file is /mysql/data/mysql-relay-bin.000002 Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Thu Aug 25 16:09:32 2016 - [info] Slaves settings check done. Thu Aug 25 16:09:32 2016 - [info] 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 Thu Aug 25 16:09:32 2016 - [info] Checking replication health on 192.168.137.20.. Thu Aug 25 16:09:32 2016 - [info] ok. Thu Aug 25 16:09:32 2016 - [info] Checking replication health on 192.168.137.30.. Thu Aug 25 16:09:32 2016 - [info] ok. Thu Aug 25 16:09:32 2016 - [info] Checking master_ip_failover_script status: Thu Aug 25 16:09:32 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Checking the Status of the script.. OK Thu Aug 25 16:09:32 2016 - [info] OK. Thu Aug 25 16:09:32 2016 - [warning] shutdown_script is not defined. Thu Aug 25 16:09:32 2016 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
Ignore_fail_on_start: When there is a slave node down, the default is not bootable, plus -- ignore_fail_on_start can start MHA even if there is a node down, plus this parameter ignores the server configuration ignore_fail=1 in the startup file.
3. Check MHA Manager status
masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf

Since mha has not yet been started, the detection here is stopped
4. Start MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
--remove_dead_master_conf: This parameter represents that when master-slave switching occurs, the ip of the old master library will be removed from the configuration file. This parameter is not used here for the time being, because it will mess up the ha1.cnf configuration file if used.
-- start_log: Log.
ignore_last_failover: The MHA manager service automatically stops after the master-slave switch occurs, and the file app1.failover.complete is generated under the manager_workdir directory. To start MHA, you must delete the file first. This parameter represents the file generated by ignoring the last MHA trigger switch, which is set to -ignore_last_failover. By default, Failover will not occur if MHA detects a continuous downtime with less than eight hours between downtimes. The reason for this limitation is to avoid ping-pong effect.
Ignore_fail_on_start: When there is a slave node down, the default is not bootable, plus -- ignore_fail_on_start can start MHA even if there is a node down, plus this parameter ignores the server configuration ignore_fail=1 in the startup file.
(1) Check again whether the MHA status is normal:
[root@monitor ha1]# masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf ha1 (pid:6371) is running(0:PING_OK), master:192.168.137.10 [root@monitor ha1]#
(2) View the startup log
cat manager.log
Thu Aug 25 17:11:50 2016 - [info] 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 Thu Aug 25 17:11:50 2016 - [info] Checking master_ip_failover_script status: Thu Aug 25 17:11:50 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Checking the Status of the script.. OK Thu Aug 25 17:11:50 2016 - [info] OK. Thu Aug 25 17:11:50 2016 - [warning] shutdown_script is not defined. Thu Aug 25 17:11:50 2016 - [info] Set master ping interval 1 seconds. Thu Aug 25 17:11:50 2016 - [info] Set secondary check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 Thu Aug 25 17:11:50 2016 - [info] Starting ping health check on 192.168.137.10(192.168.137.10:3306).. Thu Aug 25 17:11:50 2016 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond.. [root@monitor ha1]#
(3) Documents generated
ha1.master_status.health: mha normally starts to produce this file
manager.log: mha monitoring log
Start. log: log generated at MHA startup
5. Close MHA
masterha_stop --conf=/usr/local/mha/ha1/ha1.cnf
6. Fault Handling Steps
When master-slave switchover occurs, the MHA service automatically stops
1. Check logs
Check the fault processing log to ensure the normal transfer of the fault.
cat /usr/local/mha/ha1/manager.log
2. Handling Fault master
The master that handles the failures, configures it from the library chang to the new master, and finds the change statement from manager.log.
grep "CHANGE MASTER TO MASTER" /usr/local/mha/ha1/manager.log | tail -1
Fri Aug 26 12:04:22 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000143', MASTER_LOG_POS=22123166, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Note: Here we want to ensure that slave's SQL_THREAD and IO_TRREAD are normal. If we configure semi-synchronous replication to ensure that semi-synchronous replication starts properly, we can execute "show status like'% rpl_%;", referring specifically to the previous semi-synchronous replication.
3. Modify the ha1.cnf configuration file
You need to modify master_host, master_ip, master_port in the "secondary_check_script" option to be the new master; if both computers have the same configuration, you don't need to modify anywhere else.
4. Delete fail files (not required)
Since the -- ignore_last_failover parameter is added when starting mha, the file generated by failower can also be started without deleting it, otherwise the file "ha1.failover.complete" generated by failower needs to be deleted.
rm -f /usr/local/mha/ha1/ha1.failover.complete
5.check check
Check SSH configuration masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf Check replication masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf Check status masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf
It is necessary to ensure that all checks are passed.
6. Start MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
7. Simulated Failover
1. Automatic failover
I'm an asynchronous replicator, 137.20 is the current master, and then I execute concurrent insertion on 137.20. I close 137.10 and 137.30 IO threads at the same time. I test on 137.20 for a period of time, then I open 137.30 IO threads first, and then I open 137.10 IO threads in a few seconds. Make sure that 137.30 binlog is updated compared with the candidate 137.10 binlog.
master 137.20(22497564)
candidate slave:137.10(pos=9857376)
new replay slave:137.30(pos=22461852)
Fri Aug 26 11:57:36 2016 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query) Fri Aug 26 11:57:36 2016 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/mysql/log --output_file=/tmp/save_binary_logs_test --manager_version=0.55 --binlog_prefix=mysql-bin Fri Aug 26 11:57:36 2016 - [info] Executing seconary network check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 --user=root --master_host=192.168.137.20 --master_ip=192.168.137.20 --master_port=3306 Fri Aug 26 11:57:37 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:37 2016 - [warning] Connection failed 1 time(s).. Fri Aug 26 11:57:38 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:38 2016 - [warning] Connection failed 2 time(s).. Fri Aug 26 11:57:38 2016 - [info] HealthCheck: SSH to 192.168.137.20 is reachable. Monitoring server backup is reachable, Master is not reachable from backup. OK. Fri Aug 26 11:57:39 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:39 2016 - [warning] Connection failed 3 time(s).. Monitoring server master is reachable, Master is not reachable from master. OK. Fri Aug 26 11:57:41 2016 - [info] Master is not reachable from all other monitoring servers. Failover should start. Fri Aug 26 11:57:41 2016 - [warning] Master is not reachable from health checker! Fri Aug 26 11:57:41 2016 - [warning] Master 192.168.137.20(192.168.137.20:3306) is not reachable! Fri Aug 26 11:57:41 2016 - [warning] SSH is reachable. Fri Aug 26 11:57:41 2016 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /usr/local/mha/ha1/ha1.cnf again, and trying to connect to all servers to check server status.. Fri Aug 26 11:57:41 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Aug 26 11:57:41 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 11:57:41 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 11:57:42 2016 - [info] Dead Servers: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Alive Servers: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306) Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306) Fri Aug 26 11:57:42 2016 - [info] Alive Slaves: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 11:57:42 2016 - [info] Checking slave configurations.. Fri Aug 26 11:57:42 2016 - [info] read_only=1 is not set on slave 192.168.137.10(192.168.137.10:3306). Fri Aug 26 11:57:42 2016 - [info] Checking replication filtering settings.. Fri Aug 26 11:57:42 2016 - [info] Replication filtering check ok. Fri Aug 26 11:57:42 2016 - [info] Master is down! Fri Aug 26 11:57:42 2016 - [info] Terminating monitoring script. Fri Aug 26 11:57:42 2016 - [info] Got exit code 20 (Master dead). Fri Aug 26 11:57:42 2016 - [info] MHA::MasterFailover version 0.55. Fri Aug 26 11:57:42 2016 - [info] Starting master failover. Fri Aug 26 11:57:42 2016 - [info] Fri Aug 26 11:57:42 2016 - [info] * Phase 1: Configuration Check Phase.. Fri Aug 26 11:57:42 2016 - [info] Fri Aug 26 11:57:44 2016 - [info] Dead Servers: Fri Aug 26 11:57:44 2016 - [info] 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:44 2016 - [info] Checking master reachability via mysql(double check).. Fri Aug 26 11:57:44 2016 - [info] ok. Fri Aug 26 11:57:44 2016 - [info] Alive Servers: Fri Aug 26 11:57:44 2016 - [info] 192.168.137.10(192.168.137.10:3306) Fri Aug 26 11:57:44 2016 - [info] 192.168.137.30(192.168.137.30:3306) Fri Aug 26 11:57:44 2016 - [info] Alive Slaves: Fri Aug 26 11:57:44 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:44 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:44 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 11:57:44 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:44 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:44 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 11:57:44 2016 - [info] ** Phase 1: Configuration Check Phase completed. Fri Aug 26 11:57:44 2016 - [info] Fri Aug 26 11:57:44 2016 - [info] * Phase 2: Dead Master Shutdown Phase.. Fri Aug 26 11:57:44 2016 - [info] Fri Aug 26 11:57:44 2016 - [info] Forcing shutdown so that applications never connect to the current master.. Fri Aug 26 11:57:44 2016 - [info] Executing master IP deactivatation script: Fri Aug 26 11:57:44 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --command=stopssh --ssh_user=root IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Disabling the VIP on old master: 192.168.137.20 Fri Aug 26 11:57:45 2016 - [info] done. Fri Aug 26 11:57:45 2016 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Fri Aug 26 11:57:45 2016 - [info] * Phase 2: Dead Master Shutdown Phase completed. Fri Aug 26 11:57:45 2016 - [info] Fri Aug 26 11:57:45 2016 - [info] * Phase 3: Master Recovery Phase.. Fri Aug 26 11:57:45 2016 - [info] Fri Aug 26 11:57:45 2016 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Fri Aug 26 11:57:45 2016 - [info] Fri Aug 26 11:57:45 2016 - [info] The latest binary log file/position on all slaves is mysql-bin.000074:22461852 Fri Aug 26 11:57:45 2016 - [info] Latest slaves (Slaves that received relay log files to the latest): Fri Aug 26 11:57:45 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:45 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:45 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 11:57:45 2016 - [info] The oldest binary log file/position on all slaves is mysql-bin.000074:9857376 Fri Aug 26 11:57:45 2016 - [info] Oldest slaves: Fri Aug 26 11:57:45 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:45 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:45 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 11:57:45 2016 - [info] Fri Aug 26 11:57:45 2016 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase.. Fri Aug 26 11:57:45 2016 - [info] Fri Aug 26 11:57:46 2016 - [info] Fetching dead master's binary logs.. Fri Aug 26 11:57:46 2016 - [info] Executing command on the dead master 192.168.137.20(192.168.137.20:3306): save_binary_logs --command=save --start_file=mysql-bin.000074 --start_pos=22461852 --binlog_dir=/mysql/log --output_file=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 Creating /tmp if not exists.. ok. Concat binary/relay logs from mysql-bin.000074 pos 22461852 to mysql-bin.000074 EOF into /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog .. Dumping binlog format description event, from position 0 to 120.. ok. Dumping effective binlog data from /mysql/log/mysql-bin.000074 position 22461852 to tail(22497564).. ok. Concat succeeded. Fri Aug 26 11:57:49 2016 - [info] scp from root@192.168.137.20:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded. Fri Aug 26 11:57:52 2016 - [info] HealthCheck: SSH to 192.168.137.10 is reachable. Fri Aug 26 11:57:55 2016 - [info] HealthCheck: SSH to 192.168.137.30 is reachable. Fri Aug 26 11:57:55 2016 - [info] Fri Aug 26 11:57:55 2016 - [info] * Phase 3.3: Determining New Master Phase.. Fri Aug 26 11:57:55 2016 - [info] Fri Aug 26 11:57:55 2016 - [info] Finding the latest slave that has all relay logs for recovering other slaves.. Fri Aug 26 11:57:55 2016 - [info] Checking whether 192.168.137.30 has relay logs from the oldest position.. Fri Aug 26 11:57:55 2016 - [info] Executing command: apply_diff_relay_logs --command=find --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --workdir=/tmp --timestamp=20160826115742 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ : Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000003 Fast relay log position search succeeded. Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539. Target relay log FOUND! Fri Aug 26 11:57:56 2016 - [info] OK. 192.168.137.30 has all relay logs. Fri Aug 26 11:57:56 2016 - [info] Searching new master from slaves.. Fri Aug 26 11:57:56 2016 - [info] Candidate masters from the configuration file: Fri Aug 26 11:57:56 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:56 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:56 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 11:57:56 2016 - [info] Non-candidate masters: Fri Aug 26 11:57:56 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:56 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:56 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 11:57:56 2016 - [info] Searching from candidate_master slaves which have received the latest relay log events.. Fri Aug 26 11:57:56 2016 - [info] Not found. Fri Aug 26 11:57:56 2016 - [info] Searching from all candidate_master slaves.. Fri Aug 26 11:57:56 2016 - [info] New master is 192.168.137.10(192.168.137.10:3306) Fri Aug 26 11:57:56 2016 - [info] Starting master failover.. Fri Aug 26 11:57:56 2016 - [info] From: 192.168.137.20 (current master) +--192.168.137.10 +--192.168.137.30 To: 192.168.137.10 (new master) +--192.168.137.30 Fri Aug 26 11:57:56 2016 - [info] Fri Aug 26 11:57:56 2016 - [info] * Phase 3.3: New Master Diff Log Generation Phase.. Fri Aug 26 11:57:56 2016 - [info] Fri Aug 26 11:57:56 2016 - [info] Server 192.168.137.10 received relay logs up to: mysql-bin.000074:9857376 Fri Aug 26 11:57:56 2016 - [info] Need to get diffs from the latest slave(192.168.137.30) up to: mysql-bin.000074:22461852 (using the latest slave's relay logs) Fri Aug 26 11:57:56 2016 - [info] Connecting to the latest slave host 192.168.137.30, generating diff relay log files.. Fri Aug 26 11:57:56 2016 - [info] Executing command: apply_diff_relay_logs --command=generate_and_send --scp_user=root --scp_host=192.168.137.10 --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --diff_file_readtolatest=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog --workdir=/tmp --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ Fri Aug 26 11:58:02 2016 - [info] Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000003 Fast relay log position search succeeded. Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539. Concat binary/relay logs from mysql-relay-bin.000003 pos 9857539 to mysql-relay-bin.000003 EOF into /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog .. Dumping binlog format description event, from position 0 to 283.. ok. Dumping effective binlog data from /mysql/data/mysql-relay-bin.000003 position 9857539 to tail(22462015).. ok. Concat succeeded. Generating diff relay log succeeded. Saved at /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog . scp slave:/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to root@192.168.137.10(22) succeeded. Fri Aug 26 11:58:02 2016 - [info] Generating diff files succeeded. Fri Aug 26 11:58:02 2016 - [info] Sending binlog.. Fri Aug 26 11:58:04 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to root@192.168.137.10:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded. Fri Aug 26 11:58:04 2016 - [info] Fri Aug 26 11:58:04 2016 - [info] * Phase 3.4: Master Log Apply Phase.. Fri Aug 26 11:58:04 2016 - [info] Fri Aug 26 11:58:04 2016 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed. Fri Aug 26 11:58:04 2016 - [info] Starting recovery on 192.168.137.10(192.168.137.10:3306).. Fri Aug 26 11:58:04 2016 - [info] Generating diffs succeeded. Fri Aug 26 11:58:04 2016 - [info] Waiting until all relay logs are applied. Fri Aug 26 12:00:06 2016 - [info] done. Fri Aug 26 12:00:06 2016 - [info] Getting slave status.. Fri Aug 26 12:00:06 2016 - [info] This slave(192.168.137.10)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:9857376). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 12:00:06 2016 - [info] Connecting to the target slave host 192.168.137.10, running recover script.. Fri Aug 26 12:00:06 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.10 --slave_ip=192.168.137.10 --slave_port=3306 --apply_files=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 12:04:22 2016 - [info] Concat all apply files to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog .. Copying the first binlog file /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog.. ok. Dumping binlog head events (rotate events), skipping format description events from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog.. dumped up to pos 120. ok. /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog has effective binlog events from pos 120. Dumping effective binlog data from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog position 120 to tail(35832).. ok. Concat succeeded. All apply target binary logs are concatinated at /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog . MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.10:3306. This may take long time... Applying log files succeeded. Fri Aug 26 12:04:22 2016 - [info] All relay logs were successfully applied. Fri Aug 26 12:04:22 2016 - [info] Getting new master's binlog name and position.. Fri Aug 26 12:04:22 2016 - [info] mysql-bin.000143:22123166 Fri Aug 26 12:04:22 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000143', MASTER_LOG_POS=22123166, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Fri Aug 26 12:04:22 2016 - [info] Executing master IP activate script: Fri Aug 26 12:04:22 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --new_master_host=192.168.137.10 --new_master_ip=192.168.137.10 --new_master_port=3306 --new_master_user='root' --new_master_password='root' IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Enabling the VIP - 192.168.137.50/24 on the new master - 192.168.137.10 Fri Aug 26 12:04:25 2016 - [info] OK. Fri Aug 26 12:04:25 2016 - [info] ** Finished master recovery successfully. Fri Aug 26 12:04:25 2016 - [info] * Phase 3: Master Recovery Phase completed. Fri Aug 26 12:04:25 2016 - [info] Fri Aug 26 12:04:25 2016 - [info] * Phase 4: Slaves Recovery Phase.. Fri Aug 26 12:04:25 2016 - [info] Fri Aug 26 12:04:25 2016 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase.. Fri Aug 26 12:04:25 2016 - [info] Fri Aug 26 12:04:25 2016 - [info] -- Slave diff file generation on host 192.168.137.30(192.168.137.30:3306) started, pid: 5029. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826115742.log if it takes time.. Fri Aug 26 12:04:26 2016 - [info] Fri Aug 26 12:04:26 2016 - [info] Log messages from 192.168.137.30 ... Fri Aug 26 12:04:26 2016 - [info] Fri Aug 26 12:04:25 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave. Fri Aug 26 12:04:26 2016 - [info] End of log messages from 192.168.137.30. Fri Aug 26 12:04:26 2016 - [info] -- 192.168.137.30(192.168.137.30:3306) has the latest relay log events. Fri Aug 26 12:04:26 2016 - [info] Generating relay diff files from the latest slave succeeded. Fri Aug 26 12:04:26 2016 - [info] Fri Aug 26 12:04:26 2016 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase.. Fri Aug 26 12:04:26 2016 - [info] Fri Aug 26 12:04:26 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) started, pid: 5031. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826115742.log if it takes time.. Fri Aug 26 12:04:32 2016 - [info] Fri Aug 26 12:04:32 2016 - [info] Log messages from 192.168.137.30 ... Fri Aug 26 12:04:32 2016 - [info] Fri Aug 26 12:04:26 2016 - [info] Sending binlog.. Fri Aug 26 12:04:28 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to root@192.168.137.30:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded. Fri Aug 26 12:04:28 2016 - [info] Starting recovery on 192.168.137.30(192.168.137.30:3306).. Fri Aug 26 12:04:28 2016 - [info] Generating diffs succeeded. Fri Aug 26 12:04:28 2016 - [info] Waiting until all relay logs are applied. Fri Aug 26 12:04:28 2016 - [info] done. Fri Aug 26 12:04:28 2016 - [info] Getting slave status.. Fri Aug 26 12:04:28 2016 - [info] This slave(192.168.137.30)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:22461852). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 12:04:28 2016 - [info] Connecting to the target slave host 192.168.137.30, running recover script.. Fri Aug 26 12:04:28 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.30 --slave_ip=192.168.137.30 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 12:04:30 2016 - [info] MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.30:3306. This may take long time... Applying log files succeeded. Fri Aug 26 12:04:30 2016 - [info] All relay logs were successfully applied. Fri Aug 26 12:04:30 2016 - [info] Resetting slave 192.168.137.30(192.168.137.30:3306) and starting replication from the new master 192.168.137.10(192.168.137.10:3306).. Fri Aug 26 12:04:31 2016 - [info] Executed CHANGE MASTER. Fri Aug 26 12:04:31 2016 - [info] Slave started. Fri Aug 26 12:04:32 2016 - [info] End of log messages from 192.168.137.30. Fri Aug 26 12:04:32 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) succeeded. Fri Aug 26 12:04:32 2016 - [info] All new slave servers recovered successfully. Fri Aug 26 12:04:32 2016 - [info] Fri Aug 26 12:04:32 2016 - [info] * Phase 5: New master cleanup phase.. Fri Aug 26 12:04:32 2016 - [info] Fri Aug 26 12:04:32 2016 - [info] Resetting slave info on the new master.. Fri Aug 26 12:04:32 2016 - [info] 192.168.137.10: Resetting slave info succeeded. Fri Aug 26 12:04:32 2016 - [info] Master failover to 192.168.137.10(192.168.137.10:3306) completed successfully. Fri Aug 26 12:04:32 2016 - [info] ----- Failover Report ----- ha1: MySQL Master failover 192.168.137.20 to 192.168.137.10 succeeded Master 192.168.137.20 is down! Check MHA Manager logs at monitor:/usr/local/mha/ha1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 192.168.137.20. The latest slave 192.168.137.30(192.168.137.30:3306) has all relay logs for recovery. Selected 192.168.137.10 as a new master. 192.168.137.10: OK: Applying all logs succeeded. 192.168.137.10: OK: Activated master IP address. 192.168.137.30: This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. 192.168.137.30: OK: Applying all logs succeeded. Slave started, replicating from 192.168.137.10. 192.168.137.10: Resetting slave info succeeded. Master failover to 192.168.137.10(192.168.137.10:3306) completed successfully.
Explanation: Some main processes are marked in red, and five steps in each step are marked in bright color and bold color.
Failover steps are as follows:
1.fail judgment, respectively, to determine the arrival of MySQL (Ping (SELECT) and ssh of dead Master (between which the master ha_secondary_check script will be called) dead master processing stage
2. Configuration file checking, which checks the entire cluster configuration file configuration (to determine dead server, candidate master and all servers, respectively, and whether the configuration meets the requirements)dead master processing stage
3. downtime master processing, including virtual ip removal operation, host shutdown operation (no shutdown operation is configured here)dead master processing stage
/usr/local/mha/ha1/fail_script/master_ip_failover --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --command=stopssh --ssh_user=root
4. Find the slave with the latest relay log (and find the position of the slave with the oldest binlog) and determine whether it is a candidate slave new master reduction stage, respectively.
5. Save the relay log with the difference between dead master(137.20) and the latest slave(137.30) in the / tmp directory of dead master (remote_workdir configured according to the configuration file), and then determine whether this part of the difference binlog (saved_master_binlog_) is valid, that is, whether there is a binlog difference between dead master and the latest slave, and whether there is a binlog difference between dead master and the latest slave. The difference copies the generated binlog to the workdir(137.40) of mha the new master reduction stage.
Fri Aug 26 11:57:46 2016 - [info] Executing command on the dead master 192.168.137.20(192.168.137.20:3306): save_binary_logs --command=save --start_file=mysql-bin.000074 --start_pos=22461852 --binlog_dir=/mysql/log --output_file=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 Creating /tmp if not exists.. ok. Concat binary/relay logs from mysql-bin.000074 pos 22461852 to mysql-bin.000074 EOF into /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog .. Dumping binlog format description event, from position 0 to 120.. ok. Dumping effective binlog data from /mysql/log/mysql-bin.000074 position 22461852 to tail(22497564).. ok. Concat succeeded. Fri Aug 26 11:57:49 2016 - [info] scp from root@192.168.137.20:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded.
7. Identify the new master and check whether the relay log of the latest slave(30) can be used to restore other slave new master restore stages
8. Generate the difference between the latest slave(137.30) and the new master(137.10) relay log (binlog generated under the slave / tmp of the latest relay log and other slave differences is the difference between the two "Read_Master_Log_Pos", named "relay_from_read_to_latest_followed by the IP of the target slave"), and then cp to the target (new mas_read_to_latest_ip). At the same time, copy the "saved_master_binlog_" (if it exists) file just saved under mha workdir to the new master's / tmp new master's restoring stage.
Fri Aug 26 11:57:56 2016 - [info] Connecting to the latest slave host 192.168.137.30, generating diff relay log files.. Fri Aug 26 11:57:56 2016 - [info] Executing command: apply_diff_relay_logs --command=generate_and_send --scp_user=root --scp_host=192.168.137.10 --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --diff_file_readtolatest=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog --workdir=/tmp --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ Fri Aug 26 11:58:02 2016 - [info] Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000003 Fast relay log position search succeeded. Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539. Concat binary/relay logs from mysql-relay-bin.000003 pos 9857539 to mysql-relay-bin.000003 EOF into /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog .. Dumping binlog format description event, from position 0 to 283.. ok. Dumping effective binlog data from /mysql/data/mysql-relay-bin.000003 position 9857539 to tail(22462015).. ok. Concat succeeded. Generating diff relay log succeeded. Saved at /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog . scp slave:/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to root@192.168.137.10(22) succeeded.
9.new master applies different relay logs (first of all, it will determine whether the original Read_Master_Log_Pos and Exec_Master_Log_Pos are equal. Because it is not a semi-synchronous replication, slave reads the pos, but because the replication is asynchronous, all of them have to wait for master to send binlog to slave regularly if the master is in the middle. Failure will lead to inconsistency between the two. If not, the relay log of the difference between the slave executing save_binary_logs will be named "relay_from_exec_to_read_followed by its own ip"; and then the three "relay_from_read_to_latest_, saved_master_binlog_, relay_from_exec_to_read_" will be applied. The relay log of the difference, and the contents of the three files are combined to form a new binlog file "total_binlog_for_" new master restore phase
Fri Aug 26 12:00:06 2016 - [info] This slave(192.168.137.10)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:9857376). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 12:00:06 2016 - [info] Connecting to the target slave host 192.168.137.10, running recover script.. Fri Aug 26 12:00:06 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.10 --slave_ip=192.168.137.10 --slave_port=3306 --apply_files=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 12:04:22 2016 - [info] Concat all apply files to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog .. Copying the first binlog file /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog.. ok. Dumping binlog head events (rotate events), skipping format description events from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog.. dumped up to pos 120. ok. /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog has effective binlog events from pos 120. Dumping effective binlog data from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog position 120 to tail(35832).. ok. Concat succeeded. All apply target binary logs are concatinated at /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog . MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.10:3306. This may take long time... Applying log files succeeded. Fri Aug 26 12:04:22 2016 - [info] All relay logs were successfully applied.
10. Generate other change statements from slave to new master, execute master_ip_failover to complete switching to generate VIP_new master restore phase
11. Other slaves also repeat the steps of the new masters slave (from steps 8-9, for example, here we will copy saved_master_binlog_from mha's workdir to apply different relay log on the latest slave (137.30)other slave reduction stage.
12. other slave change new master other slave reduction stage
13. Generate failover report
Note: The relay log here refers to the location of master binglog read by slave (that is, the location of the latest master binlog has been saved in the relay log file in slave) in show slave status G, that is, "Read_Master_Log_Pos" is not "Exec_Master_Log_Pos", so the salve of the latest relay log is not. The data must be up-to-date (but this situation is relatively rare), which only means that the master binlog it saves is up-to-date.
mha first fixes the new master (whether it's the latest slave or not, so if the candidate slave is the latest slave then naturally the best candidate slave will be fixed soon), and then fixes the other slaves.
2. Offline manual Failover
Note: The precondition is that mha does not start and there is a master of dead. MHA manager detects a server without dead, will report an error and end failover.
Manual failover, this scenario means that the MHA automatic handover function is not enabled in business. When the primary server fails, the MHA is manually invoked to perform the failover operation. The specific commands are as follows:
Statements are as follows:
masterha_master_switch --master_state=dead --conf=/usr/local/mha/ha1/ha1.cnf --dead_master_host=192.168.137.10 --dead_master_port=3306 --new_master_host=192.168.137.20 --new_master_port=3306 --ignore_fail_on_start --ignore_last_failover
There are several times in the process of switching that you need to enter "yes" for the next step.
[root@monitor ha1]# masterha_master_switch --master_state=dead --conf=/usr/local/mha/ha1/ha1.cnf --dead_master_host=192.168.137.10 --dead_master_port=3306 --new_master_host=192.168.137.20 --new_master_port=3306 --ignore_fail_on_start --ignore_last_failover --dead_master_ip=<dead_master_ip> is not set. Using 192.168.137.10. Fri Aug 26 17:44:10 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Aug 26 17:44:10 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 17:44:10 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 17:44:10 2016 - [info] MHA::MasterFailover version 0.55. Fri Aug 26 17:44:10 2016 - [info] Starting master failover. Fri Aug 26 17:44:10 2016 - [info] Fri Aug 26 17:44:10 2016 - [info] * Phase 1: Configuration Check Phase.. Fri Aug 26 17:44:10 2016 - [info] Fri Aug 26 17:44:11 2016 - [info] Dead Servers: Fri Aug 26 17:44:11 2016 - [info] 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:11 2016 - [info] Checking master reachability via mysql(double check).. Fri Aug 26 17:44:11 2016 - [info] ok. Fri Aug 26 17:44:11 2016 - [info] Alive Servers: Fri Aug 26 17:44:11 2016 - [info] 192.168.137.20(192.168.137.20:3306) Fri Aug 26 17:44:11 2016 - [info] 192.168.137.30(192.168.137.30:3306) Fri Aug 26 17:44:11 2016 - [info] Alive Slaves: Fri Aug 26 17:44:11 2016 - [info] 192.168.137.20(192.168.137.20:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:11 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:11 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 17:44:11 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:11 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:11 2016 - [info] Not candidate for the new Master (no_master is set) Master 192.168.137.10 is dead. Proceed? (yes/NO): yes Fri Aug 26 17:44:18 2016 - [info] ** Phase 1: Configuration Check Phase completed. Fri Aug 26 17:44:18 2016 - [info] Fri Aug 26 17:44:18 2016 - [info] * Phase 2: Dead Master Shutdown Phase.. Fri Aug 26 17:44:18 2016 - [info] Fri Aug 26 17:44:20 2016 - [info] HealthCheck: SSH to 192.168.137.10 is reachable. Fri Aug 26 17:44:22 2016 - [info] Forcing shutdown so that applications never connect to the current master.. Fri Aug 26 17:44:22 2016 - [info] Executing master IP deactivatation script: Fri Aug 26 17:44:22 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 --command=stopssh --ssh_user=root IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Disabling the VIP on old master: 192.168.137.10 Fri Aug 26 17:44:23 2016 - [info] done. Fri Aug 26 17:44:23 2016 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Fri Aug 26 17:44:23 2016 - [info] * Phase 2: Dead Master Shutdown Phase completed. Fri Aug 26 17:44:23 2016 - [info] Fri Aug 26 17:44:23 2016 - [info] * Phase 3: Master Recovery Phase.. Fri Aug 26 17:44:23 2016 - [info] Fri Aug 26 17:44:23 2016 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Fri Aug 26 17:44:23 2016 - [info] Fri Aug 26 17:44:23 2016 - [info] The latest binary log file/position on all slaves is mysql-bin.000144:120 Fri Aug 26 17:44:23 2016 - [info] Latest slaves (Slaves that received relay log files to the latest): Fri Aug 26 17:44:23 2016 - [info] 192.168.137.20(192.168.137.20:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:23 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:23 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 17:44:23 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:23 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:23 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 17:44:23 2016 - [info] The oldest binary log file/position on all slaves is mysql-bin.000144:120 Fri Aug 26 17:44:23 2016 - [info] Oldest slaves: Fri Aug 26 17:44:23 2016 - [info] 192.168.137.20(192.168.137.20:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:23 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:23 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 17:44:23 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 17:44:23 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Fri Aug 26 17:44:23 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 17:44:23 2016 - [info] Fri Aug 26 17:44:23 2016 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase.. Fri Aug 26 17:44:23 2016 - [info] Fri Aug 26 17:44:24 2016 - [info] Fetching dead master's binary logs.. Fri Aug 26 17:44:24 2016 - [info] Executing command on the dead master 192.168.137.10(192.168.137.10:3306): save_binary_logs --command=save --start_file=mysql-bin.000144 --start_pos=120 --binlog_dir=/mysql/log --output_file=/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 Creating /tmp if not exists.. ok. Concat binary/relay logs from mysql-bin.000144 pos 120 to mysql-bin.000144 EOF into /tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog .. Dumping binlog format description event, from position 0 to 120.. ok. Dumping effective binlog data from /mysql/log/mysql-bin.000144 position 120 to tail(143).. ok. Concat succeeded. saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog 100% 143 0.1KB/s 00:00 Fri Aug 26 17:44:27 2016 - [info] scp from root@192.168.137.10:/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog to local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog succeeded. Fri Aug 26 17:44:29 2016 - [info] HealthCheck: SSH to 192.168.137.20 is reachable. Fri Aug 26 17:44:31 2016 - [info] HealthCheck: SSH to 192.168.137.30 is reachable. Fri Aug 26 17:44:31 2016 - [info] Fri Aug 26 17:44:31 2016 - [info] * Phase 3.3: Determining New Master Phase.. Fri Aug 26 17:44:31 2016 - [info] Fri Aug 26 17:44:31 2016 - [info] Finding the latest slave that has all relay logs for recovering other slaves.. Fri Aug 26 17:44:31 2016 - [info] All slaves received relay logs to the same position. No need to resync each other. Fri Aug 26 17:44:31 2016 - [info] 192.168.137.20 can be new master. Fri Aug 26 17:44:31 2016 - [info] New master is 192.168.137.20(192.168.137.20:3306) Fri Aug 26 17:44:31 2016 - [info] Starting master failover.. Fri Aug 26 17:44:31 2016 - [info] From: 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 To: 192.168.137.20 (new master) +--192.168.137.30 Starting master switch from 192.168.137.10(192.168.137.10:3306) to 192.168.137.20(192.168.137.20:3306)? (yes/NO): yes Fri Aug 26 17:44:40 2016 - [info] New master decided manually is 192.168.137.20(192.168.137.20:3306) Fri Aug 26 17:44:40 2016 - [info] Fri Aug 26 17:44:40 2016 - [info] * Phase 3.3: New Master Diff Log Generation Phase.. Fri Aug 26 17:44:40 2016 - [info] Fri Aug 26 17:44:40 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave. Fri Aug 26 17:44:40 2016 - [info] Sending binlog.. saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog 100% 143 0.1KB/s 00:00 Fri Aug 26 17:44:42 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog to root@192.168.137.20:/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog succeeded. Fri Aug 26 17:44:42 2016 - [info] Fri Aug 26 17:44:42 2016 - [info] * Phase 3.4: Master Log Apply Phase.. Fri Aug 26 17:44:42 2016 - [info] Fri Aug 26 17:44:42 2016 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed. Fri Aug 26 17:44:42 2016 - [info] Starting recovery on 192.168.137.20(192.168.137.20:3306).. Fri Aug 26 17:44:42 2016 - [info] Generating diffs succeeded. Fri Aug 26 17:44:42 2016 - [info] Waiting until all relay logs are applied. Fri Aug 26 17:44:42 2016 - [info] done. Fri Aug 26 17:44:42 2016 - [info] Getting slave status.. Fri Aug 26 17:44:42 2016 - [info] This slave(192.168.137.20)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000144:120). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 17:44:42 2016 - [info] Connecting to the target slave host 192.168.137.20, running recover script.. Fri Aug 26 17:44:42 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.20 --slave_ip=192.168.137.20 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826174410 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 17:44:43 2016 - [info] MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog on 192.168.137.20:3306. This may take long time... Applying log files succeeded. Fri Aug 26 17:44:43 2016 - [info] All relay logs were successfully applied. Fri Aug 26 17:44:43 2016 - [info] Getting new master's binlog name and position.. Fri Aug 26 17:44:43 2016 - [info] mysql-bin.000075:120 Fri Aug 26 17:44:43 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.20', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000075', MASTER_LOG_POS=120, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Fri Aug 26 17:44:43 2016 - [info] Executing master IP activate script: Fri Aug 26 17:44:43 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 --new_master_host=192.168.137.20 --new_master_ip=192.168.137.20 --new_master_port=3306 --new_master_user='root' --new_master_password='root' IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Enabling the VIP - 192.168.137.50/24 on the new master - 192.168.137.20 Fri Aug 26 17:44:44 2016 - [info] OK. Fri Aug 26 17:44:44 2016 - [info] ** Finished master recovery successfully. Fri Aug 26 17:44:44 2016 - [info] * Phase 3: Master Recovery Phase completed. Fri Aug 26 17:44:44 2016 - [info] Fri Aug 26 17:44:44 2016 - [info] * Phase 4: Slaves Recovery Phase.. Fri Aug 26 17:44:44 2016 - [info] Fri Aug 26 17:44:44 2016 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase.. Fri Aug 26 17:44:44 2016 - [info] Fri Aug 26 17:44:44 2016 - [info] -- Slave diff file generation on host 192.168.137.30(192.168.137.30:3306) started, pid: 5354. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826174410.log if it takes time.. Fri Aug 26 17:44:45 2016 - [info] Fri Aug 26 17:44:45 2016 - [info] Log messages from 192.168.137.30 ... Fri Aug 26 17:44:45 2016 - [info] Fri Aug 26 17:44:44 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave. Fri Aug 26 17:44:45 2016 - [info] End of log messages from 192.168.137.30. Fri Aug 26 17:44:45 2016 - [info] -- 192.168.137.30(192.168.137.30:3306) has the latest relay log events. Fri Aug 26 17:44:45 2016 - [info] Generating relay diff files from the latest slave succeeded. Fri Aug 26 17:44:45 2016 - [info] Fri Aug 26 17:44:45 2016 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase.. Fri Aug 26 17:44:45 2016 - [info] Fri Aug 26 17:44:45 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) started, pid: 5356. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826174410.log if it takes time.. saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog 100% 143 0.1KB/s 00:00 Fri Aug 26 17:44:47 2016 - [info] Fri Aug 26 17:44:47 2016 - [info] Log messages from 192.168.137.30 ... Fri Aug 26 17:44:47 2016 - [info] Fri Aug 26 17:44:45 2016 - [info] Sending binlog.. Fri Aug 26 17:44:45 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog to root@192.168.137.30:/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog succeeded. Fri Aug 26 17:44:45 2016 - [info] Starting recovery on 192.168.137.30(192.168.137.30:3306).. Fri Aug 26 17:44:45 2016 - [info] Generating diffs succeeded. Fri Aug 26 17:44:45 2016 - [info] Waiting until all relay logs are applied. Fri Aug 26 17:44:45 2016 - [info] done. Fri Aug 26 17:44:45 2016 - [info] Getting slave status.. Fri Aug 26 17:44:45 2016 - [info] This slave(192.168.137.30)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000144:120). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 17:44:45 2016 - [info] Connecting to the target slave host 192.168.137.30, running recover script.. Fri Aug 26 17:44:45 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.30 --slave_ip=192.168.137.30 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826174410 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 17:44:45 2016 - [info] MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/saved_master_binlog_from_192.168.137.10_3306_20160826174410.binlog on 192.168.137.30:3306. This may take long time... Applying log files succeeded. Fri Aug 26 17:44:45 2016 - [info] All relay logs were successfully applied. Fri Aug 26 17:44:45 2016 - [info] Resetting slave 192.168.137.30(192.168.137.30:3306) and starting replication from the new master 192.168.137.20(192.168.137.20:3306).. Fri Aug 26 17:44:46 2016 - [info] Executed CHANGE MASTER. Fri Aug 26 17:44:46 2016 - [info] Slave started. Fri Aug 26 17:44:47 2016 - [info] End of log messages from 192.168.137.30. Fri Aug 26 17:44:47 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) succeeded. Fri Aug 26 17:44:47 2016 - [info] All new slave servers recovered successfully. Fri Aug 26 17:44:47 2016 - [info] Fri Aug 26 17:44:47 2016 - [info] * Phase 5: New master cleanup phase.. Fri Aug 26 17:44:47 2016 - [info] Fri Aug 26 17:44:47 2016 - [info] Resetting slave info on the new master.. Fri Aug 26 17:44:47 2016 - [info] 192.168.137.20: Resetting slave info succeeded. Fri Aug 26 17:44:47 2016 - [info] Master failover to 192.168.137.20(192.168.137.20:3306) completed successfully. Fri Aug 26 17:44:47 2016 - [info] ----- Failover Report ----- ha1: MySQL Master failover 192.168.137.10 to 192.168.137.20 succeeded Master 192.168.137.10 is down! Check MHA Manager logs at monitor for details. Started manual(interactive) failover. Invalidated master IP address on 192.168.137.10. The latest slave 192.168.137.20(192.168.137.20:3306) has all relay logs for recovery. Selected 192.168.137.20 as a new master. 192.168.137.20: OK: Applying all logs succeeded. 192.168.137.20: OK: Activated master IP address. 192.168.137.30: This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. 192.168.137.30: OK: Applying all logs succeeded. Slave started, replicating from 192.168.137.20. 192.168.137.20: Resetting slave info succeeded. Master failover to 192.168.137.20(192.168.137.20:3306) completed successfully.
3. Online Manual Failover
In many cases, an existing primary server needs to be migrated to another server. For example, the main server hardware failure, the RAID control card needs to be rebuilt, the main server will be moved to a better performance server, and so on. Maintenance of the primary server results in performance degradation, resulting in downtime at least not being able to write data. In addition, blocking or killing the currently running session can lead to data inconsistency between hosts. MHA provides fast switching and elegant blocking writing. This switching process only takes 0.5-2 seconds, during which data cannot be written. In many cases, blocking writes of 0.5-2s are acceptable. Therefore, switching primary servers does not require scheduling maintenance time windows.
The general process of MHA online switching:
1. Detecting replication settings and determining the current primary server
2. Identify a new primary server
3. Blocking Writing to the Current Main Server
4. Wait for all slave servers to catch up with replication
5. Grant write to the new primary server
6. Reset the slave server
Note that the application architecture needs to consider the following two issues when switching online:
1. Automatic identification of master and slave (master machine may switch), if the vip approach is adopted, this problem can be basically solved.
2. Load balancing (you can define the approximate read-write ratio, the load ratio that each machine can bear, which needs to be considered when the machine leaves the cluster)
In order to ensure complete data consistency and complete switching in the fastest time, the online switching of MHA must satisfy the following conditions before switching is successful, otherwise the switching will fail.
1. All slave IO threads are running
2. All slave SQL threads are running
3. The Seconds_Behind_Master parameter in the output of all show slave status is less than or equal to running_updates_limit seconds. If running_updates_limit is not specified in the switching process, then running_updates_limit is 1 second by default.
4. On the old master side, no update takes longer than running_updates_limit seconds through show process list output.
1. First, stop MHA monitoring:
masterha_stop --conf=/usr/local/mha/ha1/ha1.cnf
2. Manual online failover
The new master is 192.168.137.10
masterha_master_switch --conf=/usr/local/mha/ha1/ha1.cnf --master_state=alive --new_master_host=192.168.137.10 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
When orig_master_is_new_slave is switched, this parameter is added to change the original master into a slave node. If this parameter is not added, the original master will not start.
- running_updates_limit=10000. In case of failure handover, mha handover cannot succeed if the candidate master has a delay. Additionally, this parameter indicates that the delay can be switched within this time range (in s), but the length of the handover is determined by the size of the relay log on recover y.
Note: The failover script for manual online use is "master_ip_online_change"
3. Switching logs
[root@monitor fail_script]# masterha_master_switch --conf=/usr/local/mha/ha1/ha1.cnf --master_state=alive --new_master_host=192.168.137.10 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 Mon Aug 29 10:41:37 2016 - [info] MHA::MasterRotate version 0.55. Mon Aug 29 10:41:37 2016 - [info] Starting online master switch.. Mon Aug 29 10:41:37 2016 - [info] Mon Aug 29 10:41:37 2016 - [info] * Phase 1: Configuration Check Phase.. Mon Aug 29 10:41:37 2016 - [info] Mon Aug 29 10:41:37 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Aug 29 10:41:37 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Mon Aug 29 10:41:37 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Mon Aug 29 10:41:38 2016 - [info] Current Alive Master: 192.168.137.20(192.168.137.20:3306) Mon Aug 29 10:41:38 2016 - [info] Alive Slaves: Mon Aug 29 10:41:38 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Mon Aug 29 10:41:38 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Mon Aug 29 10:41:38 2016 - [info] Primary candidate for the new Master (candidate_master is set) Mon Aug 29 10:41:38 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Mon Aug 29 10:41:38 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Mon Aug 29 10:41:38 2016 - [info] Not candidate for the new Master (no_master is set) It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.137.20(192.168.137.20:3306)? (YES/no): yes Mon Aug 29 10:41:40 2016 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. Mon Aug 29 10:41:40 2016 - [info] ok. Mon Aug 29 10:41:40 2016 - [info] Checking MHA is not monitoring or doing failover.. Mon Aug 29 10:41:40 2016 - [info] Checking replication health on 192.168.137.10.. Mon Aug 29 10:41:40 2016 - [info] ok. Mon Aug 29 10:41:40 2016 - [info] Checking replication health on 192.168.137.30.. Mon Aug 29 10:41:40 2016 - [info] ok. Mon Aug 29 10:41:40 2016 - [info] 192.168.137.10 can be new master. Mon Aug 29 10:41:40 2016 - [info] From: 192.168.137.20 (current master) +--192.168.137.10 +--192.168.137.30 To: 192.168.137.10 (new master) +--192.168.137.30 +--192.168.137.20 Starting master switch from 192.168.137.20(192.168.137.20:3306) to 192.168.137.10(192.168.137.10:3306)? (yes/NO): yes Mon Aug 29 10:41:42 2016 - [info] Checking whether 192.168.137.10(192.168.137.10:3306) is ok for the new master.. Mon Aug 29 10:41:42 2016 - [info] ok. Mon Aug 29 10:41:42 2016 - [info] 192.168.137.20(192.168.137.20:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host. Mon Aug 29 10:41:42 2016 - [info] 192.168.137.20(192.168.137.20:3306): Resetting slave pointing to the dummy host. Mon Aug 29 10:41:42 2016 - [info] ** Phase 1: Configuration Check Phase completed. Mon Aug 29 10:41:42 2016 - [info] Mon Aug 29 10:41:42 2016 - [info] * Phase 2: Rejecting updates Phase.. Mon Aug 29 10:41:42 2016 - [info] Mon Aug 29 10:41:42 2016 - [info] Executing master ip online change script to disable write on the current master: Mon Aug 29 10:41:42 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_online_change --command=stop --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --orig_master_user='root' --orig_master_password='root' --new_master_host=192.168.137.10 --new_master_ip=192.168.137.10 --new_master_port=3306 --new_master_user='root' --new_master_password='root' *************************************************************** Disabling the VIP - 192.168.137.50/24 on old master: 192.168.137.20 *************************************************************** Mon Aug 29 10:41:43 2016 - [info] ok. Mon Aug 29 10:41:43 2016 - [info] Locking all tables on the orig master to reject updates from everybody (including root): Mon Aug 29 10:41:43 2016 - [info] Executing FLUSH TABLES WITH READ LOCK.. Mon Aug 29 10:41:43 2016 - [info] ok. Mon Aug 29 10:41:43 2016 - [info] Orig master binlog:pos is mysql-bin.000076:120. Mon Aug 29 10:41:43 2016 - [info] Waiting to execute all relay logs on 192.168.137.10(192.168.137.10:3306).. Mon Aug 29 10:41:43 2016 - [info] master_pos_wait(mysql-bin.000076:120) completed on 192.168.137.10(192.168.137.10:3306). Executed 0 events. Mon Aug 29 10:41:43 2016 - [info] done. Mon Aug 29 10:41:43 2016 - [info] Getting new master's binlog name and position.. Mon Aug 29 10:41:43 2016 - [info] mysql-bin.000147:120 Mon Aug 29 10:41:43 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000147', MASTER_LOG_POS=120, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Mon Aug 29 10:41:43 2016 - [info] Executing master ip online change script to allow write on the new master: Mon Aug 29 10:41:43 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_online_change --command=start --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --orig_master_user='root' --orig_master_password='root' --new_master_host=192.168.137.10 --new_master_ip=192.168.137.10 --new_master_port=3306 --new_master_user='root' --new_master_password='root' *************************************************************** Enabling the VIP - 192.168.137.50/24 on new master: 192.168.137.10 *************************************************************** Mon Aug 29 10:41:44 2016 - [info] ok. Mon Aug 29 10:41:44 2016 - [info] Mon Aug 29 10:41:44 2016 - [info] * Switching slaves in parallel.. Mon Aug 29 10:41:44 2016 - [info] Mon Aug 29 10:41:44 2016 - [info] -- Slave switch on host 192.168.137.30(192.168.137.30:3306) started, pid: 4371 Mon Aug 29 10:41:44 2016 - [info] Mon Aug 29 10:41:45 2016 - [info] Log messages from 192.168.137.30 ... Mon Aug 29 10:41:45 2016 - [info] Mon Aug 29 10:41:44 2016 - [info] Waiting to execute all relay logs on 192.168.137.30(192.168.137.30:3306).. Mon Aug 29 10:41:44 2016 - [info] master_pos_wait(mysql-bin.000076:120) completed on 192.168.137.30(192.168.137.30:3306). Executed 0 events. Mon Aug 29 10:41:44 2016 - [info] done. Mon Aug 29 10:41:44 2016 - [info] Resetting slave 192.168.137.30(192.168.137.30:3306) and starting replication from the new master 192.168.137.10(192.168.137.10:3306).. Mon Aug 29 10:41:44 2016 - [info] Executed CHANGE MASTER. Mon Aug 29 10:41:44 2016 - [info] Slave started. Mon Aug 29 10:41:45 2016 - [info] End of log messages from 192.168.137.30 ... Mon Aug 29 10:41:45 2016 - [info] Mon Aug 29 10:41:45 2016 - [info] -- Slave switch on host 192.168.137.30(192.168.137.30:3306) succeeded. Mon Aug 29 10:41:45 2016 - [info] Unlocking all tables on the orig master: Mon Aug 29 10:41:45 2016 - [info] Executing UNLOCK TABLES.. Mon Aug 29 10:41:45 2016 - [info] ok. Mon Aug 29 10:41:45 2016 - [info] Starting orig master as a new slave.. Mon Aug 29 10:41:45 2016 - [info] Resetting slave 192.168.137.20(192.168.137.20:3306) and starting replication from the new master 192.168.137.10(192.168.137.10:3306).. Mon Aug 29 10:41:45 2016 - [info] Executed CHANGE MASTER. Mon Aug 29 10:41:45 2016 - [info] Slave started. Mon Aug 29 10:41:45 2016 - [info] All new slave servers switched successfully. Mon Aug 29 10:41:45 2016 - [info] Mon Aug 29 10:41:45 2016 - [info] * Phase 5: New master cleanup phase.. Mon Aug 29 10:41:45 2016 - [info] Mon Aug 29 10:41:45 2016 - [info] 192.168.137.10: Resetting slave info succeeded. Mon Aug 29 10:41:45 2016 - [info] Switching master to 192.168.137.10(192.168.137.10:3306) completed successfully.
Switchover failed:
[error][/usr/local/share/perl5/MHA/MasterRotate.pm, ln262] We should not start online master switch when one of connections are running long queries on the new master(192.168.137.10(192.168.137.10:3306)). Currently 1 thread(s) are running. Details: {'Time' => '1173','Command' => 'Daemon','db' => undef,'Id' => '3','Info' => undef,'User' => 'event_scheduler','State' => 'Waiting on empty queue','Host' => 'localhost'}
From what the error message has said is very clear, there is a long queries in the new master, and the id=3 of the thread is an event scheduling thread. Because the new master I opened the "scheduler" and caused the online manual handover failure, I closed the "scheduler" successfully.
The alternative Master in the MHA environment cannot turn on "scheduler"
Reference resources:
http://www.cnblogs.com/gomysql/p/3675429.html
http://blog.csdn.net/lichangzai/article/details/50470771
mha download address:
https://mysql-master-ha.googlecode.com/files/mha4mysql-manager-0.55.tar.gz
https://mysql-master-ha.googlecode.com/files/mha4mysql-node-0.54.tar.gz
Previous copying articles:
Master-slave replication: http://www.cnblogs.com/chenmh/p/5089919.html
Master master replication: http://www.cnblogs.com/chenmh/p/5153184.html
MMM scheme: http://www.cnblogs.com/chenmh/p/5563778.html
Semi-synchronous replication and MMM: http://www.cnblogs.com/chenmh/p/5744227.html
summary
Semi-synchronous replication is needed between master and standby to ensure that the maximum data of MHA is not lost, otherwise there will be no advantage in using MHA; there is also no scheduler for master and standby, otherwise manual online failover will fail. MHA first fixes the new master (whether it's the latest slave or not, so if the candidate slave is the latest slave then naturally the best candidate slave will be fixed soon), and then fixes the other slaves.
Note: Some configuration notes are provided in this article, which need to be deleted in actual deployment.
|
Remarks: Author: pursuer.chen Blog: http://www.cnblogs.com/chenmh All essays on this site are original, and you are welcome to reproduce them; however, when reproducing, you must specify the source of the article, and give clear links at the beginning of the article. Welcome to Exchange and Discussion |