MySql logical architecture
It is mainly divided into: connection layer, service layer, engine layer and storage layer.
The process of the client executing a select command is as follows:
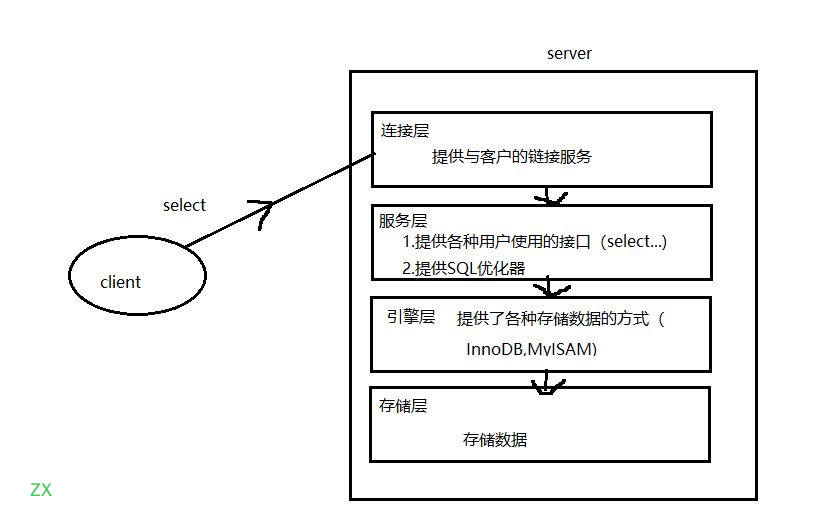
- Connection layer: the top layer is some clients and connection services, including local sock communication and most communication similar to tcplip based on client / server tools. It mainly completes some security schemes similar to connection processing, authorization and authentication, and related security schemes. On this layer, the concept of thread pool is introduced to provide threads for clients who access safely through authentication. SSL based secure links can also be implemented on this layer. The server will also verify its operation permissions for each client with secure access.
- Service layer: the second layer architecture mainly completes many core service functions, such as SQL interface, cache query, SQL analysis and optimization, and the execution of some built-in functions. All functions across storage engines are also implemented in this layer, such as procedures, functions, etc. In this layer, the server will parse the query and create the corresponding internal parsing tree, and complete the corresponding optimization, such as determining whether the order of the query table uses the index, and finally generate the corresponding execution operations. If it is a select statement, the server will also query the internal cache. If the cache space is large enough, it can improve the performance of the system in the environment of solving a large number of read operations.
- Engine layer: storage engine layer. The storage engine is really responsible for the storage and extraction of data in MySQL. The server communicates with the storage engine through API. Different storage engines have different functions, so we can select them according to our actual needs. Later, we will introduce MyISAM and InnoDB.
- Storage layer: the data storage layer mainly stores the data on the file system running on the bare device and completes the interaction with the storage engine.
The more important one is the storage engine. The default storage engine used by MySql is InnoDB. You can use relevant commands to view it:
show engines;
If you view the storage engine currently in use, you can use the following command:
show variables like '%storage_engine%';
When creating a database, you can specify the storage engine:
CREATE TABLE tbl_emp ( id INT(11) NOT NULL AUTO_INCREMENT, NAME VARCHAR(20) DEFAULT NULL, deptId INT(11) DEFAULT NULL, PRIMARY KEY (id) )ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
MySQL SQL optimization
Reference article:
- https://www.hollischuang.com/archives/6330
- https://dev.mysql.com/doc/refman/8.0/en/using-explain.html
Why SQL optimization?
- Poor SQL statements and long execution time;
- Index failure;
To perform SQL optimization, first understand the difference between SQL writing process and SQL execution process:
- SQL writing process:
select distinct .. from .. join .. on .. where .. group by .. having .. order by .. limit ..
- SQL execution process:
from .. on .. join .. where .. group by .. having .. select distinct .. order by .. limit ..
The reason why the SQL writing process is different from the execution process is that Mysql has an optimizer module specifically responsible for optimizing the SELECT statement.
MySQL Query Optimizer: MySQL Query Optimizer. Its main function is to provide the best execution plan for the Query requested by the client by calculating and analyzing the statistical information collected in the system.
When the client requests a Query from mysql, the command parser module completes the request classification, distinguishes it from SELECT and forwards it to MySQL Query Optimizer, MySQL Query Optimizer will first optimize the whole Query, dispose of some constant expressions and directly convert the budget into constant values.
And simplify and transform the Query conditions in Query, such as removing some useless or obvious conditions, structural adjustment, etc. Then analyze the Hint information (if any) in the Query to see whether the Hint information can completely determine the execution plan of the Query. If there is no Hint or the Hint information is not enough to completely determine the execution plan, the statistical information of the involved objects will be read, the corresponding calculation and analysis will be written according to the Query, and then the final execution plan will be obtained.
Hint: in short, it is to manually assist the MySQL optimizer to generate the optimal execution plan in some specific scenarios. Generally speaking, the execution plan of the optimizer is optimized, but in some specific scenarios, the execution plan may not be optimized.
How to optimize SQL:
- Maximize the use of indexes;
- Avoid full table scanning as far as possible;
- Reduce the query of invalid data;
For back-end programmers, the most important thing is to optimize the index.
Indexes
MySQL's official definition of Index is: Index is a data structure that helps MySQL obtain data efficiently. You can get the essence of Index: Index is a data structure. It is equivalent to a directory or dictionary of a book.
For example, to find the word "mysql", we must locate the letter m, then find the letter y from the bottom, and then find the rest of the sql; if there is no index, you may need to find it one by one. You can simply understand that the index maintains a set of ordered data.
Unless otherwise specified, the indexes we usually refer to refer to the indexes organized by the B-tree structure. Of course, in addition to the B + tree type indexes, there are hash indexes, etc.
Conclusion: index, this data structure is to exchange space for time.
Advantages and disadvantages of indexing
Advantages of indexing:
- Improve the efficiency of data retrieval and reduce the IO cost of database;
- Reduce the cost of data sorting and reduce the consumption of CPU;
Disadvantages of indexing:
- The index itself is large and can be placed in memory and hard disk, usually hard disk;
- The index is not applicable to all cases, so it should be considered when establishing:
- If the amount of data is very small, it is not suitable for establishment;
- Frequently updated fields are not suitable for creation;
- Rarely used fields are not suitable for creation;
- If a field contains many duplicate data, it is not suitable for creation;
- Although the index improves the efficiency of query, it will reduce the efficiency of addition, deletion and modification;
Index classification and operation
- Single value index: that is, an index contains only a single column, and a table can have multiple single column indexes;
- Unique index: the value of the index column must be unique, but null values are allowed;
- Composite index: an index contains multiple columns;
- Primary key index: a unique index, but the value cannot be null;
Create index:
CREATE [UNIQUE] INDEX indexName ON mytable(columnName(length)); ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnName(length));
Delete index:
DROP INDEX [indexName] ON [tableName];
Modify index:
-- This statement adds a primary key, which means that the index value must be unique and cannot be null NULL ALTER TABLE [tableName] ADD PRIMARY KEY (column_list); -- The value of the index created by this statement must be unique(except NULL Outside, NULL May occur multiple times) ALTER TABLE [tableName] ADD UNIQUE [indexName] (column_list); -- Add a normal index, and the index value can appear multiple times ALTER TABLE [tableName] ADD INDEX [indexName] (column_list); -- The statement specifies that the index is FULLTEXT,For full-text indexing ALTER TABLE [tableName] ADD FULLTEXT [indexName] (column_list);
View index:
SHOW INDEX FROM [tableName];
Indexing principles
- Don't build too many indexes: maintaining indexes requires space and performance. MySQL will maintain a B-tree for each index. If there are too many indexes, it will undoubtedly increase the burden on MySQL;
- Do not create an index for frequently added, deleted and modified fields: if a field is frequently modified, it means that the index also needs to be modified, which will inevitably affect the performance of MySQL;
- Index the frequently queried fields: index the fields that are often used as query criteria, which can improve the query efficiency of SQL; On the contrary, do not index fields that are rarely used;
- Avoid indexing "large fields": try to use fields with small field length as indexes; For example, to index the fields of varchar(5) and varchar(200), priority should be given to the creation of varchar(5); If you do not want to index the fields of varchar(200), you can do this:
-- by varchar(200)Index the field of and set its length to 20 create index tbl_001 on dual(address(20));
- Select columns with large data differentiation for indexing: if a field contains many duplicate data, it is not suitable for indexing. Suppose there is a "gender" field in which the data values are either male or female. Such a field is not suitable for indexing. Because if the probability of value occurrence is almost equal, no matter which value is searched, half of the data may be obtained. In these cases, it's better not to index, because MySQL also has a query optimizer. When the query optimizer finds that the percentage of a value in the data row of the table is very high, it generally ignores the index and scans the whole table.
The customary percentage boundary is "30%". (when the amount of matched data exceeds a certain limit, the query will give up using the index (this is also one of the scenarios of index invalidation).
Implementation plan
Use the explain keyword to simulate the optimizer to execute SQL query statements, so as to know how MySQL handles your SQL statements. Analyze the performance bottlenecks of your query statements or table structures.
EXPLAIN applies to SELECT, DELETE, INSERT, REPLACE, and UPDATE statements.
When EXPLAIN interpretable statements are used together, MySQL displays information from the Optimizer about the statement execution plan. That is, MySQL explains how it will process statements, including information about how tables are connected and connected in order
Add the explain keyword before executing any SQL in MySql to see:
+----+-------------+----------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+------+---------+------+------+-------+
id,table
Table shows which table the data in this row is about.
id is the sequence number of the select query, containing a set of numbers, indicating the order in which the select clause or operation table is executed in the query.
- The id value is the same, and the execution order is from top to bottom;
- Different id values, the larger the id value, the higher the priority, and the earlier it is executed;
The execution order of the table is closely related to the data in the table. For example, table A: 3 data tables B: 4 data tables C: 6 data tables.
Assuming that the id values of tables A, B and C are the same when executing an SQL, assume that the execution order is: tables A, B and C. after adding 4 pieces of data to table B, execute the previous SQL again and find that the execution order is changed to: tables A, C and B.
This is because the intermediate results will affect the execution order of the table:
3 * 4 * 2 = 12 * 2 = 24
3 * 2 * 4 = 6 * 4 = 24
Although the final result is the same, the intermediate process is different. The smaller the intermediate process is, the smaller the space it occupies. Therefore, when the ID value is the same, the table with small data will be queried first.
select_type
select_type is the type of query, which is mainly used to distinguish complex queries such as ordinary queries, joint queries and sub queries.
Query type:
- PRIMARY: PRIMARY query including self query, the outermost part;
- SUBQUERY: the query statement contains subqueries, not the outermost layer;
- SIMPLE: SIMPLE query, that is, SQL does not contain sub query or UNION query;
- DERIVED: temporary tables are created during the query, such as SQL:
explain select name from (select * from table1) t1;
- UNION: if the second SELECT appears after the UNION, it will be marked as UNION; if the UNION is included in the subquery of the FROM clause, the outer layer SELECT will be marked as: DERIVED;
explain select name from (select * from table1 union select * from table2) t1;
- UNION RESULT: the result from the UNION table;
type
Type is an index type and an important indicator. The result values from the best to the worst are:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index >ALL
It may not be used in actual work. Generally, just remember the following:
system > const > eq_ref > ref > range > index > ALL
Among them, system and const are only ideal cases, and they can actually reach ref and range.
Common index types:
- System: a system table with only one row of records, or a primary query with only one row of data in a derived table;
-- Derivative table:(select * from tbl_001) There is only one record; id Index for primary key explain select * from (select * from tbl_001) where id = 1;
- const: SQL that can query only one record and is used for primary key index or unique key index;
-- tbl_001 Table has only one record; id Is a primary key index or a unique key index explain select * from tbl_001 where id = 1;
- eq_ref: unique index; for each index key query, data matching a unique row will be returned. There is only one data, and it cannot be more or 0. It is common in primary key or unique index scanning;
-- tbl_001.tid Is an indexed column; and tbl_001 And tbl_002 The data records in the table correspond one by one select * from tbl_001,tbl_002 where tbl_001.tid = tbl_002.id
- ref: non unique index; for the query of each index key, multiple matching rows are returned, including 0;
-- name Is an index column; tbl_001 In the table name Value is zs There are multiple explain select * from tbl_001 where name = 'zs';
- Range: retrieves the rows in the specified range, followed by a range query. Common queries include between and, in, >, < =;
-- tid Is an index column; explain select * from tbl_001 where tid <=3;
- index: query the data in all indexes;
-- name Is an index column; explain select name from tbl_001;
- All: query the data in all tables;
-- name Not an index column; explain select name from tbl_001;
possible_keys,key
possible_keys is the index that may be used. It is a kind of prediction and inaccurate. key is the index actually used. If it is null, the index is not used.
-- name Index column explain select name from tbl_001; +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+ | 1 | SIMPLE | tbl_001 | index | NULL | idx_name | 83 | NULL | 4 | Using index | +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+
key_len
key_len the length used by the index. You can judge whether the composite index is used by the length of the index column, such as name vachar(20).
-- name Is an indexed column; can be null;varchar Type; utf8 Character set; explain select name from tbl_001 name = 'zs'; +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+ | 1 | SIMPLE | tbl_001 | index | NULL | idx_name | 63 | NULL | 4 | Using index | +----+-------------+---------+-------+---------------+----------+---------+------+------+-------------+
If the index field can be null, MySql will identify it with one byte; varchar is variable length, and MySql will identify it with two bytes.
utf8: one character, three bytes;
gbk: one character and two bytes;
latin: one character and one byte;
ref
ref indicates the field referenced by the current table.
-- among b.d Can be a constant const identification select ... where a.c = b.d;
-- tid Index column explain select * from tbl_001 t1,tbl_002 t2 where t1.tid = t2.id and t1.name = 'zs'; +----+-------------+-------+--------+------------------+----------+---------+-----------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+------------------+----------+---------+-----------------+------+-------------+ | 1 | SIMPLE | t1 | ref | idx_name,idx_tid | idx_name | 83 | const | 1 | Using where | | 1 | SIMPLE | t2 | eq_ref | PRIMARY | PRIMARY | 4 | sql_demo.t1.tid | 1 | NULL | +----+-------------+-------+--------+------------------+----------+---------+-----------------+------+-------------+
rows
Rows indicates the number of query rows, and the actual number of rows queried through the index.
mysql> select * from tbl_001 t1,tbl_002 t2 where t1.tid = t2.id and t1.name = 'ls'; +----+------+------+----+------+-------+-------+ | id | name | tid | id | name | name1 | name2 | +----+------+------+----+------+-------+-------+ | 2 | ls | 2 | 2 | ls | ls1 | ls2 | | 4 | ls | 1 | 1 | zs | zs1 | zs2 | +----+------+------+----+------+-------+-------+ mysql> explain select * from tbl_001 t1,tbl_002 t2 where t1.tid = t2.id and t1.name = 'ls'; +----+-------------+-------+-------+------------------+------------+---------+----------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+------------------+------------+---------+----------------+------+-------------+ | 1 | SIMPLE | t2 | index | PRIMARY | index_name | 249 | NULL | 2 | Using index | | 1 | SIMPLE | t1 | ref | idx_name,idx_tid | idx_tid | 5 | sql_demo.t2.id | 1 | Using where | +----+-------------+-------+-------+------------------+------------+---------+----------------+------+-------------+
Extra
Extra contains additional information that is not suitable for display in other columns but is important.
Common values:
- Using filesort: sorting within a file; this value represents an additional sorting (query), which consumes a lot of performance and requires SQL optimization. It is common in the order by statement;
For a single valued index, if the same field is sorted and searched, Using filesort will not appear. On the contrary, it is generally avoided by ordering by which fields according to where.-- name Is a single valued index explain select * from tbl_001 where name = 'zs' order by tid; +----+-------------+---------+------+---------------+----------+---------+-------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+----------+---------+-------+------+----------------+ | 1 | SIMPLE | tbl_001 | ref | idx_name | idx_name | 83 | const | 1 | Using filesort | +----+-------------+---------+------+---------------+----------+---------+-------+------+----------------+
For composite indexes, they should be used in the order in which composite indexes are established. They should not be used across columns or out of order.-- name,tid Is a composite index explain select * from tbl_001 where name = 'zs' order by tid; +----+-------------+---------+------+---------------+-----------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+-----------+---------+-------+------+-------------+ | 1 | SIMPLE | tbl_001 | ref | idx_trans | idx_trans | 83 | const | 1 | Using index | +----+-------------+---------+------+---------------+-----------+---------+-------+------+-------------+
Cross column use means that the fields behind where and the fields behind order by are spliced to see whether the index order is met. If not, it is cross column, and using filport will appear.
- Using temporary: enables you to save intermediate results with a temporary table. MysQL uses a temporary table when sorting query results. Performance consumption is also large. Generally, SQL optimization is required for this word. It is common in group query group by statements;
The reason for Using temporary is that there is already a table, but it is not used. You must use another table. We can avoid this problem by grouping by which columns we query.-- name,tid,cid Is a composite index explain select name from tbl_001 where name = 'zs' group by cid; +----+-------------+---------+------+---------------+---------+---------+-------+------+------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+---------+---------+-------+------+------------------------------+ | 1 | SIMPLE | tbl_001 | ref | idx_ntc | idx_ntc | 83 | const | 2 | Using index; Using temporary | +----+-------------+---------+------+---------------+---------+---------+-------+------+------------------------------+
- Using index: this value indicates that the performance is good; It means that the overlay index is used, the source file is not read, only the data is obtained from the index file, and there is no need to query back to the table.
Covering Index is called index covering: the queried data columns can be obtained from the index file without reading the original data rows. MySQL can use the index to return the fields in the select list without reading the data file again according to the index. In other words, all the queried columns are in the index column, which is index covering.
If you want to use an overlay index, you must note that only the required columns are taken out of the select list, and you cannot select *, because if you index all fields together, the index file will be too large and the query performance will be degraded.
If index override is used, it will be used for possible_key and key impact:-- name,tid,cid Is a composite index explain select name,tid,cid from tbl_001 where name = 'zs'; +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | tbl_001 | ref | idx_ntc | idx_ntc | 83 | const | 2 | Using index | +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+
- If where is not used, the index only appears in the key;
- If there is a where, the index appears in key and possible_key;
- Using where: when this value appears, it indicates that a table back query is required;
-- name It is a single value index. At this time, the index does not contain other fields. If you want to query other fields, you must query back to the table explain select name,tid,cid from tbl_001 where name = 'zs'; +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | tbl_001 | ref | idx_name | idx_name | 83 | const | 2 | Using where | +----+-------------+---------+------+---------------+---------+---------+-------+------+-------------+
- Impossible WHERE: the where statement is always false and never holds;
explain select * from tbl_001 where name = 'zs' and name = 'ls'; +----+-------------+-------+------+---------------+------+---------+------+------+------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+------------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE | +----+-------------+-------+------+---------------+------+---------+------+------+------------------+
SQL optimization case
Single table optimization
-- Prepare test table and test data create table book_2021( bid int(4) primary key, name varchar(20) not null, authorid int(4) not null, publicid int(4) not null, typeid int(4) not null ); insert into book_2021 values(1,'java',1,1,2); insert into book_2021 values(2,'php',4,1,2); insert into book_2021 values(3,'c',1,2,2); insert into book_2021 values(4,'c#',3,1,2); insert into book_2021 values(5,'c++',3,1,2);
SQL to optimize:
-- SQL Prototype, optimize the SQL select bid from book_2021 where typeid in(2,3) and authorid=1 order by typeid desc;
Execute the plan to analyze the SQL. It is found that the SQL has using filesort and type is ALL. SQL optimization is required.
explain select bid from book_2021 where typeid in(2,3) and authorid=1 order by typeid desc; +----+-------------+-----------+------+---------------+------+---------+------+------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+------+-----------------------------+ | 1 | SIMPLE | book_2021 | ALL | NULL | NULL | NULL | NULL | 5 | Using where; Using filesort | +----+-------------+-----------+------+---------------+------+---------+------+------+-----------------------------+
- According to the execution process of SQL, the order of index creation is typeid, authorid and bid;
-- sql Execution sequence from .. on .. join .. where .. group by .. having .. select distinct .. order by .. limit ..
-- Indexing alter table book_2021 add index idx_tab(typeid,authorid,bid);
- When using in, the index will be invalidated. If in is invalidated, the subsequent indexes will also be invalidated, so put the range condition last;
Delete the old index and create the index corresponding to the field order.-- Optimized SQL select bid from book_2021 where authorid=1 and typeid in(2,3) order by typeid desc;
Warm tip: once the index is upgraded and optimized, you need to delete the index to prevent interference
-- delete idx_tab Indexes drop index idx_tab on book_2021; -- Give table book_2021 Add index idx_atb alter table book_2021 add index idx_atb(authorid,typeid,bid);
SQL execution process after final optimization:
explain select bid from book_2021 where authorid=1 and typeid in(2,3) order by typeid desc; +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------------------------+ | 1 | SIMPLE | book_2021 | NULL | range | idx_atb | idx_atb | 8 | NULL | 3 | 100.00 | Using where; Backward index scan; Using index | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------------------------------+
Summary of single table optimization:
- The best left prefix principle keeps the definition and use order of the index consistent;
- The index needs to be optimized step by step;
- Put the criteria containing the range query last
Two table optimization
-- Prepare test table and test data create table teacher2( tid int(4) primary key, cid int(4) not null ); insert into teacher2 values(1,2); insert into teacher2 values(2,1); insert into teacher2 values(3,3); create table course2( cid int(4) not null, cname varchar(20) ); insert into course2 values(1,'java'); insert into course2 values(2,'phython'); insert into course2 values(3,'kotlin');
SQL to optimize:
-- SQL Prototype, optimize the SQL select * from teacher2 t left outer join course2 c on t.cid = c.cid where c.cname = 'java';
The execution process analyzed the SQL and found that a full table scan was performed.
explain select * from teacher2 t left outer join course2 c on t.cid = c.cid where c.cname = 'java'; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ | 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where | | 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where; Using join buffer (hash join) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
Optimization ideas:
- Indexing; Which table and which field are indexed? That is, the small table drives the large table, and the index should be based on the frequently used fields. Assuming that there is little data in the teacher table at this time, the problem should be cited in the t.cid and c.name fields;
Small table drives large table: assume that there are 10 pieces of data in the small table; 300 pieces of data in large table; Let the large and small tables do nested loops. Whether 10 is an outer loop or 300 is an outer loop, the result is 3000 times. However, in order to reduce the number of table connection creation, 10, that is, small tables, should be placed in the outer loop, which will be more efficient.
Reasons for small meter driving large meter:
There are two tables A and B, with 200 data in table A and 200000 data in table B; According to the concept of cycle, for example:
Small table drives large table > a driven table, B driven table
for(200) {for(200000) {...}}
Large table drives small table > b driven table, A driven table
for(200000) {for(200) {...}}
Summary:
If the small loop is in the outer layer, it is only connected 200 times for table connection;
If the large cycle is in the outer layer, 200000 meter connections are required, thus wasting resources and increasing consumption;
The main purpose of small table driving large table is to speed up query by reducing the number of table connection creation.
-- Give table teacher2,course2 Add index alter table teacher2 add index idx_teacher2_cid(cid); alter table course2 add index idx_course2_cname(cname);
Final optimized SQL:
-- After adding an index explain select * from teacher2 t left outer join course2 c on t.cid = c.cid where c.cname = 'java'; +----+-------------+-------+------------+------+-------------------+-------------------+---------+----------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+-------------------+-------------------+---------+----------------+------+----------+-------------+ | 1 | SIMPLE | c | NULL | ref | idx_course2_cname | idx_course2_cname | 83 | const | 1 | 100.00 | Using where | | 1 | SIMPLE | t | NULL | ref | idx_teacher2_cid | idx_teacher2_cid | 4 | sql_demo.c.cid | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+-------------------+-------------------+---------+----------------+------+----------+-------------+
Summary of multi table optimization:
- Small meter drives large meter;
- The index is based on frequently queried fields;
Some principles to avoid index failure
- When using composite indexes, do not use them across columns or out of order, that is, the best left prefix rule; Otherwise, the index is invalid;
Cross column use means that the fields behind where and the fields behind order by are spliced to see whether the index order is met. If not, it is cross column, and using filport will appear.
- Do not perform any operations on the index, such as calculation, function operation, type conversion, etc; Otherwise, the index is invalid;
-- age Column as an index, but at this time SQL sentence age Column has calculation, age Invalid index column; select * from tbl_001 where age*3 = '10'; -- name Is an index column. At this time, function calculation is performed on the index column, name Invalid index column; select * from tbl_001 tbl_001 left(name,4)='July'; -- typeid Is an index column, typeid by int Type, where implicit type conversion occurs, typeid Invalid index column; select * from tbl_001 c typeid = '1';
- The composite index cannot be used that is not equal to (! =, < >) or is null or is not null, otherwise it and the index on the right will be invalid;
In most cases, if the composite index uses the above operators, the index will fail, but MySql has an SQL optimization stage in the service layer. Therefore, even if the composite index uses operations such as not equal to, is null and is not null, the index may take effect.
- Try to use overlay index. Using overlay index will improve system performance;
-- name,tid,cid Is a composite index select name,tid,cid from tbl_001 where name = 'zs';
- like starts with a constant instead of% as far as possible, otherwise the index will become invalid;
-- name Is an index column, where the index is invalid select * from tbl_002 where name like '%x%'; -- If necessary%At the beginning, you can save it by using the overlay index select name from tbl_002 where name like '%x%';
- Do not use or, otherwise the index will become invalid;
-- authorid,typeid Composite index, here or All indexes on the left and right sides of the are invalid select * from book_2021 where authorid = 1 or typeid = 1;
- Avoid using *, because MySql needs to calculate and replace with the corresponding column after use;
-- Do not use*,hold*Replace with the required column select * from book_2021;
SQL optimization method
exist and in selection
The two can replace each other. If the data set of the main query is large, the efficiency of using in is a little higher; If the data set of the sub query is large, it is more efficient to use exist;
-- Assuming that the main query data set here is large, use in select * from tbl_001 where tid in (select id from tbl_001); -- Assuming that the sub query data set is large, use exist select tid from tbl_001 where exists (select * from tbl_001);
exists syntax: put the results of the main query into the sub query results to judge whether there is data in the sub query. If there is data, keep the data and return it; If not, null is returned.
order by optimization
Order by is a commonly used keyword. Basically, the queried data should be sorted, otherwise it will be too messy. The use of order by is often accompanied by the use of filesort. There are two algorithms at the bottom of Using filesort, which are divided into:
- Two way sorting: before MySQL 4.1, two-way sorting was used by default; For the specific implementation process, two-way sorting needs to scan the fields on the disk twice. First scan the sorted fields to sort the fields, and then scan other fields;
- Single channel sorting: in order to reduce the number of IO accesses, single channel sorting is used by default after MySQL 4.1; Read all the fields at once and sort them in the buffer. However, there are hidden dangers in this method, which is not necessarily read-only data. If the amount of data is too large for the buffer, the file needs to be read again, which can be alleviated by adjusting the buffer;
-- Set read file buffer( buffer)Size of,Unit byte set max_length_for_sort_data = 1024;
If the total size of the columns to be sorted exceeds the set max_length_for_sort_data, the bottom layer of MySql will automatically switch from one-way sorting to two-way sorting.
Ensure the consistency of all index sorting fields, in ascending or descending order, not in partial ascending or partial descending order.
Troubleshooting SQL
In MySql, you can perform SQL troubleshooting by grabbing the slow SQL log. If the slow SQL log exceeds the response time threshold for 10 seconds by default, the SQL will be recorded; the slow SQL log is closed by default. It is recommended to open it during development and tuning and close it when the final deployment goes online.
Slow SQL log settings
Check whether slow SQL logging is enabled through SQL:
-- View variables slow_query_log,Logging slow queries is off by default show variables like '%slow_query_log%'; +---------------------+----------------------------------------------+ | Variable_name | Value | +---------------------+----------------------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /usr/local/mysql/data/MacBook-Pro-2-slow.log | +---------------------+----------------------------------------------+
You can enable slow SQL logging through SQL:
-- Slow start in memory SQL Log; in this way mysql Failure after service restart set global slow_query_log=1; -- Check whether the slow SQL Logging show variables like '%slow_query_log%'; +---------------------+----------------------------------------------+ | Variable_name | Value | +---------------------+----------------------------------------------+ | slow_query_log | ON | | slow_query_log_file | /usr/local/mysql/data/MacBook-Pro-2-slow.log | +---------------------+----------------------------------------------+
-- stay MySql my.cnf Append configuration to configuration file;restart MySql It also takes effect after service, that is, it is permanently opened slow_query_log=1 slow_query_log_file=/usr/local/mysql/data/MacBook-Pro-2-slow.log
View slow SQL log threshold:
-- View slow SQL Logging threshold, default 10 seconds show variables like '%long_query_time%'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+
Modify slow SQL logging threshold:
-- Modify slow query settings in memory SQL The logging threshold is 5 seconds. Note that it will not take effect immediately after setting, and you need to log in again mysql The client will take effect set global long_query_time = 5; -- Log in again after setting mysql Use the command to view slow SQL Query log threshold show variables like '%long_query_time%'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 5.000000 | +-----------------+-----------+
-- stay MySql configuration file my.cnf Modify slow query in SQL Logging threshold,Set to 3 seconds long_query_time=3
View slow SQL log
- View slow SQL logs directly;
View slow SQL log record cat /usr/local/mysql/data/MacBook-Pro-2-slow.log execute the command:-- Simulate slow query SQL select sleep(5); -- Check whether the slow SQL Logging show variables like '%slow_query_log%'; +---------------------+----------------------------------------------+ | Variable_name | Value | +---------------------+----------------------------------------------+ | slow_query_log | ON | | slow_query_log_file | /usr/local/mysql/data/MacBook-Pro-2-slow.log | +---------------------+----------------------------------------------+
MacBook-Pro-2:~ root# cat /usr/local/mysql/data/MacBook-Pro-2-slow.log /usr/local/mysql/bin/mysqld, Version: 8.0.22 (MySQL Community Server - GPL). started with: Tcp port: 3306 Unix socket: /tmp/mysql.sock Time Id Command Argument # Time: 2021-09-17T06:46:20.655775Z # User@Host: root[root] @ localhost [] Id: 15 # Query_time: 4.003891 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 use sql_demo; SET timestamp=1631861176; select sleep(4);
- Through the mysqldumpslow tool, you can quickly find the slow SQL to be located through some filter conditions;
Syntax: mysqldumpslow various parameters slow query log file path
-s: Sorting method
-r: Reverse order
-l: Lock time, do not subtract the lock time from the total time
-g: Look in the file for the string you want to include
For more instruction parsing, see mysqldumpslow --help-- Get up to 3 returned records SQL mysqldumpslow -s r -t 3 /usr/local/mysql/data/MacBook-Pro-2-slow.log -- Get the 3 most visited SQL mysqldumpslow -s r -t 3 /usr/local/mysql/data/MacBook-Pro-2-slow.log -- Sorted by time, the top 10 items include left join Query of SQL mysqldumpslow -s t -t 10 -g "left join" /usr/local/mysql/data/MacBook-Pro-2-slow.log
Simulate data and analyze SQL
- Analog data;
-- Create table create database testdata; use testdata; create table dept ( dno int(5) primary key default 0, dname varchar(20) not null default '', loc varchar(30) default '' ) engine=innodb default charset=utf8; create table emp ( eid int(5) primary key, ename varchar(20) not null default '', job varchar(20) not null default '', deptno int(5) not null default 0 )engine=innodb default charset=utf8;
-- Create stored procedure: get random string set global log_bin_trust_function_creators=1; use testdata; delimiter $ create function randstring(n int) returns varchar(255) begin declare all_str varchar(100) default 'abcdefghijklmnopqrestuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i<n do set return_str=concat(return_str, substring(all_str, FLOOR(1+rand()*52), 1)); set i=i+1; end while; return return_str; end $-- Create storage function: insert random integer use testdata; create function ran_num() returns int(5) begin declare i int default 0; set i=floor(rand()*100); return i; end$
-- Create stored procedure: emp Table insert data create procedure insert_emp(in eid_start int(10), in data_times int(10)) begin declare i int default 0; set autocommit =0; repeat insert into emp values(eid_start+i, randstring(5), 'other', ran_num()); set i=i+1; until i=data_times end repeat; commit; end $
-- Create stored procedure: dept Table insert data create procedure insert_dept(in dno_start int(10), in data_times int(10)) begin declare i int default 0; set autocommit =0; repeat insert into dept values(dno_start+i, randstring(6), randstring(8)); set i=i+1; until i=data_times end repeat; commit; end $
-- towards emp,dept Insert data into table delimiter ; call insert_emp(1000, 800000); call insert_dept(10, 30);
-- Verify the amount of data inserted select count(1) from emp;
- Use show profile for sql analysis;
-- see profiling Whether to enable it. It is off by default show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | OFF | +---------------+-------+ -- If not, turn it on set profiling=on;
- Execute the test SQL, and any execution can be used for subsequent SQL analysis;
select * from emp; select * from emp group by eid order by eid; select * from emp group by eid limit 150000;
-- Execute the command to view the results show profiles; +----------+------------+--------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------+ | 2 | 0.00300900 | show tables | | 3 | 0.01485700 | desc emp | | 4 | 0.00191200 | select * from emp group by eid%10 limit 150000 | | 5 | 0.25516300 | select * from emp | | 6 | 0.00026400 | select * from emp group by eid%10 limit 150000 | | 7 | 0.00019600 | select eid from emp group by eid%10 limit 150000 | | 8 | 0.03907500 | select eid from emp group by eid limit 150000 | | 9 | 0.06499100 | select * from emp group by eid limit 150000 | | 10 | 0.00031500 | select * from emp group by eid%20 order by 5 | | 11 | 0.00009100 | select * from emp group by eid%20 order by | | 12 | 0.00012400 | select * from emp group by eid order by | | 13 | 0.25195300 | select * from emp group by eid order by eid | | 14 | 0.00196200 | show variables like 'profiling' | | 15 | 0.26208900 | select * from emp group by eid order by eid | +----------+------------+--------------------------------------------------+
- Use the command show profile cpu,block io for query. In the previous step, execute the Query_ID of show profiles; diagnose SQL;
Parameter remarks, case insensitive:
All: display all overhead information;
block io: displays the overhead related to block lO;
context switches: context switching related costs;
CPU: displays CPU related overhead information;
ipc: display sending and receiving related overhead information;
Memory: displays memory related overhead information;
page faults: display overhead information related to page errors;
Source: displays overhead information related to Source_function, Source_file, Source_line;
swaps: displays information about the cost related to the number of exchanges;show profile cpu,block io for query 3; +----------------------------+----------+----------+------------+--------------+---------------+ | Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | +----------------------------+----------+----------+------------+--------------+---------------+ | starting | 0.004292 | 0.000268 | 0.000941 | 0 | 0 | | checking permissions | 0.000026 | 0.000012 | 0.000013 | 0 | 0 | | checking permissions | 0.000007 | 0.000005 | 0.000003 | 0 | 0 | | Opening tables | 0.003883 | 0.000865 | 0.000880 | 0 | 0 | | init | 0.000022 | 0.000013 | 0.000008 | 0 | 0 | | System lock | 0.000013 | 0.000012 | 0.000002 | 0 | 0 | | optimizing | 0.000994 | 0.000078 | 0.000155 | 0 | 0 | | statistics | 0.000233 | 0.000222 | 0.000011 | 0 | 0 | | preparing | 0.000046 | 0.000043 | 0.000003 | 0 | 0 | | Creating tmp table | 0.000075 | 0.000073 | 0.000002 | 0 | 0 | | executing | 0.001532 | 0.000141 | 0.000266 | 0 | 0 | | checking permissions | 0.000050 | 0.000044 | 0.000005 | 0 | 0 | | checking permissions | 0.000014 | 0.000012 | 0.000002 | 0 | 0 | | checking permissions | 0.001539 | 0.000102 | 0.000356 | 0 | 0 | | checking permissions | 0.000044 | 0.000037 | 0.000007 | 0 | 0 | | checking permissions | 0.000019 | 0.000016 | 0.000002 | 0 | 0 | | checking permissions | 0.001250 | 0.000089 | 0.000318 | 0 | 0 | | end | 0.000015 | 0.000007 | 0.000008 | 0 | 0 | | query end | 0.000006 | 0.000004 | 0.000001 | 0 | 0 | | waiting for handler commit | 0.000041 | 0.000040 | 0.000002 | 0 | 0 | | removing tmp table | 0.000012 | 0.000010 | 0.000001 | 0 | 0 | | waiting for handler commit | 0.000010 | 0.000009 | 0.000002 | 0 | 0 | | closing tables | 0.000019 | 0.000018 | 0.000001 | 0 | 0 | | freeing items | 0.000648 | 0.000081 | 0.000152 | 0 | 0 | | cleaning up | 0.000067 | 0.000047 | 0.000021 | 0 | 0 | +----------------------------+----------+----------+------------+--------------+---------------+
Global query log
Do not enable this function in the production environment.
Set the global query log in the MySql configuration file my.cnf:
-- Enable global query log general_log=1 -- Path to log file general_log_file=/path/logfile -- Set the output format to FILE log_output=FILE -- adopt cat Command to view directly; if it is empty, you need to create data cat /var/lib/mysql/bigdata01.log;
Set the global query log on the mysql client:
-- Check whether the global query log is enabled show variables like '%general_log%'; -- Enable global query log set global general_log=1; -- Set the output format to TABLE set global log_output='TABLE'; -- Available in mysql Curie's geneial_log View the table; if it is empty, you need to create data select * from mysql.general_log;
MySql lock mechanism
In the database, in addition to traditional computing resources (such as CPU, RAM, I/O, etc.) In addition to the contention, data is also a resource shared by many users. How to ensure the consistency and effectiveness of data concurrent access is a problem that must be solved for all databases, and lock conflict is also an important factor affecting the performance of database concurrent access. From this perspective, lock is particularly important and more complex for databases. In short, lock System is to solve the concurrency problem caused by resource sharing.
According to the type of data operation, locks in MySql are divided into: read locks are shared locks and write locks are mutually exclusive locks; according to the operation granularity, they are divided into table locks, row locks and page locks.
- Read lock: for the same data, multiple read operations can be performed simultaneously without interference.
- Write lock: if the current write operation is not completed, other read and write operations cannot be performed.
- Table lock: lock one table at a time. MyISAM storage engine is biased towards table lock, which has low overhead, fast locking, no deadlock and a large range of locks, but it is prone to lock conflict and low concurrency.
- Row lock: lock one piece of data at a time. InnoDB storage engine prefers row lock, which is expensive, slow to lock, prone to deadlock and small range of locks, but not prone to lock conflict and high concurrency.
Use lock
Watch lock
Test data:
create table mylock (
id int not null primary key auto_increment,
name varchar(20) default ''
) engine myisam;
insert into mylock(name) values('a');
insert into mylock(name) values('b');
insert into mylock(name) values('c');
insert into mylock(name) values('d');
insert into mylock(name) values('e');
Common commands:
-- Lock lock table Table name 1 read/write, Table name 2 read/write, other; -- Unlock unlock tables; -- Check whether the table is locked In_use Column, 0 means no lock, 1 means lock show open tables; -- Analysis table lock -- Table_locks_immediate: The number of times table level locks are generated, indicating the number of queries that can obtain locks immediately. Add 1 for each lock value obtained immediately -- Table_locks_waited: The number of times a wait occurred due to table level lock contention(The number of times the lock cannot be obtained immediately. The lock value is increased by 1 for each waiting time),A high value indicates that there is a serious table level lock contention show status like 'table_locks%';
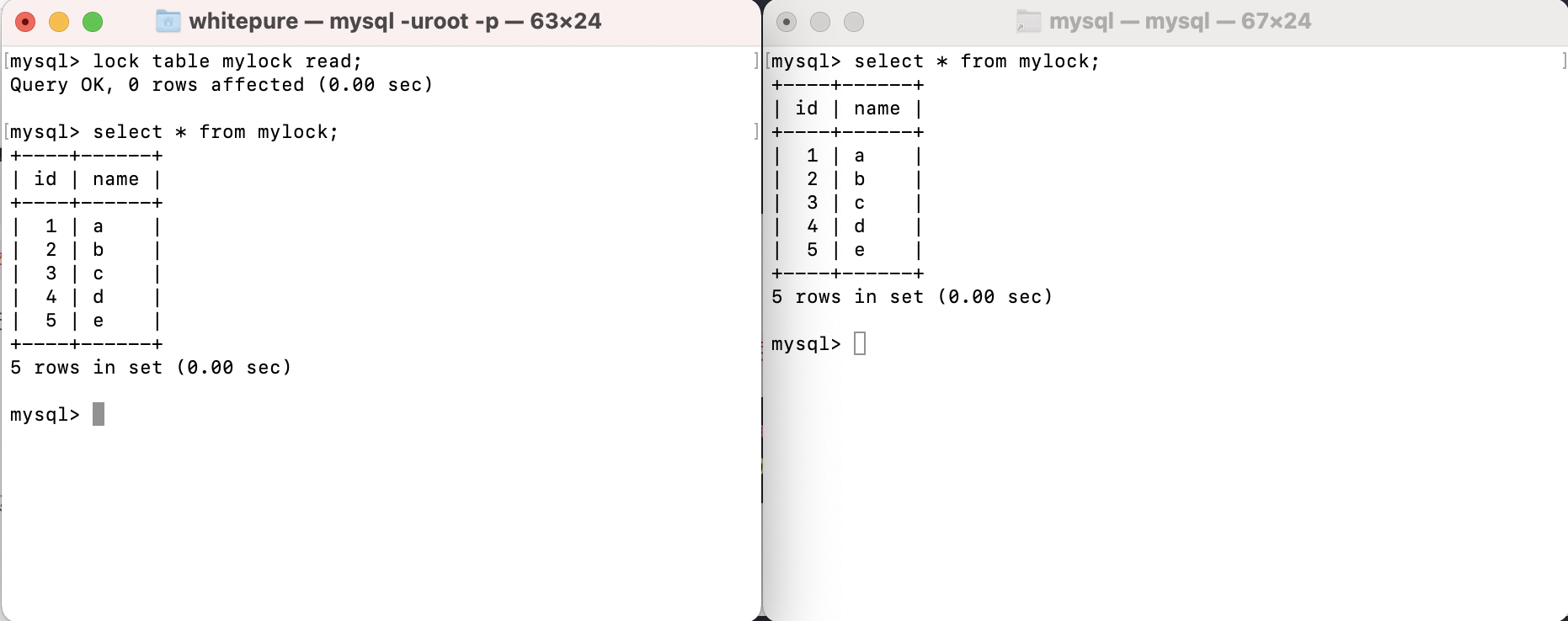
Add read lock to the table and test read operation:
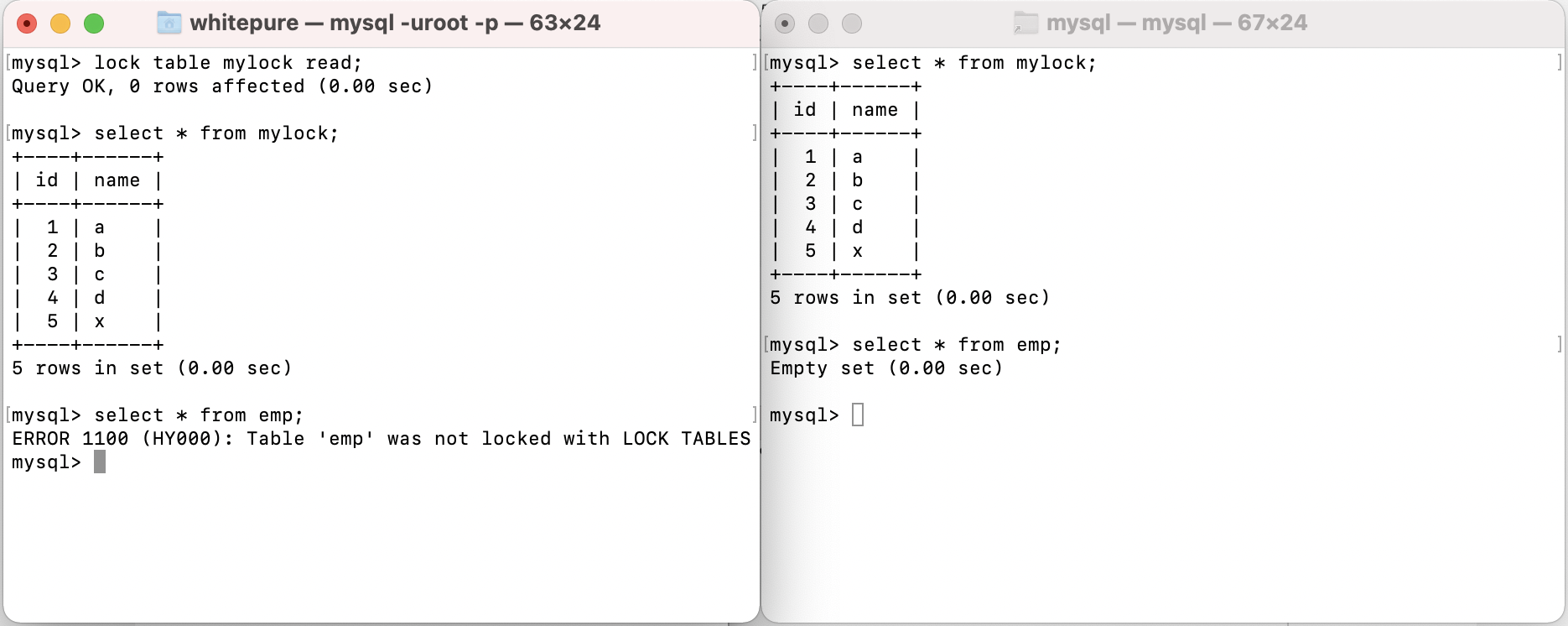
Add read lock and test write operation to the table:
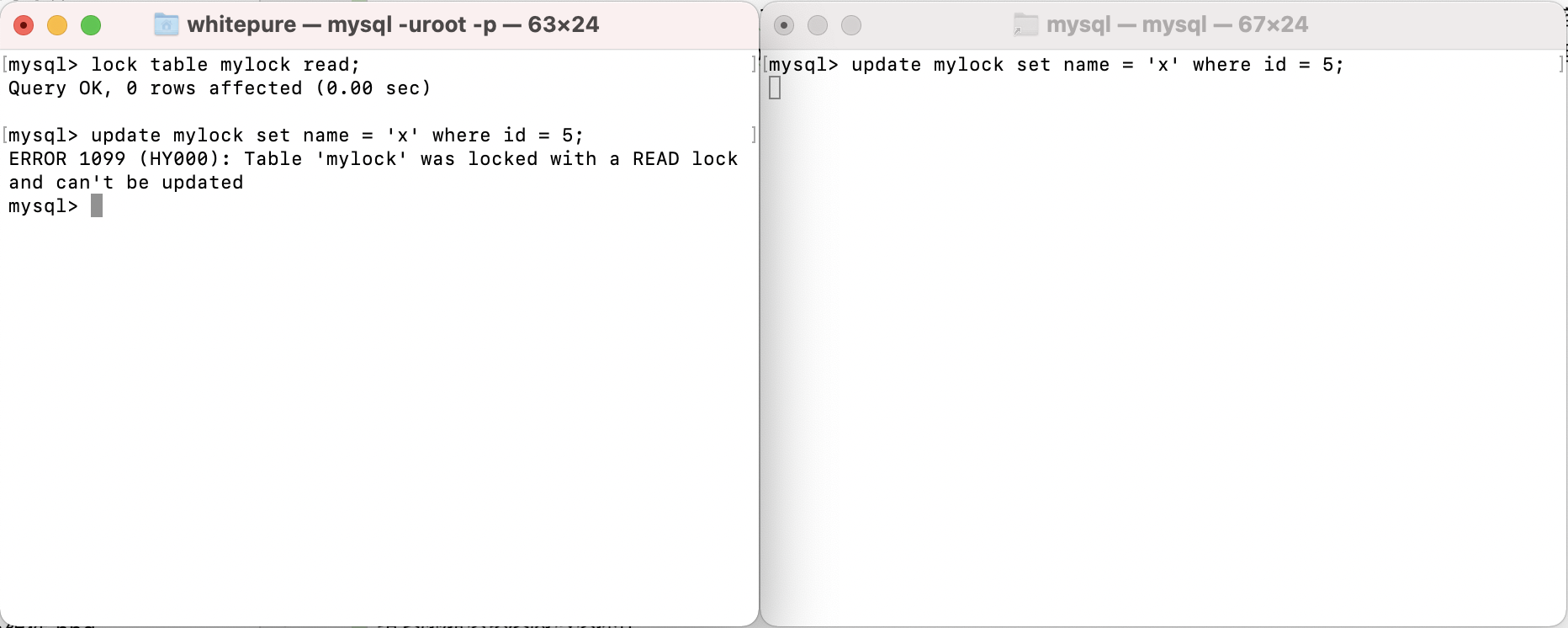
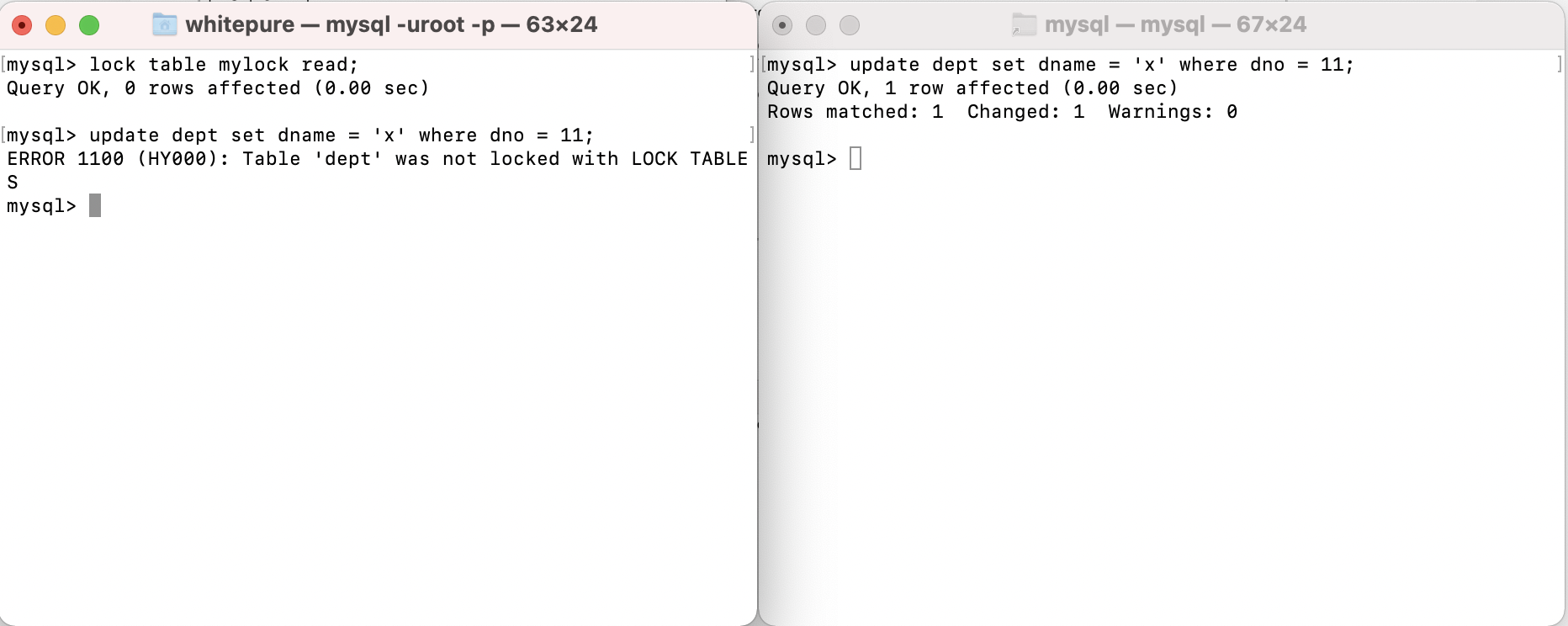
After adding a read lock to a table, all sessions can read the table, but the current session cannot write to the table and read and write to other tables; other sessions can only write after the lock holding session releases the lock of the table. During this period, they will be in a waiting state and can read and write to other tables.
Add write lock and test read operation to the table:
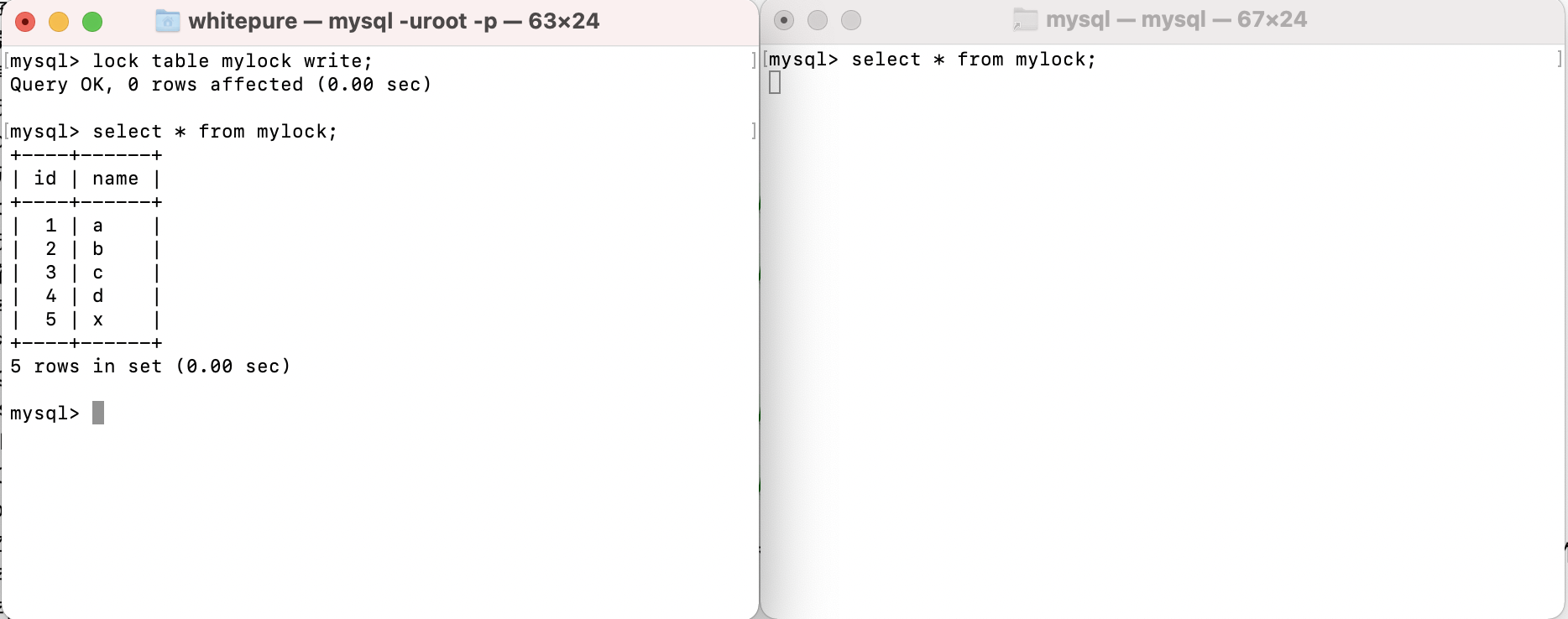
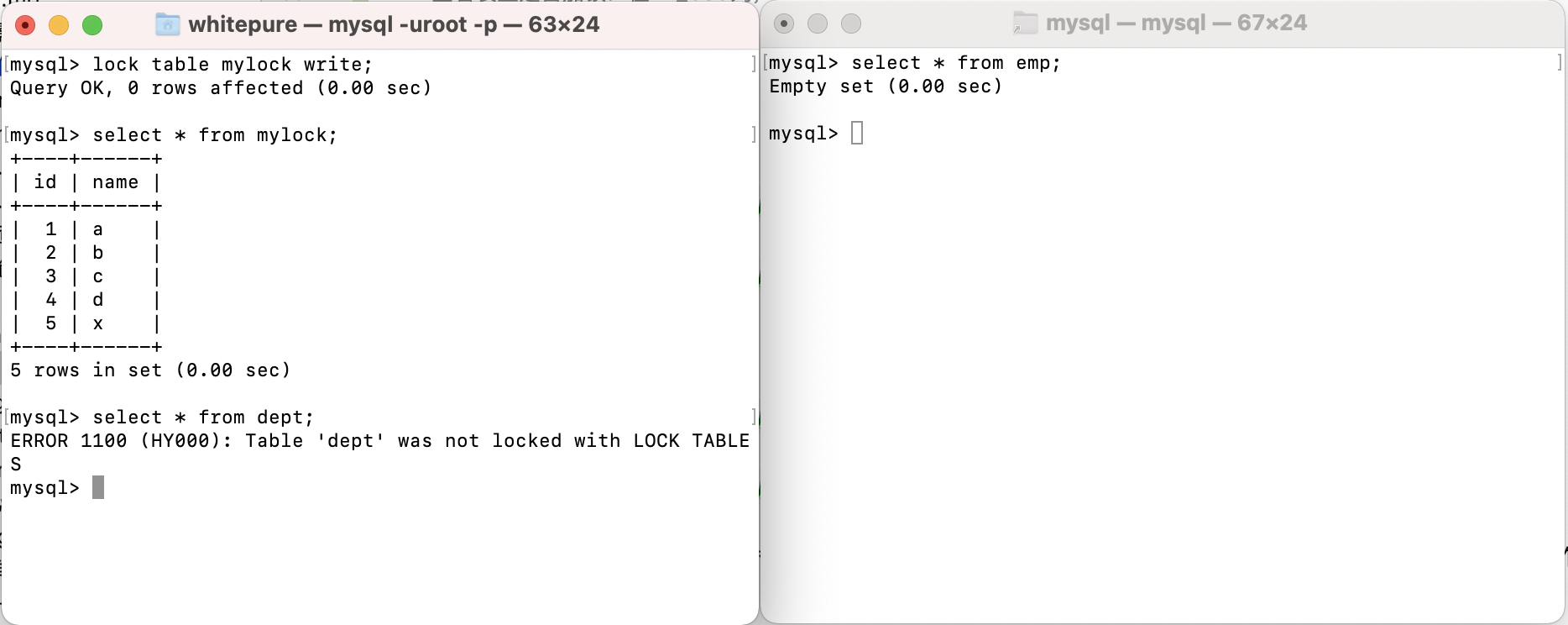
Add write lock to table and test write operation:
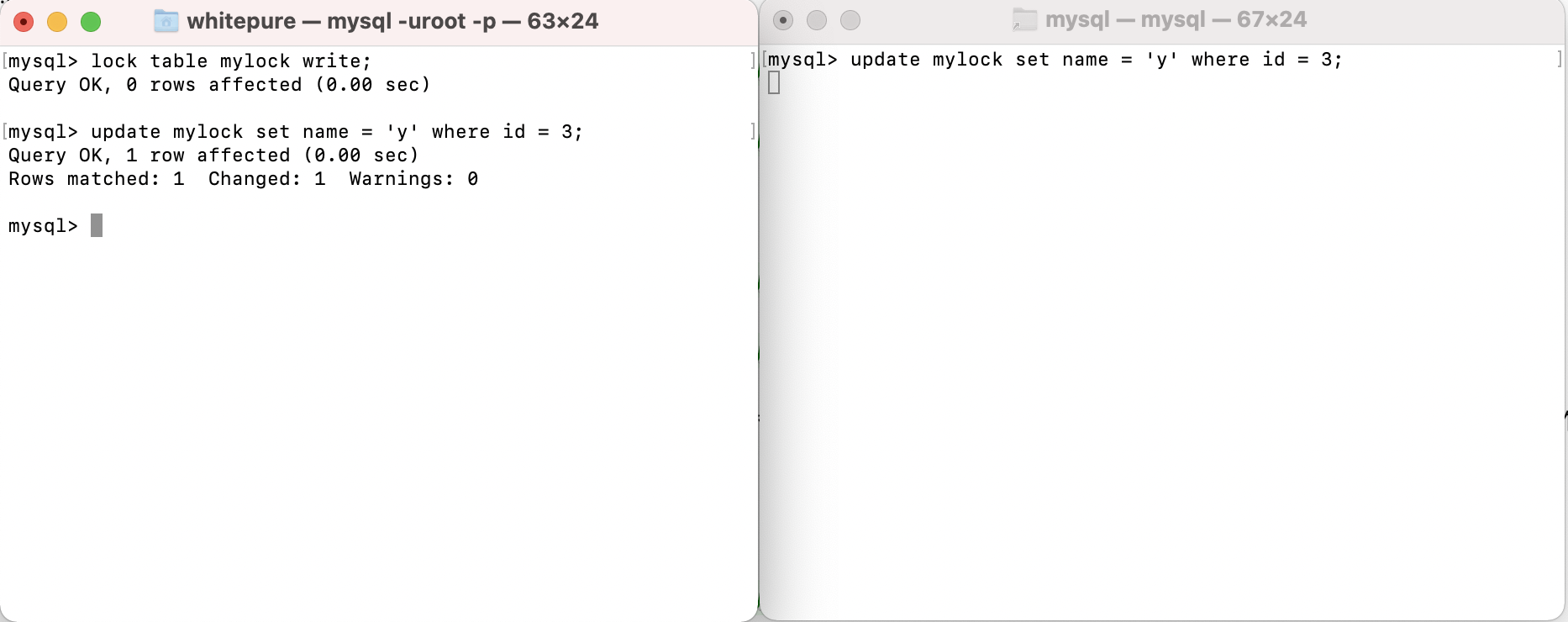
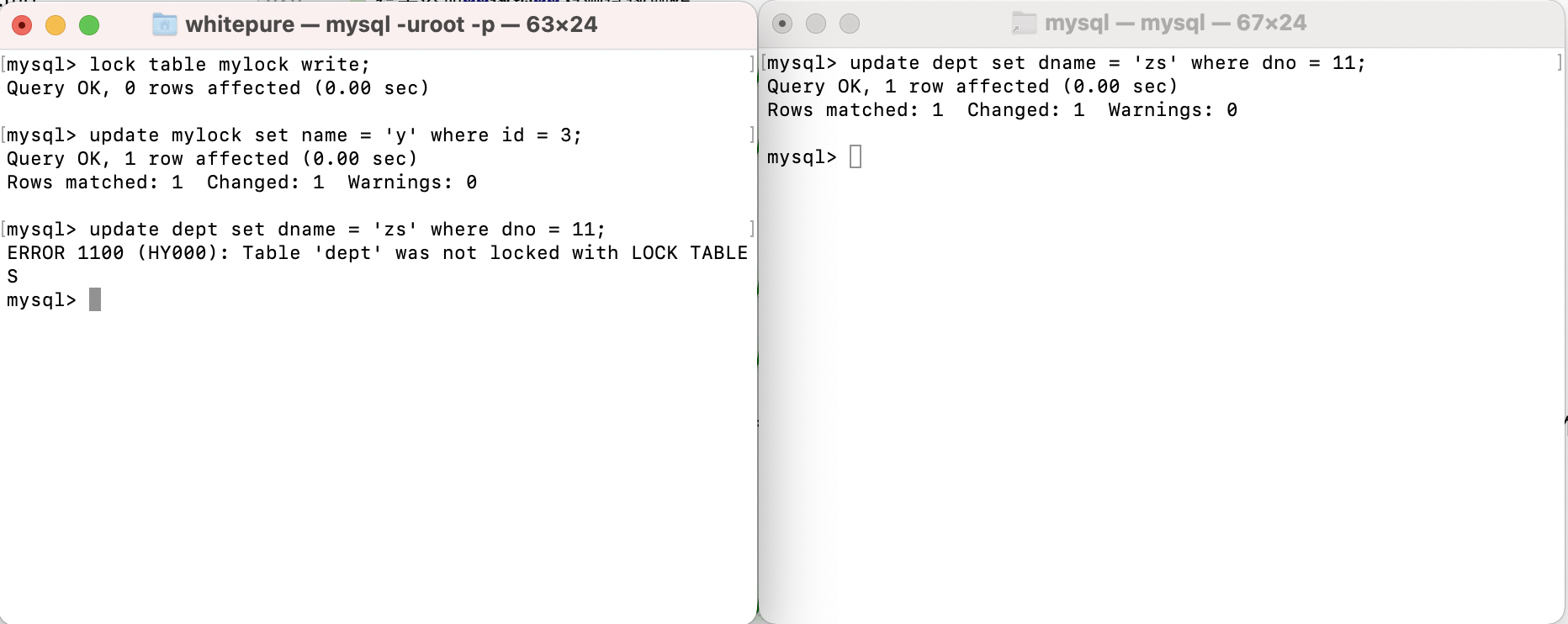
After adding a write lock to a table, the current session can write and read the table. If other sessions want to read and write the table, they need to wait for the session holding the lock to release the lock. Otherwise, they will wait for the lock to be released all the time; However, the session currently holding the lock cannot read and write to other tables, and other sessions can read and write to other tables.
For table locks, MyISAM will automatically add read locks to all tables involved before executing query statements, and automatically add write locks to the tables involved before adding, deleting and modifying operations.
- The read operation (adding read lock) on the MyISAM table will not block the read requests of other processes to the same table, but will block the write requests to the same table. Only when the read lock is released will the write operation of other processes be performed.
- The write operation (write lock) on the MyISAM table will block the read and write operations of other processes on the same table. The read and write operations of other processes will be executed only after the write lock is released.
In short, read locks block writes, but not reads. The write lock blocks both reading and writing.
Row lock
Test data:
CREATE TABLE test_innodb_lock (a INT(11),b VARCHAR(16))ENGINE=INNODB; INSERT INTO test_innodb_lock VALUES(1,'b2'); INSERT INTO test_innodb_lock VALUES(3,'3'); INSERT INTO test_innodb_lock VALUES(4, '4000'); INSERT INTO test_innodb_lock VALUES(5,'5000'); INSERT INTO test_innodb_lock VALUES(6, '6000'); INSERT INTO test_innodb_lock VALUES(7,'7000'); INSERT INTO test_innodb_lock VALUES(8, '8000'); INSERT INTO test_innodb_lock VALUES(9,'9000'); INSERT INTO test_innodb_lock VALUES(1,'b1'); CREATE INDEX test_innodb_a_ind ON test_innodb_lock(a); CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock(b);
Common commands:
-- Analysis row lock: -- Especially when the waiting times are high and the waiting time is not small, we need to analyze why there are so many waiting in the system, and then start to specify the optimization plan according to the analysis results. -- Innodb_row_lock_current_waits: The number of currently waiting to be locked; -- Innodb_row_lock_time: Total length of time from system startup to current locking; -- Innodb_row_lock_time_avg: Average time spent waiting each time; -- Innodb_row_lock_time_max: Time spent waiting for the most frequent time from system startup to now; -- Innodb_row_lock_waits: Total waiting times since system startup; -- show status like 'innodb_row_lock%';
Because row locks are related to transactions, you need to turn off automatic submission of MySql before testing:
-- Turn off automatic submission; 0 off, 1 on set autocommit = 0;
Test row lock read / write operations:
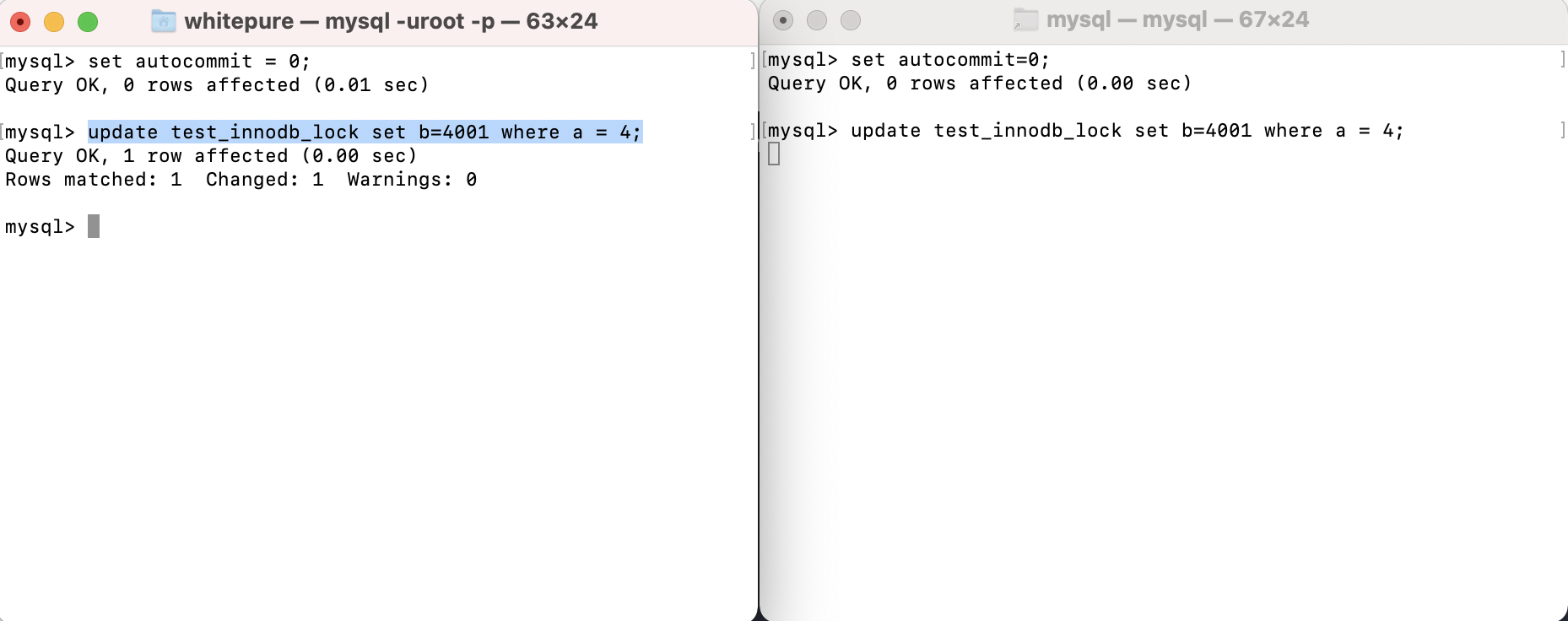
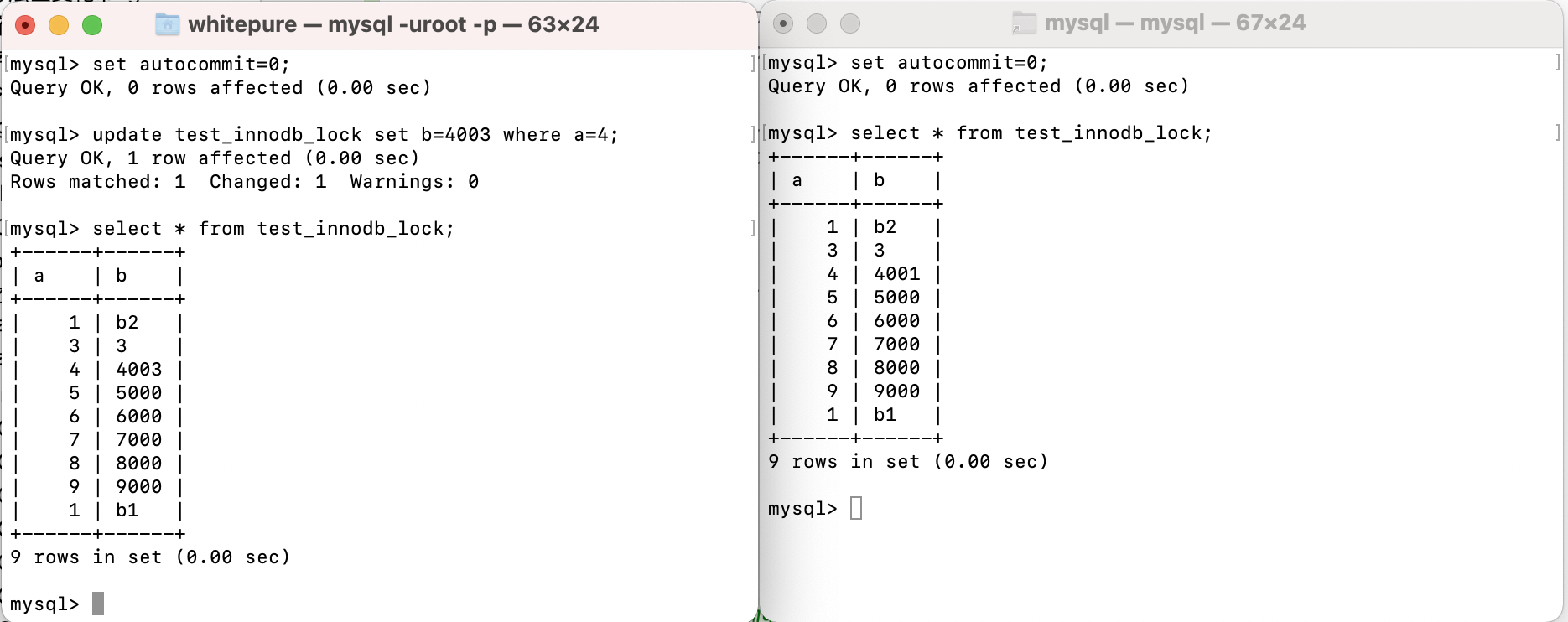
In the current session, a row of data in the table will be modified after MySql automatic submission is closed. The modified data will not be visible to other sessions before submission; If the current session and other sessions modify a row of data, the other sessions will wait until the session holding the lock commit s.
If the current session and other sessions operate on different rows of data in the same table, they will not affect each other.
When using row locks, note that no indexed rows or invalid indexes will turn row locks into table locks.
Clearance lock:
When we use the range condition instead of the equal condition to retrieve data and request a shared or exclusive lock, InnoDB will lock the index entries of existing data records that meet the conditions. The records whose key values are within the condition range but do not exist are called "gaps". InnoDB will also lock this "gap". This locking mechanism is the so-called gap lock.
Because if the Query passes the range search during execution, it will lock all index key values in the whole range, even if the key value does not exist.
A fatal weakness of gap lock is that when a range key value is locked, even some nonexistent key values will be locked innocently, resulting in the inability to insert any data within the range of locked key values during locking. In some scenarios, this may cause great harm to performance.
How to lock a row?
Use the for update keyword in the query statement:
select * from test_innodb_lock where a=8 for update;
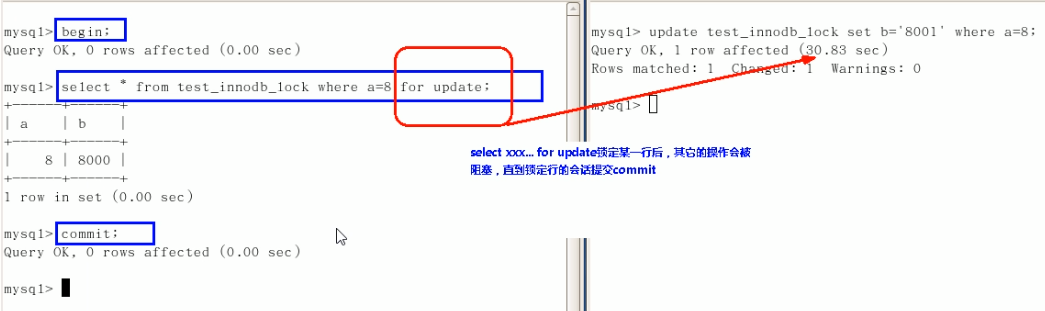
Because Innodb storage engine implements row level locking, although the performance loss caused by the implementation of locking mechanism may be higher than that of table level locking, it is much better than that of table level locking of MyISAM in terms of overall concurrent processing capacity. When the system concurrency is high, the overall performance of Innodb will have obvious advantages over MylISAM.
However, Innodb's row level locking also has its weak side. When we use it improperly, the overall performance of Innodb may not be higher than MyISAM, or even worse.
Summary:
- Let all data retrieval be completed by index as far as possible to avoid upgrading non indexed row lock to table lock.
- Reasonably design the index to minimize the scope of the lock
- Search conditions shall be as few as possible to avoid gap lock
- Try to control the transaction size and reduce the amount of locking resources and time length
- Low level transaction isolation as possible