Note: the test database version is MySQL 8.0
I Introduction to partition table
In MySQL 8.0, partition support is provided by InnoDB and NDB storage engines.
It is not possible for the InnoDB storage engine to disable partition support.
The SQL standard does not provide much guidance on the physical aspects of data storage. The purpose of SQL language itself is any data structure or media independent of the schema, table, row or column it uses. Nevertheless, most advanced database management systems have developed methods to determine the physical location (including file system, hardware, or even both) for storing specific data blocks. In mysql, the InnoDB storage engine has long supported the concept of table space. Even before partition is introduced, the MySQL server can be configured to use different physical directories to store different databases.
Partitioning takes this concept a step further by allowing you to distribute parts of a single table in the file system according to rules that you can set as needed. In fact, different parts of a table are stored in different locations as separate tables. The rules selected by the user to complete data division are called partition functions. In MySQL, they can be modulus, simple matching for a set of ranges or value lists, an internal hash function or a linear hash function. The function selects according to the partition type specified by the user, and takes the value of the expression provided by the user as its parameter. This expression can be a column value, a function acting on one or more column values, or a collection of one or more column values, depending on the partition type used.
Principle of zoning
Partition tables are implemented by multiple related underlying tables, which are also represented by handler objects, so we can also directly access each partition. The storage engine manages each underlying table of the partition just as it manages ordinary tables (all underlying tables must use the same storage engine). The index of the partitioned table is only to add an identical index to each underlying table. From the perspective of the storage engine, the underlying table is no different from an ordinary table, and the storage engine does not need to know whether it is an ordinary table or a part of a partitioned table.
Operations on the partition table follow the following operation logic:
-
SELECT query
When querying a partition table, the partition layer first opens and locks all the underlying tables. The optimizer first determines whether some partitions can be filtered, and then calls the corresponding storage engine interface to access the data of each partition. -
INSERT operation
When writing a record, the partition layer first opens and locks all the underlying tables, then determines which partition receives the record, and then writes the record to the corresponding underlying table. -
DELETE operation
When deleting a record, the partition layer first opens and locks all the underlying tables, then determines the partition corresponding to the data, and finally deletes the corresponding underlying tables. -
UPDATE operation
When updating a record, the partition layer first opens and locks all the underlying tables. MySQL first determines which partition the record to be updated is in, then takes out the data and updates it, and then determines which partition the updated data should be placed in. Finally, write to the underlying table and delete the underlying table where the original data is located.
II Type of partition
2.1 range zoning
Tables that are partitioned by range are partitioned in such a way that each partition contains rows whose partition expression values are within a given range. The ranges should be continuous, but not overlapping, and defined using the VALUES LESS THAN operator. In the next few examples, suppose you are creating a table, as shown below, to store personnel records of 20 video stores (numbered from 1 to 20):
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);
Depending on your needs, you can partition the table by range in a variety of ways. One way is to use store_id column. For example, you can partition a table by adding a partition by RANGE clause, as shown below:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
In this partition scheme, all rows corresponding to employees in retail stores 1 to 5 are stored in partition p0, all rows corresponding to employees in retail stores 6 to 10 are stored in partition p1, and so on. Each partition is defined from low to high. This is the requirement of PARTITION BY RANGE syntax; You can think of it as a series of if... Else if... In C or Java.
It is easy to determine that a new row containing data (72, 'Mitchell', 'Wilson', '1998-06-25', NULL, 13) is inserted into partition p2, but what happens when your chain adds the 21st storage? In this mode, there are no rules covering the store_ A line with an ID greater than 20, so an error occurs because the server does not know where to put it. You can avoid this by using the "catchall" VALUES LESS THAN clause in the CREATE TABLE statement, which provides all values greater than the explicitly named maximum:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
MAXVALUE represents an integer value that is always greater than the maximum possible integer value (in mathematical language, it acts as the minimum upper bound). Now, any store_ Rows whose ID column value is greater than or equal to 16 (the highest value defined) are stored in partition p3. At some point in the future - when the number of stores increases to 25, 30, or more, you can use the ALTER TABLE statement to add new partitions for stores 21-25, 26-30, etc.
You can partition the table based on the employee's work code (that is, based on the range of job_code column values) in a very similar way. For example, suppose that a two digit work code is used for ordinary (in store) workers, a three digit work code is used for offices and support personnel, and a four digit work code is used for management positions. You can create a partition table using the following statement:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (job_code) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (10000)
);
In this example, all rows related to workers in the store are stored in partition p0, rows related to office and logistics personnel are stored in partition p1, and rows related to managers are stored in partition p2.
You can also use expressions in the VALUES LESS THAN clause. However, MySQL must be able to evaluate the return value of the expression as part of the less than (<) comparison.
Instead of splitting table data by storage number, you can use an expression based on one of the two DATE columns. For example, let's assume that you want to divide by the YEAR each employee left the company; That is, the value of YEAR (separated). The following is an example of a CREATE TABLE statement that implements this partition mode:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE ( YEAR(separated) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
In this example, for all employees who resigned before 1991, rows are stored in partition p0; Those who left office from 1991 to 1995 were in P1; p2 for those who left from 1996 to 2000; For workers who left after 2000, p3.
You can also use UNIX_ The TIMESTAMP() function partitions the table by RANGE according to the value of the TIMESTAMP column, as shown in the following example:
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
No other expressions involving TIMESTAMP values are allowed.
Range partitioning is particularly useful when one or more of the following conditions are met:
- You want or need to DELETE "old" data. If you are using the partition scheme shown above for the employees table, you can simply use ALTER table employees DROP PARTITION p0; DELETE all lines related to employees who stopped working for the company before 1991. For a table with many rows, this is better than running a DELETE query (such as DELETE from employees where year < = 1990;) Much more efficient.
- You want to use columns that contain date or time values, or contain values from other series.
- You often run queries that depend directly on the columns used to partition the table. For example, when EXPLAIN SELECT COUNT(*) FROM employees WHERE separated BETWEEN '2000-01-01' AND '2000-12-31' group by store is executed_ id; When querying, MySQL can quickly determine that only p2 partitions need to be scanned, because the remaining partitions cannot contain any records that meet the WHERE clause.
A variation of this partition type is the RANGE COLUMNS partition. Partitioning through RANGE COLUMNS allows you to define partition ranges using multiple columns. These partition ranges are applicable not only to row placement in partitions, but also to determining whether to include or exclude specific partitions when performing partition pruning.
You can also partition by time field type:
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE COLUMNS(joined) (
PARTITION p0 VALUES LESS THAN ('1960-01-01'),
PARTITION p1 VALUES LESS THAN ('1970-01-01'),
PARTITION p2 VALUES LESS THAN ('1980-01-01'),
PARTITION p3 VALUES LESS THAN ('1990-01-01'),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
2.2 list partition
List partitioning in MySQL is similar to RANGE partitioning in many ways. As with partitioning by RANGE, each partition must be explicitly defined. The main difference between the two partition types is that in a list partition, each partition is defined and selected according to the membership of a column value in a set of value list, rather than one of a continuous set of value ranges. This is achieved by using PARTITION by LIST(expr), where expr is a column value or an expression based on the column value and returns an integer value, and then defining each partition through VALUES IN (value_list), where value_ List is a comma separated list of integers.
Unlike in the case of defining partitions by scope, list partitions do not need to be declared in any particular order. More detailed syntax information.
For the following example, we assume that the basic definition of the table to be partitioned is provided by the following CREATE table statement:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
);
It is assumed that there are 20 audio-visual stores distributed in 4 franchised stores, as shown in the table below:
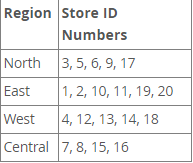
To partition this table into rows of stores belonging to the same region and store them in the same partition, you can use the CREATE table statement:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
This makes it easy to add or DELETE employee records related to a specific area in the table. For example, suppose that all stores in the western region are sold to another company. In MySQL 8.0, you can use the ALTER TABLE employees TRUNCATE PARTITION pWest query to DELETE all rows related to employees in this area, which is better than the equivalent DELETE statement DELETE FROM employees WHERE store_id In(4,12,13,14,18) is much more efficient. (using ALTER TABLE employees drop partition pwst will also DELETE all these rows, but the partition pwst will also be deleted from the table definition; you need to use the ALTER TABLE... ADD PARTITION statement to restore the original partition scheme of the table.)
Like RANGE partition, LIST partition can be combined with hash or key partition to generate composite partition (sub partition).
Unlike the RANGE PARTITION, there is no "capture all" like MAXVALUE; All expected values of the PARTITION expression should be included in the value in the PARTITION... (...) clause. An INSERT statement containing an unmatched PARTITION column value fails with an error, as shown in the following example:
mysql> CREATE TABLE h2 (
-> c1 INT,
-> c2 INT
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (1, 4, 7),
-> PARTITION p1 VALUES IN (2, 5, 8)
-> );
Query OK, 0 rows affected (0.11 sec)
mysql> INSERT INTO h2 VALUES (3, 5);
ERROR 1525 (HY000): Table has no partition for value 3
When an INSERT statement is used to INSERT multiple rows of data into an InnoDB table, InnoDB will treat the statement as a transaction. Therefore, any mismatched value will cause the statement to fail completely, so no rows will be inserted.
Use the IGNORE keyword to IGNORE such errors. If you do, do not insert rows that contain mismatched partition column values, but insert any rows that match values, and no errors are reported:
mysql> TRUNCATE h2; Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM h2; Empty set (0.00 sec) mysql> INSERT IGNORE INTO h2 VALUES (2, 5), (6, 10), (7, 5), (3, 1), (1, 9); Query OK, 3 rows affected (0.00 sec) Records: 5 Duplicates: 2 Warnings: 0 mysql> SELECT * FROM h2; +------+------+ | c1 | c2 | +------+------+ | 7 | 5 | | 1 | 9 | | 2 | 5 | +------+------+ 3 rows in set (0.00 sec)
MySQL 8.0 also provides support for LIST COLUMNS partition, which is a variant of LIST partition. It allows you to partition columns with columns other than integer types, and use multiple columns as partition keys
2.3 colonies partition
The next two sections discuss COLUMNS partitions, which are variants of RANGE and LIST partitions. Column partitioning allows multiple COLUMNS to be used in the partitioning key. All of these COLUMNS are considered in order to place rows in partitions and to determine which partitions to check in partition pruning to match rows.
In addition, both the RANGE COLUMNS partition and the LIST COLUMNS partition support the use of non integer columns to define value ranges or list members. The allowed data types are shown in the following table:
- All integer types: TINYINT, SMALLINT, mediamint, INT (integer), BIGINT. (this is the same as partitioning by RANGE and LIST.)
Other numeric data types, such as DECIMAL or float, are not supported as partition columns. - Date and DATETIME.
Columns that use other data types related to date or time are not supported as partition columns. - The following string types: CHAR, VARCHAR, BINARY, VARBINARY.
TEXT and BLOB columns are not supported as partition columns.
2.3.1 RANGE COLUMNS partition
A range column partition is similar to a range partition, but allows you to define a partition using a range based on multiple column values. In addition, you can define ranges using type columns of non integer types.
The difference between RANGE COLUMNS partition and RANGE partition is mainly reflected in the following aspects:
- RANGE COLUMNS does not accept expressions, only column names.
- RANGE COLUMNS accepts a list of one or more columns.
The RANGE COLUMNS partition is based on comparisons between tuples (list of column values), not scalar values. Row placement in the RANGE COLUMNS partition is also based on comparisons between tuples. - RANGE column partition column is not limited to integer column; String, DATE, and DATETIME columns can also be used as partition columns.
The basic syntax for creating a RANGE COLUMNS partition table is as follows:
CREATE TABLE table_name
PARTITIONED BY RANGE COLUMNS(column_list) (
PARTITION partition_name VALUES LESS THAN (value_list)[,
PARTITION partition_name VALUES LESS THAN (value_list)][,
...]
)
column_list:
column_name[, column_name][, ...]
value_list:
value[, value][, ...]
In the syntax just shown, column_list is a list of one or more columns (sometimes called partitioned column list), value_list is a list of values (that is, it is a list of partition defined values). You must provide a value for each partition definition_ List, and each value_ The number of values of list must be the same as column_list has the same number of columns. In general, if you use n columns in the columns clause, you must provide a list of N values for each VALUES LESS THAN clause.
The elements in the partition column list and the value list that defines each partition must appear in the same order. In addition, each element in the value list must have the same data type as the corresponding element in the column list. However, the order of column names in the partitioned column list and value list does not have to be the same as the order of table column definitions in the main part of the CREATE TABLE statement. Like a table partitioned by RANGE, you can use MAXVALUE to represent a value so that any legal value inserted into a given column is always less than this value. The following is an example of a CREATE TABLE statement that helps illustrate all of these points:
mysql> CREATE TABLE rcx (
-> a INT,
-> b INT,
-> c CHAR(3),
-> d INT
-> )
-> PARTITION BY RANGE COLUMNS(a,d,c) (
-> PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
-> PARTITION p1 VALUES LESS THAN (10,20,'mmm'),
-> PARTITION p2 VALUES LESS THAN (15,30,'sss'),
-> PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
-> );
Query OK, 0 rows affected (0.15 sec)
Table rcx contains columns a, b, c, d. The list of partitioned columns provided to the columns clause uses three of these columns in the order a, d, c. Each value list used to define the partition contains three values in the same order; That is, each value list tuple has the form (INT, INT, CHAR(3)), which corresponds to the data type used by columns a, d and c (in this order).
The tuple inserted by the row is compared with the tuple used to define the table partition in the values less than clause to determine where the row is placed in the partition. Because we compare tuples (that is, lists or collections of values) rather than scalar values, the semantics of values less than used in the RANGE COLUMNS partition is somewhat different from that in the case of simple RANGE partitions. In the RANGE partition, the row whose generated expression value is equal to a limit value in values less than will never be placed in the corresponding partition; However, when a RANGE COLUMNS partition is used, sometimes a row whose value of the first element of the partition column list is equal to the value of the first element in the VALUES LESS THAN value list may be placed in the corresponding partition.
CREATE TABLE r1 (
a INT,
b INT
)
PARTITION BY RANGE (a) (
PARTITION p0 VALUES LESS THAN (5),
PARTITION p1 VALUES LESS THAN (MAXVALUE)
);
If we insert 3 rows in this table, the column value for each row is 5, and all 3 rows are stored in partition p1, because a column value is not less than 5 in each case, we can see the INFORMATION_SCHEMA by executing the appropriate query. Partition table:
mysql> INSERT INTO r1 VALUES (5,10), (5,11), (5,12);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT PARTITION_NAME,TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'r1';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 0 |
| p1 | 3 |
+----------------+------------+
2 rows in set (0.00 sec)
Now consider a similar table rc1, which uses RANGE COLUMNS partition. COLUMNS a and b are referenced in the COLUMNS clause, as follows:
CREATE TABLE rc1 (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a, b) (
PARTITION p0 VALUES LESS THAN (5, 12),
PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE)
);
If we insert exactly the same rows in rc1 as in r1, the distribution of these rows will be very different:
mysql> INSERT INTO rc1 VALUES (5,10), (5,11), (5,12);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT PARTITION_NAME,TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'rc1';
+--------------+----------------+------------+
| TABLE_SCHEMA | PARTITION_NAME | TABLE_ROWS |
+--------------+----------------+------------+
| p | p0 | 2 |
| p | p1 | 1 |
+--------------+----------------+------------+
2 rows in set (0.00 sec)
This is because we compare rows rather than scalar values. We can compare the inserted row value with the restricted row value of the values then less then clause, which is used to define partition p0 in table rc1, as follows:
mysql> SELECT (5,10) < (5,12), (5,11) < (5,12), (5,12) < (5,12); +-----------------+-----------------+-----------------+ | (5,10) < (5,12) | (5,11) < (5,12) | (5,12) < (5,12) | +-----------------+-----------------+-----------------+ | 1 | 1 | 0 | +-----------------+-----------------+-----------------+ 1 row in set (0.00 sec)
The values of the two tuples (5,10) and (5,11) are less than (5,12), so they are stored in partition p0. Because 5 is not less than 5, 12 is not less than 12, (5,12) is considered not less than (5,12) and stored in partition p1.
The SELECT statement in the previous example can also be written using an explicit row constructor, as shown below:
SELECT ROW(5,10) < ROW(5,12), ROW(5,11) < ROW(5,12), ROW(5,12) < ROW(5,12);
More information about using row constructors in MySQL.
For a RANGE COLUMNS partitioned table that uses only a single partitioned column, the row storage in the partition is the same as that of an equivalent table that uses a RANGE partition. The following CREATE TABLE statement creates a table partitioned by RANGE COLUMNS using 1 partitioned column:
CREATE TABLE rx (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS (a) (
PARTITION p0 VALUES LESS THAN (5),
PARTITION p1 VALUES LESS THAN (MAXVALUE)
);
If we insert rows (5,10), (5,11) and (5,12) into this table, we can see that their positions are the same as the table r we created and populated earlier:
mysql> INSERT INTO rx VALUES (5,10), (5,11), (5,12);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT PARTITION_NAME,TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'rx';
+--------------+----------------+------------+
| TABLE_SCHEMA | PARTITION_NAME | TABLE_ROWS |
+--------------+----------------+------------+
| p | p0 | 0 |
| p | p1 | 3 |
+--------------+----------------+------------+
2 rows in set (0.00 sec)
You can also create tables that are partitioned by RANGE COLUMNS, where the limit values of one or more columns are repeated in successive partition definitions. This can be done as long as the tuples used to define the column values of the partition are strictly increased. For example, the following CREATE TABLE statements are valid:
CREATE TABLE rc2 (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a,b) (
PARTITION p0 VALUES LESS THAN (0,10),
PARTITION p1 VALUES LESS THAN (10,20),
PARTITION p2 VALUES LESS THAN (10,30),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
CREATE TABLE rc3 (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a,b) (
PARTITION p0 VALUES LESS THAN (0,10),
PARTITION p1 VALUES LESS THAN (10,20),
PARTITION p2 VALUES LESS THAN (10,30),
PARTITION p3 VALUES LESS THAN (10,35),
PARTITION p4 VALUES LESS THAN (20,40),
PARTITION p5 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
The following statement is also successful, even if it may not appear at first glance, because the limit values of column b are 25 partition p0 and 20 partition p1, and the column c 100 values of limiting partition p1 and p2 50 partition:
CREATE TABLE rc4 (
a INT,
b INT,
c INT
)
PARTITION BY RANGE COLUMNS(a,b,c) (
PARTITION p0 VALUES LESS THAN (0,25,50),
PARTITION p1 VALUES LESS THAN (10,20,100),
PARTITION p2 VALUES LESS THAN (10,30,50)
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);
When designing a table partitioned by RANGE COLUMNS, you can always test the continuous partition definition by comparing the required tuples with the mysql client, as follows:
mysql> SELECT (0,25,50) < (10,20,100), (10,20,100) < (10,30,50); +-------------------------+--------------------------+ | (0,25,50) < (10,20,100) | (10,20,100) < (10,30,50) | +-------------------------+--------------------------+ | 1 | 1 | +-------------------------+--------------------------+ 1 row in set (0.00 sec)
If a CREATE TABLE statement contains partition definitions that are not strictly incremented, it will fail with errors, as shown in the following example:
mysql> CREATE TABLE rcf (
-> a INT,
-> b INT,
-> c INT
-> )
-> PARTITION BY RANGE COLUMNS(a,b,c) (
-> PARTITION p0 VALUES LESS THAN (0,25,50),
-> PARTITION p1 VALUES LESS THAN (20,20,100),
-> PARTITION p2 VALUES LESS THAN (10,30,50),
-> PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
-> );
ERROR 1493 (HY000): VALUES LESS THAN value must be strictly increasing for each partition
When you encounter such errors, you can infer which partition definitions are invalid by comparing "less than" between their column lists. In this case, the problem lies in the definition of partition p2, because the tuple used to define it is not less than the tuple used to define partition p3, as follows:
mysql> SELECT (0,25,50) < (20,20,100), (20,20,100) < (10,30,50); +-------------------------+--------------------------+ | (0,25,50) < (20,20,100) | (20,20,100) < (10,30,50) | +-------------------------+--------------------------+ | 1 | 0 | +-------------------------+--------------------------+ 1 row in set (0.00 sec)
When using the RANGE column, MAXVALUE may also appear in multiple VALUES LESS than clauses. However, in a continuous partition definition, the limit value of each column should be incremented. There should be no more than one defined partition, where MAXVALUE is used as the upper limit of all column values, and this partition definition should appear in the partition... Value is less than clause. In addition, you cannot use MAXVALUE as the limit value for the first column in multiple partition definitions.
As mentioned earlier, using RANGE COLUMNS partitions, you can also use non integer columns as partition columns. Consider a table named employees (unpartitioned), which is created using the following statement:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);
Using the RANGE COLUMNS partition, you can create a version of this table and store each row in one of the four partitions according to the employee's last name, as shown below:
CREATE TABLE employees_by_lname (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE COLUMNS (lname) (
PARTITION p0 VALUES LESS THAN ('g'),
PARTITION p1 VALUES LESS THAN ('m'),
PARTITION p2 VALUES LESS THAN ('t'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
Alternatively, you can implement the partition of the employees table created earlier by executing the following ALTER table statement:
ALTER TABLE employees PARTITION BY RANGE COLUMNS (lname) (
PARTITION p0 VALUES LESS THAN ('g'),
PARTITION p1 VALUES LESS THAN ('m'),
PARTITION p2 VALUES LESS THAN ('t'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
Similarly, you can use the ALTER table statement to partition the employees table, and store each row in a partition of multiple partitions, which is based on the ten years of employment of the corresponding employee:
ALTER TABLE employees PARTITION BY RANGE COLUMNS (hired) (
PARTITION p0 VALUES LESS THAN ('1970-01-01'),
PARTITION p1 VALUES LESS THAN ('1980-01-01'),
PARTITION p2 VALUES LESS THAN ('1990-01-01'),
PARTITION p3 VALUES LESS THAN ('2000-01-01'),
PARTITION p4 VALUES LESS THAN ('2010-01-01'),
PARTITION p5 VALUES LESS THAN (MAXVALUE)
);
2.3.2 LIST COLUMNS
MySQL 8.0 supports LIST COLUMNS partitions. This is a variant of LIST partitioning, which allows multiple columns to be used as partitioning keys, and columns of data types other than integer types are used as partitioning columns; You can use string types, DATE, and DATETIME columns.
Suppose your enterprise has customers in 12 cities. For the purpose of sales and marketing, you divide it into 4 regions of 3 cities, as shown in the following table:
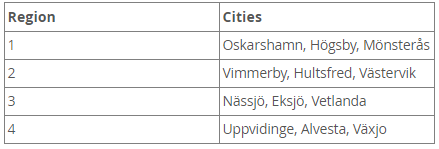
Using the LIST COLUMNS partition, you can create a table for customer data and assign a row to any of the four partitions corresponding to these regions according to the name of the customer's city, as shown below:
CREATE TABLE customers_1 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(city) (
PARTITION pRegion_1 VALUES IN('Oskarshamn', 'Högsby', 'Mönsterås'),
PARTITION pRegion_2 VALUES IN('Vimmerby', 'Hultsfred', 'Västervik'),
PARTITION pRegion_3 VALUES IN('Nässjö', 'Eksjö', 'Vetlanda'),
PARTITION pRegion_4 VALUES IN('Uppvidinge', 'Alvesta', 'Växjo')
);
As with partitioning by RANGE COLUMNS, you do not need to use expressions in the COLUMNS() clause to convert column values to integers. (in fact, COLUMNS() does not allow expressions other than column names.)
You can also use the DATE and DATETIME columns, as shown in the following example, which uses the same customers as shown earlier_ 1 the table has the same name and column, but the row is stored in one of the four partitions using the LIST COLUMNS partition based on the updated column, depending on when the customer account is scheduled to be updated in February 2010:
CREATE TABLE customers_2 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(renewal) (
PARTITION pWeek_1 VALUES IN('2010-02-01', '2010-02-02', '2010-02-03',
'2010-02-04', '2010-02-05', '2010-02-06', '2010-02-07'),
PARTITION pWeek_2 VALUES IN('2010-02-08', '2010-02-09', '2010-02-10',
'2010-02-11', '2010-02-12', '2010-02-13', '2010-02-14'),
PARTITION pWeek_3 VALUES IN('2010-02-15', '2010-02-16', '2010-02-17',
'2010-02-18', '2010-02-19', '2010-02-20', '2010-02-21'),
PARTITION pWeek_4 VALUES IN('2010-02-22', '2010-02-23', '2010-02-24',
'2010-02-25', '2010-02-26', '2010-02-27', '2010-02-28')
);
This is feasible, but if the number of dates involved increases very large, definition and maintenance become very troublesome; In this case, it is usually more practical to use RANGE or RANGE COLUMNS partitions. In this example, because the column we want to use as the partition key is the DATE column, we use the RANGE COLUMNS partition, as shown below:
CREATE TABLE customers_3 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY RANGE COLUMNS(renewal) (
PARTITION pWeek_1 VALUES LESS THAN('2010-02-09'),
PARTITION pWeek_2 VALUES LESS THAN('2010-02-15'),
PARTITION pWeek_3 VALUES LESS THAN('2010-02-22'),
PARTITION pWeek_4 VALUES LESS THAN('2010-03-01')
);
2.4 hash partition
HASH partition is mainly used to ensure that data is evenly distributed among a predetermined number of partitions. For a range partition or a list partition, you must explicitly specify in which partition a given column value or a set of column values should be stored; When using HASH partitioning, you can handle this decision for you. You only need to specify the column value or expression according to the column value to HASH and the number of partitions to divide the partitioned table.
In order to partition the table using HASH partition, a partition BY HASH (expr) clause needs to be appended after the CREATE table statement, where expr is an expression that returns an integer. This can be the name of a column whose type is one of the integer types of MySQL. In addition, you probably want to use PARTITIONS num, where num is a positive integer indicating the number of partitions into which the table is to be divided.
The following statement creates a pair of stores_ The ID column uses a hashed table and is divided into four partitions:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
If the PARTITIONS clause is not included, the number of PARTITIONS is 1 by default; Using the sections keyword without a number after it will result in a syntax error.
You can also use SQL expressions that return integers for expr. For example, you might want to divide based on the year employees were hired. This can be done:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH( YEAR(hired) )
PARTITIONS 4;
expr must return a very, non random integer value (in other words, it should be variable but deterministic). You should also remember that the expression evaluates whenever a row is inserted or updated (or possibly deleted); This means that very complex expressions can cause performance problems, especially when performing an operation that affects a large number of rows, such as batch insertion.
The most effective hash function is to operate on a single table column, and its value increases or decreases in line with the column value, because this allows "pruning" of the partition range. That is, the closer the expression changes with the value of the column on which it is based, the more effectively MySQL can use the expression for hash partitioning.
For example, where DATE_ Col is a column of type DATE, then the expression TO_DAYS(date_col) is said to follow DATE directly_ The value of col changes because for DATE_ Every time the value of col changes, the value of the expression changes in a consistent way. The expression YEAR(date_col) is relative to DATE_ Col doesn't change like TO_DAYS(date_col) is so direct, because it's not DATE_ Every possible change in col will produce an equivalent change of YEAR(date_col). Nevertheless, YEAR(date_col) is a good candidate for hash functions because it follows DATE directly_ Col, and DATE_ The change of col cannot lead to a disproportionate change in YEAR(date_col).
In contrast, suppose you have an INT_ Col, whose type is INT. Now consider the expression POW(5-int_col,3) + 6. This is a bad choice for hash functions because changing INT_ The value of col does not necessarily result in a proportional change in the value of the expression. Change INT by the given number_ The value of col can vary greatly in the value of the expression. For example, set INT_ Changing the value of col from 5 to 6 causes the expression value to change to - 1, but INT_ Changing the value of col from 6 to 7 causes the expression value to change to - 7.
In other words, the closer the relationship between the column value and the value of the expression, the more consistent it is with the line depicted by the equation y = CX (where c is a non-zero constant), and the more suitable the expression is for hashing. This is related to the fact that the more nonlinear an expression is, the more uneven the data distribution between partitions it often produces.
Theoretically, expressions containing multiple column values can also be trimmed, but determining which such expression is appropriate is quite difficult and time-consuming. Therefore, hash expressions involving multiple columns are not particularly recommended.
When using PARTITION BY HASH, the storage engine determines which partition in the num partition to use according to the modulus of the expression result. In other words, for a given expression expr, the partition in which the record is stored is the partition number N, where N = MOD(expr, num). Suppose that table t1 is defined as follows, so it has four partitions:
CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE)
PARTITION BY HASH( YEAR(col3) )
PARTITIONS 4;
MySQL 8.0 also supports a variant of HASH partitioning called linear hashing, which uses a more complex algorithm to determine the location of new rows inserted into the partitioned table.
User supplied expressions are evaluated each time a record is inserted or updated. Depending on the situation, you can also evaluate records when they are deleted.
2.4.1 LINEAR HASH partition
MySQL also supports linear hash, which is different from conventional hash in that linear hash uses linear quadratic power algorithm, while conventional hash uses the modulus of hash function value.
Syntactically, the only difference between a LINEAR hash partition and a regular hash is the addition of the LINEAR keyword in the PARTITION BY clause, as shown below:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 4;
Given the expression expr, when linear hash is used, the partition in which records are stored is the partition number N in num partitions, where n is derived according to the following algorithm:
- Find the next power greater than num by 2. We call this value V; Can be calculated as:
V = POWER(2, CEILING(LOG(2, num)))
(Suppose that num is 13. Then LOG(2,13) is 3.7004397181411. CEILING(3.7004397181411) is 4, and V = POWER(2,4), which is 16.)
2. Set N = F(column_list) & (V - 1).
3. While N >= num:
Set V = V / 2
Set N = N & (V - 1)
Suppose that table t1 with linear hash partition has 6 partitions, and create it with the following statement:
CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE)
PARTITION BY LINEAR HASH( YEAR(col3) )
PARTITIONS 6;
Now suppose you want to insert two records with col3 column values' 2003-04-14 'and' 1998-10-19 'in t1. The partition number of the first one is as follows:
V = POWER(2, CEILING( LOG(2,6) )) = 8
N = YEAR('2003-04-14') & (8 - 1)
= 2003 & 7
= 3
(3 >= 6 is FALSE: record stored in partition #3)
The partition number for storing the second record is as follows:
V = 8
N = YEAR('1998-10-19') & (8 - 1)
= 1998 & 7
= 6
(6 >= 6 is TRUE: additional step required)
N = 6 & ((8 / 2) - 1)
= 6 & 3
= 2
(2 >= 6 is FALSE: record stored in partition #2)
The advantage of partitioning through linear hashing is that it is much faster to add, delete, merge, and split partitions, which is beneficial when dealing with tables containing large amounts of (tb) data. The disadvantage is that the data is less likely to be evenly distributed between partitions than the distribution obtained using conventional hash partitions.
2.5 key partition
Key partition is similar to hash partition. Except that hash partition uses user-defined expressions, MySQL server provides hash functions for key partition. The NDB cluster uses MD5() for this purpose; For tables that use other storage engines, the server uses its own internal hash function.
The syntax rule of CREATE TABLE... PARTITION BY KEY is similar to creating a hash partitioned table. Here are the main differences:
- Use KEY instead of HASH.
- KEY only accepts a list containing 0 or more column names. If a table has a primary KEY, any column used as a partition KEY must contain some or all of the primary keys of the table. If no column name is specified as the partition KEY, the primary KEY of the table (if any) is used. For example, the following CREATE TABLE statement is valid in MySQL 8.0:
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
If there is no primary key but there is a unique key, the unique key will be used for the partition key:
CREATE TABLE k1 (
id INT NOT NULL,
name VARCHAR(20),
UNIQUE KEY (id)
)
PARTITION BY KEY()
PARTITIONS 2;
However, if the unique key column is not defined as not NULL, the previous statement will fail.
In both cases, the partitioning key is an id column, even if it does not appear in the output of SHOW CREATE TABLE or information_ Division of schema_ In the expression column. Partition table.
Unlike other partition types, the columns used by the KEY partition are not limited to integer or NULL values. For example, the following CREATE TABLE statement is valid:
CREATE TABLE tm1 (
s1 CHAR(32) PRIMARY KEY
)
PARTITION BY KEY(s1)
PARTITIONS 10;
If you want to specify a different partition type, the previous statement will be invalid. (in this case, simply using PARTITION BY KEY() is also effective, and has the same effect as PARTITION BY KEY(s1), because s1 is the primary key of the table.)
Partitioning keys do not support columns with index prefixes. This means that CHAR, VARCHAR, BINARY, and VARBINARY columns can be used in partition keys as long as they do not use prefixes; Because the BLOB and TEXT columns must be prefixed in the index definition, it is not possible to use both types of columns in the partition key. Before MySQL 8.0.21, prefix columns are allowed to be used when creating, modifying or upgrading partitioned tables, even if they are not included in the partition key of the table; In MySQL 8.0.21 and later versions, this allowed behavior is not supported. When one or more such columns are used, the server will display appropriate warnings or errors. For more information and examples, see column index prefixes that are not supported by key partitions.
You can also partition tables with linear keys. Here is a simple example:
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;
2.6 subarea
Partitions - also known as composite partitions - are further partitions of each partition in the partition table. Consider the following CREATE TABLE statement:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
Table ts has three RANGE partitions. Each partition (p0, p1 and p2) is further divided into two sub partitions. In fact, the entire table is divided into 3 * 2 = 6 partitions. However, due to the function of the PARTITION BY RANGE clause, the first two only store records with values less than 1990 in the purchased columns.
Tables partitioned by RANGE or LIST can be sub partitioned. Sub partitions can use HASH or KEY partitions. This is also called composite segmentation.
You can also explicitly define a sub partition and use the sub partition clause to specify the options for a single sub partition. For example, a more detailed way to create the same table ts as in the previous example is:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
Here are some syntactic considerations:
- Each partition must have the same number of child partitions.
- If you explicitly define any child partitions using subartition on any partition of a partitioned table, you must define all child partitions. In other words, the following statement fails:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s2,
SUBPARTITION s3
)
);
Even with subartitions 2, this statement will still fail.
- Each subartition clause must contain (at least) the name of the child partition. Otherwise, you can set any desired option for the child partition, or allow it to set the default setting for that option.
- The child partition name must be unique throughout the table. For example, the following CREATE TABLE statement is valid:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
2.7 how MySQL partitions handle null values
Partitions in MySQL do not allow null as the value of partition expressions, whether column values or user provided expressions. Even if NULL is allowed as the value of an expression, otherwise an integer must be generated. It is important to remember that null is not a number. MySQL partition implementation treats null as smaller than any non null value, just like ORDER BY.
This means that the processing of NULL is different between different types of partitions. If not prepared, unexpected behavior may occur.
Use RANGE partition to handle NULL. If a row is inserted into a table partitioned by RANGE and the column value used to determine the partition is NULL, the row is inserted into the lowest partition. Consider these two tables in a database named p. the creation method is as follows:
mysql> CREATE TABLE t1 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY RANGE(c1) (
-> PARTITION p0 VALUES LESS THAN (0),
-> PARTITION p1 VALUES LESS THAN (10),
-> PARTITION p2 VALUES LESS THAN MAXVALUE
-> );
Query OK, 0 rows affected (0.09 sec)
mysql> CREATE TABLE t2 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY RANGE(c1) (
-> PARTITION p0 VALUES LESS THAN (-5),
-> PARTITION p1 VALUES LESS THAN (0),
-> PARTITION p2 VALUES LESS THAN (10),
-> PARTITION p3 VALUES LESS THAN MAXVALUE
-> );
Query OK, 0 rows affected (0.09 sec)
You can see the two CREATE TABLE statements in information_ Partitions created in the partitions table of the schema database:
mysql> SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH
> FROM INFORMATION_SCHEMA.PARTITIONS
> WHERE TABLE_SCHEMA = 'p' AND TABLE_NAME LIKE 't_';
+------------+----------------+------------+----------------+-------------+
| TABLE_NAME | PARTITION_NAME | TABLE_ROWS | AVG_ROW_LENGTH | DATA_LENGTH |
+------------+----------------+------------+----------------+-------------+
| t1 | p0 | 0 | 0 | 0 |
| t1 | p1 | 0 | 0 | 0 |
| t1 | p2 | 0 | 0 | 0 |
| t2 | p0 | 0 | 0 | 0 |
| t2 | p1 | 0 | 0 | 0 |
| t2 | p2 | 0 | 0 | 0 |
| t2 | p3 | 0 | 0 | 0 |
+------------+----------------+------------+----------------+-------------+
7 rows in set (0.00 sec)
Now, let's fill these tables with a single row, which contains an empty column as the partition key, and verify the row insertion using a pair of SELECT statements:
mysql> INSERT INTO t1 VALUES (NULL, 'mothra'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO t2 VALUES (NULL, 'mothra'); Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM t1; +------+--------+ | id | name | +------+--------+ | NULL | mothra | +------+--------+ 1 row in set (0.00 sec) mysql> SELECT * FROM t2; +------+--------+ | id | name | +------+--------+ | NULL | mothra | +------+--------+ 1 row in set (0.00 sec)
Through INFORMATION_SCHEMA reruns the previous query to see which partitions are used to store the inserted rows. Partition and check output:
mysql> SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH
> FROM INFORMATION_SCHEMA.PARTITIONS
> WHERE TABLE_SCHEMA = 'p' AND TABLE_NAME LIKE 't_';
+------------+----------------+------------+----------------+-------------+
| TABLE_NAME | PARTITION_NAME | TABLE_ROWS | AVG_ROW_LENGTH | DATA_LENGTH |
+------------+----------------+------------+----------------+-------------+
| t1 | p0 | 1 | 20 | 20 |
| t1 | p1 | 0 | 0 | 0 |
| t1 | p2 | 0 | 0 | 0 |
| t2 | p0 | 1 | 20 | 20 |
| t2 | p1 | 0 | 0 | 0 |
| t2 | p2 | 0 | 0 | 0 |
| t2 | p3 | 0 | 0 | 0 |
+------------+----------------+------------+----------------+-------------+
7 rows in set (0.01 sec)
You can also demonstrate that these rows are stored in the lowest numbered partition of each table by deleting these partitions, and then rerun the SELECT statement:
mysql> ALTER TABLE t1 DROP PARTITION p0; Query OK, 0 rows affected (0.16 sec) mysql> ALTER TABLE t2 DROP PARTITION p0; Query OK, 0 rows affected (0.16 sec) mysql> SELECT * FROM t1; Empty set (0.00 sec) mysql> SELECT * FROM t2; Empty set (0.00 sec)
NULL is also handled in this way for partition expressions that use SQL functions. Suppose we use the CREATE table statement to define a table, as follows:
CREATE TABLE tndate (
id INT,
dt DATE
)
PARTITION BY RANGE( YEAR(dt) ) (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
Like other MySQL functions, YEAR(NULL) returns NULL. A row with a NULL dt column value is treated as if the value of the partition expression is less than any other value, so it is inserted into the partition p0.
Use LIST partition to handle NULL. The table of a LIST partition allows NULL values if and only if a partition is defined using a LIST of values containing NULL. On the contrary, if the table of the LIST partition does not explicitly use NULL in the value LIST, the row that causes the value of the partition expression to be NULL will be rejected, as shown in the following example:
mysql> CREATE TABLE ts1 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (0, 3, 6),
-> PARTITION p1 VALUES IN (1, 4, 7),
-> PARTITION p2 VALUES IN (2, 5, 8)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO ts1 VALUES (9, 'mothra');
ERROR 1504 (HY000): Table has no partition for value 9
mysql> INSERT INTO ts1 VALUES (NULL, 'mothra');
ERROR 1504 (HY000): Table has no partition for value NULL
Only rows with c1 values between 0 and 8 can be inserted into ts1. NULL does not fall into this range, just like the number 9. We can create tables ts2 and ts3, whose value list contains NULL, as shown below:
mysql> CREATE TABLE ts2 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (0, 3, 6),
-> PARTITION p1 VALUES IN (1, 4, 7),
-> PARTITION p2 VALUES IN (2, 5, 8),
-> PARTITION p3 VALUES IN (NULL)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE TABLE ts3 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (0, 3, 6),
-> PARTITION p1 VALUES IN (1, 4, 7, NULL),
-> PARTITION p2 VALUES IN (2, 5, 8)
-> );
Query OK, 0 rows affected (0.01 sec)
When defining a list of values for a partition, you can (and should) treat NULL as any other value. For example, VALUES IN (NULL) and VALUES IN (1, 4, 7, NULL) are valid, VALUES IN (1, NULL, 4, 7), VALUES IN (NULL, 1, 4, 7), and so on. You can insert a row with NULL column c1 in each table ts2 and ts3:
mysql> INSERT INTO ts2 VALUES (NULL, 'mothra'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO ts3 VALUES (NULL, 'mothra'); Query OK, 1 row affected (0.00 sec)
Through INFORMATION_SCHEMA issues the appropriate query. Partition, you can determine which partitions are used to store the rows just inserted (we assume that, as in the previous example, the partition table is created in the p database):
mysql> SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH
> FROM INFORMATION_SCHEMA.PARTITIONS
> WHERE TABLE_SCHEMA = 'p' AND TABLE_NAME LIKE 'ts_';
+------------+----------------+------------+----------------+-------------+
| TABLE_NAME | PARTITION_NAME | TABLE_ROWS | AVG_ROW_LENGTH | DATA_LENGTH |
+------------+----------------+------------+----------------+-------------+
| ts2 | p0 | 0 | 0 | 0 |
| ts2 | p1 | 0 | 0 | 0 |
| ts2 | p2 | 0 | 0 | 0 |
| ts2 | p3 | 1 | 20 | 20 |
| ts3 | p0 | 0 | 0 | 0 |
| ts3 | p1 | 1 | 20 | 20 |
| ts3 | p2 | 0 | 0 | 0 |
+------------+----------------+------------+----------------+-------------+
7 rows in set (0.01 sec)
As shown earlier in this section, you can also verify which partitions are used to store these rows by deleting these partitions and then performing SELECT.
Use HASH and KEY partitions to handle NULL. NULL processing is slightly different for tables partitioned by HASH or KEY. In these cases, any partition expression that produces a NULL value is treated as having a return value of zero. We can verify this behavior by examining the impact on the file system of creating a HASH partitioned table and populating it with records containing appropriate values. Suppose you have a table th (also in the p database) created with the following statement:
mysql> CREATE TABLE th (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY HASH(c1)
-> PARTITIONS 2;
Query OK, 0 rows affected (0.00 sec)
Partitions belonging to this table can be viewed using the following query:
mysql> SELECT TABLE_NAME,PARTITION_NAME,TABLE_ROWS,AVG_ROW_LENGTH,DATA_LENGTH
> FROM INFORMATION_SCHEMA.PARTITIONS
> WHERE TABLE_SCHEMA = 'p' AND TABLE_NAME ='th';
+------------+----------------+------------+----------------+-------------+
| TABLE_NAME | PARTITION_NAME | TABLE_ROWS | AVG_ROW_LENGTH | DATA_LENGTH |
+------------+----------------+------------+----------------+-------------+
| th | p0 | 0 | 0 | 0 |
| th | p1 | 0 | 0 | 0 |
+------------+----------------+------------+----------------+-------------+
2 rows in set (0.00 sec)
Table per partition_ Rows is 0. Now insert two rows with c1 column values of NULL and 0 into th and verify that they are inserted, as follows:
mysql> INSERT INTO th VALUES (NULL, 'mothra'), (0, 'gigan'); Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM th; +------+---------+ | c1 | c2 | +------+---------+ | NULL | mothra | +------+---------+ | 0 | gigan | +------+---------+ 2 rows in set (0.01 sec)
Recall that for any integer n, the value of NULL mod n is always NULL. For tables partitioned by HASH or KEY, this result will be used to determine the correct partition as 0. Check INFORMATION_SCHEMA. Again, we can see that both rows are inserted into partition p0:
mysql> SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH
> FROM INFORMATION_SCHEMA.PARTITIONS
> WHERE TABLE_SCHEMA = 'p' AND TABLE_NAME ='th';
+------------+----------------+------------+----------------+-------------+
| TABLE_NAME | PARTITION_NAME | TABLE_ROWS | AVG_ROW_LENGTH | DATA_LENGTH |
+------------+----------------+------------+----------------+-------------+
| th | p0 | 2 | 20 | 20 |
| th | p1 | 0 | 0 | 0 |
+------------+----------------+------------+----------------+-------------+
2 rows in set (0.00 sec)
By repeating the previous example and using PARTITION By KEY instead of PARTITION By HASH in the table definition, you can verify that NULL is also treated as 0 for this type of partition.
III Partition management
3.1 manage range and list partitions
The addition and deletion of range and list partitions are handled in a similar way, so we will discuss the management of these two partitions in this section.
Deleting a partition from a table partitioned by RANGE or LIST can be done using the ALTER table statement with the DROP partition option. Suppose you have created a table by RANGE, and then filled in 10 records with the following CREATE table and INSERT statements:
mysql> CREATE TABLE tr (id INT, name VARCHAR(50), purchased DATE)
-> PARTITION BY RANGE( YEAR(purchased) ) (
-> PARTITION p0 VALUES LESS THAN (1990),
-> PARTITION p1 VALUES LESS THAN (1995),
-> PARTITION p2 VALUES LESS THAN (2000),
-> PARTITION p3 VALUES LESS THAN (2005),
-> PARTITION p4 VALUES LESS THAN (2010),
-> PARTITION p5 VALUES LESS THAN (2015)
-> );
Query OK, 0 rows affected (0.28 sec)
mysql> INSERT INTO tr VALUES
-> (1, 'desk organiser', '2003-10-15'),
-> (2, 'alarm clock', '1997-11-05'),
-> (3, 'chair', '2009-03-10'),
-> (4, 'bookcase', '1989-01-10'),
-> (5, 'exercise bike', '2014-05-09'),
-> (6, 'sofa', '1987-06-05'),
-> (7, 'espresso maker', '2011-11-22'),
-> (8, 'aquarium', '1992-08-04'),
-> (9, 'study desk', '2006-09-16'),
-> (10, 'lava lamp', '1998-12-25');
Query OK, 10 rows affected (0.05 sec)
Records: 10 Duplicates: 0 Warnings: 0
You can see which items should be inserted into partition p2, as follows:
mysql> SELECT * FROM tr
-> WHERE purchased BETWEEN '1995-01-01' AND '1999-12-31';
+------+-------------+------------+
| id | name | purchased |
+------+-------------+------------+
| 2 | alarm clock | 1997-11-05 |
| 10 | lava lamp | 1998-12-25 |
+------+-------------+------------+
2 rows in set (0.00 sec)
You can also get this information through partition selection, as shown below:
mysql> SELECT * FROM tr PARTITION (p2); +------+-------------+------------+ | id | name | purchased | +------+-------------+------------+ | 2 | alarm clock | 1997-11-05 | | 10 | lava lamp | 1998-12-25 | +------+-------------+------------+ 2 rows in set (0.00 sec)
You can also get this information through partition selection, as shown below:
mysql> SELECT * FROM tr PARTITION (p2); +------+-------------+------------+ | id | name | purchased | +------+-------------+------------+ | 2 | alarm clock | 1997-11-05 | | 10 | lava lamp | 1998-12-25 | +------+-------------+------------+ 2 rows in set (0.00 sec)
To delete the partition named p2, execute the following command:
mysql> ALTER TABLE tr DROP PARTITION p2; Query OK, 0 rows affected (0.03 sec)
It is important to remember that when you delete a partition, you will also delete all data stored in that partition. You can see this by rerunning the previous SELECT query:
mysql> SELECT * FROM tr WHERE purchased
-> BETWEEN '1995-01-01' AND '1999-12-31';
Empty set (0.00 sec)
Therefore, you must have DROP permission on the table before executing ALTER table. Delete partitions on this table.
If you want to delete all data in all partitions while preserving the table definition and its partition mode, use the TRUNCATE table statement.
If you want to change the partition of a table without losing data, use ALTER table... To reorganize the partition. Information about REORGANIZE PARTITION.
If you execute a SHOW CREATE TABLE statement now, you can see how the partition composition of the table changes:
mysql> SHOW CREATE TABLE tr\G
*************************** 1. row ***************************
Table: tr
Create Table: CREATE TABLE `tr` (
`id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`purchased` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY RANGE ( YEAR(purchased))
(PARTITION p0 VALUES LESS THAN (1990) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1995) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2005) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (2010) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (2015) ENGINE = InnoDB) */
1 row in set (0.00 sec)
When you use the purchased column values (including '1995-01-01' and '2004-12-31') to insert new rows into the changed table, these rows are stored in partition p3. You can verify as follows:
mysql> INSERT INTO tr VALUES (11, 'pencil holder', '1995-07-12');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM tr WHERE purchased
-> BETWEEN '1995-01-01' AND '2004-12-31';
+------+----------------+------------+
| id | name | purchased |
+------+----------------+------------+
| 1 | desk organiser | 2003-10-15 |
| 11 | pencil holder | 1995-07-12 |
+------+----------------+------------+
2 rows in set (0.00 sec)
mysql> ALTER TABLE tr DROP PARTITION p3;
Query OK, 0 rows affected (0.03 sec)
mysql> SELECT * FROM tr WHERE purchased
-> BETWEEN '1995-01-01' AND '2004-12-31';
Empty set (0.00 sec)
The number of rows deleted from the table is reported by the server as ALTER table... DROP PARTITION, unlike the equivalent DELETE query.
To delete a LIST partition, the same ALTER TABLE... DROP PARTITION syntax is used to delete a RANGE partition. However, there is an important difference in the impact of using the table later: you can no longer insert any rows into the table that contain any values contained in the LIST of values that define the deleted partition. (see the example in "LIST Partitioning" in section 24.2.2.)
To add a new RANGE or list partition to a previously partitioned table, use ALTER table... To add a partition declaration. For tables partitioned by RANGE, this can be used to add a new RANGE to the end of the existing partition list. Suppose you have a partition table containing organization member data, which is defined as follows:
CREATE TABLE members (
id INT,
fname VARCHAR(25),
lname VARCHAR(25),
dob DATE
)
PARTITION BY RANGE( YEAR(dob) ) (
PARTITION p0 VALUES LESS THAN (1980),
PARTITION p1 VALUES LESS THAN (1990),
PARTITION p2 VALUES LESS THAN (2000)
);
It is further assumed that the minimum age of members is 16 years. As 2015 approaches, you realize that you must be ready to accept members born in 2000 (and beyond) as soon as possible. You can modify the membership table to accommodate new members born from 2000 to 2010, as follows:
ALTER TABLE members ADD PARTITION (PARTITION p3 VALUES LESS THAN (2010));
For tables partitioned by range, you can use ADD PARTITION to add a new partition only to the high end of the partition list. Attempting to add a new partition between or before existing partitions in this way will result in the following error:
mysql> ALTER TABLE members
> ADD PARTITION (
> PARTITION n VALUES LESS THAN (1970));
ERROR 1463 (HY000): VALUES LESS THAN value must be strictly »
increasing for each partition
You can solve this problem by reorganizing the first partition into two new partitions, like this:
ALTER TABLE members
REORGANIZE PARTITION p0 INTO (
PARTITION n0 VALUES LESS THAN (1970),
PARTITION n1 VALUES LESS THAN (1980)
);
Using SHOW CREATE TABLE, you can see that the ALTER TABLE statement has achieved the desired effect:
mysql> SHOW CREATE TABLE members\G
*************************** 1. row ***************************
Table: members
Create Table: CREATE TABLE `members` (
`id` int(11) DEFAULT NULL,
`fname` varchar(25) DEFAULT NULL,
`lname` varchar(25) DEFAULT NULL,
`dob` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY RANGE ( YEAR(dob))
(PARTITION n0 VALUES LESS THAN (1970) ENGINE = InnoDB,
PARTITION n1 VALUES LESS THAN (1980) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1990) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (2000) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2010) ENGINE = InnoDB) */
1 row in set (0.00 sec)
You can also use ALTER TABLE... ADD PARTITION to add a new partition to the table of the LIST partition. Suppose a table tt is defined with the following CREATE table statement:
CREATE TABLE tt (
id INT,
data INT
)
PARTITION BY LIST(data) (
PARTITION p0 VALUES IN (5, 10, 15),
PARTITION p1 VALUES IN (6, 12, 18)
);
You can add a new partition to store rows with data column values of 7, 14 and 21, as shown in the figure:
ALTER TABLE tt ADD PARTITION (PARTITION p2 VALUES IN (7, 14, 21));
Remember that you cannot add a new LIST partition that contains any values already contained in the existing partition value LIST. If you try to do this, an error results:
mysql> ALTER TABLE tt ADD PARTITION
> (PARTITION np VALUES IN (4, 8, 12));
ERROR 1465 (HY000): Multiple definition of same constant »
in list partitioning
Because any row with a data column value of 12 has been assigned to partition p1, a new partition containing 12 cannot be created in the value list of table tt. To do this, you can remove p1 and add np, plus a new definition of modified p1. However, as mentioned earlier, this will result in the loss of all the data stored in p1 -- usually, this is not what you really want to do. Another solution might be to use a new partition to copy the table, and then use CREATE table to copy the data to the table. Select... And then delete the old table and rename the new table, but this can be time-consuming when processing large amounts of data. This may not be feasible where high availability is required.
You can add multiple partitions in one ALTER TABLE... The ADD PARTITION statement is as follows:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
hired DATE NOT NULL
)
PARTITION BY RANGE( YEAR(hired) ) (
PARTITION p1 VALUES LESS THAN (1991),
PARTITION p2 VALUES LESS THAN (1996),
PARTITION p3 VALUES LESS THAN (2001),
PARTITION p4 VALUES LESS THAN (2005)
);
ALTER TABLE employees ADD PARTITION (
PARTITION p5 VALUES LESS THAN (2010),
PARTITION p6 VALUES LESS THAN MAXVALUE
);
Fortunately, MySQL's partitioning implementation provides a way to redefine partitions without losing data. Let's start with a few simple examples involving RANGE partitioning. Recall that the member table is now defined as follows:
mysql> SHOW CREATE TABLE members\G
*************************** 1. row ***************************
Table: members
Create Table: CREATE TABLE `members` (
`id` int(11) DEFAULT NULL,
`fname` varchar(25) DEFAULT NULL,
`lname` varchar(25) DEFAULT NULL,
`dob` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY RANGE ( YEAR(dob))
(PARTITION n0 VALUES LESS THAN (1970) ENGINE = InnoDB,
PARTITION n1 VALUES LESS THAN (1980) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1990) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (2000) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2010) ENGINE = InnoDB) */
1 row in set (0.00 sec)
Suppose you want to move all rows representing members born before 1960 to a separate partition. As we've seen, you can't use ALTER TABLE... To add partitions. However, you can do this using another partition related extension, ALTER TABLE:
ALTER TABLE members REORGANIZE PARTITION n0 INTO (
PARTITION s0 VALUES LESS THAN (1960),
PARTITION s1 VALUES LESS THAN (1970)
);
In effect, this command splits partition p0 into two new partitions s0 and s1. It also moves the data stored in p0 to a new partition. According to the rule, it is reflected in two partitions... Value... Clauses, so that s0 only contains records with a year (dob) less than 1960, and s1 contains rows with a year (dob) greater than or equal to 1960 but less than 1970.
The REORGANIZE PARTITION clause can also be used to merge adjacent partitions. You can reverse the impact of the previous statement on the member table, as shown below:
ALTER TABLE members REORGANIZE PARTITION s0,s1 INTO (
PARTITION p0 VALUES LESS THAN (1970)
);
Data is not lost when partitions are split or merged using REORGANIZE PARTITION. When the above statement is executed, MySQL moves all records stored in partitions s0 and s1 to partition p0.
The general syntax of REORGANIZE PARTITION is as follows:
ALTER TABLE tbl_name
REORGANIZE PARTITION partition_list
INTO (partition_definitions);
Here, tbl_name is the name of the partition table, partition_list is a comma separated list of the names of one or more existing partitions to change. partition_definitions is a comma separated list of new partition definitions that follow the partition used in CREATE TABLE_ The same rules as the definitions list. When using REORGANIZE partition, you are not limited to merging multiple partitions into one partition, nor to splitting a partition into multiple partitions. For example, you can reorganize all four partitions of a member table into two, as follows:
ALTER TABLE members REORGANIZE PARTITION p0,p1,p2,p3 INTO (
PARTITION m0 VALUES LESS THAN (1980),
PARTITION m1 VALUES LESS THAN (2000)
);
You can also use REORGANIZE PARTITION on the table of the LIST partition. Let's go back to the problem of adding a new partition to the LIST partitioned TT table because the value of the new partition already appears in the value LIST of an existing partition. We can deal with this problem by adding a partition that contains only non conflicting values, and then reorganizing the new partition and the existing partition so that the values stored in the existing partition are now moved to the new partition:
ALTER TABLE tt ADD PARTITION (PARTITION np VALUES IN (4, 8));
ALTER TABLE tt REORGANIZE PARTITION p1,np INTO (
PARTITION p1 VALUES IN (6, 18),
PARTITION np VALUES in (4, 8, 12)
);
Here are some key points to keep in mind when using ALTER TABLE. REORGANIZE PARTITION repartitionrepartition the table of the RANGE or LIST partition:
The PARTITION option used to determine the new PARTITION scheme follows the same rules as the CREATE TABLE statement.
A new RANGE partition scheme cannot have any overlapping RANGE; A new LIST partition scheme cannot have any overlapping value sets.
partition_ The combination of partitions in the definitions list should be considered with partition_ The same range or value set as the named composite partition in the list.
For example, partitions p1 and p2 contain the years from 1980 to 1999 in the member table as an example of this section. Any reorganization of the two divisions should cover the same year range.
For tables partitioned by RANGE, you can only reorganize adjacent partitions; Cannot skip RANGE partition.
For example, you cannot reorganize the sample member table with a statement beginning with ALTER table members reorganize PARTITION p0,p2 INTO. Because p0 covers the years before 1970 and p2 covers the years from 1990 to 1999, these are not adjacent partitions. (in this case, you cannot skip partition p1.)
You cannot use REORGANIZE PARTITION to change the partition type used by the table (for example, you cannot change the RANGE partition to HASH partition or vice versa). You cannot use this statement to change partition expressions or columns. To complete these tasks without deleting and recreating the table, you can use ALTER table... Partition... As shown below:
ALTER TABLE members
PARTITION BY HASH( YEAR(dob) )
PARTITIONS 8;
3.2 manage hash and key partitions
In partition settings, tables partitioned by hash or key are very similar. They are different from tables partitioned by range or list in many ways. Therefore, this section deals with modifications to tables that are partitioned only by hash or key. Discussion on adding and removing partitions to tables that are partitioned by range or list.
You cannot delete the partition of a table with a HASH or KEY partition as you delete a table with a RANGE or LIST partition. However, you can merge HASH or KEY partitions and use ALTER TABLE... To merge partitions. Suppose a clients table containing client data is divided into 12 partitions, as shown below:
CREATE TABLE clients (
id INT,
fname VARCHAR(30),
lname VARCHAR(30),
signed DATE
)
PARTITION BY HASH( MONTH(signed) )
PARTITIONS 12;
To reduce the number of partitions from 12 to 8, execute the following ALTER TABLE statement:
mysql> ALTER TABLE clients COALESCE PARTITION 4; Query OK, 0 rows affected (0.02 sec)
COALESCE also works well with tables divided by HASH, KEY, LINEAR HASH, or LINEAR KEY. The following is an example similar to the previous one, except that the table is partitioned through a LINEAR KEY:
mysql> CREATE TABLE clients_lk (
-> id INT,
-> fname VARCHAR(30),
-> lname VARCHAR(30),
-> signed DATE
-> )
-> PARTITION BY LINEAR KEY(signed)
-> PARTITIONS 12;
Query OK, 0 rows affected (0.03 sec)
mysql> ALTER TABLE clients_lk COALESCE PARTITION 4;
Query OK, 0 rows affected (0.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
The number after COALESCE PARTITION is the number of partitions to merge into the remaining partitions -- in other words, the number of partitions to delete from the table.
Attempting to delete more partitions than in the table will result in the following error:
mysql> ALTER TABLE clients COALESCE PARTITION 18; ERROR 1478 (HY000): Cannot remove all partitions, use DROP TABLE instead
If you want to increase the number of partitions of the clients table from 12 to 18, use ALTER table... To add partitions as follows:
ALTER TABLE clients ADD PARTITION PARTITIONS 6;
3.3 switching partition and sub partition
In MySQL 8.0, you can exchange a table partition or subpartition table. Use ALTER table pt to exchange partition p table elements, where pt is the partition of partition table and p, or the subpartition pt and nt partition table. The following statements are provided for the exchange:
- Table nt itself has no partitions.
- Table nt is not a temporary table.
- The structure of tables pt and nt is the same in other respects.
- Table nt does not contain any foreign key references, and other tables do not have any foreign key references nt.
- For P, there are no rows outside the partition definition boundary in NT. If WITHOUT VALIDATION is used, this condition does not apply.
- For InnoDB tables, the two tables use the same row format. To determine the row format of InnoDB table, you can query INFORMATION_SCHEMA.INNODB_TABLES.
- nt does not have any partitions using the DATA DIRECTORY option. This restriction is removed in MySQL 8.0.14 and later InnoDB tables.
In addition to the ALTER, INSERT and CREATE permissions normally required by ALTER TABLE statements, you must also have DROP permission to execute ALTER TABLE... Swap partitions.
You should also note that ALTER TABLE... Swap partitions:
- Executing ALTER TABLE... EXCHANGE PARTITION does not call any triggers on partitioned tables or tables to be exchanged.
- Swap all auto in table_ The increment column will be reset.
- IGNORE keywordswap partitions in ALTER TABLE.
ALTER TABLE... Where pt is the partitioned table, p is the partition (or sub partition) to be exchanged, and nt is the non partitioned table to be exchanged with p:
ALTER TABLE pt
EXCHANGE PARTITION p
WITH TABLE nt;
You can also attach WITH VALIDATION or with out validation. ALTER TABLE... When swapping a partition to a non partitioned table, the EXCHANGE PARTITION operation does not perform any row by row validation, which allows the database administrator to be responsible for ensuring that rows are within the boundaries of the partition definition. WITH VALIDATION is the default.
In an ALTER TABLE EXCHANGE PARTITION statement, only one partition or sub partition can be exchanged with a non partitioned table. If you want to swap multiple partitions or sub partitions, use multiple ALTER TABLE EXCHANGE PARTITION statements. EXCHANGE PARTITION cannot be used with other ALTER TABLE options. The partitions and (if applicable) sub partitions used by the partition table can be any type supported in MySQL 8.0.
3.3.1 exchanging partitions with non partitioned tables
Suppose that a partitioned table has been created and populated with the following SQL statement e:
CREATE TABLE e (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30)
)
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (50),
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (150),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
INSERT INTO e VALUES
(1669, "Jim", "Smith"),
(337, "Mary", "Jones"),
(16, "Frank", "White"),
(2005, "Linda", "Black");
Now let's create a non partitioned copy of e named e2. This can be done using the mysql client, as follows:
mysql> CREATE TABLE e2 LIKE e; Query OK, 0 rows affected (0.04 sec) mysql> ALTER TABLE e2 REMOVE PARTITIONING; Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0
By querying INFORMATION_SCHEMA, you can see which partitions in table e contain rows. Partition table, like this:
mysql> SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
2 rows in set (0.00 sec)
To exchange the p0 partition and e2 table in the e table, you can use ALTER table, as shown below:
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2; Query OK, 0 rows affected (0.04 sec)
More precisely, the statement just issued will cause any row found in the partition to be exchanged with the row found in the table. You can query INFORMATION_SCHEMA to see how this happens. Partition table, as before. The table row previously found in partition p0 no longer exists:
mysql> SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 0 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
4 rows in set (0.00 sec)
If you look at table e2, you can see that the "missing" row can now be found there:
mysql> SELECT * FROM e2; +----+-------+-------+ | id | fname | lname | +----+-------+-------+ | 16 | Frank | White | +----+-------+-------+ 1 row in set (0.00 sec)
The table to be exchanged with the partition is not necessarily empty. To demonstrate this, we first insert a new row in table e, ensure that this row is stored in partition p0 by selecting an id column value less than 50, and then verify this by querying the PARTITIONS table:
mysql> INSERT INTO e VALUES (41, "Michael", "Green");
Query OK, 1 row affected (0.05 sec)
mysql> SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
4 rows in set (0.00 sec)
Now, we use the ALTER table statement again to exchange the p0 partition with the e2 partition:
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2; Query OK, 0 rows affected (0.28 sec)
The output of the following query shows that before issuing the ALTER table statement, the table rows stored in partition p0 and table e2 have now exchanged positions:
mysql> SELECT * FROM e;
+------+-------+-------+
| id | fname | lname |
+------+-------+-------+
| 16 | Frank | White |
| 1669 | Jim | Smith |
| 337 | Mary | Jones |
| 2005 | Linda | Black |
+------+-------+-------+
4 rows in set (0.00 sec)
mysql> SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM e2;
+----+---------+-------+
| id | fname | lname |
+----+---------+-------+
| 41 | Michael | Green |
+----+---------+-------+
1 row in set (0.00 sec)
3.3.2 unmatched rows
You should remember any rows found in the non partitioned table before issuing ALTER table. EXCHANGE PARTITION statements must meet the conditions required to store them in the target partition; Otherwise, the statement will fail. To understand how this happens, first insert a row into e2 outside the boundary of the partition definition of partition p0 of table e. For example, insert a row whose id column value is too large; Then try to swap the table with the partition again:
mysql> INSERT INTO e2 VALUES (51, "Ellen", "McDonald"); Query OK, 1 row affected (0.08 sec) mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2; ERROR 1707 (HY000): Found row that does not match the partition
Only the WITHOUT VALIDATION option allows this operation to succeed:
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2 WITHOUT VALIDATION; Query OK, 0 rows affected (0.02 sec)
When a partition is exchanged with a table containing rows that do not match the partition definition, the database administrator is responsible for repairing the mismatched rows. You can use REPAIR table or ALTER table... To repair the partition.
3.3.3 switching partitions without line by line verification
When a partition is exchanged with a table with many rows, in order to avoid time-consuming validation, the partition can be exchanged by attaching WITHOUT validation to ALTER table.
The following example compares execution time WITH and without validating swap partitioned and non partitioned tables. The partitioned table (table e) contains two partitions, each WITH 1 million rows. The rows in p0 of table e are deleted, and p0 is exchanged WITH a non partitioned table WITH 1 million rows. WITH validation takes 0.74 seconds. In contrast, the WITHOUT VALIDATION operation takes only 0.01 seconds.
# Create a partitioned table with 1 million rows in each partition
CREATE TABLE e (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30)
)
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (1000001),
PARTITION p1 VALUES LESS THAN (2000001),
);
mysql> SELECT COUNT(*) FROM e;
| COUNT(*) |
+----------+
| 2000000 |
+----------+
1 row in set (0.27 sec)
# View the rows in each partition
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'e';
+----------------+-------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+-------------+
| p0 | 1000000 |
| p1 | 1000000 |
+----------------+-------------+
2 rows in set (0.00 sec)
# Create a nonpartitioned table of the same structure and populate it with 1 million rows
CREATE TABLE e2 (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30)
);
mysql> SELECT COUNT(*) FROM e2;
+----------+
| COUNT(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.24 sec)
# Create another nonpartitioned table of the same structure and populate it with 1 million rows
CREATE TABLE e3 (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30)
);
mysql> SELECT COUNT(*) FROM e3;
+----------+
| COUNT(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.25 sec)
# Drop the rows from p0 of table e
mysql> DELETE FROM e WHERE id < 1000001;
Query OK, 1000000 rows affected (5.55 sec)
# Confirm that there are no rows in partition p0
mysql> SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 0 |
| p1 | 1000000 |
+----------------+------------+
2 rows in set (0.00 sec)
# Exchange partition p0 of table e with the table e2 'WITH VALIDATION'
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2 WITH VALIDATION;
Query OK, 0 rows affected (0.74 sec)
# Confirm that the partition was exchanged with table e2
mysql> SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1000000 |
| p1 | 1000000 |
+----------------+------------+
2 rows in set (0.00 sec)
# Once again, drop the rows from p0 of table e
mysql> DELETE FROM e WHERE id < 1000001;
Query OK, 1000000 rows affected (5.55 sec)
# Confirm that there are no rows in partition p0
mysql> SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 0 |
| p1 | 1000000 |
+----------------+------------+
2 rows in set (0.00 sec)
# Exchange partition p0 of table e with the table e3 'WITHOUT VALIDATION'
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e3 WITHOUT VALIDATION;
Query OK, 0 rows affected (0.01 sec)
# Confirm that the partition was exchanged with table e3
mysql> SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1000000 |
| p1 | 1000000 |
+----------------+------------+
2 rows in set (0.00 sec)
If a partition is exchanged with a table containing rows that do not match the partition definition, the database administrator is responsible for repairing the mismatched rows. You can use REPAIR table or ALTER table... To repair the partition.
3.3.4 exchanging sub partitions with non partitioned tables
You can also use ALTER table to swap the child partitions of a partitioned table and a non partitioned table. Swap partitions. In the following example, we first create a table es, which is partitioned by RANGE and KEY. Fill this table, just as we do table e, and then create an empty, non partitioned table copy es2, as shown below:
mysql> CREATE TABLE es (
-> id INT NOT NULL,
-> fname VARCHAR(30),
-> lname VARCHAR(30)
-> )
-> PARTITION BY RANGE (id)
-> SUBPARTITION BY KEY (lname)
-> SUBPARTITIONS 2 (
-> PARTITION p0 VALUES LESS THAN (50),
-> PARTITION p1 VALUES LESS THAN (100),
-> PARTITION p2 VALUES LESS THAN (150),
-> PARTITION p3 VALUES LESS THAN (MAXVALUE)
-> );
Query OK, 0 rows affected (2.76 sec)
mysql> INSERT INTO es VALUES
-> (1669, "Jim", "Smith"),
-> (337, "Mary", "Jones"),
-> (16, "Frank", "White"),
-> (2005, "Linda", "Black");
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> CREATE TABLE es2 LIKE es;
Query OK, 0 rows affected (1.27 sec)
mysql> ALTER TABLE es2 REMOVE PARTITIONING;
Query OK, 0 rows affected (0.70 sec)
Records: 0 Duplicates: 0 Warnings: 0
Although we did not explicitly name any child PARTITIONS when creating the table es, we can_ Select the subartition of the PARTITIONS table in schema_ Name column to get the generated name, as follows:
mysql> SELECT PARTITION_NAME, SUBPARTITION_NAME, TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'es';
+----------------+-------------------+------------+
| PARTITION_NAME | SUBPARTITION_NAME | TABLE_ROWS |
+----------------+-------------------+------------+
| p0 | p0sp0 | 1 |
| p0 | p0sp1 | 0 |
| p1 | p1sp0 | 0 |
| p1 | p1sp1 | 0 |
| p2 | p2sp0 | 0 |
| p2 | p2sp1 | 0 |
| p3 | p3sp0 | 3 |
| p3 | p3sp1 | 0 |
+----------------+-------------------+------------+
8 rows in set (0.00 sec)
The following ALTER TABLE statement exchanges the sub partition p3sp0 in table es with the non partition table es2:
mysql> ALTER TABLE es EXCHANGE PARTITION p3sp0 WITH TABLE es2; Query OK, 0 rows affected (0.29 sec)
You can verify the exchanged rows by issuing the following query:
mysql> SELECT PARTITION_NAME, SUBPARTITION_NAME, TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'es';
+----------------+-------------------+------------+
| PARTITION_NAME | SUBPARTITION_NAME | TABLE_ROWS |
+----------------+-------------------+------------+
| p0 | p0sp0 | 1 |
| p0 | p0sp1 | 0 |
| p1 | p1sp0 | 0 |
| p1 | p1sp1 | 0 |
| p2 | p2sp0 | 0 |
| p2 | p2sp1 | 0 |
| p3 | p3sp0 | 0 |
| p3 | p3sp1 | 0 |
+----------------+-------------------+------------+
8 rows in set (0.00 sec)
mysql> SELECT * FROM es2;
+------+-------+-------+
| id | fname | lname |
+------+-------+-------+
| 1669 | Jim | Smith |
| 337 | Mary | Jones |
| 2005 | Linda | Black |
+------+-------+-------+
3 rows in set (0.00 sec)
If a table is partitioned, you can only exchange a sub partition of the table - not the entire partition - and an unpartitioned table, as shown below:
mysql> ALTER TABLE es EXCHANGE PARTITION p3 WITH TABLE es2; ERROR 1704 (HY000): Subpartitioned table, use subpartition instead of partition
Table structures are compared in a rigorous manner; The number, order, name, and type of columns and indexes of partitioned and non partitioned tables must exactly match. In addition, both tables must use the same storage engine:
mysql> CREATE TABLE es3 LIKE e;
Query OK, 0 rows affected (1.31 sec)
mysql> ALTER TABLE es3 REMOVE PARTITIONING;
Query OK, 0 rows affected (0.53 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW CREATE TABLE es3\G
*************************** 1. row ***************************
Table: es3
Create Table: CREATE TABLE `es3` (
`id` int(11) NOT NULL,
`fname` varchar(30) DEFAULT NULL,
`lname` varchar(30) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
mysql> ALTER TABLE es3 ENGINE = MyISAM;
Query OK, 0 rows affected (0.15 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE es EXCHANGE PARTITION p3sp0 WITH TABLE es3;
ERROR 1497 (HY000): The mix of handlers in the partitions is not allowed in this version of MySQL
3.4 maintenance zoning
Many table and partition maintenance tasks can be performed on partitioned tables using SQL statements for such purposes.
The table maintenance of the partition table can be completed by using the statements CHECK Table, OPTIMIZE Table, ANALYZE Table and REPAIR Table supported by the partition table.
You can use many extended alter tables to perform this type of operation directly on one or more partitions, as shown in the following table:
- Rebuilding partitions.
Re zoning; This has the same effect as deleting all records stored in the partition and reinserting them. This is useful for defragmentation.
ALTER TABLE t1 REBUILD PARTITION p0, p1;
- Optimizing partitions
If you delete a large number of rows from a partition, or if you make many changes to a partitioned table with variable length rows (that is, with VARCHAR, BLOB, or TEXT columns), you can use ALTER table... To optimize the partition to reclaim any unused space and organize the partition data file.
ALTER TABLE t1 OPTIMIZE PARTITION p0, p1;
Using OPTIMIZE PARTITION on a given partition is equivalent to running CHECK PARTITION, ANALYZE PARTITION, and REPAIR PARTITION on that partition.
Some MySQL storage engines, including InnoDB, do not support partition optimization; In these cases, ALTER TABLE... OPTIMIZE PARTITION analyzes and rebuilds the entire table with appropriate warnings. (Bug #11751825, Bug #42822) use ALTER TABLE... To rebuild the partition and ALTER TABLE... Instead of ANALYZE PARTITION to avoid this problem.
- Analyzing partitions
This will read and store the key distribution for the partition.
ALTER TABLE t1 ANALYZE PARTITION p3;
- Repairing partitions
Fix bad partition table.
ALTER TABLE t1 REPAIR PARTITION p0,p1;
- Checking partitions.
You can check partitions for errors in the same way you use check TABLE for non partitioned tables.
ALTER TABLE trb3 CHECK PARTITION p1;
IV partition pruning
The Optimization called partition pruning is based on a relatively simple concept, which can be described as "don't scan partitions without matching values". Suppose a partition table t1 is created by the following statement:
CREATE TABLE t1 (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
region_code TINYINT UNSIGNED NOT NULL,
dob DATE NOT NULL
)
PARTITION BY RANGE( region_code ) (
PARTITION p0 VALUES LESS THAN (64),
PARTITION p1 VALUES LESS THAN (128),
PARTITION p2 VALUES LESS THAN (192),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
Suppose you want to get results from a SELECT statement, for example:
SELECT fname, lname, region_code, dob
FROM t1
WHERE region_code > 125 AND region_code < 130;
It is easy to see that all the rows that should be returned are not in the p0 or p3 partition; That is, we only need to search for matching rows in partitions p1 and p2. By limiting the search, it takes much less time and effort to find matching rows than to scan all partitions in the table. This "cutting" of unwanted partitions is called trimming. When the optimizer can use partition pruning when executing this query, the execution speed of the query may be one order of magnitude faster than that of a non partitioned table containing the same column definition and data.
When the WHERE condition can be reduced to one of the following two cases, the optimizer can perform pruning:
- partition_column = constant
- partition_ Column in (constant 1, constant 2,... constantN)
In the first case, the optimizer only evaluates the partition expression for a given value, determines which partition contains the value, and scans only this partition. In many cases, the equal sign can be replaced by another arithmetic comparison, including <, >, < =, > = and < >. Some queries that use BETWEEN in the WHERE clause can also take advantage of partition pruning. See examples later in this section.
In the second case, the optimizer calculates the partition expression for each value in the list, creates a list of matching partitions, and then scans only the partitions in the partition list.
SELECT, DELETE, and UPDATE statements support partition pruning. For the inserted row, the INSERT statement can only access one partition; This is true even for tables partitioned with HASH or KEY, although it is not currently displayed in the output of EXPLAIN.
Pruning can also be applied to shorter ranges, which the optimizer can convert to a list of equivalent values. For example, in the previous example, the WHERE clause can be converted to WHERE region_code in(126, 127, 128, 129). Then, the optimizer can determine that the first two values in the list are found in partition p1, the other two values are found in partition p2, and the other partitions do not contain relevant values, so there is no need to search for matching rows.
The optimizer can also prune WHERE conditions that involve the above type of comparison of multiple columns of a table partitioned with RANGE columns or LIST columns.
This type of optimization can be applied when the partition expression contains an equation or a range that can be reduced to a set of equations, or when the partition expression represents an increasing or decreasing relationship. When the partition expression uses YEAR() or to_ The days() function can also apply pruning to tables partitioned by DATE or DATETIME columns. When the partition expression uses to_ You can also apply pruning to such tables when using the seconds() function.
Suppose that the table t2 partitioned on the DATE column is created using the following statement:
CREATE TABLE t2 (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
region_code TINYINT UNSIGNED NOT NULL,
dob DATE NOT NULL
)
PARTITION BY RANGE( YEAR(dob) ) (
PARTITION d0 VALUES LESS THAN (1970),
PARTITION d1 VALUES LESS THAN (1975),
PARTITION d2 VALUES LESS THAN (1980),
PARTITION d3 VALUES LESS THAN (1985),
PARTITION d4 VALUES LESS THAN (1990),
PARTITION d5 VALUES LESS THAN (2000),
PARTITION d6 VALUES LESS THAN (2005),
PARTITION d7 VALUES LESS THAN MAXVALUE
);
Using t2, you can use the following statement for partition pruning:
SELECT * FROM t2 WHERE dob = '1982-06-23'; UPDATE t2 SET region_code = 8 WHERE dob BETWEEN '1991-02-15' AND '1997-04-25'; DELETE FROM t2 WHERE dob >= '1984-06-21' AND dob <= '1999-06-21'
For the last statement, the optimizer can also be as follows:
- Locate the partition that contains the low end of the range.
YEAR('1984-06-21 ') generates the value 1984, which is located in partition d3. - Locate the partition that contains the high end of the range.
The value of YEAR('1999-06-21 ') is 1999, which is located in partition d5. - Scan only these two partitions and any partitions between them.
In this case, this means that only d3, d4, and d5 partitions are scanned. The remaining partitions can be safely ignored (and ignored).
V Partition table instance
Environment introduction
There is such a large table in mysql. We need to change this ordinary table into a partitioned table.
mysql> select count(*) from fact_sale; +-----------+ | count(*) | +-----------+ | 767830001 | +-----------+ 1 row in set (1 min 2.80 sec) mysql> desc fact_sale; +-----------+--------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type | Null | Key | Default | Extra | +-----------+--------------+------+-----+-------------------+-----------------------------------------------+ | id | bigint | NO | PRI | NULL | auto_increment | | sale_date | timestamp | NO | MUL | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP | | prod_name | varchar(200) | NO | | NULL | | | sale_nums | int | YES | | NULL | | +-----------+--------------+------+-----+-------------------+-----------------------------------------------+ 4 rows in set (0.03 sec) mysql> select * from fact_sale limit 10; +----+---------------------+-----------+-----------+ | id | sale_date | prod_name | sale_nums | +----+---------------------+-----------+-----------+ | 1 | 2011-08-16 00:00:00 | PROD4 | 28 | | 2 | 2011-11-06 00:00:00 | PROD6 | 19 | | 3 | 2011-04-25 00:00:00 | PROD8 | 29 | | 4 | 2011-09-12 00:00:00 | PROD2 | 88 | | 5 | 2011-05-15 00:00:00 | PROD5 | 76 | | 6 | 2011-02-23 00:00:00 | PROD6 | 64 | | 7 | 2012-09-26 00:00:00 | PROD2 | 38 | | 8 | 2012-02-14 00:00:00 | PROD6 | 45 | | 9 | 2010-04-22 00:00:00 | PROD8 | 57 | | 10 | 2010-10-31 00:00:00 | PROD5 | 65 | +----+---------------------+-----------+-----------+ 10 rows in set (0.00 sec) mysql>
5.1 create range partition
Just tested. If the id column is the primary key, an error will be reported. The partition column is sale_ The date must be in the primary key (which can be a federated primary key). The mysql partition table is really a little unfriendly
code:
CREATE TABLE `fact_sale_range` (
`id` bigint NOT NULL ,
`sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`prod_name` varchar(200) NOT NULL,
`sale_nums` int DEFAULT NULL
)
PARTITION BY RANGE(UNIX_TIMESTAMP(SALE_DATE)) (
PARTITION P0 VALUES LESS THAN (UNIX_TIMESTAMP('2010-01-01 00:00:00')),
PARTITION P1 VALUES LESS THAN (UNIX_TIMESTAMP('2011-01-01 00:00:00')),
PARTITION P2 VALUES LESS THAN (UNIX_TIMESTAMP('2012-01-01 00:00:00')),
PARTITION P3 VALUES LESS THAN (UNIX_TIMESTAMP('2013-01-01 00:00:00')),
PARTITION PMAX VALUES LESS THAN MAXVALUE
);
insert into fact_sale_range select * from fact_sale limit 10000000;
Test record:
From this point of view, the OLTP performance of MySQL is quite good. 1000w data takes about 1 minute, and the server is configured with a 4-core 8G virtual machine.
mysql> insert into fact_sale_range select * from fact_sale limit 10000000; Query OK, 10000000 rows affected (1 min 26.13 sec) Records: 10000000 Duplicates: 0 Warnings: 0 mysql>
5.1.1 viewing partition table data volume
View the number of partitions
mysql> select count(*) from fact_sale_range partition (P0); +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.01 sec) mysql> select count(*) from fact_sale_range partition (P1); +----------+ | count(*) | +----------+ | 2934777 | +----------+ 1 row in set (0.13 sec) mysql> select count(*) from fact_sale_range partition (P2); +----------+ | count(*) | +----------+ | 4056076 | +----------+ 1 row in set (0.23 sec) mysql> select count(*) from fact_sale_range partition (P3); +----------+ | count(*) | +----------+ | 3009147 | +----------+ 1 row in set (0.17 sec) mysql> select count(*) from fact_sale_range partition (PMAX); +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.00 sec)
Queries without partitions are slower:
mysql> select count(*) from fact_sale_range where sale_date >= '2010-01-01 00:00:00' and sale_date < '2011-01-01 00:00:00'; +----------+ | count(*) | +----------+ | 2934777 | +----------+ 1 row in set (4.66 sec)
5.1.2 adding and deleting partitions
Add and remove partitions:
show create table fact_sale_range\G
-- MAXVALUE can only be used in last partition definition
alter table fact_sale_range add partition (partition P4 VALUES LESS THAN (UNIX_TIMESTAMP('2014-01-01 00:00:00')));
-- Delete first maxvalue Partition before adding
alter table fact_sale_range drop partition PMAX;
alter table fact_sale_range add partition (partition P4 VALUES LESS THAN (UNIX_TIMESTAMP('2014-01-01 00:00:00')));
alter table fact_sale_range add partition (partition PMAX VALUES LESS THAN (MAXVALUE));
-- Finally, review the table structure of the partition table
show create table fact_sale_range\G
Test record:
mysql> show create table fact_sale_range\G
*************************** 1. row ***************************
Table: fact_sale_range
Create Table: CREATE TABLE `fact_sale_range` (
`id` bigint NOT NULL,
`sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`prod_name` varchar(200) NOT NULL,
`sale_nums` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
/*!50100 PARTITION BY RANGE (unix_timestamp(`sale_date`))
(PARTITION P0 VALUES LESS THAN (1262275200) ENGINE = InnoDB,
PARTITION P1 VALUES LESS THAN (1293811200) ENGINE = InnoDB,
PARTITION P2 VALUES LESS THAN (1325347200) ENGINE = InnoDB,
PARTITION P3 VALUES LESS THAN (1356969600) ENGINE = InnoDB,
PARTITION PMAX VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
1 row in set (0.00 sec)
mysql>
mysql> alter table fact_sale_range add partition (partition P4 VALUES LESS THAN (UNIX_TIMESTAMP('2014-01-01 00:00:00')));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
mysql> alter table fact_sale_range drop partition PMAX;
Query OK, 0 rows affected (0.22 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table fact_sale_range add partition (partition P4 VALUES LESS THAN (UNIX_TIMESTAMP('2014-01-01 00:00:00')));
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
mysql> alter table fact_sale_range add partition (partition PMAX VALUES LESS THAN (MAXVALUE));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table fact_sale_range\G
*************************** 1. row ***************************
Table: fact_sale_range
Create Table: CREATE TABLE `fact_sale_range` (
`id` bigint NOT NULL,
`sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`prod_name` varchar(200) NOT NULL,
`sale_nums` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
/*!50100 PARTITION BY RANGE (unix_timestamp(`sale_date`))
(PARTITION P0 VALUES LESS THAN (1262275200) ENGINE = InnoDB,
PARTITION P1 VALUES LESS THAN (1293811200) ENGINE = InnoDB,
PARTITION P2 VALUES LESS THAN (1325347200) ENGINE = InnoDB,
PARTITION P3 VALUES LESS THAN (1356969600) ENGINE = InnoDB,
PARTITION P4 VALUES LESS THAN (1388505600) ENGINE = InnoDB,
PARTITION PMAX VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
1 row in set (0.00 sec)
mysql>
5.2 create List partition
code:
CREATE TABLE `fact_sale_list` ( `id` bigint NOT NULL , `sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `prod_name` varchar(200) NOT NULL, `sale_nums` int DEFAULT NULL ) PARTITION BY list(sale_nums) ( PARTITION P1 VALUES in (1,2,3,4,5,6,7,8,9), PARTITION P2 VALUES in (11,12,13,14,15,16,17,18,19), PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29), PARTITION P4 VALUES in (31,32,33,34,35,36,37,38,39), PARTITION P5 VALUES in (41,42,43,44,45,46,47,48,49), PARTITION P6 VALUES in (51,52,53,54,55,56,57,58,59), PARTITION P7 VALUES in (61,62,63,64,65,66,67,68,69), PARTITION P8 VALUES in (71,72,73,74,75,76,77,78,79), PARTITION P9 VALUES in (81,82,83,84,85,86,87,88,89) ); insert into fact_sale_list select * from fact_sale limit 10000000; drop table fact_sale_list; CREATE TABLE `fact_sale_list` ( `id` bigint NOT NULL , `sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `prod_name` varchar(200) NOT NULL, `sale_nums` int DEFAULT NULL ) PARTITION BY list(sale_nums) ( PARTITION P1 VALUES in (1,2,3,4,5,6,7,8,9,10), PARTITION P2 VALUES in (11,12,13,14,15,16,17,18,19,20), PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29,30), PARTITION P4 VALUES in (31,32,33,34,35,36,37,38,39,40), PARTITION P5 VALUES in (41,42,43,44,45,46,47,48,49,50), PARTITION P6 VALUES in (51,52,53,54,55,56,57,58,59,60), PARTITION P7 VALUES in (61,62,63,64,65,66,67,68,69,70), PARTITION P8 VALUES in (71,72,73,74,75,76,77,78,79,80), PARTITION P9 VALUES in (81,82,83,84,85,86,87,88,89,90), PARTITION P10 VALUES in (91,92,93,94,95,96,97,98,99,100) ); insert into fact_sale_list select * from fact_sale limit 10000000;
Test record:
mysql> CREATE TABLE `fact_sale_list` (
-> `id` bigint NOT NULL ,
-> `sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> `prod_name` varchar(200) NOT NULL,
-> `sale_nums` int DEFAULT NULL
-> )
-> PARTITION BY list(sale_nums) (
-> PARTITION P1 VALUES in (1,2,3,4,5,6,7,8,9),
-> PARTITION P2 VALUES in (11,12,13,14,15,16,17,18,19),
-> PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29),
-> PARTITION P4 VALUES in (31,32,33,34,35,36,37,38,39),
-> PARTITION P5 VALUES in (41,42,43,44,45,46,47,48,49),
-> PARTITION P6 VALUES in (51,52,53,54,55,56,57,58,59),
-> PARTITION P7 VALUES in (61,62,63,64,65,66,67,68,69),
-> PARTITION P8 VALUES in (71,72,73,74,75,76,77,78,79),
-> PARTITION P9 VALUES in (81,82,83,84,85,86,87,88,89)
-> );
Query OK, 0 rows affected (0.06 sec)
mysql>
mysql>
mysql> insert into fact_sale_list select * from fact_sale limit 10000000;
ERROR 1526 (HY000): Table has no partition for value 50
mysql>
mysql>
mysql>
mysql>
mysql> CREATE TABLE `fact_sale_list` (
-> `id` bigint NOT NULL ,
-> `sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> `prod_name` varchar(200) NOT NULL,
-> `sale_nums` int DEFAULT NULL
-> )
-> PARTITION BY list(sale_nums) (
-> PARTITION P1 VALUES in (1,2,3,4,5,6,7,8,9,10),
-> PARTITION P2 VALUES in (11,12,13,14,15,16,17,18,19,20),
-> PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29,30),
-> PARTITION P4 VALUES in (31,32,33,34,35,36,37,38,39,40),
-> PARTITION P5 VALUES in (41,42,43,44,45,46,47,48,49,50),
-> PARTITION P6 VALUES in (51,52,53,54,55,56,57,58,59,60),
-> PARTITION P7 VALUES in (61,62,63,64,65,66,67,68,69,70),
-> PARTITION P8 VALUES in (71,72,73,74,75,76,77,78,79,80),
-> PARTITION P9 VALUES in (81,82,83,84,85,86,87,88,89,90),
-> PARTITION P10 VALUES in (91,92,93,94,95,96,97,98,99,100)
-> );
ERROR 1050 (42S01): Table 'fact_sale_list' already exists
mysql>
mysql> drop table fact_sale_list;
Query OK, 0 rows affected (0.04 sec)
mysql>
mysql> CREATE TABLE `fact_sale_list` (
-> `id` bigint NOT NULL ,
-> `sale_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> `prod_name` varchar(200) NOT NULL,
-> `sale_nums` int DEFAULT NULL
-> )
-> PARTITION BY list(sale_nums) (
-> PARTITION P1 VALUES in (1,2,3,4,5,6,7,8,9,10),
-> PARTITION P2 VALUES in (11,12,13,14,15,16,17,18,19,20),
-> PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29,30),
-> PARTITION P4 VALUES in (31,32,33,34,35,36,37,38,39,40),
-> PARTITION P5 VALUES in (41,42,43,44,45,46,47,48,49,50),
-> PARTITION P6 VALUES in (51,52,53,54,55,56,57,58,59,60),
-> PARTITION P7 VALUES in (61,62,63,64,65,66,67,68,69,70),
-> PARTITION P8 VALUES in (71,72,73,74,75,76,77,78,79,80),
-> PARTITION P9 VALUES in (81,82,83,84,85,86,87,88,89,90),
-> PARTITION P10 VALUES in (91,92,93,94,95,96,97,98,99,100)
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> PARTITION P3 VALUES in (21,22,23,24,25,26,27,28,29,30),^C
mysql>
mysql> insert into fact_sale_list select * from fact_sale limit 10000000;
Query OK, 10000000 rows affected (1 min 37.28 sec)
Records: 10000000 Duplicates: 0 Warnings: 0
mysql>
reference resources:
- https://dev.mysql.com/doc/refman/8.0/en/partitioning.html
- High performance MySQL