There are two ways to realize read-write separation and data segmentation
Method 1: middle tier agent (mycat)
System application ----- > intermediate agent ----- > Database
Method 2: the client mode (sharding JDBC) only needs to introduce the jar package of the client
Difference: mycat is the server agent and sharding JDBC is the client agent
mycat does not support horizontal segmentation and sharding JDBC in the consent library
Vertical segmentation, horizontal segmentation
vertical partitioning
-
Segmentation by business
For example, orders, goods and users are all in one database. Now put these three tables in different databases and segment them according to the dimension of the table -
One database for each business table
-
join associated query is prohibited between different businesses (it is troublesome)
advantage
-
After the split, the business relationship is clear
-
It is easy to expand and upgrade between systems and will not affect other tables to be updated
-
Simple database maintenance
shortcoming
-
The business table cannot be join ed and can only be called through the interface, which increases the complexity of the code
-
Cross database transactions are difficult to handle
-
When the amount of business data is large, there will also be a performance bottleneck
horizontal partitioning
Divide the data of the table into different libraries according to the specified rules
For example: divide orders according to users, and put odd and even numbers in different libraries respectively
advantage
-
It solves the bottleneck problem of large amount of data in single database and high performance of Chinese flat hair
-
The developer pays attention and the agent layer acts as agent
shortcoming
-
It is difficult to unify all the rules of splitting
For example, the user only needs to check the corresponding database according to the id, while the merchant needs to find out all of them and then filter them -
The system is difficult to expand and upgrade (rules change, data migration is required), and maintenance is difficult
In the project, it is divided vertically and then horizontally, according to different businesses, and then according to rules
MyCat
Construction of environment
I suggest you take a look https://www.cnblogs.com/fger/p/10387593.html
mysql official website installation https://dev.mysql.com/doc/refman/8.0/en/linux-installation-yum-repo.html
mycat official website installation https://www.yuque.com/ccazhw/gl7qp9/pbegu1
server.xml configuration
Configure the user name, password, permission and Schema of mycat
<!-- mycat Account number -->
<user name="root" defaultAccount="true">
<!-- password -->
<property name="password">alpha.mycat</property>
<!-- Logical library that this account can access,corresponding schema.xml Document schema Nodal name-->
<property name="schemas">adnc_usr,adnc_maint,adnc_cus</property>
<!-- Read only permissions -->
<property name="readOnly">true</property>
</user>
server.xml official https://github.com/AlphaYu/Adnc/blob/master/doc/mycat/server.xml
schema.xml basic configuration
Configure dataHost (node host), including read / write host
Configure the dataNode to specify the specific database
Configure schema, table name, data node and fragmentation rules
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- Configure 3 logical Libraries-->
<!-- sqlMaxLimit:limlt Statement is valid only for partitioned tables-->
<schema name="adnc_usr" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn_usr"></schema>
<schema name="adnc_maint" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn_maint"></schema>
<schema name="adnc_cus" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn_cus"></schema>
<!-- Real database corresponding to logical library-->
<dataNode name="dn_usr" dataHost="dh_adnc" database="adnc_usr" />
<dataNode name="dn_maint" dataHost="dh_adnc" database="adnc_maint" />
<dataNode name="dn_cus" dataHost="dh_adnc" database="adnc_cus" />
<!--The server address where the real database is located. 1 master and 2 slave are configured here. master server(hostM1)Downtime automatically switches to(hostS1) -->
<!--balance: 0: If the read-write separation is not enabled, they all fall on the writeHost;1: First not read writeHost;2: Uniform random distribution of reading and writing writeHost,readHost;3 Read in readHost -->
<!--writeType: 0: Fall first writeHost,1: Randomly fall on writeHost -->
<dataHost name="dh_adnc" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="172.20.0.11:3306" user="root" password="alpha.abc" >
<readHost host="hostS2" url="172.20.0.13:3306" user="root" password="alpha.abc" />
</writeHost>
<writeHost host="hostS1" url="172.20.0.12:3306" user="root" password="alpha.abc" />
</dataHost>
</mycat:schema>
schema.xml official
https://github.com/AlphaYu/Adnc/blob/master/doc/mycat/schema.xml
mycat authoritative guide (Chapter VII interpretation of mycat configuration file) http://www.mycat.org.cn/document/mycat-definitive-guide.pdf
mysql master-slave
Master slave configuration view https://blog.csdn.net/weixin_45367838/article/details/117888130
Enumeration fragmentation
schema.xml configuration other tags
Rule attribute in the table tag: defines the fragmentation rule of the fragmentation table. The rule name is in rule XML, which must correspond to the value of the name attribute in the tableRule tag one by one.

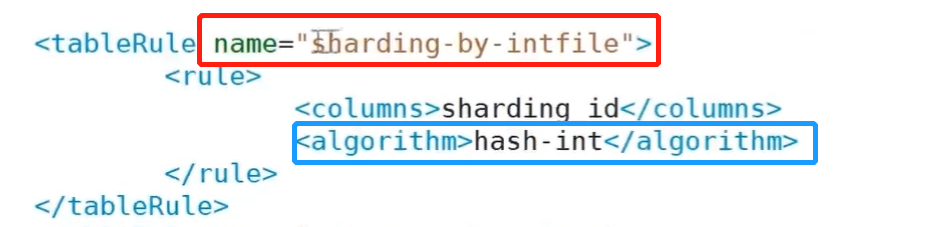
This rule is applicable to specific scenarios by configuring possible enumeration IDS in the configuration file and configuring fragmentation by yourself. For example, some businesses need to be saved according to provinces or districts and counties, while provinces, districts and counties across the country are fixed. This rule is used for such businesses (it will also be the fragmentation rule)
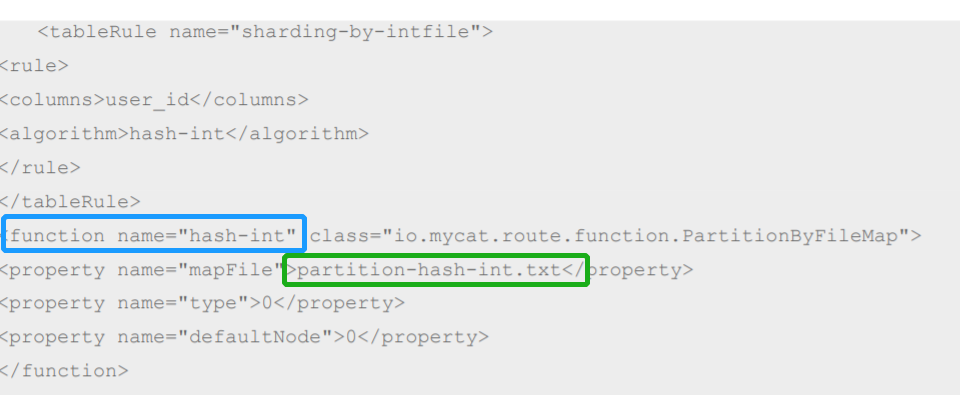
Specify the fragmentation rules under this file
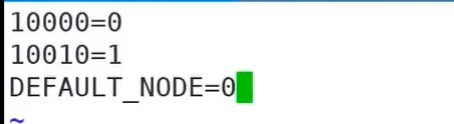
It can be modified through mycat and will be synchronized to other libraries. The inserted data should also be consistent with the above rules. 0: indicates the first library; 1: Represents the second library; Default_Node=0: indicates that other numbers are placed in the first library;
Other segmentation rules can refer to the guide
mycat authoritative guide (Chapter 10 has the commonly used segmentation rules of mycat) http://www.mycat.org.cn/document/mycat-definitive-guide.pdf
A table that does not require fragmentation
schema.xml configuration other tags
The type attribute in the table tag: Global is a global table, and fragmentation is not specified.
This attribute defines the type of logical table. At present, there are only two types of logical table: global table and ordinary table. Corresponding configuration:
• global table: global.
• normal table: all tables that do not specify this value as globla.
Sub table
If the tables related to the order are fragmented, it is troublesome to cross database. At this time, it is better to use sub tables to join in one fragment
schema.xml configuration other tags
The childTable tag is defined in the table
childTable tag: defines a fragment sub table, which is associated with the parent table through the attributes on the tag
Name attribute: defines the table name of the child table.
joinKey attribute: the id in the child table, which is used to associate with the parent table
parentKey attribute: the id in the parent table, which corresponds to the joinKey
Sharding-Jdbc
Distributed relational database middleware
Client agent mode
Lightweight java framework, jar package provides services
Four configuration modes are provided
Java Api,Yaml,SpringBoot,Spring(xml)
Sharding JDBC official website https://shardingsphere.apache.org/document/current/cn/overview/
Only for your own study and notes!!!