1. Overview of new MySQL8 features
1.1 MySQL8.0 New Features
1. Simpler NoSQL support
NoSQL refers generally to non-relational databases and data storage. With the rapid development of Internet platform, traditional relational databases have become increasingly unsatisfactory. MySQL has been supporting simple NoSQL storage since version 5.6. MySQL 8 has optimized this functionality to provide a more flexible way to implement NoSQL functionality without relying on schema.
2. Better index
In a query, using the index correctly can improve the efficiency of the query. Hidden and descending indexes have been added to MySQL 8. Hidden indexes can be used to test the impact of removing indexes on query performance. When there are mixed multicolumn indexes in a query, using a descending index can improve query performance.
3. Better JSON support
MySQL has supported the storage of native JSON data since 5.7, and MySQL 8 has optimized this functionality by adding the aggregate function JSON_ARRAYAGG() and JSON_OBJECTAGG(), which aggregates parameters into JSON arrays or objects, adds in-line operator - >, which is an enhancement of column path operator - >, enhances JSON sorting, and optimizes JSON update operation.
4. Security and Account Management
New caching_in MySQL 8 Sha2_ The password authorization plug-ins, roles, password history, and FIPS mode support enhance the security and performance of the database, enabling database administrators to have more flexibility in account management.
5. Changes in InnoDB
InnoDB is MySQL's default storage engine and is the preferred engine for transactional databases, supports transactional security tables (ACID s), row locking, and foreign keys. In MySQL version 8, InnoDB has made a lot of improvements and optimizations in terms of self-growth, indexing, encryption, deadlock, shared lock, and support for Atomic Data Definition Language (DDL), which improves data security and provides better support for transactions.
6. Data Dictionary
In previous versions of MySQL, dictionary data was stored in metadata files and non-transactional tables. A new transaction data dictionary has been added since MySQL 8, where database object information is stored and these data dictionaries are stored in internal transaction tables.
7. Atomic Data Definition Statement
MySQL 8 began to support the Atomic Data Definition Statement (Automic DDL), or Atomic DDL. Currently, only the InnoDB storage engine supports atomic DDL. The Atomic Data Definition Statement (DDL) combines DDL operation-related data dictionary updates, storage engine operations, and binary log writing into a single atomic transaction, which causes the transaction to commit or roll back even if the server crashes.
Tables created using a storage engine that supports atomic operations support atomic operations when performing operations such as DROP TABLE, CREATE TABLE, ALTER TABLE, RENAME TABLE, TRUNCATE TABLE, CREATE TABLESPACE, DROP TABLESPACE, and so on, i.e., transactions are either fully successful or rolled back after failure and no longer partially committed.
For statements copied from MySQL 5.7 to MySQL 8, you can add IF EXISTS or IF NOT EXISTS statements to avoid errors.
8. Resource Management
MySQL 8 started supporting the creation and management of resource groups, allowing threads running within the server to be assigned to specific groupings so that they can execute based on available resources within the group. Group attributes control resources within a group, enabling or limiting resource consumption within a group. The database administrator can change these properties appropriately depending on the workload.
Currently, CPU time is a controllable resource, represented by the concept of "virtual CPU", which includes the number of CPU cores, hyperthreads, hardware threads, and so on. The server determines the number of virtual CPUs available at startup. The database administrator with the corresponding permissions can associate these CPUs with the resource group and assign threads to the resource group.
The resource group component provides the SQL interface for resource group management in MySQL. The properties of a resource group are used to define the resource group. There are two default groups in MySQL, system group and user group. The default group cannot be deleted and its properties cannot be changed. For user-defined groups, all properties can be initialized when a resource group is created, with the exception of name and type, and other properties can be changed after creation.
On some platforms, or when MySQL is configured, resource management is limited or even unavailable. For example, if a thread pool plug-in is installed, or if a macOS system is used, resource management will be unavailable. In FreeBSD and Solaris systems, resource thread priority will fail. On Linux systems, only CAP_is configured SYS_ NICE attribute for resource management priority to work.
9. Character set support
The default character set in MySQL 8 was changed from latin1 to utf8mb4, and for the first time a specific set for Japanese was added, utf8mb4_ja_0900_as_cs.
10. Optimizer Enhancement
MySQL optimizer started supporting hidden and descending indexes. Hidden indexes are not used by the optimizer. You do not need to delete the index to verify its necessity. Hide the index first, and you can truly delete the index if the optimizer performance has no impact. Descending indexes allow the optimizer to sort multiple columns and allow inconsistent sort order.
11. Common table expressions
Common Table Expressions are short for CTE, and MySQL now supports both recursive and non-recursive forms of CTE. CTE names a temporary result set by using a WITH statement before a SELECT statement or other specific statement.
The basic syntax is as follows:
WITH cte_name (col_name1,col_name2 ...) AS (Subquery) SELECT * FROM cte_name;
Subquery represents a subquery, and the result set is named cte_using a WITH statement before the subquery Name, cte_can be used in subsequent queries Name queries.
12. Window Functions
MySQL 8 started to support window functions. Most aggregation functions that existed in previous versions can also be used as window functions in MySQL 8.
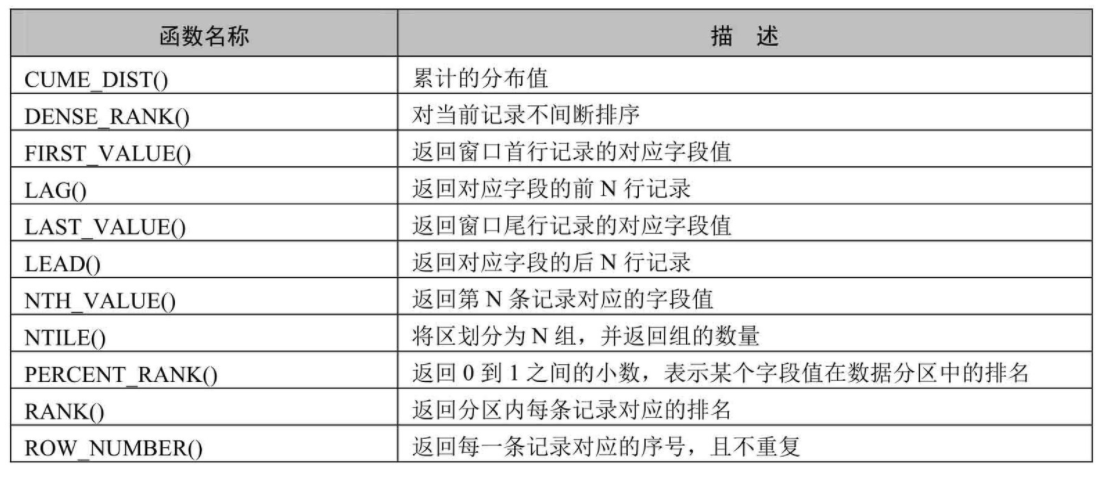
13. Regular expression support
MySQL uses an internationalized component library that supports Unicode for regular expression operations in versions later than 8.0.4, which provides full Unicode support as well as multibyte secure encoding. MySQL added REGEXP_LIKE(), EGEXP_INSTR(), REGEXP_REPLACE() and REGEXP_ Functions such as SUBSTR() to improve performance. In addition, regexp_stack_limit and regexp_ Time_ The limit system variable can control resource consumption by matching the engine.
14. Internal Temporary Table
The TempTable storage engine replaces the MEMORY storage engine as the default storage engine for internal temporary tables. The TempTable storage engine provides efficient storage for VARCHAR and VARBINARY columns. Internal_ Tmp_ Mem_ Storage_ The engine session variable defines the storage engine for the internal temporary table, with two optional values, TempTable and MMORY, where TempTable is the default storage engine. Temptable_ Max_ The ram system configuration item defines the maximum amount of memory that the TempTable storage engine can use.
15. Logging
The error logging subsystem in MySQL 8 consists of a series of MySQL components. The components are made up of the system variable log_error_services are configured to filter and write log events.
16. Backup Lock
The new backup lock allows data action statements to be executed during an online backup, while preventing operations that may cause snapshot inconsistencies. New backup locks are supported by the LOCK INSTANCE FOR BACKUP and UNLOCK INSTANCE syntax, which require backup administrator privileges.
17. Enhanced MySQL replication
MySQL 8 replication supports partially updated binary logging of JSON documents using a compact binary format, which saves space for recording complete JSON documents. When using statement-based logging, this compact logging is done automatically and can be done by adding a new binlog_row_value_options system variable value set to PARTIAL_JSON to enable.
1.2 MySQL8.0 Removed old features
Applications developed on MySQL version 5.7 use MySQL8.0 Removed feature, statement may fail or produce different execution results. To avoid these problems, for applications that use removal features, every effort should be made to correct avoidance of these features and to use alternatives whenever possible.
1. Query Cache
The query cache has been removed and the items deleted are:
**(1) Statement: **FLUSH QUERY CACHE and RESET QUERY CACHE.
**(2) System variables: **query_cache_limit, query_cache_min_res_unit, query_cache_size, query_cache_type, query_cache_wlock_invalidate.
**(3) State variable: **Qcache_free_blocks, Qcache_free_memory, Qcache_hits, Qcache_inserts, Qcache_lowmem_prunes, Qcache_not_cached, Qcache_queries_in_cache, Qcache_total_blocks.
**(4) Thread state: **checking privileges on cached query, checking query cache for query, invalidating query cache entries, sending cached result to client, storing result in query cache, waiting for query cache lock.
2. Encryption-related
Deleted encryption-related content is: ENCODE(), DECODE(), ENCRYPT(), DES_ENCRYPT() and DES_DECRYPT() function, configuration item des-key-file, system variable have_ DES_of crypt, FLUSH statement KEY_ FILE option, HAVE_CRYPT CMake option.
For the removed ENCRYPT() function, consider using SHA2() instead, and for the other removed functions, use AES_ENCRYPT() and AES_DECRYPT() instead.
3. Spatial function correlation
In MySQL version 5.7, multiple spatial functions have been marked as obsolete. These obsolete functions have been removed in MySQL 8, leaving only the corresponding ST_ And MBR functions.
4.\N and NULL
In SQL statements, the parser no longer treats \N as NULL, so NULL should be used instead of \N in SQL statements. This change will not affect the import and export of operation files using LOAD DATA INFILE or SELECT...INTO OUTFILE. In such operations, NULL is still equivalent to \N.
5. mysql_install_db
Mysql_has been removed from the MySQL distribution Install_ DB program, data dictionary initialization needs to call mysqld with the'-initialize'or'-initialize-insecure option to replace the implementation. In addition, - bootstrap and INSTALL_SCRIPTDIR CMake has also been deleted.
6. General Partition Handler
The generic partition handler has been removed from the MySQL service. To partition a given table, the storage engine used by the table requires its own partition handler.
There are two MySQL storage engines that provide local partition support, InnoDB and NDB, whereas only InnoDB is supported in MySQL 8.
7. System and state variable information
In INFORMATION_ In SCHEMA databases, system and state variable information is no longer maintained. GLOBAL_VARIABLES, SESSION_VARIABLES, GLOBAL_STATUS, SESSION_ The STATUS tables have been deleted. In addition, the system variable show_compatibility_56 has also been deleted. Deleted state variable has Slave_heartbeat_period, Slave_last_heartbeat,Slave_received_heartbeats, Slave_retried_transactions, Slave_running. The above deleted content can be replaced with the corresponding content in the performance mode.
8.mysql_plugin tool
Mysql_ The plugin tool, which configures MySQL server plug-ins, has been removed and can be replaced by the plugin-load or plugin-load-add option to load plug-ins at server startup or by loading plug-ins at runtime using the INSTALL PLUGIN statement.
2. New Feature 1: Window Functions
2.1 Contrast before and after using window functions
Suppose I have a table that shows how much a shopping website sells in each district of each city:
CREATE TABLE sales(
id INT PRIMARY KEY AUTO_INCREMENT,
city VARCHAR(15),
county VARCHAR(15),
sales_value DECIMAL
);
INSERT INTO sales(city,county,sales_value)
VALUES
('Beijing','Haidian',10.00),
('Beijing','Chaoyang',20.00),
('Shanghai','Huangpu',30.00),
('Shanghai','Changning',10.00);
Query:
mysql> SELECT * FROM sales; +----+------+--------+-------------+ | id | city | county | sales_value | +----+------+--------+-------------+ | 1 | Beijing | Haidian | 10 | | 2 | Beijing | Chaoyang | 20 | | 3 | Shanghai | Huangpu | 30 | | 4 | Shanghai | Changning | 10 | +----+------+--------+-------------+ 4 rows in set (0.00 sec)
**Demand: ** Now calculate the total sales of this website in each city, the total sales in the country, the ratio of sales in each district to sales in the city, and the ratio of sales to total sales.
If grouping and aggregation functions are used, the calculations will take several steps.
First, calculate the total sales amount and save it in temporary table a:
CREATE TEMPORARY TABLE a -- Create Temporary Table SELECT SUM(sales_value) AS sales_value -- Calculate total amount FROM sales;
Check Temporary Table a:
mysql> SELECT * FROM a; +-------------+ | sales_value | +-------------+ | 70 | +-------------+ 1 row in set (0.00 sec)
Step two calculates the total sales for each city and puts them in temporary table b:
CREATE TEMPORARY TABLE b -- Create Temporary Table SELECT city,SUM(sales_value) AS sales_value -- Calculate total city sales FROM sales GROUP BY city;
View temporary table b:
mysql> SELECT * FROM b; +------+-------------+ | city | sales_value | +------+-------------+ | Beijing | 30 | | Shanghai | 40 | +------+-------------+ 2 rows in set (0.00 sec)
The third step is to calculate the proportion of sales in each district to the total amount of sales in the city where they are located and the proportion to the total amount of sales. We can get the desired results from the following join query:
mysql> SELECT s.city AS City,s.county AS area,s.sales_value AS District sales,
-> b.sales_value AS Market Sales,s.sales_value/b.sales_value AS City Ratio,
-> a.sales_value AS Total Sales,s.sales_value/a.sales_value AS Total Ratio
-> FROM sales s
-> JOIN b ON (s.city=b.city) -- Temporary Table of Connected City Statistics Results
-> JOIN a -- Temporary Table of Total Connected Amounts
-> ORDER BY s.city,s.county;
+------+------+----------+----------+--------+----------+--------+
| City | area | District sales | Market Sales | City Ratio | Total Sales | Total Ratio |
+------+------+----------+----------+--------+----------+--------+
| Shanghai | Changning | 10 | 40 | 0.2500 | 70 | 0.1429 |
| Shanghai | Huangpu | 30 | 40 | 0.7500 | 70 | 0.4286 |
| Beijing | Chaoyang | 20 | 30 | 0.6667 | 70 | 0.2857 |
| Beijing | Haidian | 10 | 30 | 0.3333 | 70 | 0.1429 |
+------+------+----------+----------+--------+----------+--------+
4 rows in set (0.00 sec)
The results show that: the amount of municipal sales, the proportion of municipal sales, the total sales amount, the proportion of total sales are calculated.
The same query is much simpler if you use window functions. We can do this with the following code:
mysql> SELECT city AS City,county AS area,sales_value AS District sales,
-> SUM(sales_value) OVER(PARTITION BY city) AS Market Sales, -- Calculate market sales
-> sales_value/SUM(sales_value) OVER(PARTITION BY city) AS City Ratio,
-> SUM(sales_value) OVER() AS Total Sales, -- Calculate total sales
-> sales_value/SUM(sales_value) OVER() AS Total Ratio
-> FROM sales
-> ORDER BY city,county;
+------+------+----------+----------+--------+----------+--------+
| City | area | District sales | Market Sales | City Ratio | Total Sales | Total Ratio |
+------+------+----------+----------+--------+----------+--------+
| Shanghai | Changning | 10 | 40 | 0.2500 | 70 | 0.1429 |
| Shanghai | Huangpu | 30 | 40 | 0.7500 | 70 | 0.4286 |
| Beijing | Chaoyang | 20 | 30 | 0.6667 | 70 | 0.2857 |
| Beijing | Haidian | 10 | 30 | 0.3333 | 70 | 0.1429 |
+------+------+----------+-----------+--------+----------+--------+
4 rows in set (0.00 sec)
As it turns out, we get the same results as the query above.
Using window functions, the query is completed in one step. Also, because temporary tables are not used, execution is more efficient. Clearly, in this scenario where the results of grouping statistics are needed to calculate each record, it is better to use window functions.
2.2 Window Function Classification
MySQL supports window functions from version 8.0 onwards. The window function acts like grouping data in a query, except that the grouping operation aggregates the grouped results into one record, while the window function places the results in each data record.
Window functions can be divided into static window functions and dynamic window functions.
- The window size of a static window function is fixed and does not vary from record to record.
- The window size of the dynamic window function varies with the record.
The website address of the window function of the MySQL official website is https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html#function_row-number.
Overall, window functions can be divided into ordinal functions, distribution functions, forward and backward functions, first and last functions, and other functions, as follows:
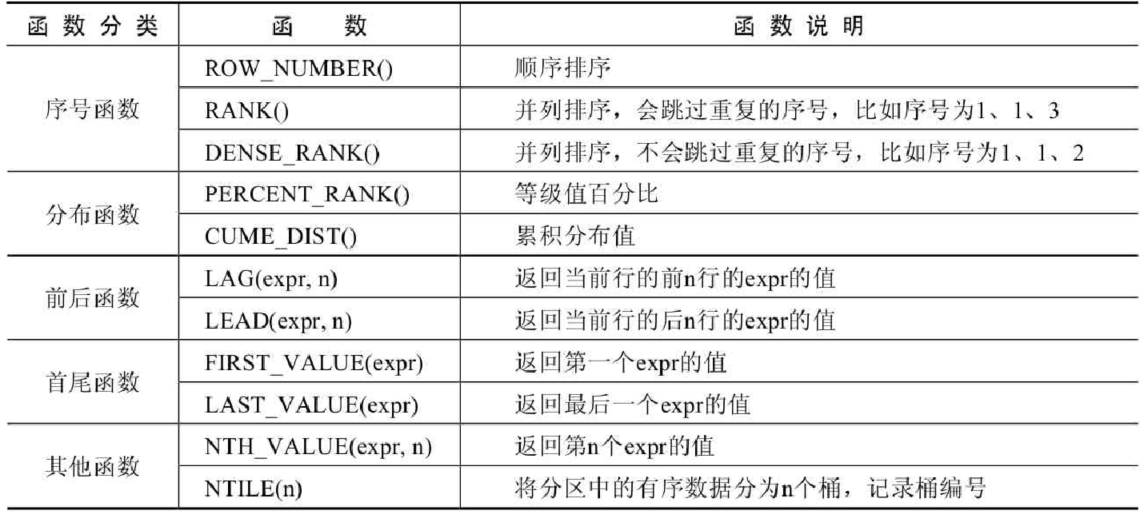
2.3 Grammatical Structure
The syntax structure of the window function is:
function OVER([PARTITION BY Field name ORDER BY Field name ASC|DESC])
Or:
function OVER Window Name... WINDOW Window Name AS ([PARTITION BY Field name ORDER BY Field name ASC|DESC])
- The OVER keyword specifies the scope of the function window.
- If you omit the parentheses, the window will contain all records that meet the WHERE condition, and the window function will be calculated based on all records that meet the WHERE condition.
- If the parentheses following the OVER keyword are not empty, you can set the window using the following syntax.
- Window name: Set an alias for the window to identify it.
- PARTITION BY clause: Specifies which fields the window functions are grouped by. After grouping, the window function can be executed separately in each grouping.
- ORDER BY clause: Specifies which fields the window functions are sorted by. Performs a sort operation so that the window functions are numbered in the order of the sorted data records.
- FRAME clause: Defines a rule for a subset of partitions that can be used as a sliding window.
2.4 Explanation of Classification
Create tables:
CREATE TABLE goods( id INT PRIMARY KEY AUTO_INCREMENT, category_id INT, category VARCHAR(15), NAME VARCHAR(30), price DECIMAL(10,2), stock INT, upper_time DATETIME );
Add data:
INSERT INTO goods(category_id,category,NAME,price,stock,upper_time) VALUES (1, 'Dresses/Women's boutique', 'T Pension', 39.90, 1000, '2020-11-10 00:00:00'), (1, 'Dresses/Women's boutique', 'Dress', 79.90, 2500, '2020-11-10 00:00:00'), (1, 'Dresses/Women's boutique', 'Sweater', 89.90, 1500, '2020-11-10 00:00:00'), (1, 'Dresses/Women's boutique', 'Jeans', 89.90, 3500, '2020-11-10 00:00:00'), (1, 'Dresses/Women's boutique', 'Pleated skirt', 29.90, 500, '2020-11-10 00:00:00'), (1, 'Dresses/Women's boutique', 'Wool jacket', 399.90, 1200, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Bicycle', 399.90, 1000, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Mountain Bike', 1399.90, 2500, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Alpenstocks', 59.90, 1500, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Equipment', 399.90, 3500, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Sport coat', 799.90, 500, '2020-11-10 00:00:00'), (2, 'Outdoor sport', 'Skate', 499.90, 1200, '2020-11-10 00:00:00');
The following validates the functionality of each window function against the data in the goods table.
1. Sequence Function
1.ROW_NUMBER() function
ROW_ The NUMBER() function is capable of sequentially displaying ordinal numbers in the data.
Example: Query the goods data table for information about each commodity in descending order under each commodity category.
mysql> SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 3 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 4 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
| 5 | 1 | 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 |
| 6 | 5 | 1 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 |
| 1 | 8 | 2 | Outdoor sport | Mountain Bike | 1399.90 | 2500 |
| 2 | 11 | 2 | Outdoor sport | Sport coat | 799.90 | 500 |
| 3 | 12 | 2 | Outdoor sport | Skate | 499.90 | 1200 |
| 4 | 7 | 2 | Outdoor sport | Bicycle | 399.90 | 1000 |
| 5 | 10 | 2 | Outdoor sport | Equipment | 399.90 | 3500 |
| 6 | 9 | 2 | Outdoor sport | Alpenstocks | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)
Example: Query the goods data table for the three highest-priced goods under each commodity category.
mysql> SELECT *
-> FROM (
-> SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE row_num <= 3;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 3 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 1 | 8 | 2 | Outdoor sport | Mountain Bike | 1399.90 | 2500 |
| 2 | 11 | 2 | Outdoor sport | Sport coat | 799.90 | 500 |
| 3 | 12 | 2 | Outdoor sport | Skate | 499.90 | 1200 |
+---------+----+-------------+---------------+------------+----------+-------+
6 rows in set (0.00 sec)
In the category named "Women's / Women's Goods", there are two items with a price of 89.90 yuan, namely, sanitary garments and jeans. The serial number of both items should be 2, not 2 for one item and 3 for the other. In this case, you can use the RANK() function and DENSE_ The RANK() function solves the problem.
2. RANK() function
The RANK() function allows you to sort ordinals side by side and skips duplicate ordinals, such as 1, 1, and 3.
Example: Use the RANK() function to get information about goods in the goods data table sorted from high to low prices for each category.
mysql> SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 2 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 4 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
| 5 | 1 | 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 |
| 6 | 5 | 1 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 |
| 1 | 8 | 2 | Outdoor sport | Mountain Bike | 1399.90 | 2500 |
| 2 | 11 | 2 | Outdoor sport | Sport coat | 799.90 | 500 |
| 3 | 12 | 2 | Outdoor sport | Skate | 499.90 | 1200 |
| 4 | 7 | 2 | Outdoor sport | Bicycle | 399.90 | 1000 |
| 4 | 10 | 2 | Outdoor sport | Equipment | 399.90 | 3500 |
| 6 | 9 | 2 | Outdoor sport | Alpenstocks | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)
Example: Use the RANK() function to get information about the four most expensive items in the goods data table categorized as "women's/women's boutique".
mysql> SELECT *
-> FROM(
-> SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE category_id = 1 AND row_num <= 4;
+---------+----+-------------+---------------+----------+--------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+----------+--------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 2 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 4 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
+---------+----+-------------+---------------+----------+--------+-------+
4 rows in set (0.00 sec)
You can see that the serial numbers are 1, 2, 2, 4 using the RANK() function, the same price of the goods has the same serial number, followed by discontinuous serial numbers, skipping duplicate serial numbers.
3. DENSE_RANK() function
DENSE_ The RANK() function sorts ordinals side by side and does not skip duplicate ordinals, such as 1, 1, or 2.
Example: Using DENSE_ The RANK() function obtains information about the commodities in the goods table sorted from the highest to the lowest prices for each category.
mysql> SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 2 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 3 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
| 4 | 1 | 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 |
| 5 | 5 | 1 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 |
| 1 | 8 | 2 | Outdoor sport | Mountain Bike | 1399.90 | 2500 |
| 2 | 11 | 2 | Outdoor sport | Sport coat | 799.90 | 500 |
| 3 | 12 | 2 | Outdoor sport | Skate | 499.90 | 1200 |
| 4 | 7 | 2 | Outdoor sport | Bicycle | 399.90 | 1000 |
| 4 | 10 | 2 | Outdoor sport | Equipment | 399.90 | 3500 |
| 5 | 9 | 2 | Outdoor sport | Alpenstocks | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)
Example: Using DENSE_ The RANK() function retrieves information about the four most expensive items in the goods data table categorized as "women's/women's boutique".
mysql> SELECT *
-> FROM(
-> SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE category_id = 1 AND row_num <= 3;
+---------+----+-------------+---------------+----------+--------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+----------+--------+-------+
| 1 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 2 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 3 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
+---------+----+-------------+---------------+----------+--------+-------+
4 rows in set (0.00 sec)
As you can see, use DENSE_ The RANK() function gives the line numbers 1, 2, 2, 3, with the same commodity serial number at the same price, followed by continuous commodity serial numbers without skipping duplicate serial numbers.
2. Distribution function
1.PERCENT_RANK() function
PERCENT_ The RANK() function is a hierarchical value percentage function. Calculate as follows.
(rank - 1) / (rows - 1)
Where rank is the ordinal number generated using the RANK() function and rows is the total number of records in the current window.
Example: Calculate the PECENT_of goods in the goods data table under the category named "Women's / Women's boutique" RANK value.
#Writing 1:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1;
#Writing 2:
mysql> SELECT RANK() OVER w AS r,
-> PERCENT_RANK() OVER w AS pr,
-> id, category_id, category, NAME, price, stock
-> FROM goods
-> WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);
+---+-----+----+-------------+---------------+----------+--------+-------+
| r | pr | id | category_id | category | NAME | price | stock |
+---+-----+----+-------------+---------------+----------+--------+-------+
| 1 | 0 | 6 | 1 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 |
| 2 | 0.2 | 3 | 1 | Dresses/Women's boutique | Sweater | 89.90 | 1500 |
| 2 | 0.2 | 4 | 1 | Dresses/Women's boutique | Jeans | 89.90 | 3500 |
| 4 | 0.6 | 2 | 1 | Dresses/Women's boutique | Dress | 79.90 | 2500 |
| 5 | 0.8 | 1 | 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 |
| 6 | 1 | 5 | 1 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 |
+---+-----+----+-------------+---------------+----------+--------+-------+
6 rows in set (0.00 sec)
2.CUME_DIST() function
CUME_ The DIST() function is primarily used to query scales less than or equal to a value.
Example: Query a goods table for a proportion less than or equal to the current price.
mysql> SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
-> id, category, NAME, price
-> FROM goods;
+---------------------+----+---------------+------------+---------+
| cd | id | category | NAME | price |
+---------------------+----+---------------+------------+---------+
| 0.16666666666666666 | 5 | Dresses/Women's boutique | Pleated skirt | 29.90 |
| 0.3333333333333333 | 1 | Dresses/Women's boutique | T Pension | 39.90 |
| 0.5 | 2 | Dresses/Women's boutique | Dress | 79.90 |
| 0.8333333333333334 | 3 | Dresses/Women's boutique | Sweater | 89.90 |
| 0.8333333333333334 | 4 | Dresses/Women's boutique | Jeans | 89.90 |
| 1 | 6 | Dresses/Women's boutique | Wool jacket | 399.90 |
| 0.16666666666666666 | 9 | Outdoor sport | Alpenstocks | 59.90 |
| 0.5 | 7 | Outdoor sport | Bicycle | 399.90 |
| 0.5 | 10 | Outdoor sport | Equipment | 399.90 |
| 0.6666666666666666 | 12 | Outdoor sport | Skate | 499.90 |
| 0.8333333333333334 | 11 | Outdoor sport | Sport coat | 799.90 |
| 1 | 8 | Outdoor sport | Mountain Bike | 1399.90 |
+---------------------+----+---------------+------------+---------+
12 rows in set (0.00 sec)
3. Front and Back Functions
1. LAG(expr,n) function
The LAG(expr,n) function returns the value of the expr in the first n rows of the current row.
Example: Query the difference between the price of the previous commodity and the price of the current commodity in the goods data table.
mysql> SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price
-> FROM (
-> SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price
-> FROM goods
-> WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
+----+---------------+------------+---------+-----------+------------+
| id | category | NAME | price | pre_price | diff_price |
+----+---------------+------------+---------+-----------+------------+
| 5 | Dresses/Women's boutique | Pleated skirt | 29.90 | NULL | NULL |
| 1 | Dresses/Women's boutique | T Pension | 39.90 | 29.90 | 10.00 |
| 2 | Dresses/Women's boutique | Dress | 79.90 | 39.90 | 40.00 |
| 3 | Dresses/Women's boutique | Sweater | 89.90 | 79.90 | 10.00 |
| 4 | Dresses/Women's boutique | Jeans | 89.90 | 89.90 | 0.00 |
| 6 | Dresses/Women's boutique | Wool jacket | 399.90 | 89.90 | 310.00 |
| 9 | Outdoor sport | Alpenstocks | 59.90 | NULL | NULL |
| 7 | Outdoor sport | Bicycle | 399.90 | 59.90 | 340.00 |
| 10 | Outdoor sport | Equipment | 399.90 | 399.90 | 0.00 |
| 12 | Outdoor sport | Skate | 499.90 | 399.90 | 100.00 |
| 11 | Outdoor sport | Sport coat | 799.90 | 499.90 | 300.00 |
| 8 | Outdoor sport | Mountain Bike | 1399.90 | 799.90 | 600.00 |
+----+---------------+------------+---------+-----------+------------+
12 rows in set (0.00 sec)
2. LEAD(expr,n) function
The LEAD(expr,n) function returns the value of the expr in the last n rows of the current row.
Example: Query the difference between the latter and current commodity prices in the goods data table.
mysql> SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price
-> FROM(
-> SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
+----+---------------+------------+--------------+---------+------------+
| id | category | NAME | behind_price | price | diff_price |
+----+---------------+------------+--------------+---------+------------+
| 5 | Dresses/Women's boutique | Pleated skirt | 39.90 | 29.90 | 10.00 |
| 1 | Dresses/Women's boutique | T Pension | 79.90 | 39.90 | 40.00 |
| 2 | Dresses/Women's boutique | Dress | 89.90 | 79.90 | 10.00 |
| 3 | Dresses/Women's boutique | Sweater | 89.90 | 89.90 | 0.00 |
| 4 | Dresses/Women's boutique | Jeans | 399.90 | 89.90 | 310.00 |
| 6 | Dresses/Women's boutique | Wool jacket | NULL | 399.90 | NULL |
| 9 | Outdoor sport | Alpenstocks | 399.90 | 59.90 | 340.00 |
| 7 | Outdoor sport | Bicycle | 399.90 | 399.90 | 0.00 |
| 10 | Outdoor sport | Equipment | 499.90 | 399.90 | 100.00 |
| 12 | Outdoor sport | Skate | 799.90 | 499.90 | 300.00 |
| 11 | Outdoor sport | Sport coat | 1399.90 | 799.90 | 600.00 |
| 8 | Outdoor sport | Mountain Bike | NULL | 1399.90 | NULL |
+----+---------------+------------+--------------+---------+------------+
12 rows in set (0.00 sec)
4. First and last functions
1.FIRST_VALUE(expr) function
FIRST_ The VALUE (expr) function returns the value of the first expr.
Example: Query the price information of the first commodity, sorted by price.
mysql> SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS first_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+-------+-------------+
| id | category | NAME | price | stock | first_price |
+----+---------------+------------+---------+-------+-------------+
| 5 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 | 29.90 |
| 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 | 29.90 |
| 2 | Dresses/Women's boutique | Dress | 79.90 | 2500 | 29.90 |
| 3 | Dresses/Women's boutique | Sweater | 89.90 | 1500 | 29.90 |
| 4 | Dresses/Women's boutique | Jeans | 89.90 | 3500 | 29.90 |
| 6 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 | 29.90 |
| 9 | Outdoor sport | Alpenstocks | 59.90 | 1500 | 59.90 |
| 7 | Outdoor sport | Bicycle | 399.90 | 1000 | 59.90 |
| 10 | Outdoor sport | Equipment | 399.90 | 3500 | 59.90 |
| 12 | Outdoor sport | Skate | 499.90 | 1200 | 59.90 |
| 11 | Outdoor sport | Sport coat | 799.90 | 500 | 59.90 |
| 8 | Outdoor sport | Mountain Bike | 1399.90 | 2500 | 59.90 |
+----+---------------+------------+---------+-------+-------------+
12 rows in set (0.00 sec)
2.LAST_VALUE(expr) function
LAST_ The VALUE (expr) function returns the value of the last expr.
Example: Query the price information of the last commodity, sorted by price.
mysql> SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+-------+------------+
| id | category | NAME | price | stock | last_price |
+----+---------------+------------+---------+-------+------------+
| 5 | Dresses/Women's boutique | Pleated skirt | 29.90 | 500 | 29.90 |
| 1 | Dresses/Women's boutique | T Pension | 39.90 | 1000 | 39.90 |
| 2 | Dresses/Women's boutique | Dress | 79.90 | 2500 | 79.90 |
| 3 | Dresses/Women's boutique | Sweater | 89.90 | 1500 | 89.90 |
| 4 | Dresses/Women's boutique | Jeans | 89.90 | 3500 | 89.90 |
| 6 | Dresses/Women's boutique | Wool jacket | 399.90 | 1200 | 399.90 |
| 9 | Outdoor sport | Alpenstocks | 59.90 | 1500 | 59.90 |
| 7 | Outdoor sport | Bicycle | 399.90 | 1000 | 399.90 |
| 10 | Outdoor sport | Equipment | 399.90 | 3500 | 399.90 |
| 12 | Outdoor sport | Skate | 499.90 | 1200 | 499.90 |
| 11 | Outdoor sport | Sport coat | 799.90 | 500 | 799.90 |
| 8 | Outdoor sport | Mountain Bike | 1399.90 | 2500 | 1399.90 |
+----+---------------+------------+---------+-------+------------+
12 rows in set (0.00 sec)
5. Other functions
1.NTH_VALUE(expr,n) function
NTH_ The VALUE (expr, n) function returns the value of the nth expr.
Example: Query the price information ranked 2nd and 3rd in the goods data table.
mysql> SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price,
-> NTH_VALUE(price,3) OVER w AS third_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+--------------+-------------+
| id | category | NAME | price | second_price | third_price |
+----+---------------+------------+---------+--------------+-------------+
| 5 | Dresses/Women's boutique | Pleated skirt | 29.90 | NULL | NULL |
| 1 | Dresses/Women's boutique | T Pension | 39.90 | 39.90 | NULL |
| 2 | Dresses/Women's boutique | Dress | 79.90 | 39.90 | 79.90 |
| 3 | Dresses/Women's boutique | Sweater | 89.90 | 39.90 | 79.90 |
| 4 | Dresses/Women's boutique | Jeans | 89.90 | 39.90 | 79.90 |
| 6 | Dresses/Women's boutique | Wool jacket | 399.90 | 39.90 | 79.90 |
| 9 | Outdoor sport | Alpenstocks | 59.90 | NULL | NULL |
| 7 | Outdoor sport | Bicycle | 399.90 | 399.90 | 399.90 |
| 10 | Outdoor sport | Equipment | 399.90 | 399.90 | 399.90 |
| 12 | Outdoor sport | Skate | 499.90 | 399.90 | 399.90 |
| 11 | Outdoor sport | Sport coat | 799.90 | 399.90 | 399.90 |
| 8 | Outdoor sport | Mountain Bike | 1399.90 | 399.90 | 399.90 |
+----+---------------+------------+---------+--------------+-------------+
12 rows in set (0.00 sec)
2. NTILE(n) function
The NTILE(n) function divides the ordered data in a partition into n buckets and records the bucket number.
Examples: Goods in the goods table are grouped into three groups by price.
mysql> SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+----+---------------+------------+---------+
| nt | id | category | NAME | price |
+----+----+---------------+------------+---------+
| 1 | 5 | Dresses/Women's boutique | Pleated skirt | 29.90 |
| 1 | 1 | Dresses/Women's boutique | T Pension | 39.90 |
| 2 | 2 | Dresses/Women's boutique | Dress | 79.90 |
| 2 | 3 | Dresses/Women's boutique | Sweater | 89.90 |
| 3 | 4 | Dresses/Women's boutique | Jeans | 89.90 |
| 3 | 6 | Dresses/Women's boutique | Wool jacket | 399.90 |
| 1 | 9 | Outdoor sport | Alpenstocks | 59.90 |
| 1 | 7 | Outdoor sport | Bicycle | 399.90 |
| 2 | 10 | Outdoor sport | Equipment | 399.90 |
| 2 | 12 | Outdoor sport | Skate | 499.90 |
| 3 | 11 | Outdoor sport | Sport coat | 799.90 |
| 3 | 8 | Outdoor sport | Mountain Bike | 1399.90 |
+----+----+---------------+------------+---------+
12 rows in set (0.00 sec)
2.5 Summary
The feature of window functions is that they can be grouped and sorted within groups. In addition, the window function does not reduce the number of rows in the original table because of grouping, which is very useful for statistics and sorting based on the original table data.
3. New Feature 2: Common Table Expressions
Common table expressions (or common table expressions) are referred to simply as CTE (Common Table Expressions). CTE is a named temporary result set that scopes to the current statement. CTE can be interpreted as a subquery that can be reused. Of course, it is slightly different from subqueries. CTE can refer to other CTEs, but subqueries cannot refer to other subqueries. Therefore, consider replacing subqueries.
Common table expressions can be classified into two types, common table expressions and recursive common table expressions, depending on their syntax structure and execution.
3.1 Common Table Expressions
The grammatical structure of common table expressions is:
WITH CTE Name AS (Subquery) SELECT|DELETE|UPDATE Sentence;
Common common table expressions are similar to subqueries, but unlike subqueries, they can be referenced multiple times and can be referenced by other common table expressions.
Example: Query the details of the Department where the employee is located.
mysql> SELECT * FROM departments
-> WHERE department_id IN (
-> SELECT DISTINCT department_id
-> FROM employees
-> );
+---------------+------------------+------------+-------------+
| department_id | department_name | manager_id | location_id |
+---------------+------------------+------------+-------------+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| 30 | Purchasing | 114 | 1700 |
| 40 | Human Resources | 203 | 2400 |
| 50 | Shipping | 121 | 1500 |
| 60 | IT | 103 | 1400 |
| 70 | Public Relations | 204 | 2700 |
| 80 | Sales | 145 | 2500 |
| 90 | Executive | 100 | 1700 |
| 100 | Finance | 108 | 1700 |
| 110 | Accounting | 205 | 1700 |
+---------------+------------------+------------+-------------+
11 rows in set (0.00 sec)
This query can also be done as a common table expression:
mysql> WITH emp_dept_id
-> AS (SELECT DISTINCT department_id FROM employees)
-> SELECT *
-> FROM departments d JOIN emp_dept_id e
-> ON d.department_id = e.department_id;
+---------------+------------------+------------+-------------+---------------+
| department_id | department_name | manager_id | location_id | department_id |
+---------------+------------------+------------+-------------+---------------+
| 90 | Executive | 100 | 1700 | 90 |
| 60 | IT | 103 | 1400 | 60 |
| 100 | Finance | 108 | 1700 | 100 |
| 30 | Purchasing | 114 | 1700 | 30 |
| 50 | Shipping | 121 | 1500 | 50 |
| 80 | Sales | 145 | 2500 | 80 |
| 10 | Administration | 200 | 1700 | 10 |
| 20 | Marketing | 201 | 1800 | 20 |
| 40 | Human Resources | 203 | 2400 | 40 |
| 70 | Public Relations | 204 | 2700 | 70 |
| 110 | Accounting | 205 | 1700 | 110 |
+---------------+------------------+------------+-------------+---------------+
11 rows in set (0.00 sec)
Examples show that common table expressions can act as subqueries. If you encounter a scenario in which you need to use a subquery later, you can define a common table expression before the query, then use it in place of the subquery in the query. Moreover, compared with subqueries, common table expressions have the advantage that queries that have defined common table expressions can refer to common table expressions multiple times like a table, while subqueries cannot.
3.2 Recursive Common Table Expressions
Recursive common table expressions are also common table expressions, except that they have their own characteristics, that is, they can call themselves. Its grammatical structure is:
WITH RECURSIVE CTE Name AS (Subquery) SELECT|DELETE|UPDATE Sentence;
Recursive common table expressions consist of two parts, a seed query and a recursive query, connected by the keyword UNION [ALL]. The seed query here means to get the initial value of the recursion. This query only runs once to create the initial dataset, and then the recursive query is executed until no new query data is generated and returned recursively.
**Case: ** For our common employees table, which contains employee_id, last_name and manager_id three fields. If A is the manager of b, then we can call B a subordinate, and if B is also the manager of c, then C is the subordinate of B and is the subordinate of A.
Below we try to list all subordinate information in a query.
If you solve it with what we have learnt before, it will be more complex and will take at least four queries to complete:
-
The first step is to find out first-generation managers, that is, people who don't take anyone else as their manager and store the results in temporary tables.
-
The second step is to find out all the people who are managers of the first generation, get a subordinate set, and save the results in a temporary table.
-
The third step is to find all the subordinates who are managers, get a set of subordinates, and save the results in a temporary table.
-
Step 4, find out all the people below as managers and get a result set.
If the result set of step 4 is empty, the calculation ends, and the result set of step 3 is the subordinate set we need, otherwise we must proceed to step 4 until the result set is empty. For example, with this data table above, you need to go to step 5 to get an empty result set. Finally, there is a sixth step: merging the results of the third and fourth steps so that we can finally get the set of results we need.
If you use recursive common table expressions, it's very simple. Let me give you some ideas.
-
Use the seed query in the recursive common table expression to find out the initial managers. Field n denotes the generation, with an initial value of 1, indicating that it is the first-generation manager.
-
Using a recursive query in a recursive common table expression, find out who is the human manager in this recursive common table expression and add a value of 1 to the next generation. Until no one manages this recursive common table expression as a human, recursive return.
-
In the final query, select all the people whose generation is greater than or equal to 3. They must be subordinates of the third generation and above, that is, subordinates. This gives us the result set we need.
It looks like there are three steps here, but it's actually three parts of a query that only needs to be executed once. There is no need to save intermediate results in a temporary table, which is much simpler than the method just used.
Code implementation:
WITH RECURSIVE cte AS ( SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100 -- Seed Query, Find First Generation Leaders UNION ALL SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte ON (a.manager_id = cte.employee_id) -- Recursive queries to find people led by recursive common table expressions ) SELECT employee_id,last_name FROM cte WHERE n >= 3;
In summary, recursive common table expressions are useful for querying tree-structured data with a common root node. It can easily find the data of all nodes without hierarchical restrictions. If you use other queries, they are more complex.
3.3 Summary
Common table expressions are used instead of subqueries and can be referenced multiple times. Recursive common table expressions are very efficient for querying tree-structured data with a common root node, making it easy to find queries that are difficult to handle by other queries.