Main content of this paper
- This paper briefly introduces the process of processing text information by convolutional neural network (CNN)
- Use CNN for text classification and comment the code
- Article code[ https://github.com/540117253/Chinese-Text-Classification ]
1, CNN overview
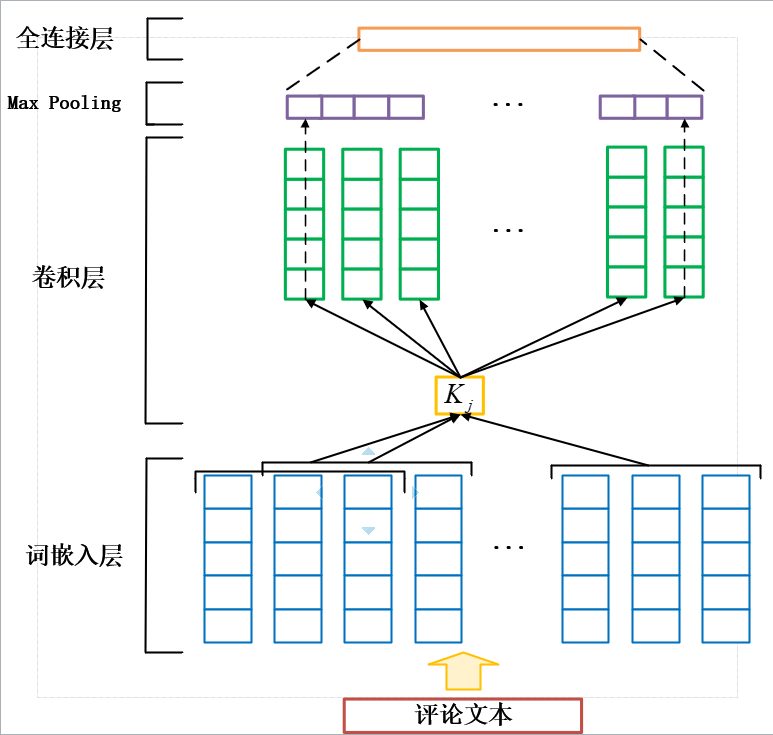
The structure of CNN text encoder is shown in Figure 1. In the first layer, the word mapping function f:M → Rdf:M \rightarrow R^{d}f:M → Rd maps each word of the comment to a ddd dimension vector, and then converts the given comment text to a word embedding matrix with fixed length as TTT (only the first TTT words in the comment text are intercepted, if the text is not long enough, it will be filled).
After the word mapping layer is the convolution layer, which contains mmm neurons. The convolution kernel K ∈ Rt × dK \in R^{t \times d}K ∈ Rt × d corresponding to each neuron is used for convolution operation of word vectors to extract features. Assume V1:TV_{1:T}V1:T is a word embedding matrix whose text length is TTT. The characteristics of the jjj neurons are as follows:
zj=ReLU(V1:T∗Kj+bj)
z_j=ReLU(V_{1:T}*K_j + b_j)
zj=ReLU(V1:T∗Kj+bj)
Where bjb_jbj is the bias term, * * * is the convolution operation, and relurelulu is the nonlinear activation function.
Finally, under the action of sliding window t t t, the characteristics of the jjj neurons are z1,z2,...,zjT − t+1z_1,z_2,...,z_j^{T-t+1}z1,z2,...,zjT−t+1. It is mainly used to capture the most important feature with the maximum value. It is defined as:
oj=max(z1,z2,...,zjT−t+1)
o_j = max(z_1,z_2,...,z_j^{T-t+1})
oj=max(z1,z2,...,zjT−t+1)
the final output of the final convolution layer is the splicing result of mmm neuron output, which is defined as:
O=[o1,o2,....om]
O=[o_1,o_2,....o_m]
O=[o1,o2,....om]
Generally, OOO will be sent to the full connection layer, which contains the weight matrix W ∈ Rm × nW \in R ^{m \times n}W ∈ Rm × N and the offset term g ∈ Rn \ in R ^ ng ∈ Rn. The specific formula is as follows:
X=ReLU(WO+g)
X=ReLU(WO+g)
X=ReLU(WO+g)
On the whole, the convolution kernel size of CNN is generally 3 or 5 (that is, only 3 or 5 words of information are calculated in a convolution operation), which can scan the whole text through a sliding window by using only one convolution kernel, so the whole text can be regarded as a group of parameters sharing the same convolution kernel, which can save memory space very well. However, a convolution operation can only contain the words in the convolution window. The longer the input text is, the more previous information will be lost when the convolution window slides to the end of the text. Therefore, for text data, RNN is generally used, which is better than CNN in text information extraction.
2, CNN text classification example
2.1 data set introduction
1. Download address:
[https://github.com/skdjfla/toutiao-text-classfication-dataset ]
2. Format:
6552431613437805063_ ! 102_ ! news_ entertainment_ ! Xie Na clarifies the Internet rumors for Li haofei, and then adds points for her two actions_ ! Tong Liya, Internet rumors, happy base camp, Li haofei, Xie Na, audience
Each line of data to_ ! The divided fields are: News ID, category code (see below), category name (see below), news string (only including title), news keyword
Classification code and name:
100 people's livelihood stories news_story 101 cultural news_culture 102 entertainment news_entertainment 103 sports news_sports 104 financial news_finance 106 real estate news_house 107 Auto news_car 108 Education news_edu 109 Technology news_tech 110 military news_military 112 Tourism news_travel 113 international news_world 114 stock 115 agricultural news_agriculture 116 e-games news_game
2.2 pre training word vector
The pre training word vector uses the word vector trained in Baidu Encyclopedia based on ACL-2018 model.
Download address:[ https://github.com/Embedding/Chinese-Word-Vectors ]
2.3 data preprocessing
- Remove useless characters and do word segmentation
- Build the dictionary of the whole dataset, key=word, value = the number of words
- Truncate or supplement 0 to ensure that the length of each sample is maxlen
- Label of the serialized sample, for example, the category number of "sports news" is 1, and the category number of "entertainment news" is 2
- Convert the processed data to DataFrame format and save it to hard disk
2.4 definition of CNN model
''' Text => CNN => Fully_Connected => Softmax //Parameters: filter_sizes: The size of convolution kernel num_filters: The number of convolution kernels embedded_size: The dimension of word vector dict_size: Number of words in the dataset maxlen: Maximum number of words per sample label_num: Number of sample categories learning_rate: Initial learning rate of gradient optimizer ''' class CNN: def __init__(self, filter_sizes, num_filters, embedded_size, dict_size, maxlen, label_num, learning_rate): # print('model_Name:', 'CNN') self.droput_rate = 0.5 ''' Convulutional Neural Network ''' def cnn (input_emb, filter_sizes, num_filters): pooled_outputs = [] for i, filter_size in enumerate(filter_sizes): filter_shape = [filter_size, embedded_size, 1, num_filters] W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W") b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b") conv = tf.nn.conv2d( input_emb, W, strides=[1, 1, 1, 1], padding="VALID", name="conv") # shape(conv) = [None, sequence_length - filter_size + 1, 1, num_filters] h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu") word_num = input_emb.shape.as_list()[1] pooled = tf.nn.max_pool( h, ksize=[1, word_num - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding='VALID', name="pool") # shape(pooled) = [None, 1, 1, num_filters] pooled_outputs.append(pooled) num_filters_total = num_filters * len(filter_sizes) h_pool = tf.concat(pooled_outputs,3) h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total]) # shape = [None,num_filters_total] cnn_fea = tf.nn.dropout(h_pool_flat, keep_prob = self.droput_rate) return cnn_fea self.X = tf.placeholder(tf.int32, [None, maxlen], name='input_x') self.Y = tf.placeholder(tf.int64, [None]) self.encoder_embeddings = tf.Variable(tf.random_uniform([dict_size, embedded_size], -1, 1), trainable=False) encoder_embedded = tf.nn.embedding_lookup(self.encoder_embeddings, self.X) # Since conv2d requires a four-dimensional input data, a dimension needs to be added manually. encoder_embedded = tf.expand_dims(encoder_embedded, -1) # shape(encoder_embedded) = [None, user_review_num*u_n_words, embedding_size, 1] outputs = cnn(input_emb = encoder_embedded, filter_sizes = filter_sizes, num_filters = num_filters) self.logits = keras.layers.Dense(label_num, use_bias=True)(outputs) self.probability = tf.nn.softmax(self.logits, name='probability') self.cost = tf.nn.sparse_softmax_cross_entropy_with_logits( labels = self.Y, logits = self.logits) self.cost = tf.reduce_mean(self.cost) self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost) self.pre_y = tf.argmax(self.logits, 1, name='pre_y') correct_pred = tf.equal(self.pre_y, self.Y) self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
2.5 training model
- The preprocessed data set is divided into 80% training set, 10% verification set and 10% test set
- After each training with a training set, the verification set is used for testing.
- When the accuracy of the verification set drops 5 times in a row, step 2 is stopped, and then the result of the test set is used as the final performance of the model.