summary
- The open source NoSQL database, the native graph database, was developed in 2003, using scala and java language, and was released in 2007;
- One of the most advanced graph databases in the world, which provides native graph data storage, retrieval and processing;
- The Property graph model is adopted to greatly improve and enrich the graph data model;
- Cypher, an exclusive query language, is intuitive and efficient;
Storage structure of Neo4j
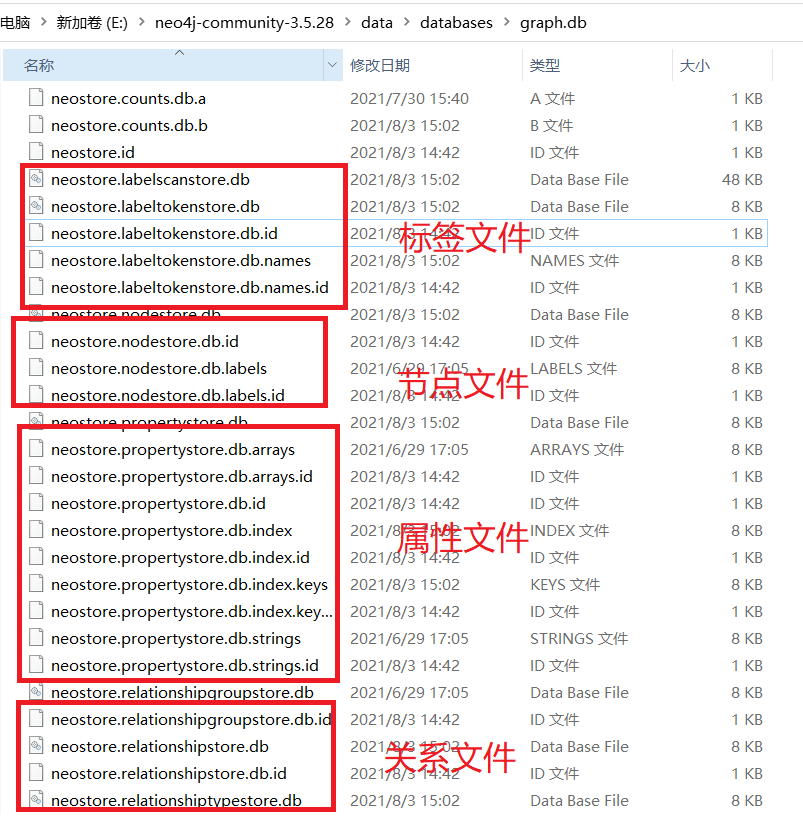
In Neo4j, its database files are divided into four categories for classified storage:
- label
- node
- attribute
- relationship
neo4j browser
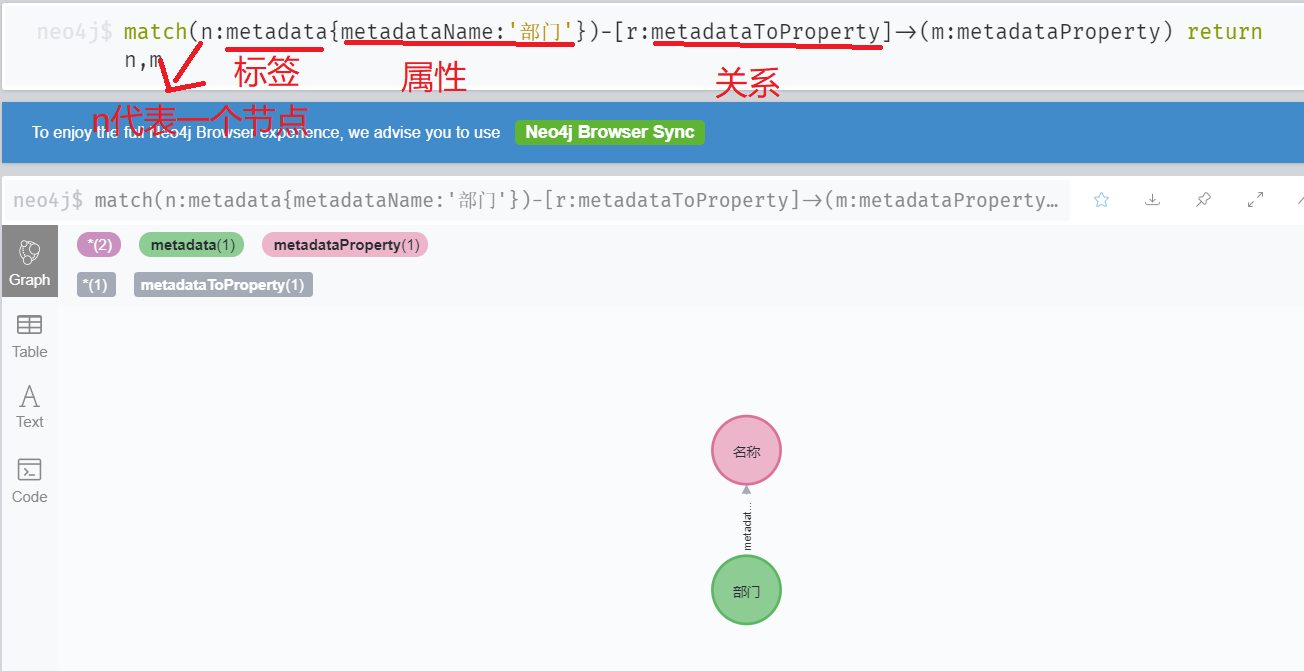
Basic statement
// Running statement
MATCH (n) DETACH DELETE n;
// Find all
match(n) return n;
//Create a single node
CREATE (a:Person {name:'a', born:1997}) return a;
//Create multiple node s
CREATE (b:Person {name:'b', born:1997}),(c:Person {name:'c', born:1961}) Return b,c;
//Two statements for creating relationships
1.according to Id Create relationship
start m =node(1025),f=node(1024) create (m)-[n:gift]->(f) return m,f;
2.Create relationships based on conditions
CREATE (m:Person{name:'a'})-[:gift]->(f:Person{name:'b'}) return m,f;
//Create relationships for previously defined nodes
MATCH(n:Person{name:'a',born:1997}),(b:Person{name:'b',born:1997}) merge(n)-[:teacher]->(b);
//Condition query
MATCH (n:Person{age:'18'}) return n;
match(n:Person) where n.age = '18' return n;
//Specify number
MATCH (n:Test) RETURN n LIMIT 25;
//Query first level relationship
match q=(n:A{name:'House 2'})-[]-()return q;
//Query secondary relationship
match q=(n:A{name:'House 2'})-[]-(),p=(n:A{name:'House 2'})-[]-()-[]-() return p,q;
//Modify statement
MATCH (n:Person)WHERE n.name="a" SET n.born = 2003RETURN n;
//Delete statement (when the node has a relationship, it cannot be deleted)
match(n:Person{name:'Zhang San'}) delete n;
//If there is a relationship, delete the relationship first
MATCH(n:Person{name:'a',born:1997}),(b:Person{name:'d',born:1987}) merge(n)-[p:children]->(b) delete p;
//Delete node b and its relationship
MATCH(n:Person{name:'a',born:1997}),(b:Person{name:'b',born:1997}) merge(n)-[p:teacher]->(b) delete p,b;
//Delete Test and all its relationships
match p=(n:Test)-[]-() delete p;
match(n:Test) detach delete n;
Application scenario
Recommendation engine
- In 2012, google officially released the knowledge map search engine
- 2013 facebook open knowledge map search portal
knowledge graph
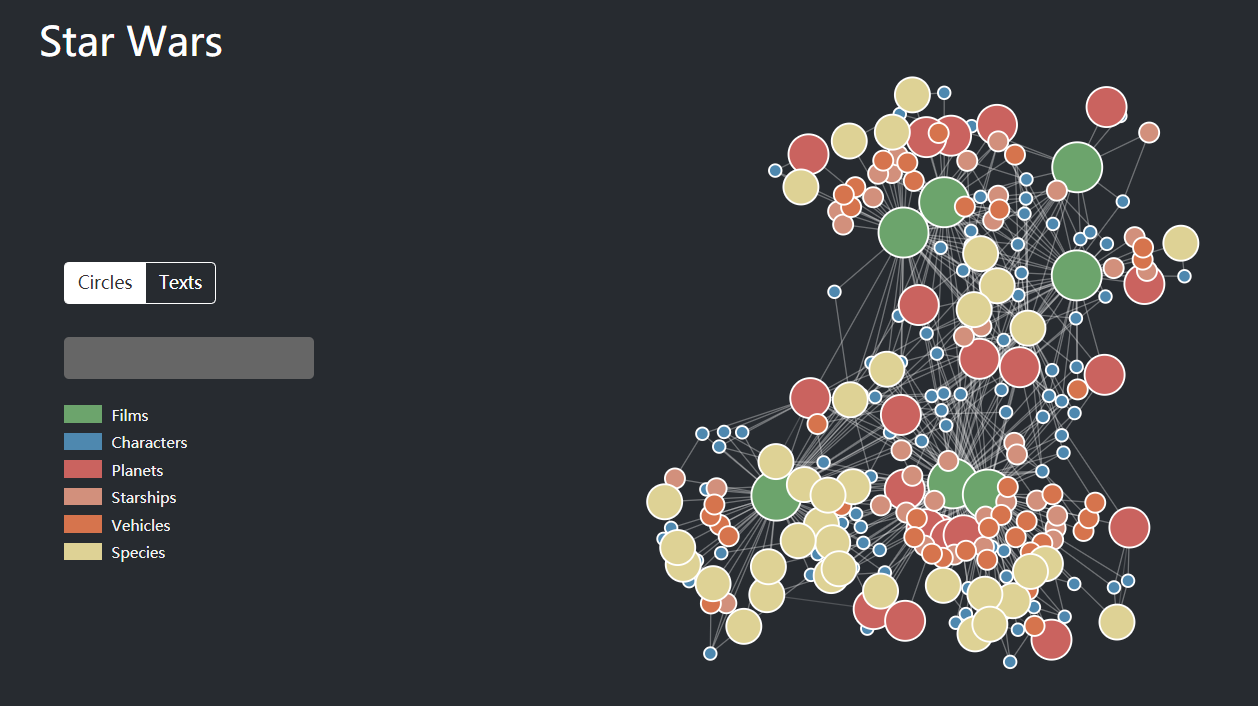
Star Wars character relationship map
Social network map
In the social network, if you want to know Trump's daughter Ivanka, query the shortest path to get to know Ivanka, and everyone in this path is single. And no matter who you are, you are likely to know Ivanka through 6 ~ 7 people. This is the famous six degree separation theory (small world effect): any two strangers can always have an inevitable connection or relationship through a certain way of contact.
In the hypothetical program implementation, a global character relationship network can be built through Neo4j, and Ivanka can be found by specifying the start node and end node.
MATCH (p1:Person {name:"xxx"}),(p2:Person{name:"ivanka "}),
p=shortestpath((p1)-[*..6]->(p2))
RETURN p
other
In the multi-dimensional association analysis scenario of anti fraud in the financial industry, anti fraud is already a core application. Through the graph database, association analysis can be done for different individuals and groups, from the behavior of people in a specified time, such as the IP address of places they have been Correlation analysis of used MAC addresses (including mobile phone, PC, WIFI, etc.) and social networks, whether they have appeared near the same geographical location at the same time point, and whether there is historical transaction information between bank accounts.
In daily operation, enterprises will deal with customers, partners, channels and investors, which also determines that enterprises are widely involved in all fields of society and present complex aspects. Therefore, they can query and mine information layer by layer through the enterprise data map.
Figure advantages and disadvantages of database
Relational database was originally designed to deal with paper forms and tabular structure. When relational database modeled complex relationships in the actual model, it did not do very well, that is to say, relational database did not do well in dealing with links, and its expansibility was also very poor.
Relational database is a powerful mainstream database. After 40 years of development and improvement, it has been very reliable, powerful and practical, and can store a large amount of data.
What are relational databases not good at? When you look for data items, relational patterns, or relationships between multiple data items, they often end in failure.
In the search of understanding Ivanka just mentioned, we deal with the social network map with depth of 6. Now suppose two people are randomly selected, and whether there is a path to associate them with a relationship length of up to 5. For a social network containing 1 million people and about 50 friends per person, the performance comparison between the traditional relational database and Neo4j is as follows:
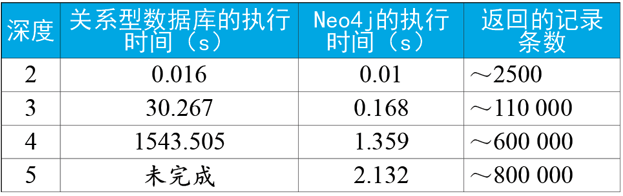
The results clearly show that graph database is the best choice for associated data.
Any shallow traversal query that goes beyond looking for direct friends or looking for friends will slow the search because of the number of indexes involved. Because graph database uses graph traversal technology, the amount of data to be calculated is far less than that of relational database, so it is very fast.
The graph database is not perfect. Although it makes up for the defects of many relational databases, it also has some inapplicability, such as the following fields:
- Record a large amount of event based data (such as log entries or sensor data);
- Processing large-scale distributed data, similar to Hadoop;
- Binary data storage;
- It is suitable for structured data stored in relational database.
expectation
Although relational database is still the best choice for storing structured data, graph database is more suitable for managing semi-structured data, unstructured data and graphic data. If the data model contains a large amount of associated data, and you want to use an intuitive, interesting and fast database for development, you can consider trying the graph database.
In the actual production environment, a truly mature and effective analysis environment should include relational database and graph database, which can be combined for effective analysis according to different application scenarios.
On the whole, there are still many unsolved problems in graph database, and many technologies need to be developed, such as super node problem and distributed large graph storage. It can be predicted that with the expansion of Internet data, graph database will usher in a development opportunity, and various computing and data mining jobs based on graph will become more and more hot.