netfilter Kernel Implementation overview
1, Foreword
netfilter is the foundation of network firewall in Linux kernel. Whether it is iptables based on xtables, conntrack and nftables, its bottom layer is based on netfilter. In general, netfilter provides a relatively general firewall framework, which provides an entry through which other network modules in the kernel can implement their own network logic. This paper simply combs the whole framework of netfilter and its kernel implementation.
2, netfilter framework
2.1 basic principles
Compared with some functions based on netfilter (such as iptables), the implementation of netfilter itself is not complex. In essence, it provides some HOOK points in the kernel network. Different protocol families (such as ip protocol family, arp protocol, bridge equipment, etc.) provide different HOOK points. Taking ipv4 protocol as an example, the HOOK points provided by it are consistent with the five chains in iptables we usually contact (for details, please refer to: iptables principle Introduction to rule chain in:
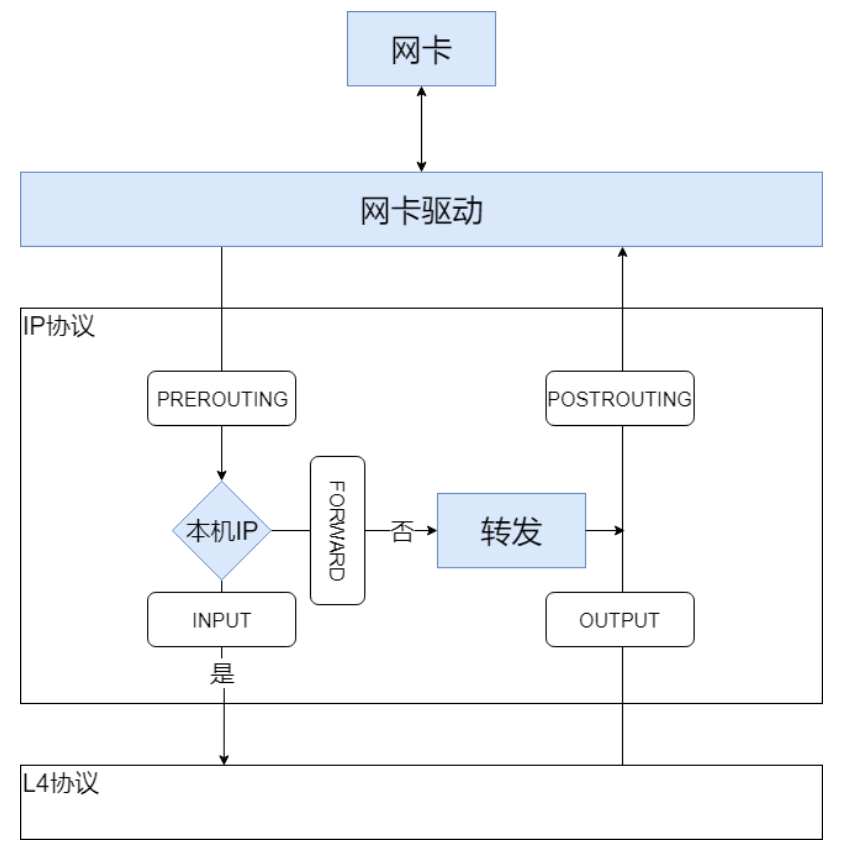
When the kernel is implemented, struct netns is used_ NF to represent all currently supported protocol families and their HOOK points, as shown below:
struct netns_nf {
#if defined CONFIG_PROC_FS
struct proc_dir_entry *proc_netfilter;
#endif
const struct nf_queue_handler __rcu *queue_handler;
const struct nf_logger __rcu *nf_loggers[NFPROTO_NUMPROTO];
#ifdef CONFIG_SYSCTL
struct ctl_table_header *nf_log_dir_header;
#endif
/* Since each HOOK point corresponds to a struct nf_hook_entries, which is an array
* To store the entries corresponding to all HOOK points of the current protocol family.
*/
struct nf_hook_entries __rcu *hooks_ipv4[NF_INET_NUMHOOKS];
struct nf_hook_entries __rcu *hooks_ipv6[NF_INET_NUMHOOKS];
#ifdef CONFIG_NETFILTER_FAMILY_ARP
struct nf_hook_entries __rcu *hooks_arp[NF_ARP_NUMHOOKS];
#endif
#ifdef CONFIG_NETFILTER_FAMILY_BRIDGE
struct nf_hook_entries __rcu *hooks_bridge[NF_INET_NUMHOOKS];
#endif
#if IS_ENABLED(CONFIG_DECNET)
struct nf_hook_entries __rcu *hooks_decnet[NF_DN_NUMHOOKS];
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV4)
bool defrag_ipv4;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
bool defrag_ipv6;
#endif
};
It can be seen here that the key to the implementation of netfilter is struct nf_hook_entries is the structure. This structure defines the HOOK functions registered by all modules in the kernel at their corresponding HOOK points.
/* Array multiple nf_hook_entry is an organized structure. Generally, a protocol family or
* A HOOK point of a firewall (such as ipv4) corresponds to an nf_hook_entries, representing all registrations
* The handler at this HOOK point.
*
* This structure adopts the following structure diagram in terms of data storage:
* num_hook_entries | (struct nf_hook_entry) * num_hook_entries |
* (struct nf_hook_ops) * num_hook_entries
*
* Each entry has an ops corresponding to it. You can directly find the entry and ops through the index.
*/
struct nf_hook_entries {
u16 num_hook_entries;
/* padding */
struct nf_hook_entry hooks[];
*/
};
2.2 priority
There are several HOOK functions on the same HOOK point of the same protocol family. The execution order of these functions is determined according to the priority of registration. This can be obtained from the registration function of HOOK function__ nf_register_net_hook() can see. NF in progress_ HOOK_ When OPS is registered, it will first find the corresponding NF according to the namespace, protocol family and HOOK number_ HOOK_ Entries, and then call nf_. HOOK_ entries_ Grow inserts it into nf_hook_entries. When inserting, all nf_hook_entries are stored in descending order of priority.
Each protocol family has its own set of priority definitions. Taking IPv4 as an example, its priority list is as follows:
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_RAW_BEFORE_DEFRAG = -450,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
It can be seen that although both connrack and NAT work at the same HOOK point (preouting), connrack will always run before NAT because of its high priority.
2.3 HOOK registration
Here's a brief look at how the HOOK function on HOOK is registered. HOOK functions are defined and registered through struct nf_hook_ops structure. The pf and hooknum fields of the structure basically determine the protocol family to which the current HOOK function belongs and the HOOK point; nf_hookfn defines the fallback function to be executed.
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook;
struct net_device *dev;
void *priv;
u_int8_t pf;
unsigned int hooknum;
/* Priority. Different ops on the same HOOK point are sorted from small to large
* In order.
*/
int priority;
};
Taking the ip4 protocol in the conntrack module as an example, it defines the following struct nf_hook_ops:
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_confirm,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_confirm,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};
When conntrack is enabled (see nf_ct_netns_get() function for details), the above four HOOK functions will be registered to the corresponding HOOK point. The specific registration process is relatively simple. First, according to NF_ HOOK_ The pf and hooknum of ops find the corresponding struct NF from the current network namespace_ HOOK_ Entries, and then insert ops into entries according to a certain priority.
2.4 execution
The implementation of netfilter is relatively simple. Generally, it uses macros to define NF_HOOK(). It will find the corresponding struct NF of the current namespace according to the protocol family and hooknum_ hook_ entries.
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb);
return ret;
}
Then, traverse struct NF_ hook_ All structs on entries NF_ hook_ Enter and call the callback function on it.
/* Execute all registered HOOK functions on a specific HOOK point of a specific protocol family, and do corresponding processing according to the return value.
* If the function returns 1, it means okfn should be executed; Otherwise, do not execute.
*/
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state,
const struct nf_hook_entries *e, unsigned int s)
{
unsigned int verdict;
int ret;
for (; s < e->num_hook_entries; s++) {
verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
switch (verdict & NF_VERDICT_MASK) {
case NF_ACCEPT:
break;
case NF_DROP:
kfree_skb(skb);
ret = NF_DROP_GETERR(verdict);
if (ret == 0)
ret = -EPERM;
return ret;
case NF_QUEUE:
ret = nf_queue(skb, state, s, verdict);
if (ret == 1)
continue;
return ret;
default:
/* Implicit handling for NF_STOLEN, as well as any other
* non conventional verdicts.
*/
return 0;
}
}
return 1;
}
3, nftables
Similar to iptables, nftables is also a firewall tool in Linux system. The difference is that iptables only supports ip protocol families. For example, if you want to intercept arp, you need to use arptable. Moreover, due to the cumbersome framework and low efficiency of iptables implementation, nftables has been used to replace iptables in the current release version. Here, let's take nftables as an example to see how nftables are associated with netfilter.
3.1 basic principles
For the concepts of table and chain, nftables is completely consistent with iptables, which is why users can switch from iptables to nftables without perception. To understand the Kernel Implementation of nftables, we need to understand the following structures: struct nft_chain_type,struct nft_chain,struct nft_table. If you have a certain understanding of the implementation of iptables (xtables), the concept here will become easy to understand.
The basic concepts of table and chain will not be repeated here. We need to focus on the concept of chain_type, which is somewhat different from iptables. The table in iptables is predefined. For example, the filter table is used for filtering and the NAT table is used for forwarding. That is, the table is used to distinguish the role of rules. Nftables is somewhat different. Nftables is more flexible. It has no fixed (default) tables. Users can add tables at will. So how does a rule distinguish between filtering and NAT? This is determined by the chain type. Let's take a brief look at the use of nftables. The following command creates the filter table and adds three chains of input, output and forward to it. In this way, the function of this table is the same as that of the filter in iptables. The type field in the command determines that these three chains can only be used as filters and not as Nats.
nft create table inet filter
nft add chain inet filter input { type filter hook input priority filter \; }
nft add chain inet filter output { type filter hook output priority filter \; }
nft add chain inet filter forward { type filter hook forward priority filter \; }
Next, we also create the NAT type chain into the filter table, and we can see that it has also been added successfully. This shows that the rule type is determined by the chain type, not the table type.
nft add chain inet filter prerouting { type nat hook prerouting priority dstnat \; }
3.2 Kernel Implementation
Through the above analysis, we can probably know that the processing logic of nftables is determined by the chain type, and struct NFT is adopted in the kernel_ chain_type. In fact, chain_type can be understood as the metadata of nftables, which defines the HOOK points, processing functions and other information supported on the current chain type. The following is the chain of filter type of ipv4_ Definition of type:
static const struct nft_chain_type nft_chain_filter_ipv4 = {
.name = "filter",
.type = NFT_CHAIN_T_DEFAULT,
.family = NFPROTO_IPV4,
.hook_mask = (1 << NF_INET_LOCAL_IN) |
(1 << NF_INET_LOCAL_OUT) |
(1 << NF_INET_FORWARD) |
(1 << NF_INET_PRE_ROUTING) |
(1 << NF_INET_POST_ROUTING),
.hooks = {
[NF_INET_LOCAL_IN] = nft_do_chain_ipv4,
[NF_INET_LOCAL_OUT] = nft_do_chain_ipv4,
[NF_INET_FORWARD] = nft_do_chain_ipv4,
[NF_INET_PRE_ROUTING] = nft_do_chain_ipv4,
[NF_INET_POST_ROUTING] = nft_do_chain_ipv4,
},
};
All the chain types supported by the kernel are registered with the global array chain_type. This is a two-dimensional array. The indexes are protocol number and chain type respectively.
/* According to the protocol family and table type, the NFT is set as a two-dimensional array_ chain_ Organize yourself. * Where, each nft_chain_type corresponds to a table of a protocol family. * * NFT_CHAIN_T_MAX Represents the maximum number of protocol family tables, such as FILTER, NAT, etc. */ static const struct nft_chain_type *chain_type[NFPROTO_NUMPROTO][NFT_CHAIN_T_MAX];
Among them, there are three types of chain models currently supported:
- NFT_CHAIN_T_DEFAULT: the default chain type (filter type)
- NFT_CHAIN_T_ROUTE: chain of route type
- NFT_CHAIN_T_NAT: the chain for NAT address forwarding
3.3 addition of chain
Let's take a look at how a chain is added to the kernel and how it is associated with netfilter. All nftables operations are implemented through netlink, and the addition of the chain will eventually call nf_tables_addchain() is the kernel function. As can be seen from the following function processing process, when creating chains, the kernel will create a corresponding NF for each chain (non NAT type)_ hook_ Ops structure and register in the corresponding entries in the netfilter framework. For NAT type chains, NAT involves the cooperation between various modules, so it is a little more complex. This part will be specifically discussed below.
static int nf_tables_addchain(struct nft_ctx *ctx, u8 family, u8 genmask,
u8 policy, u32 flags)
{
const struct nlattr * const *nla = ctx->nla;
struct nft_table *table = ctx->table;
struct nft_base_chain *basechain;
struct nft_stats __percpu *stats;
struct net *net = ctx->net;
char name[NFT_NAME_MAXLEN];
struct nft_trans *trans;
struct nft_chain *chain;
struct nft_rule **rules;
int err;
if (table->use == UINT_MAX)
return -EOVERFLOW;
if (nla[NFTA_CHAIN_HOOK]) {
struct nft_chain_hook hook;
if (flags & NFT_CHAIN_BINDING)
return -EOPNOTSUPP;
/* Extract the information needed to register the hook function from netlink, including the type of the current chain
* Priority, hooknum, etc., and stored in nft_chain_hook structure.
*/
err = nft_chain_parse_hook(net, nla, &hook, family, true);
if (err < 0)
return err;
/* NFT chain is adopted in the kernel_ Chain structure representation. This structure mainly saves
* The content and relationship among chains, tables and rules. Each NFT_ Chains are embedded in
* nft_base_chain In the structure, this structure holds the chain and netfilter
* Related contents, including NF registered in netfilter_ hook_ ops,
* Type of chain, etc.
*/
basechain = kzalloc(sizeof(*basechain), GFP_KERNEL);
if (basechain == NULL) {
nft_chain_release_hook(&hook);
return -ENOMEM;
}
chain = &basechain->chain;
if (nla[NFTA_CHAIN_COUNTERS]) {
stats = nft_stats_alloc(nla[NFTA_CHAIN_COUNTERS]);
if (IS_ERR(stats)) {
nft_chain_release_hook(&hook);
kfree(basechain);
return PTR_ERR(stats);
}
rcu_assign_pointer(basechain->stats, stats);
static_branch_inc(&nft_counters_enabled);
}
/* Initialize bashchain, including using the priority and hook point in hook
* bashchain->ops,Use hook in type_ FN to initialize the hook function.
*/
err = nft_basechain_init(basechain, family, &hook, flags);
[......]
/* Register ops with netfilter. For chains of non NAT type, the
* nf_register_net_hook()To register basechain - > OPS directly;
* For NAT type chains, chain is called_ Type.
* Take IPv4 as an example, NF will be called here_ nat_ ipv4_ register_ FN () to register.
*/
err = nf_tables_register_hook(net, table, chain);
if (err < 0)
goto err_destroy_chain;
[......]
4, conntrack and nat
4.1 basic principle of conntrack
Conntrack, that is, connect track, is used to track all connection states in the system, including tcp, udp, icmp and other protocols. Conntrack is also based on netfilter. The framework of conntrack is slightly different for different protocol families. At present, the supported protocol families include ipv4, ipv6 and Bridge (bridge device). This can be from NF_ ct_ netns_ do_ You can see it in the get () function. Here, take ipv4 as an example to explain the general framework of conntrack implementation.
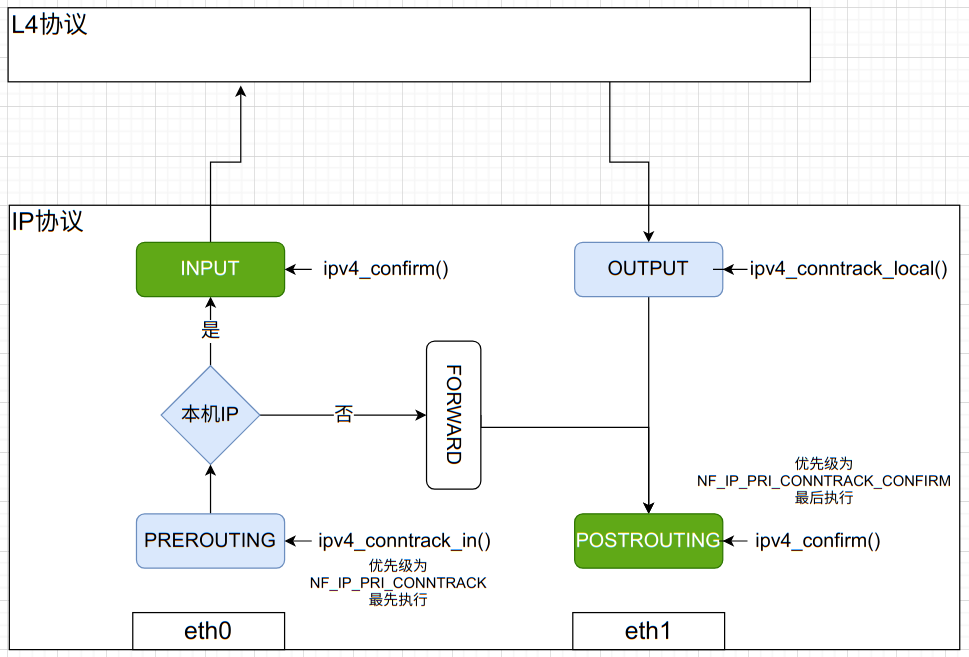
From ipv4_conntrack_ops definition, we can get the schematic diagram in the figure above. The conntrack of ipv4 uses four HOOK points in netfilter, namely, preouting and LOCAL_OUT,LOCAL_IN and POSTROUTINTG. We can classify the four HOOK points. The first two are the HOOK points when the message enters the IP protocol layer, and the last two are the HOOK points when the message leaves the IP layer.
First, let's introduce the data structure used by the kernel for conntrack. The core data structure of ct is struct nf_conn, here you can focus on the description of the tuplehash field. A ct record actually maintains the state of two directions of a connection, which are called ORIGIN and REPLY. As the name suggests, ORIGIN is the original direction, which can be understood as the direction of the message when creating ct; REPLY is the response direction, that is, the direction of the response message. To maintain both directions of a connection, nf_conn uses a type of struct NF with a length of 2_ conntrack_ tuple_ Array of hash:
struct nf_conn {
[...]
#ifdef CONFIG_NF_CONNTRACK_ZONES
struct nf_conntrack_zone zone;
#endif
/* This can be said to be the most important field in conntrack. It is an array with a length of 2,
* The type is struct nf_conntrack_tuple_hash.
*
* struct nf_conntrack_tuple_hash It is used to represent A connection, such as native A
* If a TCP connection is established to server B, the first element in the array represents
* A -> B Connection, tuplehash [0] SRC stores the address and port of A, tuplehash [0] dst
* The address and port of B are stored.
*
* Since conntrack tracks two-way connections, tuplehash[1] stores this connection
* The connection of B - > A in, i.e. tuplehash [1] SRC stores the address and port of B,
* tuplehash[1].dst The address and port of B are stored.
*/
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* The status flag of the current ct, including whether confirm, whether response package has been received, etc. */
unsigned long status;
u16 cpu;
/* The network namespace to which it belongs. */
possible_net_t ct_net;
#if IS_ENABLED(CONFIG_NF_NAT)
struct hlist_node nat_bysource;
#endif
/* all members below initialized via memset */
struct { } __nfct_init_offset;
/* If we were expected by an expectation, this will be it */
struct nf_conn *master;
#if defined(CONFIG_NF_CONNTRACK_MARK)
u_int32_t mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
u_int32_t secmark;
#endif
/* Extensions */
struct nf_ct_ext *ext;
/*
* Protocol related content, such as TCP window information, etc.
*/
union nf_conntrack_proto proto;
};
Next, we will introduce the following ct States and some flag bits. The following are the ct flags (which will be set in the status field above):
enum ip_conntrack_status {
/* It's an expected connection: bit 0 set. This bit never changed */
IPS_EXPECTED_BIT = 0,
IPS_EXPECTED = (1 << IPS_EXPECTED_BIT),
/* Whether the current ct has received the REPLY message. */
IPS_SEEN_REPLY_BIT = 1,
IPS_SEEN_REPLY = (1 << IPS_SEEN_REPLY_BIT),
/* Conntrack should never be early-expired. */
IPS_ASSURED_BIT = 2,
IPS_ASSURED = (1 << IPS_ASSURED_BIT),
/* Whether the current ct has been confirmed. confirm here can be understood as an effective message
* When leaving the IP protocol layer, the newly created ct will be confirmed and added to the hash table.
*
* ct without confirmation is not effective.
*/
IPS_CONFIRMED_BIT = 3,
IPS_CONFIRMED = (1 << IPS_CONFIRMED_BIT),
/* This indicates that SNAT is required for this connection */
IPS_SRC_NAT_BIT = 4,
IPS_SRC_NAT = (1 << IPS_SRC_NAT_BIT),
/* This indicates that DNAT is required for this connection */
IPS_DST_NAT_BIT = 5,
IPS_DST_NAT = (1 << IPS_DST_NAT_BIT),
/* Both together. */
IPS_NAT_MASK = (IPS_DST_NAT | IPS_SRC_NAT),
/* Connection needs TCP sequence adjusted. */
IPS_SEQ_ADJUST_BIT = 6,
IPS_SEQ_ADJUST = (1 << IPS_SEQ_ADJUST_BIT),
/* This marks the completion of SNAT initialization. */
IPS_SRC_NAT_DONE_BIT = 7,
IPS_SRC_NAT_DONE = (1 << IPS_SRC_NAT_DONE_BIT),
/* This marks the completion of DNAT initialization. */
IPS_DST_NAT_DONE_BIT = 8,
IPS_DST_NAT_DONE = (1 << IPS_DST_NAT_DONE_BIT),
/* Both together */
IPS_NAT_DONE_MASK = (IPS_DST_NAT_DONE | IPS_SRC_NAT_DONE),
[...]
};
In addition to the CT owned state, some states representing the direction of the current message are also maintained on the current skb and stored in the skb. According to this status, it can be determined whether the current message is in ORIGIN direction or REPLY direction (according to whether the status value is greater than IP_CT_IS_REPLY). This value will be set to skb during CT initialization or recovery.
enum ip_conntrack_info {
/* ct The chain has been built. This will enter this state after receiving the response message. */
IP_CT_ESTABLISHED,
/* Similar to NEW, I haven't figured out what to do */
IP_CT_RELATED,
/* ct Just created */
IP_CT_NEW,
/* This is a split line, and the following states are in the REPLY direction. */
IP_CT_IS_REPLY,
/* REPLY Direction building chain */
IP_CT_ESTABLISHED_REPLY = IP_CT_ESTABLISHED + IP_CT_IS_REPLY,
/* REPLY direction */
IP_CT_RELATED_REPLY = IP_CT_RELATED + IP_CT_IS_REPLY,
IP_CT_NUMBER,
};
4.2 conntrack initialization
Conntrack will initialize the conntrack record (hereinafter referred to as CT) when the message just enters the IP layer. This can be obtained from IPv4_ conntrack_ in()/ipv4_ conntrack_ The implementation of local () shows that both functions call nf_conntrack_in(), this function will find the corresponding CT from the hash table of conntrack according to the tuple information of the current message and restore it to the skb message. If the corresponding CT is not found, init is called_ Conntrack() creates a new CT. The whole process can be from resolve_normal_ct() shows. After finding (or creating) CT, the kernel will set the CT and the above-mentioned state to skb_ On the nfct field (via the nf_ct_set function).
Since NAT, IPVS and other modules will use ct, the hook function here should be executed before other modules, and its priority is NF_IP_PRI_CONNTRACK.
After setting ct to skb, the kernel will also call the processing function of specific protocol and further process ct, which is controlled by nf_conntrack_handle_packet(). Taking TCP as an example, TCP will maintain some TCP specific status information (such as SYN_SEND, SYN_RECEIVE, etc.) and do some legitimacy verification on ct. For example, if the serial number or ACK number of TCP message is not within the window range, the ct on skb will be reset without trace.
4.3 confirmation of conntrack
Before the message leaves the IP protocol layer, the kernel will confirm the ct. ct will be confirmed only once. After confirmation, the corresponding flag bit will be set, and the confirmation will not be repeated in subsequent messages. The confirmation of ipv4 will call ipv4_confirm, which will eventually be called__ nf_conntrack_confirm. The so-called confirmation is to insert ct into nf_conntrack_hash this hash table. Since the message content may be modified from entering to leaving the IP layer (such as NAT, IPVS, etc.), confirm needs to be carried out at the end, which is why the HOOK function of conntrack has the lowest priority in the HOOK point of POSTROUTING.
The insertion function of ct is__ nf_conntrack_hash_insert():
static void __nf_conntrack_hash_insert(struct nf_conn *ct,
unsigned int hash,
unsigned int reply_hash)
{
hlist_nulls_add_head_rcu(&ct->tuplehash[IP_CT_DIR_ORIGINAL].hnnode,
&nf_conntrack_hash[hash]);
hlist_nulls_add_head_rcu(&ct->tuplehash[IP_CT_DIR_REPLY].hnnode,
&nf_conntrack_hash[reply_hash]);
}
From this function, it can be seen that during hash insertion, the tunpehash on ct is inserted instead of ct, which hashes tunpehash [0] and tunpehash [1] respectively. This is reasonable. Taking a simple forward message in the following figure as an example, the ct of the same connection needs to be able to perform hash lookup according to the messages in two directions, so it is necessary to add the tuples in two directions to the hash table. At the same time, the direction of the current message (ORIGIN or REPLY) can be determined according to which tuple is found (the first or the second).
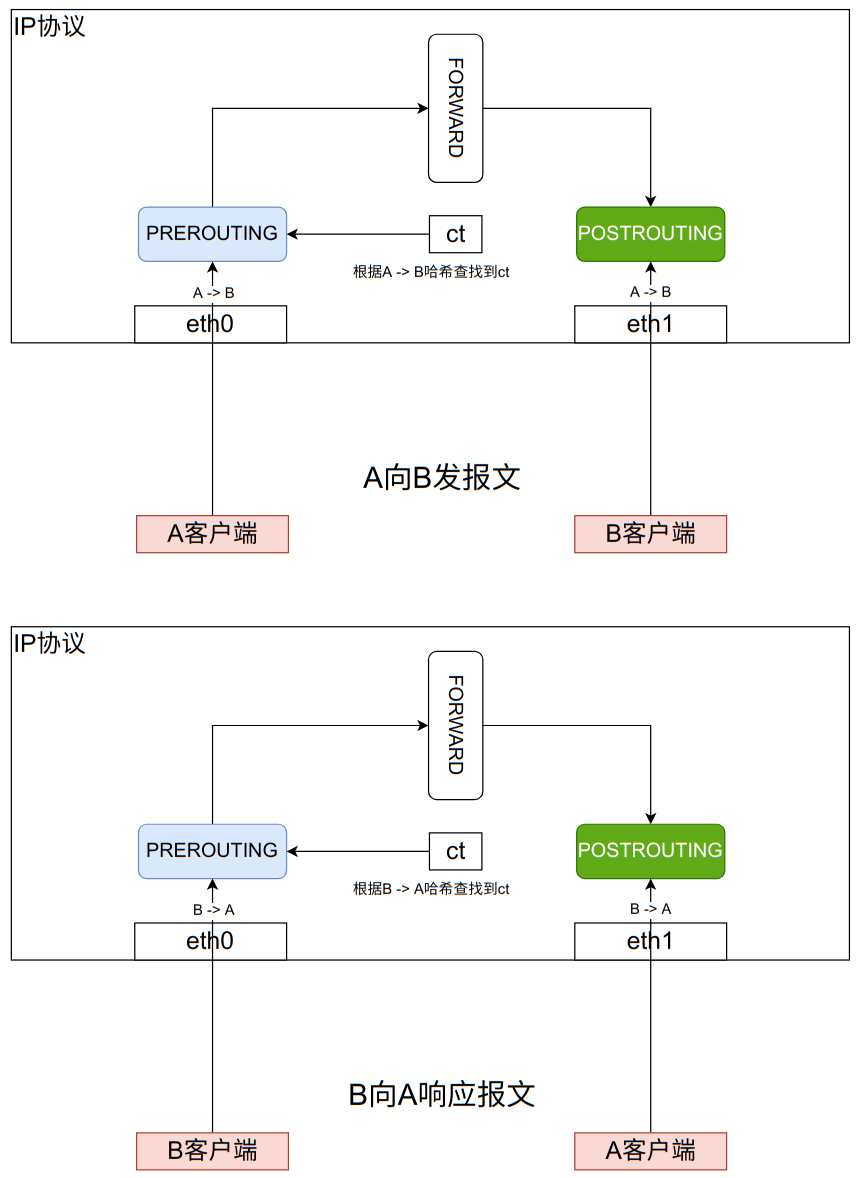
4.4 NAT Principle
netfilter's NAT module is inseparable from conntrack, so let's introduce it here. Nat can be divided into SNAT (source address forwarding) and DNAT (destination address forwarding). The modules capable of NAT are iptables, nftables, etc. It should be noted that both iptables and nftables use NAT provided by netfilter and implemented in netfilter. iptables/nftables itself is only a simple call to the NAT of netfilter. Here, take the NAT of IPV4 as an example.
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_in,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_out,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* Before packet filtering, change destination */
{
.hook = nf_nat_ipv4_local_fn,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
{
.hook = nf_nat_ipv4_fn,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
NAT's HOOK point is complementary to conntrack, and it is also a HOOK function registered on the four HOOK points. All four HOOK functions eventually call the same function nf_nat_inet_fn(), so we just need to look at this function.
Several concepts need to be clarified here. The first is the manitype in the code, which is used to distinguish the HOOK points of SNAT and DNAT. Its values include:
- NF_NAT_MANIP_SRC: indicates that the current HOOK point needs to check whether SNAT is required. This includes POSTROUTING and LOCAL_IN two HOOK points
- NF_NAT_MANIP_DST: it represents the current HOOK point and needs to check whether DNAT is required. This includes preouting and LOCAL_OUT two HOOK points
The second is NAT initialization. During the period from ct creation to confirmation, the initialization of NAT state on ct will be completed. Where, in NF_ NAT_ MANIP_ The SRC will initialize the SNAT status; In NF_ NAT_ MANIP_ Initialize DNAT status at DST. Initialization here is the key to the implementation of NAT. As can be seen from the following switch statement, the initialization process will come when ct does not enter the ESTABLISHED state (REPLY message is received).
Here we need to explain the registration of NAT HOOK function. As analyzed above, netfilter registers hooks on four HOOK points. What happens when we add a NAT type chain using nftable/iptables? At this point, the NF corresponding to this chain_ HOOK_ Ops will not be registered to the HOOK point of netfilter, but will be registered to the private field of NAT HOOK function on the corresponding HOOK point. When the NAT HOOK function finds that it has registered other hooks, it will call these hooks to initialize NAT, that is, netfilter will give control to nftables/iptables. If no HOOK is found, the netfilter default initialization function NF is called_ nat_ alloc_ null_ Bind() to initialize NAT.
unsigned int
nf_nat_inet_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
struct nf_conn_nat *nat;
/* maniptype == SRC for postrouting. */
enum nf_nat_manip_type maniptype = HOOK2MANIP(state->hook);
/* This function is the core function of netfilter for NAT. It is used in pre routing, post routing
* local_out And local_in will be called.
*/
/* NAT Receiving and contracting processing logic. First, check whether there is conntrack information. If not, directly
* Return to ACCEPT. The conntrack module will create conntrack information before the NAT module.
*
* conntrack The creation of occurs in preouting (ipv4_conntrack_in() function) or
* LOCAL_OUT(ipv4_conntrack_local()Function), from which we can see that the kernel will
* conntrack the locally sent and received messages.
*/
ct = nf_ct_get(skb, &ctinfo);
if (!ct)
return NF_ACCEPT;
nat = nfct_nat(ct);
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
/* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */
case IP_CT_NEW:
/* Initialize NAT in both directions. This process usually triggers conntrack
* The record is completed during the processing of the message created.
*
* In preouting / local_ DNAT initialization will be completed at out;
* In postrouting / local_ SNAT initialization will be completed at in.
*/
if (!nf_nat_initialized(ct, maniptype)) {
struct nf_nat_lookup_hook_priv *lpriv = priv;
struct nf_hook_entries *e = rcu_dereference(lpriv->entries);
unsigned int ret;
int i;
if (!e)
goto null_bind;
/* Traverse the entries on the current ops and process the message. If current
* HOOK If ops exists on the point and NAT is performed on the message, the NAT on ct
* The message will be initialized and jump to do_nat.
*/
for (i = 0; i < e->num_hook_entries; i++) {
ret = e->hooks[i].hook(e->hooks[i].priv, skb,
state);
if (ret != NF_ACCEPT)
return ret;
if (nf_nat_initialized(ct, maniptype))
goto do_nat;
}
null_bind:
/* Default NAT initialization function (no NAT) */
ret = nf_nat_alloc_null_binding(ct, state->hook);
if (ret != NF_ACCEPT)
return ret;
} else {
pr_debug("Already setup manip %s for ct %p (status bits 0x%lx)\n",
maniptype == NF_NAT_MANIP_SRC ? "SRC" : "DST",
ct, ct->status);
if (nf_nat_oif_changed(state->hook, ctinfo, nat,
state->out))
goto oif_changed;
}
break;
default:
/* ESTABLISHED */
WARN_ON(ctinfo != IP_CT_ESTABLISHED &&
ctinfo != IP_CT_ESTABLISHED_REPLY);
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
do_nat:
/* After initializing the NAT information in ct, we call here to modify the content of the message. Here will
* When ct - > status is marked with NAT enabled, use the information in ct to modify the message
* Content (address, port, etc.).
*/
return nf_nat_packet(ct, ctinfo, state->hook, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
Either the default initialization function or the default initialization function will eventually call nf_nat_setup_info() function. The functions of this function include:
- Select an available (Unused) tuple from the range and set it to the tuple in the REPLY direction of ct
- Sets the state of NAT initialization
Note the range here, which stores the range of tuples. If the current function is called by the default initialization function, the range stores the original tuple (refer to the implementation of nf_nat_alloc_null_binding()), and use get_ unique_ The new element group obtained by tuple () must be the same as the original; If it is the hook function of nftables/iptables, the range here stores the target tuple (SNAT, source address and port information; DNAT, destination address information), and the obtained new element group must be different from the original (refer to the implementation of nft_nat_eval() function).
unsigned int
nf_nat_setup_info(struct nf_conn *ct,
const struct nf_nat_range2 *range,
enum nf_nat_manip_type maniptype)
{
struct net *net = nf_ct_net(ct);
struct nf_conntrack_tuple curr_tuple, new_tuple;
/* Can't setup nat info for confirmed ct. */
if (nf_ct_is_confirmed(ct))
return NF_ACCEPT;
/* This function initializes the state of NAT in conntrack record, including obtaining from range
* Tuples can be used to set ct status.
*/
WARN_ON(maniptype != NF_NAT_MANIP_SRC &&
maniptype != NF_NAT_MANIP_DST);
if (WARN_ON(nf_nat_initialized(ct, maniptype)))
return NF_DROP;
/* What we've got will look like inverse of reply. Normally
* this is what is in the conntrack, except for prior
* manipulations (future optimization: if num_manips == 0,
* orig_tp = ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple)
*/
nf_ct_invert_tuple(&curr_tuple,
&ct->tuplehash[IP_CT_DIR_REPLY].tuple);
/* Get the available tuples (stored in the tuple variable). This method first checks the current tuple
* (origin_tuple)Whether it is available. If it is available, use it directly. Basis for judging whether it is available
* Yes, use nf_nat_used_tuple() determines whether the tuple has been occupied.
*
* If it is already occupied, it will find the available address or port from the optional area and store it in the
* tunple Yes.
*
* For NAT, generally, iptables/nftables will call nf_nat_setup_info()
* Initialize the tuple information in SNAT or DNAT, and set the range as you want during initialization
* Value. After initialization, netfilter calls nf_nat_packet() according to the information in ct
* To modify the message.
*
* Note: for SNAT or DNAT operations, new_tuple and curr_ Tuples won't be equal because
* range The address or port range to be modified will be limited in. So, for SNAT or DNAT,
* ct->status IPS must be set in the flag bit_ SRC_ NAT or IPS_DST_NAT.
*/
get_unique_tuple(&new_tuple, &curr_tuple, range, ct, maniptype);
if (!nf_ct_tuple_equal(&new_tuple, &curr_tuple)) {
struct nf_conntrack_tuple reply;
/* If the new element group is different from the old one, it indicates that SNAT or DNAT has been sent. At this point, the
* The new tuple is applied to ct.
*/
/* Alter conntrack table so will recognize replies. */
nf_ct_invert_tuple(&reply, &new_tuple);
nf_conntrack_alter_reply(ct, &reply);
/* Judge whether SNAT or DNAT has occurred according to the current HOOK point. */
if (maniptype == NF_NAT_MANIP_SRC)
ct->status |= IPS_SRC_NAT;
else
ct->status |= IPS_DST_NAT;
if (nfct_help(ct) && !nfct_seqadj(ct))
if (!nfct_seqadj_ext_add(ct))
return NF_DROP;
}
if (maniptype == NF_NAT_MANIP_SRC) {
unsigned int srchash;
spinlock_t *lock;
srchash = hash_by_src(net,
&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple);
lock = &nf_nat_locks[srchash % CONNTRACK_LOCKS];
spin_lock_bh(lock);
hlist_add_head_rcu(&ct->nat_bysource,
&nf_nat_bysource[srchash]);
spin_unlock_bh(lock);
}
/* This step shows that NAT conflict detection has been completed and has entered the state where NAT can be performed. */
if (maniptype == NF_NAT_MANIP_DST)
ct->status |= IPS_DST_NAT_DONE;
else
ct->status |= IPS_SRC_NAT_DONE;
return NF_ACCEPT;
}
After completing the initialization of NAT, NF_ nat_ inet_ fn -> nf_ nat_ Packet function will be called. This function is used to modify the message content according to the tuple information in ct:
unsigned int nf_nat_packet(struct nf_conn *ct,
enum ip_conntrack_info ctinfo,
unsigned int hooknum,
struct sk_buff *skb)
{
enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);
enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);
unsigned int verdict = NF_ACCEPT;
unsigned long statusbit;
/* Judge whether the current HOOK point is SNAT or DNAT, and whether it is SNAT or DNAT with ct
* If the comparison is consistent, it indicates that NAT (modification message) is required.
*/
if (mtype == NF_NAT_MANIP_SRC)
statusbit = IPS_SRC_NAT;
else
statusbit = IPS_DST_NAT;
/* If the message is a response message, the direction of judgment should also be reversed. For example, SNAT here thinks
* PREROUTING The HOOK point should process the response message.
*/
if (dir == IP_CT_DIR_REPLY)
statusbit ^= IPS_NAT_MASK;
/* Non-atomic: these bits don't change. */
if (ct->status & statusbit)
verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);
return verdict;
}
It can be seen from the above process that NAT rules in nftables/iptables will be used only when ct is just created. Once ct is created, NAT rules will not be used for subsequent messages, and NAT will only be carried out according to the information on ct. It can be seen here that even deleting the corresponding NAT rule will not affect the progress of existing connections.
It should be noted that conntrack and NAT hooks are registered only when they are used. Nat depends on conntrack, so the registration of conntrack hooks will be triggered when NAT hooks are registered; The NAT of nftables/iptables depends on the NAT of netfilter. Therefore, when nftables adds a NAT type chain, it will trigger the registration of the NAT hook of netfilter (the same principle is used for logout).